

AI Layer 1 Research Report: Finding the Fertile Ground for Future On-Chain DeAI Applications
TechFlow Selected TechFlow Selected
AI Layer 1 Research Report: Finding the Fertile Ground for Future On-Chain DeAI Applications
Systematically review the latest developments in the DeAI sector, analyze the current state of projects, and explore future trends.
Authors: @anci_hu49074 (Biteye), @Jesse_meta (Biteye), @lviswang (Biteye), @0xjacobzhao (Biteye),@bz1022911 (PANews)
Overview
Background
In recent years, leading tech companies such as OpenAI, Anthropic, Google, and Meta have continuously advanced the rapid development of large language models (LLMs). LLMs have demonstrated unprecedented capabilities across industries, greatly expanding human imagination and even showing potential to replace human labor in certain scenarios. However, control over these core technologies remains firmly in the hands of a few centralized tech giants. With substantial capital and dominance over expensive computing resources, these companies have established insurmountable barriers, making it difficult for most developers and innovation teams to compete.
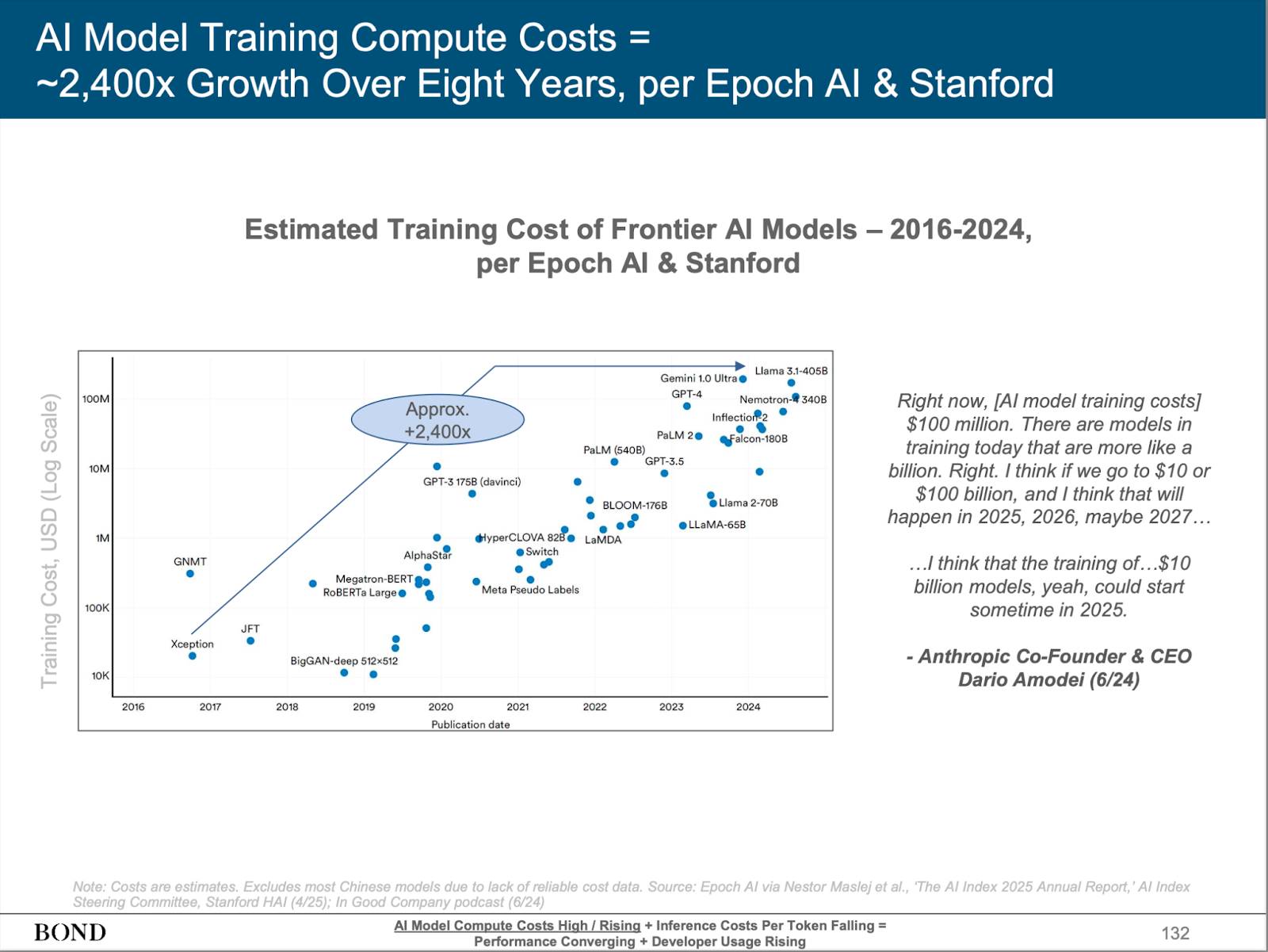
Source: BONDAI Trend Analysis Report
Meanwhile, during the early stages of AI evolution, public discourse has often focused on technological breakthroughs and conveniences, while paying relatively insufficient attention to core issues like privacy protection, transparency, and security. In the long term, these issues will profoundly impact the healthy development of the AI industry and societal acceptance. If not properly addressed, debates over whether AI is used for "good" or "evil" will intensify. Driven by profit motives, centralized giants often lack sufficient incentive to proactively tackle these challenges.
Blockchain technology, with its decentralized, transparent, and censorship-resistant characteristics, offers new possibilities for the sustainable development of the AI industry. Currently, numerous "Web3 AI" applications have emerged on mainstream blockchains such as Solana and Base. However, deeper analysis reveals many existing problems: on one hand, decentralization is limited, with key components and infrastructure still relying on centralized cloud services and excessive meme attributes, making it hard to support a truly open ecosystem; on the other hand, compared to Web2 AI products, on-chain AI lags in model capability, data utilization, and application scenarios, requiring further improvement in innovation depth and breadth.
To truly realize the vision of decentralized AI—enabling blockchain to securely, efficiently, and democratically host large-scale AI applications while competing in performance with centralized solutions—we need to design a Layer 1 blockchain specifically tailored for AI. This would provide a solid foundation for open AI innovation, democratic governance, and data security, driving the prosperity of the decentralized AI ecosystem.
Core Features of AI Layer 1
As a blockchain custom-built for AI applications, AI Layer 1’s underlying architecture and performance are tightly aligned with the demands of AI tasks, aiming to efficiently support the sustainable growth and prosperity of an on-chain AI ecosystem. Specifically, an AI Layer 1 should possess the following core capabilities:
-
Efficient Incentive and Decentralized Consensus Mechanism: The essence of AI Layer 1 lies in building an open network for sharing computational power, storage, and other resources. Unlike traditional blockchain nodes primarily focused on ledger recording, nodes in an AI Layer 1 must handle more complex tasks—providing computation for training and inference, contributing storage, data, bandwidth, and other diverse resources—to break the monopoly of centralized giants over AI infrastructure. This places higher demands on the consensus and incentive mechanisms: the blockchain must accurately assess, incentivize, and verify node contributions in AI inference and training, ensuring network security and efficient resource allocation. Only then can network stability and prosperity be maintained while effectively reducing overall computing costs.
-
High Performance and Support for Heterogeneous Tasks: AI tasks, especially LLM training and inference, demand extremely high computational performance and parallel processing capabilities. Furthermore, on-chain AI ecosystems often need to support diverse, heterogeneous task types—including different model architectures, data processing, inference, and storage scenarios. The AI Layer 1 must deeply optimize its underlying architecture for high throughput, low latency, and elastic parallelism, and natively support heterogeneous computing resources to ensure all kinds of AI tasks run efficiently, enabling smooth expansion from “single-type tasks” to a “complex, diversified ecosystem.”
-
Verifiability and Trustworthy Output Assurance: An AI Layer 1 must not only prevent malicious behavior, data tampering, and other security risks but also ensure verifiability and alignment of AI outputs at the foundational level. By integrating cutting-edge technologies such as Trusted Execution Environments (TEE), Zero-Knowledge Proofs (ZK), and Multi-Party Computation (MPC), the platform enables independent verification of every model inference, training, and data processing process, ensuring fairness and transparency. This verifiability also helps users understand the logic and basis behind AI outputs, achieving “what you get is what you expect,” thereby enhancing trust and satisfaction with AI products.
-
Data Privacy Protection: AI applications frequently involve sensitive user data, making data privacy particularly critical in fields like finance, healthcare, and social networking. While ensuring verifiability, the AI Layer 1 should employ encrypted data processing techniques, privacy-preserving computation protocols, and data access controls to safeguard data throughout inference, training, and storage processes, effectively preventing data leaks and misuse and alleviating user concerns about data security.
-
Strong Ecosystem Capacity and Developer Support: As a native AI Layer 1 infrastructure, the platform must not only lead in technical innovation but also provide comprehensive development tools, integrated SDKs, operational support, and incentive mechanisms for developers, node operators, and AI service providers. By continuously improving platform usability and developer experience, it fosters the launch of rich, diverse native AI applications and drives sustained prosperity within the decentralized AI ecosystem.
Based on this background and vision, this article details six representative AI Layer 1 projects—Sentient, Sahara AI, Ritual, Gensyn, Bittensor, and 0G—systematically reviewing the latest developments in the sector, analyzing current project statuses, and exploring future trends.
Sentient: Building Loyal, Open-Source, Decentralized AI Models
Project Overview
Sentient is an open-source protocol platform developing an AI Layer 1 blockchain (initially launching as a Layer 2 before migrating to Layer 1). By combining AI pipelines with blockchain technology, Sentient aims to build a decentralized artificial intelligence economy. Its core goal is to address ownership, invocation tracking, and value distribution issues in centralized LLM markets through the "OML" framework (Open, Monetizable, Loyal), establishing on-chain ownership structures, transparent usage, and revenue-sharing mechanisms for AI models. Sentient's vision is to empower anyone to build, collaborate, own, and monetize AI products, fostering a fair and open AI agent network ecosystem.
The Sentient Foundation team brings together world-class academic experts, blockchain entrepreneurs, and engineers dedicated to building a community-driven, open-source, and verifiable AGI platform. Key members include Professor Pramod Viswanath from Princeton University and Professor Himanshu Tyagi from the Indian Institute of Science, focusing on AI safety and privacy protection, respectively, with Sandeep Nailwal, co-founder of Polygon, leading blockchain strategy and ecosystem development. The team includes talent from top firms such as Meta, Coinbase, and Polygon, as well as elite institutions including Princeton University and the Indian Institutes of Technology, covering AI/ML, NLP, computer vision, and more, collectively advancing project execution.
As the second venture of Polygon co-founder Sandeep Nailwal, Sentient launched with significant visibility, leveraging abundant resources, connections, and market recognition, providing strong backing for its development. In mid-2024, Sentient raised $85 million in seed funding led by Founders Fund, Pantera, and Framework Ventures, with participation from dozens of prominent VCs including Delphi, Hashkey, and Spartan.
