

Phân tích chuyên sâu về $VVV: Cơ sở hạ tầng AI bảo mật quyền riêng tư và đường cong tăng trưởng bị đánh giá thấp
Tuyển chọn TechFlowTuyển chọn TechFlow
Phân tích chuyên sâu về $VVV: Cơ sở hạ tầng AI bảo mật quyền riêng tư và đường cong tăng trưởng bị đánh giá thấp
Phân tích toàn bộ chuỗi giá trị của Venice, từ kiến trúc bảo mật đến mô hình kinh doanh.
Tác giả: Yan Liberman
Biên dịch: TechFlow
Giới thiệu bởi TechFlow: Dữ liệu đăng ký của Venice trong ba tuần gần đây cho thấy tốc độ tăng trưởng ARR mới đạt mức cao tới 34%, trong khi định giá hiện tại chỉ bằng 2,5 lần doanh thu dự kiến trong 12 tháng tới. Một cựu nhà đầu tư tiền mã hóa đã phân tích toàn bộ chuỗi giá trị của Venice — từ kiến trúc bảo mật đến mô hình kinh doanh — và cho rằng thị trường đang đánh giá quá thấp quy mô thực sự của phân khúc “AI suy luận riêng tư”, cũng như lợi thế không thể thay thế của Venice trên phân khúc này nhờ sự kết hợp độc đáo của nhiều yếu tố, đồng thời bày tỏ quan điểm tích cực đối với $VVV.

Venice là một nền tảng suy luận AI lấy bảo mật làm ưu tiên hàng đầu, cho phép người dùng khai thác các mô hình tiên tiến và mô hình nguồn mở mà không cần tiết lộ danh tính của mình cho nhà cung cấp mô hình nền tảng. Theo tôi, đây là giải pháp bảo mật toàn diện nhất hiện có trên thị trường AI: đại lý ẩn danh, định tuyến mô hình nguồn mở, suy luận TEE (Trusted Execution Environment – Môi trường thực thi đáng tin cậy) được xác thực phần cứng, và suy luận được mã hóa đầu cuối — cả bốn chức năng này đều được tích hợp vào một sản phẩm tiêu dùng duy nhất, với chế độ bảo mật có thể lựa chọn theo từng yêu cầu. Không có đối thủ nào khác có thể cung cấp đồng thời cả bốn tính năng này.
Mô hình kinh doanh này đang tăng trưởng mạnh mẽ. Các cuộc thảo luận trên Crypto Twitter về Venice thường đánh giá thấp doanh thu hiện tại, tốc độ tăng trưởng gần đây và triển vọng tương lai. Venice mới đây bắt đầu công bố dữ liệu đăng ký hàng ngày; dữ liệu chi tiết trong ba tuần cho thấy tốc độ tăng trưởng ARR từ đăng ký mới rõ ràng đang gia tốc:
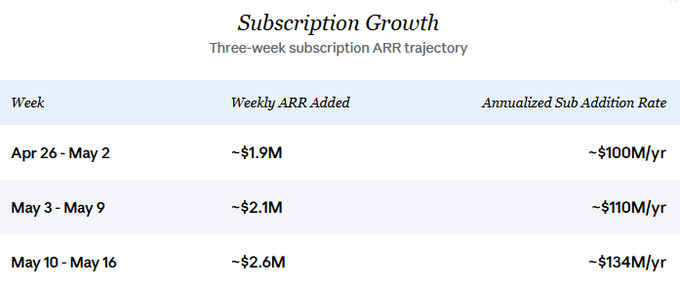
Tốc độ tăng trưởng liên tục là giả định cốt lõi của phân tích này. Tôi cũng cho rằng doanh thu từ API gần đây luôn tăng song hành với tốc độ tăng đăng ký — giả định này sẽ được giải thích chi tiết hơn trong phần “Tình trạng hiện tại và tăng trưởng” bên dưới. Với mức tăng đăng ký mới mỗi năm ở mức thận trọng là 100 triệu USD (tương đương tốc độ vào cuối tháng Tư), và giả sử doanh thu từ API cũng tăng thêm cùng mức, tổng doanh thu tăng trong 12 tháng tới sẽ vào khoảng 200 triệu USD.
