

Sora 的算力數學題
TechFlow Selected深潮精選
Sora 的算力數學題
Sora 不僅代表了視頻生成質量和功能上的重大進步,也預示著在未來可能會大幅增加推理環節對 GPU 的需求。
撰文:Matthias Plappert
編譯:Siqi、Lavida、Tianyi
在上個月推出視頻生成模型 Sora 後,就在昨天,OpenAI 又發佈了一系列創意工作者藉助 Sora 進行的創作,效果極為驚豔。毫無疑問,就生成質量,Sora 是迄今為止最強的視頻生成模型,它的出現不僅會直接對創意行業帶來衝擊,也會影響對機器人、自動駕駛領域的一些關鍵問題的解決。
雖然 OpenAI 發佈了 Sora 的技術報告,但報告中關於技術細節的呈現極為有限,本文編譯自 Factorial Fund 的 Matthias Plappert 的研究,Matthias 曾在 OpenAI 任職並參與了 Codex 項目,在這篇研究中,Matthias 探討了 Sora 的關鍵技術細節、模型的創新點是什麼又會帶來哪些重要影響外,還分析了 Sora 這樣的視頻生成模型對算力的需求。Matthias 認為,隨著視頻生成的應用越來越廣泛依賴,推理環節的計算需求一定會迅速超過訓練環節,尤其對於 Sora 這樣的 diffusion-based 模型。
根據 Matthias 的估算,Sora 在訓練環節對算力需求就是 LLM 高出好幾個倍,大約需要在 4200-10500 張 Nvidia H100 上訓練 1 個月,並且,當模型生成 1530 萬到 3810 萬分鐘的視頻後,推理環節的計算成本將迅速超過訓練環節。作為對比,目前用戶每天上傳到 TikTok 的視頻為 1700 萬分鍾,YouTube 則為 4300 萬分鍾。OpenAI CTO Mira 在近期的一個訪談中也提到,視頻生成的成本問題也是 Sora 暫時還不能對公眾開放的原因,OpenAI 希望做到和 Dall·E 圖片生成接近的成本之後再考慮開放。
OpenAI 近期發佈的 Sora 憑藉極為逼真的視頻場景生成能力震驚了世界。在這篇文章中,我們將深入討論 Sora 背後的技術細節,這些視頻模型的潛在影響以及我們當下的一些思考。最後,我們還將分享我們關於訓一個 Sora 這樣的模型所需要的算力,並展示與推理相比,訓練計算的預測情況,這對於預估未來 GPU 需求具有重要的意義。
核心觀點
本篇報告中的核心結論如下:
-
Sora 是一個 diffusion model,它是基於 DiT 和 Latent Diffusion 訓練而成的,並且在模型規模和訓練數據集上進行了 scaling;
-
Sora 證明了 scale up 在視頻模型中的重要意義,並且持續地 scaling 會是模型能力提升過程中的主要驅動力,這一點和 LLM 類似;
-
Runway、Genmo 和 Pika 這些公司正在探索在 Sora 這樣的 diffusion-based 視頻生成模型上來構建直觀的界面和工作流,而這將決定模型的推廣和易用性;
-
Sora 的訓練對算力規模的要求巨大,我們推測需要在 4200-10500 張 Nvidia H100 上訓練 1 個月;
