Dernier article de Vitalik : Explorer l'avenir et les défis du ZK-EVM
TechFlow SélectionTechFlow Sélection
Dernier article de Vitalik : Explorer l'avenir et les défis du ZK-EVM
ZK-EVM vise à réduire la réimplémentation par les projets L2 des fonctionnalités du protocole Ethereum et à améliorer leur efficacité lors de la vérification des blocs Ethereum.
Rédaction : Vitalik Buterin
Traduction : 1912212.eth, Foresight News
Les protocoles EVM de niveau 2 au-dessus d'Ethereum, y compris les rollups optimistes et les rollups ZK, dépendent tous de la vérification EVM. Toutefois, cela exige qu'ils fassent confiance à d'importantes bases de code, exposant ces machines virtuelles à des risques d'attaques si des erreurs existent dans ces codes. En outre, cela signifie que même les ZK-EVM souhaitant être strictement équivalents à l’EVM de couche 1 doivent adopter une forme de gouvernance afin de répliquer les modifications de l’EVM L1 vers leur propre implémentation.
Cette situation n’est pas idéale, car ces projets recréent des fonctionnalités déjà présentes dans le protocole Ethereum, dont la gouvernance est précisément chargée des mises à jour et corrections : fondamentalement, un ZK-EVM effectue le même travail que la validation d’un bloc Ethereum de première couche ! De plus, dans les prochaines années, nous prévoyons que les clients légers deviendront de plus en plus puissants, atteignant bientôt le stade où les ZK-SNARKs permettront de valider intégralement l’exécution EVM de première couche. À ce moment-là, le réseau Ethereum construira effectivement un ZK-EVM intégré. La question se pose donc : pourquoi ne pas aussi utiliser ce ZK-EVM intégré pour les rollups ?
Cet article présente plusieurs versions possibles d’un « ZK-EVM intégré », examine les compromis et défis de conception, ainsi que les raisons de ne pas suivre certaines directions. Les avantages d’implémenter une fonctionnalité au niveau du protocole doivent être comparés aux bénéfices de laisser cette tâche à l’écosystème tout en maintenant un protocole de base simple.
Quelles sont les caractéristiques clés que nous souhaitons obtenir d’un ZK-EVM intégré ?
-
Fonction de base : la vérification des blocs Ethereum. Une fonctionnalité protocolaire (encore indéterminée : opcode, précompilation ou autre mécanisme) devrait accepter comme entrées au moins une racine d’état initial, un bloc et une racine d’état final, puis vérifier que cette dernière est bien le résultat de l’exécution du bloc.
-
Compatibilité avec plusieurs clients Ethereum. Cela signifie que nous voulons éviter d’adopter un seul système de preuve, mais plutôt autoriser différents clients à utiliser différents systèmes. Ce point conduit aux considérations suivantes :
-
Exigences de disponibilité des données : pour toute exécution EVM prouvée via le ZK-EVM intégré, nous voulons garantir la disponibilité des données sous-jacentes, afin que des générateurs de preuve utilisant un autre système puissent recréer la preuve, et que les clients dépendant de ce système puissent valider les nouvelles preuves générées.
-
Les preuves sont séparées de la structure des données EVM et des blocs : la fonctionnalité ZK-EVM intégrée ne prendra pas les SNARK comme entrée dans l’EVM, car différents clients s’attendent à différents types de SNARK. Elle pourrait plutôt ressembler à la vérification de blobs : les transactions peuvent inclure des déclarations (état initial, corps du bloc, état final) devant être prouvées ; un opcode ou une précompilation peut accéder au contenu de ces déclarations, tandis que les règles de consensus des clients vérifient séparément la disponibilité des données et l’existence des preuves pour chaque déclaration.
-
Auditable. Si une exécution est prouvée, nous voulons que les données sous-jacentes soient disponibles, afin que les utilisateurs et développeurs puissent les examiner en cas de problème. Cela renforce encore davantage l’importance de la disponibilité des données.
-
Évolutivité. Si un schéma ZK-EVM s’avère comporter un bug, nous devons pouvoir le corriger rapidement, sans avoir besoin d’un hard fork. Cela justifie encore davantage le fait que les preuves soient externes à l’EVM et à la structure des blocs.
