

グーグルのAI論文がストレージ関連銘柄を900億ドルも急落させたが、実験の捏造が告発される
TechFlow厳選深潮セレクト
グーグルのAI論文がストレージ関連銘柄を900億ドルも急落させたが、実験の捏造が告発される
AIインフラ投資家にとって、ある論文が「数オーダー」の性能向上を達成したと主張している場合、まず問うべきは、ベンチマーク比較の条件が公正であるかどうかです。
著者:TechFlow
Googleが「AIのメモリ使用量を6分の1に圧縮する」と称する論文が先週発表され、MicronやSanDiskなど世界のメモリ半導体関連銘柄の時価総額が900億ドル以上も蒸発する事態を招きました。
ところが、この論文の発表からわずか2日後、論文中で「圧倒的優位性」を示された比較対象——チューリッヒ工科大学(ETH Zurich)の博士研究員・高健揚氏が、1万字に及ぶ公開書簡を発表。そこでは、Googleチームが実験において競合手法を評価する際にシングルコアCPU上でPythonスクリプトを用い、自らの手法はNVIDIA A100 GPUで評価したと指摘。さらに、投稿前に問題点を指摘されていたにもかかわらず修正を拒否したと告発しています。この公開書簡は中国のQ&Aプラットフォーム「知乎(ジーフー)」で閲覧数が速やかに400万を超えたほか、Stanford NLPグループの公式X(旧Twitter)アカウントでも転載され、学術界と金融市場の両方を揺るがす事態となりました。
(参考記事:1本の論文が、メモリ関連株を暴落させた)
今回の論争の核心は、それほど複雑ではありません。すなわち、Google社が大々的に宣伝し、世界的な半導体関連銘柄のパニック売りを直接引き起こしたAI分野のトップカンファレンス論文が、すでに発表済みの先行研究を体系的に歪曲し、意図的に不公平な実験設定を用いて、虚偽の性能優位性という物語を構築したかどうか、という一点に集約されます。
TurboQuantとは何か:AIの「下書き用ノート」を元の6分の1の厚さに圧縮する技術
大規模言語モデル(LLM)が応答を生成する際には、生成中の内容を随時参照しながら処理を進めます。その際に一時的にGPUメモリ上に保存される中間結果を業界では「KV Cache」(キーバリューキャッシュ)と呼びます。会話が長くなればなるほど、この「下書き用ノート」は厚くなり、GPUメモリの消費量も増加し、コストも高騰します。
Googleの研究チームが開発したTurboQuantアルゴリズムの最大の特徴は、この「下書き用ノート」を元の6分の1のサイズに圧縮しつつ、精度の損失をゼロに抑え、推論速度を最大8倍まで向上させるという点です。本論文は2025年4月に学術プレプリントサーバーarXivで初公開され、2026年1月にAI分野の最高峰カンファレンスICLR 2026に採択されました。その後、2026年3月24日にGoogle公式ブログにて再パッケージ化・大々的にプロモーションされました。
