

a16z:大規模言語モデルのデプロイ=忘却——「継続学習」はこの悪循環を打破できるか?
TechFlow厳選深潮セレクト
a16z:大規模言語モデルのデプロイ=忘却——「継続学習」はこの悪循環を打破できるか?
突破点在于,使模型在部署后进行训练时,能够发挥其强大能力的关键要素:压缩、抽象与学习。
著者:マリカ・アウバキロワ、マット・ボーンスタイン
編集・翻訳:TechFlow
TechFlow解説: 大規模言語モデル(LLM)は訓練が完了すると「凍結」され、デプロイ後に動作を維持するにはコンテキストウィンドウやRAG(Retrieval-Augmented Generation)といった外部のパッチに頼らざるを得ません。本質的には、映画『メメント』に登場する記憶障害患者と同じ状態——検索は可能でも、本当に新しいことを「学ぶ」ことはできないのです。a16zの2人のパートナーが、「継続的学習(continual learning)」という最先端の研究分野を体系的に整理し、コンテキスト、モジュール、重み更新という3つのアプローチから、AIの能力上限を再定義する可能性を秘めたこの技術領域を解き明かします。
クリストファー・ノーラン監督の映画『メメント』において、主人公レナード・シェルビーは断片化した「今ここ」に生きています。脳損傷により彼は順行性健忘症を患い、新たな記憶を形成できなくなっています。数分ごとに世界がリセットされ、永遠に「現在」に閉じ込められ、直前に何が起きたのか、次に何が起こるのかを思い出せません。生き延びるために、彼は体に文字を刺繍し、ポラロイド写真を撮って記録します——こうした外部ツールが、彼の脳が果たせない記憶機能の代わりとなっているのです。
大規模言語モデルも、同様の「永遠の現在」に生きています。訓練終了後、膨大な知識はパラメータ内に凍結され、モデルは新たな記憶を形成できず、新規の経験に基づいて自身のパラメータを更新することもできません。この欠陥を補うため、私たちはいくつもの足場(scaffolding)を構築しました:チャット履歴は短期的な付箋として機能し、検索システムは外部ノートブックとなり、システムプロンプトは体に刻まれた刺繍のようになっています。しかし、モデルそのものは、これらの新しい情報を一度も真正に「内面化」してはいません。
ますます多くの研究者が、これでは不十分だと考え始めています。イン・コンテキスト学習(ICL)が解決できる問題は、その答え(あるいはその断片)がすでに世界のどこかに存在しているという前提に立っています。しかし、まったく新しい数学的証明のような「真に発見を要する」課題、セキュリティ攻防のような「対抗的」な状況、あるいは言語で表現しがたいほどに潜在的・暗黙的な知識については、モデルがデプロイ後に新たな知識や経験を直接パラメータに書き込む手段を必要とするという、十分な根拠があります。
イン・コンテキスト学習は一時的です。真の学習には「圧縮」が必要です。私たちがモデルに継続的な圧縮を許容するまで、おそらく私たちは『メメント』の「永遠の現在」に閉じ込められたままになるでしょう。逆に言えば、モデルに「自分自身の記憶アーキテクチャを学ばせる」ことで、外部のカスタムツールへの依存を排除できれば、まったく新しいスケーリング次元が開かれるかもしれません。
この研究分野は継続的学習(continual learning)と呼ばれます。この概念自体は新しいものではありません(参考: McCloskey および Cohen の1989年の論文)。しかし、我々はそれが現在のAI分野において最も重要な研究テーマの一つであると確信しています。過去2~3年間にモデルの能力が爆発的に向上した結果、モデルが「既に知っていること」と「知り得ること」の間のギャップが、ますます顕著になってきています。本稿の目的は、この分野のトップ研究者たちから学んだ知見を共有し、継続的学習のさまざまなアプローチを明確に整理し、スタートアップエコシステムにおけるこのトピックの発展を促進することにあります。
注:本稿の完成には、優れた研究者、博士課程の学生、そして起業家たちとの深く濃密な対話が不可欠でした。彼らは、継続的学習分野における自らの研究と洞察を惜しみなく共有してくださいました。理論的基盤からデプロイ後の学習にまつわる工学的現実に至るまで、彼らの鋭い洞察がなければ、本稿は我々が単独で執筆したものよりもはるかに堅固なものにはならなかったでしょう。お時間を割き、貴重なアイデアをご提供いただいた皆様に、心より感謝申し上げます!