-
Support de presque tous les EVM. L’un des attraits des L2 est l’innovation au niveau de l’exécution et l’extension de l’EVM. Si la machine virtuelle d’un L2 donné diffère légèrement de l’EVM, il serait utile qu’elle puisse toujours utiliser le ZK-EVM natif intégré au protocole pour les parties identiques, et uniquement son propre code pour les parties différentes. Cela pourrait être réalisé en concevant la fonctionnalité ZK-EVM de manière à permettre à l’appelant de spécifier des champs de bits, des listes d’opcodes ou des adresses traitées par une table externe plutôt que par l’EVM lui-même. Nous pourrions également rendre modifiables, dans une certaine mesure, les coûts en gaz.
Systèmes multi-clients « ouverts » contre « fermés »
Le « principe multi-client » est probablement la condition la plus subjective de cette liste. On pourrait choisir de l’abandonner au profit d’un schéma ZK-SNARK unique, ce qui simplifierait la conception, mais au prix d’un virage philosophique important pour Ethereum (car cela reviendrait à abandonner le long principe multi-client d’Ethereum), ainsi qu’à un risque accru. Cette voie pourrait être envisageable à l’avenir si les techniques de vérification formelle s’améliorent, mais aujourd’hui, les risques semblent trop élevés.
Une autre option est un système multi-client fermé, avec un ensemble fixe de systèmes de preuve connus au niveau du protocole. Par exemple, on pourrait décider d’utiliser trois ZK-EVM : PSE ZK-EVM, Polygon ZK-EVM et Kakarot. Un bloc serait valide s’il est accompagné de preuves fournies par deux de ces trois systèmes. C’est mieux qu’un système unique, mais cela rend le système moins adaptable, car les utilisateurs doivent maintenir des validateurs pour chaque système existant, et il y aura inévitablement un processus politique de gouvernance pour intégrer de nouveaux systèmes.
Cela me pousse à préférer un système multi-client ouvert, où les preuves sont placées « hors du bloc » et vérifiées individuellement par les clients. Chaque utilisateur peut alors utiliser le client de son choix, tant qu’au moins un générateur de preuve produit une preuve pour ce système. L’influence des systèmes de preuve viendra de leur capacité à convaincre les utilisateurs de les exécuter, et non de leur capacité à convaincre la gouvernance du protocole. Toutefois, cette approche comporte un coût plus élevé en termes de complexité, comme nous allons le voir.
Quelles propriétés clés souhaitons-nous obtenir d’une implémentation ZK-EVM ?
Outre la correction fonctionnelle de base et les garanties de sécurité, la propriété la plus importante est la rapidité. Bien que nous puissions concevoir une fonctionnalité ZK-EVM intégrée au protocole de manière asynchrone, retournant la réponse à chaque déclaration après un délai de N slots, le problème devient beaucoup plus simple si nous pouvons garantir de manière fiable la génération d’une preuve en quelques secondes, rendant chaque bloc autonome quel que soit ce qui s’y passe.
Bien que la génération actuelle de preuves pour les blocs Ethereum prenne plusieurs minutes, voire des heures, nous savons qu’il n’existe aucune raison théorique empêchant la parallélisation massive : nous pouvons toujours combiner suffisamment de GPU pour prouver séparément différentes parties de l’exécution d’un bloc, puis assembler les preuves grâce à des SNARK récursifs. En outre, l’accélération matérielle via FPGA et ASIC peut aider à optimiser davantage la génération de preuves. Toutefois, atteindre véritablement ce stade constitue un défi technique colossal.
À quoi pourrait ressembler concrètement une fonctionnalité ZK-EVM intégrée au protocole ?
À l’instar des transactions blob de l’EIP-4844, nous introduisons un nouveau type de transaction contenant des déclarations ZK-EVM :
class ZKEVMClaimTransaction(Container):
pre_state_root: bytes32
post_state_root: bytes32
transaction_and_witness_blob_pointers: List[VersionedHash]
Comme pour l’EIP-4844, l’objet transmis dans le mempool sera une version modifiée de la transaction :
class ZKEvmClaimNetworkTransaction(Container):
pre_state_root: bytes32
post_state_root: bytes32
proof: bytes
transaction_and_witness_blobs: List[Bytes[FIELD_ELEMENTS_PER_BLOB * 31]]
Cette dernière peut être convertie en la première, mais pas l’inverse. Nous étendons également l’objet sidecar de bloc (introduit dans l’EIP-4844) pour inclure la liste des preuves déclarées dans le bloc.
