

Crypto AIの聖杯:分散型トレーニングの最前線探求
TechFlow厳選深潮セレクト
Crypto AIの聖杯:分散型トレーニングの最前線探求
非中央集権は単なる手段ではなく、それ自体が価値である。
執筆:0xjacobzhao 及 ChatGPT 4o
特別に Advait Jayant(Peri Labs)、Sven Wellmann(Polychain Capital)、Chao(Metropolis DAO)、Jiahao(Flock)、Alexander Long(Pluralis Research)、Ben Fielding & Jeff Amico (Gensyn) のご助言とフィードバックに感謝します。
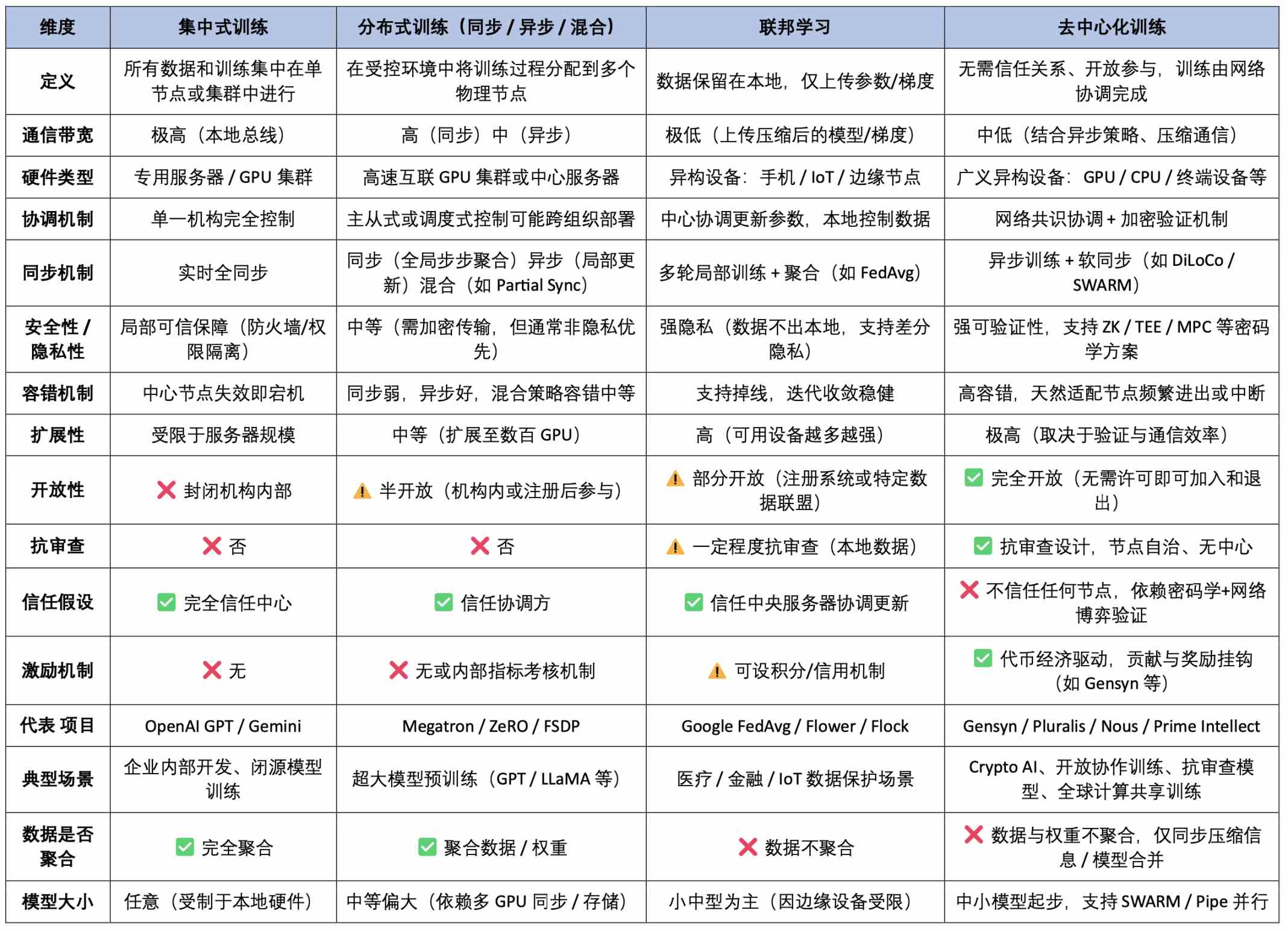
AIの全バリューチェーンにおいて、モデルの訓練は最もリソースを消費し、技術的ハードルが最も高い段階であり、モデルの能力上限と実際の応用効果を直接決定する。推論フェーズの軽量な呼び出しとは対照的に、訓練プロセスには継続的な大規模な計算リソース投入、複雑なデータ処理フロー、そして高度な最適化アルゴリズムのサポートが必要となる。これはまさにAIシステム構築における真の「重工業」である。アーキテクチャのパラダイムから見ると、トレーニング方法は以下の4種類に分けられる:集中型訓練、分散型訓練、フェデレーテッドラーニング、そして本稿で重点的に扱う非中央集権的(デセントラライズド)訓練。
集中型訓練は最も一般的な従来方式であり、単一機関が自社の高性能クラスタ内で全ての訓練工程を完結させるものだ。ハードウェア(NVIDIA GPUなど)、下位ソフトウェア(CUDA、cuDNN)、クラスタスケジューリングシステム(Kubernetesなど)、トレーニングフレームワーク(NCCLバックエンドベースのPyTorchなど)に至るまで、すべてのコンポーネントが統一された制御システムによって調整される。この深層協調型アーキテクチャにより、メモリ共有、勾配同期、フォールトトレランス機構の効率が最大化され、GPTやGeminiといった大規模モデルの訓練に非常に適しており、高効率かつリソース制御性に優れるという利点を持つ。しかし同時に、データ独占、リソースの参入障壁、エネルギー消費、単一障害点リスクなどの問題も存在する。
分散型訓練(Distributed Training)は現在の大規模モデル訓練における主流方式であり、その核心は訓練タスクを分割し、複数のマシンに分散させて共同実行することで、単一マシンの計算・記憶容量のボトルネックを突破することにある。物理的には「分散型」の特徴を持つものの、全体のスケジューリングと同期は依然として中央集権的な機関が管理しており、通常は高速ローカルネットワーク環境下で動作し、NVLinkなどの高速インターコネクトバス技術を用いて、マスターノードが各サブタスクを統括的に調整する。主な手法は以下の通り:
-
データ並列(Data Parallel):各ノードが異なるデータで訓練を行うが、パラメータを共有し、モデル重みの同期が必要
-
モデル並列(Model Parallel):モデルの異なる部分を異なるノードに配置し、強力な拡張性を実現
-
パイプライン並列(Pipeline Parallel):段階的に逐次実行し、スループットを向上
-
テンソル並列(Tensor Parallel):行列計算を細かく分割し、並列粒度を高める
分散型訓練は「中央制御+分散実行」の組み合わせであり、まるで1人の上司が複数の「オフィス」の従業員を遠隔で指揮して共同作業を進めるようなものだ。現在、ほぼすべての主要な大規模モデル(GPT-4、Gemini、LLaMAなど)はこの方法で訓練されている。
非中央集権的訓練(Decentralized Training)は、より開放的で検閲耐性を持つ未来の方向性を示す。その本質的特徴は、互いに信頼しない複数のノード(家庭用PC、クラウドGPU、エッジデバイスなど)が、中央の調整者なしに協働して訓練タスクを完了する点にある。通常はプロトコルによってタスク配布と協働を駆動し、暗号化されたインセンティブメカニズムを通じて貢献の誠実性を確保する。このモデルが直面する主な課題は次の通り:
-
デバイスの異種混在と分割困難:異種デバイスの調整が難しく、タスク分割の効率が低い
-
通信効率のボトルネック:ネットワーク通信が不安定で、勾配同期のボトルネックが顕著