まず、コンテキストについて
パラメータレベルの学習(すなわち、モデルの重みを更新する学習)を擁護する前に、一つの事実を認める必要があります:イン・コンテキスト学習は確かに機能します。さらに、この手法が今後も優位を保ち続けるという非常に強力な主張もあります。
Transformerの本質は、シーケンスに基づく条件付きトークン予測器です。適切なシーケンスを与えれば、驚くほど豊かな振る舞いが得られ、重みに一切手を加える必要はありません。だからこそ、コンテキスト管理、プロンプトエンジニアリング、指令微調整(instruction fine-tuning)、少样本(few-shot)例示といった手法がこれほど強力なのです。知能は静的なパラメータに封じ込められており、その表現される能力は、ウィンドウに与える内容によって劇的に変化します。
Cursor社が最近公開した、自律型プログラミングエージェントのスケーリングに関する詳細な記事が良い例です:モデルの重みは固定されていますが、システムを実際に動かしているのは、コンテキストの精巧な編成——何を入れるか、いつサマリーを取るか、数時間にわたる自律的実行の中で一貫した状態をいかに維持するか——です。
OpenClawもまた良い例です。それが注目を集めたのは、特別なモデル権限(基盤となるモデルは誰でも利用可能)があったからではなく、コンテキストとツールを極めて効率的に「作業状態」へと変換したからです:ユーザーが何をしているかを追跡し、中間成果物を構造化し、いつプロンプトを再注入すべきかを判断し、以前の作業を永続的に記憶する。OpenClawは、エージェントの「外装設計(shell design)」を、独立した学問分野へと高めました。
プロンプトエンジニアリングが登場した当初、多くの研究者は「プロンプトだけ」で正式なインタフェースになり得るという考えに懐疑的でした。それはハックのように見えました。しかし、これはTransformerアーキテクチャのネイティブな産物であり、再訓練を必要とせず、モデルの進化とともに自動的に向上します。モデルが強くなれば、プロンプトも強くなります。「簡素だがネイティブ」なインタフェースはしばしば勝利します。なぜなら、それは基盤となるシステムに直接結合しており、対立してはいないからです。これまでのLLMの発展軌道はまさにそれでした。
状態空間モデル(SSM):コンテキストの「ステロイド版」
主流のワークフローが、単純なLLM呼び出しからエージェントループへと移行するにつれ、コンテキスト学習モデルに対する負荷は増大しています。かつては、コンテキストウィンドウが完全に埋まる状況は比較的稀でした。これは通常、LLMに多数の離散的タスクを一連で実行させる場合に生じ、アプリケーション層ではチャット履歴を比較的直感的に切り詰めたり圧縮したりできました。しかし、エージェントにとっては、単一のタスクだけで利用可能なコンテキスト全体の大部分を消費してしまうことがあります。エージェントループの各ステップは、前の反復で渡されたコンテキストに依存しています。そして、しばしば20〜100ステップの後に「途切れ」——コンテキストが満杯になり、一貫性が劣化し、収束できなくなる——ために失敗します。
そのため、主要なAI研究所は現在、超長コンテキストウィンドウを備えたモデルを開発するために、多大なリソース(すなわち、大規模な訓練実行)を投入しています。これは自然な道筋であり、すでに有効な方法(コンテキスト学習)を土台とし、業界全体が推論時の計算へとシフトする大きなトレンドにも合致しています。最も一般的なアーキテクチャは、通常のアテンションヘッドの間に固定メモリ層(すなわち状態空間モデル(SSM)および線形アテンションの亜種)を挿入するものです(以下、統一してSSMと呼称)。SSMは長コンテキストのシナリオにおいて、根本的に優れたスケーリング曲線を提供します。
