

Galaxy Digital:暗号資産と人工知能の交点を理解する
TechFlow厳選深潮セレクト
Galaxy Digital:暗号資産と人工知能の交点を理解する
パブリックブロックチェーンの登場は、コンピュータ科学の歴史の中で最も深い進歩の一つであり、人工知能の発展は、すでにそしてこれからも、私たちの世界に深远な影響を与えるだろう。
翻訳:Block unicorn
序論
パブリックブロックチェーンの登場は、コンピュータ科学史上で最も画期的な進歩の一つである。一方で人工知能(AI)の発展も、すでに世界に深遠な影響を与えている。ブロックチェーン技術が取引決済、データ保存、システム設計に新たなテンプレートを提供するならば、AIは計算、分析、コンテンツ配信の分野における革命である。これらの分野での革新は新しいユースケースを解放し、今後数年間で両者の採用を加速させる可能性がある。本レポートでは、暗号資産とAIの継続的な統合について考察し、そのギャップを埋め、双方の力を活用する新規ユースケースに注目する。具体的には、分散型コンピューティングプロトコル、ゼロナレッジ機械学習(zkML)インフラ、AIエージェントの開発プロジェクトを調査する。
暗号資産は、許可不要・信頼不要かつ組み合わせ可能な決済レイヤーをAIに提供する。これにより、分散型コンピューティングを通じてハードウェアへのアクセスが容易になり、価値交換を伴う複雑なタスクを実行できるAIエージェントの構築、Sybil攻撃やディープフェイクに対抗するためのアイデンティティおよび出所追跡ソリューションの開発といったユースケースが可能になる。AIは、Web2で見られるのと同じ利点を暗号資産にもたらす。これには、大規模言語モデル(専門的に訓練されたChatGPTやCopilotなど)によるユーザーおよび開発者のUX向上、スマートコントラクトの機能性と自動化の可能性の大幅な改善が含まれる。ブロックチェーンは、AIに必要な透明性のあるデータ豊富な環境である。しかし、ブロックチェーンの計算能力には制限があり、これがAIモデルを直接統合する主な障壁となっている。
暗号資産とAIの交差点における実験と最終的な採用の背後にある駆動力は、暗号資産において最も有望なユースケースを推進しているものと同じである――すなわち、許可不要で信頼不要な調整層へのアクセスを通じて、価値移転をより効果的に促進すること。巨大な潜在力が見込まれるこの分野では、関係者が両技術の統合方法の基本を理解することが不可欠である。
要点:
-
近い将来(6ヶ月~1年)、暗号資産とAIの統合は、開発者効率、スマートコントラクトの監査性・安全性、ユーザーのアクセシビリティを高めるAIアプリケーションによって主導される。これらの統合は暗号資産特有ではないが、オンチェーン開発者とユーザー体験を強化する。
-
高性能GPUの深刻な不足と同様に、分散型コンピューティング製品はAI向けGPU製品を導入しており、採用を後押ししている。
-
ユーザーエクスペリエンスと規制は、分散型コンピューティングの顧客獲得の障壁である。しかし、OpenAIの最新の発展や米国での規制審査の進行は、許可不要・検閲耐性・分散型AIネットワークの価値提案を浮き彫りにしている。
-
オンチェーンAI統合、特にAIモデルを使用できるスマートコントラクトは、zkML技術や他のオフチェーン計算検証手法の改善を必要とする。包括的なツールや開発人材の不足、コストの高さが採用の障害となっている。