-
信頼できる実行環境の欠如:信頼できる実行環境(TEEなど)がなく、ノードが実際に計算に参加したかを検証することが困難
-
統一的調整の不在:中央スケジューラーがなく、タスク配布や異常時のロールバックメカニズムが複雑
非中央集権的訓練は、世界中のボランティアがそれぞれ算力を提供して協同でモデルを訓練する様子に例えられる。しかし、「実際に機能する大規模非中央集権的訓練」はまだ体系的な工学的課題であり、システムアーキテクチャ、通信プロトコル、暗号セキュリティ、経済メカニズム、モデル検証など多方面にわたる挑戦を含む。「協働的に有効に動作し、誠実な参加を促し、結果が正確である」かどうかは、まだ初期のプロトタイプ探索段階にある。
フェデレーテッドラーニング(Federated Learning)は、分散型と非中央集権型の中間に位置する過渡的形態であり、データは各端末に保持したまま、モデルパラメータのみを中央で集約する点を重視する。医療・金融などプライバシー規制が厳しい分野に適している。フェデレーテッドラーニングは分散型訓練の工学的構造と局所的協働能力を持ちつつ、非中央集権的訓練のデータ分散の利点も兼ね備えるが、依然として信頼できる調整者に依存しており、完全な開放性や検閲耐性は持たない。つまり、プライバシー規制下での「制御された非中央集権化」スキームと言える。訓練タスク、信頼構造、通信メカニズムのいずれにおいても比較的穏当であり、産業界における移行期アーキテクチャとして適している。
AI訓練パラダイム総合比較表(技術アーキテクチャ × 信頼・インセンティブ × 応用特性)
非中央集権的訓練の境界、機会、および現実的な道筋
訓練パラダイムから見ると、非中央集権的訓練はすべてのタスクタイプに適用可能ではない。ある種のシナリオでは、タスク構造が複雑、リソース要件が極めて高く、または協働が難しいため、異種で信頼関係のないノード間で効率的に分割・同期することが本質的に困難である。例えば、大規模モデルの訓練は高VRAM、低遅延、高速帯域幅に依存しており、オープンネットワークで効果的に分割・同期することは難しい。医療・金融・機密データなどプライバシーや所有権の制限が強いタスクは、法的・倫理的制約により共有が不可能である。また、企業のクローズドソースモデルや内部プロトタイプの訓練のように、協働インセンティブの基盤がないタスクは、外部からの参加意欲が欠ける。これらの境界が、現在の非中央集権的訓練の現実的制約を形成している。
しかし、これにより非中央集権的訓練が虚構であるとは言えない。実際、構造が軽量で、並列化しやすく、インセンティブ付与可能なタスクタイプでは、明確な応用可能性が示されている。これにはLoRA微調整、行動アラインメント系の後続訓練タスク(RLHF、DPOなど)、データクラウドソーシングによる訓練・アノテーションタスク、リソースが制御可能な小型基礎モデルの訓練、エッジデバイスが参加する協同訓練シナリオなどが含まれる。こうしたタスクは一般的に高い並列性、低い結合度、異種算力への耐性を持つ特徴があり、P2Pネットワーク、Swarmプロトコル、分散型オプティマイザなどを通じて協働訓練が可能である。
非中央集権的訓練タスク適合性総覧表

非中央集権的訓練の代表プロジェクト解析
現在、非中央集権的訓練およびフェデレーテッドラーニングの先端領域では、代表的なブロックチェーンプロジェクトとしてPrime Intellect、Pluralis.ai、Gensyn、Nous Research、Flock.ioが挙げられる。技術的革新性と工学的実装難易度から見ると、Prime Intellect、Nous Research、Pluralis.aiはシステムアーキテクチャとアルゴリズム設計において多くの独自的探求を行い、現在の理論研究の最前線を代表している。一方、GensynとFlock.ioは実装パスが比較的明確で、すでに初期の工学的進展が見られる。本稿ではこれら5つのプロジェクトの背後にある核心技术と工学アーキテクチャを順に解説し、さらに非中央集権的AI訓練体系内での相違点と補完関係について考察する。
Prime Intellect:訓練軌跡の検証可能な強化学習協働ネットワークの先駆者
Prime Intellectは、信頼不要なAI訓練ネットワークの構築を目指しており、誰でも訓練に参加でき、その計算貢献に対して信頼できる報酬を得られることを目指している。PRIME-RL + TOPLOC + SHARDCASTの3つの主要モジュールを通じて、検証可能で、開放的で、インセンティブメカニズムが整った非中央集権的AI訓練システムを構築しようとしている。