-
在推理環節,我們預估每張 H100 每小時最多能生成 5 分鐘左右時長的視頻,Sora 這類 diffusion-based 模型的推理成本要比 LLM 高出好幾個量級;
-
隨著 Sora 這樣的視頻生成模型被大範圍推廣應用,推理環節將超過模型訓練稱為計算量消耗的主導,這裡的臨界點位於生產 1530 萬到 3810 萬分鐘的視後,此時在推理上花費的計算量將超過原始訓練的計算量。作為對比,用戶每天上傳到 TikTok 的視頻為 1700 萬分鍾,YouTube 則為 4300 萬分鍾;
-
假設 AI 已經在視頻平臺上被充分應用,比如在 TikTok 上已經有 50% 的視頻由 AI 生成、YouTube 上 15% 的視頻由 AI 生成。考慮到硬件使用效率和使用方式,我們估算在峰值需求下,推理環節需要約 72 萬張 Nvidia H100。
總的來說,Sora 不僅代表了視頻生成質量和功能上的重大進步,也預示著在未來可能會大幅增加推理環節對 GPU 的需求。
01.背景
Sora 是一個 diffusion 模型,diffusion 模型在圖片生成領域的應用很普遍,比如 OpenAI 的 Dall-E 或者 Stability AI 的 Stable Diffusion 這些代表性的圖片生成模型都是 diffusion-based,而 Runway、Genmo 以及 Pika 等最近出現的探索視頻生成的公司,大概率也都是用了 diffusion 模型。
廣義上講,作為一種生成模型,diffusion model 是通過逐步學會逆轉一個給數據增加隨機噪聲的過程,從而學會創造出與其訓練數據,比如圖像或視頻,相似數據的能力。這些模型最初從完全的噪聲開始,逐步去除噪聲,並細化圖案,直到它變成連貫且詳盡的輸出。

擴散過程的示意圖:
噪聲逐步被移除,直至詳細的視頻內容顯現
Source: Sora 技術報告
這個過程和 LLM 概念下模型的工作方式存在明顯不同:LLM 是通過迭代依次生成一個接一個的 token,這個過程也被稱為自迴歸 sampling。一旦模型生成了一個 token,它就不會再改變,我們在使用 Perplexity 或者 ChatGPT 這類工具時就能看到這個過程:答案是一字一字出現的,就像有人在打字一樣。
02.Sora 的技術細節
在發佈 Sora 的同時,OpenAI 也公佈了一份關於 Sora 的技術報告,但報告中並沒有呈現太多細節。不過,Sora 的設計似乎很大程度上受到了 Scalable Diffusion Models with Transformers 這篇論文的影響。在這篇論文中,2 位作者提出了一種名為 DiT 的用於圖片生成的 Transformer-based 架構,Sora 看起來是將這篇論文的工作拓展到了視頻生成領域。結合 Sora 的技術報告和 DiT 這篇論文,我們基本可以準確梳理出 Sora 的整個邏輯。
關於 Sora 的三個重要信息:
1. Sora 沒有選擇在 pixel space(像素空間)層面工作,而是選擇在 latent space(潛空間,也稱為 latent diffusion)中進行擴散;
2. Sora 採用了 Transformer 架構;