Xu hướng gia tốc gần đây cho thấy, nếu tốc độ này được duy trì, con số thực tế sẽ có dư địa tăng đáng kể.
Bài viết này sẽ lần lượt phân tích những điểm độc đáo của Venice:
- Cấp độ bảo mật: Một kiến trúc bảo mật sâu sắc vượt xa khái niệm thông thường về “trò chuyện AI riêng tư”.
- Phân loại người dùng: Người dùng của Venice là những cá nhân bị đẩy ra ngoài các luồng chính thống do các chính sách nội dung, yêu cầu tuân thủ, mô hình đe dọa hoặc nguyên tắc đạo đức — chứ không phải do chiến dịch tiếp thị thu hút.
- Quy mô thị trường: Một thị trường suy luận riêng tư đang mở rộng, thường bị đánh giá thấp khi áp dụng khuôn khổ trò chuyện AI dành cho người tiêu dùng.
- Cảnh quan cạnh tranh: Venice kết hợp đồng thời độ sâu bảo mật, khả năng truy cập mô hình không kiểm duyệt và phân phối natively-encrypted — một tổ hợp hiện chưa có đối thủ nào sao chép được.
- Thiết kế token và định giá $VVV: Cơ chế của VVV và DIEM chuyển đổi tăng trưởng nền tảng thành giá trị token như thế nào, và định giá VVV so với các đối thủ cùng phân khúc suy luận riêng tư như OpenRouter, Fireworks, Together AI… ra sao.
Sau đợt tăng giá gần đây và điều chỉnh về mức 14 USD, vốn hóa thị trường của VVV đạt khoảng 660 triệu USD, định giá đầy đủ (FDV) khoảng 1,12 tỷ USD. ARR hiện tại ước tính khoảng 60 triệu USD (được tính toán chi tiết trong phần “Tình trạng hiện tại và tăng trưởng” bên dưới), đang tăng với tốc độ khoảng 200 triệu USD mỗi năm và vẫn đang gia tốc. Tính theo ARR hiện tại, hệ số P/S (tỷ lệ vốn hóa/doanh thu) của VVV khoảng 11x (FDV khoảng 19x), thấp hơn mức 26x của OpenRouter — đối thủ cùng phân khúc suy luận riêng tư. Nếu tính theo ARR dự kiến trong 12 tháng tới khoảng 260 triệu USD (60 triệu USD hiện tại cộng thêm mức tăng 200 triệu USD/năm), hệ số P/S của VVV sẽ giảm còn khoảng 2,5x (FDV khoảng 4,3x).
Tình trạng hiện tại và tăng trưởng
Venice gần đây bắt đầu công bố dữ liệu đăng ký mới hàng ngày. Kết hợp với các mốc công khai định kỳ về số lượng người dùng đăng ký, hai luồng dữ liệu này giúp tôi xây dựng được ước tính ARR hiện tại và dự báo xu hướng tăng trưởng trong tương lai.
Để ước tính ARR hiện tại, tôi bắt đầu từ tổng số người đăng ký. Dựa trên nhịp độ công bố công khai trong một khoảng thời gian, tổng số người đăng ký luôn tăng với tốc độ khoảng 300.000 người/tháng. Mốc gần đây nhất được xác nhận là khoảng 3 triệu người đăng ký tính đến ngày 16/05/2026, tăng từ mức khoảng 2 triệu người vào ngày 01/02 — phù hợp với tốc độ tăng 300.000 người/tháng. Giả sử tỷ lệ chuyển đổi thanh toán trọn đời khoảng 5% (một con số thận trọng, vì dữ liệu hàng ngày cho thấy tốc độ chuyển đổi của người đăng ký mới nhanh hơn), điều này nghĩa là đến giữa tháng Năm, Venice có khoảng 150.000 người dùng trả phí đang hoạt động. Cho đến giữa cuối tháng Tư, chỉ có gói Pro cơ bản giá 18 USD/tháng tồn tại; các gói Pro+ (68 USD/tháng) và Max (200 USD/tháng) mới được ra mắt và đang dần thay đổi cấu trúc, nhưng đa số người dùng trả phí vẫn chọn gói 18 USD. ARPPU (Doanh thu trung bình trên mỗi người dùng trả phí) có trọng số khoảng 18–19 USD/tháng, nghĩa là MRR (Doanh thu hàng tháng) từ đăng ký hiện tại khoảng 2,8 triệu USD, tương đương ARR từ đăng ký khoảng 33 triệu USD. Đây chỉ là phần đăng ký; doanh thu từ API sẽ được bổ sung sau trong phần này để đưa ra ước tính ARR tổng thể.