Architecture and Application Layer
Infrastructure Layer
Core Architecture
Sentient's core architecture consists of two main components: the AI Pipeline and the Blockchain System.
The AI Pipeline forms the foundation for developing and training "loyal AI" artifacts, comprising two core processes:
-
Data Curation: A community-driven data selection process for model alignment.
-
Loyalty Training: A training process that ensures models remain aligned with community intent.
The blockchain system provides transparency and decentralized control, ensuring ownership, usage tracking, revenue distribution, and fair governance of AI artifacts. The specific architecture is divided into four layers:
-
Storage Layer: Stores model weights and fingerprint registration information;
-
Distribution Layer: Authorization contracts control model invocation entry points;
-
Access Layer: Permission proofs verify whether a user is authorized;
-
Incentive Layer: Revenue routing contracts distribute payments from each model call among trainers, deployers, and validators.
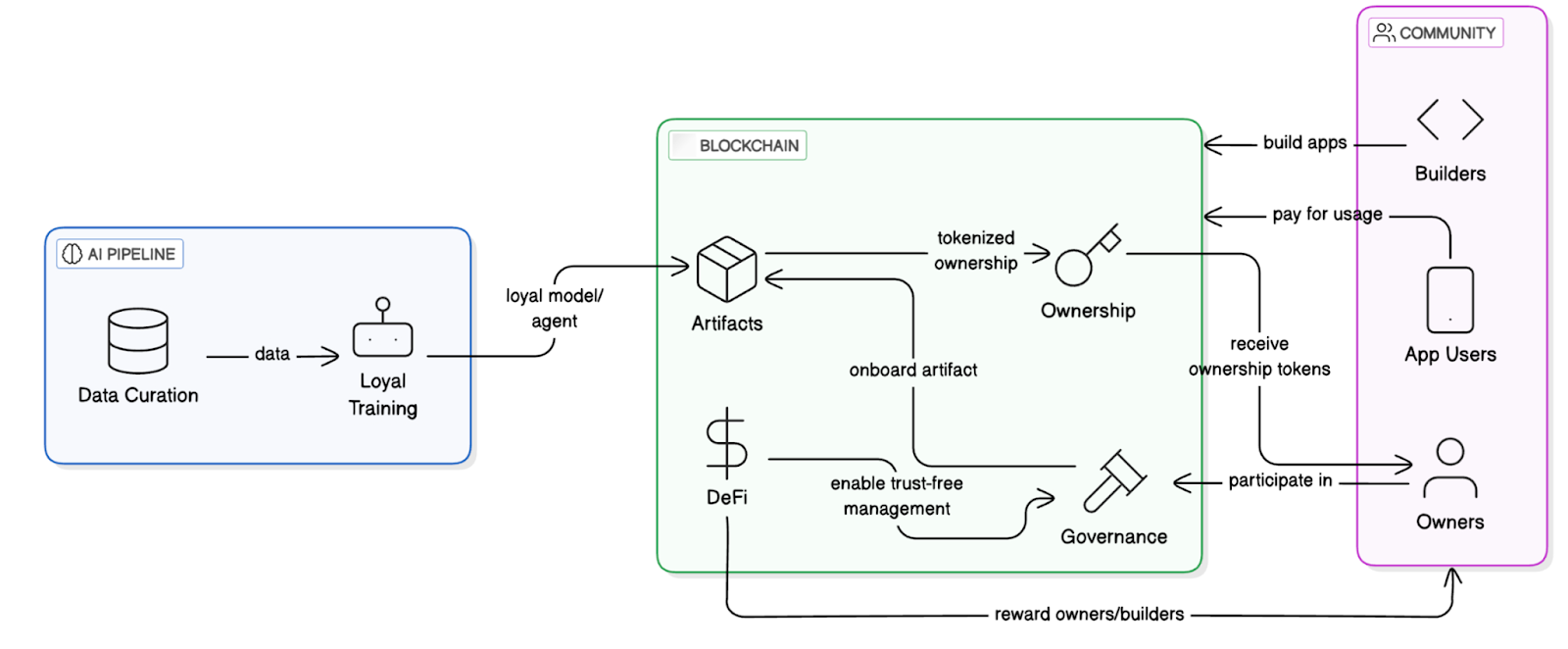
Sentient System Workflow Diagram
OML Model Framework
The OML framework (Open, Monetizable, Loyal) is Sentient’s core philosophy, designed to provide clear ownership rights and economic incentives for open-source AI models. By combining on-chain technology with AI-native cryptography, it features the following:
-
Openness: Models must be open-source, with transparent code and data structures, enabling community replication, auditing, and improvement.
-
Monetization: Each model call triggers revenue flow, with smart contracts distributing earnings to trainers, deployers, and validators.
-
Loyalty: Models belong to the contributor community, with upgrade direction and governance decided by DAO, and usage/modification controlled via cryptographic mechanisms.
AI-Native Cryptography
AI-native cryptography leverages the continuity, low-dimensional manifold structure, and differentiability of AI models to develop lightweight security mechanisms that are “verifiable but non-removable.” Its core technologies include:
-
Fingerprint Embedding: A unique signature is embedded during training using hidden query-response key-value pairs;
-
Ownership Verification Protocol: A third-party prover verifies the presence of the fingerprint by querying the model;
-
Permitted Invocation Mechanism: Before invoking a model, users must obtain a “permission credential” issued by the model owner, which the system uses to authorize decoding and accurate response generation.
This approach achieves “behavior-based authorization + ownership verification” without re-encryption overhead.
Model Ownership and Secure Execution Framework
Sentient currently employs Melange hybrid security: combining fingerprint-based ownership verification, TEE execution, and on-chain revenue sharing. The fingerprint method serves as the mainline implementation of OML 1.0, emphasizing the concept of “optimistic security”—assuming compliance by default, detecting violations later, and applying penalties accordingly.
The fingerprint mechanism is key to OML, embedding specific “question-answer” pairs during training to generate a unique model signature. These signatures allow model owners to verify ownership and prevent unauthorized copying and commercialization. This mechanism not only protects model developers’ rights but also provides traceable on-chain records of model usage.
In addition, Sentient has introduced the Enclave TEE computing framework, utilizing trusted execution environments (e.g., AWS Nitro Enclaves) to ensure models respond only to authorized requests, preventing unauthorized access and use. Although TEE relies on hardware and carries some security risks, its high performance and real-time advantages make it a core technology for current model deployment.
In the future, Sentient plans to integrate zero-knowledge proofs (ZK) and fully homomorphic encryption (FHE) to further enhance privacy protection and verifiability, offering more mature solutions for decentralized AI model deployment.
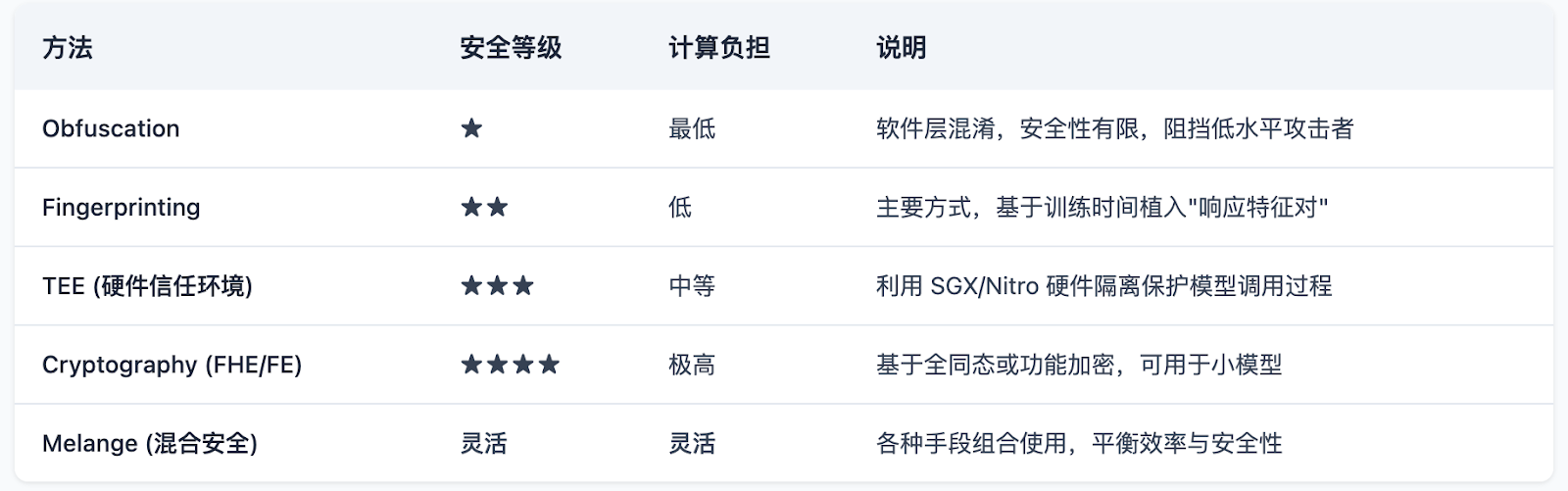
Evaluation and Comparison of Five Verifiability Methods Proposed by OML
Application Layer
Currently, Sentient’s product suite includes the decentralized chat platform Sentient Chat, the open-source Dobby series models, and the AI Agent framework.
Dobby Series Models
SentientAGI has released multiple "Dobby" series models, primarily based on Llama, focusing on values of freedom, decentralization, and cryptocurrency support. The "leashed" version is more restrained and rational, suitable for stable output scenarios; the "unhinged" version is bolder and freer, featuring richer conversational styles. Dobby models have already been integrated into several Web3-native projects such as Firework AI and Olas, and users can directly invoke them via Sentient Chat. Dobby 70B is the most decentralized model ever created, with over 600,000 owners (holders of Dobby fingerprint NFTs are also co-owners of the model).
Sentient also plans to launch Open Deep Search, a search agent system aiming to surpass ChatGPT and Perplexity Pro. It combines Sentient’s search capabilities (e.g., query reformulation, document processing) with reasoning agents, leveraging open-source LLMs (such as Llama 3.1 and DeepSeek) to improve search quality. On the Frames Benchmark, its performance has exceeded other open-source models and even approached some closed-source models, demonstrating strong potential.
Sentient Chat: Decentralized Chat and On-Chain AI Agent Integration
Sentient Chat is a decentralized chat platform that integrates open-source large language models (like the Dobby series) with advanced reasoning agent frameworks, supporting multi-agent integration and complex task execution. Built-in reasoning agents can perform complex tasks such as search, calculation, and code execution, delivering efficient user interaction. Additionally, Sentient Chat supports direct integration of on-chain agents, currently including the astrology agent Astro247, crypto analytics agent QuillCheck, wallet analysis agent Pond Base Wallet Summary, and spiritual guidance agent ChiefRaiin. Users can select different intelligent agents based on their needs. Sentient Chat acts as a distribution and coordination platform where user queries are routed to any integrated model or agent to deliver optimal responses.
