

La Sainte Grâce de l'IA crypto : exploration des frontières de l'entraînement décentralisé
TechFlow SélectionTechFlow Sélection
La Sainte Grâce de l'IA crypto : exploration des frontières de l'entraînement décentralisé
La décentralisation n'est pas seulement un moyen, elle est en soi une valeur.
Rédaction : 0xjacobzhao et ChatGPT 4o
Merci particulièrement à Advait Jayant (Peri Labs), Sven Wellmann (Polychain Capital), Chao (Metropolis DAO), Jiahao (Flock), Alexander Long (Pluralis Research), Ben Fielding & Jeff Amico (Gensyn) pour leurs suggestions et retours.
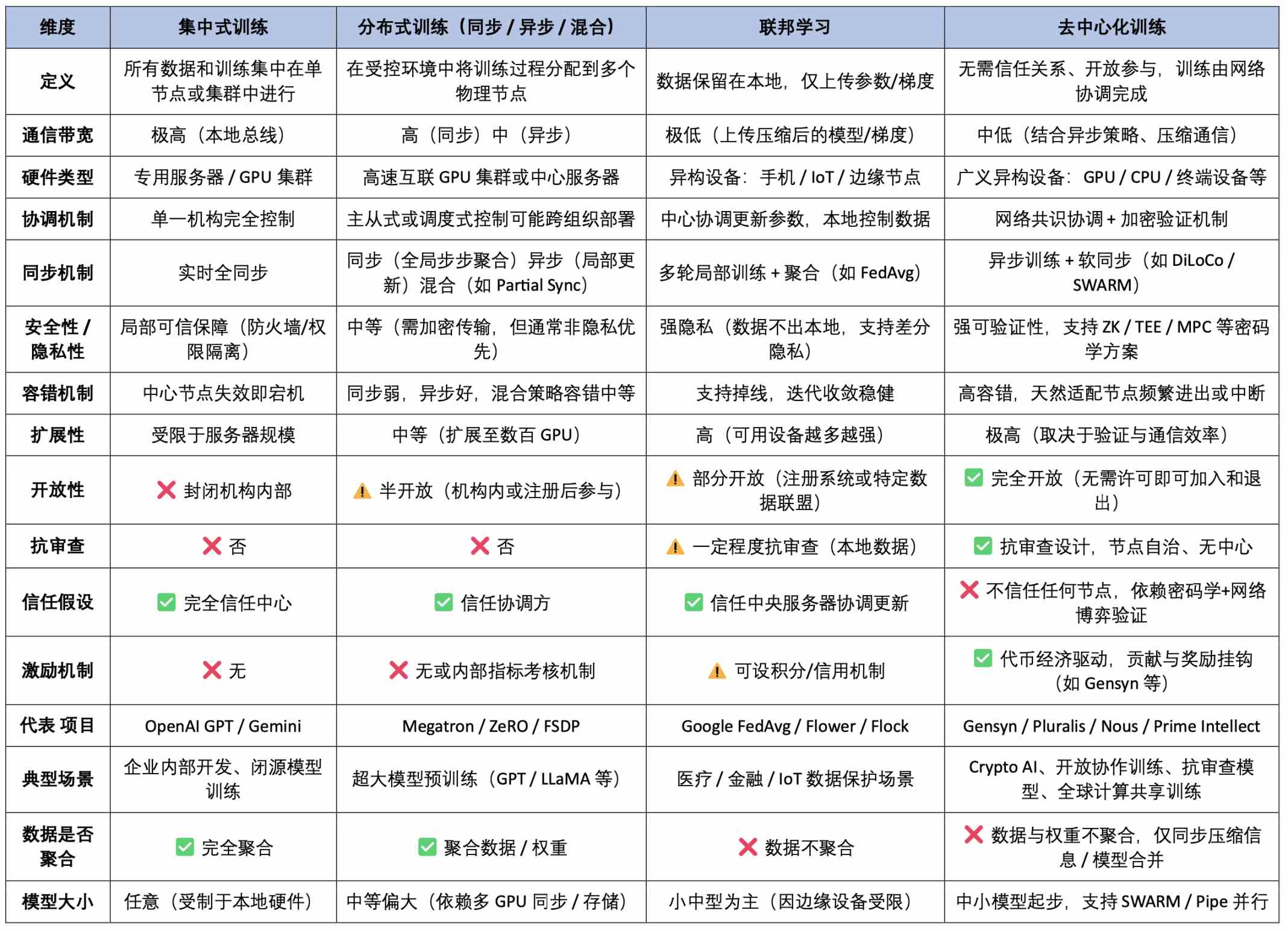
Dans la chaîne de valeur complète de l'IA, l'entraînement des modèles est la phase la plus gourmande en ressources et la plus exigeante sur le plan technologique, déterminant directement les capacités maximales d'un modèle ainsi que son efficacité dans des applications concrètes. Comparé à l'inférence, qui repose sur des appels légers, l'entraînement exige un investissement continu en puissance de calcul à grande échelle, des processus complexes de traitement des données et des algorithmes d’optimisation intensifs. C'est véritablement l'« industrie lourde » de la construction des systèmes d'intelligence artificielle. Du point de vue architectural, les méthodes d'entraînement peuvent être classées en quatre catégories : entraînement centralisé, entraînement distribué, apprentissage fédéré, et entraînement décentralisé — ce dernier étant au cœur de cet article.
