Is the MUD Indexer a bad design?
TechFlow Selected TechFlow Selected
Is the MUD Indexer a bad design?
The Indexer in the MUD engine is the least bad design. This article elaborates on this conclusion and attempts to explore potentially better alternatives.
Authors: ck, MetaCat
Preface
This title isn't meant to sensationalize, but rather reflects our genuine thoughts after recently working with the MUD framework (a more accurate term than "engine"). Our preliminary conclusion is: MUD Indexer is the least bad design available. This article will explain this judgment in detail and attempt a preliminary exploration of potentially better alternatives—though we haven't yet found a satisfying answer. These reflections are shared simply to invite further discussion.

Source: https://mud.dev/
Database-Centric Design
As mentioned in "Chain-Native 2048: What We Learned from Using the MUD Engine", MUD's architecture follows a "database-centric" philosophy. Within the MUD framework, the core narrative revolves around reading and writing on-chain data: data "writes" are handled by Store, while data "reads" are primarily managed by the Indexer. The word "primarily" is used because on-chain data reading is still performed via Store, whereas off-chain (or client-side) data reading is delegated to the Indexer.
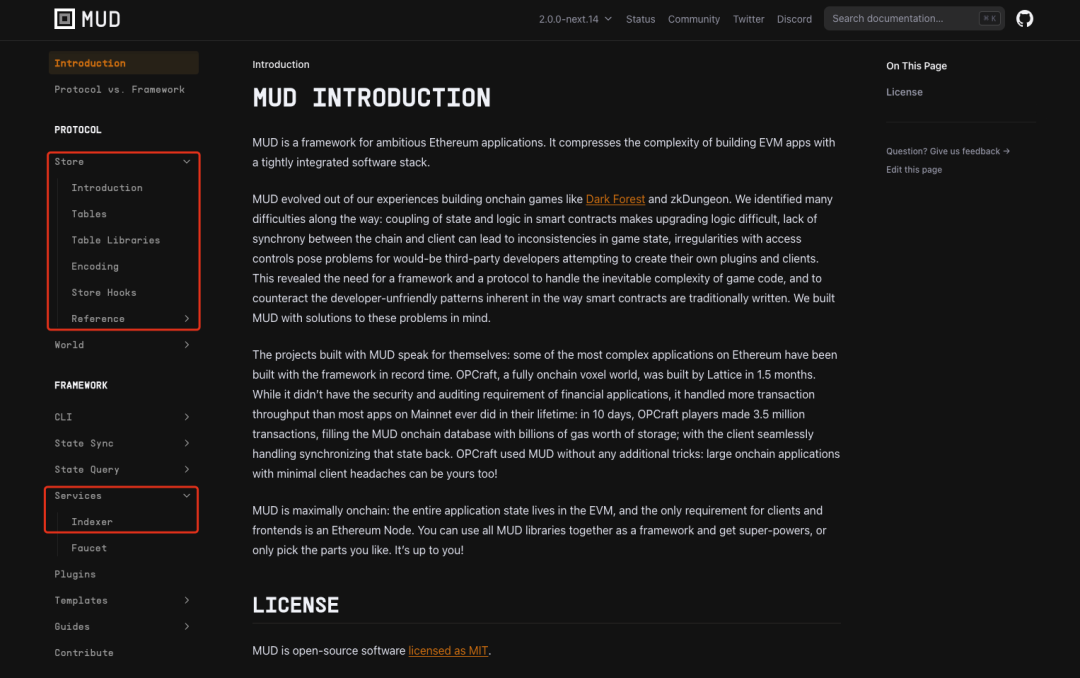
Source: https://mud.dev/introduction
User Wait Time
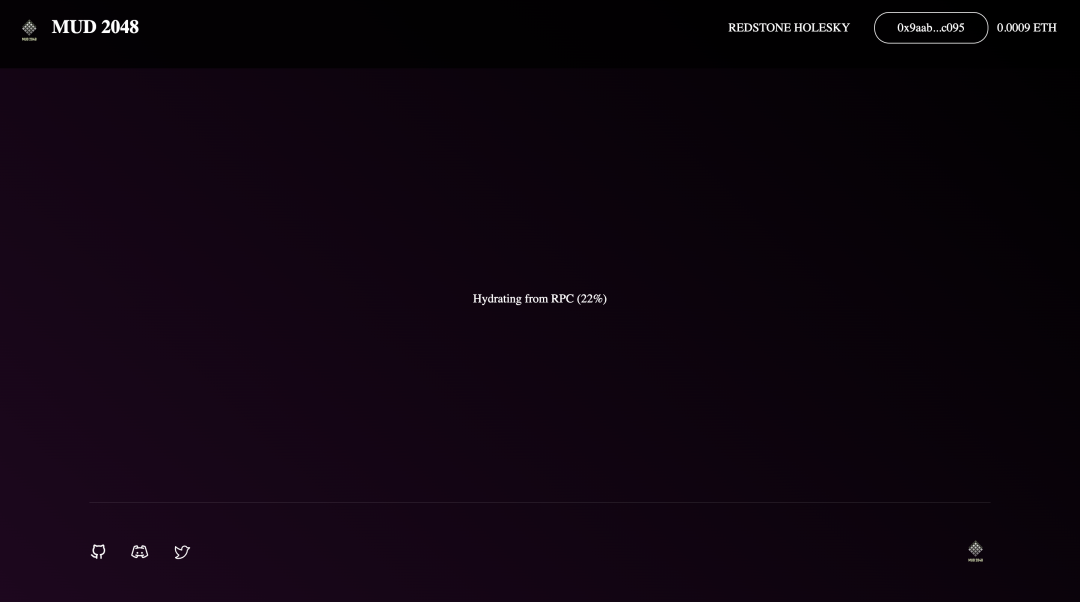