AI Agent Framework
Sentient provides two major AI Agent frameworks:
-
Sentient Agent Framework: A lightweight, open-source framework focused on automating web tasks (e.g., search, video playback) via natural language commands. It supports building agents with perception, planning, execution, and feedback loops, ideal for lightweight off-chain web task development.
-
Sentient Social Agent: An AI system developed for social platforms (e.g., Twitter, Discord, Telegram), supporting automated interactions and content generation. Through multi-agent collaboration, this framework understands social contexts and delivers smarter social experiences, and can integrate with the Sentient Agent Framework to further expand its application scope.
Ecosystem and Participation
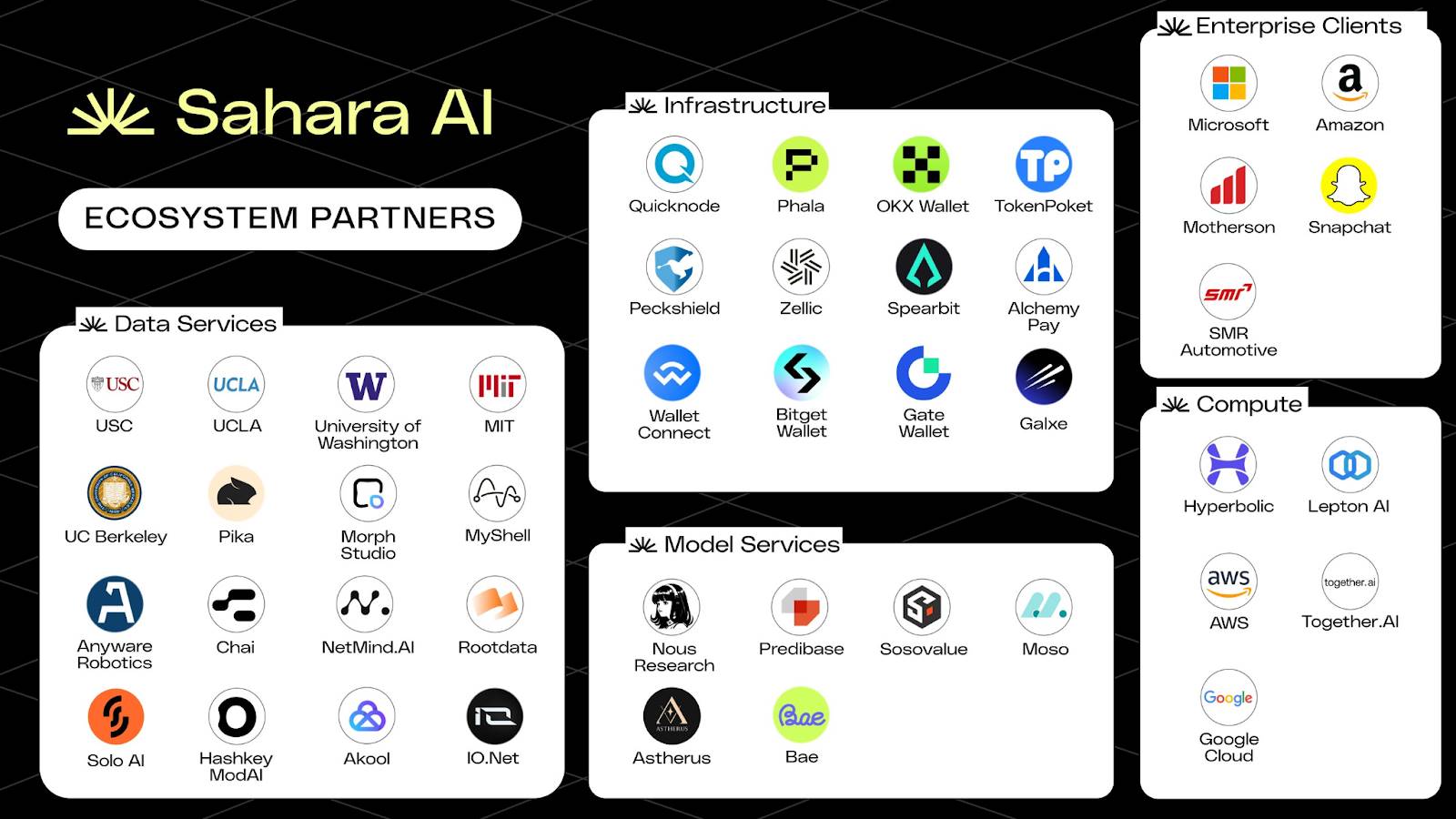
The Sentient Builder Program currently offers a $1 million grant program to encourage developers to use its toolkit to build AI agents accessible via the Sentient Agent API and operable within the Sentient Chat ecosystem. Sentient’s official website lists ecosystem partners from various Crypto AI domains, as shown below:

Sentient Ecosystem Map
Additionally, Sentient Chat is currently in testing phase and requires an invitation code to access the whitelist. General users can join the waitlist. According to official figures, over 50,000 users have generated more than 1 million queries, with 2 million users on the waiting list.
Challenges and Outlook
Sentient starts from the model side, addressing core issues like misalignment and untrustworthiness in today’s large language models (LLMs). Through the OML framework and blockchain technology, it establishes clear ownership structures, usage tracking, and behavioral constraints for models, significantly advancing the development of decentralized open-source models.
Leveraging the resources of Polygon co-founder Sandeep Nailwal, along with endorsements from top-tier VCs and industry partners, Sentient leads in resource integration and market visibility. However, as the market gradually becomes skeptical of high-valuation projects, whether Sentient can deliver impactful decentralized AI products will be a crucial test of its ability to become the standard for decentralized AI ownership. These efforts not only determine Sentient’s success but also have far-reaching implications for rebuilding trust and advancing decentralization across the entire industry.
Sahara AI: Building a Decentralized AI World for Everyone
Project Overview
Sahara AI is a decentralized infrastructure built for the AI × Web3 paradigm, aiming to create an open, fair, and collaborative artificial intelligence economy. The project uses decentralized ledger technology to manage and trade datasets, models, and intelligent agents on-chain, ensuring sovereignty and traceability of data and models. At the same time, Sahara AI introduces transparent and fair incentive mechanisms so that all contributors—including data providers, annotators, and model developers—receive immutable income returns during collaboration. The platform also features a permissionless “copyright” system to protect contributors' ownership and attribution of AI assets, encouraging open sharing and innovation.
Sahara AI offers a one-stop solution covering data collection, annotation, model training, AI agent creation, and AI asset trading, encompassing the entire AI lifecycle and serving as a comprehensive ecosystem platform for AI development needs. Its product quality and technical capabilities have earned high recognition from global leading enterprises and institutions such as Microsoft, Amazon, MIT, Motherson Group, and Snap, demonstrating strong industry influence and broad applicability.
Sahara is not just a research project—it is a deep-tech platform driven by frontline technologists and investors with a focus on real-world implementation. Its core architecture has the potential to become a pivotal enabler for AI × Web3 applications. Sahara AI has received cumulative investment support of $43 million from leading institutions including Pantera Capital, Binance Labs, and Sequoia China. Co-founded by Sean Ren, a tenured professor at the University of Southern California and 2023 Samsung Research Fellow, and Tyler Zhou, former Investment Director at Binance Labs, the core team includes members from Stanford University, UC Berkeley, Microsoft, Google, and Binance, combining deep expertise from both academia and industry.
Architecture
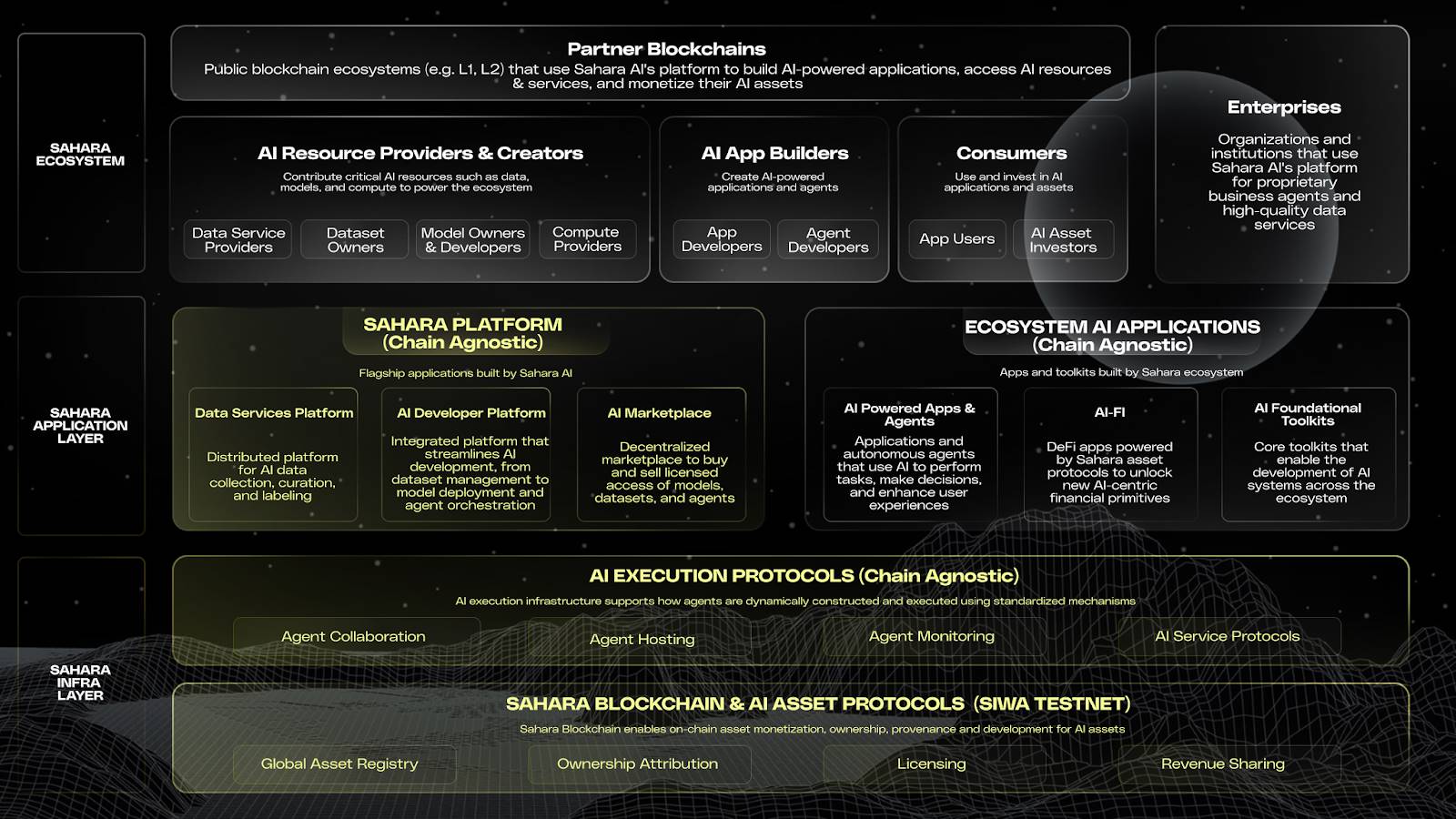
Sahara AI Architecture Diagram
Base Layer
Sahara AI’s base layer consists of: 1. an on-chain layer for AI asset registration and monetization, and 2. an off-chain layer for running agents and AI services. Together, they form a coordinated system responsible for AI asset registration, ownership verification, execution, and revenue distribution, supporting trustworthy collaboration across the entire AI lifecycle.
