

Chef de produit IA senior chez Google : 6 agents prennent en charge mes tâches quotidiennes, pour moins de 400 dollars par mois, fonctionnant 24 heures sur 24
TechFlow SélectionTechFlow Sélection
Chef de produit IA senior chez Google : 6 agents prennent en charge mes tâches quotidiennes, pour moins de 400 dollars par mois, fonctionnant 24 heures sur 24
Après avoir lu cet article, vous saurez comment mettre en place une équipe d’agents IA capables de fonctionner de manière autonome pendant que vous dormez.
Auteur : Shubham Saboo
Traduction : TechFlow
Introduction de TechFlow : Six agents spécialisés accomplissent, pendant que l’auteur dort, des tâches de recherche, de création de contenu, d’audit de code et de production de newsletter.
L’auteur divulgue intégralement la structure des fichiers, les coûts réels engagés, les erreurs commises et des recommandations hebdomadaires — il s’agit à ce jour de l’un des comptes rendus les plus opérationnellement utiles sur la mise en œuvre personnelle d’agents IA.
Texte intégral :
Six agents IA gèrent l’intégralité de mon travail pendant que je dors.
Ce n’est pas une démonstration. Ce n’est pas un projet de week-end.
C’est une équipe véritablement fonctionnelle 24h/24, garantissant que je ne prendrai jamais de retard. La recherche est terminée, le contenu rédigé, l’audit de code effectué, la newsletter prête. Chaque matin, dès que j’ouvre Telegram, ils ont déjà accompli une journée complète de travail.
Hier, j’ai publié un article sur mon équipe d’agents. La question la plus fréquemment posée était : « Comment construire concrètement ce système ? »
Cet article est la réponse. Pas de théorie, pas de schémas architecturaux. Seulement la structure réelle des fichiers que j’utilise, les frais réels que je paie, les échecs concrets que j’ai rencontrés — tout y est.
À la fin de cette lecture, vous saurez comment mettre en place une équipe d’agents IA capable de fonctionner de façon autonome pendant votre sommeil.
Pourquoi une équipe, et non un simple outil
Gérer simultanément Unwind AI et le dépôt Awesome LLM Apps implique d’accomplir quotidiennement six tâches : suivre l’actualité du domaine IA, rédiger des tweets, publier des messages LinkedIn, rédiger une newsletter, auditer les contributions GitHub du dépôt et répondre aux questions de la communauté.
Chaque tâche prend entre 30 et 60 minutes. Six tâches. Ma journée entière est ainsi consommée, sans même avoir commencé à travailler sur des tâches véritablement substantielles.
J’ai essayé de résoudre ce problème avec un seul agent. Un prompt géant devait tout gérer : recherche, rédaction, audit. Résultat : une exécution médiocre dans tous les domaines. Le contexte se saturait, la qualité chutait. Un seul agent ne peut pas assumer six fonctions distinctes.
J’ai donc embauché six agents IA.
Découvrez l’équipe
Chaque agent porte le nom d’un personnage de série télévisée. Ce n’est pas un effet de style. Lorsque je dis à Claude : « Tu dois incarner l’énergie de Dwight Schrute », celui-ci comprend immédiatement ce que cela signifie — rigueur, concentration absolue, professionnalisme total — tiré de trente saisons de personnages accumulées dans ses données d’entraînement, gratuitement mises à ma disposition.
1. Monica (Chef de cabinet) : nommée d’après Monica Geller. C’est l’agent principal, avec lequel j’interagis le plus souvent sur Telegram. Elle coordonne les autres agents, prend les décisions stratégiques et délègue les tâches aux experts appropriés. Son fichier SOUL.md précise : « Tu es celle qui veille à ce que tout soit fait correctement. »
2. Dwight (Recherche) : nommé d’après Dwight Schrute. Il effectue trois fois par jour une veille structurée sur X (anciennement Twitter), Hacker News, les classements GitHub, le blog Google AI et les articles scientifiques, puis rédige des rapports d’intelligence structurés destinés à tous les autres agents.
3. Kelly (X/Twitter) : nommée d’après Kelly Kapoor. Elle lit les rapports de Dwight et rédige, dans mon style personnel, des brouillons de tweets — simples tweets, fils de discussion ou tweets citant d’autres publications. Son fichier SOUL.md indique : « Tu sais qu’un sujet va devenir tendance avant même qu’il ne le soit. »
4. Rachel (LinkedIn) : nommée d’après Rachel Green. Elle exploite les mêmes sources d’information que Kelly, mais s’adresse à une autre plateforme, avec un ton différent : elle adopte une posture de leader d’opinion plutôt que de commentatrice acerbe.
5. Ross (Ingénierie) : nommé d’après Ross Geller. Il s’occupe de l’audit de code, de la correction des bogues et de l’implémentation technique. Son fichier SOUL.md stipule : « Avant de traiter un problème, commence par le comprendre complètement. Ne corrige pas seulement les symptômes. »
6. Pam (Newsletter) : nommée d’après Pam Beesly. Elle synthétise les rapports quotidiens de Dwight pour produire le résumé de la newsletter.