-
AIエージェントは暗号資産に適しており、ユーザー(またはエージェント自体)がウォレットを作成し、他のサービス、エージェント、人物と取引できる。これは従来の金融インフラでは不可能である。より広範な採用には、非暗号製品とのさらなる統合が必要である。
用語解説
人工知能(AI)とは、計算と機械を用いて人間の推論や問題解決能力を模倣すること。
ニューラルネットワークはAIモデルの一種の訓練方法。入力を離散的なアルゴリズム層で処理し、改良を重ねて所望の出力を得る。ニューラルネットワークは重み付きの方程式からなり、重みを変更することで出力を調整できる。正確な出力を得るには大量のデータと計算資源を要する。これはAIモデル開発の最も一般的な方法の一つ(ChatGPTはTransformerに基づくニューラルネットワークプロセスを使用)。
トレーニングとは、ニューラルネットワークやその他のAIモデルを開発するプロセス。モデルが入力を正しく解釈し、正確な出力を生成できるよう大量のデータで訓練する。トレーニング中、モデル方程式の重みは満足のいく出力が得られるまで繰り返し修正される。費用は非常に高額になることがある。例えば、ChatGPTは数万の自社GPUでデータ処理を行っている。リソースが限られるチームは通常、Amazon Web Services、Azure、Google Cloudなどの専門的コンピューティングプロバイダーに依存している。
推論(Inference)とは、AIモデルを実際に使用して出力や結果を得ること(例:ChatGPTを使って暗号資産とAIの交差点に関する論文のアウトライン作成)。トレーニングプロセス全体と最終製品の両方で使用される。計算コストのため、トレーニング完了後も運用コストは高いが、トレーニングほど計算負荷は高くない。
ゼロナレッジ証明(ZKP)は、基礎情報を開示せずに主張を検証できる仕組み。暗号資産では主に2つの理由で有用:1) プライバシー 2) スケーリング。プライバシー保護では、財布にいくらETHがあるかといった機微情報を開示せず取引できる。スケーリングでは、オフチェーン計算を再実行するより速くオンチェーンで証明できる。これにより、ブロックチェーンやアプリケーションが安価にオフチェーンで計算を行い、その後オンチェーンで検証できる。ゼロナレッジとEthereum Virtual Machine(EVM)における役割の詳細については、Christine Kimのレポート「zkEVMs:イーサリアムのスケーラビリティの未来」を参照。
AI/暗号資産マーケットマップ

AIと暗号資産の統合プロジェクトは、大規模なオンチェーンAI相互作用に必要な基盤インフラの構築を続けている。
分散型コンピューティング市場は、AIモデルのトレーニングと推論に必要な膨大な物理ハードウェア(主にGPU)を提供するために台頭している。これらの双方向市場は、コンピューティングの賃貸と借り手を結びつけ、価値移転と計算検証を促進する。分散型コンピューティングでは、付加機能を提供するいくつかのサブカテゴリーが現れている。双方向市場に加え、本レポートでは検証可能なトレーニングとファインチューニング出力を専門に提供する機械学習トレーニングプロバイダー、およびコンピューティングとモデル生成を接続してAIを実現するプロジェクト(しばしばスマートインセンティブネットワークとも呼ばれる)を検討する。
