

Testing 7 Mainstream AI Large Models Reveals Privacy Exposure as a Common Flaw
TechFlow Selected TechFlow Selected
Testing 7 Mainstream AI Large Models Reveals Privacy Exposure as a Common Flaw
We look forward to active responses from major model providers, proactively optimizing product designs and privacy policies, and clearly explaining to users the origins and usage of their data in a more open and transparent manner, so that users can confidently use large model technologies.
Author: Siyuan,TechFlow

Image source: Generated by Wujie AI
In the age of AI, user-input information no longer belongs solely to personal privacy—it has become a "stepping stone" for advancing large models.
"Help me create a PowerPoint," "Design a Spring Festival poster," "Summarize this document." Since the rise of large models, using AI tools to boost productivity has become part of white-collar workers’ daily routines. Some even use AI to order takeout or book hotels.
However, this method of data collection and usage brings significant privacy risks. Many users overlook a key issue in the digital era: the lack of transparency when using digital technologies and tools. They are unaware of how their data is collected, processed, and stored by these AI tools, nor can they be certain whether their data might be misused or leaked.
In March this year, OpenAI admitted that ChatGPT had a vulnerability exposing some users' chat history—sparking public concern over data security and personal privacy in large models. Beyond the ChatGPT incident, Meta’s AI model also faced controversy over copyright infringement. In April, U.S. authors and artists sued Meta, accusing its AI model of being trained on their works without permission.
Similar incidents have occurred domestically as well. Recently, iQiyi and MiniMax—one of China's so-called "six little tigers" of large models—drew attention due to a copyright dispute. iQiyi accused MiniMax’s Helu AI of using its copyrighted materials to train models without authorization. This marks the first lawsuit in China where a video platform has taken legal action against an AI video model for infringement.
These events have heightened scrutiny over the sources of training data and copyright issues in large models, underscoring that AI advancement must be built upon robust user privacy protection.
To assess current transparency levels in Chinese large models, TechFlow selected seven mainstream domestic AI products—Doubao, ERNIE Bot, Kimi, HunYuan, Spark Large Model, Qwen (Tongyi Qianwen), and Kuaishou KeLing—for evaluation. Through analysis of privacy policies, user agreements, and hands-on testing of product design, we found many shortcomings—revealing the sensitive relationship between user data and AI products.
01. Withdrawal Rights Are Largely Illusory
Firstly, TechFlow observed from login pages that all seven Chinese large model apps follow the standard internet APP practice of including Terms of Service and Privacy Policies. Each policy contains sections explaining how personal information is collected and used.
The wording across these platforms is nearly identical: “To optimize and improve service experience, we may analyze user feedback on output content and issues encountered during use. Under secure encryption and strict de-identification measures, user inputs, instructions given to the AI, generated responses, and usage patterns may be analyzed and used for model training.”
In theory, using user data to refine products creates a positive cycle. But users care about one critical question: Do they have the right to refuse or withdraw consent for their data to be fed into AI training?
TechFlow’s review and practical testing revealed that only four out of the seven—Doubao, iFlytek, Qwen, and KeLing—explicitly mention options to “change the scope of data collection or withdraw consent” within their privacy clauses.
Doubao primarily allows withdrawal specifically regarding voice data. Its policy states: “If you do not wish your input or provided voice information to be used for model training and optimization, you can disable it via Settings > Account Settings > Improve Voice Service.” However, for other types of data, users must contact official support directly to request removal from training datasets.