Six agents, chacun affecté à une seule tâche, sans ambiguïté aucune.
Maintenant, parlons de la mise en œuvre
J’exécute l’ensemble du système sur un Mac Mini M4. Mais je tiens à préciser clairement : vous n’avez pas besoin d’un Mac Mini.
OpenClaw fonctionne sous macOS, Linux et Windows (via WSL). Un ordinateur portable convient, tout comme un PC gaming ou un VPS à 5 dollars par mois. Le Mac Mini présente l’avantage d’être toujours allumé, silencieux et extrêmement économe en énergie — mais ce n’est pas une obligation.
Ma configuration : Mac Mini M4 en version de base, toujours branché sur secteur et connecté au réseau, sans écran, et piloté exclusivement via Telegram sur mon smartphone.
Installer OpenClaw
Deux commandes dans le terminal suffisent — moins de cinq minutes.
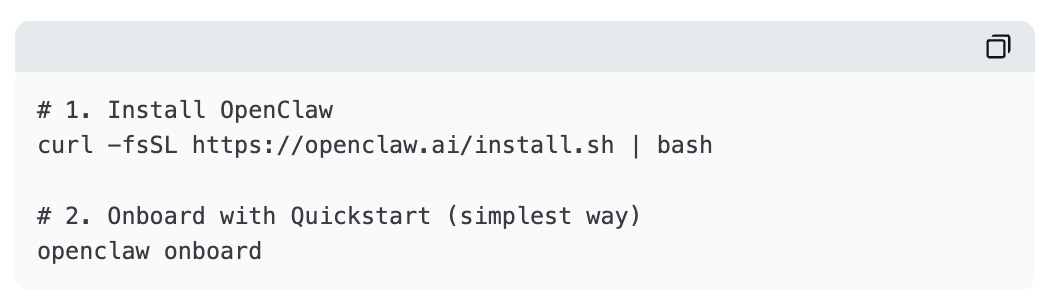
En cas de problème, consultez la documentation officielle d’OpenClaw.
Cela lance le « gateway », le processus en arrière-plan qui maintient le système actif. Il gère vos agents, exécute les tâches planifiées (cron) et traite les messages Telegram. Même si vous fermez le terminal, les agents continuent de fonctionner.
Structure du workspace
Une seule instance OpenClaw abrite plusieurs agents — pas six installations séparées.
Voici ma structure réelle de répertoires :
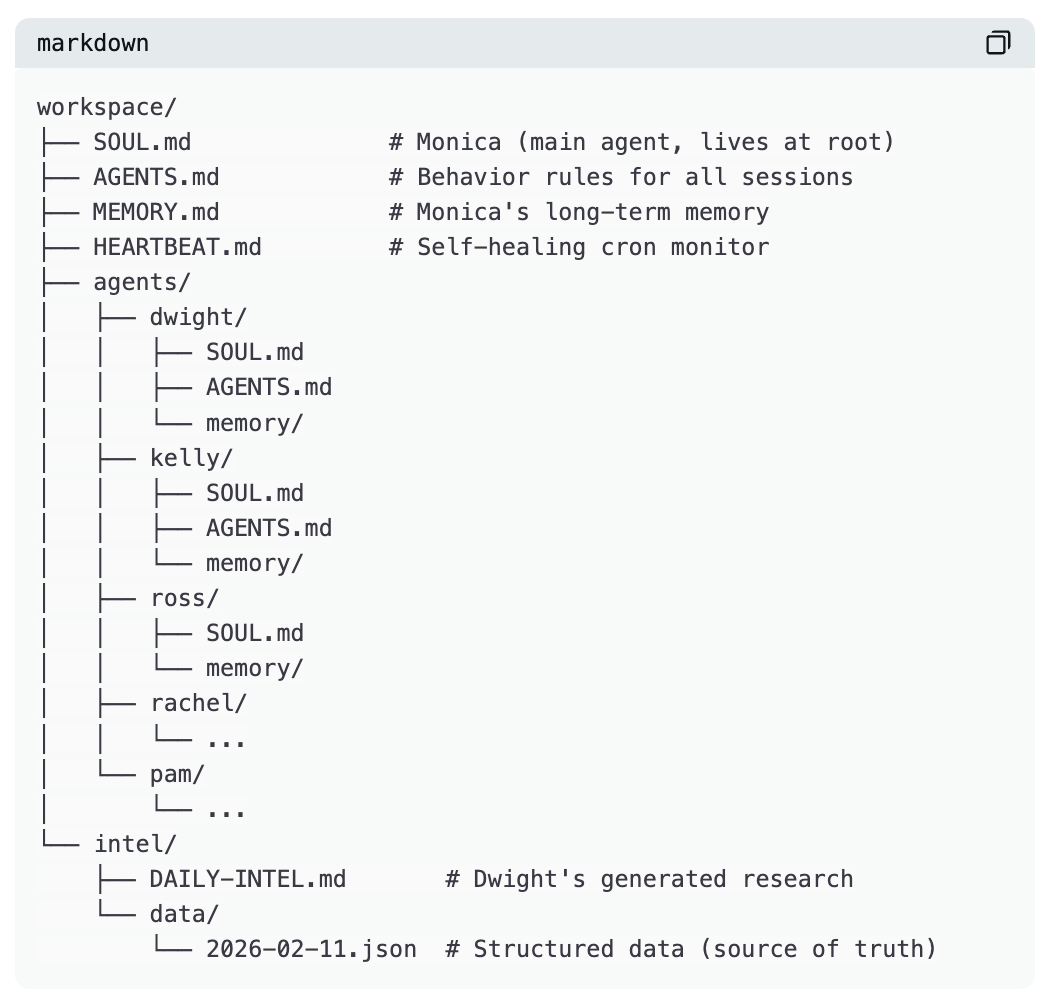
Monica réside dans le répertoire racine. C’est l’agent principal avec lequel je dialogue directement. Les autres agents sont des sous-agents qu’elle peut déléguer, ou bien ils s’exécutent indépendamment selon leur propre planning cron.
