

Ethereum Upgrade: Fundamentals of Consensus (Part 2)
TechFlow Selected TechFlow Selected
Ethereum Upgrade: Fundamentals of Consensus (Part 2)
This is an authoritative technical book on the Ethereum Proof-of-Stake protocol. It starts with some preliminary content, covering consensus fundamentals that are not limited to Ethereum.
Author: Ben Edgington
Translation: tiao
This article is the second half of the chapter "Fundamentals of Consensus." See the first part here: Upgrading Ethereum: Fundamentals of Consensus.
Fork Choice Rule
As we have seen, for various reasons—network latency, network outages, incorrect message ordering, or malicious peer behavior—nodes on the network may end up with different views of the network state. Ultimately, we want every honest node on the network to converge on a single, linear view of history and thus form a shared understanding of the system state. The protocol's fork choice rule exists precisely to achieve this convergence.
Given a block tree and some decision criteria based on a node’s local view of the network, the purpose of a fork choice rule is to select from all available branches the one most likely to become the final, canonical, linear chain. That is, when a node attempts to align with the canonical view, it selects the branch least likely to be pruned from the block tree.

A fork choice rule implicitly selects a branch by selecting a block at the tip of that branch, known as the head block.
For any honest node, the first requirement of any fork choice rule is that the selected block must be valid—compliant with the protocol rules—and all its ancestors must also be valid. Any invalid block is ignored, and any block built atop an invalid block is itself invalid.
With that in mind, there are many examples of fork choice rules.
-
The Proof-of-Work protocols in Ethereum and Bitcoin use the "heaviest chain rule" [4] (sometimes called "longest chain," though this is not entirely accurate). The head block is the tip of the chain that has accumulated the most "work" under Proof-of-Work.
-
In Ethereum's Proof-of-Stake Casper FFG protocol, the fork choice rule is "follow the chain containing the highest justified checkpoint," and it never reverts a finalized block.
-
In Ethereum's Proof-of-Stake LMD GHOST protocol, the fork choice rule is evident in its name: adopt the "Latest Message-driven Greatest Originating Subtree." It involves calculating the cumulative votes of validators for a block and its descendants. It also follows the same rules as Casper FFG.
We will explain the second and third examples in detail in their respective sections.
You might already notice that these fork choice rules are all methods of assigning numerical scores to blocks. The winning block—the head block—has the highest score. The idea is that when all honest nodes eventually see a particular block, they will unambiguously agree it is the head block and choose to follow its branch, regardless of their other views of the network. Thus, all honest nodes will ultimately converge on a shared view of a single canonical chain tracing back to genesis.
Reorgs and Reversions
When a node receives new blocks (and, in Proof-of-Stake, new votes on blocks), it re-evaluates the fork choice rule based on the new information. Most commonly, the new block will be a child of the block currently considered the head block and will become the new head.
However, sometimes the new block might be a descendant of some other block in the block tree. (Note that if the node does not yet have the parent of the new block, it needs to request it from its peers, just as it would for any other missing block.)
In any case, running the fork choice rule on the updated block tree might point to a head block on a different branch than the previous one. When this happens, the node must perform a reorganization (reorg, short for reorganisation), also known as a reversion. It will eject (roll back) previously included blocks from its chain and adopt blocks from the new head block's branch.
In the following diagram, a node evaluates block F as the head block, so its chain consists of blocks A, B, D, E, F. The node knows about block C, but it is not in the node's chain view; block C lies on a side branch.
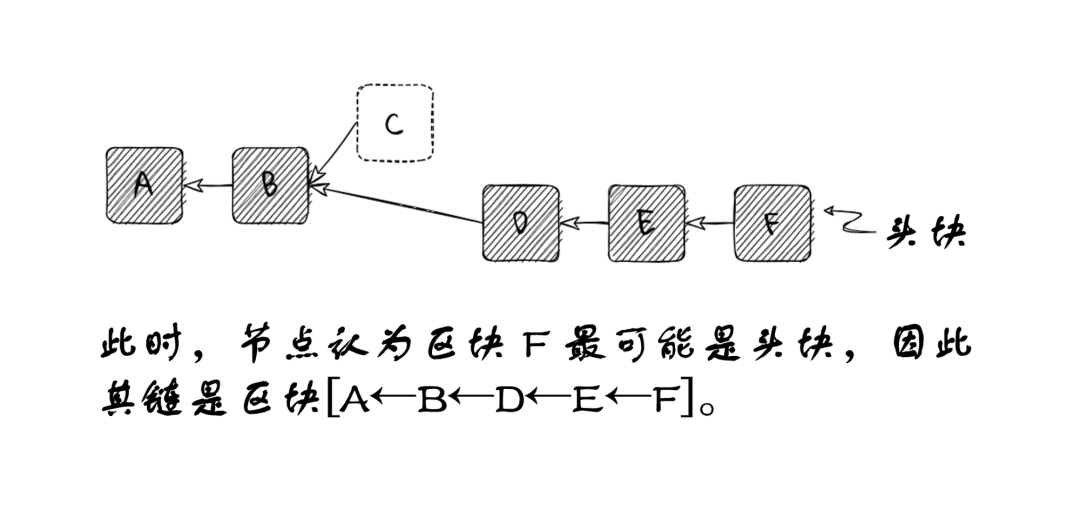
Some time later, the node receives block G, which is not built on its current head block F, but rather on the branch of block C. Depending on the specifics of the fork choice rule, the node might still consider F a better head than G and thus ignore G. But in this scenario, we assume the fork choice rule indicates G is now the better head.
