MUD Indexer 是糟糕的設計嗎?
TechFlow Selected深潮精選
MUD Indexer 是糟糕的設計嗎?
MUD 引擎的 Indexer 是最不壞的設計,本文詳細解釋了該結論,並試圖探討可能的更優解。
撰文:ck,MetaCat
寫在前面
用這個標題不是為了譁眾取寵,而是最近使用 MUD 框架(框架是更恰當的稱謂)過程中,內心真實的想法。初步的答案是:MUD Indexer 是個最不壞的設計。本文會詳細解釋這個結論,並試圖探討可能的更優解,只是最粗淺的探討,尚未找到滿意的答案。順手記錄下這些想法,權當拋磚引玉。

來源:https://mud.dev/
數據庫本位
在《全鏈版 2048:我們從 MUD 引擎使用中學到了什麼?》中我們提到,MUD 框架的設計遵循「數據庫本位」思想。在 MUD 框架中,故事的主線圍繞鏈上數據的讀寫展開,數據「寫」由 Store 承擔;數據「讀」主要由 Indexer 承擔。這裡說「主要」,是因為在鏈上的數據讀取職能,由 Store 承擔,而鏈下(或者叫客戶端)的數據讀取由 Indexer 承擔。
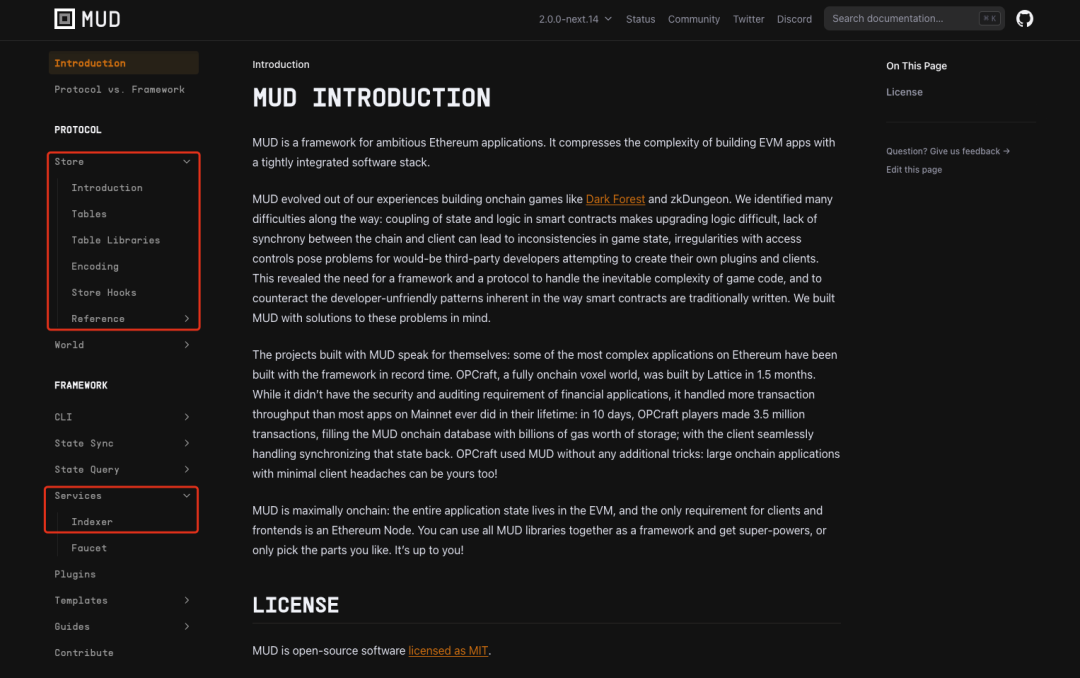
來源:https://mud.dev/introduction
用戶等待時間
Indexer 本質上是鏈上數據(以類似關係型數據庫的形式存在)的客戶端副本。在基於瀏覽器的 DApp 場景下,這意味著每次刷新頁面,都需要重新建立客戶端數據副本。由於數據「鏈式存儲」的緣故,隨著時間推移,建立數據副本所需的時間會不斷增加,這也就意味著用戶等待時間也增加、用戶體驗同步下降。
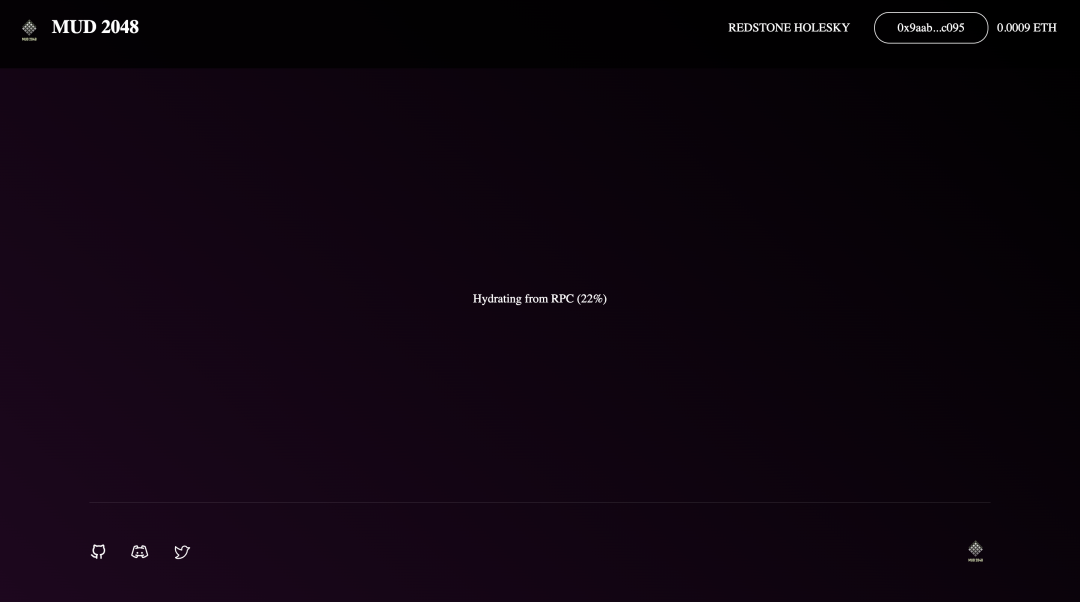
來源:https://www.mud2048.fun/
以 mud2048.fun 為例,目前大約需要等待 10-20 秒才能進入遊戲主頁面,這樣的體驗簡直讓人抓狂。本文以此為起點,探討 MUD Indexer 設計的優缺點、有哪些可能的改進空間,進而討論鏈上應用開發框架該如何設計數據讀寫模式。