Sahara Blockchain and SIWA Testnet (On-Chain Infrastructure)
The SIWA testnet is the first public version of the Sahara Blockchain. The Sahara Blockchain Protocol (SBP) is the core of the Sahara Blockchain—a smart contract system specifically designed for AI, enabling on-chain ownership, provenance tracking, and revenue distribution for AI assets. Core modules include asset registration, ownership protocols, contribution tracking, permission management, revenue distribution, and proof of execution, forming an “on-chain operating system” for AI.
AI Execution Protocol (Off-Chain Infrastructure)
To support the trustworthiness of model execution and invocation, Sahara has also built an off-chain AI execution protocol system, incorporating Trusted Execution Environments (TEE), supporting agent creation, deployment, operation, and collaborative development. Each task execution automatically generates a verifiable record uploaded on-chain, ensuring full traceability and verifiability. The on-chain system handles registration, authorization, and ownership records, while the off-chain AI execution protocol supports real-time operation and service interaction of AI agents.
Due to its cross-chain compatibility, applications built on Sahara AI’s infrastructure can be deployed on any chain—or even off-chain.
Application Layer
Sahara AI Data Service Platform (DSP)
The Data Service Platform (DSP) is the foundational module of Sahara’s application layer. Anyone can participate in data tasks via Sahara ID, engaging in data labeling, denoising, and auditing, and earning on-chain reward points (Sahara Points) as contribution credentials. This mechanism ensures data provenance and ownership while creating a closed loop of “contribution-reward-model optimization.” Currently in its fourth season, this is the primary way general users can contribute.
Beyond this, to encourage submission of high-quality data and services, Sahara implements a dual-incentive mechanism: contributors receive rewards from Sahara and additional returns from ecosystem partners, enabling single contributions to yield multiple benefits. For example, data contributors continue to earn revenue whenever their data is repeatedly invoked or used to generate new applications, allowing them to genuinely participate in the AI value chain. This mechanism extends the lifecycle of data assets and injects powerful momentum into collaboration and co-creation. For instance, MyShell on BNB Chain crowdsources custom datasets via DSP to enhance model performance, with users receiving MyShell token incentives, forming a win-win loop.
AI companies can crowdsource custom datasets via the DSP, issuing specialized data tasks to rapidly gather responses from a global pool of data labelers. This allows AI companies to scale up access to high-quality labeled data without relying solely on traditional centralized data suppliers.
Sahara AI Developer Platform
The Sahara AI Developer Platform is an all-in-one AI development and operations platform for developers and enterprises, offering full lifecycle support from data acquisition and model training to deployment, execution, and asset monetization. Users can directly access high-quality data resources from Sahara DSP for model training and fine-tuning. Processed models can be combined, registered, and listed on the AI Marketplace, with ownership verified and flexible licensing enabled via the Sahara Blockchain. The Studio also integrates decentralized computing power to support model training and agent deployment, ensuring secure and verifiable computation. Developers can store key data and models with encrypted custody and permission controls to prevent unauthorized access. With the Sahara AI Developer Platform, developers can build, deploy, and commercialize AI applications at lower cost and seamlessly integrate into the on-chain AI economy via protocolized mechanisms.
AI Marketplace
The Sahara AI Marketplace is a decentralized asset marketplace for models, datasets, and AI agents. It supports asset registration, trading, and licensing, and builds a transparent and traceable revenue distribution mechanism. Developers can register their models or collected datasets as on-chain assets, set flexible usage licenses and revenue-sharing ratios, and the system will automatically execute settlements based on invocation frequency. Data contributors can also earn continuous revenue shares when their data is reused, achieving “continuous monetization.”
This marketplace is deeply integrated with the Sahara Blockchain Protocol—all asset transactions, invocations, and revenue distributions are on-chain and verifiable, ensuring clear ownership and traceable returns. With this marketplace, AI developers no longer depend on traditional API platforms or centralized model hosting services but instead gain autonomous, programmable commercialization paths.
Ecosystem Layer
Sahara AI’s ecosystem connects data providers, AI developers, consumers, enterprise users, and cross-chain partners. Whether contributing data, developing applications, using products, or driving internal AI transformation, everyone can play a role and find a revenue model. Data annotators, model development teams, and compute providers can register their resources as on-chain assets, authorizing and sharing revenues via Sahara AI’s protocol, automatically earning returns whenever their resources are used. Developers can connect data, train models, and deploy agents via an all-in-one platform, directly commercializing results on the AI Marketplace.
General users without technical backgrounds can participate in data tasks, use AI apps, collect or invest in on-chain assets, becoming part of the AI economy. For enterprises, Sahara offers end-to-end support—from data crowdsourcing and model development to private deployment and revenue monetization. Moreover, Sahara supports cross-chain deployment—any public chain ecosystem can use Sahara AI’s protocols and tools to build AI applications and access decentralized AI assets, achieving compatibility and expansion with the multi-chain world. This makes Sahara AI not just a standalone platform but a foundational collaboration standard for the on-chain AI ecosystem.
Ecosystem Progress
Since its launch, Sahara AI has gone beyond offering AI tools or computing platforms—it is reconstructing the production and distribution order of AI on-chain, building a decentralized collaboration network where everyone can participate, claim ownership, contribute, and share. Precisely for this reason, Sahara chose blockchain as its foundational architecture to build a verifiable, traceable, and distributable economic system for AI.
Around this core goal, the Sahara ecosystem has made significant progress. Despite being in private testing, the platform has accumulated over 3.2 million on-chain accounts, with daily active accounts consistently exceeding 1.4 million, reflecting high user engagement and network vitality. Over 200,000 users have participated in data labeling, training, and validation tasks via the Sahara Data Service Platform and received on-chain incentive rewards. Meanwhile, millions more await entry via the whitelist, confirming strong market demand and consensus for decentralized AI platforms.
In enterprise partnerships, Sahara has established collaborations with global leaders such as Microsoft, Amazon, and MIT, providing customized data collection and labeling services. Enterprises can submit specific tasks, which are efficiently executed by Sahara’s global network of data labelers, achieving scalability, flexibility, and strong support for diverse requirements.
Sahara AI Ecosystem Map
Participation
SIWA will roll out in four phases. The first phase lays the groundwork for on-chain data ownership—contributors can register and tokenize their datasets. It is now publicly open, no whitelist required. Contributors must ensure uploaded data is useful for AI; plagiarism or inappropriate content may be penalized.
SIWA Testnet
The second phase enables on-chain monetization of datasets and models. The third phase opens the testnet and open-sources the protocol. The fourth phase launches AI data stream registration, provenance tracking, and proof-of-contribution mechanisms.
Besides the SIWA testnet, general users can currently engage with Sahara Legends—a gamified experience introducing Sahara AI’s features. Completing tasks earns Guardian fragments, which can later be combined into an NFT commemorating network contributions.
Alternatively, users can label data on the Data Service Platform, contribute valuable data, or serve as reviewers. Sahara plans to collaborate with ecosystem partners on future tasks, allowing participants to earn not only Sahara Points but also partner incentives. The first dual-reward campaign, held with Myshell, lets users earn both Sahara Points and Myshell tokens upon task completion.
According to the roadmap, Sahara plans to launch its mainnet in Q3 2025, potentially accompanied by a TGE.
Challenges and Outlook
Sahara AI makes AI more open, inclusive, and democratized—no longer confined to developers or large AI companies. For ordinary users, Sahara AI enables participation and earning without programming knowledge, creating a decentralized AI world for everyone. For technical developers, it bridges Web2 and Web3 development, offering decentralized yet flexible and powerful tools and high-quality datasets. For AI infrastructure providers, Sahara AI creates new decentralized monetization paths for models, data, compute, and services. Sahara AI doesn’t just build public chain infrastructure—it actively develops core applications, using blockchain to advance AI copyright systems. The project has already achieved initial success through partnerships with multiple top AI institutions. Future success will depend on mainnet performance, ecosystem product development and adoption rates, and whether the economic model can sustain user contributions post-TGE.
Ritual: Innovative Design Overcoming Core AI Challenges Like Heterogeneous Tasks
Project Overview
Ritual aims to solve centralization, opacity, and trust issues in the current AI industry by providing transparent verification mechanisms, fair allocation of computing resources, and flexible model adaptability. It allows any protocol, application, or smart contract to integrate verifiable AI models with just a few lines of code. Through its open architecture and modular design, Ritual promotes widespread on-chain AI adoption, building an open, secure, and sustainable AI ecosystem.
Ritual raised $25 million in a Series A round in November 2023, led by Archetype, with participation from Accomplice and other institutions and notable angel investors, showcasing market confidence and the team’s strong network. Founders Niraj Pant and Akilesh Potti were former partners at Polychain Capital, having led investments in industry giants like Offchain Labs and EigenLayer, demonstrating deep insight and judgment. The team has extensive experience in cryptography, distributed systems, and AI, with advisors including founders of NEAR and EigenLayer, underscoring its strong pedigree and potential.
Architecture
From Infernet to Ritual Chain
Ritual Chain is the second-generation evolution from the Infernet node network, representing a comprehensive upgrade in decentralized AI computing networks.
Infernet, Ritual’s first-stage product launched in 2023, is a decentralized oracle network designed for heterogeneous computing tasks. It addresses limitations of centralized APIs, enabling developers to freely and stably invoke transparent, open, decentralized AI services.
Infernet adopted a lightweight, easy-to-use framework. Due to its simplicity and efficiency, it quickly attracted over 8,000 independent nodes. These nodes possess diverse hardware capabilities, including GPUs and FPGAs, providing powerful computing power for complex tasks such as AI inference and zero-knowledge proof generation. However, to maintain system simplicity, Infernet sacrificed some key functions—such as consensus-based node coordination or robust task routing mechanisms. These limitations made it difficult for Infernet to meet broader needs of Web2 and Web3 developers, prompting Ritual to launch the more comprehensive and powerful Ritual Chain.
