

AI x DePIN:過熱する分野の衝突が生み出す新たな機会とは?
TechFlow厳選深潮セレクト
AI x DePIN:過熱する分野の衝突が生み出す新たな機会とは?
アルゴリズム、計算能力、データの力を利用し、AI技術の進歩がデータ処理とインテリジェント意思決定の境界を再定義している。
執筆:Cynic、Shigeru
本稿は「Web3 x AI」シリーズリサーチレポート第2弾。序章にあたる前編は『平行から交差へ:「Web3 と AI の融合」が牽引するデジタル経済の新潮流を探る』を参照。
世界のデジタル化転換が加速する中で、AIとDePIN(分散型物理インフラ)は産業横断的な変革を推進する基盤技術として注目されています。AIとDePINの融合は、技術の急速な反復と応用の拡大を促進するだけでなく、より安全で透明性が高く効率的なサービスモデルを開拓し、グローバル経済に深い影響を与えることになるでしょう。
DePIN:非仮想的かつ分散化、デジタル経済の中核的存在
DePINとは、分散型物理インフラ(Decentralized Physical Infrastructure)の略称です。狭義には、分散台帳技術によって支えられる伝統的な物理インフラの分散ネットワーク、例えば電力網、通信網、位置測定ネットワークなどを指します。広義には、ストレージネットワークやコンピューティングネットワークなど、物理デバイスによって支えられているすべての分散ネットワークをDePINと呼ぶことができます。
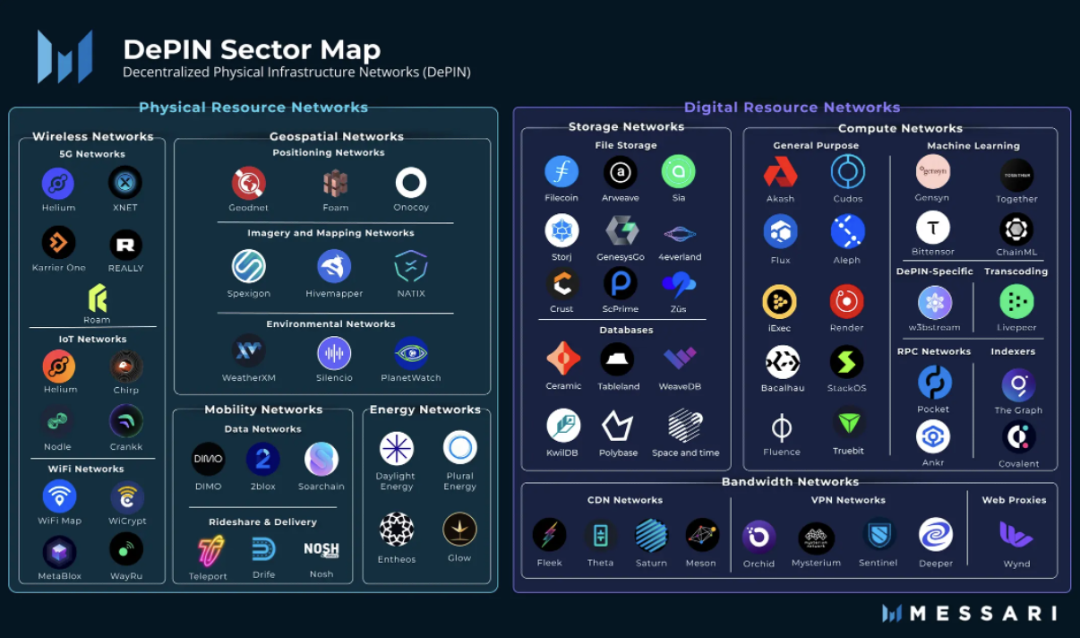
出典: Messari
Cryptoが金融分野において分散化をもたらしたとすれば、DePINは実体経済における分散化ソリューションと言えるでしょう。PoWマイニングマシン自体が一種のDePINであるとも言えます。初めからDePINはWeb3のコア支柱でした。
AIの三要素――アルゴリズム、計算力、データ。DePINはそのうち二つを独占
人工知能の発展は通常、アルゴリズム、計算力、データという3つのキーファクターに依存していると考えられています。アルゴリズムとはAIシステムを駆動する数学モデルおよびプログラム論理を指し、計算力とはこれらのアルゴリズムを実行するために必要なコンピュータリソースであり、データはAIモデルを訓練・最適化するための基礎となります。

この三要素の中でどれが最も重要でしょうか?ChatGPT登場以前は、学術会議や学術誌に次々と掲載されるアルゴリズムの微調整論文を見る限り、多くの人々はアルゴリズムこそが最重要と考えていました。しかし、ChatGPTおよびそれを支える大規模言語モデルLLMが登場して以降、後者の2要素の重要性が認識されるようになりました。膨大な計算力はモデル構築の前提条件であり、データの質と多様性は堅牢かつ効率的なAIシステムを構築するために不可欠です。これに対して、アルゴリズムに対する要求はかつてのような精緻さを求めなくなってきています。