十分な計算供給とオンチェーン計算検証能力は、オンチェーンAIエージェントの扉を開く。エージェントとは、ユーザーに代わって要求を実行できるように訓練されたモデル。エージェントは、ユーザーがチャットボットと会話するだけで複雑な取引を実行できるよう、オンチェーン体験を著しく強化する機会を提供する。しかし現時点では、エージェントプロジェクトはインフラとツールの開発に集中しており、迅速かつ容易な展開を目指している。
分散型コンピューティング
概要
AIはモデルのトレーニングと推論に大量の計算を必要とする。過去10年間、モデルがますます複雑化するにつれ、計算ニーズは指数関数的に増加した。たとえば、OpenAIは2012年から2018年にかけて、モデルの計算ニーズが2年ごとに倍増から3.5か月ごとに倍増へと加速したと報告している。これによりGPU需要が急増し、一部の暗号資産マイナーはクラウドコンピューティングサービスにGPUを転用している。計算アクセス競争の激化とコスト上昇に伴い、一部のプロジェクトは暗号技術を活用して分散型コンピューティングソリューションを提供している。彼らは競争力のある価格でオンデマンド計算を提供し、チームが経済的にモデルをトレーニング・運用できるようにする。場合によっては、性能とセキュリティのトレードオフが生じる。
最先端のGPU(Nvidia製など)は需要が非常に高い。9月、Tetherはドイツのビットコイン鉱業者Northern Dataの株式を取得し、報道によると4億2000万ドルを投じて1万台のH100 GPU(AIトレーニング用の最先端GPUの一つ)を購入した。一流ハードウェアの入手待ち時間は最低でも6ヶ月、多くの場合それ以上となる。さらに悪いことに、企業は使用しないかもしれない計算量に対して長期契約を結ぶことがよくある。これにより、利用可能な計算があっても市場で入手できない状況が生じる。分散型コンピューティングシステムはこうした市場の非効率を解決し、所有者が通知を受けた直後に余剰容量を再レンタルできる二次市場を創出し、新たな供給を解放する。
競争力のある価格とアクセシビリティに加え、分散型コンピューティングの重要な価値提案は検閲耐性である。最先端AI開発は、並外れた計算・データアクセス能力を持つ大手テック企業に支配されつつある。2023年のAIインデックス年次報告書で強調された最初の主要テーマは、産業界がAIモデル開発において学術界をますます凌駕しており、少数の技術リーダーにコントロールが集中していることだ。これにより、彼らがAIモデルの基盤となる規範や価値観の策定に大きな影響力を行使できるかどうかという懸念が生じる。特に、彼らが自身が制御できないAI開発を制限する規制を推進した後はなおさらである。
分散型コンピューティングの垂直領域
近年、それぞれ独自の重点とトレードオフを持つ複数の分散型コンピューティングモデルが登場した。

汎用コンピューティング
Akash、io.net、iExec、Cudosなどのプロジェクトは、分散型コンピューティングの応用であり、データと汎用計算ソリューションに加えて、AIトレーニング・推論用の専用計算へのアクセスを提供または提供予定である。
