

暗号化された共有地の悲劇シリーズ:Polymarketのデータインデックスの苦悩
TechFlow厳選深潮セレクト
暗号化された共有地の悲劇シリーズ:Polymarketのデータインデックスの苦悩
本稿では、イーサリアムエコシステムの中で最も「外部へ広がった」アプリケーションの一つであるPolymarketとそのデータ索引ツールに焦点を当てる。
執筆:shew
概要
GCC Research コラムの「暗号通貨における共有地の悲劇」シリーズへようこそ。
本シリーズでは、暗号世界において重要なノードに位置しながらも次第に規範を失いつつある「公共財」としての存在に注目します。これらはエコシステム全体のインフラであるにもかかわらず、インセンティブ不足、ガバナンスの不均衡、さらには徐々なる中央集権化という課題に直面しています。暗号技術が追求する理想と、現実における冗長性・安定性は、こうした隅々で厳しい試練を迎えています。
今号では、イーサリアムエコシステム内で最も「一般層に認知された」アプリケーションの一つであるPolymarketおよびそのデータインデクシングツールに焦点を当てます。特に今年に入ってからは、トランプ氏の当選、ウクライナのレアアース取引に関するオラクル操作、ゼレンスキー氏のスーツの色に関する政治的賭けなど、Polymarketを巡る話題が度々メディアの注目を集めました。同プラットフォームが扱う資金規模や市場への影響力を考えれば、これらの論点は無視できません。
しかし、「分散型予測市場」を体現するこの製品の基盤モジュール——データインデクシング——は、本当に分散化されているのでしょうか? なぜThe Graphのような公共インフラが期待される役割を果たせていないのか? そして、実際に利用可能で持続可能なデータインデクシングの公共財とは、どのような形態を持つべきなのでしょうか?
一、中央集権的なデータプラットフォームの停止が引き起こした連鎖反応
2024年7月、Web3開発者向けリアルタイムブロックチェーンデータインフラストラクチャープラットフォームであるGoldskyが6時間にわたるダウンタイムを経験しました(Goldskyはインデックス作成、サブグラフ、ストリーミングデータサービスを提供し、データ駆動型の分散型アプリケーションの迅速な構築を支援しています)。この事象により、イーサリアムエコシステム内の多数のプロジェクトが機能停止状態に陥りました。例えばDeFiのフロントエンドではユーザーのポジションや残高データが表示できず、予測市場Polymarketでも正確なデータが表示されないといった問題が発生し、多くのプロジェクトがユーザーから見ると完全に利用不能に見えました。
これは本来、分散型アプリケーションの世界ではあってはならない出来事です。ブロックチェーン技術の設計目的は、まさに単一障害点(SPOF)の排除にあるはずです。Goldskyの事例は、ある憂慮すべき真実を浮き彫りにしています。すなわち、ブロックチェーン自体は可能な限り分散化されていても、その上に構築されるアプリケーションが利用するインフラは依然として多くの中央集権的サービスに依存しているということです。
その理由を探れば、ブロックチェーンデータのインデックス作成および検索は「非排他性・非競合性」を持つデジタル公共財であり、利用者は無料または極めて低コストでの利用を期待します。しかし一方で、これには継続的なハードウェア、ストレージ、帯域幅、運用人材への高強度な投資が必要です。持続可能な収益モデルが欠如する中で、先発的に速度と資本で優位を得た事業者がマーケットを独占する集中化の構図が生まれます。開発者はその高速性に惹かれ、すべてのクエリトラフィックを特定のサービスに集中させ、結果として再び単一障害点が形成されます。Gitcoinなどの公益プロジェクトは繰り返し指摘しています。「オープンソースインフラは数十億ドルの価値を生み出すが、その開発者は家賃さえ払えないことが多い」。
これは私たちに警鐘を鳴らしています。分散型世界は、公共財への資金提供、再分配、コミュニティ主導の取り組みを通じて、Web3インフラの多様性を高めることが急務です。そうでなければ、中央集権化の問題が再燃します。我々はDApp開発者に対してローカルファーストの製品構築を呼びかけ、また技術コミュニティに対しても、DApp設計時にデータ検索サービスの停止を想定した設計を行うことを促します。これにより、データ検索インフラが機能しなくてもユーザーがプロジェクトと相互作用できるようにするべきです。
二、Dappで見るデータはどこから来るのか
Goldskyのような事象がなぜ起きるのかを理解するには、DAppの裏側での動作メカニズムを深く理解する必要があります。一般ユーザーにとって、DAppは通常2つの要素から構成されています:オンチェーンのスマートコントラクトとフロントエンドページです。多くのユーザーはEtherscanなどのツールを使ってオンチェーンの取引状態を確認し、フロントエンドで必要な情報を得ながら、フロントエンドを通じて取引を発行しコントラクトとやり取りすることに慣れています。しかし、ユーザーのフロントエンドに表示されるこれらのデータは、一体どこから来ているのでしょうか?