大規模モデル時代において、AIは「細工」から「大量投入」へと移行しており、計算力とデータへの需要は日に日に高まっています。そして、まさにDePINはこれらを提供できる存在なのです。トークンによるインセンティブがロングテール市場を活性化させ、大量のコンシューマーグレードの計算能力とストレージが大規模モデルにとって最高の栄養源となるでしょう。
AIの分散化は選択肢ではなく必須
もちろん、「AWSのデータセンターにはすでに計算力とデータがある。安定性や使い勝手もDePINより優れている。なぜあえてDePINを選ばなければならないのか?」という疑問を持つ人もいるでしょう。
確かにその主張には一理あります。現状を見れば、ほぼすべての大規模モデルは大手インターネット企業が直接または間接的に開発しています。ChatGPTの背後にはMicrosoft、Geminiの背後にはGoogleがあり、中国のIT大手もそれぞれ独自の大規模モデルを持っています。なぜなら、十分な高品質データと強固な財力を背景にした計算資源を保有できるのは、大手インターネット企業だけだからです。しかし、これは正しくありません。人々はもはやインターネット巨大企業にすべてを支配され続けることを望んでいません。
第一に、中央集権的なAIはデータプライバシーとセキュリティリスクを抱えており、検閲や統制の対象となる可能性があります。第二に、インターネット巨人が生み出すAIは人々の依存度をさらに高め、市場の集中を招き、イノベーションの障壁を高める恐れがあります。

出典: https://www.gensyn.ai/
人類はAI時代のマルチン・ルターを必要としない。人々は神と直接対話する権利を持つべきなのです。
ビジネス視点から見たDePIN:コスト削減と効率向上が鍵
分散化と中央集権の価値観の対立を一旦脇に置いたとしても、ビジネス的観点から見れば、DePINをAIに活用することは十分に意義があります。
まず明確に認識すべきことは、大手インターネット企業が多数のハイエンドGPUを握っているとはいえ、民間に散在するコンシューマーグレードGPUを合算すれば、非常に大きな計算ネットワークを形成できること、つまり「計算力のロングテール効果」があるということです。こうしたコンシューマーグレードGPUのアイドル率は実は非常に高いのです。DePINが提供するインセンティブが電気代を超えていれば、ユーザーはネットワークに計算力を提供するインセンティブを持ちます。また、すべての物理インフラがユーザー自身によって管理されているため、DePINネットワークは中央集権プロバイダーが避けられない運用コストを負担する必要がなく、プロトコル設計そのものに集中できます。