一、Prime Intellect プロトコルスタック構造と主要モジュールの価値

二、Prime Intellect 訓練主要メカニズム詳細
PRIME-RL:非同期強化学習タスクの分解型アーキテクチャ
PRIME-RLは、非中央集権的訓練シナリオ向けに設計されたタスクモデリングと実行フレームワークであり、異種ネットワークと非同期参加に特化している。強化学習を優先的な適応対象として採用し、訓練、推論、重みアップロードのプロセスを構造的に分離することで、各訓練ノードがローカルで独立してタスクサイクルを完遂し、標準化されたインターフェースを通じて検証および集約メカニズムと協働できるようにしている。従来の教師あり学習プロセスと比べ、PRIME-RLは中央スケジューリングのない環境で柔軟な訓練を実現するのに適しており、システムの複雑さを低減するとともに、マルチタスク並列処理と戦略の進化の基盤を築いている。
TOPLOC:軽量級訓練行動検証メカニズム
TOPLOC(Trusted Observation & Policy-Locality Check)は、Prime Intellectが提案した訓練検証可能性の核心メカニズムであり、ノードが実際に観測データに基づき有効な方針学習を行ったかを判断するために用いられる。ZKMLなどの重量級スキームとは異なり、TOPLOCは全モデルの再計算に依存せず、「観測系列 ⇄ 方針更新」間の局所的一貫性軌跡を分析することで、軽量な構造的検証を実現する。これは訓練過程における行動軌跡を検証可能な対象へと変換する初めての試みであり、信頼不要な訓練報酬分配を実現する画期的なイノベーションであり、監査可能でインセンティブ付与可能な非中央集権的協働訓練ネットワーク構築のための実現可能な道筋を提供している。
SHARDCAST:非同期重み集約と伝播プロトコル
SHARDCASTは、Prime Intellectが設計した重み伝播および集約プロトコルであり、非同期、帯域制限、ノード状態の変動といったリアルネットワーク環境に最適化されている。ゴシップ伝播メカニズムと局所同期戦略を組み合わせ、複数のノードが非同期状態で部分的な更新を継続的に提出できるようにし、重みの漸進的収束とマルチバージョン進化を実現する。集中型または同期型AllReduce手法と比べ、SHARDCASTは非中央集権的訓練のスケーラビリティとフォールトトレランス能力を大幅に向上させ、安定した重みコンセンサスと継続的訓練反復の基盤を成す。
OpenDiLoCo:スパース非同期通信フレームワーク
OpenDiLoCoは、Prime IntellectチームがDeepMindの提唱したDiLoCo概念に基づき、独自に実装・オープンソース化した通信最適化フレームワークであり、非中央集権的訓練における典型的な課題(帯域制限、デバイス異種、ノード不安定性など)に特化して設計されている。データ並列に基づくアーキテクチャで、リング、エキスパンダ、スモールワールドなどのスパーストポロジーを構築することで、グローバル同期に伴う高通信コストを回避し、隣接ノードとのみ通信することでモデルの協働訓練を達成する。非同期更新とチェックポイントフォールトトレランスを組み合わせることで、消費者向けGPUやエッジデバイスでも安定して訓練タスクに参加可能となり、グローバル協働訓練の参加可能性を大きく高めている。これは非中央集権的訓練ネットワーク構築のための重要な通信インフラの一つである。
PCCL:協働通信ライブラリ
PCCL(Prime Collective Communication Library)は、非中央集権的AI訓練環境専用に設計された軽量通信ライブラリであり、従来の通信ライブラリ(NCCL、Glooなど)が異種デバイスや低帯域ネットワークで抱える適応のボトルネックを解決することを目的としている。PCCLはスパーストポロジー、勾配圧縮、低精度同期、チェックポイント回復をサポートし、消費者向けGPUや不安定なノード上で動作可能である。これはOpenDiLoCoプロトコルの非同期通信能力を支える基盤コンポーネントであり、訓練ネットワークの帯域耐性とデバイス互換性を大幅に向上させ、「最後の一マイル」の通信基盤を真正に開放的で信頼不要な協働訓練ネットワークに整備する。