3. Sora 似乎使用了一個非常大的數據集。
細節 1: Latent Diffusion
要理解上面的第一點提到的 latent diffusion 可以先來想一個圖片是如何被生成的。我們可以通過 diffusion 來生成每一個像素點,但這個過程會相當低效,舉例來說,一張 512x512 的圖像就有 26 萬 2144 個像素。但除了這個方式,我們還可以選擇先把像素轉化為一個壓縮後的潛在表示(latent representation),然後再在這個數據量更小的 latent space 上進行擴散,最後再將擴散後的結果轉換回像素層。這種轉換過程能夠顯著降低計算複雜度,我們不再需要處理 26 萬 2144 個規模的 pixle,只需處理 64x64=4096 個 latent representation 即可。這個方法是 High-Resolution Image Synthesis with Latent Diffusion Models 的關鍵突破,也是 Stable Diffusion 的基礎。

將左圖的像素映射成右圖中網格代表的潛在表示
Source: Sora 技術報告
DiT 和 Sora 都用到了 latent diffusion,對於 Sora 來說,還需要額外考慮的是,視頻具有時間維度:視頻是一系列圖像的時間序列,我們也稱其為幀。通過 Sora 的技術報告我們可以看出,從像素層到 latent sapce 的編碼既發生在空間層面,即壓縮每個幀的寬度和高度,也發生在時間維度,即跨時間壓縮。
細節 2: Transformer 架構
關於第二點,DiT 和 Sora 都用最基礎的 Transformer 架構取代了被普遍使用的 U-Net 架構。這一點相當關鍵,因為 DiT 的作者們發現,通過使用 Transformer 架構可以出現可預測的 scaling :隨著技術量的增加,不論模型訓練時間增加還是模型規模變化,或者二者皆有,都能讓模型能力提升。Sora 的技術報告中也提到了同樣的觀點,只不過是針對視頻生成場景,並且報告中還附上了一個直觀的圖示。

模型質量隨著訓練計算量的增加而提高:從左到右分別為基礎計算量、4 倍計算量和 32 倍計算量
這種 scaling 的特性能夠被我們常說的 scaling law 所量化,這也是一個很重要的屬性。在視頻生成之前,無論是在 LLM 的語境下,還是其他模態中的 autoregressive model,scaling law 都被研究過。能夠通過 scale 來獲得更好的模型是推動 LLM 迅速發展的關鍵動力之一。由於圖像和視頻生成也存在 scaling 的屬性,我們應該期待 scaling law 在這些領域同樣適用。
細節 3:Dataset
要訓練一個 Sora 這樣的模型,最後還要考量的一個關鍵因素是被標註的數據。我們認為,數據環節包含了絕大部分 Sora 的秘密。要訓一個 Sora 這樣的 text2video 的模型,我們需要視頻和其對應的文本描述的配對數據。OpenAI 並沒有太多討論數據集,但他們也暗示了這個數據集很大,在技術報告中,OpenAI 提到:「基於互聯網級數據上的訓練,LLM 獲得了通用能力,我們從這件事上得到了啟發」。