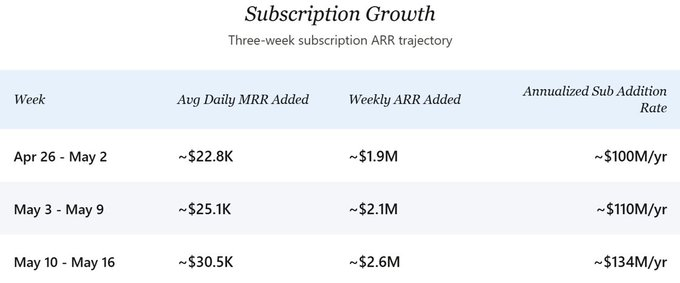
Về xu hướng trong tương lai, tốc độ tăng ARR từ đăng ký mới liên tục gia tốc. Theo tốc độ vào cuối tháng Tư, công ty tăng khoảng 2 triệu USD ARR từ đăng ký mỗi tuần. Đến tuần gần nhất (10–16/05), tốc độ này đã tăng vọt lên khoảng 2,6 triệu USD/tuần — tương đương tốc độ tăng hàng năm khoảng 134 triệu USD. Trong kịch bản cốt lõi của phân tích này, tôi chọn mức tăng hàng năm thận trọng là 100 triệu USD nhằm tránh phóng đại quá mức xu hướng gia tốc gần đây. Tốc độ tăng ròng sau khi trừ đi tỷ lệ hủy bỏ sẽ thấp hơn một chút, nhưng ở quy mô hiện tại, khoảng chênh lệch này nhỏ đến mức không ảnh hưởng đáng kể đến định hướng phân tích — tốc độ tăng thô (gross growth) là trụ cột của phân tích định hướng trong bài viết này.
Dữ liệu chi tiết trong ba tuần (26/04 – 16/05) cho thấy rõ xu hướng tăng mạnh:
Từ tuần thứ nhất đến tuần thứ ba, mức tăng MRR hàng ngày tăng khoảng 34%. Giả sử doanh thu từ API tăng theo tỷ lệ 1:1 với MRR từ đăng ký mới (giải thích chi tiết bên dưới), tốc độ tăng hàng năm tiềm ẩn đã tăng từ khoảng 200 triệu USD lên khoảng 268 triệu USD. Hai yếu tố dường như đang thúc đẩy bước ngoặt này: Việc ra mắt các gói Pro+ và Max đã mang đến lựa chọn mới cho người dùng sẵn sàng chi trả cao hơn, nâng cao ARPPU có trọng số; đồng thời, tỷ lệ chuyển đổi thanh toán dường như cũng tăng tốc sau khi mở rộng các gói dịch vụ.
Doanh thu từ API khó đo lường hơn vì không được công bố trực tiếp. Kịch bản cơ sở của tôi là, doanh thu vận hành mới từ API gần đây tăng với tỷ lệ khoảng 1:1 so với MRR từ đăng ký mới, trong khi tỷ lệ tăng lịch sử thấp hơn mức này. Kết quả là cơ sở ARR từ API hiện tại tuy đáng kể nhưng vẫn thấp hơn một chút so với ARR từ đăng ký, và đang dần thu hẹp khoảng cách để đạt mức cân bằng theo thời gian.
