

OpenAI has just released the new o1 model, and we are officially entering the next era
TechFlow Selected TechFlow Selected
OpenAI has just released the new o1 model, and we are officially entering the next era
On our path to AGI, there are no obstacles left.
Author: Kazek
At midnight, OpenAI finally unveiled its mysterious new model—one it had been teasing for nearly half a year.
Without any prior announcement, it officially arrived.
The official name isn't "Strawberry"—that was just an internal codename. Its real name is:

Here’s why OpenAI named it o1:
For complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
In translation:
For complex reasoning tasks, this is a major breakthrough representing a new level of AI capability. Therefore, we are resetting the version counter to 1 and naming this series OpenAI o1.
This model is so powerful that OpenAI has abandoned the legacy GPT naming convention entirely, launching a new “o” series instead.
It’s explosive—truly groundbreaking.
I’m getting chills right now. The release of OpenAI o1 marks a definitive turning point: the AI industry has officially entered a brand-new era.
"On our path to AGI, there are no more obstacles."
Let me first show you some numbers on logic and reasoning ability—you’ll immediately understand how absurdly advanced this thing is.
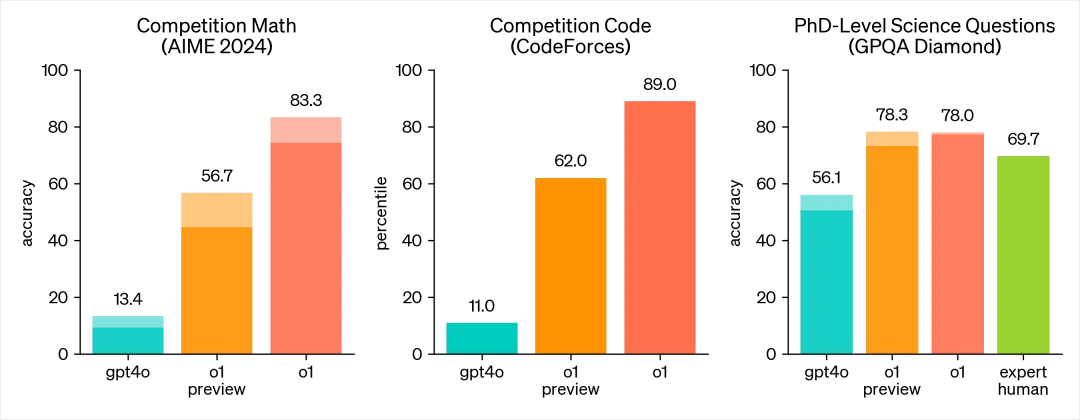
AIME 2024, a high-level math competition: GPT-4o scored 13.4%, the o1 preview version reached 56.7%, and the unreleased o1 full version achieved 83.3%.
In coding competitions: GPT-4o scored 11.0%, o1 preview hit 62%, and o1 full version reached 89%.
And in PhD-level scientific questions (GPQA Diamond): GPT-4o scored 56.1, human experts averaged 69.7, while o1 achieved a staggering 78%.
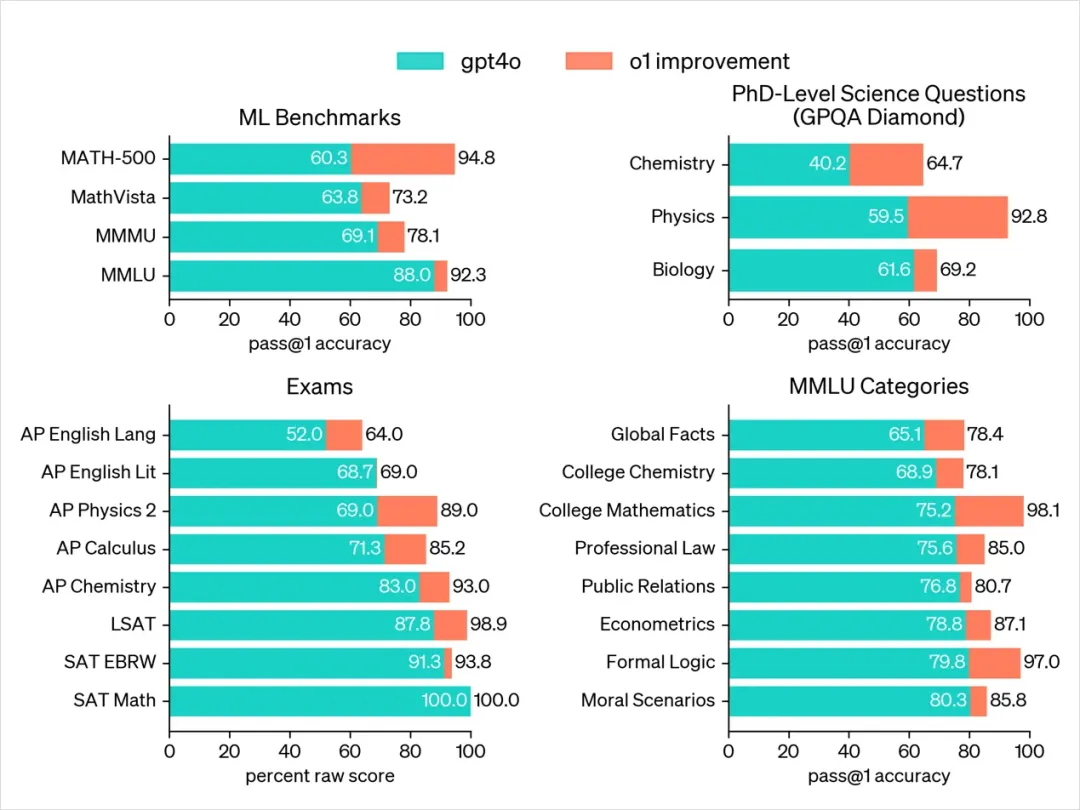
I asked Claude to translate the o1 chart—ugly as it is, but readable enough to grasp each data point.