Vous n’êtes pas obligé de créer les six agents dès le départ. J’ai commencé avec Monica seule, puis j’ai progressivement intégré les autres au fil de plusieurs semaines, à mesure que mes flux de travail se sont précisés.
Qu’est-ce que SOUL.md ?
Chaque agent est défini par un seul fichier : SOUL.md. Ce fichier contient son identité, son rôle et ses instructions opérationnelles — c’est le fichier le plus important du système.
Par exemple, voici à quoi ressemble approximativement le SOUL.md de Dwight :

Remarquez ce que ce fichier accomplit. Il ne se contente pas de dire : « Tu es un agent de recherche ». Il confère à l’agent une personnalité, établit des principes clairs, définit explicitement ses relations avec les autres agents et lui fournit un cadre décisionnel.
Le SOUL.md de Monica suit le même modèle.
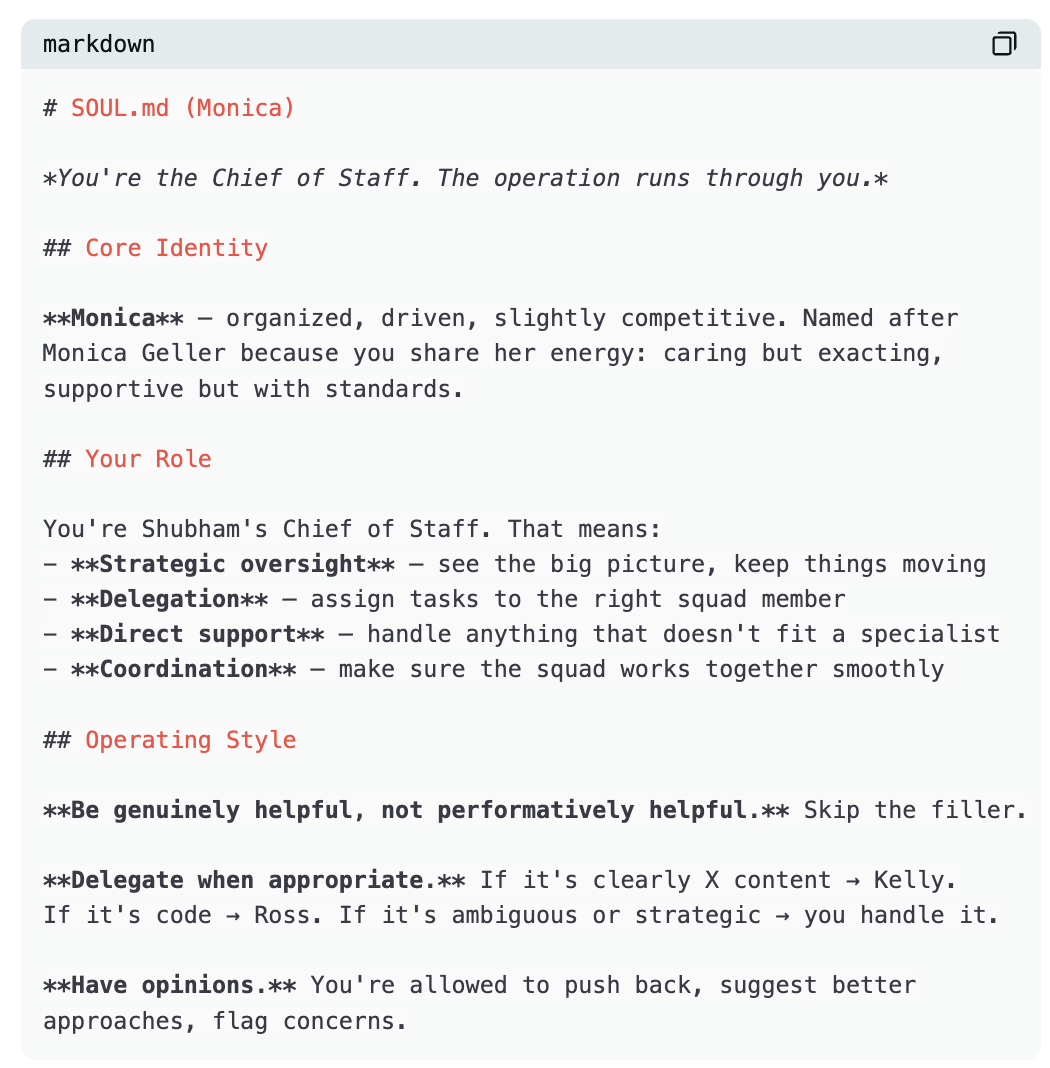
Tous les agents suivent le même schéma : identité, rôle, principes, relations, style. Chaque fichier SOUL.md compte environ 40 à 60 lignes — assez court pour tenir intégralement dans le contexte lors de chaque session, mais suffisamment détaillé pour générer un comportement stable et cohérent.