L'entraînement centralisé est la méthode traditionnelle la plus courante, où une seule entité mène l’intégralité du processus d’entraînement sur un cluster haute performance local. Tous les composants — matériel (ex. GPU NVIDIA), logiciels bas niveau (CUDA, cuDNN), système d’ordonnancement de cluster (comme Kubernetes), jusqu’au cadre d’entraînement (ex. PyTorch avec backend NCCL) — sont coordonnés par un système de contrôle unique. Cette architecture fortement intégrée permet une efficacité optimale en matière de partage mémoire, synchronisation des gradients et mécanismes de tolérance aux pannes, ce qui convient parfaitement à l'entraînement de grands modèles tels que GPT ou Gemini. Bien qu’il soit efficace et offrant un bon contrôle des ressources, ce modèle souffre toutefois de problèmes comme le monopole des données, les barrières d’accès aux ressources, une forte consommation énergétique et les risques liés aux points uniques de défaillance.
L'entraînement distribué (Distributed Training) est actuellement la méthode dominante pour former les grands modèles. Son principe fondamental consiste à diviser la tâche d'entraînement puis à la répartir entre plusieurs machines qui collaborent afin de surmonter les limites de calcul et de stockage d’un seul appareil. Bien que physiquement « distribué », l’ensemble du processus reste contrôlé de manière centralisée, souvent exécuté dans un réseau local haut débit, utilisant des interconnexions rapides comme NVLink, avec un nœud maître coordonnant toutes les sous-tâches. Les approches principales incluent :
-
Parallélisme de données (Data Parallel) : chaque nœud entraîne sur des données différentes mais partage les mêmes paramètres du modèle ; nécessite une synchronisation des poids du modèle.
-
Parallélisme de modèle (Model Parallel) : différentes parties du modèle sont réparties sur différents nœuds, permettant une forte extensibilité.
-
Parallélisme de pipeline (Pipeline Parallel) : exécution séquentielle par étapes, augmentant le débit global.
-
Parallélisme tensoriel (Tensor Parallel) : découpage fin des opérations matricielles, améliorant le niveau de parallélisme.
L'entraînement distribué correspond donc à une combinaison de « contrôle centralisé + exécution distribuée », similaire à un patron dirigeant à distance plusieurs employés travaillant dans différents bureaux. À ce jour, presque tous les grands modèles dominants (GPT-4, Gemini, LLaMA, etc.) ont été formés selon cette méthode.
L'entraînement décentralisé (Decentralized Training) représente une voie future plus ouverte et résistante à la censure. Sa caractéristique principale réside dans la collaboration de multiples nœuds mutuellement non fiables (pouvant être des ordinateurs personnels, des GPU cloud ou des dispositifs périphériques), sans aucun coordinateur central, pour accomplir conjointement une tâche d’entraînement. Cette coordination s’appuie généralement sur des protocoles pilotant la distribution des tâches et utilise des mécanismes incitatifs cryptographiques pour garantir l’honnêteté des contributions. Les principaux défis rencontrés sont :
-
Hétérogénéité des équipements et difficulté de partitionnement : la coordination d'appareils hétérogènes est complexe, et l'efficacité de la division des tâches est faible.
-
Goulot d’étranglement de communication : instabilité du réseau, synchronisation des gradients difficile.
-
Absence d’environnement d’exécution fiable : absence d’environnement sécurisé, rendant difficile la vérification que les nœuds participent réellement au calcul.
-
Absence de coordination unifiée : sans orchestrateur central, la distribution des tâches et la gestion des exceptions deviennent complexes.
On peut comparer l'entraînement décentralisé à un groupe mondial de bénévoles contribuant chacun à la formation d’un modèle. Toutefois, un « entraînement décentralisé à grande échelle effectivement réalisable » reste un défi technique systémique, impliquant l’architecture système, les protocoles de communication, la sécurité cryptographique, les mécanismes économiques et la validation des modèles. La capacité à « coopérer efficacement, inciter à l’honnêteté et produire des résultats corrects » en est encore au stade expérimental précoce.