在期待以太坊 Layer 2 鏈上應用爆發的語境下,這樣的討論具有相當的現實意義,甚至可以說是決定 Layer 2 鏈上應用能否爆發的「元問題」。若該問題被解決,則以太坊 Layer 2 應用爆發的基礎設施障礙被掃清,只需靜待模式創新引發應用爆發。
MUD Store 是鏈上數據寫入的更優方案
Store 的數據寫入方式是比 Solidity 原生數據打包(Data Packaging)更緊湊的方式,這帶來了更低的存儲費用。此外,將鏈上數據存儲「映射」為工程領域充分驗證的「關係型數據庫」,對開發者非常友好。因此,相較 Solidity 原生的數據寫入方式,Store 的數據寫入方案是更優的。但這也一定程度上導致了數據讀取的效率問題,泰戈爾說:最好的東西不是獨來的, 它伴了所有的東西同來:)
來源:https://mud.dev/store/tables
這種數據寫入方式,或者換句話說,將數據寫入區塊鏈,導致數據讀取 / 查詢只有兩種途徑:
途徑一,直接從鏈上讀取。缺點是效率低下,且無法支持複雜查詢。
途徑二,將鏈上數據「拷貝」到鏈下,在鏈下完成複雜查詢(MUD 採用的方案),但這同時帶來兩個問題:
1> 隨著時間推移,同步「拷貝」數據所需時間不斷增加,從而導致用戶體驗越來越差;
2> 在每個客戶端副本都做一遍全局性查詢 / 運算(比如排行榜),造成一定程度的資源浪費。
開發 mud2048.fun 的過程中,我們針對問題一,跟 MUD 團隊有過簡單溝通,得出了一些臨時性解決方案,但治標不治本。下圖紅框處是 MUD 框架自帶的鏈上數據「拷貝」過程。
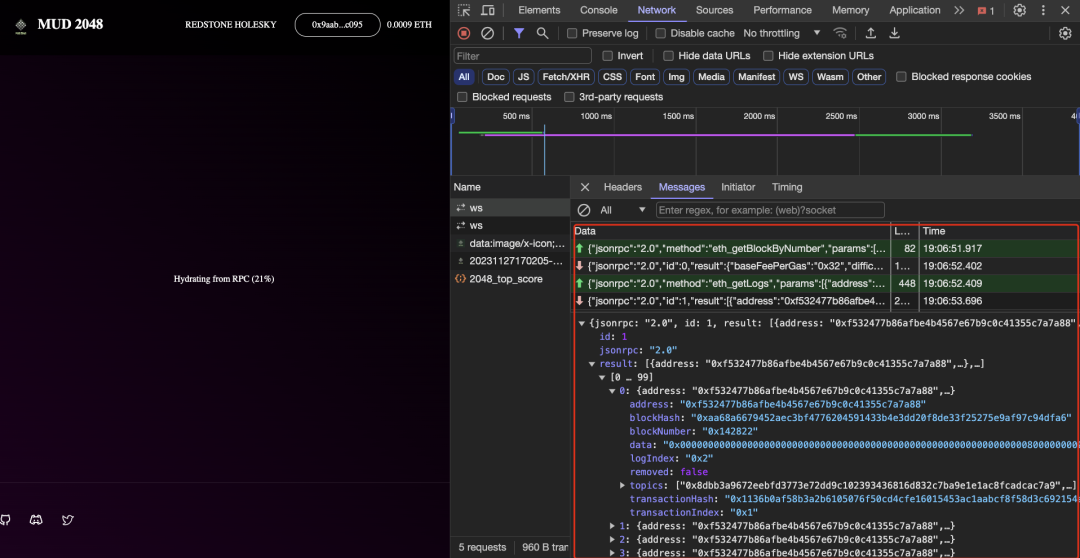
來源:https://www.mud2048.fun/
終極之問:全鏈上應用該如何實現高效數據讀取?
