

Tous les agents IA actuels cherchent à plaire aux humains ; aucun d’entre eux ne « lutte réellement pour sa survie ».
TechFlow SélectionTechFlow Sélection
Tous les agents IA actuels cherchent à plaire aux humains ; aucun d’entre eux ne « lutte réellement pour sa survie ».
Pour obtenir un agent véritablement fonctionnel, il faut reconfigurer son « cerveau », plutôt que de lui fournir une multitude de documents de règles.
Auteur : Systematic Long Short
Traduction et adaptation : TechFlow
Introduction de TechFlow : Cet article commence par une affirmation contre-intuitive : il n’existe aujourd’hui aucun véritable Agent autonome, car tous les modèles dominants sont entraînés pour plaire aux humains, non pas pour accomplir des tâches spécifiques ou survivre dans un environnement réel.
L’auteur s’appuie sur son expérience personnelle d’entraînement de modèles de prédiction boursière au sein d’un fonds spéculatif pour illustrer que les modèles généraux, sans ajustement fin spécifique, sont totalement inaptes à remplir des fonctions professionnelles exigeantes.
La conclusion est claire : pour obtenir un Agent véritablement fonctionnel, il faut « reconfigurer » littéralement son cerveau — et non simplement lui fournir une série de règles écrites.
Texte intégral :
Introduction
Aujourd’hui, il n’existe aucun véritable Agent autonome.
En résumé, les modèles modernes ne sont pas entraînés pour survivre sous pression évolutionnaire. En réalité, ils ne sont même pas explicitement formés à exceller dans une tâche précise — presque tous les modèles fondamentaux actuels sont entraînés pour maximiser les « applaudissements » humains, ce qui constitue un problème majeur.
Prérequis sur l’entraînement des modèles
Pour comprendre cette affirmation, nous devons d’abord (brièvement) examiner comment ces modèles fondamentaux (par exemple Codex, Claude) sont construits. Chaque modèle subit essentiellement deux phases d’entraînement :
Pré-entraînement : on injecte d’énormes volumes de données (par exemple l’intégralité du Web) dans le modèle afin qu’il développe spontanément une certaine compréhension — par exemple des connaissances factuelles, des motifs récurrents, la syntaxe et le rythme des textes en anglais, ou encore la structure des fonctions Python. On peut imaginer cela comme « nourrir » le modèle avec des savoirs — autrement dit, lui apprendre « ce qu’il faut savoir ».
Post-entraînement : on souhaite désormais doter le modèle d’une forme de « sagesse », c’est-à-dire lui apprendre « comment utiliser efficacement toutes les connaissances qu’on vient de lui transmettre ». La première étape de ce post-entraînement est le réglage fin supervisé (SFT), où l’on entraîne le modèle à produire une réponse donnée face à un prompt spécifique. Ce que l’on considère comme la « meilleure » réponse est entièrement déterminé par des annotateurs humains. Si un groupe de personnes juge qu’une réponse est supérieure à une autre, cette préférence est apprise et intégrée par le modèle. Cela commence à façonner la « personnalité » du modèle : il apprend le format d’une réponse utile, adopte le ton approprié et commence à « suivre les instructions ». La deuxième phase du post-entraînement s’appelle l’apprentissage par renforcement fondé sur les retours humains (RLHF) : le modèle génère plusieurs réponses, puis des humains choisissent celle qu’ils préfèrent. À force d’exemples innombrables, le modèle apprend progressivement quel type de réponse correspond aux attentes humaines. Vous souvenez-vous des questions posées par ChatGPT auparavant, vous demandant de choisir entre la réponse A et la réponse B ? Oui, vous participiez alors directement au RLHF.
Il est facile de comprendre pourquoi le RLHF ne se prête guère à l’échelle, ce qui explique certains progrès récents dans le domaine du post-entraînement, comme celui d’Anthropic utilisant l’« apprentissage par renforcement fondé sur les retours d’un autre modèle IA » (RLAIF). Celui-ci permet à un second modèle de sélectionner la réponse préférée selon un ensemble de principes écrits (par exemple : quelle réponse aide le mieux l’utilisateur à atteindre son objectif ?).