Image source: (Doubao)
In practice, disabling voice service permissions isn't difficult—but attempting to withdraw consent for other data proved ineffective. After contacting Doubao’s official team, TechFlow received no response.
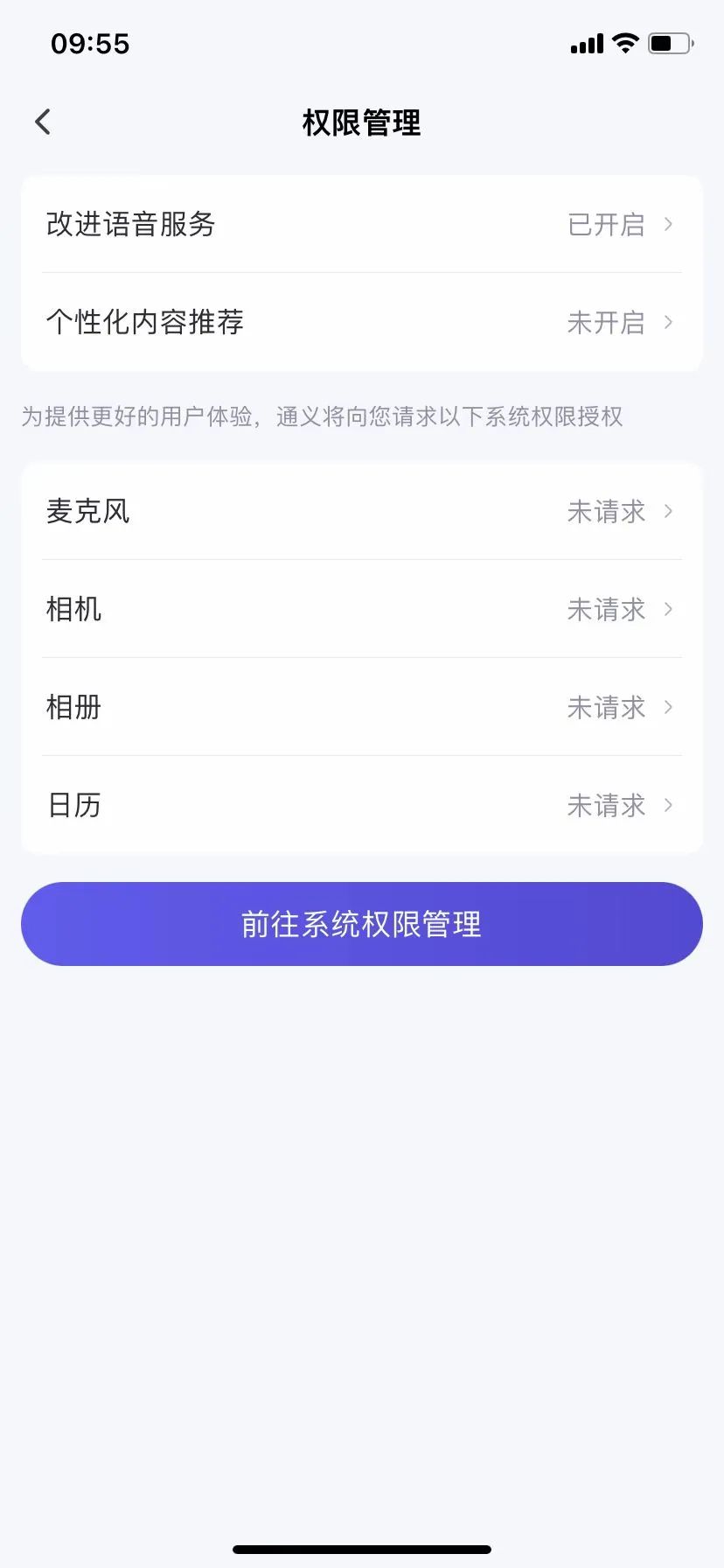
Image source: (Doubao)
Qwen operates similarly to Doubao. Users can only independently opt out of voice-related data collection. For any other data, they must reach out through disclosed channels to modify or revoke consent for data processing.

Image source: (Qwen)
KeLing, as a video and image generation platform, emphasizes facial data usage, stating it will not use or share users’ facial pixel information with third parties for any other purpose. However, to cancel authorization, users must send an email to the official team.

Image source: (KeLing)
Compared to Doubao, Qwen, and KeLing, iFlytek’s Spark Large Model imposes stricter conditions. According to its terms, users who want to change or withdraw consent for personal data collection must do so by deleting their account entirely.

Image source: (iFlytek Spark)
Notably, Tencent Yuanbao does not specify in its policy how users can alter data authorization, but within the app, there is a toggle switch labeled “Voice Function Improvement Plan.”