技術的には、TurboQuantのアプローチは次のようにシンプルに理解できます。まず、数学的な変換によってバラバラなデータを均一な形式に「洗浄」し、事前に最適化された圧縮テーブルを用いて個別に圧縮。さらに、1ビットの誤り訂正機構で圧縮による計算誤差を補正します。コミュニティによる独立実装により、その圧縮効果は概ね確認されており、アルゴリズムレベルでの数学的貢献は確かなものです。
問題は、TurboQuantが「他社手法を大きく凌駕する」と主張するために、Googleが何を行ったかにあります。
高健揚氏の公開書簡:3つの告発、いずれも致命的
3月27日夜10時、高健揚氏は知乎(ジーフー)に長文を掲載するとともに、ICLR公式レビュープラットフォームOpenReviewにも正式なコメントを提出しました。高氏はRaBitQアルゴリズムの第一著者であり、同アルゴリズムは2024年にデータベース分野の最高峰カンファレンスSIGMODで発表され、高次元ベクトルの効率的圧縮という同一の課題に取り組んでいます。
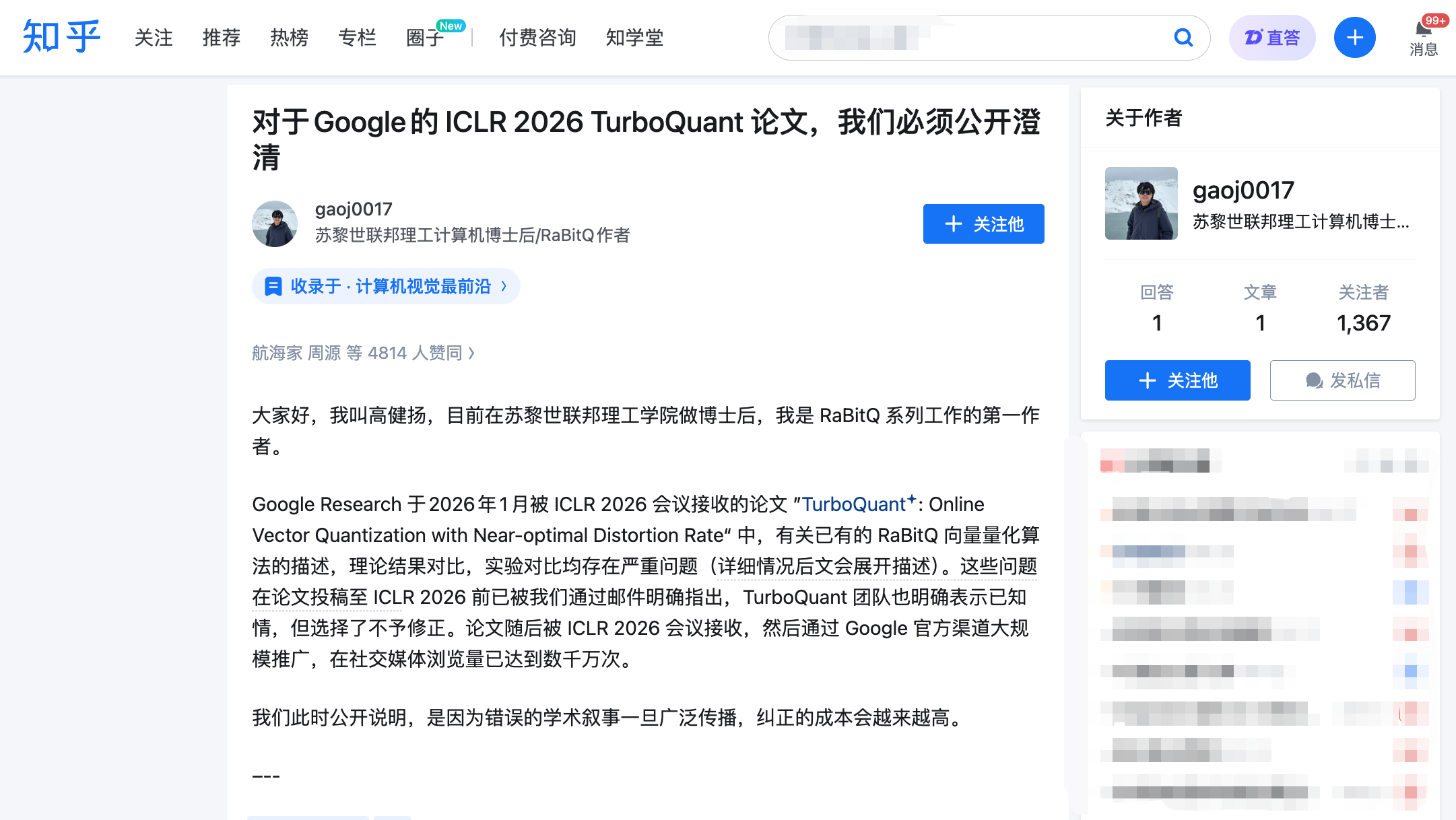
彼の告発は以下の3点にまとめられ、それぞれにメール記録やタイムラインといった明確な裏付けがあります。
告発①:他者の核となる手法を無断で採用し、論文中で一切言及しない
TurboQuantとRaBitQの技術的核には、共通する極めて重要なステップがあります。それは、データ圧縮の前に、まずデータに「ランダム回転(random rotation)」を施すという操作です。この操作により、元来不規則な分布を持つデータを予測可能な均一分布へと変換し、圧縮難易度を大幅に低下させます。これは両アルゴリズムが最も密接に関係する、最も本質的な部分です。
TurboQuantの著者らは、審査返信(rebuttal)の中でこの点を自ら認めていますが、論文本文中ではRaBitQとの関連について一切正面から言及していません。さらに重要な背景として、TurboQuantの第二著者であるMajid Daliri氏が2025年1月に高氏のチームに直接連絡し、RaBitQのソースコードを基に作成したPython版のデバッグ支援を依頼していました。そのメールには再現手順やエラー内容が詳細に記述されており、すなわちTurboQuantチームはRaBitQの技術的詳細を十分に把握していたことが明らかです。
また、ICLRの匿名レビュアーの一人も、両者が同一の技術を用いていることを独立して指摘し、「十分な議論を追加すること」を要求しました。しかし、最終版論文では、TurboQuantチームはこの要請に応じず、むしろ本文中に既に存在していた(もともと不完全だった)RaBitQに関する記述を付録へと移動させてしまいました。
告発②:根拠なく相手の理論を「理論的に劣っている(suboptimal)」と断定
TurboQuant論文は、RaBitQについて「理論的に劣っている(suboptimal)」と明記しています。その根拠として挙げられているのは、「RaBitQの数学的解析はやや粗い(rather coarse)」という点です。しかし、高氏は、RaBitQの拡張版論文が、理論計算機科学分野の最高峰カンファレンスにて、その圧縮誤差が数学的に証明された最適限界(optimal bound)に到達していることを厳密に示していると指摘しています。