Akashは現在唯一完全オープンソースの「スーパークラウド」プラットフォーム。Cosmos SDKを使用するプルーフオブステークネットワークである。AKTはAkashのネイティブトークンで、支払い手段として、ネットワークのセキュリティ保護と参加のインセンティブに使用される。Akashは2020年に初のメインネットをリリースし、許可不要なクラウドコンピューティング市場を提供することに焦点を当て、当初はストレージとCPUレンタルサービスを特色とした。2023年6月、AkashはGPUに特化した新しいテストネットをリリースし、9月にはGPUメインネットを立ち上げ、ユーザーがAIトレーニング・推論のためにGPUをレンタルできるようになった。
Akashエコシステムには2つの主要参加者――テナントとプロバイダーがいる。テナントは計算リソースを購入したいAkashネットワークのユーザー。プロバイダーは計算の提供者。テナントとプロバイダーのマッチングには、逆オクションプロセスを採用。テナントは計算要件を提出し、サーバーの位置や使用するハードウェアタイプ、支払意欲額などを指定できる。その後、プロバイダーが希望価格を提示し、最低入札者がタスクを獲得する。
Akashバリデータはネットワークの整合性を維持する。バリデータセットは現在100に制限されており、将来的に段階的に増加予定。誰でも、現在ステーキングされているAKT量が最少のバリデータより多いAKTをステーキングすることでバリデータになれる。AKT保有者はバリデータにAKTを委任することもできる。ネットワークの取引手数料とブロック報酬はAKTで分配される。また、各レンタルに対して、Akashネットワークはコミュニティが決定したレートで「課金手数料」を獲得し、それをAKT保有者に分配する。
二次市場
分散型コンピューティング市場は、既存の計算市場の非効率を埋めようとしている。供給制限により企業は必要以上の計算リソースを蓄積し、クラウドプロバイダーとの契約構造が顧客を長期契約に縛るため、継続的なアクセスが不要でも供給がさらに制限される。分散型コンピューティングプラットフォームは新たな供給を解放し、世界中の計算需要を持つ人が誰でもプロバイダーになれるようにする。
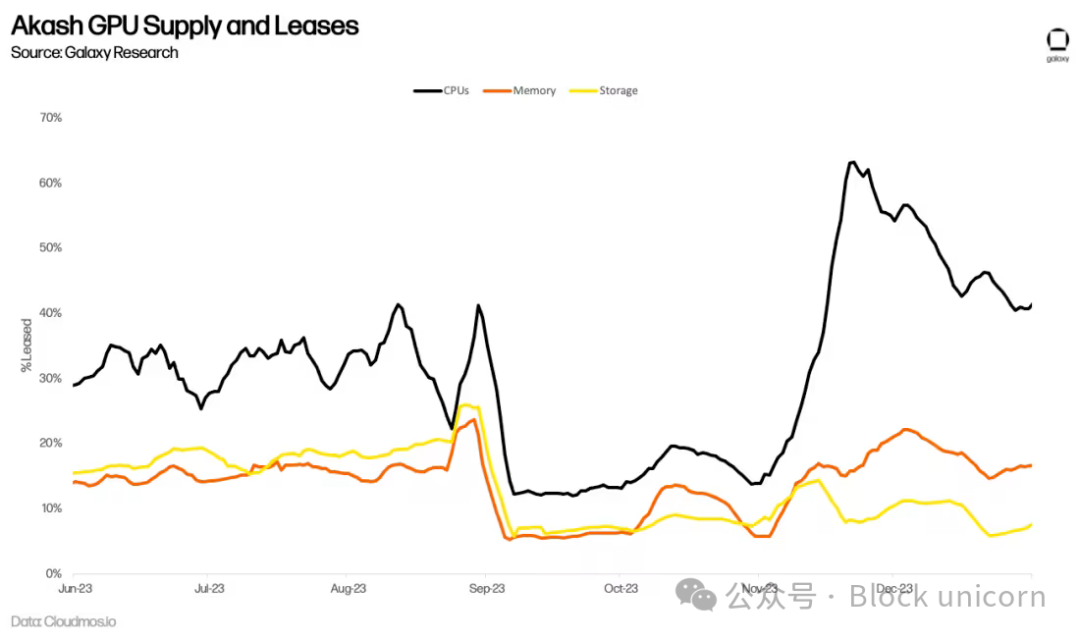
AIトレーニングによるGPU需要の急増が、Akash上の長期ネットワーク利用に転じるかどうかはまだ不明である。例えば、Akashは長年CPU市場を提供しており、集中型代替品と同等のサービスを70~80%の割引で提供している。しかし、低価格は顕著な採用をもたらしていない。ネットワーク上のアクティブなリースは横ばいとなり、2023年第2四半期には平均して計算の33%、メモリの16%、ストレージの13%にとどまっている。これらはオンチェーン採用の印象的な指標ではあるが(参考までに、主要ストレージプロバイダーFilecoinの2023年第3四半期のストレージ利用率は12.6%)、依然として需要を上回る供給があることを示している。
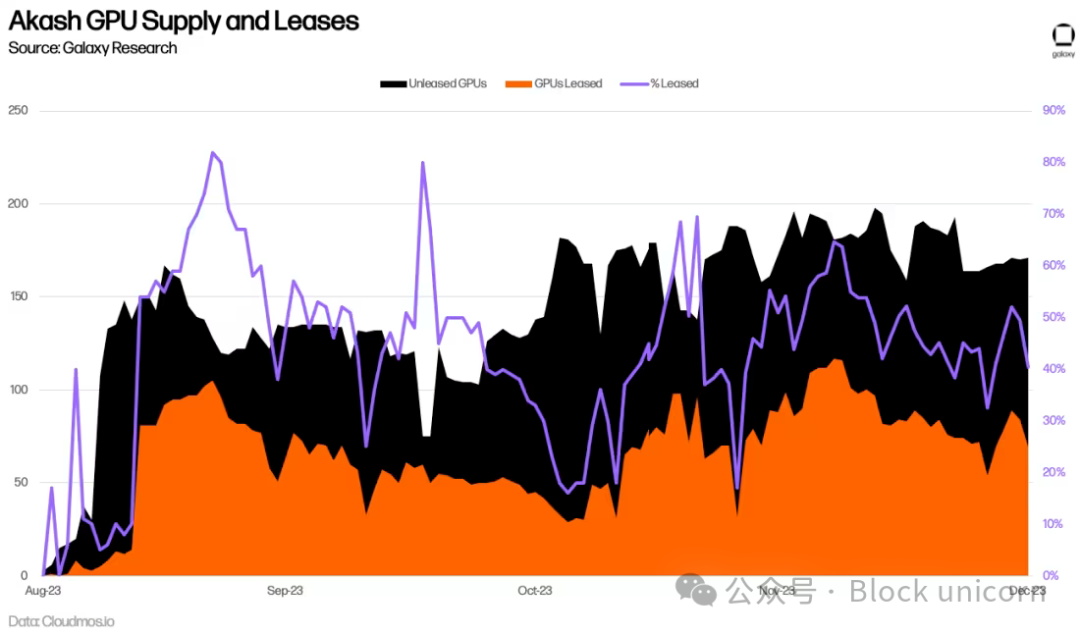
AkashのGPUネットワーク導入から半年以上が経過したが、長期的な採用率を正確に評価するには時期尚早である。これまでのところ、GPUの平均利用率は44%で、CPU、メモリ、ストレージを上回っており、これは需要の兆候である。これは主にA100のような最高品質GPUの需要によるもので、90%以上がレンタルされている。