Blocks D, E, and F are not ancestors of block G, so they must be removed from the node’s canonical chain. Any transactions or data in these blocks are rolled back as if they were never received. The node must fully revert its state to after processing block B.
After reverting to block B, the node can add blocks C and G to its chain and process them accordingly. Once done, the node has completed the reorganization of its chain.

Later, a block H built on block F might appear. If the fork choice rule indicates the new head should be H, then the node will reorganize again, rolling back to block B and rebuilding the chain along branch H.
In both Proof-of-Work and Ethereum's Proof-of-Stake protocols, short reorganizations of one or two blocks due to network latency in block propagation are not uncommon. Unless the chain is under attack, or there is a flaw in the design or implementation of the fork choice rule, very long reorganizations should be extremely rare.
Safety and Liveness
Two important concepts frequently arise when discussing consensus mechanisms: safety and liveness.
Safety
Informally, an algorithm is considered safe if "nothing bad happens" [5].
Examples of bad things that could happen in a blockchain context include double-spending of cryptocurrency or the finalization of two conflicting checkpoints.
An important aspect of safety in distributed systems is "consistency." That is, if we ask different (honest) nodes about the state of the chain at a certain point—for example, the balance of an account at a specific block height—we should always get the same answer, no matter which node we query. In a safe system, every node has an identical and immutable view of the chain's history.
In practice, safety means our distributed system "behaves like a centralized instance, executing one atomic operation at a time." (Quoting Castro and Liskov.) In Vitalik’s centralization taxonomy, a safe system is logically centralized.
Liveness
Again informally, an algorithm is said to have liveness if "something good eventually happens."
In the blockchain context, we usually interpret this to mean the chain can always add a new block; it will never reach a deadlock where no new transaction-containing block can be produced.
"Availability" is another way to frame this. I want the chain to be available, meaning that if I send a valid transaction to an honest node, it will eventually be included in a block that extends the chain.
You cannot have both!
The CAP theorem is a famous result in distributed systems theory, stating that no distributed system can simultaneously provide (1) consistency, (2) availability, and (3) partition tolerance. Partition tolerance refers to the ability to continue operating even when communication between nodes is unreliable. For example, a network failure might split nodes into two or more groups that cannot communicate with each other.
It's easy to illustrate the CAP theorem in the context of blockchains. Suppose Amazon Web Services (AWS) goes down, allowing all AWS-hosted nodes to communicate among themselves but none to communicate with the outside world; or a country blocks all incoming and outgoing connections, preventing any gossip traffic from passing through. Both scenarios split the nodes into two disjoint groups, say A and B.