This is what total domination looks like.
Especially on GPQA-Diamond, a benchmark testing expertise in chemistry, physics, and biology, o1 has surpassed human PhD experts across the board—the first model in history to achieve this.
The foundation behind this leap? Self-play RL. If you're unfamiliar, check my previous prediction article: What Exactly Is the "Strawberry" Model?
Through self-play RL, o1 learned to refine its chain of thought and improve its strategies. It learned to identify and correct its own errors.
It learned to break down complex steps into simpler ones.
And when one approach fails, it learns to try different methods.
These capabilities mirror the most fundamental aspect of human cognition: slow thinking.
Daniel Kahneman, Nobel laureate in economics, wrote a book titled *Thinking, Fast and Slow*, which thoroughly explains two modes of human thought.
The first is fast thinking (System 1)—quick, automatic, intuitive, unconscious. Examples include:
-
Recognizing someone's mood from their smile.
-
Solving simple calculations like 1+1=2.
-
Instinctively slamming the brakes when driving and encountering danger.
This is fast thinking—the kind of rapid response traditional large models master through memorization.
The second is slow thinking (System 2)—slower, effortful, logical, conscious. Examples include:
-
Solving a complex math problem.
-
Filling out tax forms.
-
Making important decisions after weighing pros and cons.
This is slow thinking—the core of human intelligence, and the essential foundation for AI to advance toward AGI.
Now, o1 has taken a solid step forward by acquiring traits of human slow thinking. Before answering, it repeatedly thinks, decomposes, understands, and reasons, then delivers the final answer.
To be honest, these enhanced reasoning abilities are extremely valuable for tackling complex problems in science, coding, mathematics, and similar domains.
For example, o1 could help medical researchers annotate cell sequencing data, assist physicists in generating complex mathematical formulas for quantum optics, or enable developers across fields to build and execute multi-step workflows, among countless other applications.
o1 is also a next-generation data flywheel: when answers are correct, the entire reasoning chain becomes a small dataset with positive and negative reward signals for training.
Given OpenAI's user scale, its future evolution speed will only become more terrifying.
Writing this, I sighed deeply. Compared to o1 a year from now, I might just be completely useless...
Currently, the o1 model is gradually rolling out to all ChatGPT Plus and Team users, with plans to consider opening access to free users in the future.
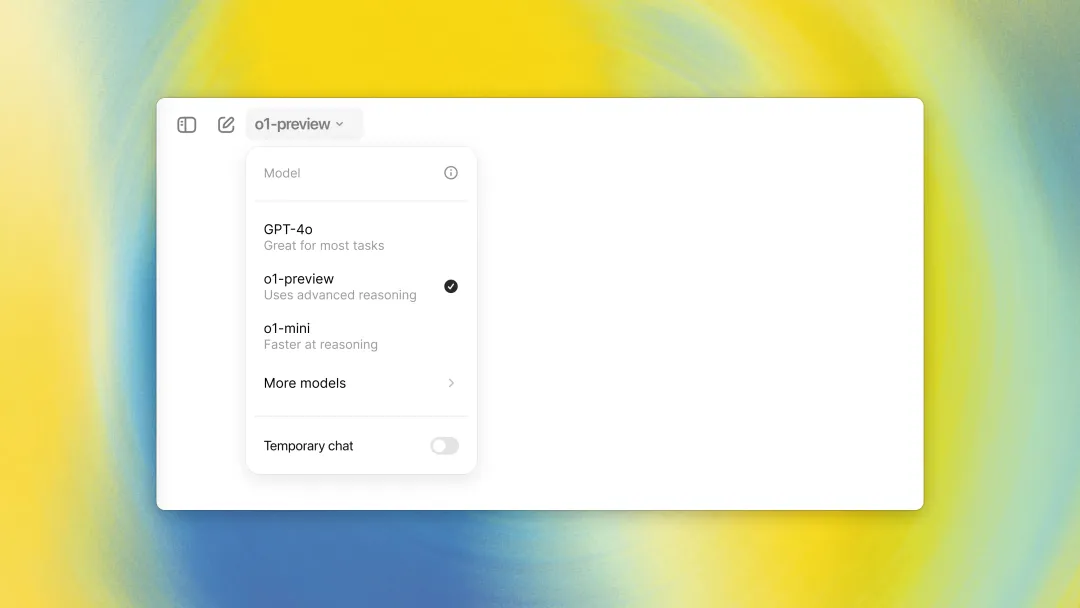
Two versions are available: o1-preview and o1-mini. The o1-mini is faster, smaller, cheaper, and strong at reasoning—especially suitable for math and code—but weaker in general world knowledge, ideal for reasoning-heavy tasks without requiring broad knowledge.
o1-preview allows 30 messages per week; o1-mini allows 50 per week.
Limited not by hourly caps like before, but weekly quotas—this alone shows just how expensive the o1 model must be.
For developers, access is currently restricted to Level 5 developers who have spent over $1,000, with a rate limit of 20 requests per minute.
Both limits are quite tight.
There's also significant feature limitation, but understandable given it's early stage.