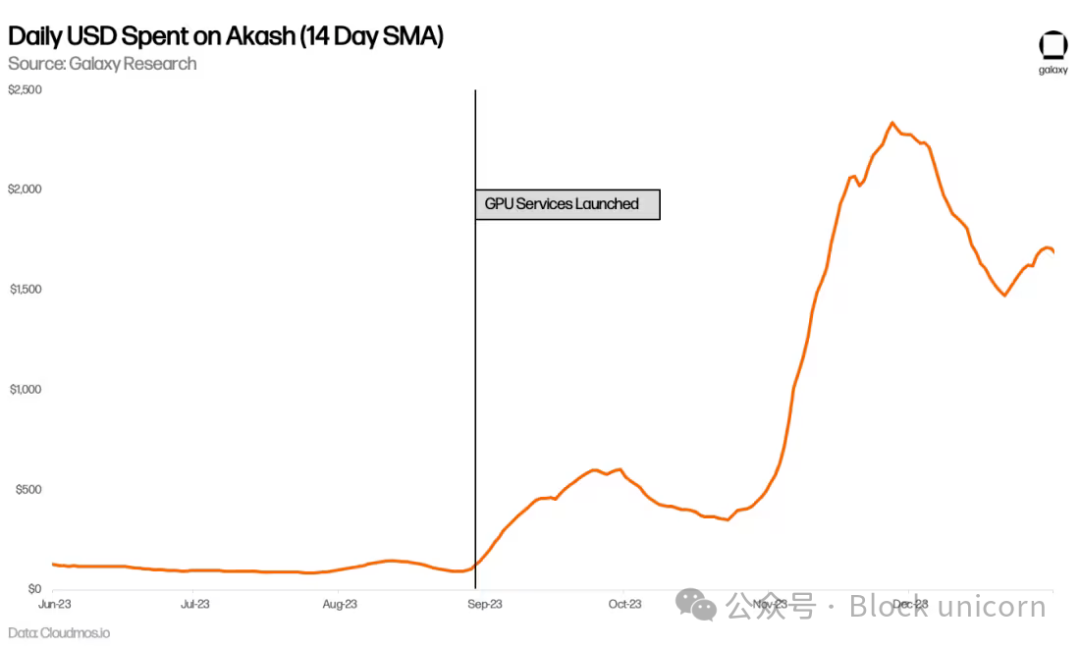
Akashの日次支出も増加しており、GPU登場前と比べてほぼ倍増した。これは他のサービス(特にCPU)の使用量増加にも起因するが、主に新しいGPU使用量の結果である。
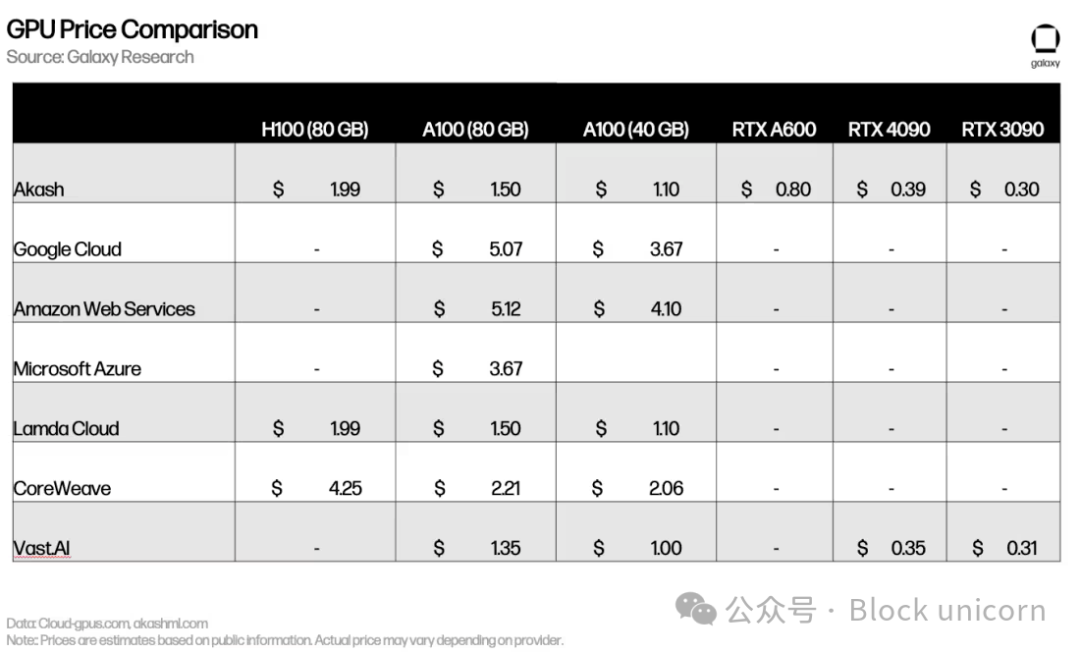
Lambda CloudやVast.aiなどの中央集権的競合他社と比較しても価格は相当(あるいは場合によってはそれ以上)。H100やA100のようなハイエンドGPUに対する巨大な需要は、ほとんどの所有者が競争的価格設定の市場に上場することにあまり関心がないことを意味している。
初期の利益はプラスだが、採用には依然障壁がある(以下でさらに議論)。分散型コンピューティングネットワークは需要と供給を生み出すためにさらに措置を講じる必要があり、チームは新規ユーザーをどう引きつけるか試行錯誤している。例えば、2024年初頭、Akashは第240号提案を通過させ、GPUプロバイダーのAKT排出量を増やして、特にハイエンドGPUへの供給を奨励した。また、概念実証モデルのリリースにも取り組んでおり、潜在的ユーザーにネットワークのリアルタイム機能を示している。Akashは独自のベースラインモデルのトレーニングを進め、Akash GPUで出力を生成できるチャットボットや画像生成製品をすでにリリースしている。同様に、io.netは安定拡散モデルを開発し、ネットワークのパフォーマンスとスケールをよりよく模倣する新しいネットワーク機能をリリースしている。
分散型機械学習トレーニング
AI関連ワークロードに計算を提供する汎用コンピューティングプラットフォームに加え、機械学習モデルトレーニングに特化したAI GPUプロバイダーのグループも台頭している。例えば、Gensynは「電力とハードウェアを調整して集団知能を構築する」ことを目指しており、「誰かが何かをトレーニングしたいと願い、誰かがそれをトレーニングしたいと思うなら、そのトレーニングは可能であるべきだ」という立場を取っている。
このプロトコルには4つの主要参加者――提出者、解決者、検証者、告発者がいる。提出者はトレーニングリクエストを含むタスクをネットワークに提出。これらのタスクにはトレーニング目標、トレーニング対象モデル、トレーニングデータが含まれる。提出プロセスの一環として、提出者は解決者が必要な推定計算量に応じて事前支払いを行う必要がある。
提出後、タスクはモデルの実際のトレーニングを行う解決者に割り当てられる。その後、解決者は完了したタスクを検証者に提出し、検証者はトレーニングが正しく行われたかを確認する責任を負う。告発者は検証者が誠実に行動しているかを確保する責任を負う。Gensynは告発者のネットワーク参加をインセンティブ化するため、定期的に故意に誤った証拠を提供し、告発者がそれを捕らえた場合に報酬を与える計画である。
AI関連ワークロードに計算を提供する以外に、Gensynの重要な価値提案はその検証システムにあるが、これはまだ開発中である。外部のGPUプロバイダーによる計算が正しく実行されているか(つまり、ユーザーのモデルが望む通りにトレーニングされているか)を保証するためには、検証が必要である。Gensynはこの問題を、「確率的学習証明、グラフベースの正確なプロトコル、Truebitスタイルのインセンティブゲーム」といった新奇な検証手法を利用して独自のアプローチで解決している。これは楽観的解決モードで、検証者がモデルを完全に再実行することなく、解決者がモデルを正しく実行したことを確認できる。これは高コストで非効率なプロセスである。
