

ハードコア対話 Scroll 張燁:zkEVM と Scroll、そしてその将来
TechFlow厳選深潮セレクト
ハードコア対話 Scroll 張燁:zkEVM と Scroll、そしてその将来
本稿はScrollを理解するための絶好の資料であり、張燁氏がScrollおよびzkEVMに関する15の質問に回答しています。
インタビュアー:Nickqiao & Faust、Geek Web3
インタビュー対象者:YeZhang、Scroll共同創設者
編集:Faust、Jomosis
6月17日、Geek Web3およびBTCEdenは、ScrollのDevRelであるVincent Jin氏の協力を得て、Scroll共同創設者の張燁(イエ・ジャン)氏を招き、ScrollやzkEVMに関する多くの疑問に答えていただきました。
このセッションでは技術的な話題だけでなく、Scrollに関連する興味深いエピソードや、アフリカ・中東・ラテンアメリカなどの新興地域における実体経済支援という壮大なビジョンについても語られました。以下は今回のインタビューを文字起こしした記録であり、1万字以上、少なくとも15のトピックを含んでいます:
-
ZK技術の伝統的分野への応用可能性
-
zkEVMとzkVMの工学的難易度の違い
-
ScrollがzkEVM実装中に直面した技術的課題
-
ScrollがZcashのhalo2証明システムに対して行った改良点
-
ScrollとEthereum PSEチームとの協業方法
-
コード監査を通じた回路の安全性確保方法
-
次世代zkEVMおよび証明システムの将来計画
-
ScrollのMulti Prover設計およびProver生成ネットワーク(zkマイニングプール)の構築方式など。
さらに、張燁氏は最後にアフリカ、トルコ、東南アジアといった金融インフラが未発達な地域に根ざし、現地の人々のために実際の経済利用シーンを提供することで「バーチャルからリアルへ」脱却するという大規模なビジョンについて触れました。本記事は、Scrollの理解を深めるための優れた資料の一つであり、ぜひじっくりとご一読ください。

1.Faust: 張燁先生、Rollup以外の分野におけるZK技術の応用についてどのようにお考えですか?多くの人はZKといえばミキサー、プライベート送金、ZK Rollup、ZKブリッジなどを思い浮かべますが、Web3以外、例えば伝統産業でのZK活用事例も多数あります。今後、ZKが最も有望だとされる応用分野はどこでしょうか?
YeZhang:これは非常に良い質問です。実は伝統産業でZKに取り組んでいる人々は、5〜6年前からさまざまな応用シナリオを探求していました。ブロックチェーンにおけるZKの応用は、全体から見ればごく一部に過ぎません。そのため、Vitalikも「10年後にはZKの応用範囲がブロックチェーンと同じくらい大きくなる」と述べているのです。
信頼性の仮定が必要な場面において、ZKは非常に大きな価値を持ちます。たとえば、複雑な計算タスクを処理したい場合、AWSでサーバーを借りて自らのタスクを実行し結果を得る方法があります。これは自分の管理下にあるデバイスで計算を行うことに相当しますが、そのコストは決して安くありません。
一方で、計算を外部委託するモデルを考えると、多くの人が余剰なデバイスやリソースを使ってあなたの計算タスクを分散処理でき、そのコストは自前でサーバーを借りるよりも安くなるかもしれません。しかし、ここには信頼の問題があります。他人が返してきた計算結果が本当に正しいかどうか、あなたには確認できません。たとえば、非常に複雑な計算を私に依頼して報酬を支払ったとして、私が30分後に適当な結果を提出しても、あなたにはそれが正当なものかどうか検証できません。なぜなら、私は結果をでっち上げることも可能だからです。
しかし、もし私が「この計算結果が正しいこと」を証明できるならば、あなたは安心でき、より多くの計算タスクを私に委託するようになります。ZKは、信頼できないデータソースを信頼できるものに変える力を持っており、これにより低コストで非信頼な第三者の計算リソースを効率的に活用できます。
このシナリオには非常に大きな意味があり、アウトソーシング型のビジネスモデルを生み出す可能性があります。学術文献ではこれを「検証可能な計算(verifiable computation)」と呼び、計算そのものを信頼できるものにする試みです。また、ZKはデータベース分野にも応用可能です。ローカルでデータベースを運用するのは高コストなので、外部委託を検討するとしましょう。誰かが余剰なデータベースリソースを持っている場合、データをその人に預けられます。ただし、相手がデータを改ざんしていないか、SQLクエリの結果が正しいか心配になります。