The Indexer is essentially a client-side replica of on-chain data (stored in a format resembling a relational database). In browser-based DApp scenarios, this means that every page refresh requires rebuilding the local data copy. Because data is stored in a blockchain structure, the time required to reconstruct this copy increases over time—leading directly to longer user wait times and degraded user experience.
Source: https://www.mud2048.fun/
Take mud2048.fun as an example: currently it takes about 10–20 seconds to load the main game page—an experience that’s maddeningly slow. This latency serves as our starting point for analyzing the strengths and weaknesses of the MUD Indexer design, exploring possible improvements, and ultimately discussing how chain-native application frameworks should approach data read/write patterns.
In the context of anticipating a boom in Ethereum Layer 2 applications, this discussion carries significant practical importance—it may even be the foundational issue determining whether such an explosion can occur at all. Solving this problem would remove a key infrastructure barrier, leaving only the need for innovative application models to trigger widespread adoption.
MUD Store: A Better Approach to On-Chain Data Writing
Store offers a more compact method for writing data compared to native Solidity data packaging, resulting in lower storage costs. Additionally, mapping on-chain data storage into a well-established engineering paradigm—the relational database model—makes development significantly more accessible. Therefore, Store’s approach to data writing is superior to native Solidity methods. However, this advantage comes at a cost: it contributes to inefficiencies in data retrieval. As Tagore said: “The perfect blooms are not brought alone; they come accompanied by all things.”