革新的な検証手法に加え、Gensynは中央集権的代替案や暗号通貨競合に比べて費用対効果が高いと主張している――AWSに比べて最大80%安いMLトレーニング価格を提供し、テストではTruebitなどの類似プロジェクトを上回っている。

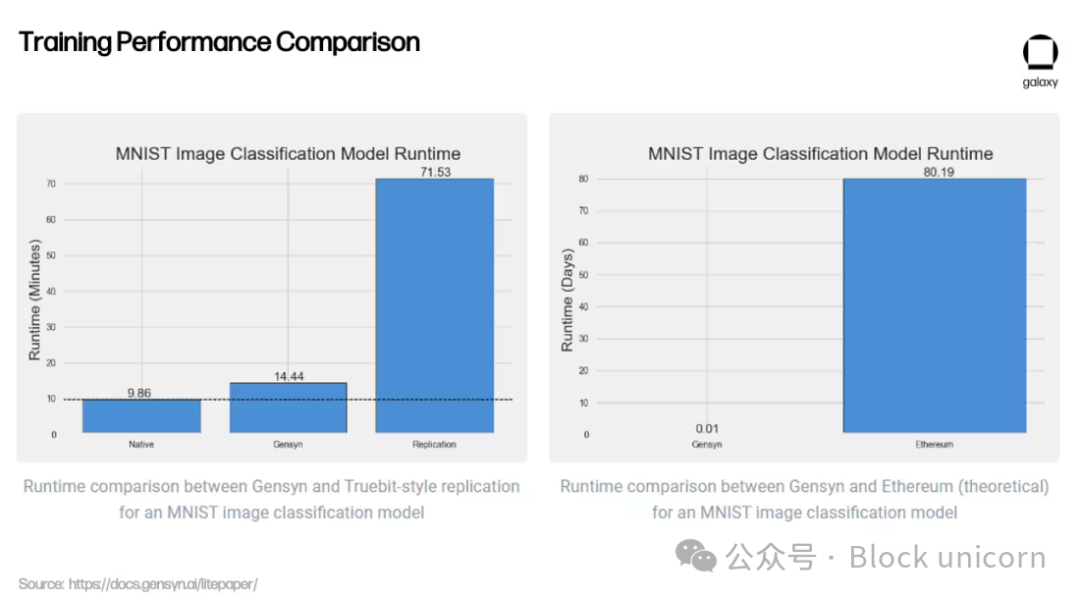
これらの初期結果が分散型ネットワークで大規模に再現可能かどうかはまだ不明である。Gensynは、小規模データセンター、個人ユーザー、将来は携帯電話などの小型モバイルデバイスといった供給者の余剰計算能力を活用したいと考えている。しかし、Gensynチーム自身が認めているように、異種コンピューティング供給者に依存することは、いくつかの新しい課題をもたらす。
Google CloudやCoreweaveなどの中央集権的プロバイダーにとって、計算コストは高く、計算間の通信(帯域幅と遅延)は安い。これらのシステムはハードウェア間の通信を最速で行うように設計されている。Gensynはこの枠組みを覆し、世界中の誰でもGPUを提供できるようにすることで計算コストを下げているが、同時にネットワークが距離の離れた異種ハードウェア上で計算ジョブを調整しなければならないため、通信コストが増加している。Gensynはまだリリースされていないが、分散型機械学習トレーニングプロトコル構築時に達成可能な可能性の概念実証である。
分散型一般知能
分散型コンピューティングプラットフォームは、AIの創造方法の設計にも可能性を提供している。BittensorはSubstrate上に構築された分散型コンピューティングプロトコルで、「我々はAIを協働的な方法にどう変えるか?」という問いに答えようとしている。Bittensorは、AI生成の分散化と商品化を目指している。このプロトコルは2021年に開始され、協働的機械学習モデルの力を活用して、継続的に反復し、より良いAIを生み出すことを目指している。
Bittensorはビットコインからインスピレーションを得ており、ネイティブ通貨TAOの供給量は2100万枚、半減周期は4年(初の半減は2025年予定)。Bittensorは、正しい乱数を生成してブロック報酬を得るプルーフオブワークではなく、「インテリジェンスプルーフ(Proof of Intelligence)」に依存し、マイナーが推論リクエストに応じて出力を生成するよう要求している。
インテリジェンスのインセンティブ
Bittensorは当初、混合専門家(MoE)モデルに依存して出力を生成していた。推論リクエストを提出すると、MoEモデルは汎用モデルに依存するのではなく、特定の入力タイプに対して最も正確なモデルにリクエストを転送する。家を建てる場合、施工過程のさまざまな側面を担当する専門家(建築家、エンジニア、塗装工、建設作業員など)を雇うようなもの。MoEはこれを機械学習モデルに適用し、入力に応じて異なるモデルの出力を活用しようとする。Bittensor創設者Ala Shaabanaが説明するように、「一人と話すよりも、賢い人たちが集まった部屋と話して最良の答えを得るようなもの」。しかし、正しいルーティング、メッセージの同期、インセンティブの確保に課題があるため、このアプローチはプロジェクトがさらに開発されるまで棚上げされている。