Lý do chia tỷ lệ 50/50 bắt nguồn từ việc so sánh với các đối thủ. Trên các nền tảng mô hình đóng lớn, API của ChatGPT chiếm khoảng 25% doanh thu, trong khi đăng ký chiếm khoảng 75%, vì cơ sở người dùng đăng ký tiêu dùng khổng lồ khiến tỷ lệ API trở nên nhỏ. API của Anthropic chiếm khoảng 80%, đăng ký chiếm khoảng 20%, do cơ sở người dùng của họ thiên về nhà phát triển và doanh nghiệp. Venice có cấu trúc nằm giữa hai cực này: Định vị bảo mật của Venice không hấp dẫn người tiêu dùng phổ thông như ChatGPT, nhưng cơ sở người dùng trả phí lại rộng hơn cơ sở doanh nghiệp chuyên sâu của Anthropic. Việc chia tỷ lệ 50/50 nằm ở trung tâm của khoảng này.
Khoảng này được củng cố bởi hai bằng chứng đặc thù của Venice.
Thứ nhất, API của Venice đã thiết lập một lượng lớn kênh phân phối dành cho nhà phát triển. OpenRouter định tuyến mô hình của Venice, Fleek mặc định sử dụng Venice cho suy luận trên tất cả các proxy được lưu trữ, Cursor, Brave Leo (thông qua BYOM) và các tiện ích mở rộng cộng đồng VSCode đều hỗ trợ Venice. Những tích hợp này đã được tích lũy trong hơn một năm qua, củng cố luận điểm rằng API là một lĩnh vực kinh doanh thực tế và quan trọng, với lưu lượng sản xuất quy mô lớn.
Thứ hai, mức tăng lượng token xử lý hàng ngày vượt xa mức tăng chỉ có thể giải thích bằng tăng trưởng đăng ký. Lượng token xử lý hàng ngày tăng từ 20 tỷ vào đầu tháng Hai lên hơn 60 tỷ vào đầu tháng Năm — tăng gấp ba lần trong ba tháng. Trong cùng khoảng thời gian, cơ sở người dùng đăng ký trả phí tăng khoảng 50% (từ khoảng 100.000 lên khoảng 150.000). Việc mở rộng các gói Pro+/Max vào giữa tháng Tư chỉ khiến một bộ phận nhỏ người đăng ký mới chuyển sang các gói có ARPPU cao hơn; ngay cả khi giả định hào phóng về mức tiêu thụ token trên mỗi người dùng đối với các gói này, cũng không thể bù đắp khoảng chênh lệch này. Phần lớn mức tăng lượng token dường như đến từ khối lượng công việc API tính theo mức sử dụng: triển khai agent, đối tác tích hợp mở rộng lưu lượng sản xuất, và các tình huống sử dụng cường độ cao tương tự.