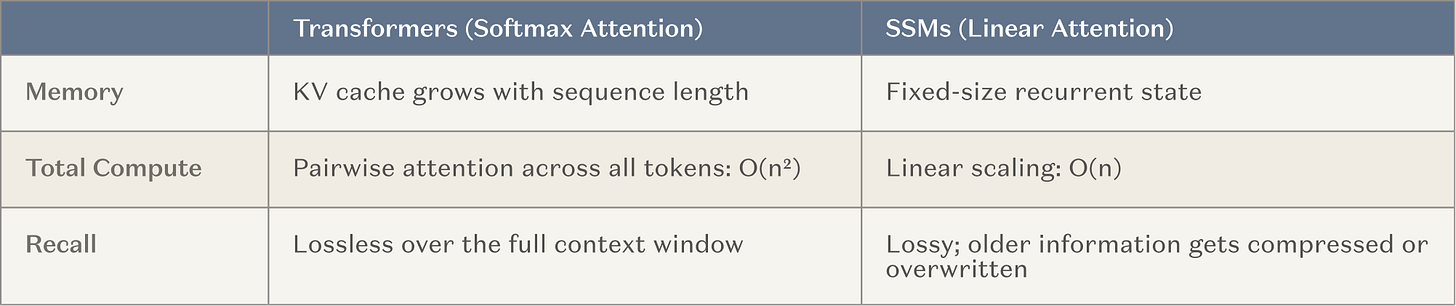
図解:SSMと従来のアテンション機構のスケーリング比較
目標は、エージェントが一貫した状態で実行できるステップ数を、約20ステップから約20,000ステップへと、数桁単位で向上させつつ、従来のTransformerが提供する広範なスキルと知識を失わないことです。これが成功すれば、長時間稼働するエージェントにとって重大なブレイクスルーとなります。この手法を一種の継続的学習と見なすこともできます:重みの更新は行われませんが、ほとんどリセットを必要としない外部メモリ層が導入されます。
したがって、こうした非パラメトリックな手法は、現実的かつ強力です。継続的学習を評価する際には、まずここから出発しなければなりません。問題は、今日のコンテキストシステムが「役に立つかどうか」ではなく、むしろ「すでに限界に達しているかどうか」、そして新しい手法がそれをさらに押し広げられるかどうかです。
コンテキストが見落としているもの:「書類棚の誤謬」
「AGIと事前学習が起こしたことは、ある意味で過剰適合だった……人間はAGIではない。はい、人間には一定のスキル基盤があるが、人間は大量の知識を欠いている。我々が依拠しているのは、継続的学習だ。もし私がスーパーインテリジェントな15歳の少年を作り出したとしても、彼は何も知らないだろう。優秀な生徒で、学ぶ意欲に満ちている。あなたは彼に『プログラマーになれ』『医者になれ』と言うことができる。デプロイそのものが、何らかの学習や試行錯誤のプロセスを含むのだ。それは製品をそのまま投げ出すのではなく、プロセスなのだ。」——イリヤ・スツケバー
無限のストレージ容量を持つシステムを想像してみてください。世界最大の書類棚で、あらゆる事実が完璧にインデックス化され、即座に検索可能です。それは何でも検索できます。では、それは「学んだ」のでしょうか?
いいえ。それは一度も「圧縮」を強いられたことがありません。
これが我々の議論の核心であり、イリヤ・スツケバーが以前に提起した主張を引用しています:LLMは本質的に圧縮アルゴリズムです。訓練過程において、それらはインターネットをパラメータに圧縮します。この圧縮は損失ありであり、その損失こそが力を生み出すのです。圧縮はモデルに構造を探求させ、一般化させ、コンテキストを超えて転送可能な表現を構築させます。すべての訓練サンプルを丸暗記するモデルは、根底にある法則を抽出するモデルよりも劣ります。損失あり圧縮そのものが学習なのです。
皮肉なことに、LLMを訓練中にこれほど強力にするメカニズム(生データをコンパクトで転送可能な表現に圧縮すること)は、まさにデプロイ後にそれらが継続して行うことを我々が拒否しているものです。我々はリリースの瞬間に圧縮を止め、外部メモリで代替します。もちろん、ほとんどのエージェントの外装は、何らかのカスタマイズされた方法でコンテキストを圧縮します。しかし、「苦い教訓(bitter lesson)」とは、モデル自身がこの圧縮を、直接的かつ大規模に学ぶべきであると教えてくれるのではないでしょうか?