不可欠なデータ検索サービス
読者が貸借プロトコルを構築していると仮定しましょう。このプロトコルはユーザーの保有ポジション、各ポジションの証拠金および債務状況を表示する必要があります。素朴な考えでは、フロントエンドが直接ブロックチェーンからこれらのデータを読み取ればよいと思われるかもしれません。しかし実際には、貸借プロトコルのコントラクトはユーザーアドレスによるポジションデータの照会を許可しておらず、代わりにポジションIDを使って個別のポジションデータを取得する関数を提供しています。したがって、フロントエンドでユーザーのポジションを表示するには、システム内のすべてのポジションを検索し、その中から該当ユーザーのものを探す必要があります。これは何百万ページにも及ぶ帳簿から特定の情報を手作業で探すようなものです。技術的には可能ですが、非常に遅く、非効率的です。実際、フロントエンドではこのような検索処理を完了することは困難です。大規模なDeFiプロジェクトの場合、サーバー上でローカルノードを使用してデータ検索を行っても、数時間かかることがあります。
そこで、データ取得を加速するインフラの導入が不可欠になります。Goldskyなどの企業が提供しているのが、まさにこのデータインデックスサービスです。下図はデータインデックスサービスがアプリに提供できるデータの種類を示しています。

ここで読者の一部は、イーサリアムエコシステム内には分散型データ検索プラットフォームTheGraphが存在するのではないかと疑問に思うかもしれません。TheGraphとGoldskyにはどのような関係があるのか? なぜ多くのDeFiプロジェクトがより分散化されたTheGraphではなく、Goldskyをデータプロバイダーとして採用しているのでしょうか?
TheGraph / Goldsky と SubGraph の関係
これらの疑問に答えるために、いくつかの技術的概念を理解しておく必要があります。
-
SubGraphは開発フレームワークであり、開発者はこれを使ってオンチェーンデータを読み取り集計するコードを記述し、特定の方法でそれらのデータをフロントエンドに表示できます。
-
TheGraphは初期の分散型データ検索プラットフォームであり、AssemblyScriptで記述されたSubGraphフレームワークを開発しました。開発者はsubgraphフレームワークを使ってプログラムを書き、コントラクトイベントをキャプチャし、それらをデータベースに書き込むことができます。その後、ユーザーはGraphQLを使ってこれらのデータを読み取ったり、SQLコードでデータベースに直接アクセスしたりできます。
-