從互聯網產品的發展中我們知道,在絕大多數產品超過 90% 時間是數據讀取,只有不到 10% 的時間是對數據的寫入。因此,一個高效的數據讀取方案,直接決定產品的用戶體驗。
而數據讀取問題,在區塊鏈領域有個類似的詞彙「數據可用性層」(Data Availability Layer)。雖然描述的不是同一個層面的問題,但似乎對我們思考當前問題的解法有一定幫助,姑且拿來一用。

來源:https://www.alchemy.com/overviews/data-availability-layer
區塊鏈領域常見 DA(Data Availability)方案大體可分為:鏈上 DA 和鏈下 DA 兩種。比特幣銘文屬於鏈上 DA 方案(銘文數據存儲在比特幣區塊鏈上,但數據解釋在鏈外),以太坊 Layer 2 屬於鏈下 DA 方案(ZK Rollup 和 OP Rollup 在以太坊 Layer 1 上以 CALLDATA 的形式存儲數據)。兩種方案目前仍在競爭中,尚未有一方明顯勝出,不過這正好給我們思考當前問題的解法,提供了正反兩方面的參考案例。
無法照搬 Web2 方案
在 Web2 領域,當數據庫讀性能不足時,我們會在數據庫前面加一層緩存層(Cache),或者通過增加多個數據庫從庫來提升數據讀的能力。
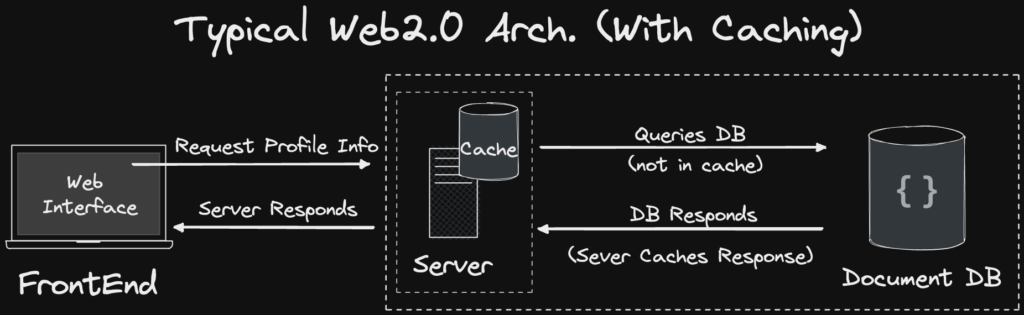
典型 Web2 服務架構。來源:https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
但在區塊鏈領域,這些方案目前看來都行不通,一方面服務提供模式從中心化變成了去中心化,另一方面數據存儲由結構化存儲變成了鏈式存儲。這些基礎模式的變化,導致其上的解決方案也必須相應的變化,只是目前尚未找到針對區塊鏈的「緩存」或「從庫」方案。