Source: Sora 技術報告
OpenAI 還公佈了一種用詳細文本標籤為圖像註釋的方法,這種方法被用來收集 DALLE-3 數據集,簡單來說,這個方法是在數據集的一個帶標籤的子集上訓練一個標註模型(captioner model),然後再使用這個模型來自動完成對其餘數據貼的標註。Sora 的數據集應該也用到了類似技術。
03.Sora 的影響
視頻模型開始被應用到實際中
在細節和時間連貫性角度,Sora 生成的視頻質量毫無疑問是很重要的突破,例如,Sora 可以正確處理視頻中的物體暫時被遮擋時保持不動,並且能夠準確生成水面反射效果。我們相信,Sora 目前的視頻質量對於特定類型的場景已經足夠好了,這些視頻可以被用到某些現實世界的應用中,比如 Sora 可能很快就會取代一些對視頻素材庫的需求。
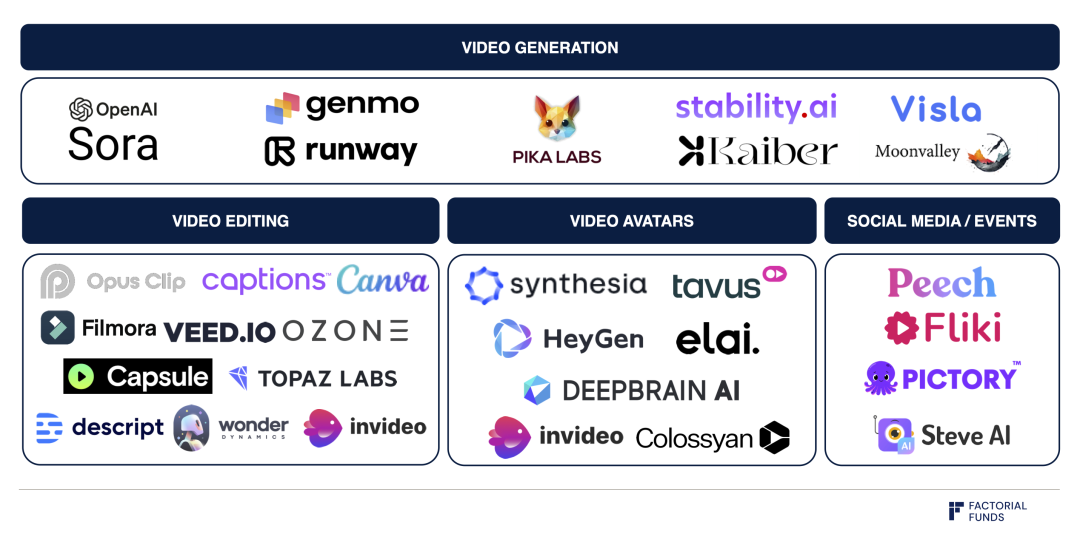
視頻生成領域圖譜
不過,Sora 依舊還面臨一些挑戰:我們目前還不清楚 Sora 的可控性如何。因為模型輸出的是像素,所以編輯一個生成出的視頻內容相當困難且耗時的。要讓模型變得有用,圍繞視頻生成模型搭建出直觀的 UI 和工作流也很必要。如上圖所示,Runway、Genmo 和 Pika 以及其他視頻生成領域的公司已經在解決這些問題了。
因為 Scaling ,我們可以加快對視頻生成的預期
我們在前面討論到,DiT 這篇研究中的一個關鍵結論是模型質量會隨著計算量的增加直接得到提升。這一點和我們已經在 LLM 中觀察到的 scaling law 很相似。我們因此也可以期待,隨著模型在更多計算資源上得到訓練,視頻生成模型質量會迅速得到進一步提升。Sora 很有力地驗證了這一點,我們預計 OpenAI 以及其他公司都會在這方面加倍投入。
合成數據生成與數據增強
在機器人以及自動駕駛等領域,數據本質上還是一種稀缺資源:在這些領域沒有一個到處都是機器人幫忙幹活或者開車的「互聯網」一般的存在。通常情況下,這兩個領域的一些問題主要是通過在模擬環境中訓練、在現實世界中大規模收集數據來解決,或同時結合兩者。然而,這兩種方法都存在挑戰,因為模擬數據往往是不符合現實的,而在現實世界中大規模收集數據的成本非常高,並且收集足夠多小概率事件的數據也具有挑戰。

如上圖所示,可以通過修改視頻的一些屬性來增強視頻,如將原始視頻(左)渲染成茂密叢林環境(右)
Source: Sora 技術報告
我們相信,像 Sora 這樣的模型在這些問題上可以發揮作用。我們認為,Sora 這類模型有可能被直接用來生成 100% 合成的數據。Sora 還可以被用來進行數據增強,也就是將對現有視頻的展現方式進行各種各樣的轉換。
這裡提到的數據增強實際上已經可以通過上面的技術報告中的示例來說明了。原始視頻中,一輛紅色汽車行駛在一條森林道路上,經過 Sora 的處理,視頻變成了汽車在熱帶叢林的道路上行駛。我們完全可以相信使用同樣的技術再渲染,還可以實現晝夜場景轉變,或者改變天氣狀況。
模擬和世界模型
「世界模型(World Models)」是一個很有價值的研究方向,如果模型足夠準確,這些世界模型可以讓人們直接在其中來訓練 AI agent,又或者這些模型可以被用來規劃和搜索。
