

NEAR Co-Founder Illia: Why AI Needs Web3?
TechFlow Selected TechFlow Selected
NEAR Co-Founder Illia: Why AI Needs Web3?
We stand at a crossroads, with one path leading to a closed AI world that will result in greater manipulation.

Recently, NEAR co-founder Illia attended the "2024 Hong Kong Web3 Festival" and delivered a keynote speech on AI and Web3. Below is an edited summary of his talk, slightly abridged.
Hello everyone, I’m Illia, co-founder of NEAR. Today we’ll discuss why AI needs Web3. NEAR actually originated from AI. Before starting our entrepreneurial journey, I worked at Google Research focusing on natural language understanding and was one of the main contributors to Google’s deep learning framework, TensorFlow. Together with a team of colleagues, we created the first "Transformers" model, which has driven major innovations in AI that we see today — this is where the “T” in GPT comes from.
Later, I left Google to found NEAR. As an AI startup, we were teaching machines how to code. One of our approaches involved extensive data labeling, using students from around the world to generate training data. We faced challenges paying them, especially since some didn’t even have bank accounts. We began exploring blockchain as a solution and realized no existing platform met our needs: scalability, low fees, ease of use, and accessibility. That’s when we built the NEAR protocol.

For those unfamiliar, language models aren’t new — they’ve existed since the 1950s. General statistical models allowed for language modeling and application across various domains. To me, the truly exciting innovation came in 2013 with the introduction of word embeddings, a concept that allows symbols like “New York” to be transformed into multidimensional vectors — mathematical representations. These work exceptionally well with deep learning models, which are essentially large-scale matrix multiplications and activation functions.
I joined Google after 2013. In early 2014, the dominant research model was the RNN (Recurrent Neural Network). It mimics how humans read — one word at a time — but this creates a significant bottleneck. If you want to process multiple documents to answer a question, there's substantial latency, making it impractical for production use at Google.
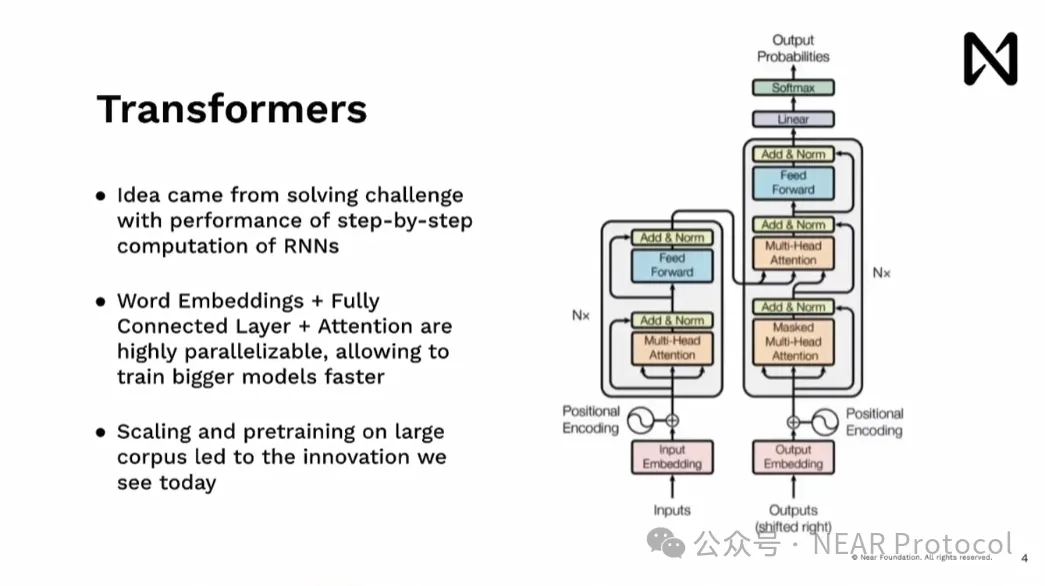
The Transformer emerged from our efforts to overcome RNN limitations. We leveraged parallel computation capabilities inherent in hardware — especially GPUs — allowing us to ingest entire documents simultaneously and understand them without step-by-step processing. This eliminated bottlenecks and enabled the OpenAI team to scale up the model, pre-training it on massive corpora, leading to breakthroughs like ChatGPT, Gemini, and others we see today.
We’re now witnessing rapid acceleration in AI innovation. These models possess basic reasoning and common sense. People continue pushing their boundaries. Crucially, in traditional machine learning and data science, human experts interpret results. Now, large language models can communicate directly with users and interact seamlessly with other applications and tools. We now have technical means to bypass intermediaries in interpreting outcomes.
For clarity, when we say these models are trained or used on GPUs, these aren’t gaming or crypto-mining GPUs. They are specialized supercomputers — typically housing eight powerful GPUs per machine, packed into racks deployed in data centers. Training a large model like Groq may take three months using 10,000 H100 chips. Renting such equipment could cost $64 million. More importantly, beyond raw compute power, connectivity is critical.
A key component here is the A100, especially the H100, connected at speeds of 900 gigabytes per second. For reference, your CPU connects to RAM at about 9 GB/s. Moving data between two nodes or GPUs within a data center rack is actually faster than moving data from GPU to CPU. And we’re still improving — Blackwell aims to double that speed to 1,800 GB/s. This insane hardware connectivity allows us to stop viewing these devices as isolated units. From a programmer’s perspective, they feel like a single unified system. When building systems at scale, this makes a huge difference. These highly interconnected devices operate over local networks where typical connections run at 100 megabytes per second — roughly ten thousand times slower.
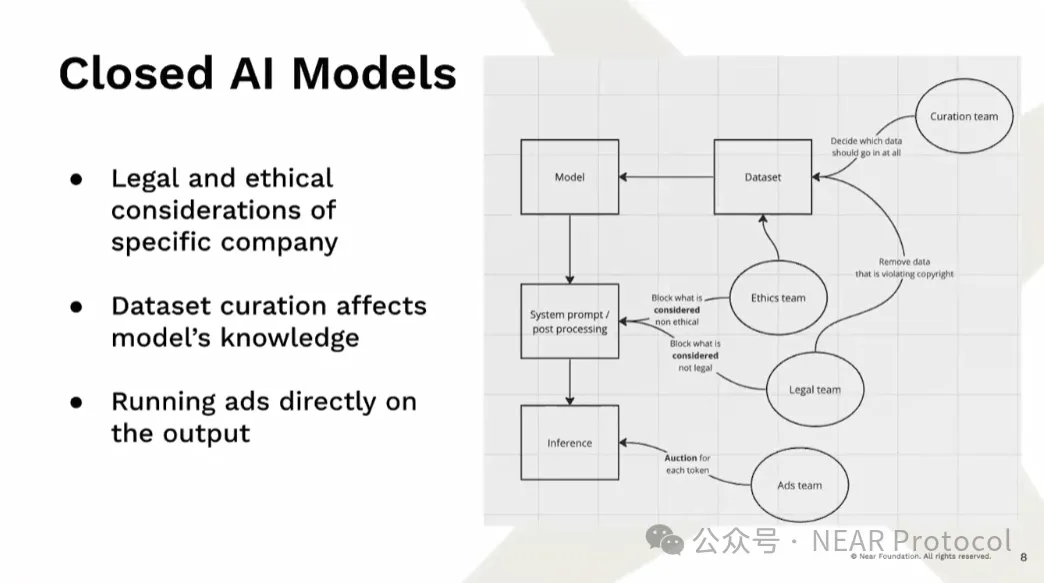
Due to these immense training requirements, we’re seeing the rise of closed AI models. Even when model weights are open-sourced, we often don’t know exactly what went into the model. This matters because models learn biases from data. Some joke that models are just “weights and biases” — and that’s essentially how they behave. Beyond engineers, many teams influence model content by curating datasets — deliberately excluding certain information. After training, post-processing and system prompts further shape what the model reasons about. Most dangerously, we often don’t know how a given model was actually produced.
We’re also seeing widespread protests and lawsuits against AI. Controversies arise around data usage, how models generate outputs, and corporate control over distribution platforms. The models themselves become gatekeepers, creating enormous risks. Regulators are stepping in, attempting to restrict bad actors — but this often makes it harder for open models and decentralized approaches to survive. Open source lacks sufficient economic incentives, so companies may initially release models openly but later restrict access once they need revenue to buy more compute and train larger models.
Generative AI is becoming a tool for mass manipulation. Corporate economics inevitably distort incentives. Once market share goals are met, companies must keep showing revenue growth — increasing average revenue per user, extracting more value from each individual. This undermines the ethos of open-source AI. Using Web3 as a tool to incentivize participation can create opportunities and pool enough computational and data resources to build competitive models.