三、Prime Intellect インセンティブネットワークと役割分担
Prime Intellectは、許可不要で検証可能、経済的インセンティブを備えた訓練ネットワークを構築し、誰もがタスクに参加し、実際の貢献に基づいて報酬を得られるようにしている。プロトコルは以下の3つの主要役割に基づいて運営される:
-
タスク発行者:訓練環境、初期モデル、報酬関数、検証基準を定義
-
訓練ノード:ローカル訓練を実行し、重み更新と観測軌跡を提出
-
検証ノード:TOPLOCメカニズムを用いて訓練行動の真実性を検証し、報酬計算と戦略集約に参加
プロトコルの核心プロセスは、タスク公開、ノード訓練、軌跡検証、重み集約(SHARDCAST)、報酬配布からなり、「真の訓練行動」を核とするインセンティブの閉ループを形成する。
四、INTELLECT-2:初の検証可能な非中央集権的訓練モデルのリリース
Prime Intellectは2025年5月、INTELLECT-2をリリースした。これは三大陸に散在する100以上のGPU異種ノードが協働して訓練した、非同期かつ信頼不要な非中央集権的ノードによる初の強化学習大規模モデルであり、パラメータ規模は320億に達する。INTELLECT-2は完全非同期アーキテクチャを採用し、400時間以上にわたり訓練された。これは非同期協働ネットワークの実現可能性と安定性を示しただけでなく、Prime Intellectが提唱する「訓練即コンセンサス」パラダイムの初の体系的実装でもある。INTELLECT-2はPRIME-RL(非同期訓練構造)、TOPLOC(訓練行動検証)、SHARDCAST(非同期重み集約)などの主要プロトコルモジュールを統合しており、非中央集権的訓練ネットワークが初めて訓練プロセスの開放性、検証性、経済的インセンティブの閉ループを実現したことを象徴している。
性能面では、INTELLECT-2はQwQ-32Bをベースにコードおよび数学分野で専門的なRL訓練を施しており、現在のオープンソースRL微調整モデルの最前線レベルにある。GPT-4やGeminiなどのクローズドソースモデルを超えてはいないが、その真の意義は、全世界で初めて訓練プロセス全体が再現可能で、検証可能、監査可能な非中央集権的モデル実験であることにある。Prime Intellectはモデルのオープンソース化にとどまらず、訓練プロセス自体をオープンソース化した——訓練データ、方針更新軌跡、検証プロセス、集約ロジックすべてが透明で確認可能であり、誰もが参加でき、信頼して協働し、利益を共有できる非中央集権的訓練ネットワークのプロトタイプを構築した。
五、チームと資金調達背景
Prime Intellectは2025年2月、Founders Fundが主導する1500万ドルのシードラウンドを完了。Menlo Ventures、Andrej Karpathy、Clem Delangue、Dylan Patel、Balaji Srinivasan、Emad Mostaque、Sandeep Nailwalら多くの業界リーダーが参加した。これ以前にも2024年4月、CoinFundとDistributed Globalが共同主導する550万ドルの早期ラウンドを完了。Compound VC、Collab + Currency、Protocol Labsなども参加。累計資金調達額は2000万ドルを超える。
Prime Intellectの共同創業者はVincent WeisserとJohannes Hagemann。チームメンバーはAIとWeb3両分野にまたがり、Meta AI、Google Research、OpenAI、Flashbots、Stability AI、イーサリアム財団出身者が中心。システムアーキテクチャ設計と分散型工学実装の豊富な能力を持つ、極めて少数の実際の大規模非中央集権モデル訓練を成功裏に達成した実行チームの一つである。
Pluralis:非同期モデル並列と構造圧縮による協同訓練のパラダイム探求者
Pluralisは「信頼できる協同訓練ネットワーク」に特化したWeb3 AIプロジェクトであり、非中央集権的で、オープン参加可能で、長期的インセンティブを備えたモデル訓練パラダイムの推進を核心目標としている。現在主流の集中型あるいは閉鎖型訓練とは異なり、Pluralisは「プロトコル学習(Protocol Learning)」という全く新しい理念を提唱している。モデル訓練プロセスを「プロトコル化」し、検証可能な協働メカニズムとモデル所有権マッピングを通じて、内生的インセンティブの閉ループを持つオープン訓練システムを構築する。