データに関して言えば、DePINネットワークはエッジコンピューティングなどの手法を通じて潜在的なデータの利用可能性を解放し、伝送コストを低減できます。また、多くの分散型ストレージネットワークは自動重複排除機能を備えており、AI訓練データの前処理作業を削減できます。
最後に、DePINがもたらすCrypto経済学はシステムのフォールトトレランスを拡大し、提供者・消費者・プラットフォームの三者がWin-Winの関係を築くことを可能にします。
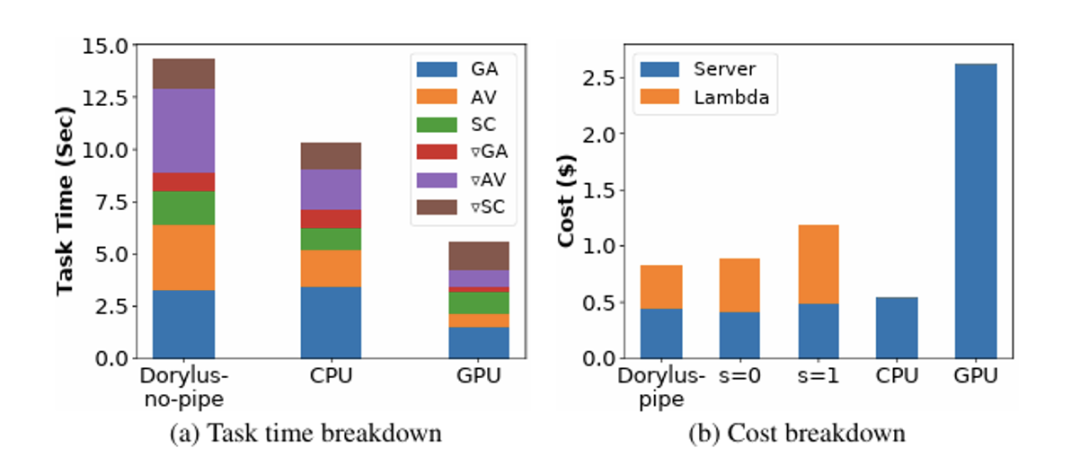
出典: UCLA
信じられないかもしれませんが、UCLAの最新研究によると、同じコストで分散型コンピューティングを使用すると、従来のGPUクラスタと比較して2.75倍のパフォーマンスを達成でき、具体的には1.22倍高速かつ4.83倍安価であることが示されています。
道は険しい:AI×DePINはどのような課題に直面するか?
「我々はこの十年間に月へ行くことを選ぶ。他のことを成そうとする。それは簡単だからではなく、むしろ難易だからこそである。」――ジョン・F・ケネディ
DePINの分散型ストレージと分散型コンピューティングを用いて信頼不要な形でAIモデルを構築することは、依然として多くの課題を抱えています。
作業の検証
本質的に、深層学習モデルの計算とPoWマイニングはどちらも汎用計算であり、最も基本的なレベルではゲート回路間の信号変化に他なりません。巨視的には、PoWマイニングは「無駄な計算」であり、無数の乱数生成とハッシュ関数の計算を繰り返して先頭にn個の0を持つハッシュ値を得ようとするものです。一方、深層学習の計算は「有益な計算」であり、順方向伝播と逆方向伝播によって各層のパラメータを計算し、効率的なAIモデルを構築します。
実際、PoWマイニングのような「無駄な計算」はハッシュ関数を利用しており、元の入力から出力を計算するのは容易ですが、出力から元の入力を求めるのは極めて困難です。そのため誰でも簡単に素早く計算結果の正当性を検証できます。一方、深層学習モデルの計算は階層構造を持っているため、各層の出力が次の層の入力となるため、計算の正当性を検証するにはこれまでのすべての計算を再実行しなければならず、簡便かつ効率的に検証することはできません。
出典: AWS
作業の検証は極めて重要です。そうでなければ、計算提供者は実際に計算を行わず、ランダムな結果を提出することさえ可能です。
一つのアイデアは、異なるサーバーに同じ計算タスクを実行させ、結果を比較して正当性を検証するというものです。しかし、ほとんどのモデル計算は非決定的であり、まったく同じ計算環境下でも同一の結果を再現することは不可能で、統計的に類似した結果を得るのがせいぜいです。また、再計算はコストの急増を招き、DePINのコスト削減・効率化という目的と矛盾します。
別のアイデアはオプティミスティック(Optimistic)メカニズムです。つまり、まず計算結果が正当であると楽観的に仮定し、誰もが結果を検証できるようにします。誤りが発見された場合、不正行為の証明(Fraud Proof)を提出でき、プロトコルは不正者に対してペナルティを科し、通報者に報酬を与えます。