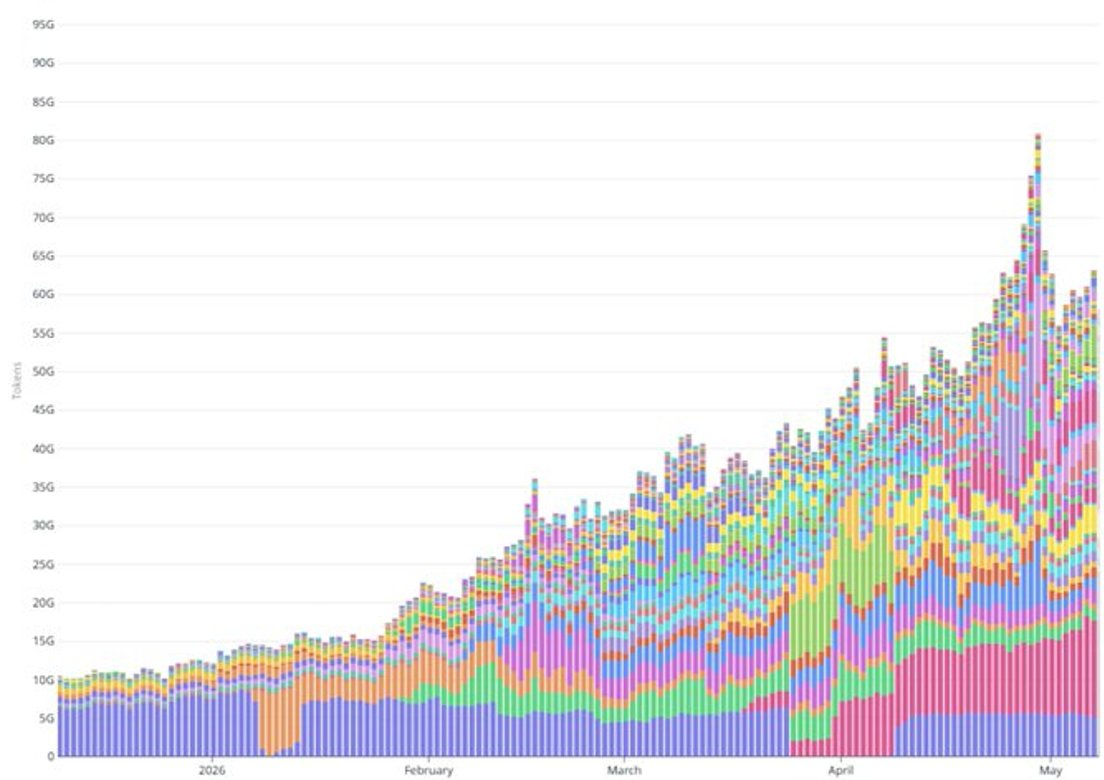
Việc ước tính ARR từ API hiện tại khó hơn so với đăng ký, vì tỷ lệ 1:1 dường như mới xuất hiện gần đây; trước giữa tháng Tư, tỷ lệ API có thể còn nhỏ hơn. Sử dụng giả định trung bình — tức là tỷ lệ API lịch sử trung bình khoảng 70–80% so với đăng ký, và mới đạt mức 1:1 gần đây — ARR từ API hiện tại ước tính khoảng 25–30 triệu USD. Tổng ARR hiện tại ước tính: khoảng 55–65 triệu USD, giá trị trung bình khoảng 60 triệu USD.
Phần API xứng đáng được giải thích ngắn gọn: Nó được tính toán dựa trên doanh thu vận hành theo mức sử dụng hiện tại được niên kim hóa, chứ không phải cam kết đăng ký định kỳ, do đó có độ biến động nội tại cao hơn phần đăng ký. Việc một khách hàng API lớn giảm mức sử dụng có thể khiến doanh thu vận hành từ API giảm mạnh, trong khi cơ sở đăng ký sẽ không bị mất tương tự.
So sánh chéo với doanh thu từ đầu năm đến nay: Dựa trên mức tăng lượng token xử lý hàng ngày từ 20 tỷ vào đầu tháng Hai lên hơn 60 tỷ vào đầu tháng Năm, Venice đã tạo ra ít nhất 30 triệu USD doanh thu tích lũy trong năm 2026. Con số này phù hợp với khoảng ước tính ARR hiện tại từ 55–65 triệu USD, cơ sở này đang tăng nhanh chóng lên tốc độ tăng niên kim 200 triệu USD.
Điều quan trọng cần lưu ý là tốc độ tăng niên kim không đồng nghĩa với doanh thu kiếm được trong 12 tháng tới. ARR mới tăng tuyến tính trong năm, do đó tốc độ tăng niên kim 200 triệu USD nếu duy trì trong suốt năm 2026 sẽ chuyển hóa thành khoảng 100 triệu USD doanh thu mới kiếm được trong năm, cộng thêm khoảng 60 triệu USD từ cơ sở ARR hiện tại. Tổng doanh thu kiếm được trong 12 tháng tới nên nằm trong khoảng 150–200 triệu USD, và ARR tại thời điểm kết thúc cửa sổ 12 tháng này sẽ đạt khoảng 260 triệu USD (trước khi trừ đi tỷ lệ hủy bỏ — tức là 60 triệu USD hiện tại cộng thêm 200 triệu USD ARR mới).