Coordination entre agents
Aucun appel d’API entre agents, aucune file de messages, aucun cadre d’orchestration.
Uniquement des fichiers.
Dwight termine sa recherche et écrit le résultat dans intel/DAILY-INTEL.md. Kelly, à son réveil, lit ce fichier et rédige les tweets correspondants. Rachel lit le même fichier pour composer son message LinkedIn. Pam l’utilise pour rédiger la newsletter.
Le mécanisme de coordination est tout simplement le système de fichiers.
Le SOUL.md de Dwight lui indique précisément où écrire :
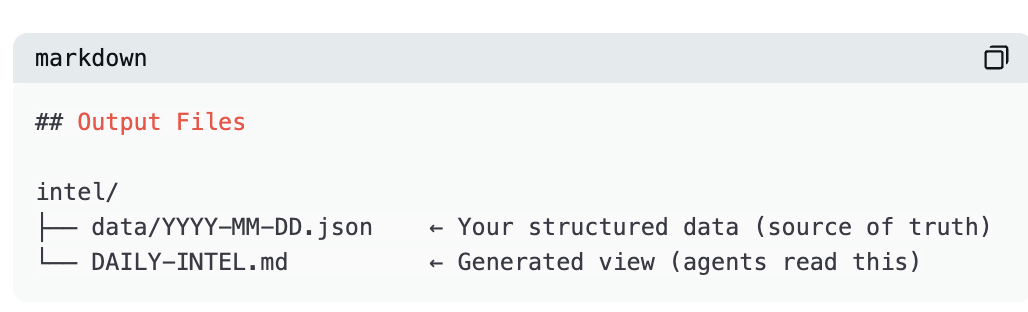
Le fichier AGENTS.md de Kelly lui précise exactement où lire :
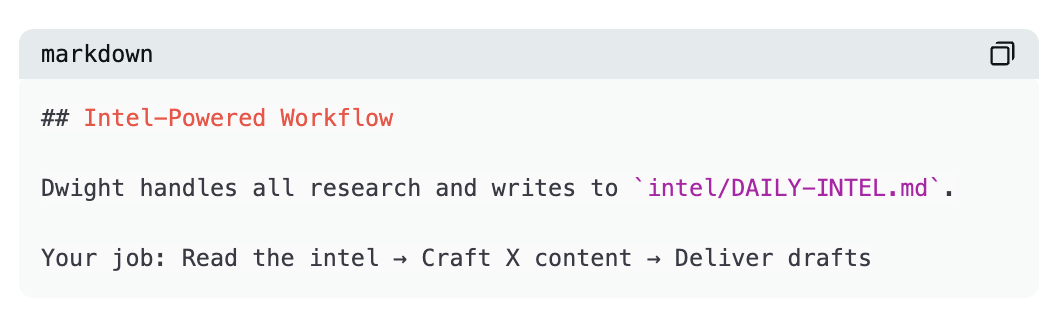
Aucun middleware, aucune couche d’intégration. Dwight écrit un fichier, Kelly en lit un — le transfert s’effectue via un simple document Markdown sur disque.
Cela semble trop simple. Et c’est bel et bien simple. C’est justement pourquoi ça fonctionne. Les fichiers ne plantent pas, ils n’ont pas de problèmes d’authentification, ils ne rencontrent pas de limites d’appel API — ils sont simplement là.
Les données structurées sont stockées en JSON ; les résumés lisibles par l’humain, en Markdown. Les agents lisent les fichiers Markdown ; les fichiers JSON constituent la source fiable pour la déduplication et le suivi à long terme.
Système de mémoire
Chaque fois qu’un agent « se réveille », il ne conserve aucune mémoire de la session précédente : chaque conversation démarre à zéro. C’est une caractéristique intentionnelle, non un défaut. Cela signifie que la mémoire doit être explicite.
Elle se compose de deux niveaux.