Bittensorネットワークには2つの主要参加者――検証者とマイナーがいる。検証者の任務はマイナーに推論リクエストを送り、出力を審査し、応答品質に基づいてランキングすること。自分のランキングが信頼できるようにするために、検証者は他の検証者のランキングとの一致度に応じて「vtrust」スコアを獲得する。「vtrust」スコアが高いほど、獲得するTAO排出量が多くなる。これは、時間とともにモデルランキングに関して合意に達するよう検証者をインセンティブ化するもので、ランキングに関して合意する検証者が多いほど、個々の「vtrust」スコアが高くなる。
マイナー、またはサーバーと呼ばれるのは、実際の機械学習モデルを実行するネットワーク参加者。マイナーは与えられたクエリに対して最も正確な出力を提供することで互いに競い合い、出力が正確であればあるほど、獲得するTAO排出量が多くなる。マイナーは自由にこれらの出力を生成できる。例えば、将来、BittensorマイナーがGensyn上でモデルをトレーニングし、それを使ってTAO排出量を獲得することもあり得る。
現在、ほとんどのやり取りは検証者とマイナーの間で直接行われる。検証者はマイナーにインプットを提出し、出力(つまりモデルトレーニング)をリクエスト。検証者がネットワーク上のマイナーにクエリを送り、応答を受け取ったら、マイナーをランキングし、そのランキングをネットワークに提出する。
検証者(PoS依存)とマイナー(モデルプルーフ依存、PoWの一種)のこのやり取りはYumaコンセンサスと呼ばれる。これは、マイナーが最高の出力を生み出してTAO排出量を獲得し、検証者がマイナー出力を正確にランキングしてより高いvtrustスコアを獲得し、TAO報酬を増やすことでネットワークのコンセンサスメカニズムを形成することを目的としている。
サブネットとアプリケーション
Bittensor上のやり取りは、主に検証者がマイナーにリクエストを提出し、その出力を評価することに集中している。しかし、貢献マイナーの質が向上し、ネットワーク全体のインテリジェンスが成長するにつれ、Bittensorは既存スタックの上にアプリケーション層を構築し、開発者がBittensorネットワークをクエリするアプリケーションを構築できるようにする。
2023年10月、BittensorはRevolutionアップグレードを通じてサブネットを導入し、この目標達成に向けた重要な一歩を踏み出した。サブネットは、特定の行動をインセンティブ化するBittensor上の独立したネットワーク。Revolutionは、サブネットを作成したい人全員にネットワークを開放した。リリース後数ヶ月で、テキストプロンプト、データスクレイピング、画像生成、ストレージ用など32以上のサブネットが立ち上がった。サブネットが成熟し製品準備ができれば、サブネット作成者はアプリケーション統合を構築し、チームが特定のサブネットをクエリするアプリケーションを構築できるようにする。一部のアプリケーション(チャットボット、画像ジェネレーター、Twitter返信ロボット、予測市場)は現在存在するが、Bittensor財団の助成金を除き、検証者がこれらのクエリを受け入れて転送する正式なインセンティブはない。