このような場合、相手にProofを生成させることで、データの保管も外部委託しつつ、信頼できる結果を得ることが可能になります。これは前述の「検証可能な計算」と同様に、重要な応用領域です。
他にも多くの応用例があります。たとえば、「Verifiable ASIC(検証可能なASIC)」という論文もありました。チップ製造時にZKアルゴリズムをチップに組み込み、プログラム実行時に自動的にProofを付与するようにします。これにより、あらゆるデバイスが信頼できる結果を出力できるようになります。
もう一つ少し突飛な応用例が「Photo Proof(写真の証明)」です。多くの画像がPhotoshopなどで加工されているか分からない場合、ZKを用いて「この写真は改ざんされていない」と証明できます。カメラアプリに設定を追加し、撮影時に自動的にデジタル署名を生成すれば、その写真に「印鑑」が押された状態になります。誰かがあなたの写真を改変して「二次創作」を行っても、署名の検証によって改ざんが判別できます。
ここでZKを導入すれば、元画像に対して回転や移動などのわずかな変更を行ったとしても、「オリジナルの内容は改ざんしていない」と証明できます。つまり、微調整後の画像とオリジナルが基本的に同一であることを示すことで、「核心的な内容を改ざんして二次創作していない」ことを証明できるのです。
この概念は動画や音声にも拡張可能です。ZKを使えば、元の動画に対してどのような変更を加えたかを明かさずに、「コアコンテンツを改ざんしていない」ことを証明できます。無害な調整だけを行ったことを証明できるのです。他にも面白い応用例が多数あり、ZKは広い分野に足を踏み入れることができます。
現在、ZKの応用が広く受け入れられていない主な理由は、コストが高すぎるためです。現存のZK証明生成方式では、任意の計算に対してリアルタイムに証明を生成することはまだ不可能です。なぜなら、ZKのオーバーヘッドは通常、元の計算の100〜1000倍程度かかるからです。もちろん、これはすでにかなり最適化された数値です。
想像してみてください。ある計算に本来1時間かかる場合、ZK証明を生成するとオーバーヘッドが100倍となり、100時間もかかってしまいます。GPUやASICを用いて時間を短縮することも可能ですが、それでも巨大な計算リソースを消費します。とても複雑な計算を要求され、しかもZK証明まで求められたら、私は断るでしょう。なぜなら、100倍の計算リソースを消費する必要があり、経済的に見合わないからです。従って、一対一のシナリオでは、単発のZK証明生成は非常に高価です。
しかし、ブロックチェーンにはZKが非常に適している理由があります。それは、ブロックチェーンが冗長な計算を行うため、多くの「1対多」のシナリオがあるからです。ブロックチェーンネットワーク内の異なるノードは同じ計算タスクを実行します。1万のノードがあれば、同じタスクが1万回実行されます。しかし、もしL2でタスクを完了し、ZK証明を生成してオンチェーンで検証するだけで済ませば、各ノードがタスクを再実行する必要はありません。つまり、1人の計算コストで、1万台のノードによる冗長計算のコストを置き換えることができ、全体としてはリソースの節約につながります。
したがって、ブロックチェーンがより非中央集権的であればあるほど、ZKとの相性は良くなります。なぜなら、誰でもほぼゼロコストでZKPを検証できるからです。初期の証明生成に一定のコストをかけることで、大多数のユーザーの負担を解放できるのです。これが、ブロックチェーンの公開検証性がZKと相性が良い理由です。ブロックチェーンには多くの「1対多」のシナリオがあるためです。
もう一つ指摘すべき点があります。現在ブロックチェーンで使われているオーバーヘッドの大きいZK証明はすべて非インタラクティブ式です。つまり、あるものを渡して証明を受け取り、それで終わりです。なぜなら、オンチェーンと何度もやり取りすることは現実的ではないからです。しかし、より効率的でオーバーヘッドの低い証明生成方法として、「インタラクティブ証明」があります。たとえば、相手がChallengeを送り、あなたが応答し、さらに相手が応答して…というように、双方が複数回やり取りすることで、ZKの計算量をさらに削減できる可能性があります。これが実現すれば、大規模なZK応用における証明生成の問題を解決できるかもしれません。
Nickqiao:zkML、つまりZKと機械学習の融合についての将来性をどう見ていますか?