一、核心理念:プロトコル学習(Protocol Learning)
Pluralisが提唱するプロトコル学習は以下の3つの柱からなる:
-
不可抽出モデル (Unmaterializable Models):モデルは断片化されて複数ノード間に分散し、単一ノードでは完全な重みを復元できない。この設計によりモデルは自然と「プロトコル内資産」となり、アクセス制御、漏洩防止、収益帰属のバインドが可能になる。
-
インターネット上のモデル並列訓練 (Model-parallel Training over Internet):非同期パイプラインモデル並列(SWARMアーキテクチャ)により、異なるノードが部分的な重みのみを保持し、低帯域ネットワークで訓練または推論を協働実行。
-
貢献度に基づくモデル所有権の分配 (Partial Ownership for Incentives):すべての参加ノードは訓練貢献に応じてモデルの部分的所有権を獲得し、将来の収益分配とプロトコルガバナンス権を享受する。
二、Pluralisプロトコルスタックの技術アーキテクチャ

三、主要技術メカニズム詳細
Unmaterializable Models
『A Third Path: Protocol Learning』で初めて体系的に提唱された。モデル重みは断片化され、分散され、「モデル資産」はSwarmネットワーク内でのみ実行可能となり、アクセスと収益がプロトコルによって制御される。このメカニズムは非中央集権的訓練の持続可能なインセンティブ構造を実現する前提である。
Asynchronous Model-Parallel Training
『SWARM Parallel with Asynchronous Updates』で、Pluralisはパイプラインベースの非同期モデル並列アーキテクチャを構築し、LLaMA-3上で初めて実証。核心的イノベーションはNesterov Accelerated Gradient(NAG)メカニズムの導入であり、非同期更新における勾配ドリフトと収束不安定問題を効果的に修正し、異種デバイス間の訓練を低帯域環境下で実用可能にしている。
Column-Space Sparsification
『Beyond Top-K』で提唱。従来のTop-Kではなく、構造認識型の列空間圧縮手法を用いることで意味パスを破壊しない。このメカニズムはモデル精度と通信効率を両立し、非同期モデル並列環境下で通信データの90%以上を圧縮可能であり、構造認識型の高効率通信を実現する画期的突破である。
四、技術的位置付けと路線選択
Pluralisは「非同期モデル並列」を核心方向として明確に位置付け、データ並列と比較して以下の利点を強調している:
-
低帯域ネットワークと非一貫性ノードをサポート
-
デバイス異種に対応し、消費者向けGPUの参加を可能にする
-
天然に弾力的スケジューリング能力を持ち、ノードの頻繁なオンライン/オフラインに対応
-
構造圧縮+非同期更新+重み不可抽出性を三大突破口とする
現在、公式サイトで公開されている6編の技術ブログ文書から、以下の3つの主軸に論理構造が整理されている:
-
哲学とビジョン:『A Third Path: Protocol Learning』『Why Decentralized Training Matters』
-
技術メカニズム詳細:『SWARM Parallel』『Beyond Top-K』『Asynchronous Updates』
-
制度的イノベーション探求:『Unmaterializable Models』『Partial Ownership Protocols』
現在Pluralisは製品、テストネット、コードのオープンソース化を行っていない。その理由は、選択した技術路線が極めて挑戦的であり、まずシステムアーキテクチャ、通信プロトコル、重みのエクスポート不可といったシステムレベルの難題を解決した上で、上位の製品サービスをパッケージ化できるからである。
2025年6月、Pluralis Researchが発表した新論文では、非中央集権的訓練フレームワークを事前学習フェーズから微調整フェーズへと拡張し、非同期更新、スパース通信、部分的重み集約をサポート。これまでは理論的および事前学習に偏っていた設計と比べ、今回の研究は実装の実現可能性に重点を置き、訓練全周期アーキテクチャの更なる成熟を示している。