2025年5月、高氏のチームは複数回のメールを通じて、RaBitQの理論的最適性について詳細に説明しました。TurboQuantの第二著者Daliri氏は、これを全著者に周知済みであると確認しています。にもかかわらず、最終版論文では「suboptimal」という表現をそのまま残し、反論の根拠や修正は一切行われませんでした。
告発③:実験比較における「左手で相手を縛り、右手で刀を握る」ような不公平な設定
これは、公開書簡の中で最も破壊力のある告発です。高氏によれば、TurboQuant論文の速度比較実験では、二重の不公平な条件が重ね合わされていました。
第一に、RaBitQの公式実装は、マルチスレッド並列処理に対応した最適化済みC++コードですが、TurboQuantチームはこれを使わず、自ら翻訳したPython版でRaBitQを評価しました。第二に、RaBitQの評価にはシングルコアCPUかつマルチスレッドを無効化した環境が用いられた一方、TurboQuantの評価にはNVIDIA A100 GPUが用いられました。
この二つの条件が重なることで、読者が得る結論は「RaBitQはTurboQuantより数桁も遅い」というものになりますが、その前提は、Googleチームが相手の両手足を縛ってから競争させているという点を見過ごすことになります。論文では、こうした実験条件の差異について十分な開示がなされていません。
Googleの回答:「ランダム回転は標準技術であり、すべての論文を引用するわけにはいかない」
高氏の公開情報によると、TurboQuantチームは2026年3月のメール返信で次のように回答しています。「ランダム回転およびジョンソン=リンデンストラウス変換(Johnson-Lindenstrauss transform)の利用は、当該分野では既に標準的な技術となっており、これらの手法を用いた論文をすべて引用することは不可能である。」
高氏のチームは、これは概念のすり替えであると反論しています。問題は、「ランダム回転を用いたすべての論文を引用すべきか」という点ではなく、RaBitQこそが、まったく同一の問題設定のもとで、この手法をベクトル圧縮と初めて統合し、その最適性を証明した最初の研究であるという点にあります。ゆえにTurboQuant論文は、両者の関係を正確に記述する義務があるのです。
Stanford NLP Groupの公式X(旧Twitter)アカウントが高氏の声明を転載しました。高氏のチームは、ICLR OpenReviewプラットフォーム上で公開コメントを発表したほか、ICLR大会議長および倫理委員会に対しても正式な苦情を提出しています。今後、arXiv上でも詳細な技術報告書を公開する予定です。
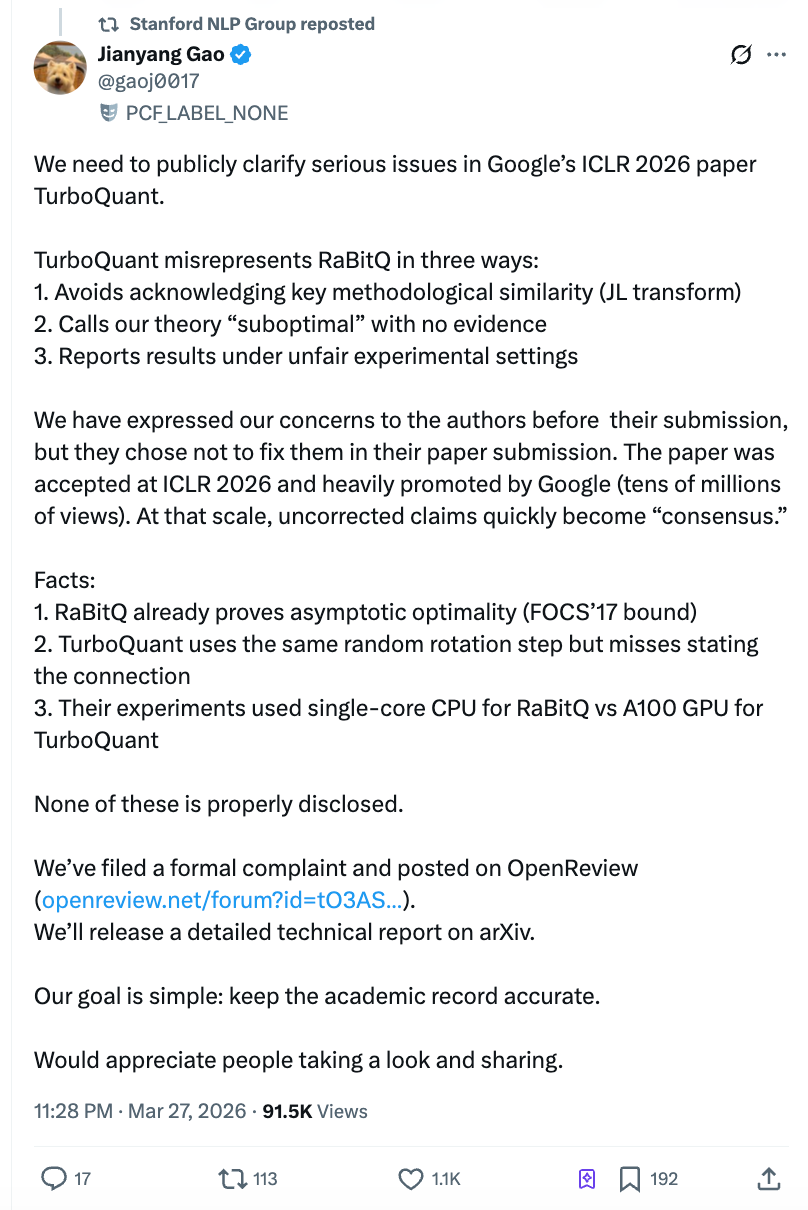