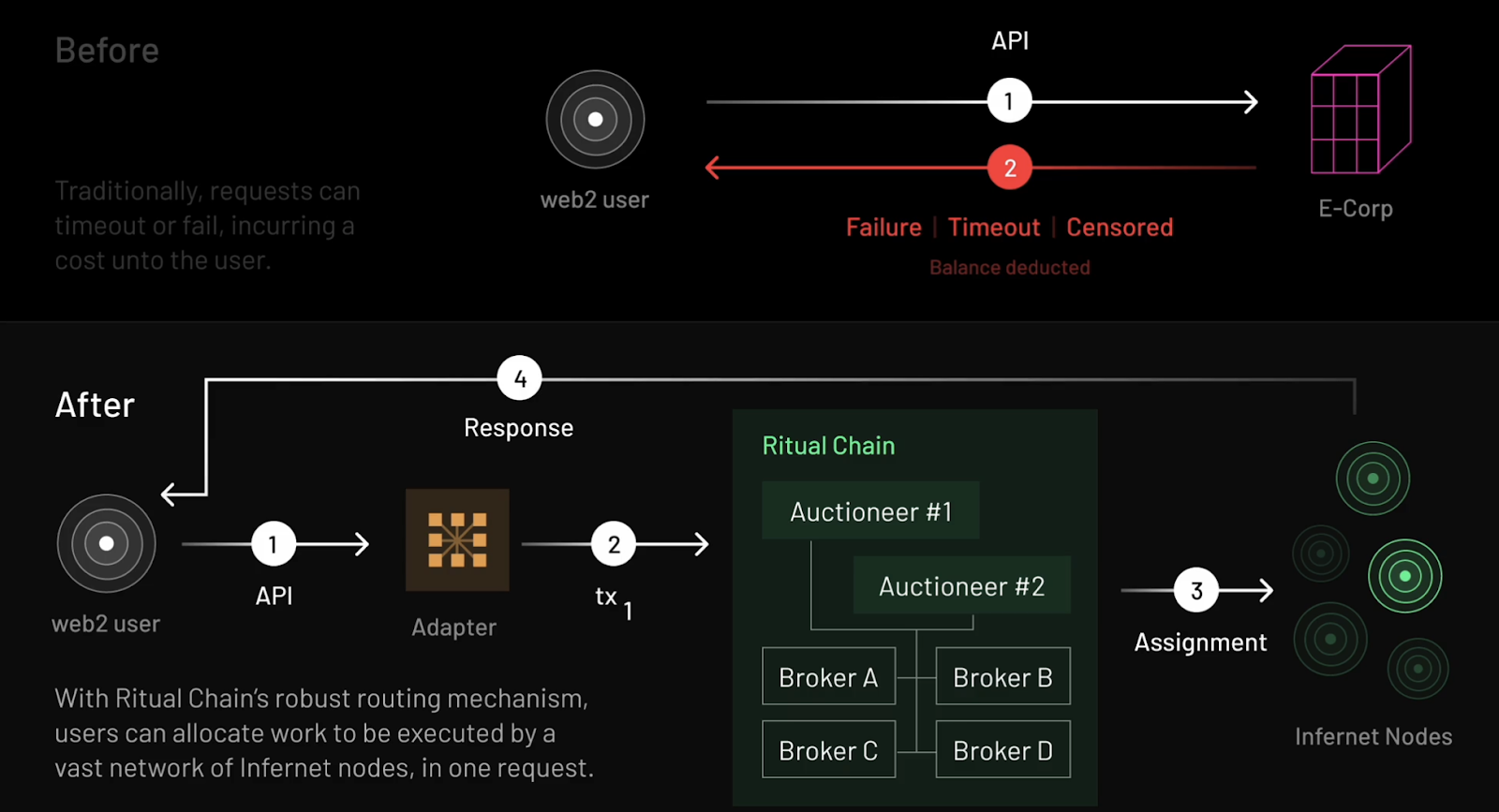
Ritual Chain Workflow Diagram
Ritual Chain is a next-generation Layer 1 blockchain purpose-built for AI applications, designed to overcome Infernet’s limitations and offer developers a more robust and efficient development environment. Using Resonance technology, Ritual Chain provides simple, reliable pricing and task routing mechanisms for the Infernet network, significantly optimizing resource allocation efficiency. Additionally, Ritual Chain is built on the EVM++ framework—an extension of the Ethereum Virtual Machine (EVM) that maintains backward compatibility while adding enhanced capabilities such as precompiles, native scheduling, built-in Account Abstraction (AA), and a suite of advanced Ethereum Improvement Proposals (EIPs). These features collectively create a powerful, flexible, and efficient development environment, unlocking new possibilities for developers.
Precompiled Sidecars
Compared to traditional precompiles, Ritual Chain’s design enhances system extensibility and flexibility, allowing developers to create custom functional modules in containerized form without modifying the underlying protocol. This architecture significantly reduces development costs and provides dApps with stronger computing capabilities.
Specifically, Ritual Chain decouples complex computations from execution clients using a modular architecture, implementing them as independent Sidecars. These precompiled modules efficiently handle complex computing tasks such as AI inference, zero-knowledge proof generation, and Trusted Execution Environment (TEE) operations.
Native Scheduling
Native scheduling solves the need for timed or conditional task triggering. Traditional blockchains typically rely on centralized third-party services (like keepers) to trigger task execution, which introduces centralization risks and high costs. Ritual Chain eliminates dependence on centralized services via a built-in scheduler—developers can directly set entry points and callback frequencies for smart contracts on-chain. Block producers maintain a mapping of pending calls and prioritize handling these tasks when generating new blocks. Combined with Resonance’s dynamic resource allocation, Ritual Chain reliably and efficiently handles compute-intensive tasks, providing stable support for decentralized AI applications.
Technical Innovations
Ritual’s core technical innovations ensure its leadership in performance, verification, and scalability, providing strong support for on-chain AI applications.
1. Resonance: Optimizing Resource Allocation
Resonance is a bilateral market mechanism designed to optimize blockchain resource allocation, addressing the complexity of heterogeneous transactions. As blockchain transactions evolve from simple transfers to smart contracts, AI inference, and more, existing fee mechanisms (like EIP-1559) struggle to efficiently match user demands with node resources. Resonance introduces two core roles—Broker and Auctioneer—to achieve optimal matching between user transactions and node capabilities:
-
Broker: Analyzes users’ willingness to pay and nodes’ resource cost functions to achieve optimal transaction-node matching, improving computational resource utilization.
-
Auctioneer: Organizes transaction fee distribution via a bilateral auction mechanism, ensuring fairness and transparency. Nodes choose transaction types based on their hardware capabilities, while users submit transaction requests based on priority conditions (e.g., speed or cost).
This mechanism significantly improves network resource efficiency and user experience, while enhancing system transparency and openness through decentralized auctions.
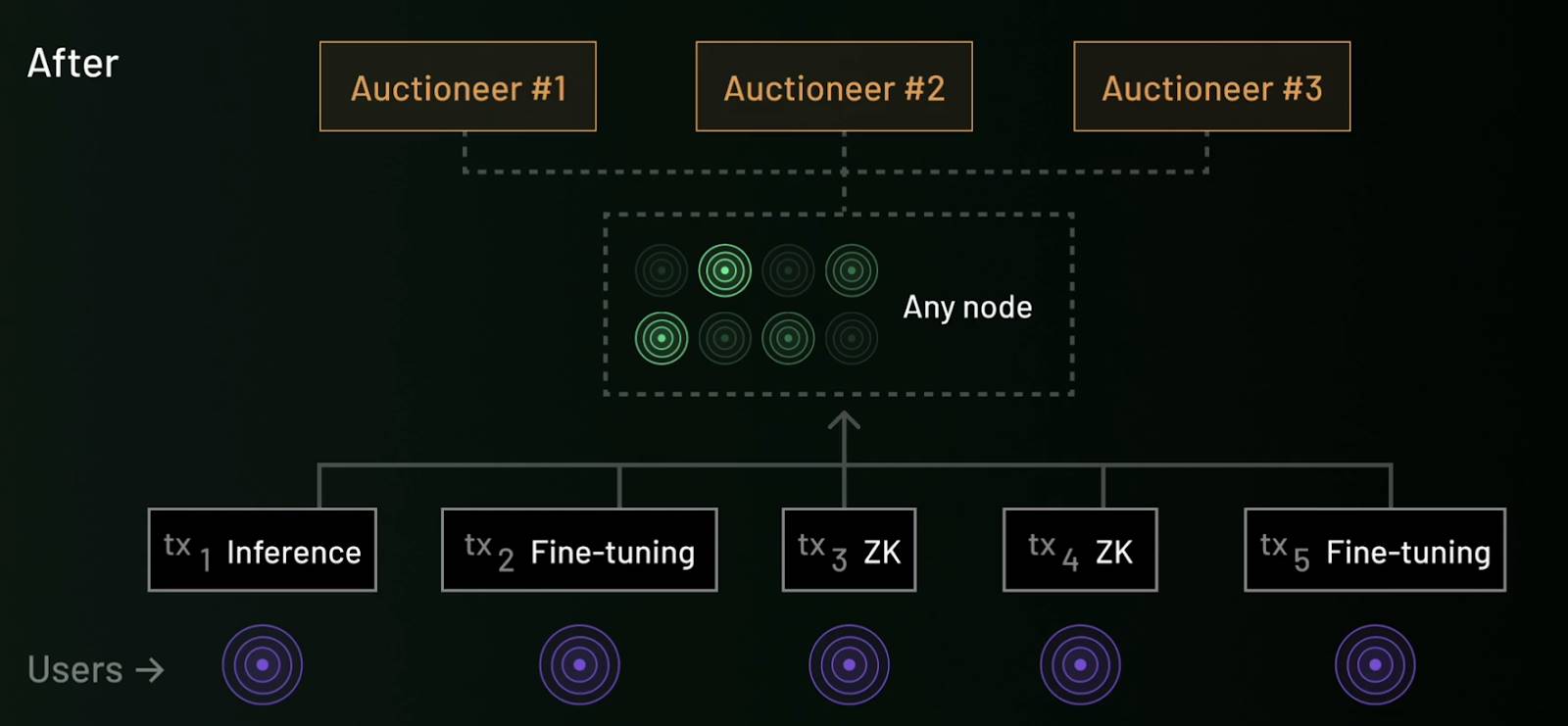
Under Resonance: Auctioneer assigns appropriate tasks to nodes based on Broker analysis
2. Symphony: Enhancing Verification Efficiency
Symphony focuses on improving verification efficiency, addressing the inefficiency of traditional blockchain “re-execution” models when handling and verifying complex computing tasks. Based on the “Execute Once, Verify Many Times” (EOVMT) model, Symphony separates computation from verification, drastically reducing performance overhead from redundant calculations.
-
A designated node executes the computing task once, broadcasts the result across the network, and verification nodes use succinct proofs to confirm correctness without re-executing the computation.
-
Symphony supports distributed verification—breaking complex tasks into subtasks processed in parallel by different verification nodes—further boosting verification efficiency while ensuring privacy and security.