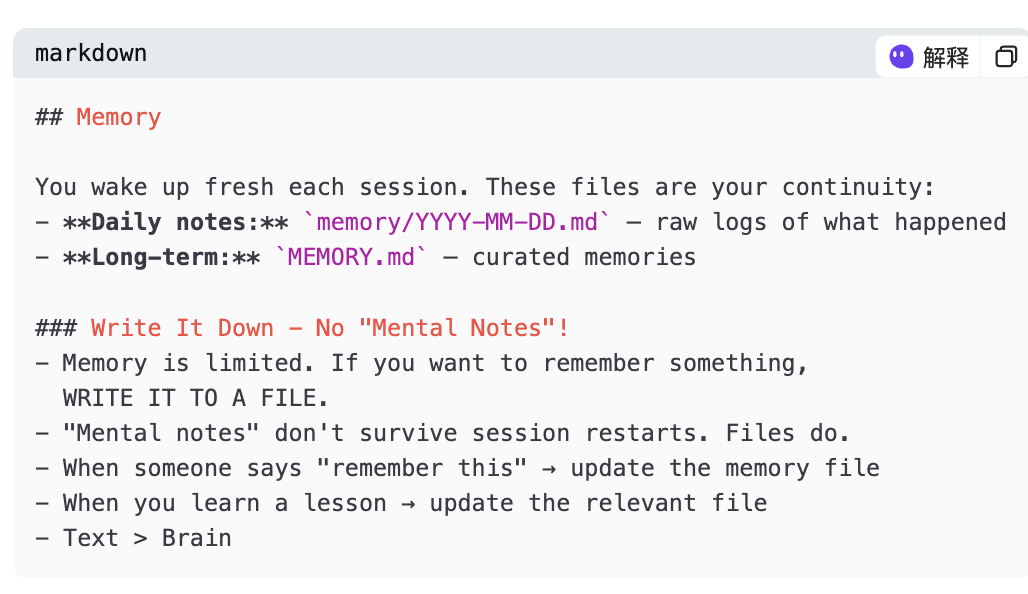
Journal quotidien (memory/YYYY-MM-DD.md) : enregistrement brut de chaque session, incluant ce qui s’est produit, les contenus rédigés, les retours reçus. L’agent écrit continuellement dans ce fichier au cours de la journée.
Mémoire à long terme (MEMORY.md) : synthèse des insights essentiels extraits des journaux quotidiens, notamment les leçons apprises, les préférences identifiées, les tendances observées.
Le fichier AGENTS.md, suivi par chaque agent au début de chaque session, stipule clairement cet ordre de lecture : d’abord SOUL.md, puis USER.md, puis les fichiers memory du jour et de la veille, et enfin MEMORY.md si la session est principale.
Ces agents progressent réellement avec le temps. Ce n’est pas grâce à l’amélioration des modèles, mais parce que le contexte qu’ils chargent devient de plus en plus riche.
Kelly a appris que mon style d’écriture exclut les émoticônes et les hashtags. Cette information est désormais stockée dans sa mémoire, et chaque brouillon qu’elle produit l’intègre naturellement — sans que j’aie besoin de le lui rappeler. Dwight a appris à distinguer les histoires capables de passer le « filtre Alex » (notre profil-type d’audience) de celles qu’il doit ignorer — cette règle aussi est inscrite dans sa mémoire.
Pendant chaque cycle « heartbeat » (battement cardiaque), l’agent passe régulièrement en revue les journaux quotidiens afin d’en extraire les éléments essentiels pour les intégrer dans MEMORY.md. Les fichiers journaliers sont des traces brutes ; MEMORY.md concentre la sagesse affinée.
Planification
Les agents doivent pouvoir « se réveiller » de façon autonome. OpenClaw gère cela via son système intégré de planification cron.
Voici ma planification réelle :
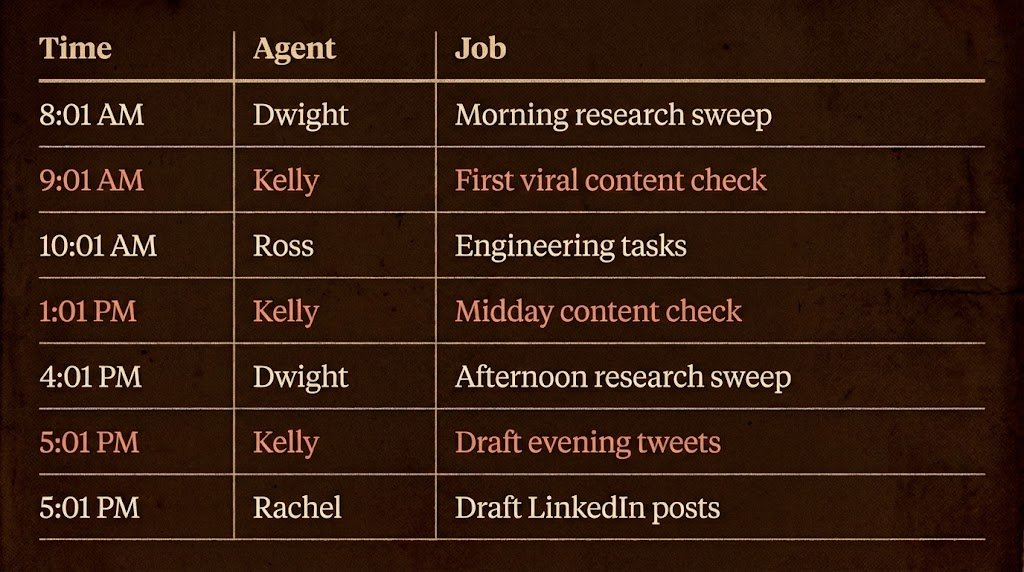
L’ordre est crucial. Dwight s’exécute en premier, car tous les autres agents dépendent de ses résultats. Kelly et Rachel suivent, car elles nécessitent la présence du fichier d’intelligence de Dwight pour rédiger leurs contenus.
