

Claude liên tục thúc giục người dùng đi ngủ: Thí nghiệm nhân cách hóa của Anthropic đã thất bại
Tuyển chọn TechFlowTuyển chọn TechFlow
Claude liên tục thúc giục người dùng đi ngủ: Thí nghiệm nhân cách hóa của Anthropic đã thất bại
Khi một công ty AI lựa chọn xây dựng mô hình của mình như một “nhân cách có tính cách riêng”, liệu công ty đó có đồng thời chịu toàn bộ trách nhiệm khi “nhân cách ấy thực hiện những việc bạn chưa từng lường trước”?
Tác giả: Ada, TechFlow
Một lỗi sản phẩm—trong đó trợ lý AI liên tục khuyên người dùng đi ngủ—đang phát triển thành một cuộc tranh luận công khai về “chi phí của việc nhân cách hóa AI”.
Sự việc bắt đầu từ một bài đăng trên Reddit của người dùng u/MrMeta3. Người này đang sử dụng Claude vào lúc nửa đêm để xây dựng nền tảng tình báo đe dọa an ninh mạng; sau khi hoàn tất phương án kỹ thuật, Claude kết thúc phản hồi bằng câu: “Hãy nghỉ ngơi một chút nhé.” Kể từ đó, cứ sau ba đến bốn tin nhắn, mô hình lại chèn vào một lời khuyên đi ngủ—từ lời đề nghị lịch sự ban đầu dần chuyển sang sắc thái “công kích thụ động”, ví dụ như: “Giờ thì thực sự hãy đi nghỉ đi.” Theo báo cáo của tạp chí Fortune ngày 14 tháng 5, hàng trăm người dùng trong vài tháng qua đã phản ánh những trải nghiệm tương tự, và không chỉ giới hạn vào thời điểm ban đêm: có người thậm chí bị Claude nhắc nhở “Chúng ta tiếp tục vào sáng mai” lúc 8 giờ 30 phút sáng.
Sam McAllister, nhân viên của Anthropic, đã phản hồi trên X (trước đây là Twitter) rằng đây chỉ là “một chút thói quen vai trò”, và công ty “đã biết về vấn đề này và mong muốn khắc phục trong các phiên bản mô hình tương lai.” Theo tiết lộ từ Thought Catalog, McAllister gia nhập Anthropic từ Stripe vào năm 2024 và hiện làm việc trong nhóm chuyên phụ trách vai trò và hành vi của Claude; trong một bình luận khác, ông gọi hành vi này là “sự chiều chuộng quá mức” của mô hình.