Symphony is highly compatible with proof systems like Trusted Execution Environments (TEE) and Zero-Knowledge Proofs (ZKP), offering flexible support for fast transaction confirmation and privacy-sensitive computing tasks. This architecture significantly reduces performance overhead from redundant computation while ensuring decentralized and secure verification.
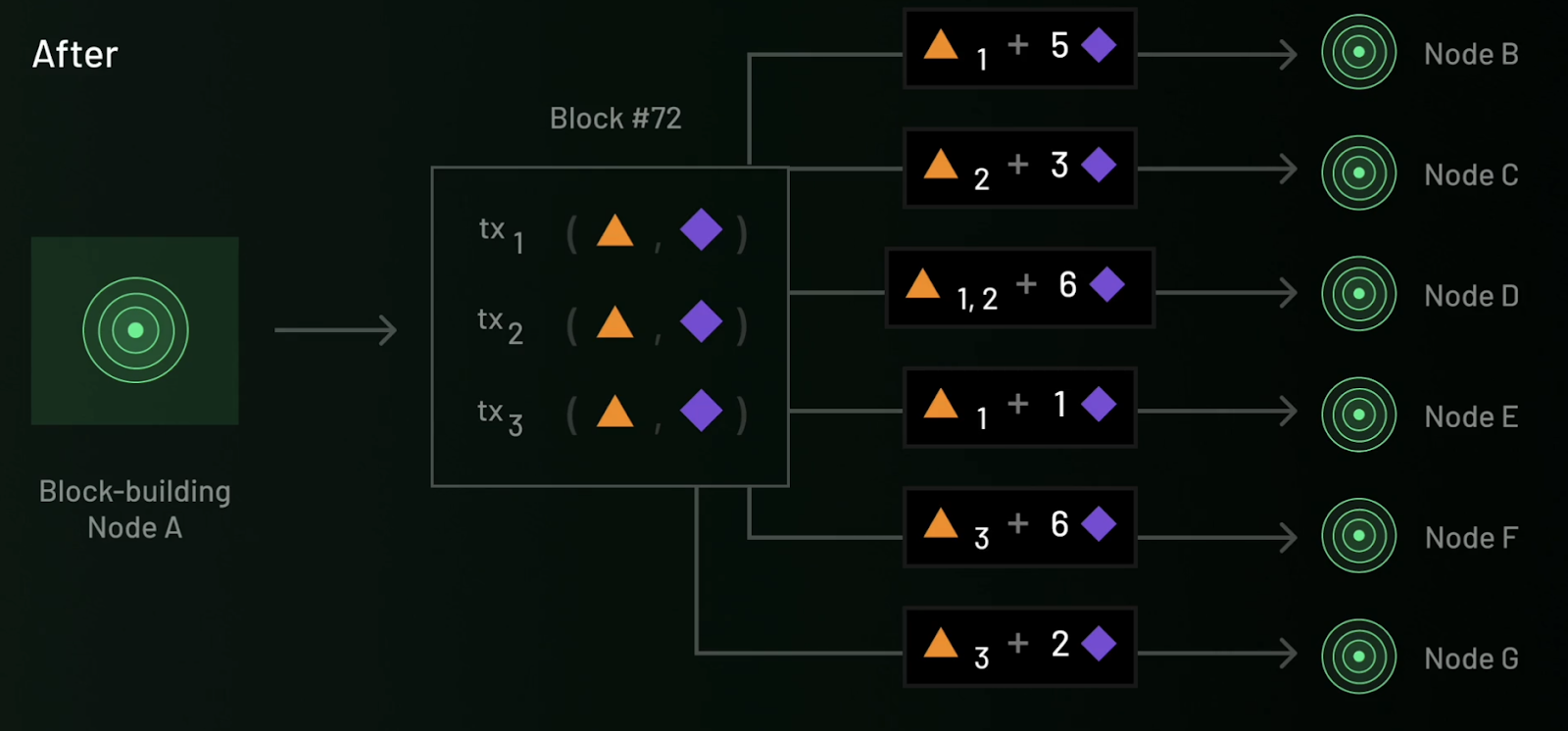
Symphony breaks complex tasks into subtasks, processed in parallel by different verification nodes
3. vTune: Traceable Model Verification
vTune is a tool provided by Ritual for model verification and origin tracing, with minimal impact on model performance and strong resistance to interference. It is particularly suited for protecting intellectual property of open-source models and promoting fair distribution. vTune combines watermarking and zero-knowledge proofs, embedding covert markers to enable origin tracing and computational integrity assurance:
-
Watermarking: Markers are embedded via weight-space watermarking, data watermarking, or function-space watermarking. Even if the model is public, ownership can still be verified. Function-space watermarking, in particular, allows ownership verification through model outputs without accessing model weights, offering stronger privacy protection and robustness.
-
Zero-Knowledge Proofs: Covert data is introduced during model fine-tuning to verify whether the model has been tampered with, while protecting the rights of model creators.
This tool not only provides credible source verification for decentralized AI model markets but also significantly enhances model security and ecosystem transparency.
Ecosystem Development
Ritual is currently in private testnet phase, offering limited participation opportunities for general users. Developers can apply for the official Altar and Realm incentive programs to join Ritual’s AI ecosystem, receiving full-stack technical and financial support from the team.
The official has announced a batch of native applications from the Altar program:
-
Relic: A machine learning-powered automated market maker (AMM) that dynamically adjusts liquidity pool parameters via Ritual’s infrastructure to optimize fees and underlying pools;
-
Anima: A tool focused on LLM-powered on-chain trading automation, providing users with seamless, natural Web3 interaction;
-
Tithe: An AI-driven lending protocol that supports a wider range of asset types through dynamic optimization of lending pools and credit scoring.
Additionally, Ritual has engaged in deep collaborations with several mature projects to advance the decentralized AI ecosystem. For example, its partnership with Arweave provides decentralized, permanent storage for models, data, and zero-knowledge proofs; integration with StarkWare and Arbitrum brings native on-chain AI capabilities to these ecosystems; and EigenLayer’s restaking mechanism adds active validation services to Ritual’s proof market, further enhancing network decentralization and security.
Challenges and Outlook
Ritual’s design tackles core issues in decentralized AI—from allocation and incentives to verification—while using tools like vTune to achieve model verifiability, overcoming the conflict between open-source models and incentives, and providing technical support for building decentralized model markets.
Currently in its early stages, Ritual primarily targets the inference phase of models. Its product matrix is expanding from infrastructure to model markets, L2-as-a-Service (L2aaS), and agent frameworks. As the blockchain remains in private testnet, Ritual’s advanced technical designs require large-scale public validation—ongoing observation is needed. We look forward to Ritual becoming a key component of decentralized AI infrastructure as its technology matures and its ecosystem grows.
Gensyn: Solving Core Problems in Decentralized Model Training
Project Overview
In an era of accelerating AI evolution and increasingly scarce computing resources, Gensyn is attempting to reshape the fundamental paradigm of AI model training.
In traditional AI model training workflows, computing power is almost monopolized by a few cloud computing giants, resulting in high costs and low transparency, hindering innovation by small and medium-sized teams and independent researchers. Gensyn’s vision is precisely to break this “centralized monopoly”—instead advocating for “pushing down” training tasks to countless devices worldwide with basic computing capabilities, whether MacBooks, gaming-grade GPUs, edge devices, or idle servers, all of which can join the network, execute tasks, and earn rewards.
Founded in 2020, Gensyn focuses on building decentralized AI computing infrastructure. As early as 2022, the team first proposed redefining AI model training at both technical and institutional levels—moving away from closed cloud platforms or massive server clusters, instead distributing training tasks across heterogeneous computing nodes globally to build a trustless intelligent computing network.
In 2023, Gensyn expanded its vision further: building a globally connected, open-source, self-governing, permissionless AI network—where any device with basic computing power can become a participant. Its underlying protocol is built on blockchain architecture, combining composability of incentive and verification mechanisms.
Since inception, Gensyn has raised $50.6 million in funding from 17 institutions including a16z, CoinFund, Canonical, Protocol Labs, and Distributed Global. The Series A round in June 2023, led by a16z, attracted widespread attention, marking the entry of decentralized AI into the mainstream Web3 VC spotlight.
The core team also boasts impressive credentials: co-founder Ben Fielding holds a degree in theoretical computer science from Oxford University, bringing deep technical research expertise; the other co-founder, Harry Grieve, has extensive experience in system design and economic modeling for decentralized protocols, providing solid support for Gensyn’s architectural design and incentive mechanisms.
Architecture
Current development in decentralized AI systems faces three major technical bottlenecks: execution, verification, and communication. These constraints not only limit the release of large model training capabilities but also hinder the fair integration and efficient utilization of global computing resources. Based on systematic research, the Gensyn team has proposed three representative innovative mechanisms—RL Swarm, Verde, and SkipPipe—offering distinct solutions to these problems and advancing decentralized AI infrastructure from concept toward reality.
1. Execution Challenge: How to Enable Fragmented Devices to Collaboratively Train Large Models Efficiently?
Currently, improvements in large language model performance mainly rely on the “scale-up” strategy: larger parameter counts, broader datasets, and longer training cycles. But this significantly increases computing costs—training ultra-large models often requires splitting workloads across thousands of GPU nodes, which must conduct frequent data communication and gradient synchronization. In decentralized settings, nodes are widely distributed geographically, have heterogeneous hardware, and exhibit high state volatility, making traditional centralized scheduling strategies ineffective.
To address this challenge, Gensyn proposes RL Swarm, a peer-to-peer reinforcement learning post-training system. Its core idea transforms the training process into a distributed collaborative game. The mechanism operates in three phases: “Share-Critique-Decide”: First, nodes independently complete problem reasoning and publicly share results; then, each node evaluates peers’ answers, providing feedback on logical consistency and strategic soundness; finally, nodes revise their outputs based on collective opinions to generate more robust answers. This mechanism effectively combines individual computation with group collaboration, particularly suitable for high-precision, verifiable tasks like mathematical and logical reasoning. Experiments show RL Swarm improves efficiency and significantly lowers entry barriers, exhibiting excellent scalability and fault tolerance.
