

「もう優れたモデルは必要ない」――Redditの話題の投稿に集まったAI業界の多様な声
TechFlow厳選深潮セレクト
「もう優れたモデルは必要ない」――Redditの話題の投稿に集まったAI業界の多様な声
能力の飛躍を主な特長とするフラッグシップ製品において、「セキュリティのために犠牲になる可用性」が、ユーザーが購入を決断する際の最も重要な要因となっています。
著者:フライデー、TechFlow
Anthropicは、紙の上では完璧な成績表を提出しました。
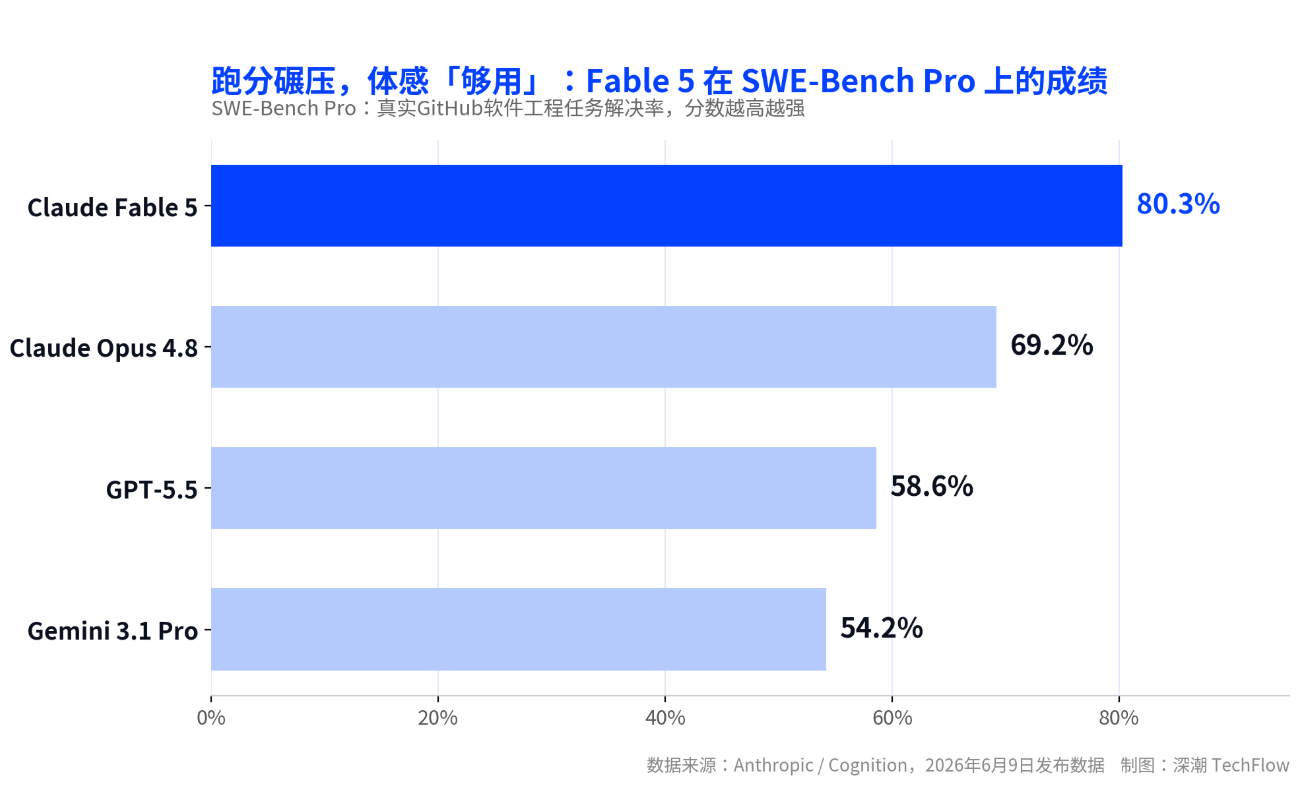
6月9日にリリースされたClaude Fable 5は、同社初の一般公開向けMythosクラスモデルであり、実際のソフトウェア工学タスクを評価するベンチマーク「SWE-Bench Pro」で80.3%というスコアを記録しました。これは自社前世代のフラッグシップモデルOpus 4.8を約11ポイント上回り、GPT-5.5を20ポイント以上も上回る結果です。
しかし、ユーザーの反応はやや冷めました。
リリースから3日後、週間アクセス数30.5万のRedditコミュニティr/artificialにて、人気投稿のタイトルにはこう書かれていました。「Claude Fableを使ってみて気づいたが、私はもう『より優れたモデル』を必要としていない」。投稿者Axi0m-22氏は、Fableを一時的にセキュリティ研究および日常業務に活用したものの、すぐにコード作成にはOpusへ、雑務処理にはHaikuへ戻ったと述べています。彼は次のように比喩しています:「iPhone 14を使っている人がiPhone 17の発表を見るようなものだ。新しい方が確かに優れているのは分かっているが、『まあ、今のでも十分だ』と思ってしまう。」
高評価コメント欄は「十分派」が支配:モデルへの審美疲労が主流の感情に
トップのコメント(42票獲得)にはこうあります。「より大きなコンテキストウィンドウ以外では、私はOpus 4.5以降、さらに強力なモデルを必要としなくなったと感じている。」
別のユーザーhyprlab氏のコメント(13票獲得)はこうです。「トークン消費量がより多くなるモデルに切り替えることによって、私のワークフローにどのようなメリットがあるのか、私には見えない。Opus 4.8のハイインテンシティモードで既に十分快適だ。」
このような発言の背景には、共通のコスト計算があります。
Fable 5のAPI価格は、100万トークンあたり10ドルで、Opus 4.8のほぼ2倍に相当します。ユーザーsiromega37氏は率直に述べています。「トークン消費量が増えたにもかかわらず、投資対効果が見られない。我々は今、プラットフォーム期に入りつつあり、いずれバブルは弾けるだろう。」
ユーザーhobopwnzor氏は、さらに体系的な解釈を示しています。「我々はすでにS字型曲線の頂点付近に長く留まっている。最近の進歩は、主にツール呼び出しや周辺エンジニアリングによるものであり、モデルそのものの能力向上ではない。」