To integrate AI meaningfully into the Web3 ecosystem, we need a wide range of AI tools working together. I’ll outline key components across data, infrastructure, and applications. One crucial aspect is that language models can now interact directly with society — enabling broad-scale manipulation and misinformation. Let me clarify: AI itself isn’t the problem; such issues have existed before. What matters is using cryptography and on-chain reputation to address them. It doesn’t matter whether content is generated by AI or humans — what counts is who published it, its origin, and community consensus. That’s what’s truly important.
On another front, we now have agents. We tend to call everything an agent, but in reality, there’s great diversity — including tool-based or autonomous agents, centralized or decentralized ones. For example, ChatGPT is a centralized tool, while Llama is open-source. So models can be used either centrally or decentrally. Decentralized models can even run entirely on users’ own devices without needing blockchain at all. Running a model locally ensures it behaves exactly as intended. Fully autonomous, decentralized AI governance requires verification — especially when allocating funds or making critical decisions.

There are also different types of specialization. Take prompting: you can do zero-shot learning, teaching Llama to respond in specific ways. You can fine-tune on particular datasets to inject additional knowledge. Or use retrieval augmentation to provide contextual background during user queries. Outputs don’t have to be text-only — they can include rich UI components or direct actions on blockchains.
Then there’s autonomy. An agent can act as a simple tool executing tasks; it can plan and execute independently; perform continuous work based only on a goal; optimize via reinforcement learning based on defined metrics and constraints; or continuously explore and discover new paths to growth.

Finally, infrastructure. You can rely on centralized providers like OpenAI or Groq. Alternatively, use distributed local models or probabilistic decentralized inference. A fascinating use case involves shifting from programmable money to smart assets — assets whose behavior is defined in natural language and capable of interacting with the real world or other users. For instance, a natural language oracle that reads news could automatically adjust investment strategies based on current events. The biggest caveat? Current language models are not robust against adversarial attacks — they can be easily manipulated.
We stand at a crossroads. On one path lies a closed AI world — one that enables greater manipulation. Regulatory decisions often push us down this road, demanding ever-increasing oversight, KYC, and compliance. Only large corporations can afford these burdens. Startups, especially those pursuing open-source, lack the resources to compete and will eventually fail or get acquired. We’re already seeing this unfold.
On the other path lie open models — built with a non-profit, open-source mindset, powered by crypto-economic incentives that generate opportunity and shared resources. This is essential for sustainable, competitive open-source AI. NEAR is actively building across this entire ecosystem. AI is NEAR. Stay tuned — we’ll have more updates in the coming weeks. Follow me on Twitter and NEAR’s social channels for the latest. Thank you!
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News