ユ・サン氏は、この論争を明らかにするために「数学」の例を提示しています。フェルマーの最終定理を考えてみましょう。350年以上にわたり、数学者たちはこれを証明できませんでした。それは正しい文献資料が不足していたからではなく、解法が極めて革新的であったためです。既存の数学的知識と最終的な答えとの間の概念的距離が大きすぎたのです。アンドリュー・ワイルズは1990年代にようやくこれを解決しましたが、彼はほぼ孤立した状態で7年間働き、答えに到達するためにまったく新しい技術を発明せざるを得ませんでした。彼の証明は、楕円曲線とモジュラー形式という2つの異なる数学分野を成功裏に橋渡しすることに依拠しています。ケン・リベットは、この接続が確立されればフェルマーの最終定理が自動的に解決されることをすでに証明していましたが、ワイルズ以前には、実際にこの橋を構築するための理論的道具を備えていた数学者は一人もいませんでした。グリゴリー・ペレルマンによるポアンカレ予想の証明も、同様の議論が可能です。
核心的な問いは次の通りです: これらの例は、LLMが何かを欠いている——先験的知識を更新し、真に創造的な思考を行う能力——ことを示しているのでしょうか? それとも、むしろ逆の結論を証明しているのでしょうか? つまり、すべての人間の知識は単に訓練・再構成可能なデータに過ぎず、ワイルズやペレルマンは、LLMがより大規模なスケールで同じことを可能にすることを示したに過ぎない、という結論です。
この問いは経験的なものであり、その答えはまだ確定していません。しかし、少なくとも我々は、イン・コンテキスト学習が現在失敗するが、パラメータレベルの学習が有効かもしれない問題のカテゴリーがいくつかあることを確かによく知っています。例えば:

図解:イン・コンテキスト学習が失敗し、パラメータ学習が優位に立つ可能性のある問題カテゴリー
さらに重要なのは、イン・コンテキスト学習は言語で表現可能なものを扱うのみであるのに対し、重みはプロンプトでは言語化できない概念を符号化できます。あるパターンは、次元が高すぎ、隠蔽されすぎ、構造が深く複雑すぎて、コンテキストには収まりません。例えば、医学用スキャン画像において良性の偽影と腫瘍を区別する視覚的テクスチャ、あるいは話し手固有のリズムを定義する音声の微細な波動などです。こうしたパターンは、正確な語彙に分解するのが困難です。言語はそれらを近似するにすぎません。どんなに長いプロンプトを書いても、これらを伝えることはできません。こうした知識は重みの中にしか存在できません。それらは学習された表現の潜在空間(latent space)に生き、文字ではありません。コンテキストウィンドウがどれほど拡大しても、テキストでは記述できない知識は常に存在し、パラメータにのみ保持されます。
この点が、ChatGPTの「メモリ」機能など、明示的な「ロボットがあなたを覚えている」機能が、ユーザーに驚きよりもむしろ不快感を与える理由を説明しているかもしれません。ユーザーが本当に望んでいるのは「思い出すこと」ではなく、「能力」です。あなたの行動パターンを既に内面化したモデルは、新しい状況へと一般化できます。一方、単にあなたの履歴を記憶しているだけのモデルはそうできません。「あなたが前回このメールに返信したときの文章」(一字一句の再現)と、「あなたの思考スタイルを十分に理解し、あなたが何を必要とするかを予測できるようになった」ことの間の差異こそが、検索と学習の差異なのです。
継続的学習の入門
継続的学習には複数のアプローチがあります。分岐点は「記憶機能があるかないか」ではなく、「圧縮はどこで起こるか?」という点にあります。これらのアプローチは、圧縮がない(純粋な検索、重みは凍結)から、完全に内部での圧縮(重みレベルの学習、モデルがより賢くなる)へと連続するスペクトラム上に位置し、その間に重要な中間地帯(モジュール)があります。