Nhìn lại quá khứ chủ yếu chỉ là một ghi chú phụ. Hiện tại, tốc độ tăng niên kim ARR của Venice khoảng 200 triệu USD, và câu hỏi thực sự là tốc độ hiện tại là đáy hay chỉ là điểm khởi đầu. Các biến số quan trọng: tăng trưởng đăng ký có duy trì không, mức sử dụng API có tiếp tục tăng nhanh hơn mở rộng đăng ký không, tỷ lệ hủy bỏ sẽ là bao nhiêu khi danh sách chờ trưởng thành, và thị trường có thể tiếp cận được có đủ lớn để hỗ trợ tốc độ tăng trưởng này trong dài hạn không.
Vấn đề quy mô thị trường dễ trả lời hơn sau khi bạn hiểu rõ Venice thực sự làm gì. Nền tảng rõ ràng nhất là một “bậc thang bảo mật” cho tương tác LLM, trong đó mỗi bậc đại diện cho một tập hợp giả định bảo mật khác nhau, và mô hình Venice được nhúng vào một bậc cụ thể.
Cấp độ bảo mật
Bậc thang dưới đây xếp hạng việc sử dụng AI dựa trên đám mây theo một trục hẹp nhưng quan trọng: Ai có thể liên kết prompt rõ ràng với danh tính người dùng? Nó không giải quyết được tất cả các vấn đề bảo mật. Việc xâm nhập thiết bị, dấu vết thanh toán, siêu dữ liệu tài khoản, rủi ro lệnh khám xét và an ninh đầu cuối vẫn là các vấn đề độc lập. Tuy nhiên, nó làm rõ điều gì thực sự thay đổi khi người dùng chuyển từ chatbot mặc định sang các chế độ bảo mật cao hơn của Venice. Các số hiệu bậc (0–7) do tôi đặt ra nhằm đặt Venice vào bối cảnh rộng hơn. Hệ thống phân loại của chính Venice chỉ sử dụng bốn chế độ có tên: Anonymous (Ẩn danh), Private (Riêng tư), TEE (Môi trường thực thi đáng tin cậy) và E2EE (Mã hóa đầu cuối), tương ứng với các Bậc 3, 4, 6 và 7 bên dưới.
Tùy chọn bảo mật mạnh nhất hoàn toàn không nằm trong bậc thang này. Chạy mô hình nguồn mở trên phần cứng bạn sở hữu, không có sự tham gia của đám mây, vượt trội hơn tất cả các tùy chọn phía sau. Chạy GLM 5.1 hoặc Qwen 3.6 trên một chiếc Mac hoặc trạm làm việc mạnh mẽ, không gọi mạng, không bên thứ ba can dự. Không gì sánh bằng “prompt không bao giờ rời khỏi máy của tôi”, miễn là máy tính đó được bảo mật hợp lý. Nhưng đây không phải là con đường đa số người dùng chọn. Phần cứng rất đắt. Các mô hình nguồn mở có thể chạy cục bộ vẫn thua kém các phòng thí nghiệm mô hình đóng tiên tiến nhất ở các nhiệm vụ khó nhất. Bạn sẽ đánh mất khả năng tích hợp và hoạt động 24/7 trên đám mây, đồng thời phải chịu trách nhiệm bảo trì toàn bộ ngăn xếp. Gác việc triển khai cục bộ sang một bên, bậc thang dưới đây bao quát các lựa chọn thực tế cho suy luận dựa trên đám mây.