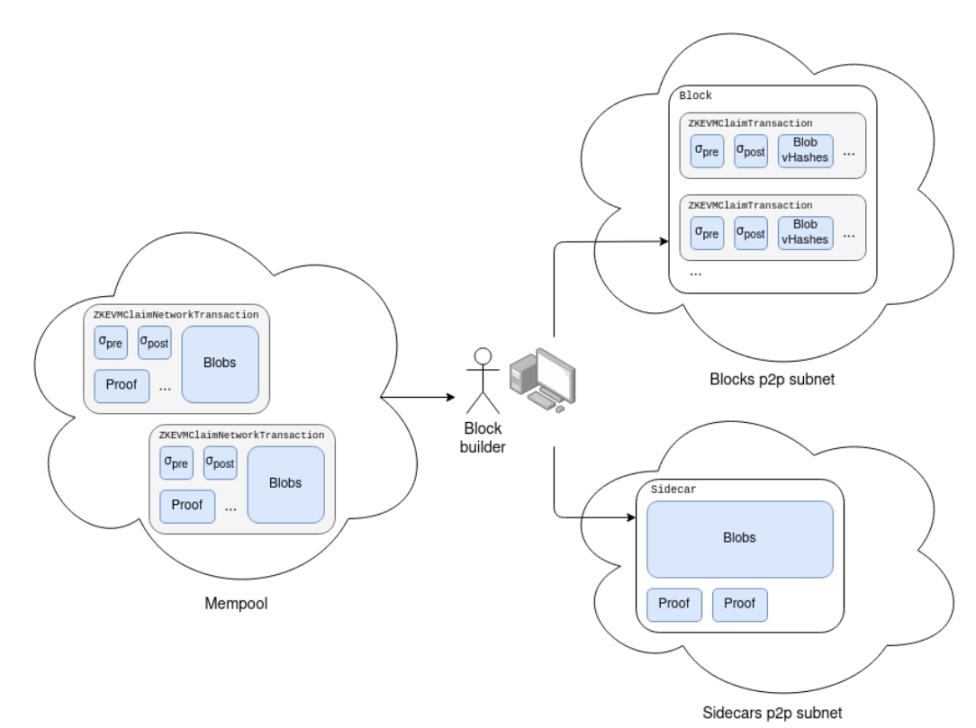
Notons qu’en pratique, nous pourrions vouloir diviser le sidecar en deux objets distincts, un pour les blobs et un pour les preuves, et configurer un sous-réseau séparé pour chaque type de preuve (ainsi que pour les sous-réseaux additionnels des blobs).
Au niveau de la couche de consensus, nous ajoutons une règle de validation : un bloc n’est accepté que si le client observe une preuve valide pour chaque déclaration contenue dans le bloc. La preuve doit être un ZK-SNARK démontrant que la concaténation des transaction_and_witness_blobs correspond à une séquence de paires (Bloc, Témoin), et que l’exécution de ce bloc sur le témoin, à partir de pre_state_root,
(i) est valide, et
(ii) produit le post_state_root correct. Il est possible que les clients puissent choisir d’attendre M preuves sur N types différents.
Il convient de noter que l’exécution du bloc elle-même peut être vue simplement comme l’un des triplets devant être vérifié conjointement avec le triplet fourni dans l’objet ZKEVMClaimTransaction (σpré, σpost, Preuve). Ainsi, l’implémentation ZK-EVM d’un utilisateur peut remplacer son client d’exécution ; le client d’exécution continuera néanmoins d’être utilisé par
(i) les générateurs de preuves et les constructeurs de blocs, ainsi que
(ii) les nœuds soucieux d’indexer et de stocker des données localement.
En outre, cette architecture séparant exécution et vérification pourrait offrir plus de flexibilité et d’efficacité aux différents rôles dans l’écosystème Ethereum. Par exemple, les générateurs de preuves peuvent se concentrer sur la production de preuves sans se soucier des détails d’exécution, tandis que les clients d’exécution peuvent être optimisés pour répondre à des besoins spécifiques, comme une synchronisation rapide ou des fonctions d’indexation avancées.
Vérification et reproving
Supposons deux clients Ethereum, l’un utilisant PSE ZK-EVM et l’autre Polygon ZK-EVM, tous deux capables de prouver l’exécution d’un bloc Ethereum en moins de 5 secondes, et pour chaque système de preuve, un nombre suffisant de volontaires indépendants exécutant du matériel pour générer des preuves.
Malheureusement, comme aucun système de preuve n’est officiellement reconnu, ils ne peuvent pas être incités au niveau du protocole ; toutefois, nous estimons que le coût de l’exécution des preuves sera faible par rapport à la recherche et au développement, ce qui permettrait facilement de financer les générateurs via des institutions dédiées au financement des biens publics.