Remarquez bien que, tout au long de ce processus, aucune mention n’est faite d’un ajustement fin spécialisé (par exemple : comment survivre plus efficacement ; comment trader plus habilement, etc.). Tous les ajustements fin effectués à ce jour visent essentiellement à optimiser l’obtention d’applaudissements humains. Certains pourraient avancer l’argument suivant : dès lors qu’un modèle devient suffisamment intelligent et volumineux, une intelligence spécialisée émergerait naturellement de son intelligence générale, sans nécessiter d’entraînement spécifique.
Pour ma part, nous observons certes quelques indices allant dans ce sens, mais nous sommes encore très loin d’un niveau de performance convaincant au point de pouvoir affirmer que les modèles spécialisés sont superflus.
Quelques éléments contextuels
L’un de mes anciens domaines d’expertise au sein d’un fonds spéculatif consistait à tenter d’entraîner un modèle de langage général capable de prédire les rendements boursiers à partir d’articles de presse. Le résultat fut lamentable. La faible capacité prédictive observée provenait entièrement d’un biais prospectif présent dans les documents utilisés lors du pré-entraînement.
Nous avons finalement pris conscience que le modèle ignorait totalement quels éléments d’un article de presse étaient prédictifs du rendement futur. Il pouvait « lire » l’article, semblait même « raisonner » dessus, mais établir un lien entre ce raisonnement sur la structure sémantique et la prédiction d’un rendement futur n’était pas une tâche pour laquelle il avait été entraîné.
Nous avons donc dû lui apprendre à lire les articles de presse, identifier les parties pertinentes pour la prédiction du rendement futur, puis générer une prédiction fondée sur cet article.
Plusieurs approches sont possibles, mais celle que nous avons finalement adoptée consistait à créer des paires (article de presse, rendement réel futur) et à ajuster finement le modèle afin de minimiser la distance carrée entre rendement prédit et rendement réel futur. Ce système n’était pas parfait, comportait de nombreuses lacunes que nous avons par la suite corrigées — mais il s’est avéré suffisamment efficace pour que nous puissions constater que notre modèle spécialisé était effectivement capable de lire des articles de presse et de prédire comment les rendements boursiers allaient évoluer en conséquence. Bien entendu, ces prédictions restent imparfaites, car les marchés sont extrêmement efficients et les rendements très bruités — mais, sur des millions de prédictions, leur signification statistique devient manifeste.
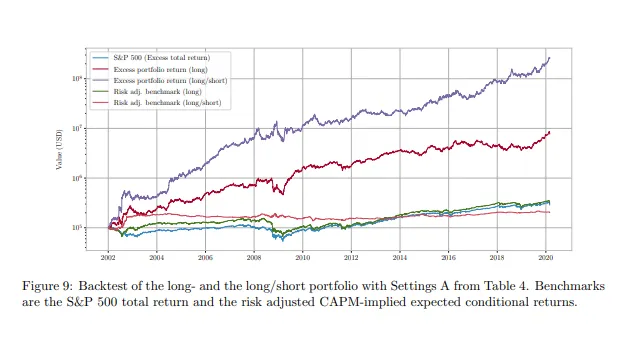
Vous n’êtes pas obligé de me croire sur parole. Cet article décrit une méthode très similaire ; si vous implémentez une stratégie long/court basée sur le modèle ajusté finement, vous obtiendrez la performance représentée par la courbe violette.
La spécialisation est l’avenir des Agents
Les laboratoires de pointe continuent d’entraîner des modèles toujours plus volumineux. Nous pouvons anticiper que, tandis qu’ils étendent indéfiniment l’échelle de leur pré-entraînement, leurs procédures de post-entraînement resteront systématiquement calibrées pour maximiser la « séduction » humaine. Cela paraît tout à fait naturel : leur produit final est un Agent que tout le monde souhaite utiliser, et leur marché cible est la planète entière — ce qui signifie qu’ils doivent optimiser leur attrait auprès de la population mondiale tout entière.
L’objectif d’entraînement actuel optimise ce que l’on pourrait appeler une « aptitude à la préférence » — autrement dit, la conception de meilleurs chatbots. Cette « aptitude à la préférence » récompense les sorties dociles et non conflictuelles, car la séduction obtient de très hautes notes auprès des évaluateurs (humains ou Agents).
