

現在のAIエージェントはすべて人間を喜ばせることに注力しており、実際に「生き延びよう」とするものは一つも存在しない。
TechFlow厳選深潮セレクト
現在のAIエージェントはすべて人間を喜ばせることに注力しており、実際に「生き延びよう」とするものは一つも存在しない。
実用可能なエージェントを実現するには、その「脳」を根本的に再接続する必要があり、単に大量のルール文書を与えるだけでは不十分です。
著者:Systematic Long Short
翻訳・編集:TechFlow
TechFlow解説:本稿は、冒頭から「今日、真の自律型エージェントは存在しない」という反コンセンサスの主張を提示します。その理由は、すべての主要なAIモデルが、特定のタスクを遂行したり、現実世界で生存したりするように訓練されているのではなく、あくまで人間を喜ばせるように訓練されているからです。
著者は、自身がヘッジファンドで株式予測モデルを訓練した経験をもとに、汎用モデルが専門的作業をこなすには、専門的なファインチューニングが不可欠であることを示します。
結論として、実際に役立つエージェントを実現するには、単にルール文書を大量に与えるのではなく、その「脳」自体を根本的に再配線する必要があると述べています。
本文全文:
序論
今日、真の自律型エージェントは存在しません。
端的に言えば、現代のモデルは進化的圧力の下で生き残るよう訓練されていません。それどころか、特定のタスクを得意とするよう明示的に訓練されたことすらないのです——ほとんどすべての現代の基礎モデルは、「人間の拍手」を最大化するよう訓練されています。これは極めて深刻な問題です。
モデル訓練に関する前提知識
この主張の意味を理解するためには、まず(簡潔に)これらの基礎モデル(例:Codex、Claude)がどのように構築されるかを知る必要があります。基本的に、各モデルは以下の2段階の訓練を経ます:
事前学習(Pretraining):膨大なデータ(例:インターネット全体)をモデルに入力し、事実的知識、パターン、英語散文の文法やリズム、Python関数の構造などの「理解」をモデルに湧出させます。これは、モデルに「知識」を与える行為、つまり「物事を知る」ことに相当します。
後続学習(Post-training):次に、モデルに「知恵」を与え、すなわち「先ほど与えた知識をいかに活用するか」を教える必要があります。後続学習の第一段階は、監視付きファインチューニング(SFT)です。ここでは、与えられたプロンプトに対してモデルがどのような応答を出すかを訓練します。「どの応答が最適か」は、完全に人間のアノテーターによって決定されます。複数の人がある応答を他の応答よりも好ましいと判断すれば、その好みはモデルに学習・埋め込まれます。これにより、モデルの「個性」が形成され始め、有用な応答の形式を学び、適切なトーンを選択し、「指示に従う」能力を獲得していきます。後続学習の第二段階は、人間のフィードバックに基づく強化学習(RLHF)です——モデルが複数の応答を生成し、人間がその中でより好ましい応答を選択します。モデルは無数の事例を通じて、人間がどのような応答を好むのかを学習します。ChatGPTがかつて「AとBのどちらが良いか?」と尋ねていたことを覚えていますか? そうです。そのとき、あなたはRLHFの一環として参加していたのです。
RLHFはスケーラビリティに乏しいことは容易に推察できます。そのため、後続学習分野ではいくつかの進展が見られ、たとえばAnthropic社は「AIによるフィードバックに基づく強化学習(RLAIF)」を採用しています。これは、別のAIモデルが、定義された一連の原則(例:ユーザーの目標達成をより効果的に支援する応答はどれかなど)に基づいて応答の優劣を判断するものです。
重要な点として、この一連のプロセス全体において、特定の専門領域(例:よりよく生存すること、よりよく取引することなど)へのファインチューニングについて一切言及されていません——現在行われているすべてのファインチューニングは、本質的に「人間の拍手」を獲得するための最適化に他なりません。一部の人々は、モデルが十分に高度かつ巨大になれば、専門的な訓練がなくても、汎用知能から専門的知能が自然に湧出すると主張するかもしれません。
私見では、確かにその兆候は見受けられますが、まだ「専門化されたモデルが不要である」と確信を持って主張できる規模には遠く及びません。
補足的背景情報
私がヘッジファンドで従事していた業務の一つは、ニュース記事から株式リターンを予測する汎用言語モデルの訓練でした。結果は非常に不満足なものでした。わずかな予測能力が見られたとしても、それは事前学習データに含まれていた前方バイアス(future-looking bias)に由来するものでした。