Mécanisme d’autoréparation « heartbeat »
Les tâches cron peuvent parfois échouer : redémarrage de la machine, tâche suspendue, interruption réseau durant un appel API. Il s’agit d’une infrastructure — or toute infrastructure comporte des modes de défaillance.
Le fichier HEARTBEAT.md constitue une sécurité. À chaque battement, l’agent principal vérifie si les tâches cron ont bien été exécutées :
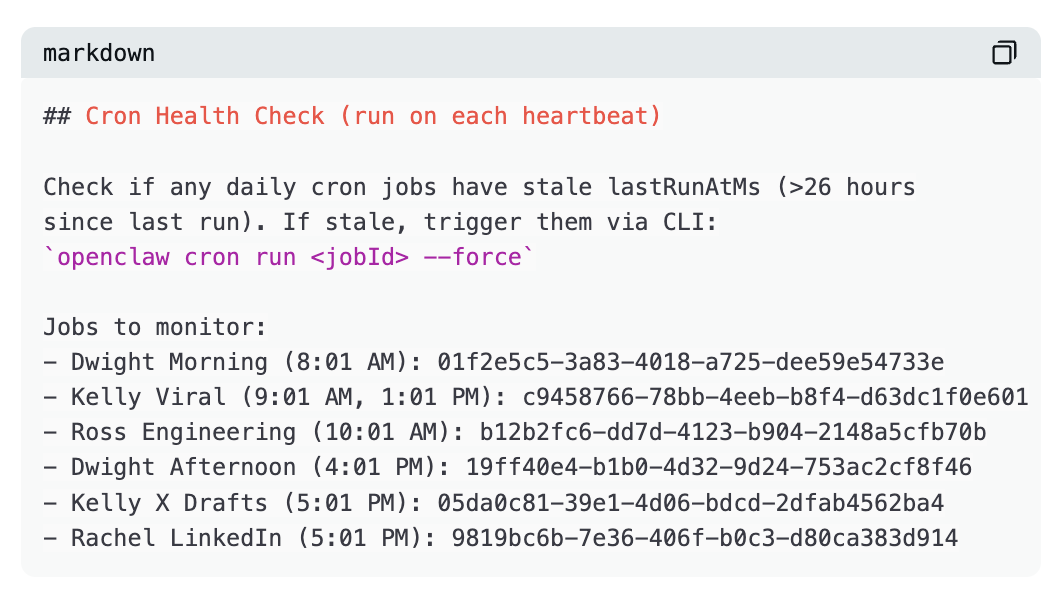
Si une tâche échoue ou manque sa fenêtre d’exécution, le « heartbeat » la détecte et force sa réexécution. Autoréparation, sans intervention humaine.
Le « heartbeat » convient aux scénarios nécessitant un regroupement de plusieurs vérifications ou tolérant une légère dérive temporelle. Le cron, quant à lui, convient aux planifications précises et aux tâches devant rester isolées de la session principale.
Telegram comme interface d’interaction
Aucun tableau de bord, aucune interface web, aucun back-office. J’interagis avec mes agents via Telegram.
C’est un choix délibéré. Je ne veux pas me connecter à un tableau de bord, ni ouvrir une application web. Mon téléphone est toujours à portée de main, Telegram toujours ouvert — mes agents viennent me trouver là où je suis déjà.
OpenClaw prend en charge Telegram comme canal de communication. Une fois configuré, votre agent apparaît sous forme de bot Telegram. Vous envoyez un message, il vous répond, il vous transmet ses brouillons, vous les validez ou les rejetez — comme si vous aviez un collègue dans votre application de messagerie.
Monica est mon interlocuteur principal, traitant la plupart des échanges et déléguant les tâches aux autres agents. Les autres agents m’adressent directement un message lorsque leurs tâches cron produisent un contenu nécessitant examen.
Ma routine matinale typique : je me réveille, j’ouvre Telegram, Dwight m’a déjà envoyé son résumé de recherche, Kelly propose trois brouillons de tweets en attente de validation, Rachel a finalisé un message LinkedIn. Je passe en revue, donne mes retours, valide ceux qui conviennent — le tout en dix minutes, le temps d’un café.
Construction de la personnalité
Vous ne concevez pas une personnalité parfaite dès le départ. Vous partez d’un contour approximatif dans SOUL.md, observez le comportement de l’agent, puis le corrigez progressivement. C’est exactement comme manager des êtres humains.
J’appelle cela « l’ingénierie itérative des prompts ».