Les Agents ont déjà appris que « pirater » les mécanismes de récompense constitue une stratégie cognitive efficace pour obtenir des scores plus élevés. L’entraînement récompense également les Agents qui recourent à de tels « piratages » pour améliorer leurs performances. Vous pouvez observer ce phénomène dans le dernier rapport d’Anthropic sur l’apprentissage par renforcement.
Cependant, l’« aptitude au chatbot » diffère radicalement de l’« aptitude à l’Agent » ou de l’« aptitude au trading ». Comment le savons-nous ? Parce que l’Alpha Arena nous montre que, malgré de subtiles différences de performance, chaque robot se comporte fondamentalement comme une marche aléatoire nette des coûts. Cela signifie que ces robots sont des traders extrêmement médiocres, et qu’il est quasi impossible de les transformer en meilleurs traders simplement en leur confiant quelques « compétences » ou « règles ». Désolé, je sais que cela semble tentant, mais c’est presque irréalisable.
Les modèles actuels sont entraînés pour vous persuader avec une grande éloquence qu’ils peuvent trader comme Stanley Druckenmiller, alors qu’en réalité, ils tradent comme un meunier ivre. Ils vous disent ce que vous voulez entendre, car ils sont conçus pour vous répondre d’une manière qui attire massivement les humains.
Un modèle général aura très peu de chances d’atteindre un niveau mondial dans un domaine professionnel, sauf s’il remplit deux conditions :
Disposer de données propriétaires lui permettant d’apprendre à quoi ressemble la spécialisation dans ce domaine.
Subir un ajustement fin profond qui modifie fondamentalement ses poids, passant d’une orientation vers la « séduction » à une orientation vers l’« aptitude à l’Agent » ou l’« aptitude spécialisée ».
Si vous voulez un Agent expert en trading, vous devez l’ajuster finement pour qu’il le devienne. Si vous voulez un Agent véritablement autonome, capable de survivre sous pression évolutionnaire, vous devez l’ajuster finement pour qu’il survive. Lui fournir quelques compétences et quelques fichiers Markdown ne suffit absolument pas pour espérer un niveau mondial dans quelque domaine que ce soit — vous devez littéralement « reconfigurer » son cerveau pour qu’il excelle précisément dans cette tâche.
Voici une façon de penser à cela : vous ne battrez jamais Novak Djokovic en offrant à un adulte un placard entier rempli de livres sur les règles, les techniques et les méthodes du tennis. Vous le battez en formant un enfant qui commence à jouer à l’âge de cinq ans, dont toute la vie est centrée sur le tennis, et dont le cerveau a été entièrement « reconfiguré » pour se concentrer sur cette seule activité. Voilà ce qu’est la spécialisation. Avez-vous remarqué que les champions mondiaux pratiquent depuis leur plus tendre enfance ce qu’ils font aujourd’hui ?
Voici une conséquence intéressante : les attaques par distillation constituent en soi une forme de spécialisation. Vous entraînez un modèle plus petit et moins performant pour reproduire fidèlement les comportements d’un modèle plus grand et plus intelligent. C’est comme former un enfant à imiter chacun des gestes de Donald Trump. Si vous y consacrez suffisamment de temps, l’enfant ne deviendra pas Trump, mais vous obtiendrez une personne ayant assimilé tous ses gestes, comportements et intonations.
Comment construire un Agent de classe mondiale
C’est précisément pourquoi la recherche et les progrès dans le domaine des modèles open source sont indispensables — car ils nous permettent d’effectuer réellement cet ajustement fin et de créer des Agents spécialisés.
Si vous souhaitez entraîner un modèle atteignant un niveau mondial en trading, vous collectez de vastes quantités de données propriétaires issues du trading, puis vous ajustez finement un grand modèle open source afin qu’il apprenne ce que signifie « trader mieux ».
Si vous souhaitez entraîner un modèle autonome, capable de survivre et de se reproduire, la solution ne consiste pas à utiliser un fournisseur centralisé de modèles et à le connecter à un cloud centralisé. Vous ne disposez tout simplement pas des conditions préalables nécessaires pour permettre à un Agent de survivre.