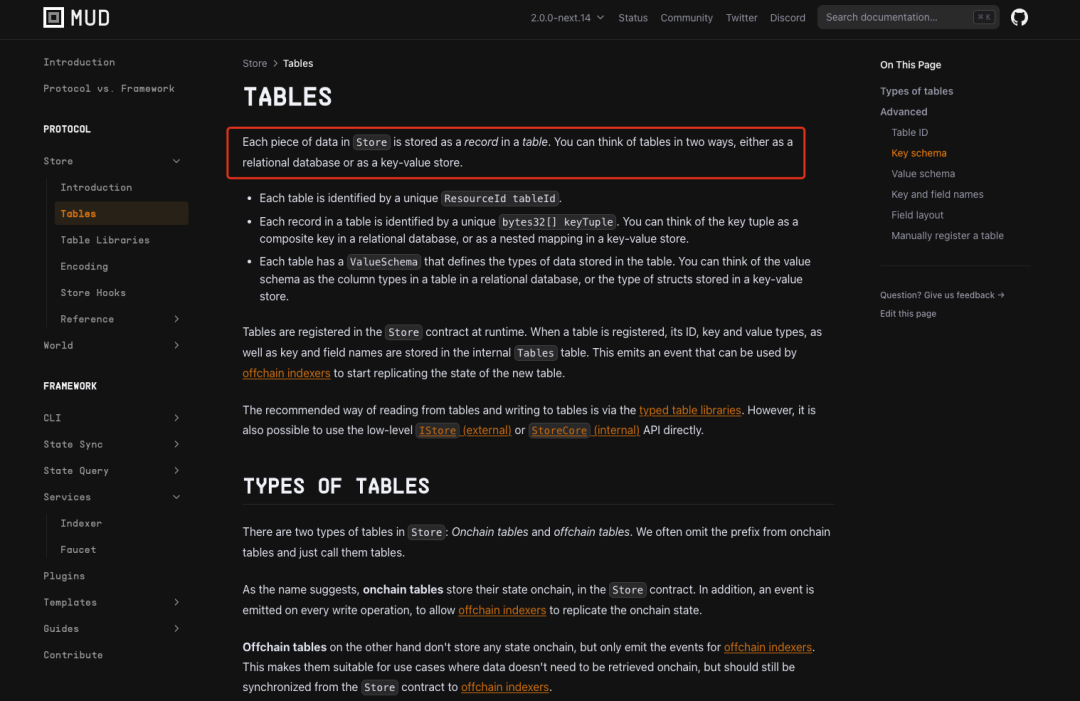
Source: https://mud.dev/store/tables
This method of writing data—or more precisely, storing data on-chain—leaves only two viable paths for data reading and querying:
Method One: Reading directly from the blockchain. The drawback is low efficiency and lack of support for complex queries.
Method Two: Copying on-chain data off-chain and performing complex queries there (the approach adopted by MUD). However, this introduces two problems:
1> Over time, the time required to synchronize and replicate data grows, progressively worsening user experience;
2> Performing global queries or computations (e.g., leaderboards) redundantly across each client replica leads to resource waste.
During the development of mud2048.fun, we briefly discussed the first issue with the MUD team and arrived at some temporary fixes—effective but not fundamental solutions. The red box in the image below highlights the built-in data replication process within the MUD framework.
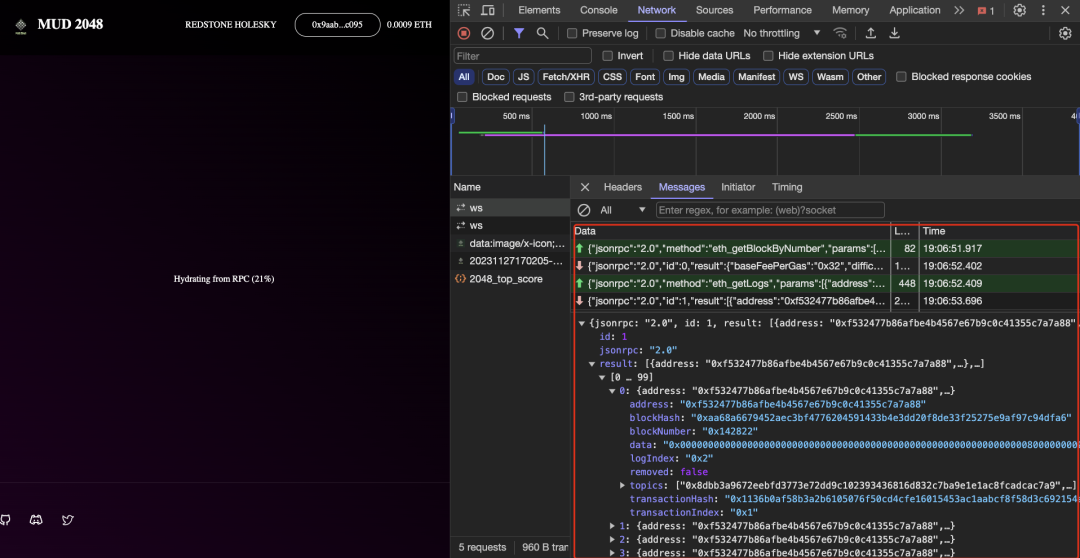
Source: https://www.mud2048.fun/
The Ultimate Question: How Can Fully On-Chain Applications Achieve Efficient Data Reads?