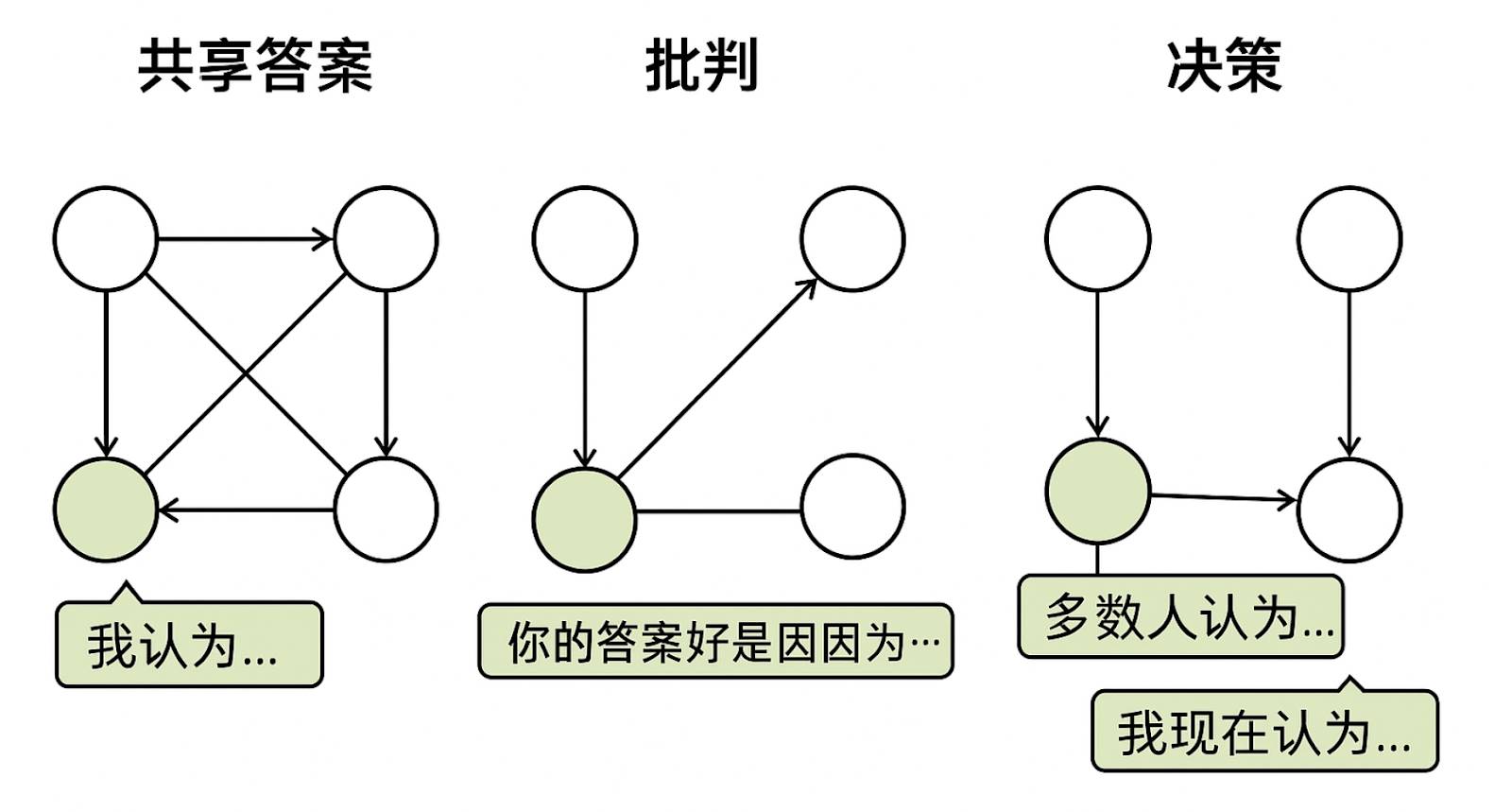
RL Swarm's Three-Phase Reinforcement Learning Training System: "Share-Critique-Decide"
2. Verification Challenge: How to Verify That Untrusted Providers Have Correctly Executed Computations?
In a decentralized training network, “anyone can provide computing power” is both an advantage and a risk. The key question is: how to verify these computations are genuine and effective without trusting the provider?
Traditional methods like recomputation or whitelisting have clear limitations—the former is too costly and unscalable; the latter excludes “long-tail” nodes, undermining network openness. To address this, Gensyn designed Verde, a lightweight arbitration protocol specifically built for neural network training verification.
Verde’s key idea is “minimal trusted arbitration”: when a verifier suspects a provider’s training result is incorrect, the arbitration contract only needs to recompute the first disputed operation node in the computation graph, rather than replaying the entire training process. This dramatically reduces verification overhead while ensuring correctness as long as at least one party is honest. To resolve floating-point nondeterminism across different hardware, Verde also developed Reproducible Operators—a library that enforces unified execution orders for common mathematical operations like matrix multiplication, achieving bit-level consistent outputs across devices. This technology significantly enhances the security and engineering feasibility of distributed training, representing a major breakthrough in trustless verification systems.
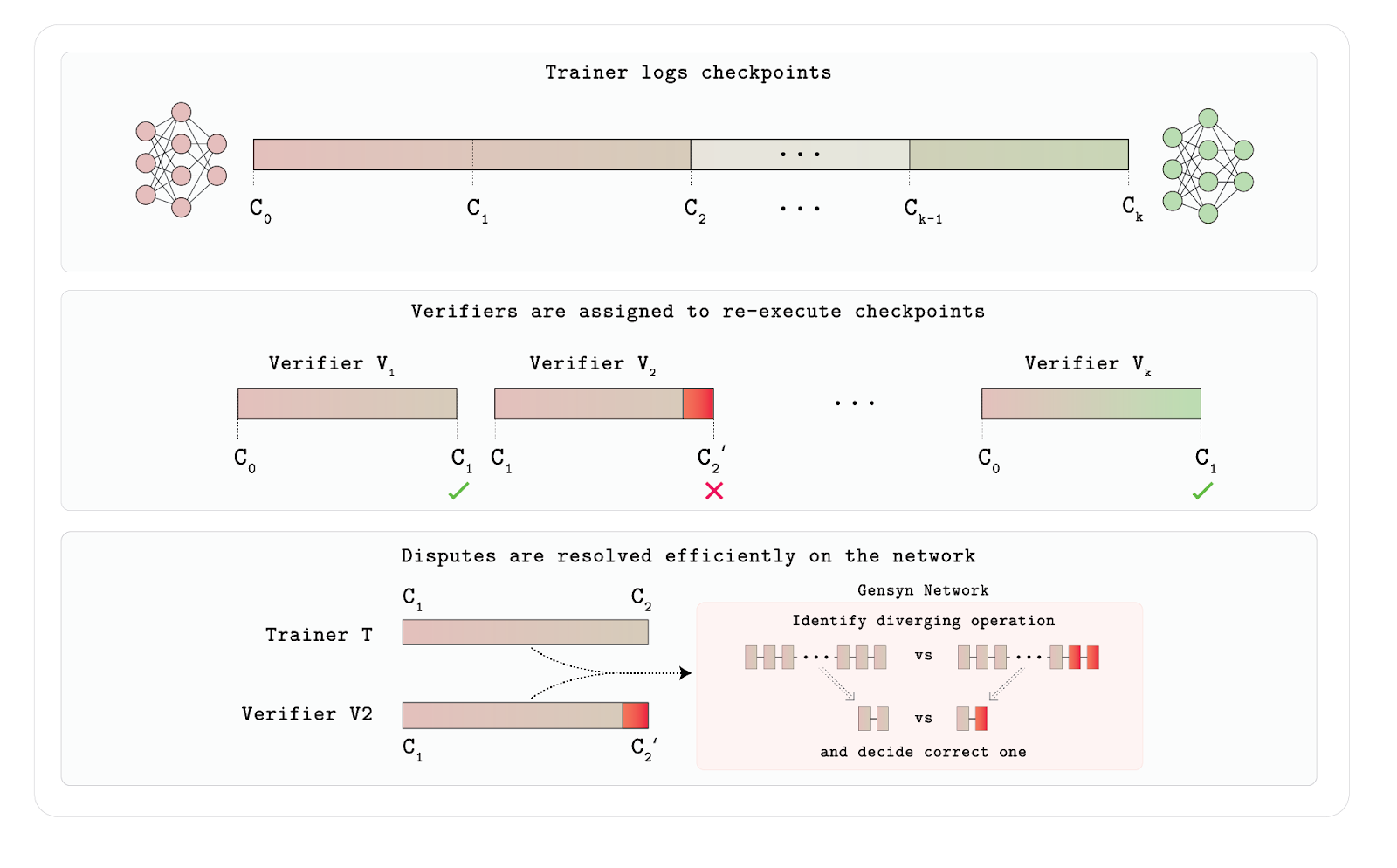
Verde Workflow
The entire mechanism relies on trainers recording key intermediate states (checkpoints). Multiple verifiers are randomly assigned to replay these training steps and judge output consistency. If a verifier’s recomputed result differs from the trainer’s, the system does not naively rerun the entire model. Instead, it uses a network arbitration mechanism to precisely locate the first divergent operation in the computation graph and only replays and compares that operation, resolving disputes at very low cost. In this way, Verde guarantees training integrity without trusting training nodes, while balancing efficiency and scalability—making it a purpose-built verification framework for distributed AI training environments.
3. Communication Challenge: How to Reduce Network Bottlenecks Caused by Frequent Node Synchronization?
In traditional distributed training, models are either fully replicated or split layer-by-layer (pipeline parallelism), both requiring frequent inter-node synchronization. Especially in pipeline parallelism, a micro-batch must strictly pass through each model layer in sequence, meaning a delay in any node stalls the entire training process.
To solve this, Gensyn proposes SkipPipe: a highly fault-tolerant pipelined training system supporting jump execution and dynamic path scheduling. SkipPipe introduces a “skip ratio” mechanism, allowing certain micro-batches to skip parts of the model layers when specific nodes are overloaded, while using scheduling algorithms to dynamically select the current optimal computation path. Experiments show that in geographically dispersed, hardware-diverse, bandwidth-limited network environments, SkipPipe can reduce training time by up to 55% and maintain only 7% loss even under 50% node failure rates, demonstrating exceptional resilience and adaptability.
Participation
Gensyn’s public testnet launched on March 31, 2025, currently in the initial phase (Phase 0) of its technical roadmap, focusing primarily on deploying and validating RL Swarm. RL Swarm is Gensyn’s first application scenario, designed for collaborative reinforcement learning model training. Each participating node binds its behavior to an on-chain identity, with the entire contribution process fully recorded—providing a verification foundation for future incentive distribution and trusted computing models.