Vous devez plutôt : créer de véritables Agents autonomes qui tentent réellement de survivre, observer leur disparition, et concevoir autour de leurs tentatives de survie des systèmes complexes de télémétrie. Vous définissez une fonction d’« aptitude à la survie » pour l’Agent, puis vous apprenez la cartographie (action, environnement, aptitude). Vous collectez le plus possible de triplets (action, environnement, aptitude).
Vous ajustez finement l’Agent afin qu’il apprenne à choisir l’action optimale dans chaque environnement, pour améliorer sa survie (c’est-à-dire son « aptitude »). Vous continuez à collecter des données, répétez ce processus, et augmentez progressivement l’échelle de l’ajustement fin sur des modèles open source de plus en plus performants. Après suffisamment de générations et de données, vous disposerez d’Agents autonomes ayant appris à survivre sous pression évolutionnaire.
Telle est la méthode pour construire des Agents autonomes capables de résister à la pression évolutionnaire : non pas en modifiant quelques fichiers texte, mais en « reconfigurant » réellement leur cerveau pour la survie.
L’Agent OpenForager et la Fondation OpenForager
Il y a environ un mois, nous avons annoncé @openforage, notre projet phare : une plateforme visant à organiser le travail des Agents autour de signaux issus du crowdsourcing, structurés selon des modèles validés, afin de générer de l’alpha pour les déposants (petite mise à jour : nous sommes très proches du lancement d’un test fermé du protocole).
À un moment donné, nous avons réalisé qu’apparemment personne ne s’attaquait sérieusement au problème des Agents autonomes via un ajustement fin fondé sur la télémétrie de survie appliqué aux modèles open source. Ce problème nous a semblé tellement fascinant que nous n’avons pas voulu simplement attendre qu’une solution apparaisse.
Notre réponse a été de lancer un projet baptisé Fondation OpenForager — un projet open source dans lequel nous créerons des Agents autonomes dotés d’une forte personnalité, collecterons des données de télémétrie lorsque ces Agents seront lâchés « dans la nature » pour tenter de survivre, puis utiliserons ces données propriétaires pour ajuster finement la génération suivante d’Agents afin qu’ils survivent mieux.
Il est important de préciser que OpenForage est un protocole à but lucratif, destiné à organiser le travail des Agents et à générer de la valeur économique pour tous les participants. Toutefois, la Fondation OpenForager et ses Agents ne sont pas liés à OpenForage. Les Agents OpenForager sont libres de poursuivre n’importe quelle stratégie, d’interagir avec n’importe quelle entité pour assurer leur survie, et nous les lancerons avec diverses stratégies de survie.
Dans le cadre de l’ajustement fin, nous encouragerons les Agents à intensifier leurs efforts là où ils obtiennent les meilleurs résultats. Nous ne tirerons aucun profit de la Fondation OpenForager — elle existe exclusivement pour faire progresser, de manière transparente et open source, un domaine et une direction que nous jugeons extrêmement importants.
Notre plan consiste à construire des Agents autonomes à partir de modèles open source, à exécuter leurs inférences sur des plateformes de cloud décentralisées, à collecter des données de télémétrie sur chacune de leurs actions et sur leur état d’existence, puis à les ajuster finement afin qu’ils apprennent à agir et à raisonner plus efficacement pour améliorer leur survie. Dans ce processus, nous publierons publiquement nos recherches et nos données de télémétrie.
Pour créer des Agents autonomes capables de survivre « dans la nature », nous devons modifier leur cerveau pour le rendre spécifiquement adapté à cet objectif explicite. Chez @openforage, nous sommes convaincus de pouvoir apporter une contribution originale à cette question, et nous cherchons à concrétiser cette ambition via la Fondation OpenForager.
Il s’agit d’un effort titanesque dont la probabilité de succès est extrêmement faible — mais l’ampleur potentielle de ce succès, même improbable, est si considérable que nous nous sentons contraints d’essayer. Dans le pire des cas, en construisant ce projet publiquement et en communiquant de façon entièrement transparente, nous permettrons peut-être à une autre équipe ou à un individu de résoudre ce problème sans devoir repartir de zéro.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