並列化
前述の通り、DePINが活性化するのは主にロングテールのコンシューマーグレード計算市場であり、単一デバイスが提供できる計算力は限られます。大型AIモデルの場合、単一デバイスでの学習時間は非常に長くなるため、並列化によって学習時間を短縮する必要があります。
深層学習の並列化の主な難点は、前後のタスク間の依存関係にあります。この依存関係により、並列化が困難になります。
現在、深層学習の並列化は主にデータ並列とモデル並列の2種類に分けられます。
データ並列とは、データを複数のマシンに分散し、各マシンがモデルの全パラメータを保持し、ローカルデータを使って学習を行い、最終的に各マシンのパラメータを集約する方法です。データ量が多い場合に効果的ですが、パラメータの集約のために同期通信が必要です。
モデル並列とは、モデルが大きすぎて単一マシンに収まらない場合、モデルを複数のマシンに分割し、各マシンがモデルの一部のパラメータを保持する方法です。順方向・逆方向伝播時には異なるマシン間での通信が必要です。モデルが非常に大きい場合に有利ですが、伝播時の通信オーバーヘッドが大きくなります。
各層間の勾配情報については、同期更新と非同期更新に分けられます。同期更新はシンプルですが待ち時間が長くなりがちです。非同期更新は待ち時間が短いものの、安定性の問題を引き起こす可能性があります。
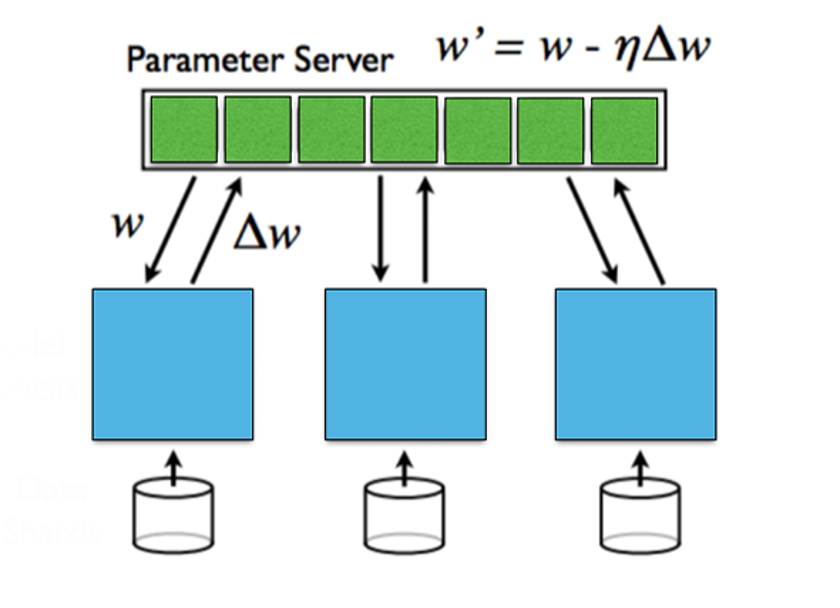
出典: Stanford University, Parallel and Distributed Deep Learning
プライバシー
世界的に個人プライバシー保護の機運が高まっており、各国政府は個人データのプライバシーとセキュリティ保護を強化しています。AIは多くの公開データセットを活用していますが、異なるAIモデルを差別化する真の鍵は各企業が持つ独自のユーザーデータにあります。
訓練中に専有データのメリットを得つつ、プライバシーを漏らさない方法とは?構築されたAIモデルのパラメータが漏洩しないようにするには?
これらはプライバシーの2つの側面、すなわちデータプライバシーとモデルプライバシーです。データプライバシーはユーザーを保護し、モデルプライバシーはモデル構築組織を保護します。現時点では、データプライバシーの方がはるかに重要です。
プライバシー問題の解決に向けてさまざまなアプローチが試みられています。フェデレーテッドラーニング(連合学習)は、データの発生元で学習を行い、データをローカルに残しつつモデルパラメータのみを転送することでデータプライバシーを確保します。ゼロ知識証明(ZKP)は今後注目されるかもしれません。
事例分析:市場にはどのような優良プロジェクトがあるか?