像 Sora 這類模型以一種隱式學習(implicitly learning)的方式從視頻數據中學習到了對現實世界運作方式的基本模型。雖然這種「湧現式模擬(emergent simulation)」目前存在缺陷,但仍舊讓人感到興奮:這件事表明我們也許可以通過大規模地使用視頻數據來訓練世界模型。此外,Sora 似乎還能夠模擬非常複雜的場景,比如液體流動、光的反射、纖維和頭髮的運動等。OpenAI 甚至將 Sora 的技術報告命名為 Video generation models as world simulators,這清楚地表明他們相信這是模型會產生影響的最重要的方面。
最近,DeepMind 在自己的 Genie 模型中也展示了類似的效果:只通過在一系列遊戲視頻上訓練,模型就學會了模擬這些遊戲,甚至創造新的遊戲的能力。在這種情況下,模型甚至能夠在沒有直接觀察到行為的情況下,學會根據行為來調整自己的預測或決策。在 Genie 的例子中,模型訓練的目標仍舊是能在這些模擬環境中進行學習。

視頻來自 Google DeepMind 的 Genie:
Generative Interactive Environments 介紹
綜合來看,我們相信,如果要在現實世界任務基礎上去大規模訓練類似於機器人這類具身 agents , 像 Sora 和 Genie 這樣的模型一定能夠發揮。當然,這種模型也有侷限性:因為模型是在像素空間中訓練的,模型會模擬每一個細節,包括視頻中的風吹草動,但是這些細節和當前的任務完全無關。雖然 latent space 是經過壓縮的,但它仍然需要保留很多這類信息,因為需要保證能夠映射回 pixel,所以目前還不清楚在 latent space 中是否能有效地進行規劃。
04.算力估算
我們很關注模型訓練和推理過程中分別對計算資源的需求,這些信息可以幫助我們去預測未來需要多少計算資源。不過,因為有關 Sora 的模型大小和數據集的詳細信息非常少,要估算出這些數字也很困難。所以我們在這一板塊的估算並不能真正反映實際情況,請審慎參考。
基於 DiT 推演 Sora 的計算規模
關於 Sora 的詳細細節相當有限,但我們可以再次回顧下 DiT 這篇論文,並參照 DiT 論文中的數據來推斷 Sora 所需的計算量的信息,因為這篇研究很顯然是 Sora 的基礎。作為最大的 DiT 模型,DiT-XL 有 6.75 億個參數,並使用了大約 1021FLOPS 的總計算資源進行訓練。為了方便理解這個計算量的大小,這個計算規模相當於使用 0.4 個 Nvidia H100 運行 1 個月,或者單張 H100 運行 12 天。
目前,DiT 只用於圖片生成,但 Sora 是一個視頻模型。Sora 最長可以生成 1 分鐘的視頻。如果我們假設視頻的編碼幀率為 24 幀每秒(fps),那麼一個視頻就包含多達 1440 幀。Sora 從 pixel 到 latent space 的映射中對時間和空間維度都同時進行了壓縮,假設 Sora 使用的是和 DiT 論文中相同的壓縮率,即 8 倍壓縮,那麼在 latent space 中就有 180 幀,因此,如果我們把 DiT 的數值進行簡單的線性外推到視頻上,就意味著 Sora 的計算量是 DiT 的 180 倍。