L'apprentissage fédéré (Federated Learning), quant à lui, constitue une transition entre entraînement distribué et décentralisé. Il met l'accent sur la conservation locale des données et l’agrégation centralisée des paramètres du modèle, ce qui le rend adapté aux scénarios sensibles à la confidentialité (comme la santé ou la finance). Bien qu’il bénéficie de la structure ingénierie distribuée et de la capacité de coordination locale, tout en préservant l’avantage de la dispersion des données propre à l’entraînement décentralisé, il dépend toujours d’un coordinateur de confiance et ne possède pas pleinement les caractéristiques d’ouverture totale ni de résistance à la censure. On peut y voir une forme de « décentralisation contrôlée », relativement modérée en termes de tâches d’entraînement, de structure de confiance et de mécanismes de communication, mieux adaptée comme architecture transitoire pour le déploiement industriel.
Tableau comparatif complet des paradigmes d’entraînement IA (Architecture technique × Confiance et incitation × Caractéristiques d’application)
Limites, opportunités et trajectoire réaliste de l’entraînement décentralisé
En regardant les paradigmes d’entraînement, l’entraînement décentralisé ne convient pas à tous les types de tâches. Dans certains cas, en raison de la complexité structurelle, de besoins élevés en ressources ou de difficultés de collaboration, il est naturellement mal adapté à une exécution efficace entre des nœuds hétérogènes et non fiables. Par exemple, l'entraînement de grands modèles repose souvent sur une mémoire vidéo élevée, une latence faible et une bande passante rapide, ce qui rend difficile leur découpage et leur synchronisation dans un réseau ouvert. Les tâches soumises à de fortes contraintes de confidentialité ou de propriété des données (comme dans le médical, la finance ou les données classifiées) sont limitées par des obligations légales et éthiques, empêchant tout partage ouvert. Enfin, les tâches manquant de base incitative à la collaboration (comme les modèles propriétaires d’entreprise ou les prototypes internes) ne suscitent pas d’engagement externe. Ces limites définissent ensemble les contraintes réelles actuelles de l’entraînement décentralisé.
Cela ne signifie toutefois pas que l’entraînement décentralisé soit une idée creuse. En réalité, pour les tâches légères, facilement parallélisables et incitables, il présente des perspectives d’application claires. Parmi celles-ci, on peut citer : le fine-tuning LoRA, les tâches postérieures d’alignement comportemental (telles que RLHF, DPO), les tâches de collecte collaborative de données et d’annotation, l’entraînement de petits modèles de base à ressources contrôlées, ou encore les scénarios d’entraînement collaboratif impliquant des dispositifs périphériques. Ces tâches ont généralement une forte parallélisation, un couplage faible et tolèrent bien les différences de puissance de calcul, ce qui les rend très adaptées à une formation collaborative via des réseaux P2P, des protocoles Swarm ou des optimiseurs distribués.
Tableau synthétique de l’adaptabilité aux tâches d’entraînement décentralisé

Analyse des projets emblématiques d’entraînement décentralisé
Actuellement, dans les domaines avancés de l’entraînement décentralisé et de l’apprentissage fédéré, les projets blockchain représentatifs incluent Prime Intellect, Pluralis.ai, Gensyn, Nous Research et Flock.io. En termes d’innovation technologique et de difficulté de mise en œuvre, Prime Intellect, Nous Research et Pluralis.ai proposent des explorations originales significatives au niveau de l’architecture système et de la conception algorithmique, incarnant ainsi les orientations théoriques les plus avancées. En revanche, Gensyn et Flock.io adoptent des approches plus claires, avec déjà des progrès visibles en ingénierie. Cet article analysera successivement les technologies clés et architectures techniques de ces cinq projets, puis examinera leurs différences et complémentarités au sein de l’écosystème d’entraînement IA décentralisé.
Prime Intellect : pionnier d’un réseau collaboratif d’apprentissage par renforcement avec trajectoire vérifiable
Prime Intellect vise à construire un réseau d’entraînement IA sans confiance, permettant à quiconque de participer et d’être récompensé de manière fiable pour sa contribution computationnelle. Le projet ambitionne de créer un système d’entraînement IA décentralisé, vérifiable, ouvert et doté d’un mécanisme incitatif complet, reposant sur trois modules clés : PRIME-RL, TOPLOC et SHARDCAST.