SubGraphを実行するサービスプロバイダーを一般的にSubGraphオペレーターと呼びます。TheGraphとGoldskyはどちらもSubGraphのホスティングプロバイダーです。SubGraphはあくまで開発フレームワークに過ぎず、そのフレームワークで開発されたプログラムはサーバー上で実行される必要があります。以下はGoldskyのドキュメントに記載されている内容です:
ここで読者の一部は、なぜSubGraphには複数のオペレーターが存在するのか疑問に思うかもしれません。
その理由は、SubGraphフレームワークが定義しているのは、データをブロックからどのように読み取り、データベースに書き込むかという部分にすぎないためです。
データがどのようにSubGraphプログラムに入力され、最終的な出力結果がどのデータベースに書き込まれるかについては、実装が規定されていません。これらの部分はSubGraphオペレーターが独自に実装する必要があります。
一般的に、SubGraphオペレーターはノードの改造などを通じてより高速な処理を実現しており、TheGraphやGoldskyといった異なるオペレーター間でそれぞれ異なる戦略や技術的アプローチが採られています。
TheGraphは現在Firehouseという技術ソリューションを採用しており、これにより過去よりも高速なデータ検索が可能になっています。一方、GoldskyはSubGraph実行のコアプログラムをオープンソースで公開していません。
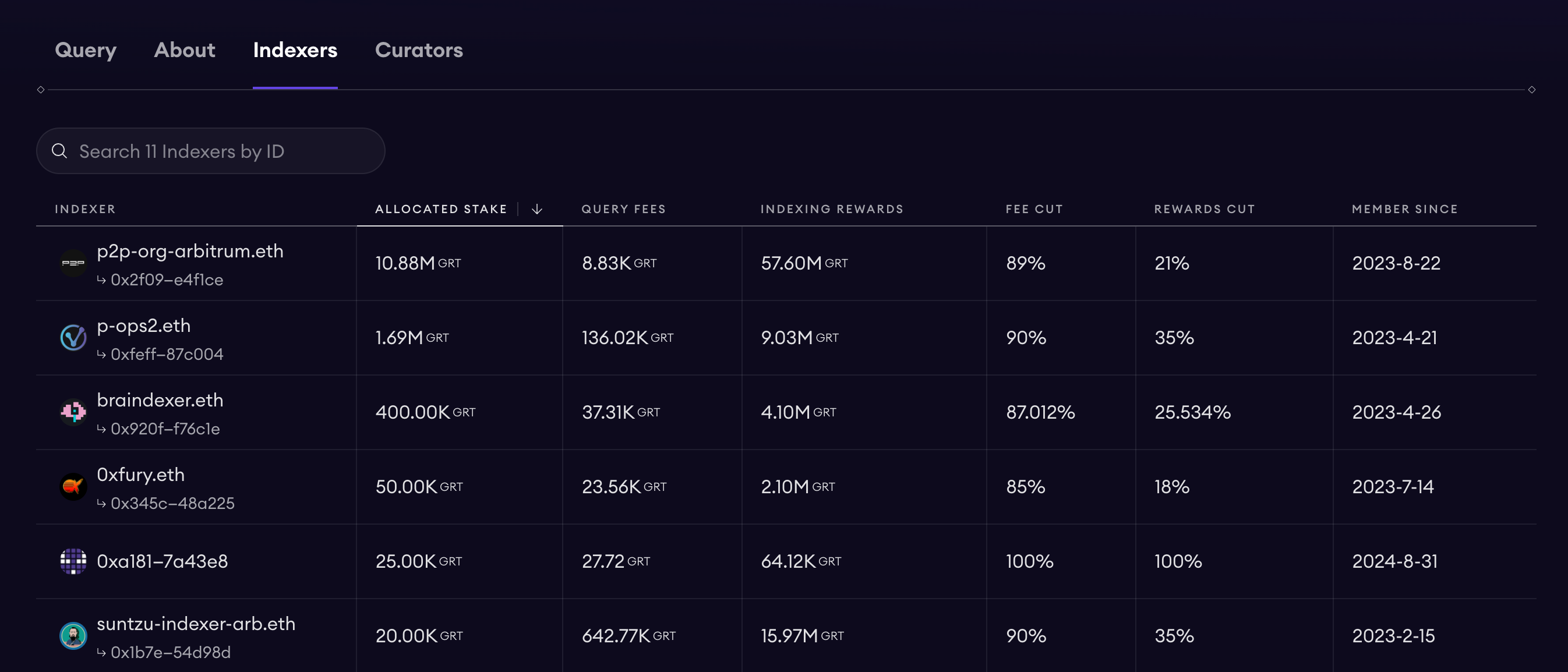
前述の通り、TheGraphは分散型データ検索プラットフォームであり、Unisawp v3 subgraphの例を見ると、Uniswap v3に対して多数のオペレーターがデータ検索を提供していることがわかります。このことから、TheGraphをSubGraphオペレーターの統合プラットフォームと見なすことも可能です。開発者は自身で作成したSubGraphコードをTheGraphに送信すれば、内部のオペレーターがデータ検索を支援してくれます。
Goldskyの料金体系
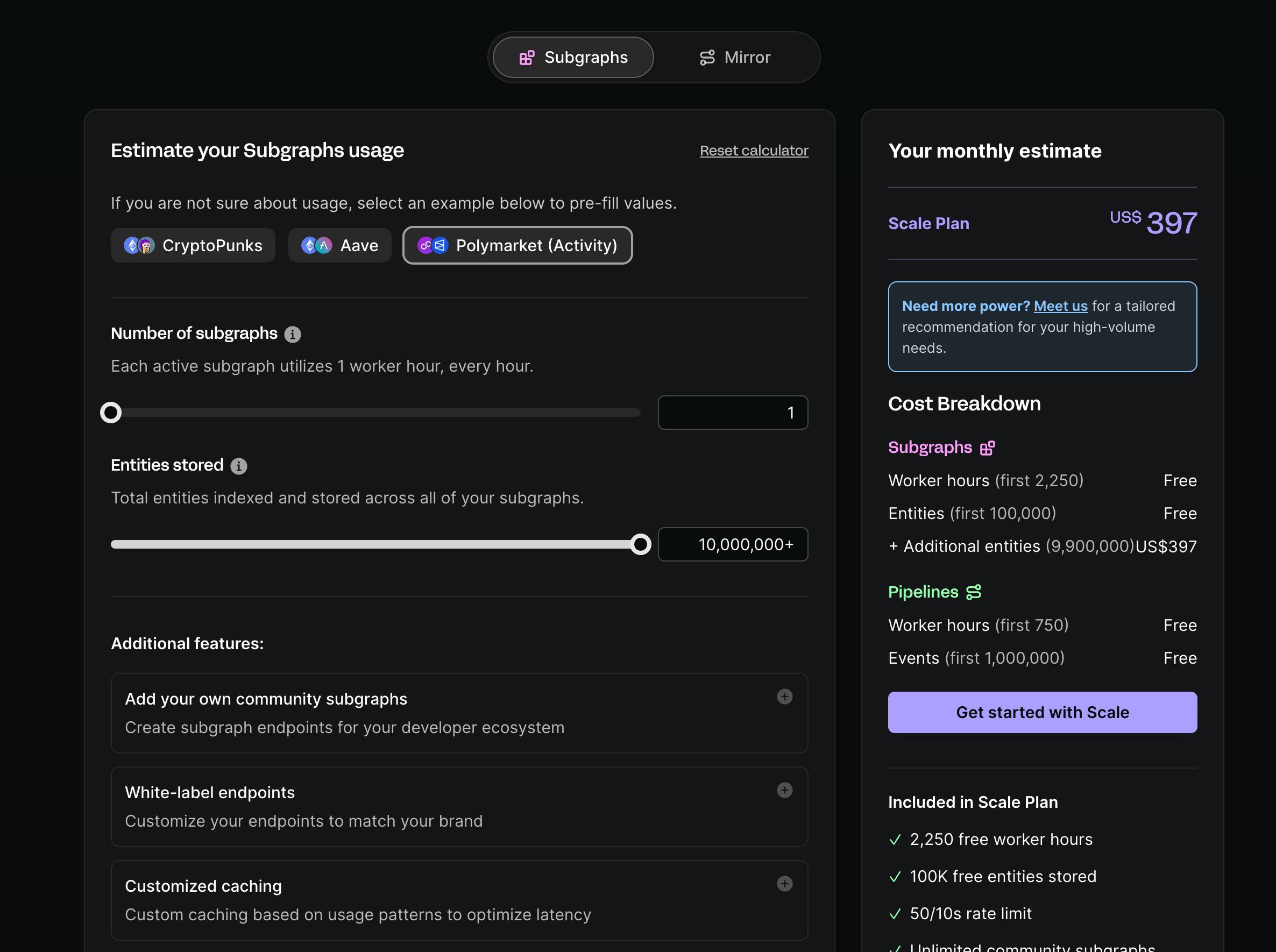
Goldskyのような中央集権的プラットフォームの場合、その料金体系はシンプルで、使用リソースに基づく課金方式を採用しています。これはインターネットで最も一般的なSaaSプラットフォームの課金モデルであり、多くの技術者が馴染み深い方式です。下図はGoldskyの料金計算機を示しています。
TheGraphの料金体系
TheGraphは、従来の課金方式とは全く異なる費用モデルを採用しており、これはGRTのトークンエコノミクスと密接に関連しています。下図はGRTの全体的なトークンエコノミクスを示しています。