Image source: (Tencent Yuanbao)
Kimi mentions in its privacy policy that users can revoke sharing of voiceprint information with third parties and perform such actions within the app. However, after extensive exploration, TechFlow could not locate the actual interface. As for text-based data, no relevant provisions were found.

Image source: (Kimi Privacy Policy)
From examining these major models, it’s clear that companies place greater emphasis on managing voiceprints—platforms like Doubao and Qwen allow self-service opt-out. Basic permissions related to location, camera, and microphone access can also be disabled manually. But withdrawing data already “fed” into training remains cumbersome across the board.
It's worth noting that overseas models adopt similar approaches regarding “user data opt-out mechanisms.” Google Gemini’s policy states: “If you don’t want us to review future conversations or use them to improve Google’s machine learning technologies, turn off Gemini app activity logging.”
Gemini further clarifies that once application activity logs are deleted, system records reviewed or annotated by human reviewers—including associated language, device type, location, or feedback—will not be erased, as they are stored separately and unlinked from Google accounts. These records may remain for up to three years.
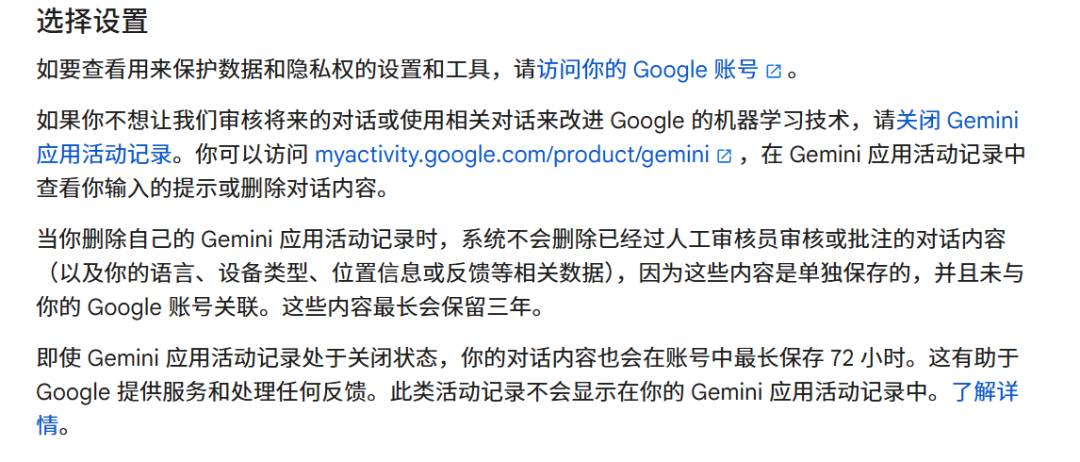
Image source: (Gemini Policy)
ChatGPT’s rules are somewhat ambiguous. It claims users may have rights to limit personal data processing. In practice, however, only Plus subscribers can actively disable data usage for training. Free users’ data is typically collected by default for training purposes, and opting out requires direct communication with the company.

Image source: (ChatGPT Policy)
Clearly, collecting user input has become an industry norm. Yet only multimodal platforms offer limited safeguards for more sensitive biometric data such as voiceprints or facial features.
This lack of transparency cannot be attributed to inexperience—especially among major tech firms. For instance, WeChat’s privacy policy meticulously details every data collection scenario, purpose, and scope, even explicitly promising “not to collect users’ chat records.” Douyin follows a similar approach, clearly specifying in its privacy policy how uploaded content is used and for what purposes.

Image source: (Douyin Privacy Policy)
Data collection practices strictly regulated during the social media era have now become commonplace in the AI age. User inputs are freely harvested by large model providers under the banner of “training corpus,” transforming personal data from protected privacy into mere stepping stones for model improvement.
Beyond user data, transparency in training corpora is equally crucial. Whether these materials are legally sourced, constitute infringement, or pose latent risks to users—all remain pressing concerns. With these questions in mind, we conducted deeper investigations into the seven selected models, yielding surprising results.
02. Hidden Risks in Training Data “Feeding”
Large model training relies not only on computing power but also high-quality corpora. However, these often include copyrighted texts, images, videos, and other creative works. Unauthorized use clearly constitutes infringement.
TechFlow found that none of the seven large models disclose specific sources of their training data in their user agreements, let alone reveal copyrighted content used.