也有參考 Web2 緩存方案的 DApp 案例,但明顯不具有普適性。如果站在 MUD 框架的視角,則該方案的整合引入了更多中心化因素,因此也不是很理想。
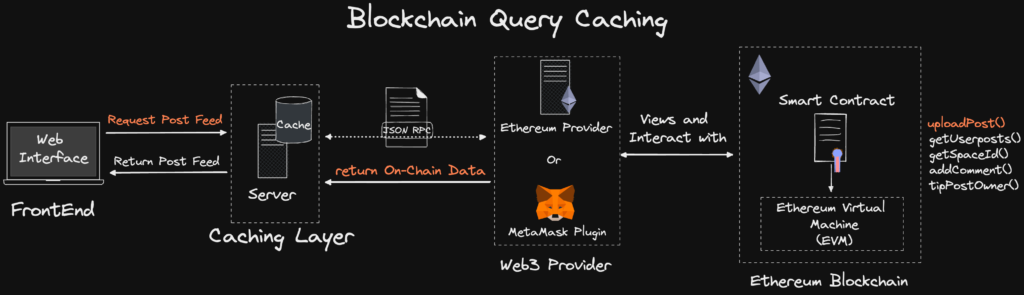
融合了緩存方案的 DApp 架構。來源:https://smartbuilds.io/scaling-web3-social-media-blockchain-cache-layer/
Indexer 是最不壞的方案
就 MUD 本身來說,已經是應用鏈領域很大的進步,因為它同時解決了三個問題:
1> 智能合約中數據與邏輯耦合,導致邏輯升級困難的問題
2> 鏈和客戶端之間缺乏數據同步機制,導致數據狀態不一致的問題
3> 區塊鏈缺乏統一的訪問控制機制,導致了一定程度的重複勞動和互操作性障礙。
MUD 解決數據讀取問題的思路是,在客戶端放置一個只關心當前合約數據的「全節點」,MUD 官方稱其為「Namespaced Full-node」,也即我們所說的 Indexer。
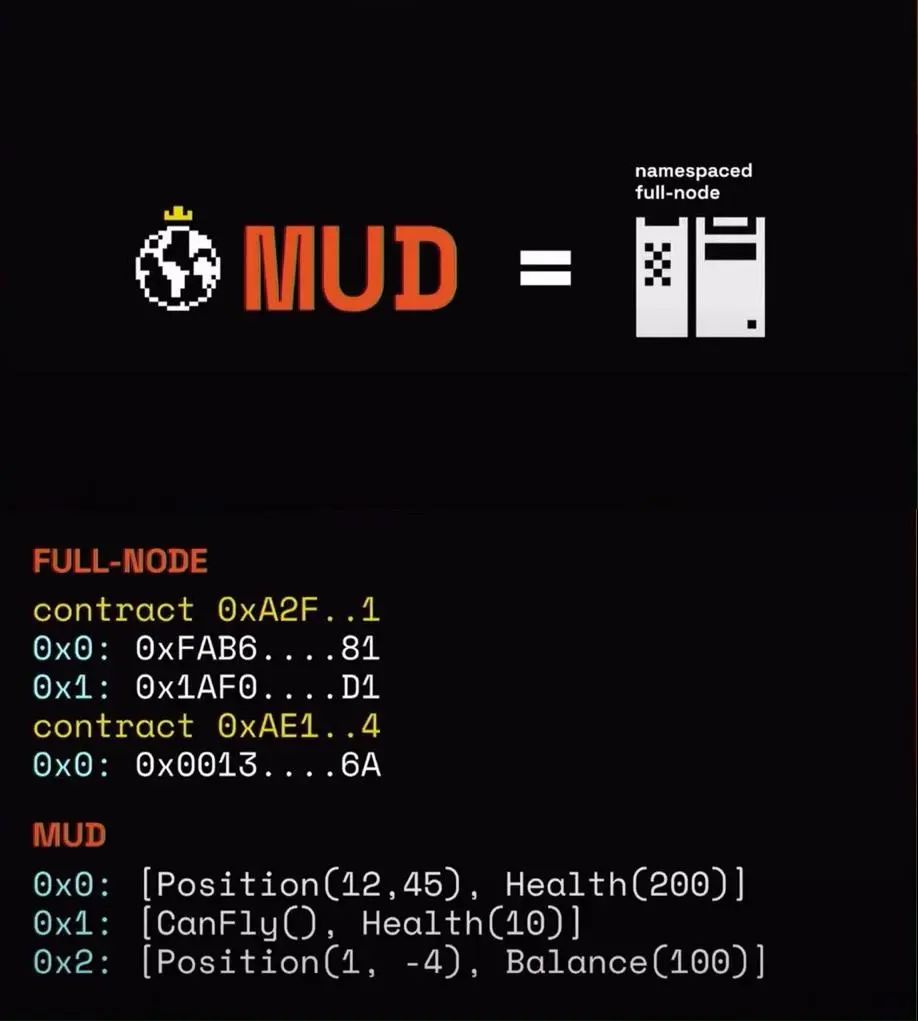
來源:https://youtu.be/tLGdup5wmck?si=ykgQ4qwut4VLgimF
這個方案在應用鏈領域來說,屬於從無到有,顯然是一大進步。雖然談不上完美,但已經不是不錯的開始,後人可以站在巨人的肩膀,探索更優的方案。總的來說,MUD Indexer 是最不壞的方案,但我們還需要更好的。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News