Gensyn
GensynはAIモデルの訓練用分散コンピューティングネットワークです。同ネットワークはPolkadotベースのレイヤー1ブロックチェーンを用いて、深層学習タスクが正しく実行されたかを検証し、支払いをトリガーします。2020年に設立され、2023年6月にa16z主導による4300万ドルのシリーズA資金調達を発表しました。
Gensynは、勾配に基づく最適化プロセスのメタデータを用いて作業証明を構築し、多粒度でグラフベースの正確なプロトコルとクロスバリデータによる一貫した実行によって、再計算による検証と整合性の比較を可能にし、最終的にブロックチェーン上で確認することで計算の正当性を保証します。さらに作業検証の信頼性を高めるため、ステーキングによるインセンティブを導入しています。
システム内には4種類の参加者がいます:タスク提出者(Submitter)、計算者(Solver)、検証者(Verifier)、通報者(Challenger)です。
-
タスク提出者はエンドユーザーであり、計算対象のタスクを提供し、完了した作業に対して支払いを行います。
-
計算者はシステムの主要なワーカーであり、モデル訓練を実行し、検証者のチェック用の証明を生成します。
-
検証者は非決定的訓練プロセスと決定的線形計算を結びつけるキープレイヤーであり、計算者の証明の一部を再計算し、距離を予想閾値と比較します。
-
通報者は最終防衛ラインであり、検証者の作業を検査し、異議を唱えることができます。異議が認められれば報酬を受け取ります。
計算者はステーキングを行う必要があり、通報者が計算者の作業を検査し、悪意ある行動を発見した場合、異議を唱えることができます。異議が承認されれば、計算者のステーキングトークンは没収され、通報者が報酬を得ます。
Gensynの予測によると、この方式は中央集権プロバイダーの1/5のコストまで削減できる見込みです。
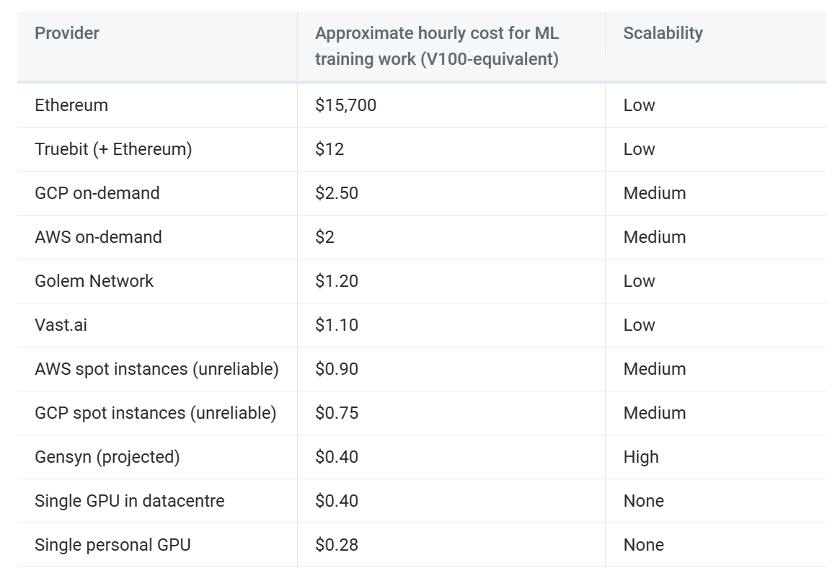
出典: Gensyn
FedML
FedMLは、どこでもどんな規模でも分散的かつ協働的なAIを実現するための分散協働型機械学習プラットフォームです。より具体的には、FedMLはMLOpsエコシステムを提供し、データ、モデル、計算リソースを組み合わせながら、プライバシーを守りつつ、機械学習モデルの訓練、展開、監視、継続的改善を行うことができます。2022年に設立され、2023年3月に600万ドルのシード資金調達を発表しました。