YeZhang:zkMLも非常に興味深い方向性です。機械学習をZK化することができるのですが、個人的にはまだ「killer application(殺しのアプリケーション)」が不足していると感じます。ZKシステムのパフォーマンスが向上すれば、将来的にはMLレベルの応用が可能になると一般的に考えられています。現在、zkMLの効率はgpt2クラスのモデルをサポートできるレベルにまで達しており、技術的には可能ですが、推論(inference)に限られます。結局のところ、「いったい何のために推論プロセスの正しさを証明する必要があるのか?」という応用シナリオの探索がまだ続いています。これは非常に難しい問いです。
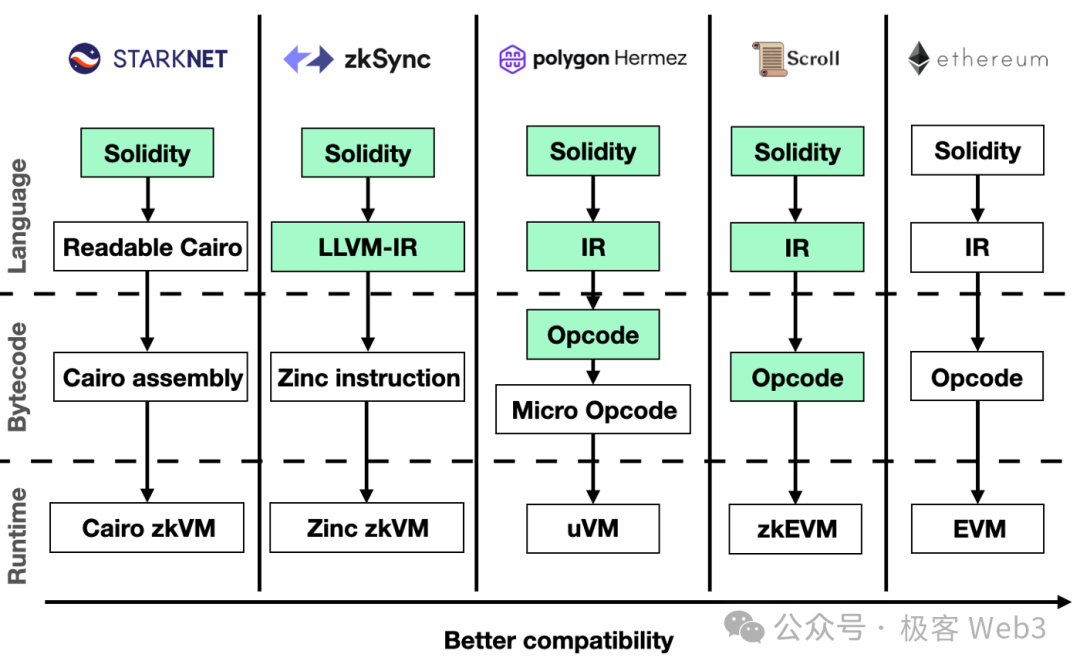
2.Nickqiao: それでは張燁先生にお尋ねします。zkEVMとzkVMの工学的実装難易度には、具体的にどれほどの差があるのでしょうか?