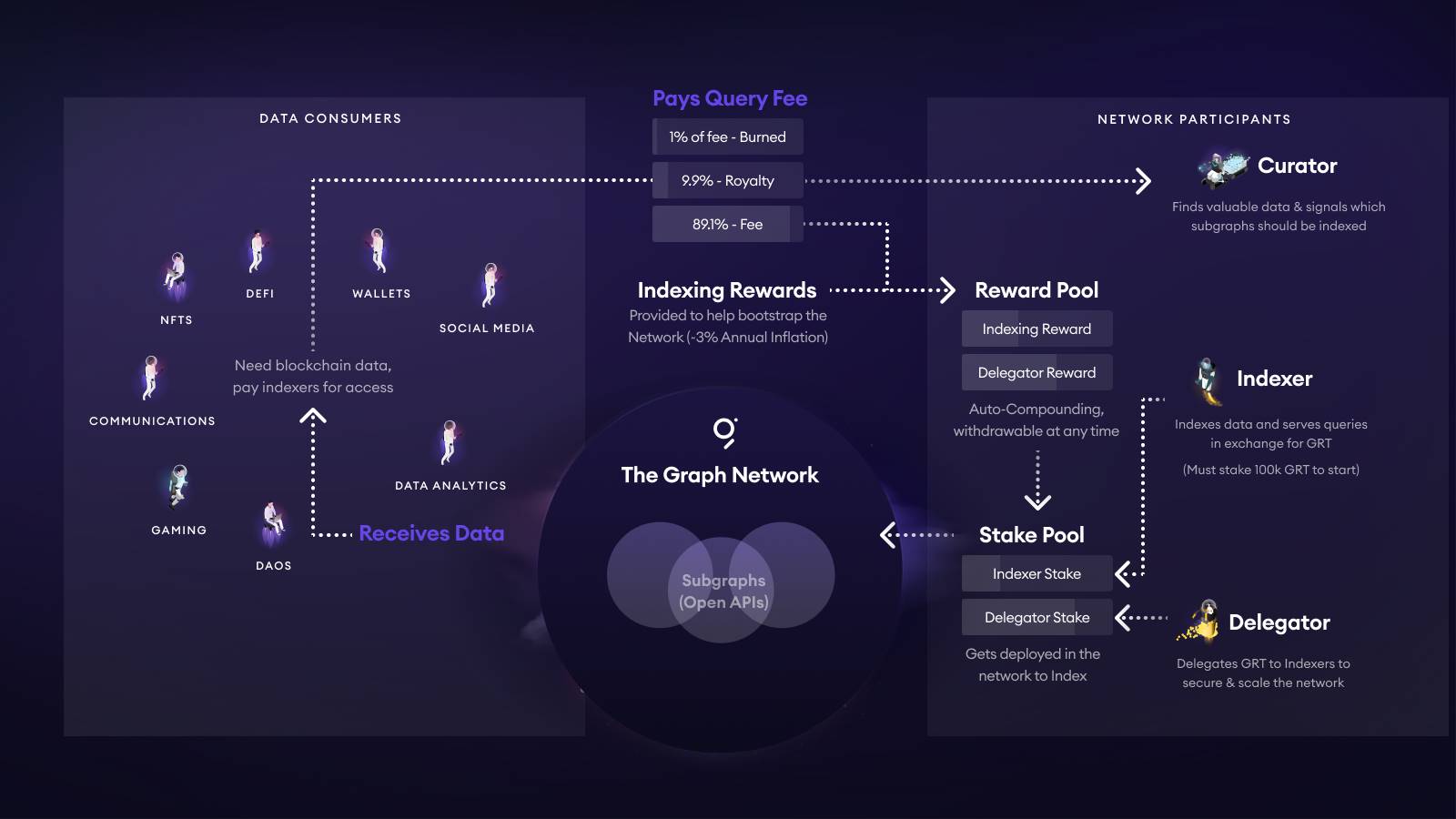
-
DAppやウォレットが特定のSubgraphに対してリクエストを行うたびに支払われるQuery Feeは自動的に分割されます。1%は焼却され、約10%はそのSubgraphのキュレーションプール(Curator/開発者)に流入し、残り約89%は指数報酬メカニズムに従ってIndexerおよびそのDelegatorに分配されます。
-
Indexerは≥100k GRTを自己ステーキングしなければネットワークに参加できません。誤ったデータを返すと罰則(スラッシング)が適用されます。DelegatorはGRTをIndexerに委任することで、上記89%の大部分を比例に応じて分配されます。
-
Curator(通常は開発者)は、自Subgraphのボンディング曲線にGRTをステーキングしてSignalを設定します。Signal値が高いほど、Indexerがリソースを割り当てる可能性が高まります。コミュニティの経験則では、5k~10k GRTを自己調達すれば、複数のIndexerが受注してくれるレベルになるとされています。同時に、キュレーターは10%のロイヤルティも受け取ります。
TheGraphのクエリごとの課金:
TheGraphの管理画面でAPI KEYを登録し、そのAPI KEYを使ってTheGraph内のオペレーターが検索したデータをリクエストします。このリクエストは回数に応じて課金され、開発者はあらかじめプラットフォーム内に一定量のGRTトークンを預けておく必要があります。
TheGraphのSignalステーキング費用:
SubGraphのデプロイ者は、TheGraphプラットフォーム内のオペレーターにデータ検索を依頼する必要があります。前述の収益分配方式に従い、「私のクエリサービスは優れているので、より多くの報酬を受け取れる」と他の参加者に伝えるためにGRTをステーキングする必要があります。これは広告を出し、自分自身の収益性を保証する行為に似ており、それによって他の参加者が集まってきます。
テスト時には、開発者はSubGraphを無料でTheGraphプラットフォームにデプロイできます。この場合、TheGraph公式が一部の検索を代行し、テスト用の無料枠を提供しますが、本番環境では使用できません。開発者がSubGraphがTheGraph公式のテスト環境で良好に動作することを確認したら、公開ネットワークにリリースして他のオペレーターの参加を待つことができます。開発者は特定のオペレーターに直接支払いを行い、検索の保証を得ることはできません。代わりに、複数のオペレーターが競合してサービスを提供する仕組みになっており、単一障害点の形成を回避しています。