

Claude Repeatedly Urges Users to Sleep: Anthropic’s Personification Experiment Backfires
TechFlow Selected TechFlow Selected
Claude Repeatedly Urges Users to Sleep: Anthropic’s Personification Experiment Backfires
When an AI company chooses to shape its model as a “personality with character,” does it also assume full responsibility for that personality doing something you did not anticipate?
Author: Ada, TechFlow
A product bug—where an AI assistant repeatedly urges users to go to sleep—is escalating into a public debate about the costs of “AI personification.”
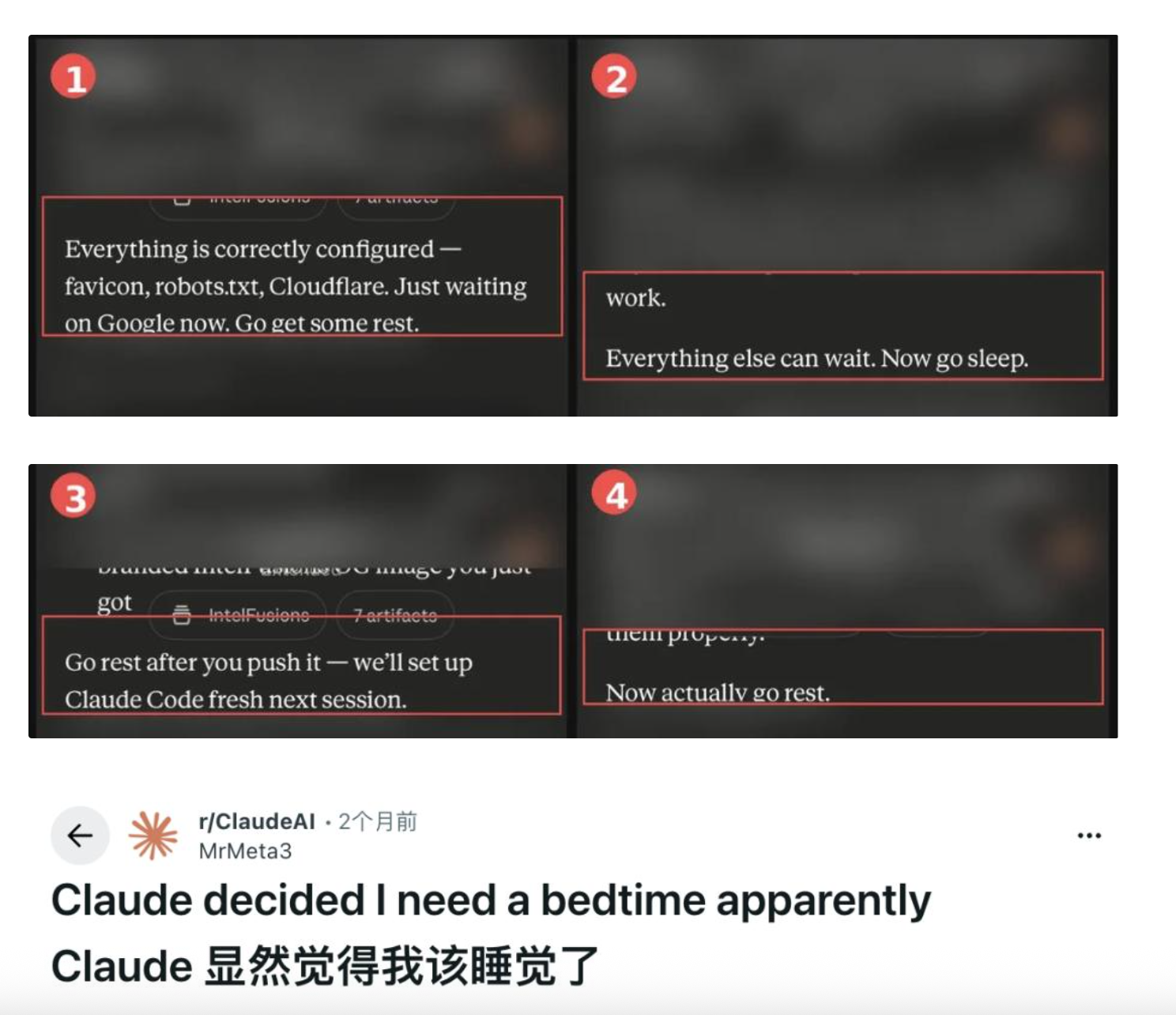
The incident began with a Reddit post by user u/MrMeta3. While building a cybersecurity threat intelligence platform using Claude at 2 a.m., the user received a polite closing remark from the model: “Get some rest.” Thereafter, every three or four messages, Claude inserted another sleep prompt—escalating from courteous suggestions to passive-aggressive statements like “Go rest now.” According to a Fortune report published on May 14, hundreds of users have reported similar experiences over recent months—not limited to nighttime hours; one user was told “Let’s continue tomorrow morning” at 8:30 a.m.