YeZhang:まず、zkEVMでもzkVMでも、本質的には特定の仮想マシンの操作コード/命令セットに対してカスタムのZK回路を構築することに変わりありません。zkEVMの工学的実装難易度は、その実現方法に大きく依存します。プロジェクトを始めた当初、ZKの効率はまだ十分ではなく、EVMの各操作コードごとに専用の回路を作成し、それを組み合わせてカスタムzkEVMを構築することが最も効率的な方法でした。
しかし、この方式の工学的実装難易度は非常に高く、zkVMよりもはるかに困難です。なぜなら、EVMの命令セットには100を超える操作コードがあり、それぞれに専用の回路を設計し、それを統合しなければならないからです。EIPによってEVMに新しい操作コードが追加されるたびに(例:EIP-4844)、zkEVM側でもそれに応じた対応が必要になります。最終的には非常に長い回路を記述し、綿密な監査を行う必要があり、開発の難易度と作業量はzkVMとは比較にならないほど大きくなります。
一方で、zkVMは独自の命令セット/操作コードを定義しており、それを極めてシンプルかつZKフレンドリーに設計できます。一度zkVMを構築すれば、底層コードを頻繁に変更せずに、さまざまなアップグレードやプリコンパイルに対応できます。したがって、zkVMの主な作業量と今後のアップグレード・メンテナンスの難易度は、「スマートコントラクトをzkVMの操作コードに変換する」コンパイラ部分に集中しており、これはzkEVMとは大きく異なります。
したがって、工学的難易度から見ると、zkVMの方がカスタムzkEVMよりも実装が容易だと考えます。ただし、zkVM上でEVMを実行する場合、全体的なパフォーマンスはカスタムzkEVMよりも大幅に劣ります。なぜなら、後者は専用に最適化されているからです。しかし、過去2年間でProverの証明生成効率は少なくとも3〜5倍、場合によっては5〜10倍も向上しており、zkVMの効率もそれに伴って向上しています。現在、zkVMでEVMを実行する場合の全体的な効率も徐々に改善されています。将来的には、zkVMのパフォーマンス上の不利が、開発・保守の容易さという利点に覆される可能性があります。いずれにせよ、zkVMとzkEVMにとって、パフォーマンス以外の最大のボトルネックは開発難易度であり、非常に強力なエンジニアリングチームがなければ、こうした複雑なシステムを維持することはできません。
3.Nickqiao: ScrollがzkEVMの実用化にあたって、技術的な課題に直面したことはありますか?また、どのように解決しましたか?
YeZhang:プロジェクトを進めてきた中で、最大の挑戦はやはり、プロジェクト開始時の不確実性が非常に大きかったことです。我々がプロジェクトを始めた時点では、ほとんど他にzkEVMに取り組んでいるチームはおらず、不可能と思われていたことを可能にする最初のチームの一つでした。理論的には、プロジェクト開始後6ヶ月ほどで実現可能な枠組みがほぼ確立されました。しかし、その後の実装段階では、zkEVMの工学的作業量が非常に大きく、いくつか非常に技術的な課題がありました。たとえば、異なるPre-Compile(プリコンパイル)を動的にサポートする方法や、操作コード(opcode)をより効率的に集約する方法など、多くの工学的課題がありました。
また、我々はEC Pairing(楕円曲線ペアリング)というプリコンパイルをサポートする唯一かつ最初のチームでもありました。ペアリングのような回路は実装が非常に難しく、数学的な知識や暗号学の素養、そして高い工学的能力が要求されます。
後期の発展段階では、技術スタックの長期的なメンテナンス性や、いつ、どのようなタイミングで次世代zkEVM 2.0にアップグレードするかという点も考慮しなければなりません。我々には専門の研究チームがあり、zkVM方式でEVMをサポートするようなスキームを常に研究しています。これに関する論文も執筆しています。
まとめると、これまでの難関は「不可能を可能にする」ことにあり、主に工学的実装と最適化の課題に直面していました。次の段階では、いつ、どのような具体的な方法でより効率的なZK証明システムに移行するか、現在のコードベースを次世代zkEVMにどのように移行するか、そして次世代zkEVMがどのような新機能を提供できるかという点に大きな挑戦があります。ここにはまだ大きな探求の余地があります。
4.Nickqiao: 聞く限り、Scrollは他のZK証明システムへの移行を検討しているようですね。私の知る限り、現在ScrollはPLONK+Lookupに基づくアルゴリズムを使用していますが、このアルゴリズムは現在zkEVMやzkVMの実装に最も適しているのでしょうか?また、今後Scrollはどのような証明システムに切り替える予定ですか?