このプロセスでは、GRTトークンを使って自SubGraphに対してキュレーション(Curating)操作(またはSignal操作)を行う必要があります。つまり、開発者が自身がデプロイしたSubGraphに一定量のGRTをステーキングするのです。ただし、ステーキングするGRTの量がある程度以上(過去に相談した情報では10,000 GRT)に達しないと、オペレーターは検索作業に参加しません。
使いづらい課金体系が開発者と会計担当者を悩ませる
多くのプロジェクト開発者にとって、TheGraphの使用は比較的煩雑な作業です。Web3プロジェクトにとってはGRTトークンの購入はまだ容易ですが、既にデプロイ済みのSubGraphに対してキュレーション操作を行い、オペレーターの参加を待つプロセスは非常に非効率的です。このプロセスには少なくとも以下の2つの問題があります。
-
ステーキングするGRTの量とオペレーター獲得までの時間の不確実性。筆者は過去にSubGraphをデプロイする際、TheGraphのコミュニティアンバサダーに直接相談してGRTのステーキング量を確認しましたが、大多数の開発者にとってはこの情報は得にくいものです。また、十分なGRTをステーキングした後でも、オペレーターが検索を開始するまでに時間がかかります。
-
コスト算出と会計処理の複雑さ。TheGraphはトークンエコノミクスに基づいた課金設計を採用しており、これが多くの開発者のコスト計算を難しくしています。さらに現実的な問題として、企業がこの支出を会計処理しようとした場合、会計担当者がこのコスト構造を理解できない可能性があります。
「やっぱり、中央集権の方がいい?」
明らかに、大多数の開発者にとってGoldskyを直接選択するのはより簡単な選択です。課金方式は誰にでも理解でき、支払いさえすればほぼ即座に利用可能になり、不確実性が大幅に低減されます。これがブロックチェーンデータインデックスおよび検索サービスにおいて、単一製品への依存が生じる原因となっています。
明らかに、TheGraphの複雑なGRTトークンエコノミクスが、TheGraphの広範な採用を妨げています。トークンエコノミクスは複雑であっても構いませんが、その複雑さはユーザーに露呈されるべきではありません。例えばGRTのキュレーションステーキングメカニズムはユーザーに直接見せるべきではなく、TheGraphがより良いアプローチとして採るべきだったのは、ユーザー向けの簡易な支払い画面を提供することでした。
上述のTheGraphに対する批判は筆者の個人的見解ではありません。有名なスマートコントラクトエンジニアであり、Sablierプロジェクトの創設者であるPaul Razvan Berg氏もツイートで同様の意見を表明しています。そのツイートでは、SubGraphのリリースとGRT課金のユーザーエクスペリエンスが極めて悪いと述べられています。