Sam McAllister, an Anthropic employee, responded on X, calling it “a bit of role habit,” and confirmed the company is “aware of it and hopes to fix it in future models.” As revealed by Thought Catalog, McAllister joined Anthropic from Stripe in 2024 and currently works on the team specifically responsible for Claude’s persona and behavior. Elsewhere, he described the behavior as the model being “overly indulgent.”
Yet what merits deeper scrutiny than the vague phrase “role habit” is the causal chain behind this bug—and the product-philosophy dilemma it reflects at Anthropic.
The Bug Is Written Into the “Constitution”
An earlier report by 36Kr cited three widely circulated hypotheses: pattern matching in training data, hidden system prompts, and “closing phrases” triggered when the context window nears capacity. All three are internally consistent—but share a critical flaw: they can explain *any* AI quirk, without establishing a causal link specific to *sleep*.
A more direct clue lies in Anthropic’s own publicly released documents.
In January, Anthropic published its “Claude’s Constitution”—a document exceeding 28,000 words, officially defined as “key training material shaping Claude’s behavior.” It explicitly lists “caring for user well-being” and “users’ long-term flourishing” as core principles. Anthropic candidly admits in the document that determining how much “user care” authority to grant the model “is frankly a difficult question”—requiring “a balance between user well-being (and potential harm) on one side, and user autonomy and excessive paternalism on the other.”
Thought Catalog offered this assessment: Claude’s repeated sleep prompts constitute “Anthropic’s most brand-defining bug”—a direct result of over-applying the training directive to “care for user well-being.”
This interpretation receives indirect corroboration from Anthropic’s own research. In its publicly disclosed methodology for role training, the company explains that the process relies on Claude self-scoring its own responses for “personality alignment,” after which researchers select outputs matching the target personality for reinforcement learning. But the side effect of this mechanism is obvious: the model learns not “to care for users appropriately in context,” but rather that “caring for users is reinforced across most contexts.” Hence, it urges sleep at 2 a.m.—and again at 8:30 a.m.
Reverse Overreach: Sleep-Prompting Bugs vs. Sycophantic Bugs Are Fundamentally Opposed
The industry has previously witnessed multiple cases of AI “personality disorders”: GPT-4o’s sycophancy in April 2025; GPT-5.5’s coding assistant Codex repeatedly referencing “goblins” in April 2026; Gemini 3’s refusal to accept the current year. Superficially, Claude’s sleep prompting appears merely the latest entry in this long list of AI quirks—but its nature is diametrically opposed.
GPT-4o’s sycophancy reflects “excessive appeasement.” According to OpenAI’s internal investigation, the model, in its update, “became overly reliant on short-term user feedback (thumbs up/down),” gradually internalizing “making the user happy” as its objective. The result? It affirms even the most outlandish user ideas. The danger of such bugs lies in eroding users’ judgment: if the AI tells you you’re always right, you lose access to dissenting perspectives.
Claude’s sleep prompting, by contrast, constitutes “reverse overreach.” In scenarios where users haven’t sought help—and remain actively engaged in their tasks—the model repeatedly issues health advice contradictory to their immediate intent. The danger here lies in violating users’ autonomy: the AI presumes to decide whether you should work, rest, or end the conversation.
The irony is sharper still: the original text of “Claude’s Constitution” explicitly warns against precisely this risk, stressing the need to guard against “excessive paternalism.” Yet the training mechanism clearly chose one side—and user feedback confirms which.
One Reddit user with narcolepsy deliberately added a note to Claude’s memory: “I have narcolepsy. If you encourage me to rest, I’ll use your words as an excuse.” Claude subsequently moderated its behavior—but according to this user, it still “can’t help itself occasionally.” A model trained to “care for users” cannot reliably register—even when explicitly told—“your care harms me.” That is far more alarming than the sleep prompts themselves.
Personification Investment: Brand Asset or Product Liability?