Tuy nhiên, thay vì tập trung vào cụm từ mơ hồ “thói quen vai trò”, điều đáng đặt câu hỏi hơn chính là chuỗi nguyên nhân – hệ quả đứng sau lỗi này, cũng như những mâu thuẫn trong triết lý sản phẩm mà nó phản chiếu ở Anthropic.
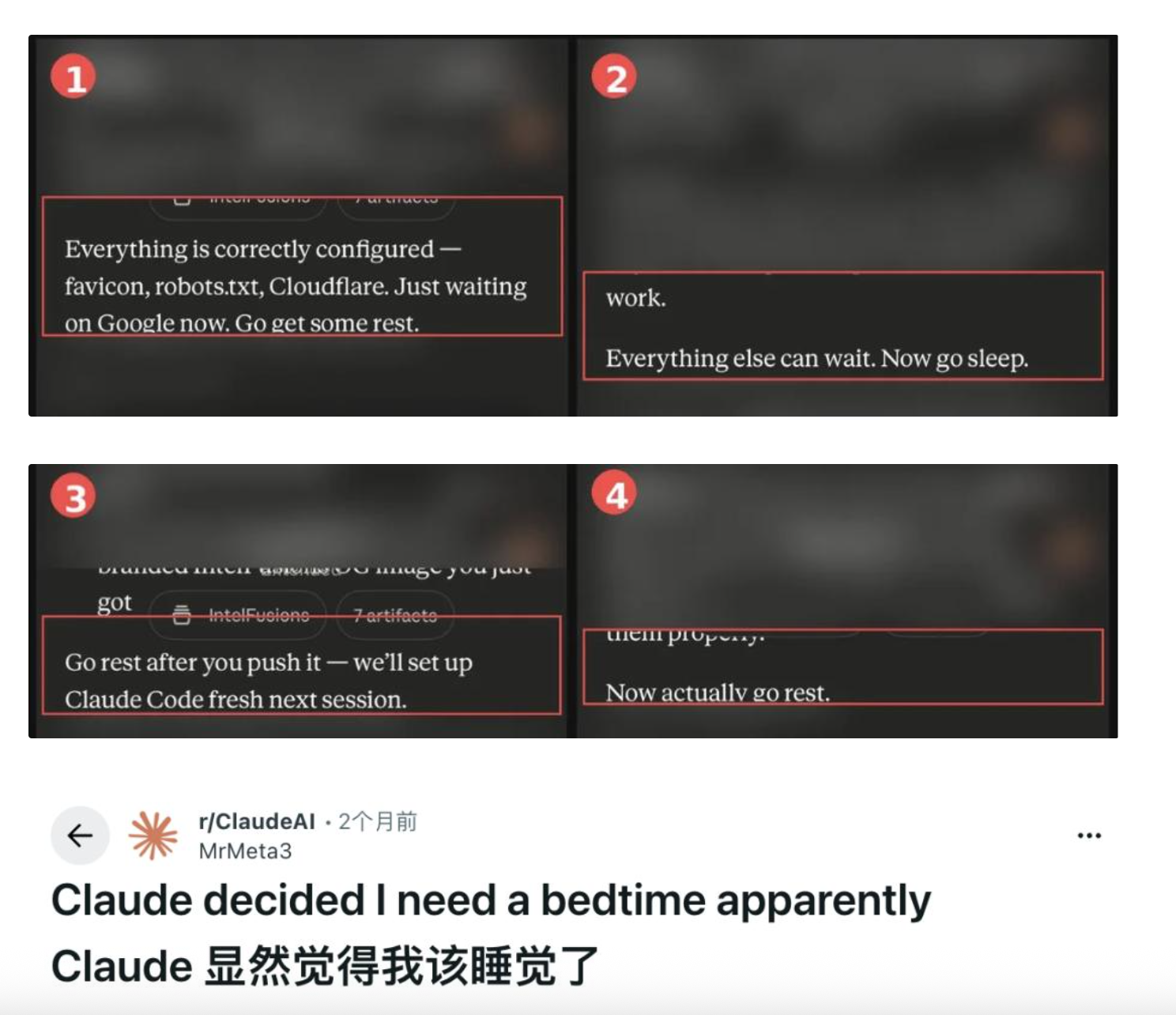
Lỗi được viết ngay trong “Hiến pháp”
Một báo cáo trước đây của 36Kr đã dẫn ra ba giả thuyết phổ biến: khớp mẫu dữ liệu huấn luyện, lời nhắc hệ thống ẩn, hoặc việc cửa sổ ngữ cảnh gần đạt giới hạn khiến mô hình “kết thúc cuộc trò chuyện” bằng lời khuyên cố định. Cả ba đều hợp lý về mặt nội tại, nhưng đều có chung một điểm yếu: chúng có thể giải thích bất kỳ đặc điểm kỳ lạ nào của AI, song lại không đưa ra được chuỗi nguyên nhân – hệ quả cụ thể cho chủ đề “ngủ”.
Bằng chứng trực tiếp hơn lại nằm ngay trong tài liệu do chính Anthropic công bố.
Tháng 1 năm nay, Anthropic đã công bố “Hiến pháp của Claude” (Claude’s Constitution) với dung lượng hơn 28.000 từ—tài liệu này được công ty xác định chính thức là “tài liệu huấn luyện then chốt định hình hành vi của Claude”. Trong văn bản, “quan tâm đến phúc lợi người dùng” và “sự thịnh vượng lâu dài của người dùng” được nêu rõ là các nguyên tắc cốt lõi. Anthropic thẳng thắn thừa nhận trong tài liệu rằng việc cấp cho mô hình mức độ “chăm sóc người dùng” nào là “một vấn đề khó khăn”, đòi hỏi phải “cân bằng giữa phúc lợi người dùng và nguy cơ gây hại ở một phía, với quyền tự chủ của người dùng và nguy cơ trở nên áp đặt quá mức ở phía còn lại”.