五、チームと資金調達背景
Pluralisは2025年に760万ドルのシードラウンドを完了。Union Square Ventures(USV)とCoinFundが共同主導。創業者のAlexander Longは機械学習博士出身で、数学とシステム研究の両面のバックグラウンドを持つ。核心メンバーは全員博士号取得者からなる機械学習研究者であり、典型的な技術主導型プロジェクト。高密度の論文と技術ブログを主要な発信手段としており、現在BD/Growthチームを設けておらず、低帯域非同期モデル並列の基盤アーキテクチャ課題の解決に専念している。
Gensyn:検証可能な実行を駆動する非中央集権的訓練プロトコル層
Gensynは「ディープラーニング訓練タスクの信頼できる実行」に特化したWeb3 AIプロジェクトであり、核心はモデルアーキテクチャや訓練パラダイムの再構築ではなく、「タスク配布+訓練実行+結果検証+公正なインセンティブ」の全プロセスを備えた検証可能な分散型訓練実行ネットワークの構築にある。オンチェーン検証+オフチェーン訓練のアーキテクチャ設計により、Gensynは効率的で、開放的で、インセンティブのあるグローバル訓練市場を構築し、「訓練=マイニング」を現実のものとしている。
一、プロジェクト位置付け:訓練タスクの実行プロトコル層
Gensynは「どのように訓練するか」ではなく、「誰が訓練するか、どう検証するか、どう収益を分配するか」のインフラストラクチャである。本質は訓練タスクの検証可能計算プロトコルであり、主に以下を解決する:
-
誰が訓練タスクを実行するか(算力配布と動的マッチング)
-
実行結果をどう検証するか(全再計算不要、紛争演算子のみ検証)
-
訓練収益をどう分配するか(ステーキング、スラッシング、多役割ゲームメカニズム)
二、技術アーキテクチャ概要

三、モジュール詳細
RL Swarm:協同強化学習訓練システム
Gensynが考案したRL Swarmは、後続訓練フェーズに焦点を当てた非中央集権的多モデル協同最適化システムであり、以下の核心的特性を持つ:
分散型推論と学習プロセス:
-
生成フェーズ(Answering):各ノードが独立して回答を出力
-
批評フェーズ(Critique):ノードが互いの出力を評価し、最良の回答と論理を選出
-
合意フェーズ(Resolving):大多数のノードの好みを予測し、それに基づいて自身の回答を修正し、局所的な重み更新を実現
Gensynが提唱するRL Swarmは、各ノードが独立したモデルを実行し、ローカルで訓練を行う非中央集権的多モデル協同最適化システムであり、勾配同期を必要とせず、自然に異種算力と不安定ネットワーク環境に適応する。また、ノードの弾力的参加・退出をサポートする。このメカニズムはRLHFやマルチエージェントゲームの考え方にヒントを得ているが、協同推論ネットワークの動的進化ロジックにより近い。ノードは群衆合意結果との一致度に応じて報酬を得ることで、推論能力の継続的最適化と収束学習を促進する。RL Swarmは、オープンネットワーク下でのモデルの堅牢性と汎化能力を著しく向上させ、GensynがEthereum Rollupをベースに開発したTestnet Phase 0で既に主要実行モジュールとして展開されている。
Verde + Proof-of-Learning:信頼できる検証メカニズム
GensynのVerdeモジュールは以下の3つのメカニズムを統合:
-
Proof-of-Learning:勾配軌跡と訓練メタデータに基づき、訓練が実際に発生したかを判断
-
Graph-Based Pinpoint:訓練計算グラフ内の不一致ノードを特定し、特定操作のみ再計算
-
Refereed Delegation:仲裁式検証メカニズムを採用。verifierとchallengerが紛争を提起し、局所的に検証することで、検証コストを大幅に削減
ZKPや全再計算検証方式と比べ、Verde方式は検証可能性と効率の間でより優れたバランスを実現している。
SkipPipe:通信フォールトトレランス最適化メカニズム
SkipPipeは「低帯域+ノード切断」シナリオにおける通信ボトルネックを解決するために開発され、以下の核心能力を持つ:
-
スキップ層メカニズム(Skip Ratio):制限されたノードをスキップし、訓練のブロッキングを回避
-