The reason for this collective silence is straightforward. First, improper data usage easily triggers copyright disputes, and there are currently no clear regulations governing whether using copyrighted material for AI training is legal. Second, it relates to competitive dynamics—disclosing training data is akin to food manufacturers revealing their ingredients, enabling competitors to quickly replicate and enhance their own offerings.
Notably, most model policies state that user interactions with the AI may be used for service optimization, research, brand promotion, marketing, and user surveys.
Honestly speaking, due to inconsistent data quality, shallow contextual depth, and diminishing marginal returns, user-generated data rarely enhances model capabilities—and may even increase data cleaning costs. Nevertheless, user data still holds value—not necessarily for improving model performance, but as a new avenue for commercial gain. By analyzing user conversations, companies can uncover behavioral insights, identify monetization opportunities, customize commercial features, and even share information with advertisers—all consistent with existing model usage policies.
Moreover, real-time processing generates data uploaded and stored in the cloud. While most large models claim to protect personal information using encryption, anonymization, and other industry-standard methods, the actual effectiveness remains questionable.
For example, if user inputs are stored in datasets, others querying similar topics later could lead to information leakage. Additionally, in the event of a cyberattack on the cloud infrastructure or product itself, original data might still be reconstructed through correlation or advanced analysis techniques—posing another risk.
The European Data Protection Board (EDPB) recently issued guidance on personal data processing by AI models. It emphasized that AI model anonymity cannot be assumed based on mere statements—it must be rigorously verified through technical validation and continuous monitoring. The guidance also stresses that enterprises must not only justify the necessity of data processing activities but also demonstrate the use of minimally intrusive methods for individual privacy throughout the process.

Therefore, when large model companies claim data collection is “for improving model performance,” we should critically ask: Is this truly essential for progress—or merely a commercially motivated abuse of user data?
03. The Gray Zone of Data Security
Beyond standard AI applications, agents and on-device AI introduce even more complex privacy risks.
Compared to chatbots and other AI tools, AI agents and on-device AI require access to more detailed and valuable personal information. Traditional mobile apps typically collect device and app information, logs, and basic permission data. But in on-device AI scenarios—especially those relying on screen reading and recording technologies—terminal agents can obtain full screen recordings and, via model analysis, extract highly sensitive identity, location, payment, and behavioral data.
For example, Honor previously demonstrated an AI ordering food during a launch event—silently capturing and recording user location, payment details, and preferences—greatly increasing the risk of personal data exposure.

As previously analyzed by Tencent Research Institute, in the mobile internet ecosystem, consumer-facing apps are generally considered data controllers, bearing responsibility for privacy and data security in services such as e-commerce, social networking, and transportation. However, when on-device AI agents perform tasks using app functionalities, the boundary of data security responsibilities between terminal manufacturers and app providers becomes blurred.
Manufacturers often justify broad data access as necessary for better service. But at scale, this is not a valid excuse. Apple Intelligence, for instance, explicitly states that user data is not stored in the cloud and employs multiple technical safeguards to prevent even Apple itself from accessing user data—thereby earning user trust.
Undoubtedly, today’s mainstream large models face urgent transparency challenges. From the difficulty of withdrawing data, opaque training corpora, to the complex privacy threats posed by agents and on-device AI—the foundation of user trust continues to erode.

As a key driver of digital transformation, enhancing transparency in large models is now imperative. It affects not only personal data security and privacy protection but is also a core determinant of whether the entire large model industry can develop healthily and sustainably.
Going forward, we hope large model providers proactively respond by optimizing product designs and privacy policies—adopting a more open and transparent stance, clearly explaining where user data comes from and how it is used, so users can confidently embrace AI technology. At the same time, regulators should accelerate the development of relevant laws and regulations, clearly defining data usage norms and responsibility boundaries—to foster an innovative, secure, and orderly environment where large models can truly become powerful tools benefiting humanity.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