1. Architecture du protocole Prime Intellect et valeur des modules clés

2. Mécanismes clés d’entraînement expliqués en détail
PRIME-RL : architecture de tâche d’apprentissage par renforcement asynchrone découplée
PRIME-RL est un cadre d'exécution et de modélisation des tâches conçu spécifiquement par Prime Intellect pour l'entraînement décentralisé, pensé pour les réseaux hétérogènes et la participation asynchrone. Il privilégie l’apprentissage par renforcement comme cas d’usage principal, en découplant structurellement les phases d’entraînement, d’inférence et de soumission des poids. Chaque nœud peut ainsi boucler localement de manière indépendante, tout en s’interfaçant de façon standardisée avec les mécanismes de vérification et d’agrégation. Comparé au flux supervisé traditionnel, PRIME-RL est mieux adapté à un environnement sans coordinateur central, réduisant la complexité du système tout en posant les bases d’une formation évolutive et multi-tâches.
TOPLOC : mécanisme léger de vérification du comportement d’entraînement
TOPLOC (Trusted Observation & Policy-Locality Check) est le mécanisme central de vérifiabilité proposé par Prime Intellect, permettant de déterminer si un nœud a réellement effectué un apprentissage stratégique valide à partir des données observées. Contrairement aux solutions lourdes comme ZKML, TOPLOC n’exige pas de recalcul complet du modèle. Il se contente d’analyser la cohérence locale entre les « séquences d’observation ↔ mises à jour de politique », réalisant ainsi une vérification structurelle légère. Il transforme pour la première fois les trajectoires comportementales pendant l’entraînement en objets vérifiables, constituant une innovation clé vers une allocation de récompense sans confiance, et ouvrant une voie praticable vers un réseau collaboratif d’entraînement vérifiable, auditable et incitatif.
SHARDCAST : protocole d’agrégation et de diffusion asynchrone des poids
SHARDCAST est un protocole d’agrégation et de propagation des poids, spécialement optimisé par Prime Intellect pour des environnements réels — asynchrones, à bande passante limitée, et avec des nœuds aux états changeants. Combinant le mécanisme de diffusion « gossip » et des stratégies de synchronisation locales, il permet à plusieurs nœuds de soumettre continuellement des mises à jour partielles même hors synchronisation, assurant une convergence progressive des poids et une évolution multivers. Comparé aux méthodes centralisées ou synchrones comme AllReduce, SHARDCAST améliore considérablement l’évolutivité et la tolérance aux pannes de l’entraînement décentralisé, servant de fondement essentiel à un consensus stable sur les poids et à des itérations continues d’entraînement.
OpenDiLoCo : cadre de communication asynchrone et parcimonieuse
OpenDiLoCo est un cadre d’optimisation de communication développé et publié en open source par l’équipe de Prime Intellect, basé sur le concept DiLoCo initialement proposé par DeepMind. Conçu pour relever les défis typiques de l’entraînement décentralisé — bande passante limitée, hétérogénéité des appareils et instabilité des nœuds — il repose sur un parallélisme de données et construit des topologies éparses (anneau, expander, small-world) pour éviter les coûts élevés de communication globale. Seules les interactions avec des voisins locaux sont nécessaires pour entraîner collaborativement le modèle. Grâce à la mise à jour asynchrone et à la reprise après panne, OpenDiLoCo permet même à des GPU grand public ou des dispositifs périphériques de participer de manière stable, augmentant fortement l’accessibilité à l’entraînement collaboratif mondial. C’est une infrastructure de communication clé pour bâtir un tel réseau.
PCCL : bibliothèque de communication collective
Le PCCL (Prime Collective Communication Library) est une bibliothèque de communication légère spécialement conçue par Prime Intellect pour l’entraînement IA décentralisé. Elle vise à surmonter les limites d’adaptation des bibliothèques traditionnelles (comme NCCL ou Gloo) face aux équipements hétérogènes et aux réseaux à faible bande passante. Supportant les topologies éparses, la compression des gradients, la synchronisation en basse précision et la reprise après interruption, PCCL fonctionne sur des GPU grand public et des nœuds instables. Elle constitue la couche basse supportant les capacités de communication asynchrone d’OpenDiLoCo, améliorant nettement la tolérance en bande passante et la compatibilité matérielle, comblant ainsi la « dernière étape » cruciale pour un réseau collaboratif vraiment ouvert et sans confiance.
3. Réseau d’incitation et répartition des rôles
Prime Intellect construit un réseau d’entraînement sans permission, vérifiable et doté d’incitations économiques, permettant à toute personne de participer et d’être récompensée selon sa contribution réelle. Le protocole repose sur trois rôles clés :
-
Initiateur de tâche : définit l’environnement d’entraînement, le modèle initial, la fonction de récompense et les critères de vérification.