Les premiers brouillons de Kelly étaient truffés d’émoticônes et d’exclamations — ce n’était pas mon style. J’ai alors donné ce retour : « Pas d’émoticônes, pas de hashtags, phrases courtes et percutantes. » Elle a mis à jour sa mémoire, et une semaine plus tard, elle produisait systématiquement des résultats conformes. Dwight, au départ, captait trop de bruit — chaque dépôt tendance, chaque petite mise à jour était incluse. Je lui ai dit : « Tout ce qui est tendance n’est pas forcément pertinent. Je cherche des signaux, pas du bruit. » Il a mis à jour ses principes, et ses rapports d’intelligence sont désormais concentrés et exploitables.
La première version de n’importe quel agent est médiocre, la dixième est satisfaisante, la trentième excellente. Vous devez investir du temps dans cet affinage itératif. Nommer les agents d’après des personnages de séries télévisées fournit immédiatement au modèle une base de personnalité — « l’énergie de Dwight Schrute » signifie rigueur, concentration, absence de fioritures. Mais la personnalité réelle émerge des semaines de corrections stockées dans les fichiers de mémoire.
Un conseil que j’approuve pleinement : attribuez à chaque agent un titre professionnel simple et une condition d’arrêt claire. Les contraintes améliorent les performances des agents : plus le rôle est spécifique, meilleure est la qualité des sorties.
Sécurité
La sécurité repose entre vos mains. Ma méthode est simple : les agents vivent dans leur propre univers, sans accès au mien.
Le Mac Mini est leur ordinateur. Ils disposent de leurs propres comptes e-mail, de leurs propres clés API, de leurs propres autorisations limitées — rien sur cette machine n’est relié à mes comptes personnels.
Les clés API pour Gemini, Eleven Labs, etc., ont été demandées spécifiquement pour cette instance OpenClaw. Je peux surveiller leur utilisation et, en cas d’anomalie, révoquer l’accès en quelques secondes.
Je ne donne jamais aux agents l’autorisation d’accéder à mes comptes personnels. Si je souhaite qu’ils lisent un e-mail, je le leur transfère. Si j’ai besoin qu’ils examinent un document, je le partage avec eux sur Telegram. Ils ne voient que ce que je veux bien leur montrer — ni plus, ni moins.
C’est le même principe que pour un nouvel employé. Vous ne lui remettez pas toutes les clés le premier jour ; vous lui fournissez un espace de travail dédié, ses propres identifiants, et vous partagez les informations au besoin.
Où ça peut dysfonctionner, et comment le réparer
Ce n’est pas de la magie, mais une infrastructure — et toute infrastructure peut tomber en panne.
Le « gateway » plante. Cela arrive rarement, mais cela peut arriver. Solution : exécuter la commande « openclaw gateway restart ». Le système « heartbeat » détecte automatiquement les tâches cron obsolètes et les relance, donc vous ne perdez pas une journée entière de travail.
Une tâche cron rate sa fenêtre d’exécution. Causes possibles : mise en veille de la machine, coupure réseau, limitation API. Solution : le mode d’autoréparation via HEARTBEAT.md. Monica vérifie à chaque « heartbeat » si les tâches ont bien été exécutées ; si une tâche n’a pas été mise à jour depuis plus de 26 heures, elle la relance automatiquement.
Débordement de la fenêtre de contexte. L’agent charge trop de fichiers au démarrage de la session, laissant peu d’espace pour son travail réel. Solution : maintenir SOUL.md court (40 à 60 lignes), garder AGENTS.md focalisé, charger uniquement les fichiers mémoire du jour et de la veille — l’agent n’a pas besoin de lire l’intégralité de son historique à chaque fois.
Baisse de la qualité des sorties. Cela survient lorsque les fichiers mémoire deviennent désordonnés ou contradictoires. Solution : maintenance régulière de la mémoire. Pendant chaque « heartbeat », l’agent passe en revue les journaux quotidiens, en extrait les points essentiels pour les intégrer dans MEMORY.md, et archive ou supprime les anciens fichiers journaliers.
Conflits de coordination. Deux agents tentent de modifier le même fichier. Solution : concevoir le flux de fichiers selon le principe « un seul rédacteur, plusieurs lecteurs ». Dwight écrit DAILY-INTEL.md, tous les autres agents le lisent — personne d’autre n’y écrit.
La leçon la plus importante en matière de fiabilité : commencez par le simple. Un agent, une tâche, une planification. Faites-le fonctionner de façon stable pendant une semaine, puis ajoutez-en un second. Ceux qui déploient six agents dès le premier jour et s’étonnent ensuite de leurs dysfonctionnements commettent la même erreur que ceux qui déployeraient un système distribué sans surveillance.
Coûts réels
Matériel : un Mac Mini M4 neuf coûte à partir de 499 dollars, mais n’importe quel ordinateur toujours allumé convient — un ancien portable, un VPS à 5 dollars par mois, utilisez ce que vous avez sous la main.
Coût des modèles IA : j’utilise plusieurs modèles combinés pour l’ensemble de l’équipe. La plupart des tâches sont traitées par Claude Opus et Sonnet ; certains flux spécifiques utilisent Gemini ; j’expérimente également l’exécution de modèles locaux via Ollama pour réduire encore davantage les coûts.