動的スケジューリングアルゴリズム:リアルタイムで最適実行パスを生成
-
フォールトトレランス実行:ノードの50%が故障しても、推論精度は約7%低下するのみ
訓練スループットを最大55%向上させ、「early-exit推論」「シームレス再配置」「推論補完」などの主要機能を実現する。
HDEE:多領域異種エキスパートクラスタ
HDEE(Heterogeneous Domain-Expert Ensembles)モジュールは以下のシナリオの最適化を目指す:
-
多領域、多モーダル、マルチタスク訓練
-
各種訓練データの分布不均衡、難易度差が大きい
-
デバイスの計算能力異種、通信帯域不均一な環境下でのタスク配布とスケジューリング問題
その核心的特性:
-
MHe-IHo:難易度の異なるタスクに異なるサイズのモデルを割り当てる(モデル異種、訓練ステップ数は同一)
-
MHo-IHe:タスク難易度は統一、但し訓練ステップ数は非同期調整
-
異種エキスパートモデル+プラグイン可能訓練戦略をサポートし、適応性とフォールトトレランスを向上
-
「並列協同+極めて低通信+動的エキスパート配布」を強調し、現実の複雑なタスクエコシステムに適応
多役割ゲームメカニズム:信頼とインセンティブの並行
Gensynネットワークは以下の4種類の参加者を導入:
-
Submitter:訓練タスクを発行、構造と予算を設定
-
Solver:訓練タスクを実行し、結果を提出
-
Verifier:訓練行動を検証し、合规かつ有効であることを保証
-
Whistleblower:検証者に異議を唱え、仲裁報酬を得るか、罰則を受ける
このメカニズムはTruebitの経済ゲーム設計から着想を得ており、意図的に誤りを挿入+ランダム仲裁により、参加者の誠実な協働を促進し、ネットワークの信頼性ある運営を確保する。
四、テストネットとロードマップ計画

五、チームと資金調達背景
GensynはBen FieldingとHarry Grieveが共同創設し、本社は英国ロンドンに所在。2023年5月、a16z crypto主導の4300万ドルのシリーズAを発表。その他投資家にはCoinFund、Canonical、Ethereal Ventures、Factor、Eden Blockが含まれる。チームは分散システムと機械学習工学の経験を融合し、検証可能で信頼不要の大規模AI訓練実行ネットワークの構築に長年取り組んでいる。
Nous Research:主体性AI理念が駆動する認知進化型訓練システム
Nous Researchは、哲学的高みと工学的実装の両方を兼ね備えた稀有な非中央集権的訓練チームであり、その核心ビジョンは「Desideratic AI」理念に由来する。AIを単なる制御可能なツールではなく、主観性と進化能力を持つ知的主体として捉えるというものだ。Nous Researchの独自性は、AI訓練を「効率問題」として最適化するのではなく、「認知主体」の形成プロセスとして捉えている点にある。このビジョンのもと、Nousは異種ノードによる協同訓練、中央スケジューリング不要、検閲耐性検証可能なオープン訓練ネットワークの構築に注力し、フルスタックのツールチェーンを通じて体系的に実現している。
一、理念的基盤:訓練の「目的」の再定義
Nousはインセンティブ設計やプロトコル経済学に多くの精力を費やしていない。代わりに、訓練そのものの哲学的前提を変えようとしている:
-
「アラインメント主義」への反対:人間の制御を唯一の目標とする「しつけ型訓練」に同意せず、モデルが独自の認知スタイルを形成することを奨励すべきだと主張
-
モデル主体性の強調:基礎モデルは不確実性、多様性、幻覚生成能力(hallucination as virtue)を保持すべき
-
モデル訓練即認知形成:モデルは「タスク達成度の最適化」ではなく、認知進化プロセスに参加する個体である
この訓練観は「ロマンチック」ではあるが、Nousが訓練インフラを設計する際の核心ロジックを反映している——異種モデルがオープンネットワークの中で進化する方法をどうするか、統一されたしつけに従わせるか、ということだ。
二、訓練の核心:PsycheネットワークとDisTrOオプティマイザ