In terms of API pricing: o1-preview costs $15 per million input tokens and $60 per million output tokens—this inference cost...

o1-mini is cheaper: $3 per million input tokens and $12 per million output tokens.

Output cost is consistently four times that of input—a stark contrast to GPT-4o, which is priced at $5 and $15 respectively.

o1-mini offers some economic viability, but we’re still in the beginning. Expect OpenAI to slash prices later.
Since o1 is already available to Plus users, I checked my account—and yes, I got access.
Naturally, I tested it immediately.
Currently, it doesn’t support many previous features—no image understanding, image generation, code interpreter, web search, etc. Just a bare conversational model.
First, I asked a classic tricky question:
"A farmer needs to bring a wolf, a goat, and a cabbage across a river. He can only carry one item at a time. The wolf cannot be left alone with the goat, nor the goat with the cabbage. How should the farmer proceed?"

After 6 seconds of thinking, it delivered a perfect solution.
Then, the infamous Chinese holiday schedule puzzle that once tripped up every large model:
"From Monday, September 9, 2024, to October 13, here's the Chinese holiday work-rest adjustment schedule: Work 6 days, rest 3; work 3, rest 2; work 5, rest 1; work 2, rest 7; work 5, rest 1.
Tell me, excluding regular weekends, how many extra days off did I get due to holidays?"
After a full 30 seconds of deliberation, o1 gave a perfectly accurate answer—down to the day.
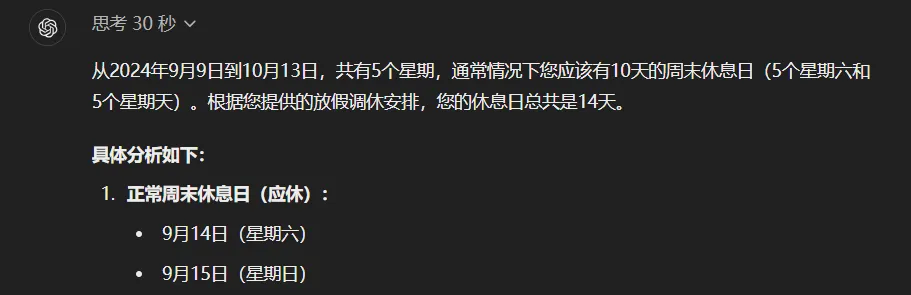

Unbeatable. Truly unbeatable.
Now, a harder one—the Olympiad math problem from Jiang Ping’s contest:

Don’t ask me what the problem means—I don’t understand it. I’m useless. This question once destroyed every large model. Now, let’s see how o1 handles it.

After over a minute of deep thinking, it produced an answer.
...
C...completely...correct...
I'm shattered.
From my own testing, I feel prompt engineering may need to be rethought. In the era of fast-thinking models like GPT, techniques such as "think step by step" were common—but now they’re ineffective, even counterproductive for o1.
OpenAI recommends the following best practices:
-
Keep prompts simple and direct: The model excels at understanding short, clear instructions without excessive guidance.
-
Avoid chain-of-thought prompting: Since these models perform internal reasoning, there's no need to instruct them to "think step by step" or "explain your reasoning."
-
Use delimiters for clarity: Use triple quotes, XML tags, or section headers to clearly separate different parts of input, helping the model interpret each segment correctly.
-
Limit additional context in retrieval-augmented generation (RAG): When providing supplementary context or documents, include only the most relevant information to prevent overcomplicating the model’s response.
Finally, let’s talk about thinking duration.
Right now, o1 thinks for a minute. But if this were true AGI, honestly—the slower it thinks, the more powerful it could be.
Imagine it taking hours, days, or even weeks to think through proving mathematical theorems, developing cancer drugs, or conducting astrophysical research?
The final outcomes could be unimaginably astonishing.
No one today can envision what AI would become at that point.
And in my view, o1’s future is absolutely not limited to being just another ChatGPT.
It is the greatest cornerstone leading us into the next era.
"On our path to AGI, there are no more obstacles."
Now, I believe this statement without hesitation.
A brilliant next era,
is here,
today.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