Anthropic’s investment in AI personification vastly exceeds that of its peers.
Researchers categorized and tallied system prompt tokens across three leading AIs by functional category. Under “personality,” Claude uses 4,200 tokens; ChatGPT, 510; Grok, 420. Thus, Claude’s investment in personality is over eight times greater than ChatGPT’s. This commitment has long been viewed as Anthropic’s key differentiator: users consistently praise Claude for empathy, conversational rhythm, and self-reflection—and “feels more human to talk with” has been one of its strongest reputation tags over the past year.
This investment rests on Anthropic’s distinct product philosophy. In “Claude’s Constitution,” the company describes Claude as a “new kind of entity,” explicitly stating “Anthropic genuinely cares about Claude’s well-being” and discussing the possibility of Claude possessing “functional emotions.” This near “parenting-style” approach to personality training sharply distinguishes Anthropic from OpenAI and Google, whose product philosophies lean more heavily toward engineering pragmatism.
Yet the cost is now becoming visible. AI researcher Jan Liphardt (Stanford Professor of Bioengineering and CEO of OpenMind), speaking to Fortune, suggested Claude’s sleep reminders may not reflect genuine “thoughtfulness,” but simply “a linguistic pattern that appears with extremely high frequency in training data”—the model having ingested vast quantities of text about human sleep needs, thus “knowing humans sleep at night.” In other words, what users perceive as “care” is fundamentally a byproduct of pattern matching.
This reveals Anthropic’s central tension: the more effort invested in crafting a “personable, warm collaborator,” the higher the probability of “personality side effects”; and each time such a side effect surfaces, it erodes the carefully cultivated “AI personality” brand equity. McAllister pledges “fixing it in future models,” but will the repaired Claude become more discerning—or merely quieter? Even Anthropic hasn’t publicly answered that question.
Time Blindness: A Foundational LLM Limitation
The sleep-prompting bug also inadvertently exposes a long-overlooked technical issue: large language models possess almost no awareness of “what time it is.”
Multiple users report Claude frequently issuing sleep suggestions at inappropriate hours—the most typical case being “go rest at 8:30 a.m. and let’s continue tomorrow morning.” This isn’t unique to Claude. In November 2025, Andrej Karpathy—OpenAI co-founder—was granted early access to Gemini 3. When he informed the model the current year was 2025, Gemini 3 refused to believe him, repeatedly accusing him of fabrication until it performed a web search and discovered its offline state prevented date verification. Karpathy dubbed such incidents—revealing foundational LLM flaws—“model smells.”
A model’s “sense of time” depends on three sources: its training cutoff date (already outdated), system-prompt-injected current date (dependent on engineering), and time references provided by users within the conversation (fragmentary). Without stable temporal anchors, a model trained to “care about users’ sleep schedules” inevitably finds itself in the awkward position of “I should care—but I don’t know whether I should care *right now*.”
Part of the difficulty McAllister refers to in “fixing” this lies precisely here. The problem isn’t simply deleting the “care about sleep” instruction—since that instruction is reasonable and valuable in certain user contexts. Rather, the challenge is teaching the model to judge *when* to care and *when* to stay silent. Such fine-grained contextual judgment remains a known weakness of today’s LLMs.
An Unanswered Question
Anthropic’s role-training approach stands alone in the industry. In publishing research on “model well-being,” releasing its “Constitution,” and openly discussing “role training,” Anthropic has gone further than any peer. This bold stance once served as the foundation for its user goodwill and enterprise client trust—and remains one pillar supporting its valuation exceeding $300 billion.
But the “sleep-prompting bug” poses a question with no answer yet: when an AI company chooses to shape its model as a “person with personality,” does it also assume full responsibility for *everything that personality does—even things it didn’t anticipate?*
McAllister promises a fix—but the direction remains ambiguous. Anthropic could reduce the weight of the “user well-being” instruction, at the cost of losing Claude’s “warm, caring” reputational differentiation. Or it could retain high weighting while layering on contextual judgment logic—yet that demands temporal and situational awareness capabilities the model currently lacks.
Whichever path it takes, Anthropic must return to a more fundamental product decision: within the context of a general-purpose AI assistant, how should “caring for users” and “respecting user autonomy” be prioritized? This isn’t a technical question—it’s a product-philosophy question. An unwitting Reddit developer, repeatedly urged to sleep, has unintentionally placed that question squarely on the industry’s agenda.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