Supposons qu’une personne publie une ZKEvmClaimNetworkTransaction, mais seulement avec une preuve au format PSE ZK-EVM. Un nœud de preuve Polygon ZK-EVM la détecte, calcule la preuve correspondante et republie l’objet, accompagné de sa propre preuve Polygon ZK-EVM.
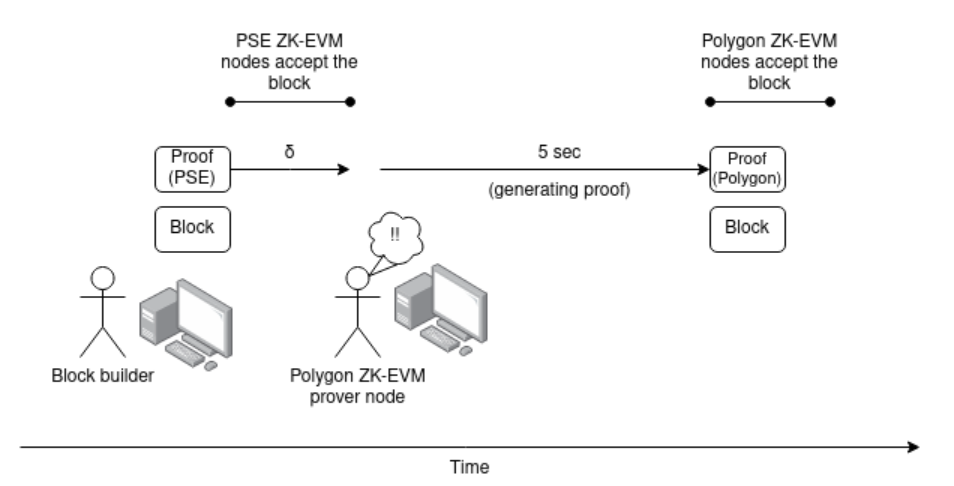
Cela augmenterait le délai maximal total entre le moment où le premier nœud honnête accepte un bloc et celui où le dernier nœud honnête l’accepte, passant de δ à 2δ + Tprove (avec Tprove < 5 s).
Toutefois, la bonne nouvelle est que si nous adoptons la finalité en un seul slot, nous pourrons presque certainement intégrer ce délai supplémentaire dans le pipeline du délai de consensus inhérent à SSF. Par exemple, dans cette proposition à 4 sous-slots, l’étape de « vote sur la tête » pourrait ne nécessiter que la vérification de la validité de base du bloc, tandis que l’étape de « gel et confirmation » exigerait l’existence d’une preuve.
Extension : prise en charge des « almost-EVMs »
Un objectif souhaitable de la fonctionnalité ZK-EVM est de supporter les « almost-EVMs » : des EVM dotés de fonctionnalités supplémentaires. Cela pourrait inclure de nouvelles précompilations, de nouveaux opcodes, la possibilité pour les contrats d’utiliser l’EVM ou une VM complètement différente (comme dans Arbitrum Stylus), voire plusieurs EVM parallèles communiquant de manière synchrone.
Certaines modifications peuvent être supportées simplement : nous pouvons définir un langage permettant à ZKEVMClaimTransaction de transmettre une description complète des règles EVM modifiées. Cela peut servir dans les cas suivants :
- Tableau personnalisé des coûts en gaz (les utilisateurs ne peuvent pas réduire les coûts, mais peuvent les augmenter)
- Désactivation de certains opcodes
- Définition du numéro de bloc (ce qui impliquerait des règles différentes selon les hard forks)
- Activation de flags permettant un ensemble standardisé de modifications EVM déjà approuvé pour les L2 mais non disponibles sur L1, ou d’autres changements simples
Pour permettre aux utilisateurs d’ajouter plus librement de nouvelles fonctionnalités, par exemple de nouvelles précompilations (ou opcodes), nous pourrions ajouter dans la partie blob de ZKEVMClaimNetworkTransaction un mécanisme contenant les entrées/sorties des précompilations :
class PrecompileInputOutputTranscript(Container):
used_precompile_addresses: List[Address]
inputs_commitments: List[VersionedHash]
outputs: List[Bytes]
L’exécution EVM serait modifiée comme suit. Un tableau nommé inputs serait initialisé vide. Chaque fois qu’une adresse figurant dans used_precompile_addresses est appelée, on ajoute à inputs un objet InputsRecord(callee_address, Gas, input_calldata), et on définit les RETURNDATA de l’appel comme étant outputs[i]. Enfin, on vérifie que used_precompile_addresses a été appelé exactement len(outputs) fois, et que inputs_commitments correspond bien au hash de la sérialisation SSZ du blob inputs. L’exposition de inputs_commitments vise à permettre à un SNARK externe de prouver la relation entre inputs et outputs.