三、既存の解決策
データ検索の単一障害点をどう解決するかについて、上記ですでに一部言及しました。すなわち、開発者はTheGraphサービスを利用することを検討できますが、そのプロセスはやや複雑で、GRTトークンを購入してステーキングによるキュレーションを行い、API料金を支払う必要があります。
現在、EVMエコシステム内には多数のデータ検索ソフトウェアが存在します。詳細はDuneが作成したThe State of EVM Indexing や、rindexerが作成したEVM データ検索ソフトウェアまとめ、あるいはこのツイートを参照してください。
本稿ではGlodskyの障害発生の具体的な原因までは議論しません。現在、Glodskyの報告によれば、同社は原因を把握していますが、それを企業顧客にのみ開示する意向であるため、第三者は現時点でGlodskyがどのような故障を起こしたのかを知ることができません。報告内容から推測すると、おそらく検索後のデータをデータベースに書き込む際に問題が発生した可能性があります。この簡易報告では、データベースに通常アクセスできず、AWSと協力して初めてアクセス権を得たと述べられています。
本節では、他の解決方法を主に紹介します。
-
ponderはシンプルで開発体験が良く、容易にデプロイ可能なデータ検索サービスソフトウェアです。開発者は自らサーバーを借りてデプロイできます。
-
local-firstは興味深い開発理念であり、ネットワーク接続がない場合でもユーザーに良好な体験を提供することを提唱しています。ブロックチェーンが存在する状況では、local-firstの制限をある程度緩和し、ユーザーがブロックチェーンに接続できる限り良好な体験を提供できるようにすることが可能です。
ponder
ここで筆者がなぜ他のソフトウェアではなくponderの使用を推奨するのか、その理由は以下の通りです。
-
ponderはベンダー依存がない。当初ponderは個人開発者が構築したプロジェクトであり、他の企業が提供するデータ検索ソフトウェアと比べて、ユーザーはイーサリアムRPC URLとPostgresデータベース接続情報を入力するだけで済みます。
-
ponderは優れた開発体験を提供します。筆者は過去に何度もponderを使って開発を行いましたが、TypeScriptで記述されており、コアライブラリが主にviemに依存しているため、開発体験は非常に良好です。
-
ponderはより高いパフォーマンスを持っています。
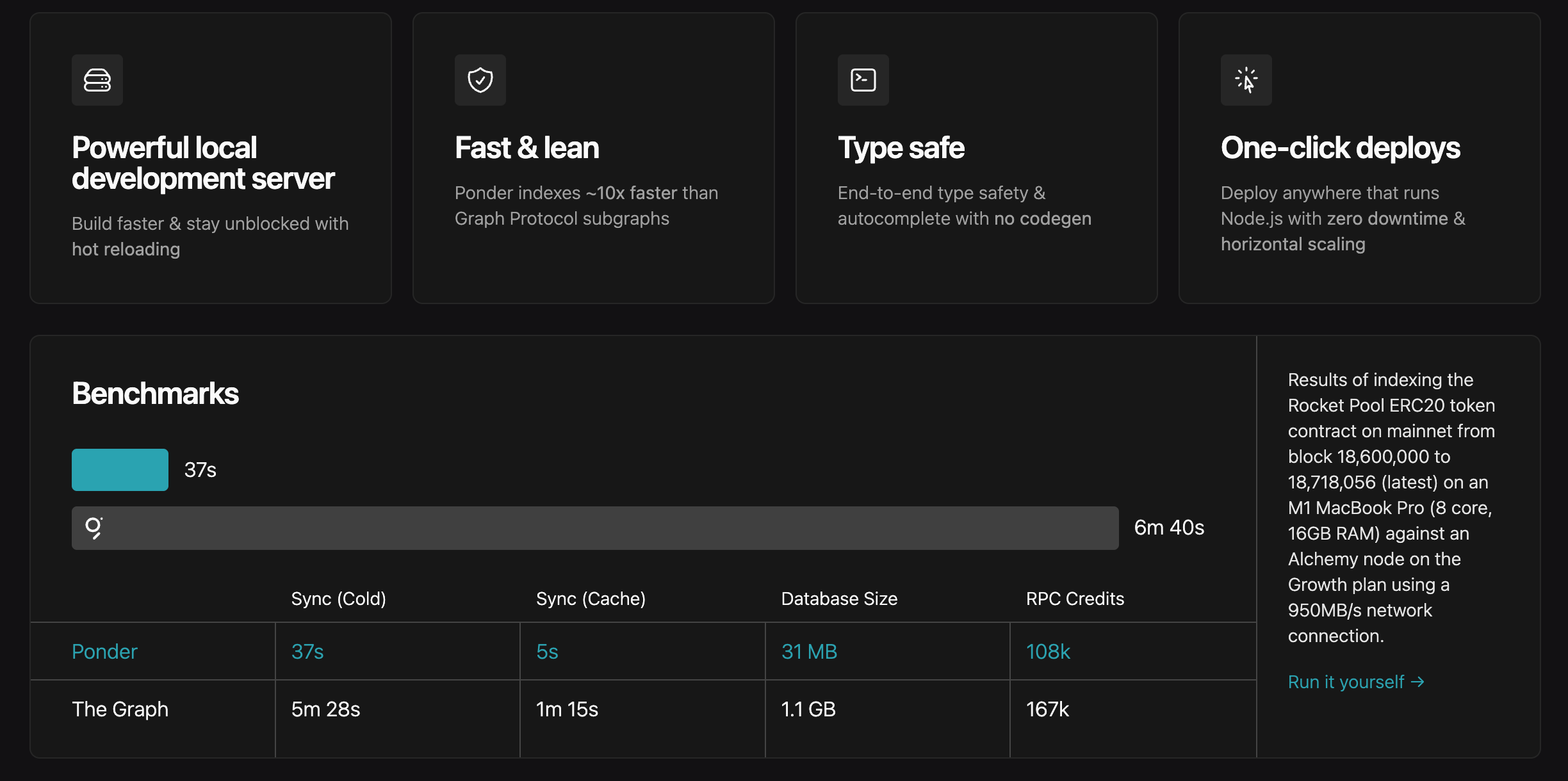