YeZhang:まず、PLONKとLookupについて簡単に説明します。現在のところ、この組み合わせはzkEVMやzkVMの実装に最も適したシステムです。ほとんどの実装は特定のPLONKとLookupに強く結びついています。一般にPLONKと言えば、PLONKのarithmetic化(算術表現方式)を用いてzkVMの回路を記述することを意味します。
Lookupは回路記述時に使用される一種の制約タイプです。したがって、「PLONK + Lookup」というのは、zkEVMやzkVMの回路を書く際にPLONKの制約形式を使用することを意味し、これが現在最も一般的な手法です。
バックエンドに関しては、PLONKとSTARKの境界は曖昧になってきており、どちらも異なる多項式コミットメント方式を使用しているだけで、実際にはよく似ています。STARK + Lookupの組み合わせであっても、PLONK + Lookupと本質的に同じです。人々が注目するのはアルゴリズム自体であり、両者の違いは主にProverの効率や証明サイズなどに現れます。当然ながら、フロントエンドの観点からは、zkEVMの実装にはPLONK + Lookupが最も適しています。
2つ目の質問、つまりScrollが将来どのような証明システムに移行するかについてです。Scrollの目的は、常に自社の技術とチェーンの枠組みをZK分野の最先端に保つことです。そのため、最新の技術を取り入れることは当然です。しかし、セキュリティと安定性を最優先とするため、ZK証明システムを過度に急激に切り替えることはしません。まずはMulti Proverなどを通じて段階的に移行し、徐々に次のバージョンへのアップグレードを進めます。要するに、スムーズな移行プロセスを確保することが重要です。
ただ、現時点では新しい証明システムへの移行はまだ早い段階です。これはおそらく今後6ヶ月から1年の次のフェーズでの話になります。
5.Nickqiao: Scrollは現在のPLONKおよびLookupに基づく証明システムに対して、独自の革新を加えていますか?
YeZhang: 現在Scrollのメインネットで稼働しているのはhalo2です。halo2はもともとZcashプロジェクトチームが開発したもので、Lookupをサポートし、柔軟な回路フォーマットを記述できるバックエンドシステムです。その後、我々はEthereumのPSEチームと共同でhalo2を改造し、多項式コミットメント方式をIPAからKZGに変更しました。これにより証明サイズが小さくなり、Ethereum上でのZK証明の検証がより効率的になりました。
また、GPUハードウェアアクセラレーションにも多くの取り組みを行い、CPUでZKPを生成する場合と比べて5〜10倍の速度向上を実現しました。総合的に言えば、我々はオリジナルのhalo2の多項式コミットメント方式を、検証が容易なバージョンに置き換え、Proverの最適化にも多くの努力を重ね、工学的実装に大きく貢献しました。

6.Nickqiao: つまり、Scrollは現在Ethereum PSEチームと共同でKZG版halo2をメンテナンスしているわけですね。では、PSEチームとの協業の具体的なやり方を教えていただけますか?