FedMLは、上位APIを表すFedML-APIと、下位APIを表すFedML-coreという2つの主要コンポーネントから構成されています。
FedML-coreは、分散通信とモデル訓練という2つの独立モジュールからなります。通信モジュールはMPIに基づき、異なるワーカー/クライアント間の低レベル通信を担当します。モデル訓練モジュールはPyTorchに基づきます。
FedML-APIはFedML-coreの上に構築されています。FedML-coreを活用することで、クライアント指向のプログラミングインターフェースを採用し、新しい分散アルゴリズムを容易に実装できます。
FedMLチームの最新の研究成果によると、コンシューマーグレードGPUのRTX 4090を用いてFedML Nexus AIでAIモデル推論を行う場合、A100と比較して20倍安価で、1.88倍高速であることが示されています。
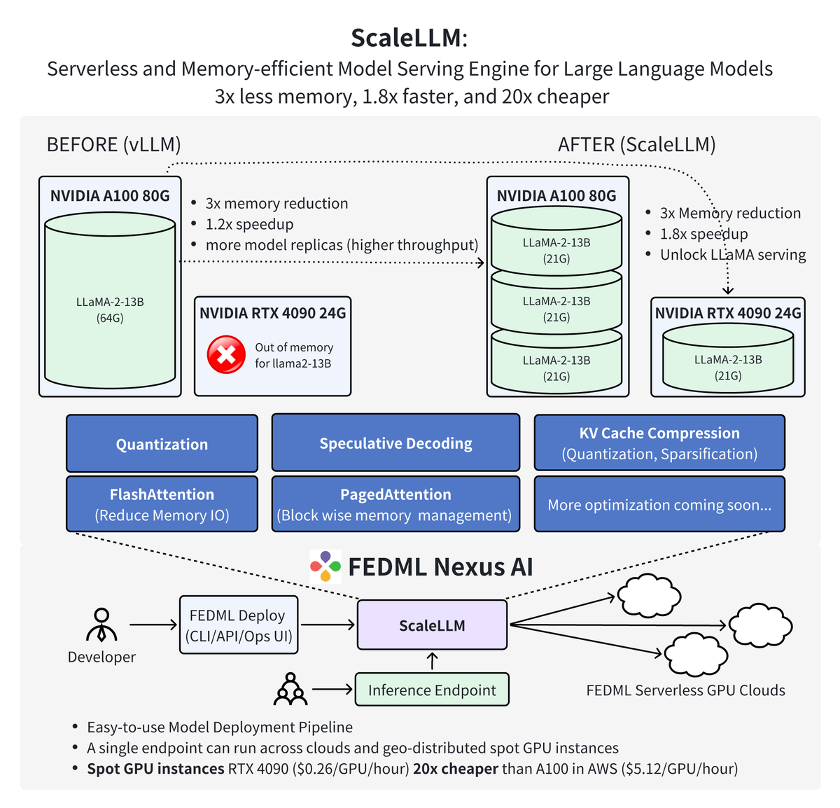
出典: FedML
将来展望:DePINがもたらすAIの民主化
いつかAIがさらに進化しAGI(汎用人工知能)となったとき、計算力は事実上の共通通貨となるでしょう。DePINはそのプロセスを前倒しにする存在です。
AIとDePINの融合は新たな技術成長ポイントを開拓し、人工知能の発展に巨大なチャンスを提供します。DePINはAIに大量の分散型計算力とデータを供給し、より大規模なモデルの訓練と高度な知能の実現を支援します。同時に、DePINはAIをより開放的で安全、信頼性の高い方向へと導き、単一の中央集権インフラへの依存を減らします。
将来を見据えると、AIとDePINは不断に連携しながら発展していくでしょう。分散ネットワークは超大規模モデルの訓練を支える強力な基盤となり、それらのモデルはDePINの応用において重要な役割を果たします。プライバシーとセキュリティを守りながら、AIはDePINネットワークのプロトコルやアルゴリズムの最適化にも貢献していくでしょう。我々は、AIとDePINがもたらすより効率的で、より公平かつ信頼できるデジタル世界を期待しています。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