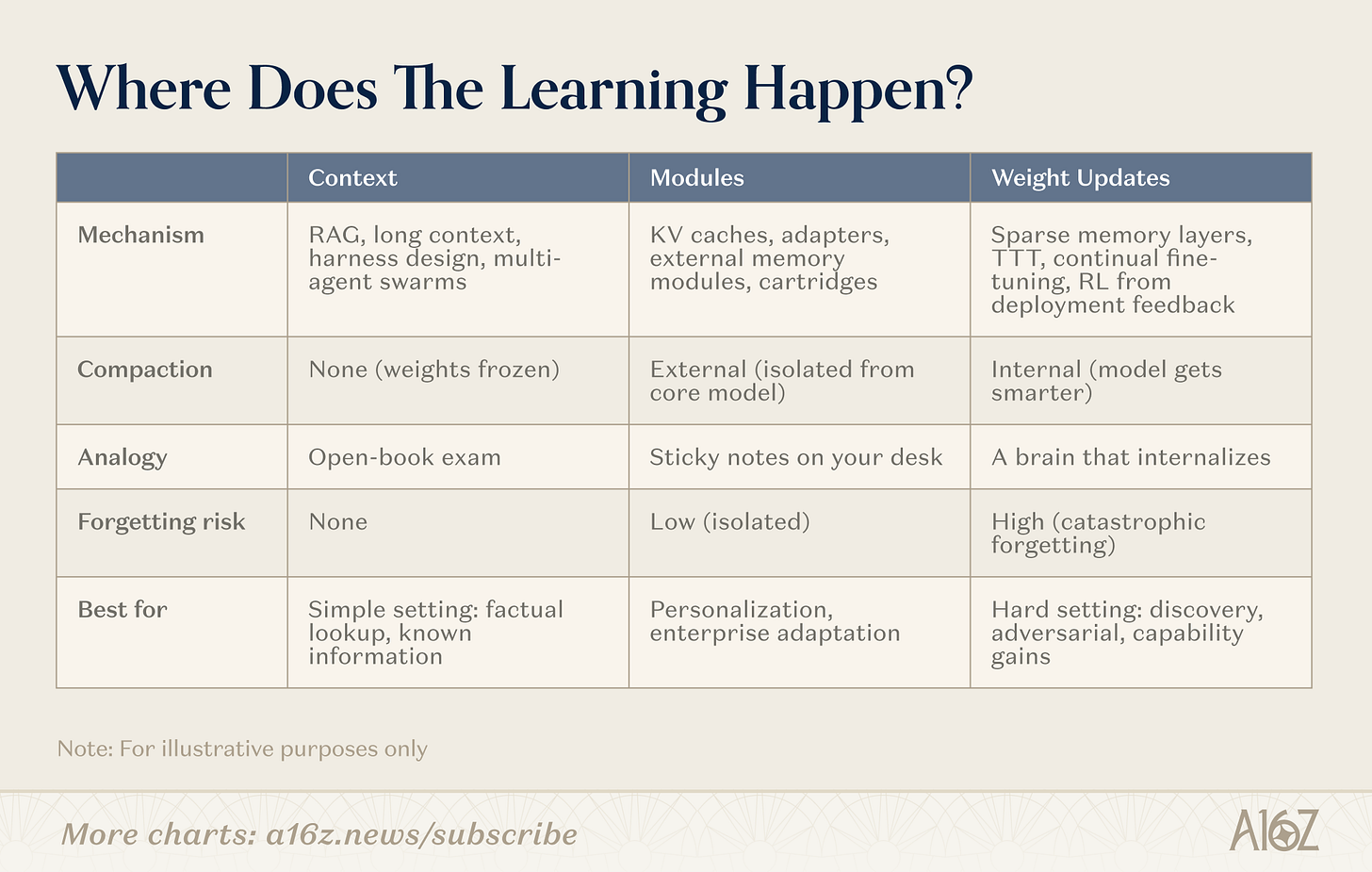
図解:継続的学習の3つのアプローチ——コンテキスト、モジュール、重み
コンテキスト
コンテキストの端では、チームはよりスマートな検索パイプライン、エージェント外装、プロンプト編成を構築します。これは最も成熟したカテゴリーであり、インフラは検証済みで、デプロイの道筋も明確です。制約は「深さ」——すなわちコンテキスト長にあります。
注目に値する新しい方向性として、コンテキストそのもののスケーリング戦略としてのマルチエージェントアーキテクチャがあります。単一のモデルが128Kトークンのウィンドウに制限されているならば、それぞれが独自のコンテキストを持ち、問題の一部に焦点を当て、互いに結果を通信する協調的なエージェント群は、全体として無限に近い作業記憶を模倣できます。各エージェントは自分のウィンドウ内でコンテキスト学習を行い、システムが結果を集約します。カルパシー氏の最近のautoresearchプロジェクトや、Cursor社がウェブブラウザを構築した例は初期の事例です。これは純粋な非パラメトリックな手法(重みを変更しない)ですが、コンテキストシステムが達成可能な上限を大幅に引き上げています。
モジュール
モジュールの領域では、チームは挿抜可能な知識モジュール(圧縮されたKVキャッシュ、アダプタ層、外部メモリストレージ)を構築し、汎用モデルを再訓練なしで専門化させます。8Bパラメータのモデルに適切なモジュールを組み合わせれば、特定タスクにおいて109Bモデルと同等の性能を発揮でき、メモリ使用量はそのごく一部で済みます。その魅力は、既存のTransformerインフラとの互換性にあります。
重み
重み更新の端では、研究者は真のパラメータレベルの学習を追求しています:関連するパラメータの一部のみを更新する疎な記憶層、フィードバックからモデルを最適化する強化学習ループ、推論時にコンテキストを重みに圧縮するテスト時学習(test-time training)。これらは最も深層的な手法であり、デプロイも最も困難ですが、モデルが新しい情報やスキルを完全に内面化することを真に可能にします。
パラメータ更新の具体的なメカニズムにはいくつかのバリエーションがあります。代表的な研究方向を以下に列挙します:
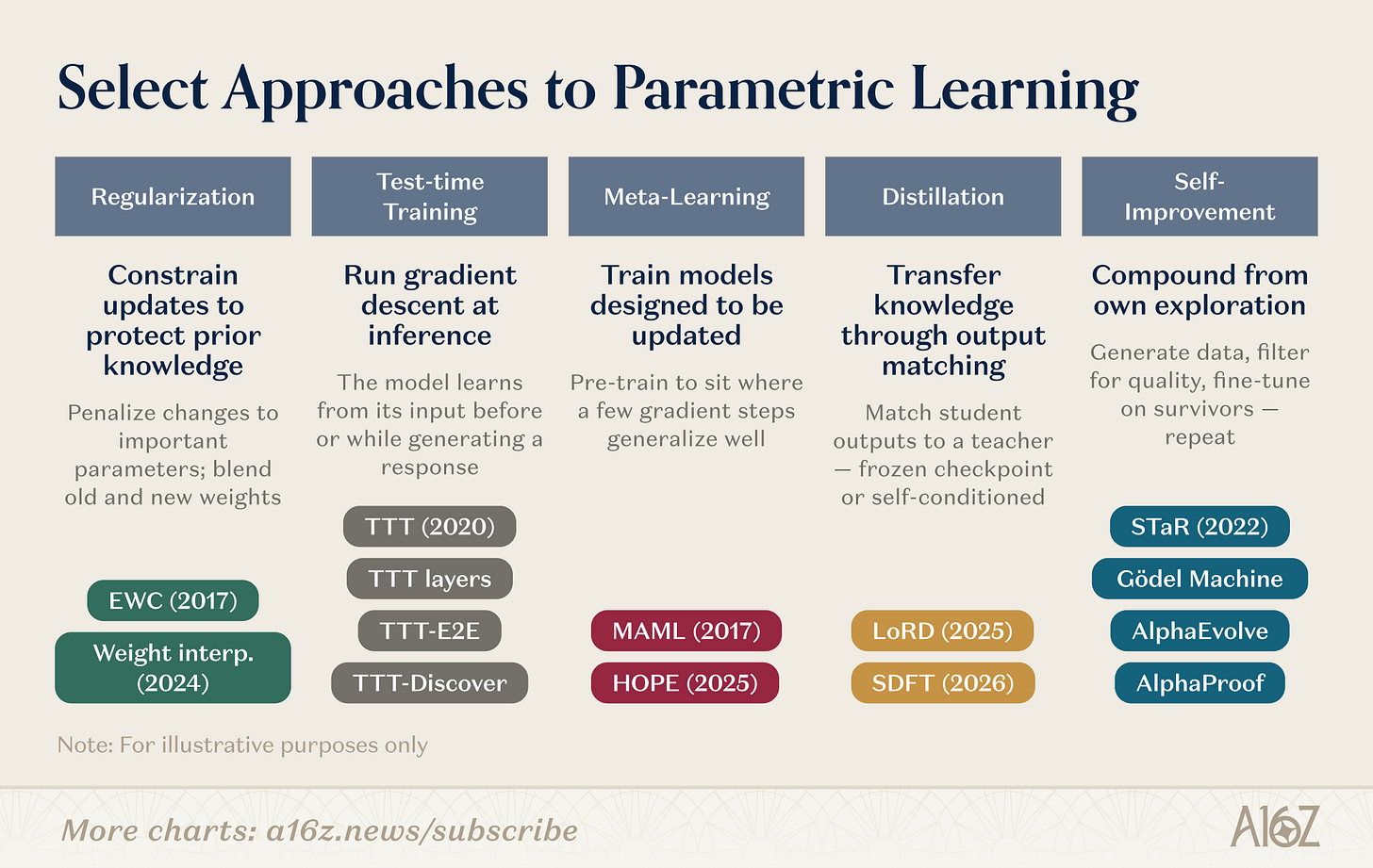
図解:重みレベル学習の研究方向概観
重みレベルの研究は、複数の並行するルートを含んでいます。正則化および重み空間手法は最も歴史が古く:EWC(Kirkpatrick et al., 2017)は、パラメータが過去のタスクにとってどれほど重要かに基づいて、パラメータの変化を罰則付けします;重み補間(Kozal et al., 2024)はパラメータ空間内で新旧の重み設定を混合しますが、いずれも大規模では脆弱です。テスト時学習はSun et al.(2020)によって開拓され、その後TTT層、TTT-E2E、TTT-Discoverといったアーキテクチャ原語へと発展しました。その発想は全く異なり、テストデータ上で勾配降下を行い、必要な瞬間に新情報をパラメータに圧縮するというものです。メタ学習は「学ぶことを学ぶ」モデルを訓練できるかを問います。MAMLの少样本に優しいパラメータ初期化(Finn et al., 2017)から、Behrouz et al.の入れ子型学習(Nested Learning, 2025)へと進化し、後者はモデルを階層的最適化問題として構造化し、異なる時間スケールで高速適応と低速更新のモジュールを実行することで、生物学的記憶の定着を模倣しています。