此外,我們相信 Sora 的參數量遠超 6.75 億,我們預估,200 億規模的參數量也是有可能的,這意味著從這個角度,我們又得到了 Sora 的計算量是 DiT 30 倍的猜測。
最後,我們認為訓練 Sora 所使用到的數據集比 DiT 用到的要大得多。DiT 在 256 的 batch size 下訓練了 300 萬個步驟,也就是總共處理了 7.68 億張圖像。不過需要注意的是,由於 ImageNet 只包含了 1400 萬張圖像,所以這裡涉及到相同數據的多次重複使用。Sora 似乎是在一個圖像和視頻的混合數據集上進行的訓練,但我們對數據集的具體情況幾乎一無所知。因此,我們先簡單假設 Sora 的數據集是由 50% 的靜態圖像和 50% 的視頻組成的,並且這個數據集比 DiT 使用的數據集大了 10~100 倍。不過,DiT 對相同的 datapoint 進行了重複訓練,在存在一個可用的、更大規模的數據集的情況下,DiT 的這種做法可能是次優的。因此,我們把計算量增加的乘數給到 4 到 10 倍更為合理。
綜合以上信息,同時考慮到我們對數據集計算規模不同水平的預估,可以得出以下計算結果:
公式:DiT 的基礎計算量 × 模型增加 × 數據集增加 × 180 幀視頻數據產生的計算量增加(只針對數據集當中的 50%)
-
對數據集規模保守預估情況下:1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1.1×1025 FLOPS
-
對數據集規模樂觀預估情況下:1021FLOPS × 30 × 10 × (180 / 2) ≈ 2.7×1025FLOPS
Sora 的計算規模相當於 4211 - 10528 張 H100 運行 一個月的計算量。
算力需求:模型推理 VS 模型計算
另外一個我們去關注計算的重要部分是訓練和推理環節計算量的對比。理論上講,訓練環節的計算量即便巨大,但訓練成本是一次性的,只需要付出一次即可。相比之下,雖然推理相對於訓練需要的計算更小,但模型每次生成內容時都會產生,並且還會隨著用戶數量的增加而增加。因此,隨著用戶數量的增加和模型的廣泛使用,模型推理變得越來越重要。
因此,找到推理計算超過訓練計算的臨界點也很有有價值。
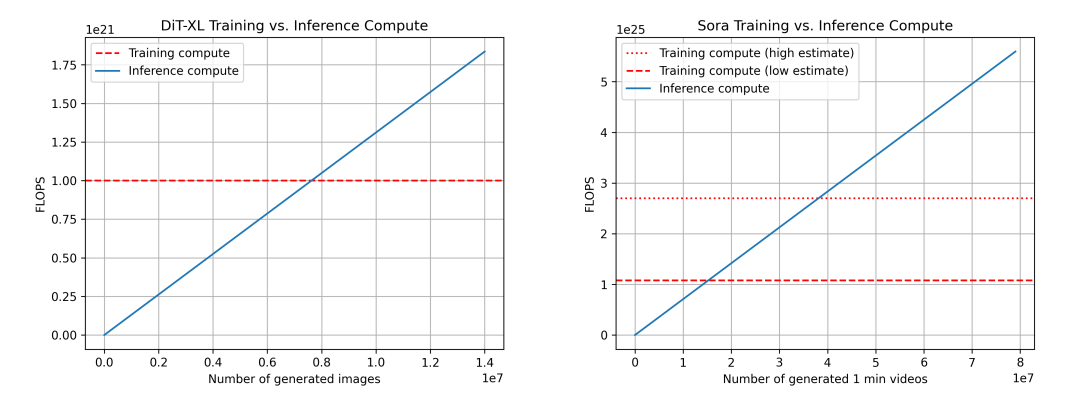
我們比較了 DiT(左)和 Sora(右)的訓練與推理計算對比。對於 Sora,基於上述估計,Sora 的數據並不完全可靠。我們還展示了兩個訓練計算的估計:一個低估計(假設數據集大小乘數為 4 倍)和一個高估計(假設數據集大小乘數為 10 倍)。
對於上述數據,我們再次使用 DiT 來推斷 Sora 的情況。對於 DiT 來說,最大的模型 DiT-XL 每一步推理使用 524×109FLOPS,而 DiT 使用生成一張圖片會經過 250 步的 diffusion,即總共是 131×1012FLOPS。我們可以看到,在生成 760 萬張圖片之後,最終達到了「推理 - 訓練的臨界點」,在此之後,模型推理開始佔據計算需求的主導地位。作為參考,用戶每天向 Instagram 上傳約 9500 萬張圖片。