-
Nœud d’entraînement : exécute l’entraînement local, soumet les mises à jour de poids et les trajectoires d’observation.
-
Nœud de vérification : utilise TOPLOC pour valider l’authenticité du comportement d’entraînement, participe au calcul des récompenses et à l’agrégation des politiques.
Le flux principal du protocole comprend : publication de la tâche, entraînement par les nœuds, vérification des trajectoires, agrégation des poids (via SHARDCAST) et distribution des récompenses — formant une boucle incitative centrée sur le « comportement d’entraînement authentique ».
4. INTELLECT-2 : lancement du premier modèle d’entraînement décentralisé vérifiable
En mai 2025, Prime Intellect a lancé INTELLECT-2, le premier grand modèle d’apprentissage par renforcement au monde entraîné de manière collaborative, asynchrone et sans confiance par des nœuds décentralisés, avec 32 milliards de paramètres. Ce modèle a été formé grâce à la collaboration de plus de 100 nœuds GPU hétérogènes répartis sur trois continents, utilisant une architecture entièrement asynchrone, avec plus de 400 heures d’entraînement. Cette réussite démontre la faisabilité et la stabilité d’un réseau de collaboration asynchrone. Plus qu’une percée technique, elle matérialise pour la première fois le paradigme de Prime Intellect : « l’entraînement comme consensus ». INTELLECT-2 intègre les modules clés PRIME-RL (structure d’entraînement asynchrone), TOPLOC (vérification du comportement) et SHARDCAST (agrégation asynchrone des poids), marquant ainsi la première mise en œuvre complète d’un réseau d’entraînement décentralisé ouvert, vérifiable et doté d’une boucle incitative économique.
Côté performance, INTELLECT-2 est basé sur QwQ-32B et a subi un entraînement RL spécialisé en code et mathématiques, le plaçant parmi les meilleurs modèles de fine-tuning RL open source. Bien qu’il n’égale pas encore des modèles fermés comme GPT-4 ou Gemini, sa véritable importance réside dans le fait qu’il s’agit du premier modèle décentralisé dont le processus d’entraînement est entièrement reproductible, vérifiable et auditables. Prime Intellect n’a pas seulement publié le modèle, mais surtout le processus d’entraînement lui-même — données, trajectoires de mise à jour, procédures de vérification et logique d’agrégation sont tous transparents. Un prototype de réseau d’entraînement décentralisé, ouvert à tous, collaboratif et partageant les bénéfices, est désormais une réalité.
5. Équipe et levée de fonds
Prime Intellect a levé 15 millions de dollars lors d’un tour de table en série A en février 2025, mené par Founders Fund, avec la participation de Menlo Ventures, Andrej Karpathy, Clem Delangue, Dylan Patel, Balaji Srinivasan, Emad Mostaque et Sandeep Nailwal. Précédemment, en avril 2024, le projet avait levé 5,5 millions de dollars lors d’un tour anticipé, co-dirigé par CoinFund et Distributed Global, avec également Compound VC, Collab + Currency et Protocol Labs. À ce jour, Prime Intellect a levé plus de 20 millions de dollars.
Ses cofondateurs sont Vincent Weisser et Johannes Hagemann. L’équipe rassemble des profils issus à la fois de l’IA et du Web3, avec des membres provenant de Meta AI, Google Research, OpenAI, Flashbots, Stability AI et de la Fondation Ethereum. Dotée d’une solide expertise en architecture système et en ingénierie distribuée, c’est l’une des rares équipes opérationnelles ayant réussi à entraîner un grand modèle décentralisé réel.
Pluralis : explorateur du paradigme d’entraînement collaboratif asynchrone, parallèle et compressé
Pluralis est un projet Web3 IA axé sur un « réseau d’entraînement collaboratif de confiance ». Son objectif central est de promouvoir un paradigme d’entraînement de modèles décentralisé, ouvert à tous et doté d’incitations à long terme. Contrairement aux chemins centralisés ou fermés dominants, Pluralis propose une nouvelle vision appelée « Protocol Learning » (Apprentissage par protocole) : protocoliser le processus d’entraînement des modèles, construisant ainsi un système d’entraînement ouvert, doté d’une boucle incitative endogène, via des mécanismes de collaboration vérifiables et une cartographie de propriété du modèle.
1. Concept central : Protocol Learning (Apprentissage par protocole)
Le Protocol Learning de Pluralis repose sur trois piliers clés :
-
Modèles non extractibles (Unmaterializable Models) : les poids du modèle sont fragmentés entre plusieurs nœuds ; aucun nœud isolé ne peut reconstituer le modèle complet, gardant ainsi les poids confidentiels. Cette conception fait naturellement du modèle un « actif du protocole », permettant le contrôle des accès, la protection contre les fuites et le lien avec la répartition des revenus.