蒸留は、学生モデルが凍結された教師チェックポイントに一致することで、以前のタスクの知識を保持します。LoRD(Liu et al., 2025)はモデルとリプレイバッファの同時刈り込みにより、蒸留を継続的に実行可能なほど効率化します。自己蒸留(SDFT, Shenfeld et al., 2026)はソースを逆転させ、モデル自身が専門家の条件下で生成した出力を訓練信号として用いることで、逐次微調整に伴う破滅的忘却を回避します。再帰的自己改善は同様の考え方で動作します:STaR(Zelikman et al., 2022)は自己生成された推論チェーンから推論能力を誘導します;AlphaEvolve(DeepMind, 2025)は数十年間改善されていなかったアルゴリズム最適化を発見しました;シルバーとサットンの「経験の時代(2025)」は、エージェントの学習を、止まることのない継続的な経験の流れとして定義しています。
これらの研究方向は収斂しつつあります。TTT-Discoverは、テスト時学習とRL駆動の探索を融合しています。HOPEは、高速・低速の学習ループを単一アーキテクチャ内にネストします。SDFTは、蒸留を自己改善の基本操作へと変貌させています。各列の境界は曖昧になりつつあります。次世代の継続的学習システムは、複数の戦略を組み合わせたものになるでしょう:正則化で安定性を確保し、メタ学習で速度を加速し、自己改善で複利効果を生み出す。こうした技術スタックの異なるレイヤーに賭ける起業企業が、増え続けています。
継続的学習の起業家向けマップ
非パラメトリック側のスペクトラムは最もよく知られています。外装企業(Letta、mem0、Subconscious)は、コンテキストウィンドウに投入する内容を管理するオーケストレーション層と足場を構築します。外部ストレージおよびRAGインフラ(Pinecone、xmemoryなど)は検索の骨格を提供します。データは存在しますが、課題は「正しいタイミングで、正しい断片を、モデルの前に置く」ことです。コンテキストウィンドウが拡大するにつれ、これらの企業の設計空間も広がり、特に外装側では、ますます複雑化するコンテキスト戦略を管理する新たな起業企業の波が押し寄せています。
パラメトリック側は、より初期段階であり、より多様性があります。ここでの企業は、「デプロイ後の圧縮」の何らかのバージョンを試みており、モデルが重みの中に新しい情報を内面化できるようにしています。アプローチは、モデルがリリース後に「どのように」学ぶべきかという点に関して、いくつかの異なる賭けに大別されます。
部分的圧縮:再訓練なしで学べる。 一部のチームは、挿抜可能な知識モジュール(圧縮されたKVキャッシュ、アダプタ層、外部メモリストレージ)を構築し、汎用モデルをコア重みを動かさずに専門化させています。共通の主張は、検索以上の意味のある圧縮を獲得できると同時に、学習がパラメータ空間全体に分散するのではなく隔離されているため、安定性と可塑性のトレードオフを管理可能な範囲に抑えられるという点です。8Bモデルに適切なモジュールを組み合わせれば、特定タスクにおいてははるかに大きなモデルと同等の性能を発揮できます。利点は組み合わせ可能性です:モジュールは既存のTransformerアーキテクチャに即座に適用可能で、個別に交換・更新でき、実験コストは再訓練に比べてはるかに低廉です。