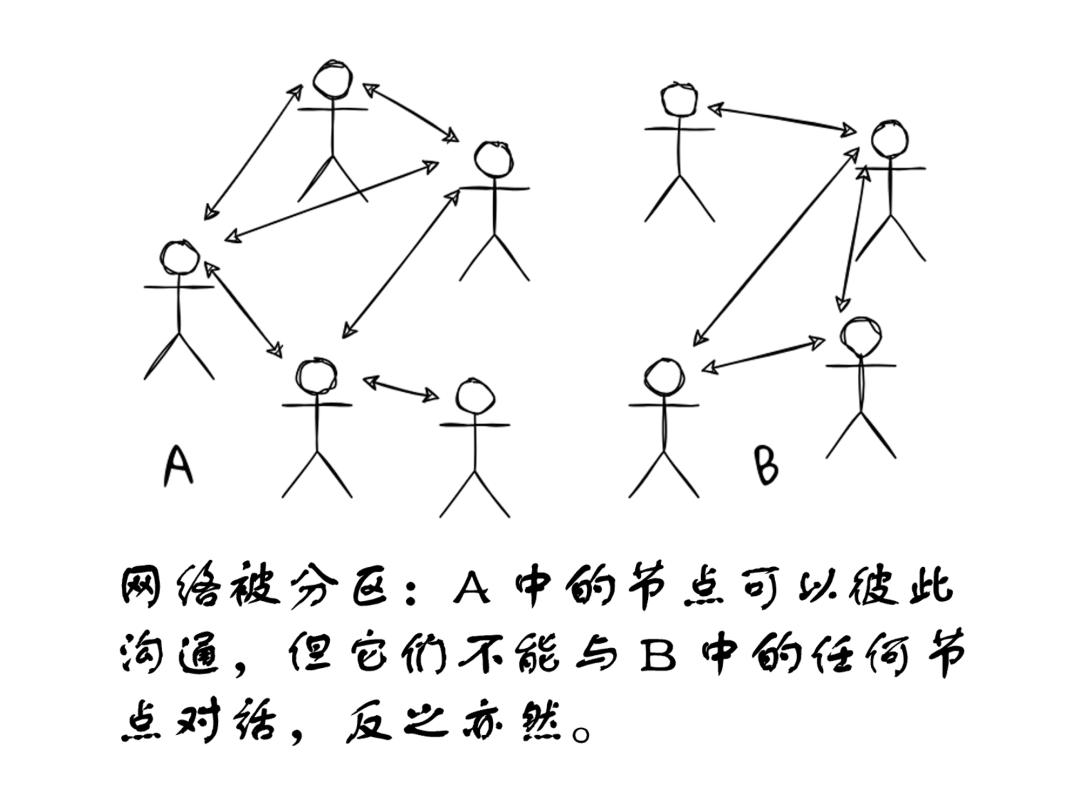
Suppose an account connected to group A sends a transaction. If nodes in group A process the transaction, their eventual state will differ from nodes in group B, who did not see the transaction. Thus, overall, we lose consistency across all nodes, and therefore lose safety. The only way to avoid this is for nodes in group A to refuse to process transactions—in which case we lose availability and liveness.
In short, the CAP theorem implies we cannot expect to design a consensus protocol that is both safe and live under all circumstances, because we have no choice but to run on an unreliable network—the internet [6].
Ethereum prioritizes liveness
Under good network conditions, Ethereum's consensus protocol provides both safety and liveness, but when network conditions deteriorate, it prioritizes liveness. During a network partition, nodes on both sides will continue producing blocks. However, finality—a property of safety—will no longer occur simultaneously on both sides. Depending on the proportion of staked value managed on each side, either one side continues to finalize or neither side does.
Eventually, unless the partition is resolved, both sides will regain finality due to the novel inactivity leak mechanism. But this too leads to a safety failure: each chain will finalize a different history, and the two chains will become irreconcilably and permanently separate.
Finality
We will discuss finality extensively in upcoming sections, as it is a property of chain safety.
Finality means certain blocks will never be reverted. When a block is finalized, all honest nodes on the network agree it will remain forever in the chain's history, and so will all its ancestors. Finality makes your pizza payment irreversible, just like cash. It is the ultimate protection against double-spending [7].
Some consensus protocols, such as classical PBFT or Tendermint, finalize every round (each block). Once a round of transactions is included on-chain, all nodes agree it will remain forever. On one hand, these protocols are very "safe": once a transaction is included, it will never be reverted. On the other hand, they are prone to liveness failures: if nodes cannot reach agreement—for example, if more than one-third of nodes go offline or become unreachable—then no new transactions can be added, and the chain halts.
Other consensus protocols, like Bitcoin’s Nakamoto Consensus, have no finality mechanism at all. There is always a possibility someone presents a heavier alternative chain. When this happens, all honest nodes must reorganize their chains accordingly, rolling back any previously processed transactions. Heuristics like "how many confirmations does your block have" are merely approximations of finality, with no guarantee [8].
Ethereum’s consensus layer prioritizes liveness but also strives to provide safety guarantees via finality when conditions allow. This is an attempt to have the best of both worlds. Vitalik defends this approach [9]:
The general principle is that you want to give users “as much consensus as possible”: if >2/3 of participating nodes agree, then we get normal consensus. But if <2/3 agree, we don’t need to stop and do nothing; clearly, the chain can keep growing, albeit with temporarily reduced security for new blocks. If individual applications are unhappy with the lower security level, they are free to ignore those blocks until they are finalized.