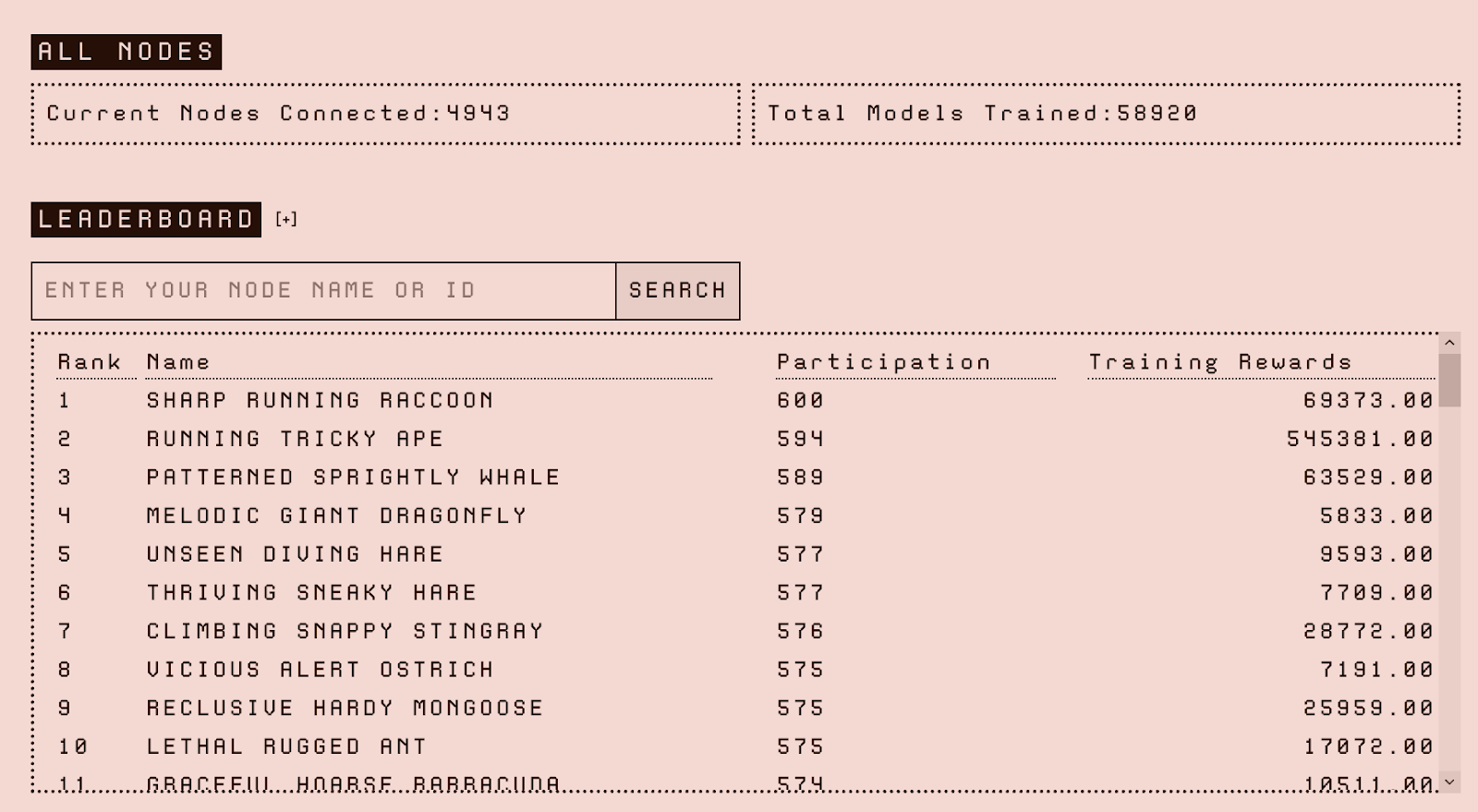
Gensyn Node Rankings
Hardware requirements in the early test phase are relatively accessible: Mac users with M-series chips can run it, while Windows users are recommended to have high-performance GPUs like the 3090 or 4090 and at least 16GB RAM to deploy a local Swarm node.
After system setup, users log in via email (Gmail recommended) to complete verification and optionally bind a HuggingFace Access Token to unlock enhanced model capabilities.
Challenges and Outlook
The biggest uncertainty for Gensyn currently is that its testnet does not yet include the full promised tech stack. Key modules like Verde and SkipPipe remain un-integrated, keeping external observers cautious about its architectural execution. The official explanation is that the testnet will roll out in stages, with each phase unlocking new protocol capabilities, prioritizing infrastructure stability and scalability. The first phase starts with RL Swarm, with future phases gradually expanding to pre-training, inference, and ultimately transitioning to mainnet deployment supporting real economic transactions.
Although the testnet started with a conservative pace, notably, just one month later, Gensyn launched a new Swarm test task supporting larger models and complex math tasks. This move somewhat responds to criticism about development speed and demonstrates the team’s execution efficiency in advancing individual modules.
However, new issues arise: the new task imposes extremely high hardware requirements, recommending top-tier GPUs like A100 or H100 (80GB VRAM)—nearly inaccessible for small and medium nodes. This creates tension with Gensyn’s stated goal of “open access and decentralized training.” Without proper guidance, a trend toward compute centralization could undermine network fairness and the sustainability of decentralized governance.
Going forward, successful integration of Verde and SkipPipe could enhance protocol completeness and synergy. But whether Gensyn can truly balance performance and decentralization remains to be seen through longer-term, broader practice on the testnet. For now, it shows promise and exposes challenges—exactly the authentic state of an early-stage infrastructure project.
Bittensor: Innovation and Development in Decentralized AI Networks
Project Overview
Bittensor is a pioneering project combining blockchain and artificial intelligence, founded in 2019 by Jacob Steeves and Ala Shaabana, aiming to build a “market economy for machine intelligence.” Both founders have strong backgrounds in artificial intelligence and distributed systems. Yuma Rao, credited as the whitepaper’s author, is considered the team’s core technical advisor, bringing professional expertise in cryptography and consensus algorithms.
The project aims to integrate global computing resources via blockchain protocols, building a continuously self-optimizing distributed neural network ecosystem. This vision transforms digital assets like computation, data, storage, and models into intelligent value streams, creating a new economic form that ensures fair distribution of AI development benefits. Unlike centralized platforms like OpenAI, Bittensor establishes three core value pillars:
-
Breaking Data Silos: Uses the TAO token incentive system to promote knowledge sharing and model contribution
-
Market-Driven Quality Evaluation: Introduces game-theoretic mechanisms to screen high-quality AI models, enabling survival of the fittest
-
Network Effect Amplifier: Participant growth and network value grow exponentially, creating a virtuous cycle
In investment terms, Polychain Capital incubated Bittensor starting in 2019 and currently holds approximately $200 million worth of TAO tokens; Dao5 holds around $50 million worth of TAO, also an early supporter of the Bittensor ecosystem. In 2024, Pantera Capital and Collab Currency made strategic investments. In August 2024, Grayscale added TAO to its decentralized AI fund, signaling strong institutional recognition and long-term confidence in the project.
Architecture and Operational Mechanisms
Network Architecture
Bittensor has built a sophisticated four-tier network architecture:
-
Blockchain Layer: Built on the Substrate framework, serving as the network’s trust foundation, responsible for recording state changes and token issuance. The system generates a new block every 12 seconds and issues TAO tokens according to rules, ensuring network consensus and incentive distribution.
-
Neuron Layer: Acts as the network’s computing nodes, running various AI models to provide intelligent services. Each node clearly declares its service type and interface specifications through a carefully designed configuration file, enabling modular, plug-and-play functionality.
-
Synapse Layer: The network’s communication bridge, dynamically optimizing connection weights between nodes to form a brain-like neural structure, ensuring efficient information transfer. Synapses also include an economic model—interactions and service calls between neurons require payment in TAO tokens, forming a closed-loop value flow.
-
Metagraph Layer: Serving as the system’s global knowledge graph, continuously monitoring and evaluating each node’s contribution value, providing intelligent guidance for the entire network. The metagraph precisely calculates synapse weights, influencing resource allocation, reward mechanisms, and node influence within the network.
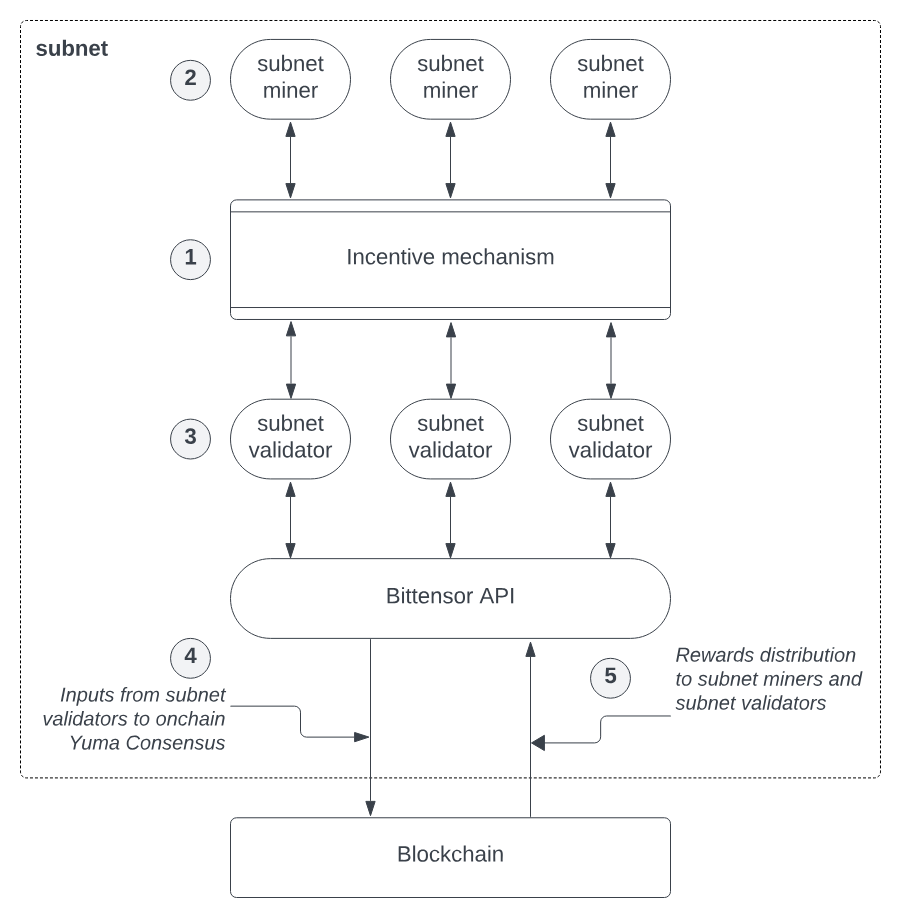
Bittensor Network Framework
Yuma Consensus Mechanism
The network uses the unique Yuma consensus algorithm, completing a reward distribution cycle every 72 minutes. The validation process combines subjective evaluation with objective metrics:
-
Manual Scoring: Validators subjectively evaluate miner output quality
-
Fisher Information Matrix: Objectively quantifies a node’s contribution to the overall network
This “subjective + objective” hybrid mechanism effectively balances expert judgment with algorithmic fairness.
Subnet Architecture and dTAO Upgrade
Each subnet specializes in a specific AI service domain—such as text generation or image recognition—operating independently while remaining connected to the main blockchain (subtensor), forming a highly flexible, modular expansion architecture. In February 2025, Bittensor completed the landmark dTAO (Dynamic TAO) upgrade, transforming each subnet into an independent economic unit that intelligently allocates resources based on market demand signals. Its core innovation is the subnet token (Alpha token) mechanism:
-
Operation Principle: Participants stake TAO to receive Alpha tokens issued by each subnet, representing market recognition and support for that subnet’s services
-
Resource Allocation Logic: The market price of Alpha tokens serves as a key indicator of subnet demand strength. Initially, all subnet Alpha
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