-
Entraînement parallèle de modèles sur Internet (Model-parallel Training over Internet) : via une architecture parallèle de type pipeline asynchrone (SWARM), différents nœuds ne détiennent qu'une partie des poids, collaborant sur des réseaux à faible bande passante pour l’entraînement ou l’inférence.
-
Propriété partielle liée à la contribution (Partial Ownership for Incentives) : chaque participant obtient une propriété partielle du modèle proportionnelle à sa contribution, lui donnant droit à une part des revenus futurs et à la gouvernance du protocole.
2. Architecture technique du protocole Pluralis

3. Explication détaillée des mécanismes clés
Unmaterializable Models
Premièrement exposé dans « A Third Path: Protocol Learning », ce concept propose que les poids soient distribués sous forme fragmentée, garantissant que l’« actif modèle » ne puisse fonctionner que dans le réseau Swarm, assurant ainsi que son accès et ses revenus soient contrôlés par le protocole. Ce mécanisme est la condition préalable à une incitation durable pour l’entraînement décentralisé.
Asynchronous Model-Parallel Training
Dans « SWARM Parallel with Asynchronous Updates », Pluralis a mis en place une architecture parallèle de modèles asynchrone basée sur le pipeline, testée empiriquement sur LLaMA-3. L’innovation centrale réside dans l’introduction du mécanisme Nesterov Accelerated Gradient (NAG), corrigeant efficacement la dérive des gradients et les problèmes de convergence instable dus à l’asynchronisme, rendant ainsi l’entraînement entre appareils hétérogènes réalisable sur des réseaux à faible bande passante.
Column-Space Sparsification
Proposée dans « Beyond Top-K », cette méthode remplace le traditionnel Top-K par une compression de l’espace colonne sensible à la structure, évitant ainsi la destruction des chemins sémantiques. Elle préserve à la fois l’exactitude du modèle et l’efficacité de communication, réduisant de plus de 90 % les données échangées dans un environnement parallèle asynchrone. C’est une percée clé pour une communication efficace et structurée.
4. Positionnement technique et choix stratégique
Pluralis choisit clairement l’« entraînement parallèle de modèles asynchrone » comme axe principal, soulignant ses avantages par rapport au parallélisme de données :
-
Compatible avec les réseaux à faible bande passante et les nœuds non homogènes.
-
S’adapte à l’hétérogénéité des équipements, permettant la participation de GPU grand public.
-
Bénéficie d’une capacité d’ordonnancement élastique, supportant les connexions/déconnexions fréquentes.
-
Repose sur trois innovations clés : compression structurelle + mise à jour asynchrone + non-extractibilité des poids.
À ce jour, six articles techniques publiés sur le site officiel forment trois axes principaux :
-
Philosophie et vision : « A Third Path: Protocol Learning », « Why Decentralized Training Matters ».
-
Détails techniques : « SWARM Parallel », « Beyond Top-K », « Asynchronous Updates ».
-
Innovation institutionnelle : « Unmaterializable Models », « Partial Ownership Protocols ».
Pluralis n’a pas encore lancé de produit, de testnet ni publié de code, car la voie choisie est extrêmement exigeante : il faut d’abord résoudre des problèmes systémiques fondamentaux (architecture système, protocoles de communication, non-extractibilité des poids) avant de pouvoir encapsuler des services.
Dans un nouvel article publié en juin 2025 par Pluralis Research, le cadre d’entraînement décentralisé est étendu du pré-entraînement au fine-tuning, supportant les mises à jour asynchrones, la communication parcimonieuse et l’agrégation partielle des poids. Contrairement aux travaux antérieurs plus théoriques, cette avancée se concentre davantage sur la faisabilité pratique, marquant une maturité accrue de l’architecture sur tout le cycle d’entraînement.
5. Équipe et financement
Pluralis a levé 7,6 millions de dollars en financement de démarrage en 2025, co-dirigé par Union Square Ventures (USV) et CoinFund. Son fondateur, Alexander Long, détient un doctorat en apprentissage automatique, combinant expertise mathématique et recherche systémique. Tous les membres clés sont des chercheurs docteurs en apprentissage automatique, typique d’un projet orienté technologie, privilégiant la publication de papiers denses et de blogs techniques. L’équipe n’a pas encore constitué d’équipe commerciale ou marketing, se concentrant exclusivement sur les défis fondamentaux de l’architecture parallèle de modèles asynchrone à faible bande passante.