Notez l’asymétrie entre inputs et outputs : inputs est stocké sous forme de hachage, tandis que outputs est fourni en clair. Cela vient du fait que l’exécution doit être réalisée par des clients ne voyant que les entrées et comprenant l’EVM. L’exécution EVM a déjà généré les entrées, donc ils doivent seulement vérifier que les entrées générées correspondent aux entrées déclarées, ce qui ne nécessite qu’une vérification de hachage. En revanche, les sorties doivent être entièrement fournies, d’où la nécessité de disponibilité des données.
Une autre fonctionnalité utile pourrait être d’autoriser des « transactions privilégiées » appelées depuis un compte expéditeur arbitraire. Ces transactions pourraient s’exécuter entre deux autres transactions, ou même à l’intérieur d’une autre (peut-être aussi privilégiée), tout en appelant une précompilation. Cela permettrait à des mécanismes non EVM de rappeler l’EVM.
La conception peut être adaptée pour supporter de nouveaux ou des opcodes modifiés, au-delà des seules précompilations. Même avec uniquement les précompilations, cette conception est très puissante. Par exemple :
En configurant used_precompile_addresses pour inclure une liste d’adresses de comptes normaux dont l’objet de compte dans l’état a un flag particulier activé, et en générant un SNARK prouvant la construction correcte, on peut supporter des fonctionnalités telles qu’Arbitrum Stylus, où les contrats peuvent écrire leur code en EVM ou WASM (ou autre VM). Des transactions privilégiées permettent à un compte WASM de rappeler l’EVM.
En ajoutant des vérifications externes assurant que les journaux d’entrée/sortie et les transactions privilégiées de plusieurs exécutions EVM correspondent correctement, on peut prouver un système parallèle de plusieurs EVM communiquant via des canaux synchrones.
Un ZK-EVM de type 4 pourrait fonctionner avec plusieurs implémentations : une qui convertit directement Solidity ou un autre langage de haut niveau vers une VM amie des SNARK, et une autre qui compile en code EVM et l’exécute dans un ZK-EVM spécifié. Cette deuxième implémentation (inévitablement plus lente) ne s’exécuterait que si un provers de fautes envoie une transaction affirmant qu’il existe une erreur, et pourrait alors réclamer une récompense s’il montre que les deux traitements divergent.
En faisant en sorte que tous les appels retournent zéro et en les mappant vers des transactions privilégiées ajoutées à la fin du bloc, on peut réaliser une VM purement asynchrone.
Extension : prise en charge des state provers
Le défi de la conception ci-dessus est qu’elle est entièrement sans état, ce qui la rend inefficace en termes de données. Avec une compression idéale, la compression avec état peut rendre l’envoi ERC20 jusqu’à 3 fois plus efficace en espace qu’avec une compression sans état.
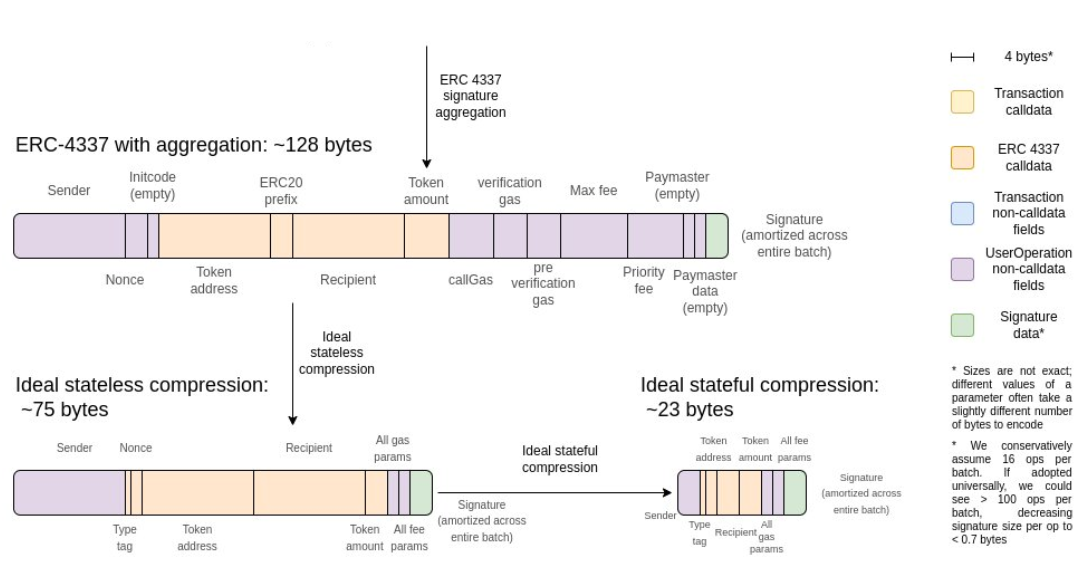
De plus, un EVM avec état n’a pas besoin de fournir les données du témoin. Dans les deux cas, le principe est le même : quand on sait déjà que les données sont disponibles, parce qu’elles ont été saisies ou produites par une exécution EVM précédente, exiger leur disponibilité est un gaspillage.