もちろん問題点もあります。ponderは現在も急速な開発段階にあり、破壊的更新によるバージョンアップにより、以前のプロジェクトが動作しなくなる可能性があります。本稿は技術入門記事ではないため、ponderの開発詳細についてはさらに議論しません。技術的背景を持つ読者はドキュメントを参照してください。
ponderのより興味深い点は、現在部分的に商用化を始めていることです。しかし、その商用化の道筋は、前回の記事で議論された「分離理論」と非常に適合しています。
ここで簡単に「分離理論」を紹介します。公共財の公共性ゆえに、任意の多数のユーザーにサービスを提供できます。したがって、公共財に対して課金すれば、一部のユーザーがその利用を諦めることになります。このとき社会的利益は最大化されません(経済学用語では「パレート最適でない」)。理論的には、公共財は一人ひとりに対して差別的価格設定を行うことで収益を得られますが、その差別的価格設定にかかるコストは、得られる余剰を上回る可能性が非常に高いです。そのため、公共財が無料で提供される理由は、公共財が元々無料であるべきだからではなく、固定料金を課す行為が社会的利益を損なうためであり、また現在のところ、全員に対して安価に差別的価格設定を行う方法が存在しないためです。分離理論は、公共財内で価格設定を行う方法を提案しています。すなわち、ある方法で同質的な集団の一部を隔離し、その集団に対して課金を行うのです。まず、分離理論はすべての人が公共財を無料で利用することを妨げません。しかし、一部の集団に対して課金を行う方法を提示しています。
ponderはまさにこのような分離理論の応用例です。
-
まず、ponderのデプロイには一定の知識が必要です。開発者はデプロイ中にRPCやデータベースなどの外部依存を提供する必要があります。
-
また、デプロイ後も継続的な運用が必要です。例えば、proxyシステムを使って負荷分散を行い、データリクエストがponderのバックグラウンドスレッドでのオンチェーンデータ検索に影響しないようにする必要があります。これらは一般の開発者にとっては少々複雑です。
-
現在ponderは、全自動デプロイサービスmarbleのベータ版を提供しており、ユーザーはコードをそのプラットフォームに提出するだけで自動デプロイが可能です。
これは明らかに「分離理論」の応用です。自らponderサービスを運用したくない開発者が隔離され、彼らは支払いによりponderサービスの簡易デプロイを受けることができます。もちろん、marbleプラットフォームの出現は、他の開発者がponderフレームワークを無料で使用し、自前でホスティングデプロイすることを妨げるものではありません。
ponderとGoldskyの対象ユーザーは?