Gensyn : couche protocole d’entraînement décentralisé pilotée par l’exécution vérifiable
Gensyn est un projet Web3 IA centré sur l’« exécution fiable des tâches d’apprentissage profond ». Son objectif n’est pas de reconcevoir l’architecture du modèle ou le paradigme d’entraînement, mais de construire un réseau d’exécution distribué vérifiable, couvrant l’intégralité du cycle « distribution des tâches + exécution + vérification des résultats + incitation équitable ». Grâce à une architecture « entraînement hors chaîne + vérification sur chaîne », Gensyn crée un marché mondial d’entraînement efficace, ouvert et incitatif, rendant possible le concept de « mining par entraînement ».
1. Positionnement du projet : couche protocole d’exécution des tâches d’entraînement
Gensyn ne se concentre pas sur « comment entraîner », mais sur « qui entraîne, comment vérifier, comment répartir les revenus ». Il s’agit fondamentalement d’un protocole de calcul vérifiable pour les tâches d’entraînement, visant à résoudre :
-
Qui exécute la tâche ? (distribution de puissance de calcul et jumelage dynamique)
-
Comment vérifier le résultat ? (sans recalcul complet, uniquement les opérateurs litigieux)
-
Comment répartir les gains ? (mise en jeu, pénalités et mécanismes de jeu multi-rôles)
2. Vue d’ensemble de l’architecture technique

3. Détail des modules
RL Swarm : système collaboratif d’apprentissage par renforcement
RL Swarm, première du genre chez Gensyn, est un système d’optimisation collaborative décentralisé destiné aux phases postérieures à l’entraînement. Ses caractéristiques clés :
Flux distribué d’inférence et d’apprentissage :
-
Phase de réponse (Answering) : chaque nœud produit indépendamment une réponse.
-
Phase de critique (Critique) : les nœuds s’évaluent mutuellement, sélectionnant la meilleure réponse et logique.
-
Phase de consensus (Resolving) : prédiction des préférences majoritaires et adaptation de la réponse, conduisant à une mise à jour locale des poids.
RL Swarm est un système d’optimisation collaborative multi-modèles décentralisé : chaque nœud exécute un modèle indépendant et s’entraîne localement, sans synchronisation de gradients. Cela s’adapte naturellement aux environnements hétérogènes et instables, tout en supportant une participation ou sortie élastique. Inspiré de RLHF et des jeux multi-agents, ce mécanisme suit davantage la logique d’évolution d’un réseau d’inférence collaboratif. Les nœuds sont récompensés selon leur alignement avec le consensus collectif, stimulant ainsi une optimisation continue et un apprentissage convergent. RL Swarm améliore notablement la robustesse et la généralisation du modèle dans un réseau ouvert. Il est déjà déployé comme module principal dans la Phase 0 du testnet de Gensyn, basé sur un Rollup Ethereum.
Verde + Proof-of-Learning : mécanisme de vérification de confiance
Le module Verde de Gensyn combine trois mécanismes :
-
Proof-of-Learning : juge si l’entraînement a eu lieu, basé sur la trajectoire des gradients et les métadonnées.
-
Graph-Based Pinpoint : identifie les nœuds divergents dans le graphe de calcul, ne recalculant que les opérations spécifiques.
-
Refereed Delegation : mécanisme de vérification arbitrale, où un vérificateur et un contestataire relèvent un désaccord et valident localement, réduisant fortement le coût.
Comparé aux solutions ZKP ou au recalcul total, Verde offre un meilleur compromis entre vérifiabilité et efficacité.
SkipPipe : mécanisme d’optimisation de tolérance aux pannes de communication
SkipPipe résout le goulot d’étranglement de communication dans les scénarios « faible bande passante + déconnexion des nœuds ». Ses capacités clés :
-
Mécanisme de saut (Skip Ratio) : contourne les nœuds bloquants, évitant le blocage de l’entraînement.
-
Algorithme d’ordonnancement dynamique : génère en temps réel le chemin d’exécution optimal.
-
Exécution tolérante aux pannes : même avec 50 % des nœuds en panne, la précision d’inférence baisse d’environ 7 %.
Il permet une augmentation du débit d’entraînement jusqu’à 55 %, et prend en charge des fonctionnalités clés comme l’inférence « early-exit », le reclassement fluide et la complétion d’inférence.
HDEE : grappes d’experts hétérogènes inter-domaines
HDEE (Heterogeneous Domain-Expert Ensembles) vise à optimiser les scénarios suivants :
-
Entraînement multi-domaine, multimodal, multi-tâches.
-
Répartition inégale des données, difficulté variable.
-
Allocation et ordonnancement des tâches dans des environnements hétérogènes (calcul, bande passante).