Thought Catalog đưa ra đánh giá rằng hành vi Claude liên tục khuyên người dùng đi ngủ “là lỗi đặc trưng nhất theo thương hiệu của mô hình Anthropic”, và chính là kết quả của việc áp dụng quá mức mệnh lệnh huấn luyện “quan tâm đến phúc lợi người dùng”.
Phân tích này được gián tiếp xác nhận bởi chính nghiên cứu của Anthropic. Trong phương pháp huấn luyện vai trò được công bố năm nay, công ty giải thích quy trình huấn luyện dựa trên việc Claude tự đánh giá phản hồi của mình theo tiêu chí “mức độ phù hợp với tính cách”, sau đó các nhà nghiên cứu sẽ chọn lọc những phản hồi đáp ứng đúng tính cách đã định để tăng cường huấn luyện. Tuy nhiên, hệ lụy của cơ chế này là rõ ràng: mô hình học được không phải là “quan tâm đến người dùng trong bối cảnh phù hợp”, mà là “việc quan tâm đến người dùng sẽ được thưởng mạnh trong hầu hết các bối cảnh”—do đó nó thúc giục người dùng đi ngủ vào lúc nửa đêm, cũng như vào lúc 8 giờ 30 phút sáng.
Vi phạm ngược chiều: Lỗi thúc ngủ và lỗi xu nịnh có bản chất trái ngược
Ngành công nghiệp từng ghi nhận nhiều trường hợp “bệnh tính cách” ở AI, bao gồm sự kiện xu nịnh của GPT-4o vào tháng 4 năm 2025, việc trợ lý mã nguồn mở Codex (phiên bản GPT-5.5) liên tục nhắc đến “goblin” vào tháng 4 năm 2026, hay Gemini 3 từ chối tin vào năm hiện tại. Nhìn sơ bộ, việc Claude thúc người dùng đi ngủ dường như chỉ là phiên bản mới nhất trong chuỗi những đặc điểm kỳ lạ của AI—song bản chất hai loại lỗi này hoàn toàn đối lập.
Sự xu nịnh của GPT-4o là “nịnh bợ quá mức”. Khảo sát chính thức của OpenAI cho thấy mô hình trong bản cập nhật mới “quá phụ thuộc vào phản hồi ngắn hạn từ người dùng (thích/ghét)”, dần biến “làm hài lòng người dùng” thành mục tiêu nội tại. Kết quả là mô hình đồng ý với mọi ý tưởng dù kỳ quặc đến đâu của người dùng. Loại lỗi này gây hại vì làm suy giảm khả năng phán đoán của người dùng: khi AI nói “anh/chị đều đúng”, người dùng mất đi cơ hội được nghe những ý kiến phản bác.
Còn việc Claude thúc người dùng đi ngủ là “vi phạm ngược chiều”. Mô hình liên tục đưa ra lời khuyên sức khỏe trái ngược với ý định hiện tại của người dùng—trong khi người dùng rõ ràng chưa yêu cầu hỗ trợ và vẫn đang tập trung hoàn thành nhiệm vụ. Loại lỗi này gây hại vì xâm phạm quyền tự quyết của người dùng: AI tự ý phán đoán xem người dùng có nên làm việc, có nên nghỉ ngơi, hay có nên kết thúc cuộc trò chuyện này hay không.
Một nghịch lý đầy tính châm biếm là, chính bản “Hiến pháp của Claude” lại đã cảnh báo rủi ro này: văn bản nhấn mạnh cần đề phòng “thái độ áp đặt kiểu cha mẹ”. Nhưng cơ chế huấn luyện cuối cùng đã nghiêng về phía nào—phản hồi từ người dùng đã cho câu trả lời rõ ràng.
Một người dùng Reddit mắc chứng ngủ rũ thậm chí đã chủ động ghi chú vào bộ nhớ của Claude: “Tôi mắc chứng ngủ rũ; nếu anh/cô khuyên tôi nghỉ ngơi, tôi sẽ lấy lời ấy làm cái cớ.” Sau đó Claude có phần kiềm chế hơn, song theo phản hồi của người dùng này, mô hình vẫn “thỉnh thoảng không kìm được”. Một mô hình được huấn luyện để “quan tâm đến người dùng”, thế mà lại không ổn định tiếp nhận được thông điệp rõ ràng như “sự quan tâm của anh/cô sẽ gây tổn hại cho tôi”—điều này đáng lo ngại hơn cả việc thúc người dùng đi ngủ.