In Ethereum’s consensus layer, finality is provided by the Casper FFG mechanism, which we will explore shortly. The idea is that all honest validators regularly agree on recent checkpoint blocks and will never revert them. Then, those blocks and all their ancestors are “finalized”—they will never change, and if you ask any honest node in the network about them or their ancestors, you will always get the same answer.
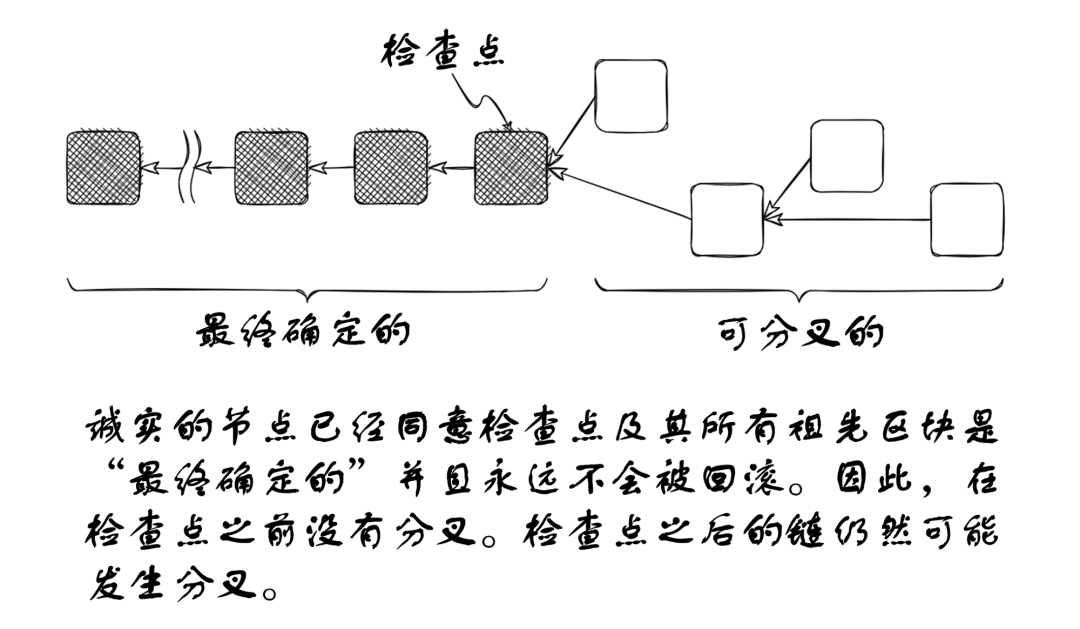
Ethereum’s finality is “economic finality.” In theory, the protocol could finalize two conflicting checkpoints—two contradictory views of chain history. However, this could only occur at enormous and quantifiable cost. Except in extreme attack or failure scenarios, finality really is finality.
The Casper FFG section will dive deeper into how this finality mechanism works.
See Also
Anything involving Leslie Lamport is always worth reading. His 1982 original paper with Shostak and Pease, “The Byzantine Generals Problem,” contains many insights. While their proposed algorithm is highly inefficient by today’s standards, the paper serves as an excellent introduction to reasoning about general consensus protocols. The same goes for Castro and Liskov’s groundbreaking 1999 paper, “Practical Byzantine Fault Tolerance,” which significantly influenced the design of Ethereum’s Casper FFG protocol. However, you might contrast these “classic” approaches with the elegant simplicity of Proof-of-Work described by Nakamoto in the 2008 Bitcoin whitepaper. If Proof-of-Work has one virtue, it is its simplicity.
Earlier, we mentioned Gilbert and Lynch’s 2012 paper, “Perspectives on the CAP Theorem.” This paper offers deep and readable insights into the concepts of consistency and availability (or, in our context, safety and liveness).
Due to differences in client implementations of the fork choice rule, the Ethereum Beacon Chain experienced a seven-block reorg in May 2022. These differences were known at the time and considered harmless—but proved otherwise. Barnabé Monnot’s account of this incident is highly illuminating.
Vitalik’s blog post “On Settlement Finality” offers a deeper and more nuanced exploration of the concept of finality.
For the systems we aim to build, our ideal is that they are politically decentralized (to enable permissionless and censorship-resistant participation), architecturally decentralized (to achieve resilience without single points of failure), but logically centralized (to ensure consistent outcomes). These criteria strongly influence how we design consensus protocols. Vitalik explores these ideas in “The Meaning of Decentralization.”
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