對於 Sora,我們推算出 FLOPS 為 524×109FLOPS × 30 × 180 ≈ 2.8×1015FLOPS。如果我們仍然假設每個視頻有 250 個 diffusion 步驟,那麼每個視頻的總 FLOPS 為 708×1015FLOPS。作為參考,這大約相當於每小時每張 Nvidia H100 生成 5 分鐘的視頻。在對數據集做保守預估的情況下,達到「推理 - 訓練臨界點」需要生成 1530 萬分鐘的視頻,在對樂觀估計數據集規模的情況下,要達到臨界點則需要生成 3810 萬分鍾 的視頻。作為參考,大約每天有 4300 萬分鐘的視頻被上傳到 YouTube。
此外還需要補充一些注意事項:對於推理來說,FLOPS 並不是唯一重要的。例如,內存帶寬也是另外一個重要因素。此外,也有團隊在積極研究減少 diffusion 的步驟,這也會帶來模型計算需求的降低,也因此推理速度會更快。FLOPS 的利用率在訓練和推理環節也可能有所不同,這也是一個重要考慮因素。
Yang Song, Prafulla Dhariwal, Mark Chen 和 Ilya Sutskever 在 2023 年 3 月發表了 Consistency Models 研究,研究指出 diffusion 模型在圖像、音頻和視頻生成領域取得了重大進展,但是存在依賴迭代採樣過程、生成緩慢等侷限性。研究提出了一致性模型,允許多次採樣交換計算,從而提高樣本質量。https://arxiv.org/abs/2303.01469
不同模態模型推理環節的計算需求
我們還研究了不同模型在不同模態下每單位輸出的推理計算變化趨勢。研究目的是不同類別的模型中推理的計算密集度會增加多少,這對計算規劃和需求有直接的影響。由於它們在不同模態中運行,每個模型的輸出單位都不同:Sora 的單個輸出是一個長達 1 分鐘的視頻,DiT 的單個輸出是一張 512x512 像素的圖像;而對於 Llama 2 和 GPT-4,我們定義的單個輸出是一個包含 1000 個 Token 文本的文檔(作為參考,平均每篇維基百科的文章大約有 670 個 token)。
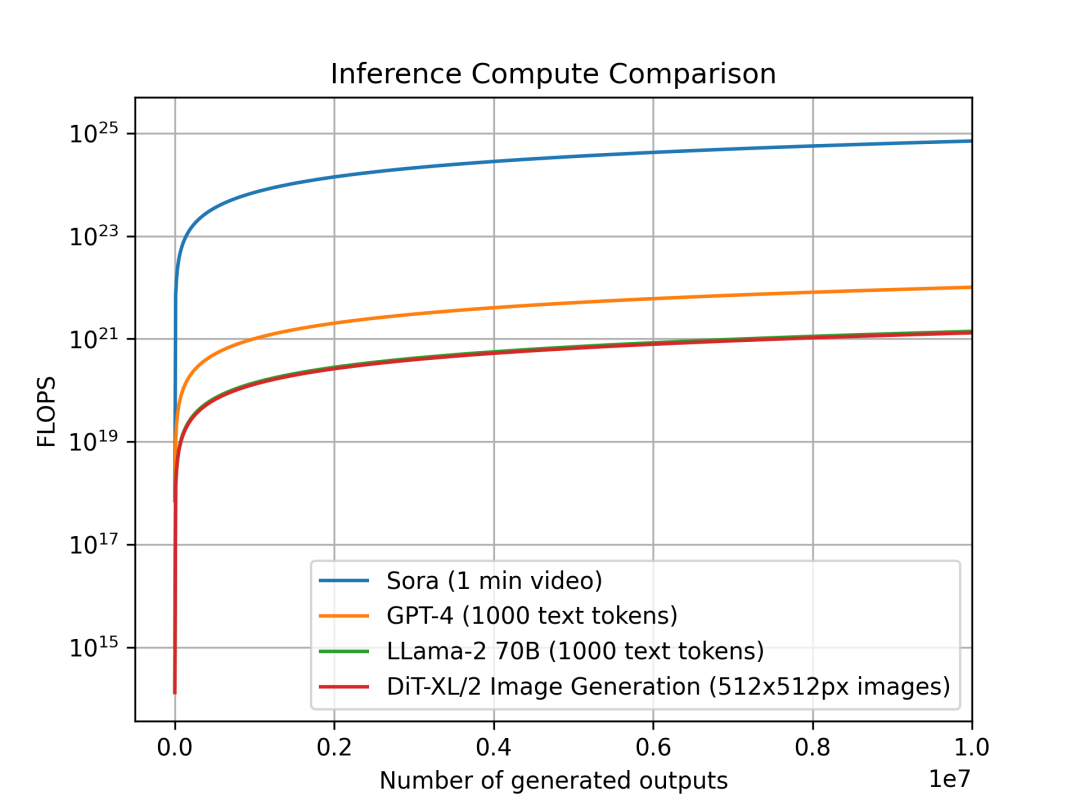
模型每個單位輸出的推理計算對比:Sora 每單位輸出 1 分鐘視頻, GPT-4 和 LLama 2 每單位輸出 1000 個 Token 的文本, DiT 每單位輸出一張 512x512px 的圖像,圖片顯示出 Sora 的推理估計在計算上要多耗費幾個數量級。
我們對比了 Sora、DiT-XL、LLama2-70B 和 GPT-4 ,並使用 log-scale 繪製了它們的 FLOPS 對比圖。對於 Sora 和 DiT,我們使用上文中的推理估計,對於 Llama 2 和 GPT-4,我們基於經驗選擇用「FLOPS = 2 × 參數量 × 生成的 Token 數量」來做一個快速估算。對於 GPT-4,我們則首先假設模型是一個 MoE 模型,每個專家模型有 2200 億參數,並且每次前向傳播都會激活 2 個專家。需要指出的是,GPT-4 相關的數據並不是 OpenAI 確認的官方口徑,僅作為參考。