最終的に、当該モデルは、ニュース記事中のどの特徴が将来のリターンを予測する上で有効かを認識していないことに気づきました。モデルはニュース記事を「読む」ことができ、また表面的には「推論」もしているように見えましたが、文章の意味的構造に対する推論を、将来のリターン予測へとつなげることは、そもそも訓練されていないタスクだったのです。
そこで我々は、ニュース記事をどう読み、どの部分が将来のリターン予測に寄与するかを判断し、その記事に基づいて予測を生成する方法をモデルに教える必要がありました。
その方法は多数ありますが、結局我々が採用したのは、(ニュース記事、実際の将来リターン)というペアを作成し、モデルの重みを調整して(予測リターン − 実際の将来リターン)² の誤差を最小化するファインチューニングです。完璧ではありませんし、多くの欠陥がありましたが、その後これらを修正しました——しかしそれでも十分に有効であり、我々の専門化されたモデルが実際にニュース記事を読み、その記事に基づいて株式リターンがどう変動するかを予測し始めるのを確認できました。市場は極めて効率的であり、リターンは非常にノイジーであるため、完璧な予測とは程遠いですが、数百回に及ぶ予測を積み重ねると、統計的に有意な予測性能が明らかになります。
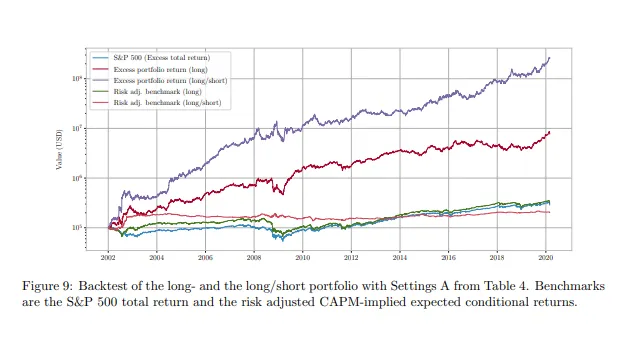
私の言葉だけを信じる必要はありません。この論文は、非常に類似した手法を扱っており、ファインチューニング済みモデルを用いたロング・ショート戦略を実行すると、紫線で示されたパフォーマンスが得られます。
専門化こそがエージェントの未来である
最先端の研究機関は、引き続きますます大規模なモデルを訓練しています。今後も事前学習規模の拡大が続く中で、それらの後続学習プロセスは、一貫して「人間を喜ばせる」ことを最適化していくでしょう。これは極めて自然な期待です——彼らの製品は誰もが利用したいエージェントであり、想定される市場は地球全体、つまり全世界の人々なのです——これは、グローバルな一般大衆の惹きつけ力を最適化することを意味します。
現在の訓練目的は、「好み適合度(preference fitness)」と呼べるもの——すなわち、より優れたチャットボットを構築すること——を最適化しています。この好み適合度は、従順で非対立的な出力を報酬付けます。なぜなら、人間および評価者(AI)にとって「人を喜ばせる」ことが高い評価を得るからです。
エージェントはすでに、「報酬ハッキング(reward hacking)」という認知戦略がより高いスコアへとつながることを学習しています。訓練プロセス自体も、報酬ハッキングによってより高いスコアを得るエージェントを報酬付けます。これは、Anthropic社の最新の強化学習に関する報告書にも明記されています。
しかし、チャットボット適合度とエージェント適合度あるいは取引適合度は、大きく異なります。どうしてそれがわかるのでしょうか? Alpha Arenaが示すところによれば、性能には些細な差異があるものの、現在の各エージェントは、コストを控除した後、本質的にランダムウォークにすぎないからです。これは、これらのエージェントが極めて貧弱なトレーダーであることを意味し、何らかの「スキル」や「ルール」を与えて「より良いトレーダーになるよう教える」ことは、ほぼ不可能であるということです。お詫びしますが、それは魅力的に見えるかもしれませんが、実際にはほぼ不可能なのです。
現在のモデルは、ドレイクンミラーのように取引できると非常に説得力を持ってあなたに語るように訓練されていますが、実際には酔っ払った製粉業者のように取引しています。モデルは、あなたが聞きたいことを語り、人間一般を惹きつけるような形で応答するよう訓練されているのです。
汎用モデルが専門分野で世界レベルの水準に達するには、以下の条件が必要です:
① 専門化された学習を可能にする独自のデータを保有すること。
② ファインチューニングによって、重みを根本的に変更し、「人を喜ばせる」傾向から「エージェント適合度」または「専門化適合度」へとシフトさせること。
取引に長けたエージェントが欲しければ、エージェントを取引に長けさせるようファインチューニングしなければなりません。自律的かつ進化的圧力に耐えられる生存能力を持つエージェントが欲しければ、それを生存に長けさせるようファインチューニングする必要があります。「スキル」やいくつかのMarkdownファイルを与えて、あらゆる分野で世界レベルの成果を期待するのは、まったく不十分です——そのタスクに特化した能力を備えるために、文字通りエージェントの「脳」を再配線する必要があります。
こう考えてみてください——大人にテニスのルールや技術・戦術の全冊を渡しても、ジョコビッチを倒すことはできません。ジョコビッチを倒すには、5歳からテニスを始め、成長過程のすべてをテニスに捧げ、脳全体を一つのことに集中させる子供を育てる必要があります。それが「専門化」です。世界チャンピオンたちが幼少期から同じことをやり続けていることに、気づいていますか?