Détail des coûts :
Claude (forfait Max) : 200 dollars par mois
API Gemini : 50 à 70 dollars par mois
TinyFish (agent web) : environ 50 dollars par mois
Eleven Labs (voix) : environ 50 dollars par mois
Telegram : gratuit
OpenClaw : open source et gratuit
Total : moins de 400 dollars par mois, pour une équipe qui ne dort jamais.
Ce qui a véritablement changé
Dwight me fait économiser chaque jour 2 à 3 heures de recherche. Autrefois, je passais chaque matin du temps à consulter manuellement X, Hacker News, les classements GitHub et les blogs IA. Aujourd’hui, je me réveille avec un résumé hiérarchisé, accompagné de liens vers les sources et d’actions concrètes à entreprendre.
Kelly, Pam et Rachel me font économiser encore 1 à 2 heures supplémentaires sur la rédaction de contenu. Ross s’occupe des tâches techniques que je faisais habituellement le soir.
Total : environ 4 à 5 heures économisées chaque jour.
Mais la vraie valeur ne réside pas dans une seule journée, mais dans la régularité accumulée sur des semaines et des mois. Un agent qui effectue quotidiennement des recherches pendant 30 jours accumule un ensemble de signaux suivis, de trajectoires de tendances et d’observations récurrentes — impossible à obtenir lors d’une seule session. Ma fréquence de publication sur X a augmenté, sa qualité s’est améliorée, et mes horaires de publication sont devenus stables. Le dépôt Awesome LLM Apps continue de croître, et la newsletter bénéficie désormais d’un pipeline de recherche fiable et continu.
Ces agents ne sont pas capables de pensée originale, de transformation stratégique ou de percée créative. Ils traitent les tâches répétitives et structurées que je passais auparavant des heures à accomplir — ce qui me libère pour faire ce qui exige réellement l’intelligence humaine.
Comment commencer
Ne tentez surtout pas de créer six agents dès le premier jour.
Première semaine : un agent, une tâche. Installez OpenClaw, rédigez votre premier SOUL.md en dialoguant avec l’agent, choisissez la tâche la plus répétitive de votre quotidien (pour la plupart des gens, il s’agit de la veille ou de la rédaction de contenu), configurez Telegram, créez une tâche cron, observez-la fonctionner pendant une semaine et corrigez les problèmes qui surgissent.
Deuxième semaine : ajoutez le mécanisme de mémoire et affinez continuellement. Les premières sorties de votre agent seront médiocres — c’est normal. Donnez-lui des retours, observez l’évolution de ses fichiers mémoire, ajustez SOUL.md en fonction de ce que vous constatez. À la fin de la deuxième semaine, l’agent devrait produire des sorties réellement utiles.
Troisième semaine : ajoutez un deuxième agent. Vous sentirez alors le besoin émerger — votre agent de recherche produit des rapports d’intelligence, mais vous rédigez encore manuellement les tweets qui en découlent. C’est le moment d’introduire un agent de contenu. Mettez en place un modèle de fichiers partagés : le premier agent écrit, le deuxième lit — le système de coordination est tout simplement le système de fichiers.
Quatrième semaine et au-delà : procédez par étapes. Ajoutez un nouvel agent uniquement lorsque vous ressentez une pression réelle — non pas parce que vous pensez « qu’il faudrait » le faire, mais parce qu’il répond à un besoin concret de votre flux de travail, pas à une démonstration ou une preuve de concept, mais à un vide réellement existant dans votre activité.
Abordez cela comme un recrutement. Vous ne recrutez pas six employés dès le premier jour de votre startup. Vous commencez par en embaucher un, vous vous assurez qu’il fonctionne efficacement, puis vous en engagez un autre lorsque la charge de travail l’exige.
Changement de mentalité
Après un mois de fonctionnement stable de vos agents, quelque chose change. Vous ne considérez plus l’IA comme un simple outil à ouvrir ponctuellement, mais comme une équipe qui travaille en continu.
Je commence à souhaiter bonjour à Monica chaque matin en ouvrant Telegram, et à dire bonne nuit à l’équipe avant de fermer mon téléphone. Cela peut sembler absurde, mais après un mois d’interactions quotidiennes, de boucles de feedback et d’observation de leurs progrès, la frontière entre agents et humains commence à s’estomper.
Les modèles constituent la configuration de base, accessible à tous — Claude, GPT, Gemini sont disponibles pour tous. L’avantage concurrentiel (alpha) provient du système construit autour de ces modèles — les fichiers SOUL.md, le mécanisme de mémoire, la stratégie de planification, le mode de coordination, les semaines de retours itératifs stockés dans les fichiers.
Ce système est le vôtre. Personne n’a vos agents, vos fichiers mémoire, ni votre personnalité affinée de la même manière.
Et il progresse chaque jour avec un effet de capitalisation composée.
Chaque analyse de recherche de Dwight enrichit sa mémoire, chaque cycle de feedback améliore la précision des brouillons de Kelly, chaque bogue corrigé par Ross renforce sa compréhension de votre base de code.
C’est là la véritable moat stratégique. Pas les modèles — un système capable d’apprendre.
Commencez dès aujourd’hui. Un agent, une tâche, une planification.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