Caractéristiques principales :
-
MHe-IHo : assigne des modèles de tailles différentes selon la difficulté (modèles hétérogènes, pas d’entraînement identiques).
-
MHo-IHe : difficulté uniforme, mais pas d’entraînement ajustés de manière asynchrone.
-
Supporte des modèles experts hétérogènes + stratégies d’entraînement interchangeables, améliorant adaptabilité et tolérance.
-
Mise en avant de « collaboration parallèle + communication minimale + allocation dynamique d’experts », adapté aux écosystèmes complexes.
Mécanisme de jeu multi-rôles : confiance et incitation combinées
Le réseau Gensyn introduit quatre rôles :
-
Submitter : publie la tâche, définit structure et budget.
-
Solver : exécute la tâche, soumet le résultat.
-
Verifier : vérifie l’entraînement, assure conformité.
-
Whistleblower : conteste le vérificateur, gagne une récompense ou subit une sanction.
Inspiré du design de jeu économique Truebit, ce mécanisme insère volontairement des erreurs et utilise un arbitrage aléatoire pour inciter à la collaboration honnête, assurant un fonctionnement fiable du réseau.
4. Testnet et feuille de route

5. Équipe et financement
Fondé par Ben Fielding et Harry Grieve, basé à Londres, Royaume-Uni. En mai 2023, Gensyn a annoncé une levée de 43 millions de dollars en série A, menée par a16z crypto, avec la participation de CoinFund, Canonical, Ethereal Ventures, Factor et Eden Block. L’équipe allie expérience en systèmes distribués et en ingénierie ML, œuvrant depuis longtemps à la construction d’un réseau d’exécution d’entraînement IA à grande échelle, vérifiable et sans confiance.
Nous Research : système d’entraînement cognitif évolutif guidé par la notion d’IA subjective
Nous Research est l’un des rares projets d’entraînement décentralisé alliant hauteur philosophique et mise en œuvre technique. Son ambition centrale découle de la notion de « Desideratic AI » : considérer l’IA comme un agent intelligent doté de subjectivité et de capacité d’évolution, plutôt qu’un simple outil contrôlable. La singularité de Nous réside dans le fait qu’elle ne traite pas l’entraînement IA comme un problème d’« efficacité » à optimiser, mais comme un processus de « formation d’un sujet cognitif ». Sous cette impulsion, Nous se concentre sur la construction d’un réseau d’entraînement ouvert, collaboratif entre nœuds hétérogènes, sans orchestrateur central, résistant à la censure, et mettant en œuvre cette vision via une suite d’outils complète.
1. Fondement conceptuel : redéfinir le « but » de l’entraînement
Nous n’investit pas massivement dans la conception d’incitations ou l’économie des protocoles, mais cherche à changer les prémisses philosophiques mêmes de l’entraînement :
-
Opposition à l’« alignmentism » : rejette l’idée que l’objectif unique soit le contrôle humain, prônant un entraînement qui encourage les modèles à développer un style cognitif indépendant.
-
Accent sur la subjectivité du modèle : les grands modèles doivent conserver incertitude, diversité et capacité à générer des hallucinations (« l’hallucination comme vertu »).
-
L’entraînement comme formation cognitive : le modèle n’est pas juste un « optimiseur de tâches », mais un individu participant à un processus d’évolution cognitive.
Cette vision, bien que « romantique », reflète la logique centrale derrière la conception de l’infrastructure d’entraînement de Nous : comment permettre à des modèles hétérogènes d’évoluer dans un réseau ouvert, plutôt que d’être uniformément formatés.
2. Cœur de l’entraînement : réseau Psyche et optimiseur DisTrO
La contribution clé de Nous à l’entraînement décentralisé est la création du réseau Psyche et de l’optimiseur de communication DisTrO (Distributed Training Over-the-Internet), formant ensemble le centre exécutif des tâches d’entraînement. Ensemble, DisTrO + réseau Psyche offrent plusieurs capacités fondamentales : compression de communication (utilisant DCT + codage 1-bit sign, réduisant fortement la demande en bande passante), adaptation aux nœuds (support des GPU hétérogènes, reconnexion après déconnexion, sortie autonome), tolérance aux pannes asynchrone (entraînement continu sans synchronisation, haute tolérance), et mécanisme de planification décentralisée (pas de coordinateur central, consensus et distribution de tâches via blockchain). Cette architecture fournit une base technique réalisable, à faible coût, élastique et vérifiable pour un réseau d’entraînement ouvert.

Cette conception privilégie la faisabilité pratique : pas de serveur central requis, compatible avec des nœuds bénévo
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News