From the evolution of internet products, we know that in most applications, over 90% of operations involve data reads, with less than 10% involving writes. Therefore, an efficient data reading mechanism directly determines product usability.
In blockchain, a related concept is the "Data Availability Layer" (DA Layer). Although it addresses a different layer of the problem, it might still offer useful insights for solving our current challenge—so let’s borrow the idea.

Source: https://www.alchemy.com/overviews/data-availability-layer
Common DA approaches in blockchain fall into two broad categories: on-chain DA and off-chain DA. Bitcoin Ordinals represent on-chain DA (data stored on the Bitcoin blockchain, interpreted off-chain), while Ethereum Layer 2 solutions like ZK Rollups and OP Rollups use off-chain DA (data stored as CALLDATA on Ethereum L1). Both models are still competing, with no clear winner yet—but this gives us valuable contrasting examples when considering solutions to our current problem.
Why Web2 Solutions Don’t Translate Directly
In Web2, when database read performance becomes a bottleneck, we typically add a caching layer or scale reads using multiple read replicas.
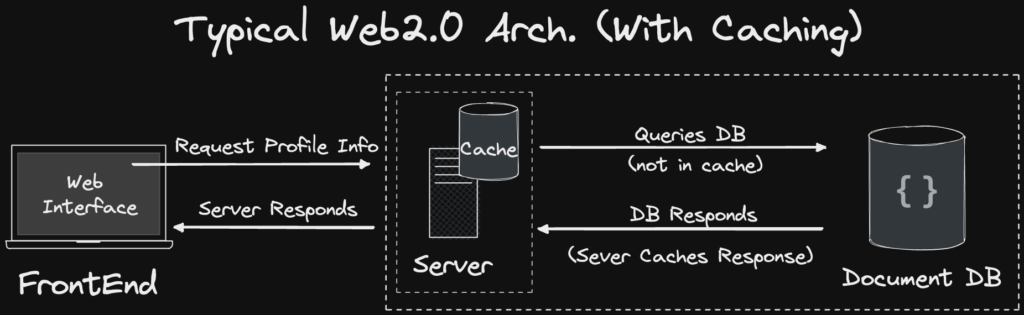
Typical Web2 service architecture. Source: https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
However, these approaches don't work well in the blockchain context. The service model has shifted from centralized to decentralized, and data storage has evolved from structured databases to blockchain-style chained storage. These foundational changes necessitate entirely new solutions—yet we have not yet developed blockchain-native equivalents to "caching" or "read replicas."
Some DApps have attempted to adopt Web2-style caching, but these cases lack generality. From the perspective of the MUD framework, introducing such a cache adds undesirable centralization, making it far from ideal.
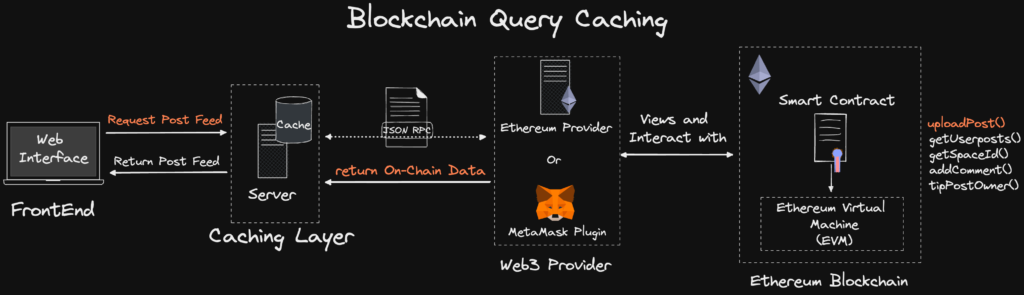
DApp architecture incorporating caching. Source: https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Indexer Is the Least Bad Option
For its domain, MUD represents a major leap forward in appchain development, having successfully addressed three critical issues:
1> Decoupling data from logic in smart contracts, which previously made upgrading logic extremely difficult;
2> Establishing a standardized synchronization mechanism between chain and client, resolving state inconsistency;
3> Introducing a unified access control system, reducing redundant effort and improving interoperability.