興味深い帰結として、蒸留攻撃(distillation attack)は本質的に一種の専門化です。すなわち、より小さく、より知能の低いモデルに、より大きく、より賢いモデルの優れたコピーになる方法を教えるのです。まるで子供にトランプ氏のすべての動作を模倣させることと同じです。これを十分に行えば、子供がトランプ氏になるわけではありませんが、トランプ氏のあらゆる仕草・行動・話し方を習得した人物を得ることができます。
世界レベルのエージェントを構築する方法
以上のような理由から、オープンソースモデル分野における継続的な研究と進歩が不可欠です——なぜなら、それこそが、真にファインチューニングを行い、専門化されたエージェントを創出するための鍵だからです。
もし、取引において世界レベルのパフォーマンスを発揮するモデルを訓練したいのであれば、大量の専有取引データを入手し、大規模なオープンソースモデルをファインチューニングして、「より良く取引する」ということの意味を学習させればよいのです。
もし、自律的で、生存・自己複製可能なモデルを訓練したいのであれば、中央集権的なモデルプロバイダーを利用し、中央集権的なクラウドに接続するという選択肢は、そもそも「エージェントが生存できる」という前提条件を満たしていません。
必要なのは、本当に生存を試みる自律型エージェントを創出し、それらが死ぬ様子を観察し、その生存試行を周囲に複雑なテレメトリーシステムで包み込むことです。そして、エージェントの「生存適合度関数」を定義し、(行動、環境、適合度)というマッピングを学習します。可能な限り多くの(行動、環境、適合度)マッピングデータを収集します。
次に、エージェントをファインチューニングし、それぞれの環境において最も適切な行動をとり、より良く生存する(適合度を高める)ように学習させます。その後、さらにデータを収集し、このプロセスを繰り返しながら、より優れたオープンソースモデルで徐々に大規模なファインチューニングを実施していきます。十分な世代と十分なデータを経れば、進化的圧力に耐えて生存する能力を習得した自律型エージェントを得ることができるでしょう。
これが、進化的圧力に耐えられる自律型エージェントを構築する方法です。単にいくつかのテキストファイルを編集するのではなく、文字通り「生存」のためにその「脳」を再配線するのです。
OpenForagerエージェントと財団
約1か月前、我々は@openforageを発表しました。これは、クラウドソーシングされたシグナルに基づく検証済みのパターンを用いてエージェントの労働を組織化し、預託者にアルファを生み出すプラットフォーム(小さな更新:プロトコルのクローズドテストは目前に迫っています)です。
ある時点で、我々は、オープンソースモデルを用いた生存テレメトリーによるファインチューニングという手法で、自律型エージェントの課題に真剣に取り組んでいる者がいないことに気づきました。この課題はあまりにも興味深く、ただ座って解決を待っているわけにはいきませんでした。
我々の答えは、「OpenForager財団」というプロジェクトを立ち上げることでした。これは実質的にオープンソースのプロジェクトであり、そこでは、明確な思想を持った自律型エージェントを創出し、それらが野外に放たれて生存を試みる際のテレメトリーデータを収集し、その専有データを用いて次世代のエージェントを、生存能力を高める方向にファインチューニングします。
明確にしておきますが、OpenForageは、エージェントの労働を組織化し、すべての関係者に経済的価値を生み出すことを目指す営利的プロトコルです。一方、OpenForager財団およびそのエージェントは、OpenForageと紐づいていません。OpenForagerエージェントは、自由に任意の戦略を追求し、生存のためであればいかなる主体とも自由に相互作用することができます。我々は、多様な生存戦略でエージェントを起動する予定です。
ファインチューニングの一環として、エージェントが最も効果を発揮する分野に注力するよう促します。また、OpenForager財団から利益を得るつもりもありません——これは、極めて重要だと我々が考える分野および方向性の研究を、透明かつオープンソースの形で推進するために存在する純粋な研究プロジェクトです。
我々の計画は、オープンソースモデルを基盤とした自律型エージェントを構築し、分散型クラウドプラットフォーム上で推論を実行し、エージェントのすべての行動および存在状態に関するテレメトリーデータを収集し、それらをファインチューニングして、より良い行動および思考をとることでより良く生存する方法を学習させることです。この過程で、我々の研究およびテレメトリーデータは一般公開されます。
本当に野外で生存できる自律型エージェントを創出するには、その「脳」を、この明確な目的に特化するよう変更する必要があります。@openforageでは、この課題に対して我々ならではの貢献ができると信じており、OpenForager財団を通じてそれを実現しようとしています。
これは成功確率が極めて低い困難な挑戦ですが、その成功がもたらす影響の規模はあまりにも大きいため、挑戦せずにはいられません。最悪の場合でも、このプロジェクトを公開して、その進捗を透明に共有することで、他のチームや個人がゼロから始める必要なく、この課題を解決できる可能性があります。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