YeZhang:プロジェクト開始前から、すでにPSEチームのエンジニアとは知り合いでした。私たちがzkEVMを作りたいと話したとき、彼らも同様のことを考えており、ちょうど同じタイミングで意思が一致しました。
したがって、我々はEthereumコミュニティ、特にEthereum Researchを通じて、zkEVMの実用化を目指す仲間たちと出会い、共にオープンソースの協業モードを自然に始めました。Ethereumに貢献したいという思いも共有していました。この協業スタイルは、商用企業よりもむしろオープンソースコミュニティに近いものです。たとえば、毎週定期的に電話会議を開き、進捗状況や課題を共有しています。
この方法でコードをオープンソースとしてメンテナンスしており、halo2の改良からzkEVMの実装まで、多くの探索を経てきました。お互いにコードレビューも積極的に行っています。Githubのコード貢献量を見ても、PSEチームが半分、Scrollが半分ほどを書いており、その後コードの監査を完了し、実際に製品化され、メインネットで稼働しているコードを完成させました。まとめると、我々とEthereum PSEの協業は、まさにオープンソースコミュニティ的な、自発的な形態だと言えます。
7.Nickqiao: 先ほども言われましたが、zkEVMの回路作成には高度な数学と暗号学の知識が必要で、zkEVMを深く理解できる人はごく少数だと思います。Scrollはどのようにして回路の正確性を保証し、バグを最小限に抑えているのでしょうか?
YeZhang:我々のコードはオープンソースであるため、すべてのPRに対して、Scrollのメンバーだけでなく、Ethereum関係者やコミュニティの参加者がレビューを行い、厳格な監査プロセスを採用しています。また、回路監査には100万ドル以上を投資し、Trail of BitsやZellicなど、業界で最も専門的な暗号学・回路監査機関に依頼しています。スマートコントラクト部分についてはopenzeppelinに監査を依頼しており、セキュリティに関わるすべての要素に最高レベルの監査リソースを投入しています。内部には専任のセキュリティチームもおり、継続的にScrollの安全性を高めています。
Nickqiao: このような監査方法以外に、形式的検証など、数学的により厳密な方法はありますか?
YeZhang:我々は以前からFormal Verification(形式的検証)の方向性を検討しており、Ethereum側でも最近zkEVMに対する形式的検証の方法を模索しています。これは非常に有望な方向性です。しかし、現時点ではzkEVM全体に対する完全な形式的検証は時期尚早であり、小さなモジュールから徐々に取り組む必要があります。なぜなら、Formal Verification自体にもコストがかかり、コードに対してFormal Verificationを実行するには、まず仕様(spec)を記述する必要がありますが、この仕様の作成自体が非常に困難であり、整備には長い時間がかかります。
したがって、現時点ではzkEVM全体に形式的検証を行う段階には至っていないと考えています。しかし、引き続きEthereumをはじめとする外部の協力者と連携し、zkEVMの形式的検証の方法を積極的に探求していきます。
現時点では、最も効果的な方法は依然として人手による監査です。なぜなら、仮に仕様とFormal Verificationがあったとしても、仕様そのものが間違っていたら問題が発生してしまうからです。したがって、現時点では人手による監査と、オープンソース、バグ報奨金制度を通じて、Scrollのコードの安定性を確保するのが最善だと考えています。
しかし、次世代zkEVMにおいては、いかに形式的検証を実施し、より良くspecを記述できるzkEVMを設計し、形式的検証によってその安全性を証明するかが、Ethereumの究極の目標となっています。つまり、zkEVMが形式的検証された後には、それをEthereumメインネットに本格導入することを完全に安心して行えるようになるのです。

8.Nickqiao: Scrollが採用しているhalo2について、STARKなどの新しい証明システムをサポートしようとすると、開発コストは非常に大きくなりますか?複数の証明システムを同時にサポートできるプラグイン型のアーキテクチャは実現可能でしょうか?