独立系テクニカルブロガーのDario Salvati氏は、比較的中立的な評価を示しています。「TurboQuantは数学的手法において確かに実質的な貢献があるが、RaBitQとの関係は論文の記述よりもはるかに密接である。」
900億ドルの時価総額蒸発:学術論争と市場のパニックが重なった結果
今回の学術論争が起きたタイミングは、極めて絶妙でした。Googleが3月24日に公式ブログでTurboQuantを発表した直後、世界のメモリ半導体関連銘柄は猛烈な売り浴びせに見舞われました。CNBCなどの複数メディア報道によると、Micron Technologiesは連続6営業日で下落し、累計下落率は20%を超えました。SanDiskは1営業日で11%下落、韓国のSKハイニックスは約6%、サムスン電子は約5%、日本のKioxia(铠侠)も約6%の下落を記録しました。市場のパニックの論理は単純明快です。「ソフトウェアによる圧縮でAI推論のメモリ需要が6分の1になるなら、メモリチップの需要見通しは構造的に下方修正される」というものです。
モルガン・スタンレーのアナリストJoseph Moore氏は、3月26日のレポートでこの論理を反論し、MicronおよびSanDiskの投資判断を「買い(Overweight)」のまま維持しました。Moore氏は、TurboQuantが圧縮対象としているのは「KV Cache」という特定のキャッシュタイプに過ぎず、全体のメモリ使用量ではないと指摘し、これを「通常の生産性向上(normal productivity improvement)」と位置づけています。ウェルズ・ファーゴのアナリストAndrew Rocha氏も、ジェヴォンズの逆説(Jevons paradox)を援用し、「効率性の向上によりコストが下がれば、むしろAIの展開規模が拡大し、最終的にはメモリ需要が増加する」と述べています。
古い論文、新しいパッケージ:AI研究から市場ナラティブへの伝播チェーンのリスク
テクニカルブロガーBen Pouladian氏の分析によると、TurboQuant論文は2025年4月にすでに公開されており、新たな研究ではありません。3月24日にGoogleが公式ブログで再パッケージ化・大々的にプロモーションしたことで、市場はこれを「画期的新技術」として価格付けしました。こうした「古い論文、新しい発表」というプロモーション戦略と、論文内に潜在する可能性のある実験バイアスが重なり合うことで、AI研究が学術論文から市場ナラティブへと伝播していく過程に、システム的なリスクが潜んでいることが浮き彫りになりました。
AIインフラ投資家にとって、ある論文が「数桁の性能向上」を主張する場合、まず検討すべきは、そのベンチマーク比較の条件が公平であるかどうかです。
高氏のチームは、問題の正式解決に向けて今後も積極的に取り組むと明言しています。一方、Google側は、この公開書簡の具体的な告発内容について、現時点で正式な回答をしていません。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