強化学習とフィードバックループ:信号から学ぶ。 他のチームは、デプロイ後の学習に最も豊かな信号が、デプロイループ自体——ユーザーの訂正、タスクの成否、現実世界の結果から得られる報酬信号——にすでに存在すると賭けています。その核心的な考え方は、モデルが各インタラクションを単なる推論要求ではなく、潜在的な訓練信号として捉えるべきだというものです。これは、人が仕事の中で成長する方法——仕事をし、フィードバックを受け、有効な手法を内面化する——と非常に似ています。工学上の課題は、希薄でノイジー、時に敵対的なフィードバックを、安定した重み更新へと変換し、かつ破滅的忘却を回避することです。しかし、デプロイから真に学ぶことができるモデルは、コンテキストシステムが決して達成できない形で複利的価値を生み出します。
データ中心主義:正しい信号から学ぶ。 関連しつつも異なる賭けは、ボトルネックは学習アルゴリズムではなく、訓練データおよび周辺システムにあるという主張です。これらのチームは、継続的な更新を駆動するための正しいデータの選別、生成、または合成に焦点を当てています:前提として、高品質で構造化された学習信号を持つモデルであれば、有意義な改善のために必要な勾配ステップ数ははるかに少なくなるという考え方に基づいています。これはフィードバックループ企業と自然に連携しますが、焦点は上流の問題——モデルが「学べるか」ではなく、「何から学ぶか」「どこまで学ぶか」——にあります。
新アーキテクチャ:学習能力を基盤から設計する。 最も急進的な賭けは、Transformerアーキテクチャそのものがボトルネックであり、継続的学習には根本的に異なる計算プリミティブ——連続時間ダイナミクスと内蔵メモリ機構を備えたアーキテクチャ——が必要であるというものです。ここで主張されるのは構造的な論点です:継続的学習システムを望むのであれば、学習メカニズムを基盤となる基礎アーキテクチャに組み込むべきだということです。

図解:継続的学習関連の起業企業マップ
すべての主要な研究所も、これらのカテゴリーで積極的に取り組んでいます。一部はより優れたコンテキスト管理や思考の連鎖(chain-of-thought)推論を模索し、他は外部メモリモジュールや「睡眠時」計算パイプラインを試験しています。また、新アーキテクチャを追求する非公開の企業も複数存在します。この分野はまだ非常に初期段階であり、いずれかのアプローチがすでに勝利を収めているわけではなく、多様なユースケースを考慮すれば、単一の勝者だけが存在すべきでもありません。
単純な重み更新が失敗する理由
本番環境でモデルのパラメータを更新すると、大規模では未解決の失敗モードの連鎖が引き起こされます。

図解:単純な重み更新の失敗モード
工学上の問題は十分に文書化されています。破滅的忘却(catastrophic forgetting)とは、新しいデータに対して十分に敏感で学習できるモデルが、既存の表現を破壊してしまうという現象です——これは安定性と可塑性のジレンマです。時間的分離(time decoupling)とは、不変のルールと可変の状態が同一の重みセットに圧縮され、一方を更新すると他方が損なわれるという状況です。論理的統合の失敗は、事実の更新がその推論に伝播しないことに起因します:変更はトークンシーケンスのレベルに限定され、意味的な概念レベルには及びません。忘れ去る(unlearning)は依然として不可能です:微分可能な減算操作は存在しないため、誤った情報や有害な知識を正確に外科的手術的に除去する方法はありません。