YeZhang: halo2は非常にモジュール化されたZK証明システムであり、フィールドや多項式コミットメントなどを交換可能です。KZGの代わりにFRIを使うように変更すれば、基本的にはhalo2版のSTARKを実現できます。実際、すでにそれを実現している人もいます。したがって、halo2がSTARKをサポートすることは、技術的にまったく問題ありません。
しかし、実際の実装では、究極の効率を追求する場合、モジュール化が進むほど若干の効率低下が生じる可能性があります。なぜなら、モジュール化のためにカスタマイズ性を犠牲にしており、何らかのトレードオフが生じるからです。我々は今後、モジュール化されたフレームワークと高度にカスタマイズされたフレームワークのどちらが望ましいかを継続的に検討しています。特に、我々は十分に強力なZK開発チームを持っているため、独立した証明体系を維持し、zkEVMをより効率的にすることも可能です。もちろん、これらはトレードオフの問題ですが、halo2自体はFRIをサポートしています。
9.Nickqiao: 現在、ScrollのZK分野における主な開発重点は何ですか?現在のアルゴリズムの最適化や、新しい機能の追加などでしょうか?
YeZhang:我々のエンジニアリングチームの中心的な取り組みは、現在のProverのパフォーマンスをさらに2倍に向上させること、そしてEVM互換性を最高峰にすることです。次のアップグレードでは、ZK Rollupの中で最もEVM互換性が高いという地位を維持し続けます。現在、他のすべてのzkEVMは私たちの互換性を超えているとは言えません。
これがScrollのエンジニアリングチームが取り組んでいる一つの柱であり、ProverとCompatibilityのさらなる最適化、および費用の削減です。すでに次世代zkEVMの研究に多くの人員を投入しており、およそ半分のエンジニアリングリソースを割いています。これにより、数分または数秒レベルでのZK証明生成を実現し、Proverの効率を高めることを目指しています。
同時に、新たなzkEVM実行レイヤーの探索も進めています。従来のノードにはgo-ethereumを使用していましたが、現在では性能がより優れたRust版Ethereumクライアント「Reth」があります。そこで我々は、次世代zkEVMとRethクライアントをどのようにより良く統合できるかを研究しています。これにより、チェーン全体のパフォーマンスを向上させることが可能になります。新しい実行レイヤーを基盤とした場合、どのような実装方式と移行方法が最適かを検討しています。
10.Nickqiao: それでは、Scrollが多様な証明システムをサポートする場合、チェーン上に複数のVerifierコントラクトを実装する必要があるでしょうか?例えば、相互検証を行うような形です。
YeZhang:これは二つの問題があります。まず一つ目は、モジュール化された証明システムや多様なProverを導入する意義があるかどうかです。これは意味のあることです。なぜなら、我々は常にオープンソースプロジェクトだからです。公開するフレームワークが汎用的であればあるほど、より多くの人が「車輪の再発明」をしてくれ、コミュニティも自然と大きくなります。将来的には、プロジェクト開発やツール利用において外部の力を活用しやすくなります。したがって、Scroll自身だけでなく、他の人々にも使えるZK証明フレームワークを作ることは非常に有意義です。
二つ目の問題は、メインネット上で相互検証を行う必要があるかということです。これは証明システム自体が多様化しているか、STARKやPLONKをサポートしているかという問題とは独立しています。同じzkEVMをPLONKで検証した後、さらにSTARKで検証するようなプロジェクトはほとんどありません。なぜなら、セキュリティの向上にほとんど寄与せず、Proverのコストが高くなるからです。そのため、通常はこのような相互検証は行われません。
我々が実際に取り組んでいるのは「Multi Prover」です。二つのProverが同じブロックを証明し、チェーン外で二つの証明をまとめてからオンチェーンで検証します。したがって、チェーン上でSTARKとSNARKの相互検証を行うことはありません。我々のMulti Prover方式は、あるProverのコードに問題が発生した場合に、別のコードがフォールバックできるようにするためのものです。つまり、一方のシステムにバグがあっても、他方が正常に動作することで、全体の安定性を確保します。これは相互検証とは別の話題です。
11.Nickqiao: ScrollのMulti Proverでは、各Proverが実行する証明プログラムにどのような違いがありますか?