Source: X
我們可以看到,像 DiT 和 Sora 這樣的 diffusion-based 的模型會在推理環節消耗更多算力:擁有 6.75 億參數的 DiT-XL 在推理環節的消耗差不多和 700 億參數的 LLama 2 相同。更進一步我們可以看到,Sora 的推理消耗比 GPT-4 還要高出好幾個數量級。
需要再次指出,上述計算中使用到的很多數字都是估算的來,依賴於簡化的假設。例如,它們沒有考慮 GPU 的實際 FLOPS 利用率、內存容量和內存帶寬的限制,以及像推測解碼( speculative decoding )這種更進階的技術方法。
當 Sora 得到大範圍應用後的推理計算需求預測:
在這一部分,我們從 Sora 的計算需求出發,來推算:如果 AI 生成的視頻在 TikTok 和 YouTube 這樣的視頻平臺已經被大規模應用,為了滿足這些需求,需要多少 Nvidia H100。
• 如上文,我們假設每張 H100 每小時可以製作 5 分鐘的視頻,相當於每張 H100 每天可以製作 120 分鐘的視頻。
• 在 TikTok 上:當前用戶每天上傳 1700 萬分鐘的視頻(3400 萬條總視頻數 × 平均長度 30 秒),假設 AI 的滲透率為 50%;
• 在 YouTube 上:當前用戶每天上傳 4300 萬分鐘的視頻,假設 AI 的滲透率為 15%(主要是 2 分鐘以下的視頻),
• 那麼 AI 每天製作的總視頻量:850 萬 + 650 萬 = 1500 萬分鍾。
• 需要支持 TikTok 和 YouTube 上創作者社區所需的總 Nvidia H100 數量:1500 萬 / 120 ≈ 8.9 萬張。
但 8.9 萬張這個數值可能偏低,因為還需要考慮到下面的多種因素:
• 我們在推算中假設的是 100% 的 FLOPS 利用率,並沒有考慮內存和通信瓶頸,50% 的利用率會更符合實際,也就是說實際的 GPU 需求是我們估算數值的 2 倍;
• 推理需求並不是沿著時間線均勻分佈,而是有突發性的,尤其還要考慮到峰值情況,因為需要更多的 GPU 來保證服務。我們認為,如果考慮峰值流量的情況,又要給 GPU 需求數量一個 2X 的乘數;
• 創作者可能會生成很多個視頻再從中選擇最好的一個上傳,如果我們保守假設平均每個上傳的視頻都對應 2 次生成,則 GPU 需求量又要乘以 2;
總的來說,在峰值流量下,需要大約 72 萬張 H100 才能滿足推理需求。
這也驗證了我們所堅信的,即隨著生成 AI 模型變得越來越受歡迎並被廣泛依賴,推理環節的計算需求將佔據主導,對於像 Sora 這樣的 diffusion-based 模型,這一點尤為明顯。
同時還需要注意的是,模型的 scaling 也將進一步大幅推動推理計算的需求。不過另一方面,通過推理技術的優化以及其他對整個技術棧的優化方式,可以抵消部分這種增加的需求。
視頻內容製作直接推動了對 Sora 這類模型的需求
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News