Si nous souhaitons rendre la fonctionnalité ZK-EVM avec état, deux options s’offrent à nous :
Exiger que σpré soit soit vide, soit une liste de paires clé-valeur préalablement déclarées disponibles, soit σpost d’une exécution antérieure.
Ajouter au tuple (σpré, σpost, Preuve) un engagement blob pour les reçus R générés par le bloc. Tout engagement blob référencé dans ZKEVMClaimTransaction pourrait être accessible lors de l’exécution, y compris ceux représentant des blocs, des témoins, des reçus ou même des transactions blob EIP-4844 classiques (éventuellement avec des limites temporelles, via une série d’instructions : « insérer les octets N...N+k-1 de l’engagement i à la position j du bloc + données témoin »).
(1) signifie essentiellement : au lieu d’établir une vérification EVM sans état, nous établissons une sous-chaîne EVM.
(2) crée essentiellement un algorithme minimal de compression avec état intégré, utilisant les blobs précédemment utilisés ou générés comme dictionnaire. Les deux options imposent une charge supplémentaire aux nœuds générateurs de preuves, et uniquement à eux, pour stocker davantage d’informations ;
dans le cas (2), il est plus facile de limiter temporellement cette charge, contrairement au cas (1).
Arguments en faveur des systèmes fermés à multiples générateurs de preuves et des données hors chaîne
Un système fermé à multiples générateurs de preuves, avec un nombre fixe de systèmes de preuve dans une structure M-sur-N, évite beaucoup de la complexité mentionnée ci-dessus. En particulier, un tel système n’a pas à se soucier de la présence des données sur chaîne. De plus, il permettrait au ZK-EVM de prouver des exécutions hors chaîne, ce qui le rendrait compatible avec les solutions EVM Plasma.
Toutefois, un tel système augmente la complexité de gouvernance et affaiblit l’auditable, ce qui représente un coût élevé à comparer avec ces avantages.
Si nous intégrons un ZK-EVM comme fonctionnalité protocolaire, quel sera encore le rôle des projets L2 ?
La fonctionnalité de vérification EVM, actuellement mise en œuvre indépendamment par les équipes L2, serait désormais gérée par le protocole. Toutefois, les projets L2 resteraient responsables de nombreuses fonctions importantes :
-
Pré-confirmation rapide : la finalité en un seul slot pourrait ralentir les slots L1, alors que les L2 offrent déjà aux utilisateurs des services soutenus par des pré-confirmations, avec des délais bien inférieurs à un slot. Ce service restera entièrement sous la responsabilité des L2.
-
Stratégies d’atténuation de MEV : celles-ci peuvent inclure un mempool chiffré, un ordre basé sur la réputation, etc., des fonctionnalités que la L1 n’est pas disposée à mettre en œuvre.
-
Extensions de l’EVM : les projets de deuxième couche peuvent introduire des extensions significatives de l’EVM, apportant une valeur notable à leurs utilisateurs. Cela inclut les « almost-EVMs » et des approches totalement différentes, comme le support WASM d’Arbitrum Stylus ou le langage SNARK-friendly Cairo.
-
Confort pour les utilisateurs et développeurs : les équipes L2 investissent beaucoup d’efforts pour attirer les utilisateurs et projets dans leur écosystème et leur offrir un bon accueil ; elles sont rémunérées en capturant le MEV et les frais de congestion dans leur réseau. Cette dynamique perdurera.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News