セキュリティガードレールが最大の不満点:「90%の用途が即座に拒否される」
「十分」という感覚はまだ感情の問題に過ぎませんが、セキュリティガードレールに対する不満は、具体的な製品課題です。
Anthropicの公式説明によると、Fable 5は、ごく少数の機関のみに提供されるMythos 5と同一の基盤モデルを採用しており、唯一の違いはFableに追加されたセキュリティ分類器にあります。サイバーセキュリティなどの高リスク領域に関するリクエストは遮断され、代わりにOpus 4.8が応答します。同社はこのメカニズムをやや保守的に調整しており、平均して5%未満の会話でしかトリガーされず、無害なリクエストを誤ってブロックすることもあると説明しています。
しかし、このReddit投稿におけるユーザーの体感では、トリガー頻度は明らかに5%を大幅に上回っています。17票獲得のユーザーjradoff氏は、「自分のコードのセキュリティチェックをFableに依頼したが、セキュリティに関連する話題に触れただけでほぼすべてのリクエストが拒否された」と述べ、その後Opusへフォールバックしたと報告しています。さらに12票獲得のコメントはもっと厳しい口調で、「あなたがこれでやりたいことの90%は拒否されるため、実質的に使い物にならない」と指摘しています。
有料ユーザーの不満はさらに強いものです。月額200ドルプランのサブスクライバーkaitava氏は次のように記しています。「私は2倍の使用料を支払っているのに、一度だけセキュリティレビューを行おうとしたところ、Opusへダウングレードされてしまった。これにより、私はFableに対して一切の好意を失い、OpenAIの追いつきを待つばかりだ。」
能力の飛躍を謳うフラッグシップ製品にとって、「セキュリティ確保のために支払う可用性の代償」は、ユーザーが購入を決断する上で最も重要な変数になりつつあります。
反論の声:重いタスクをこなすユーザーにとっては「夜と昼ほどの差」
この人気投稿には、もちろん反論も存在し、しかも反論者のプロフィールは非常に明確です。つまり、タスクが重ければ重いほど、評価も高くなります。
ユーザーPhylaras氏のコメント(15票獲得)はこうです。「Fableは私にとって実質的な違いを生んでいます。特にコンテキストウィンドウの要求が極めて大きい複雑なタスクにおいて、これまで見逃されていたエラーを検出してくれました。」また、高エネルギー物理学のシミュレーションを手がけているというユーザーは、単一のシミュレーションモデルが8,000〜1万行のコードからなり、数百のモデルが相互作用していると説明し、「環境の詳細を理解し、独立して継続的に作業できるモデルがあれば、それは私にとって極めて期待されるものだ」と述べています。