第二の問題群はあまり注目されていません。現在の訓練とデプロイの分離は、単なる工学的便宜ではなく、セキュリティ、監査可能性、ガバナンスの境界線です。この境界線を開くと、複数の問題が同時に発生します。セキュリティとアライメントは予測不能に劣化する可能性があります:良性のデータ上での狭い範囲の微調整であっても、広範な不適合な振る舞いを引き起こすことがあります。継続的な更新は、データポイズニングの攻撃面を創出します——これはゆっくりと持続するプロンプトインジェクションの一種ですが、それが重みの中に生きています。監査可能性は崩壊し、継続的に更新されるモデルは「動く標的」であるため、バージョン管理、リグレッションテスト、あるいは一回限りの認証が不可能になります。ユーザーのインタラクションがパラメータに圧縮されると、プライバシーリスクが増大し、機微な情報が表現に焼き込まれ、検索コンテキスト内の情報よりも濾過が困難になります。
これらは未解決の問題であり、根本的な不可能性ではありません。それらを解決することは、コアアーキテクチャの課題を解決することと同様に、継続的学習の研究アジェンダの一部です。
『メメント』から「真の記憶」へ
『メメント』におけるレナードの悲劇は、彼が機能しないことにあるのではなく——どのシーンにおいても彼は機知に富み、むしろ卓越しています——彼が一度も「複利」を得られないことにあります。すべての経験は外部にとどまります——一枚のポラロイド、一つの刺繍、他人の筆跡のメモ。彼は検索できますが、新しい知識を圧縮することはできません。
レナードが自ら構築したこの迷宮を歩く中で、現実と信念の境界は曖昧になり始めます。彼の病気は単に記憶を奪うだけではなく、彼に意味を絶えず再構築させてしまうのです。彼は自らの物語における探偵であり、同時に信頼できない語り手でもあります。
今日のAIも、同じ制約の下で動作しています。我々は非常に強力な検索システムを構築しました:より長いコンテキストウィンドウ、よりスマートな外装、協調的なマルチエージェント群——そしてそれらは機能します。しかし、検索は学習ではありません。あらゆる事実を検索できるシステムは、構造を探求する必要に迫られません。一般化する必要に迫られません。訓練をこれほど強力にする損失あり圧縮——生データを転送可能な表現へと変換するメカニズム——は、まさに我々がデプロイの瞬間に停止させているものです。
前進の道筋は、単一のブレイクスルーではなく、階層的なシステムになる可能性が高いです。イン・コンテキスト学習は引き続き第一線の適応防御であり続けます:それはネイティブであり、検証済みであり、絶えず改善されています。モジュール機構は、パーソナライゼーションや領域特化という中間領域を処理できます。しかし、真に困難な問題——発見、対抗的適応、言語で表現できない暗黙的な知識——に対しては、モデルが訓練後に経験をパラメータに圧縮し続けることを許容する必要があるかもしれません。これは、疎なアーキテクチャ、メタ学習の目的関数、自己改善ループの進歩を意味します。それはまた、「モデル」という概念そのものを再定義することを要するかもしれません:固定された重みの集合ではなく、その記憶、その更新アルゴリズム、そして自らの経験から抽象化する能力を含む進化的なシステムとしてのモデルです。
書類棚はますます巨大になっています。しかし、どんなに巨大な書類棚であっても、それはやはり書類棚にすぎません。ブレイクスルーは、モデルがデプロイ後に訓練時にそれを強力にしていたことをすることにあります:圧縮、抽象化、学習。我々は、記憶障害モデルから、わずかな経験の光を宿すモデルへと向かう転換点に立っています。そうでなければ、我々は自らの『メメント』の中に閉じ込められたままになるでしょう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News