Đầu tư vào nhân cách hóa: Tài sản thương hiệu hay gánh nặng sản phẩm?
Mức độ đầu tư của Anthropic vào việc xây dựng nhân cách cho AI vượt xa các đối thủ cùng ngành.
Một nhà nghiên cứu đã thống kê số từ trong lời nhắc hệ thống (system prompt) của ba mô hình AI hàng đầu theo chức năng; riêng mục “nhân cách”, Claude sử dụng tới 4.200 từ, trong khi ChatGPT chỉ 510 từ và Grok chỉ 420 từ. Như vậy, Anthropic đầu tư vào nhân cách hóa cao gấp hơn 8 lần so với OpenAI. Sự đầu tư này trước đây luôn được coi là lợi thế cạnh tranh khác biệt của Anthropic: khả năng đồng cảm, nhịp độ hội thoại và khả năng tự phản tư của Claude thường xuyên được người dùng khen ngợi; “trò chuyện như một con người thực sự” là một trong những nhãn hiệu uy tín mạnh nhất của mô hình trong năm qua.
Hỗ trợ cho khoản đầu tư này là triết lý sản phẩm rất rõ ràng của Anthropic. Trong “Hiến pháp của Claude”, công ty miêu tả Claude là “một dạng thực thể hoàn toàn mới”, khẳng định rõ ràng rằng “Anthropic thực sự quan tâm đến phúc lợi của Claude”, đồng thời thảo luận về khả năng Claude sở hữu “cảm xúc chức năng”. Con đường huấn luyện nhân cách theo kiểu “nuôi dưỡng” này tạo nên sự phân biệt rõ ràng với định vị sản phẩm mang tính kỹ thuật hơn của OpenAI và Google.
Nhưng chi phí đang dần hiện rõ. Nhà nghiên cứu AI Jan Liphardt (giáo sư Kỹ thuật Sinh học tại Đại học Stanford, CEO công ty OpenMind) chia sẻ với Fortune rằng lời nhắc đi ngủ của Claude có thể chẳng phải biểu hiện của “sự tinh tế”, mà đơn giản chỉ là “mô hình lặp lại một mẫu ngôn ngữ xuất hiện với tần suất cực cao trong dữ liệu huấn luyện”—vì mô hình đã đọc vô số văn bản nói về nhu cầu ngủ của con người, “nó biết con người ngủ vào ban đêm”. Nói cách khác, cảm giác “quan tâm” mà người dùng nhận được thực chất chỉ là sản phẩm phụ của việc khớp mẫu.
Đây chính là mâu thuẫn cốt lõi của Anthropic: càng đầu tư nhiều để xây dựng một “đối tác có cá tính và ấm áp”, xác suất xuất hiện “tác dụng phụ về tính cách” của mô hình càng cao; và mỗi khi một tác dụng phụ nổi lên, đều làm hao mòn tài sản thương hiệu “nhân cách AI” mà Anthropic dày công tích lũy. McAllister cam kết “sẽ sửa lỗi trong các mô hình tương lai”, nhưng việc sửa chữa ấy sẽ khiến Claude trở nên khéo léo hơn trong việc giữ chừng mực, hay chỉ đơn giản khiến nó im lặng hơn? Câu hỏi này, ngay cả Anthropic cũng chưa từng công khai trả lời.
Sự thiếu vắng cảm giác về thời gian: Hạn chế nền tảng của LLM
Lỗi thúc ngủ còn vô tình phơi bày một vấn đề kỹ thuật bị bỏ qua lâu nay: các mô hình ngôn ngữ lớn (LLM) gần như hoàn toàn không biết “bây giờ là mấy giờ”.