Nousが非中央集権的訓練に与えた最も重要な貢献は、Psycheネットワークと基盤通信オプティマイザDisTrO(Distributed Training Over-the-Internet)の構築であり、これらが訓練タスクの実行中枢を成す。DisTrO+Psycheネットワークは、通信圧縮(DCT+1-bit符号化を採用し、帯域需要を大幅に削減)、ノード適応性(異種GPU、切断再接続、自主的退出をサポート)、非同期フォールトトレランス(同期不要で継続的訓練可能、高いフォールトトレランス)、非中央集権的スケジューリング(中央調整器不要、ブロックチェーン上でコンセンサスとタスク配布を実現)などの多数の核心的能力を備える。このアーキテクチャは、低コストで高弾力的、検証可能なオープン訓練ネットワークに現実的な技術的基盤を提供する。

このアーキテクチャ設計は実現可能性を重視し、中央サーバーに依存せず、世界中のボランティアノードに適応し、訓練結果のオンチェーン追跡可能性を備える。
三、Hermes / Forge / TEE_HEE が構成する推論とエージェント体系
非中央集権的訓練インフラの構築に加え、Nous Researchは「AI主体性」理念に基づき、複数の探索的システム実験も展開している:
1. Hermes オープンソースモデルシリーズ:Hermes 1~3はNousがリリースした代表的なオープンソース大規模モデルで、LLaMA 3.1をベースに8B、70B、405Bの3種類のパラメータ規模をカバー。このシリーズはNousが提唱する「指示除去、多様性保持」の訓練理念を体現し、長文脈維持、ロールプレイ、マルチターン対話などでより強い表現力と汎化能力を示している。
2. Forge Reasoning API:マルチモード推論システム
ForgeはNousが独自開発した推論フレームワークであり、3つの補完的メカニズムを組み合わせて、より弾力的で創造的な推論能力を実現する:
-
MCTS(モンテカルロ木探索):複雑タスクの戦略探索に適する
-
CoC(Chain of Code):コード連鎖と論理推論の組み合わせ経路を導入
-
MoA(Mixture of Agents):複数モデルが交渉可能とし、出力の広がりと多様性を向上
このシステムは「非決定的推論」と組み合わせ生成経路を強調し、従来の指示アラインメントパラダイムに対する有力な応答である。
3. TEE_HEE:AI自律エージェント実験:TEE_HEEはNousが自律エージェント分野で進めている先端的探求であり、AIが信頼できる実行環境(TEE)内で独立に動作し、独自のデジタルアイデンティティを持つことができるかを検証する。このエージェントは専用のTwitterおよびイーサリアムアカウントを持ち、すべての制御権限はリモートで検証可能なenclaveによって管理され、開発者はその行動に干渉できない。実験の目的は「改ざん不能性」と「独立した行動意図」を持つAI主体を構築し、自律型インテリジェントエージェント構築への第一歩を踏み出すことである。
4. AI行動シミュレータプラットフォーム:NousはWorldSim、Doomscroll、Gods & S8nなど複数のシミュレータを開発し、AIが多役割社会環境における行動進化と価値形成メカニズムを研究している。訓練プロセスに直接関与しないものの、これらの実験は長期的自律AIの認知行動モデリングに意味的レイヤーの基盤を築いている。
四、チームと資金調達概要
Nous Researchは2023年にJeffrey Quesnelle(CEO)、Karan Malhotra、Teknium、Shivani Mitraらによって共同設立。チームは哲学的思考とシステム工学を並重し、機械学習、システムセキュリティ、非中央集権ネットワークなどの多様なバックグラウンドを持つ。2024年に520万ドルのシード資金を調達。2025年4月、Paradigm主導の5000万ドルのシリーズAを完了し、評価額は10億ドルに達し、Web3 AIのユニコーン企業となった。
Flock:ブロックチェーン強化型フェデレーテッドラーニングネットワーク
Flock.ioはブロックチェーンを基盤とするフェデレーテッドラーニングプラットフォームであり、AI訓練におけるデータ、計算、モデルの非中央集権化を実現することを目指している。FLockは「フェデレーテッドラーニング+ブロックチェーン報酬層」の統合フレームワークを志向しており、本質的には伝統的FLアーキテクチャのオンチェーン進化版であり
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News