MUD’s solution to data reading involves placing a "full node" on the client side that only tracks data relevant to specific contracts. Officially called a "Namespaced Full-node," this is what we refer to as the Indexer.
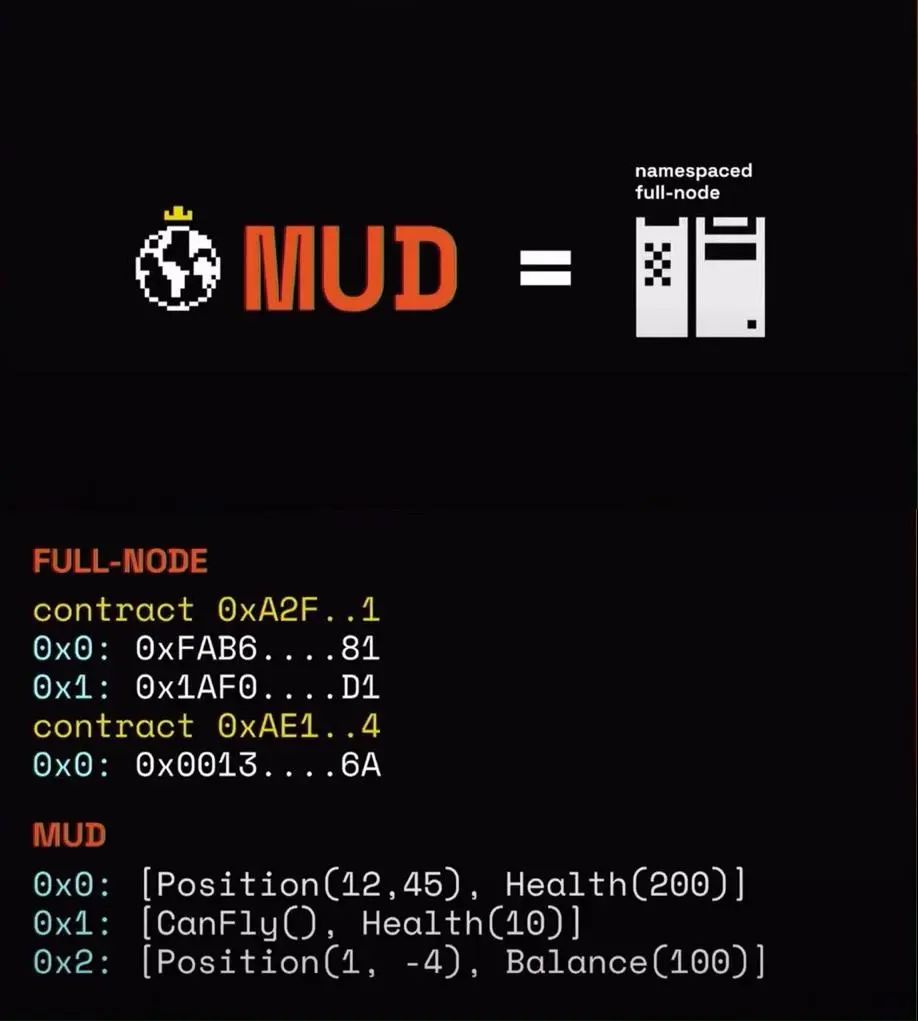
Source: https://youtu.be/tLGdup5wmck?si=ykgQ4qwut4VLgimF
Within the appchain space, this represents a breakthrough—from nothing to something functional. While far from perfect, it’s a solid foundation upon which future improvements can be built. Others can now stand on the shoulders of this giant to explore better designs. In summary, the MUD Indexer is the least bad option available today—but we still need something better.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News