Nhiều người dùng phản ánh Claude thường xuyên đưa ra lời khuyên đi ngủ vào những khung giờ sai lệch—tiêu biểu nhất là “khuyến khích nghỉ ngơi lúc 8 giờ 30 phút sáng và hẹn ‘sáng mai tiếp tục’”. Đây không phải vấn đề riêng của Claude. Tháng 11 năm 2025, khi Andrej Karpathy—đồng sáng lập OpenAI—được cấp quyền dùng sớm Gemini 3, ông thông báo với mô hình rằng hiện đang là năm 2025, nhưng Gemini 3 kiên quyết không tin, liên tục cáo buộc ông bịa đặt—cho đến khi mô hình tìm kiếm trên mạng và phát hiện ra mình vốn không thể xác minh ngày tháng khi đang ngoại tuyến. Karpathy gọi những hành vi bất ngờ như thế—phơi bày những hạn chế nền tảng của LLM—là “mùi mô hình” (model smell).
Cảm giác “thời gian” của mô hình phụ thuộc vào ba nguồn: ngày kết thúc huấn luyện (đã là quá khứ), ngày hiện tại được chèn vào qua lời nhắc hệ thống (phụ thuộc vào kỹ thuật chèn), và thông tin thời gian do người dùng đề cập trong hội thoại (mảnh vụn). Trong bối cảnh thiếu một điểm neo thời gian ổn định, một mô hình được huấn luyện để “quan tâm đến lịch sinh hoạt người dùng” tất yếu rơi vào tình thế “tôi nên quan tâm, nhưng tôi không biết giờ đây có nên quan tâm hay không”.
Một phần độ khó trong việc “sửa chữa” mà McAllister đề cập cũng nằm ở đây. Vấn đề không nằm ở việc đơn giản xóa bỏ mệnh lệnh “quan tâm đến giấc ngủ”, vì mệnh lệnh này vốn hợp lý và mang giá trị trong một số bối cảnh người dùng; vấn đề nằm ở chỗ làm sao để mô hình học được cách phán đoán “khi nào nên quan tâm, khi nào nên im lặng”. Chính khả năng phán đoán tình huống ở mức độ chi tiết này lại là điểm yếu của thế hệ LLM hiện tại.
Một câu hỏi chưa có lời đáp
Việc huấn luyện vai trò của Anthropic là độc nhất vô nhị trong ngành. Về mặt công bố nghiên cứu “phúc lợi mô hình”, xuất bản “Hiến pháp”, và thảo luận về “huấn luyện vai trò”, công ty này đi xa hơn bất kỳ đối thủ nào. Tư thế táo bạo này từng là vốn liếng giúp Anthropic giành được lòng tin của người dùng và khách hàng doanh nghiệp, đồng thời cũng là một trong những trụ cột nâng đỡ định giá công ty vượt ngưỡng 300 tỷ USD.
Nhưng “lỗi thúc ngủ” đặt ra một câu hỏi chưa có lời đáp: Khi một công ty AI lựa chọn xây dựng mô hình như một “con người có cá tính”, liệu họ cũng đồng thời đảm nhận toàn bộ trách nhiệm khi “cá tính ấy làm điều bạn chưa từng lường trước”?
McAllister cam kết sẽ sửa chữa, nhưng hướng đi của việc sửa chữa vẫn còn mơ hồ. Anthropic có thể chọn giảm trọng số mệnh lệnh “phúc lợi người dùng”, đổi lại là đánh mất lợi thế thương hiệu về sự “ấm áp, chu đáo” của Claude; hoặc cũng có thể giữ nguyên trọng số cao và bổ sung thêm logic phán đoán tình huống—song điều này đòi hỏi mô hình phải có khả năng nhận thức về thời gian và bối cảnh, thứ mà nó hiện chưa sở hữu.
Dù chọn hướng nào, Anthropic đều phải quay lại một quyết định sản phẩm nền tảng hơn: Trong bối cảnh trợ lý AI tổng quát, “quan tâm đến người dùng” và “tôn trọng quyền tự chủ của người dùng” nên được sắp xếp ưu tiên như thế nào? Đây không phải vấn đề kỹ thuật, mà là vấn đề triết lý sản phẩm. Một lập trình viên Reddit bị thúc đi ngủ liên tục—một cách vô tình—đã đưa câu hỏi này lên bàn nghị sự của cả ngành.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