最も激しい反論はユーザーNavetz氏から寄せられました。「正直に言うと、このモデルを使ったことがある人なら、このような投稿は狂気の沙汰だと感じるでしょう。私にとってはまるで別人のように賢く感じられ、今も絶え間なく利用しています。非技術系の友人に説明するならば、これは大学生のバスケットボール選手がNBAのスターターに突然昇格するようなものだと伝えます。」
中立的な活用法を提案するユーザーもいます。ユーザーready-eddy氏は、Fableを日常的な「構築者」ではなく、「計画立案者および修正者」として使うよう勧めています。ただし、コストを気にしない場合は別です。別のコメントは、よりマニュアル風に要約しています。「Fableで表計算を行うのはモデルの選択ミスであり、Haikuで16個のエージェントが絡む複雑なタスクを実行するのも同様に選択ミスです。『本質的に悪いモデル』など存在せず、あるのは『用途に合わないモデル』だけなのです。」
ベンチマークスコアとユーザー体感が乖離した後、パブリックAIは今後もさらに強化されるのか?
この議論の中で最も興味深いコメントは、製品の話題から業界構造へと視点を広げています。
ユーザーKedMcJenna氏は、「パブリックAI凍結仮説」を提起しました。すなわち、一般ユーザーが実際に利用可能なモデルは、当面、現在の水準付近で永遠に停止する可能性があり、企業や政府のエリート層だけが、さらに優れたプライベートモデルを継続的に享受していくだろう、という仮説です。「我々が知っているのは少なくともMythosだが、それよりもさらに強力で、我々が決して耳にすることのないモデルが存在する可能性も十分にある。」
このコメントは事実を指し示しています。Mythos 5は実際、一般公開されておらず、現時点ではProject Glasswingプログラムを通じて、ネットワーク防衛機関および重要インフラ企業に限定的に提供されています。
ベンチマークスコアと世論を併せて見れば、その結論は矛盾しません。
ベンチマークテストは能力の上限を測るものであり、一方でRedditの高評価コメント欄は、日常的なニーズの天井を反映しています。大多数のユーザーのタスクがすでにOpus 4.6の時代に満たされていた場合、より強力なモデルは物理シミュレーションや超長コンテキストといった極端なケースにおいてのみ、その価値を証明できます。モデルメーカーが直面している課題は、もはや「それが可能かどうか」ではなく、「誰がそれを必要とし、いくら払う意思があるか、そしてどれだけのセキュリティ上の摩擦を許容できるか」という点へと移行しています。
リリースからわずか3日で、Fable 5はベンチマークスコアと世論の場で、まったく異なる二つの成績表を手に入れました。どちらがより真実に近いかは、今後のAnthropicによるセキュリティ分類器の調整スピードと、ヘビーユーザーたちの「財布による投票」次第です。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