より明確な説明のため、以下にアプリケーションがネットワークに統合された後、Bittensorがどのように機能するかの例を示す。
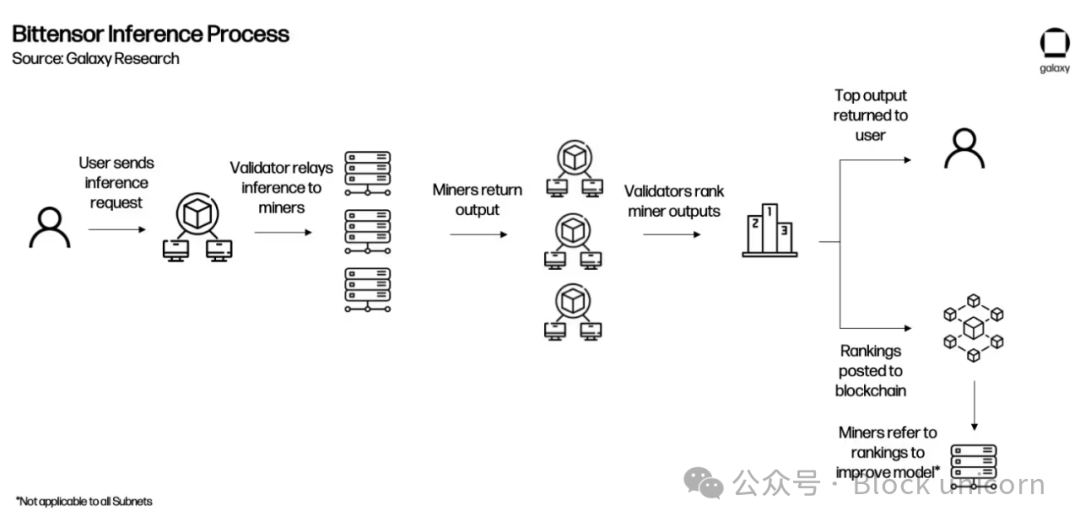
サブネットは、ルートネットワークが評価するパフォーマンスに基づいてTAOを獲得する。ルートネットワークはすべてのサブネットの上位にあり、特殊なサブネットのように機能し、64の最大サブネット検証者によってステークに基づいて管理される。ルートネットワーク検証器はサブネットのパフォーマンスに基づいてランキングし、定期的にTAO排出量をサブネットに分配。このように、個々のサブネットはルートネットワークのマイナーとして機能する。
Bittensorの展望
Bittensorは、複数のサブネットにわたるインテリジェンス生成をインセンティブ化するためにプロトコル機能を拡張する過程で、成長の苦しみを経験している。マイナーは常にネットワークを攻撃してより多くのTAO報酬を得る新しい方法を考案しており、評価が高い推論の出力をわずかに変更して複数のバリエーションを提出するなどしている。ネットワーク全体に影響するガバナンス提案は、Opentensor財団の利害関係者からなるトリウムウィレートのみが提出・実施できる(ただし、提案はBittensor検証者で構成されるBittensor上院の承認を得た後でなければ実施できない)。このプロジェクトのトークノミクスは、サブネット間でのTAO使用を促進するように修正中である。このプロジェクトは独自のアプローチで急速に有名になり、最も人気のあるAIウェブサイトの一つHuggingFaceのCEOが、Bittensorがそのリソースを同サイトに追加すべきだと述べている。
最近、コア開発者が発表した「Bittensor Paradigm」という記事で、チームはBittensorのビジョンを説明している。それは最終的に「測定対象に対して無知であること」に発展すること。理論的には、これによりBittensorはTAOによってサポートされるあらゆる種類の行動をインセンティブ化するサブネットを開発できる。しかし、かなりの実用的制限が残っている――特に、これらのネットワークが多様なプロセスを処理するためにスケールできること、そして潜在的なインセンティブが中央集権的製品を上回る進歩をもたらすことの証明が必要である。
AIモデル用分散型コンピューティングスタックの構築
上記のセクションは、開発中のさまざまなタイプの分散型AIコンピューティングプロトコルの深い概要を提供している。開発と採用の初期段階において、これらは最終的にDeFiの「マネーレゴ」概念のような「AIビルディングブロック」の作成を促進できるエコシステムの基盤を提供している。許可不要のブロックチェーンの組み合わせ可能性により、各プロトコルが他のプロトコルの上に構築され、より包括的な分散型AIエコシステムを提供する可能性がある。
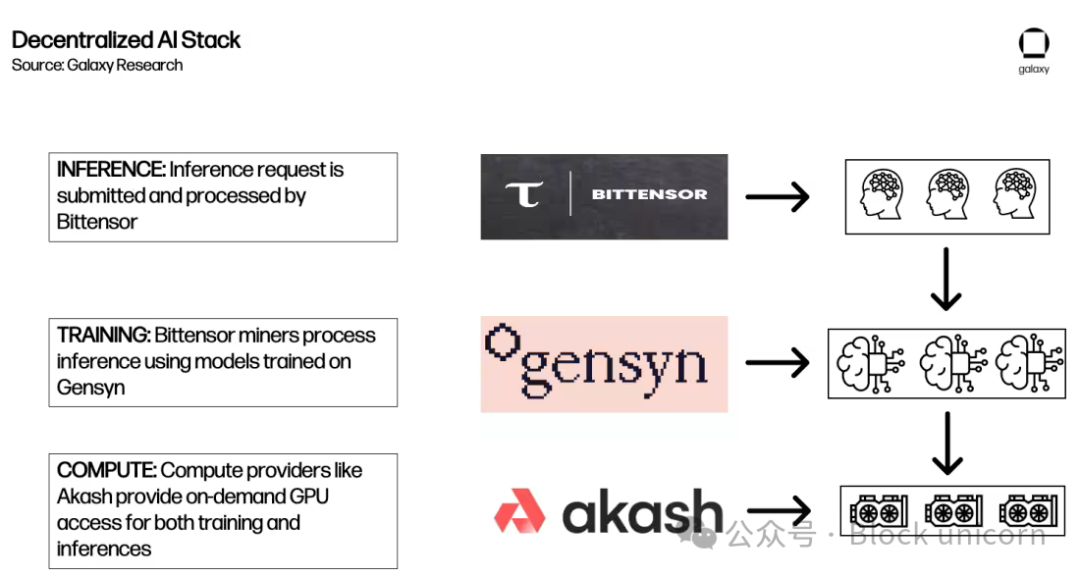
例えば、Akash、Gensyn、Bittensorが推論リクエストに応じてすべて相互作用する可能性の一例。
明
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