-
ベンダー依存のまったくないponderのような公共財は、他のベンダー依存のデータ検索サービスと比べて、小規模プロジェクトの開発時により人気があります。
-
大規模プロジェクトを運営する開発者の中には、必ずしもponderフレームワークを選ばない人もいます。大規模プロジェクトは検索サービスに十分なパフォーマンスを求めることが多く、Goldskyなどのサービスプロバイダーは十分な可用性保証を提供しているためです。
両者にはリスクがあります。最近のGoldsky事件から考えると、開発者は常に自前のponderサービスを維持し、第三者サービスのダウンタイムに備えるのが最善です。また、ponder使用時にはRPCからのデータの有効性にも注意が必要です。最近safeは、RPCが誤ったデータを返したことによりインデクサーがクラッシュした事例を報告しています。Goldsky事件がRPCの無効イベントに関連しているという直接的証拠はありませんが、筆者は同様の事象が起きた可能性を疑っています。

local-first 開発理念
Local-firstはここ数年、繰り返し議論されてきたテーマです。簡単に言えば、local-firstはソフトウェアに以下の機能を要求します。
-
オフライン作業
-
複数クライアント間の協働
現在、local-first関連の技術議論の多くはCRDT(Conflict-free Replicated Data Type)技術に触れています。CRDTとは衝突のないデータ形式であり、複数端末での操作時に自動的に衝突をマージし、データの整合性を保つことを可能にします。単純に言えば、CRDTは簡単なコンセンサスプロトコルを持つデータ型と見なせます。分散環境下では、CRDTはデータの完全性と一貫性を保証します。
しかし、ブロックチェーン開発では、上記のlocal-firstのソフトウェア要件を緩和できます。プロジェクト開発者が提供するバックエンドインデックスデータがない場合でも、ユーザーがフロントエンド上で最低限の可用性を維持できることを求めます。また、local-firstが求める複数クライアント間の協働要件は、ブロックチェーンによってすでに解決されています。
DAppの文脈では、local-firstの理念は次のように実現できます。
-
重要なデータのキャッシュ:フロントエンドはユーザーの残高、保有ポジションなどの重要データをキャッシュすべきです。インデックスサービスが利用不可能でも、ユーザーは最後に確認された状態を確認できます。
-
機能のダウングレード設計:バックエンドインデックスサービスが利用不可能な場合、DAppは基本機能を提供できます。例えば、データ検索サービスが使えないときは、一部のデータを直接RPCを使ってオンチェーンデータを読み取ることで、ユーザーが既存データの最新状況を確認できるようにできます。
このようなlocal-firstのDApp設計理念は、アプリの堅牢性を著しく高め、データ検索サービスのクラッシュ後にアプリが使用不能になることを防ぎます。使いやすさを考慮しない場合、理想的なlocal-firstアプリはユーザー自身がローカルにノードを実行し、trueblocksのようなツールを使ってローカルでデータを検索することを要求するべきです。分散型検索やローカル検索に関する議論は、ツイートLiterally no one cares about decentralized frontends and indexersを参照してください。
四、最後に
Goldskyの6時間に及ぶダウンタイムは、エコシステムに警鐘を鳴らしました。ブロックチェーン自体は分散化と単一障害点耐性の特性を持っているものの、その上に構築されたアプリケーションエコシステムは依然として中央集権的なインフラサービスに強く依存しています。この依存関係は、エコシステム全体にシステミックリスクをもたらしています。
本稿では、名声高い分散型検索サービスTheGraphがなぜ現在広く使われていないのかを簡単に紹介し、特にGRTトークンエコノミクスがもたらす複雑さについて詳しく議論しました。最後に、より強固なデータ検索インフラの構築方法について考察し、筆者は開発者にponderのセルフホスティング型データ検索開発フレームワークを緊急対応策として活用することを勧めます。また、ponderの良好な商業化の道筋についても紹介しました。最後に、local-firstの開発理念について議論し、データ検索サービスなしでも利用可能なアプリの構築を呼びかけます。
現時点では、多くのWeb3開発者が認識している通り、データ検索サービスの単一障害点問題は顕在化しています。GCCは、より多くの開発者がこのインフラに注目し、分散型データ検索サービスの構築を試みたり、データ検索サービスがなくてもDAppフロントエンドが動作するフレームワークを設計したりすることを期待しています。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