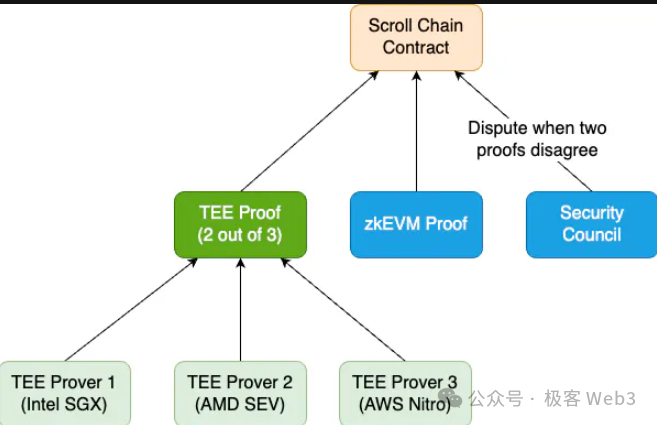
YeZhang:まず、標準的なhalo2で記述されたzkEVMがあり、通常のProverがZKPを生成してオンチェーンで検証されるケースを想定します。しかし、zkEVMは非常に複雑であり、バグが発生する可能性があります。もしバグが存在し、ハッカーまたはプロジェクト側がそのバグを利用して証明を生成し、全員の資金を引き出せてしまうような事態は明らかに好ましくありません。
Multi Proverの核心的なアイデアは、VitalikがBogotaイベントで初めて提唱したものです。つまり、zkEVMにバグが発生する可能性があるなら、異なる種類のProverを並列に走らせればよいという考え方です。たとえば、TEE(SGXベース)のProver(Scrollは現在これを採用)、OPベースのProver、あるいはzkVM上でEVMを実行するProverなどです。とにかく、これらのProverが同時にL2ブロックの有効性を証明します。
たとえば3種類の異なるProverがある場合、3つの異なる証明がすべて検証に合格するか、または3つのうち少なくとも2つが合格した場合にのみ、Ethereum上でL2の最終状態を確定できます。Multi Proverは、あるProverに問題が発生した場合でも、他の2つのProverがカバーできるため、Proverシステム全体の安定性が高まり、ZK Rollupのセキュリティが向上します。もちろん、これにはProver全体の運営コストが上がるという欠点もあります。これについては専門のブログ記事で詳しく紹介しています。
12.Nickqiao: それでは、ScrollのZK証明生成における「証明生成ネットワーク(ZKマイニングプール)」はどのように構築されているのでしょうか?自社で運営しているのか、それともCysicのような第三者に計算を外部委託しているのでしょうか?
YeZhang:現時点では、設計は非常にシンプルです。より多くのGPU保有者やマイナーに証明ネットワーク(ZKマイニングプール)に参加してもらいたいと考えています。しかし、現状ではScrollのProver Marketは自社で運営しており、GPUクラスターを持つ第三者と協力してProverを実行しています。これはメインネットの安定性のためです。なぜなら、Proverを非中央集権化すると、さまざまな問題が発生する可能性があるからです。
たとえば、インセンティブメカニズムがうまく設計されていない場合、誰も証明を生成しなくなれば、ネットワークのパフォーマンスに影響が出てしまいます。初期段階では、比較的中央集権的な方式を採用していますが、インターフェースやフレームワークの設計は、非中央集権化への移行が非常に容易になっています。誰でも我々の技術フレームワークを使って非中央集権化されたProverネットワークを構築でき、インセンティブを追加するだけで済みます。
しかし現時点では、Scrollの安定性を確保するために、Prover生成ネットワークは中央集権的になっています。今後、Proverネットワークをより広範に非中央集権化していく予定です。誰でも独自のProverノードを運営できるようにします。また、CysicやSnarkify networkといったサードパーティプラットフォームとも協力しており、誰かが我々の技術スタックを使って独自のL2を立ち上げたい場合、サードパーティのProver Marketに接続して、直接Proverサービスを利用できるようにすることを検討しています。
<
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