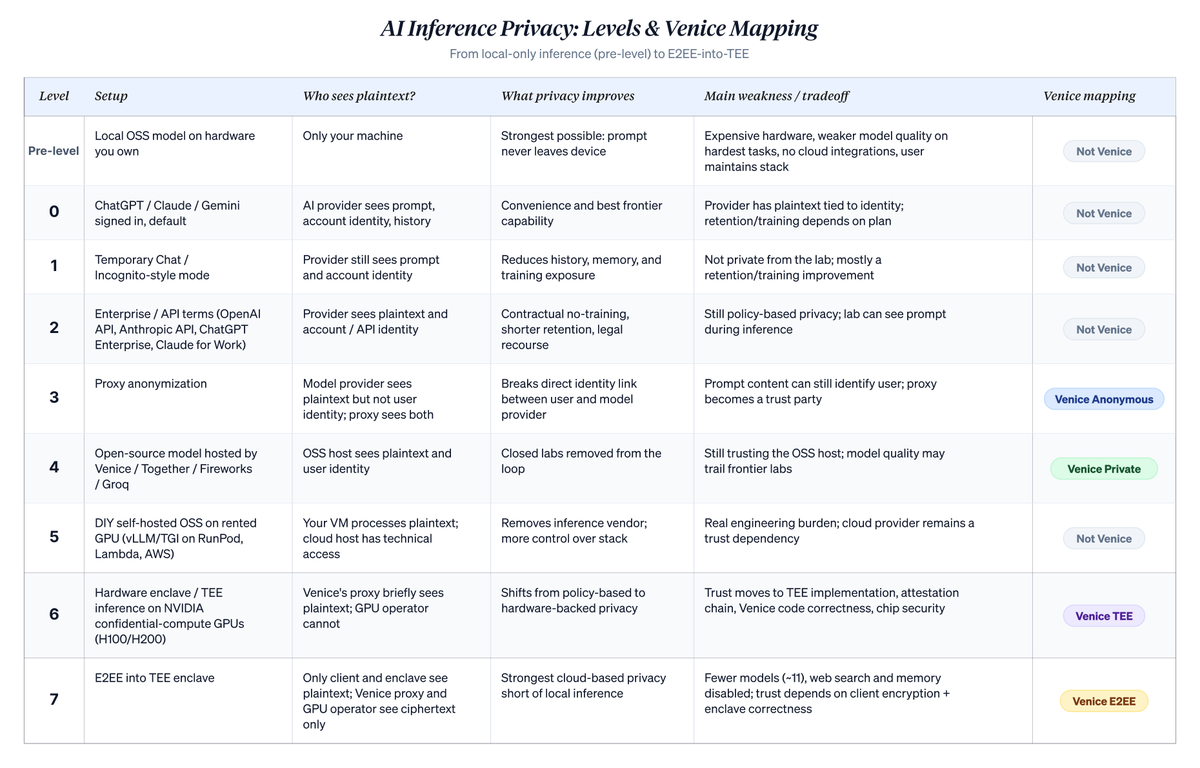
Phân tích chi tiết từng bậc như sau, kèm theo các ẩn dụ minh họa:
Bậc 0: “ChatGPT, Claude hoặc Gemini, đã đăng nhập, trạng thái mặc định.” Prompt của bạn được gửi đến phòng thí nghiệm gắn với tài khoản của bạn. Họ biết bạn là ai và bạn đã hỏi điều gì. Trong các gói tiêu dùng, trừ khi bạn chọn từ chối, cuộc trò chuyện có thể được sử dụng để cải thiện các mô hình trong tương lai và được lưu trữ trong lịch sử trò chuyện phía máy chủ của bạn. Ở đây có những cam kết thực tế (không bán dữ liệu, thời hạn lưu trữ, quyền xóa), nhưng bạn là người được nhận dạng, được lưu trữ, và trong gói tiêu dùng, có thể được đưa vào quy trình huấn luyện. Đa số mọi người ở bậc này. Về mặt kiến trúc, bất kỳ dịch vụ tiêu dùng API được lưu trữ nào cũng có tư thế giống nhau, bất kể nhà cung cấp ở đâu. Các chương trình lưu trữ của nhà cung cấp Trung Quốc (phiên bản DeepSeek lưu trữ, GLM/Zhipu, MiniMax, Qwen kết nối trực tiếp) ở cùng bậc kiến trúc: nhà cung cấp nhìn thấy prompt rõ ràng, danh tính được liên kết với tài khoản, và chính sách lưu trữ và huấn luyện phụ thuộc vào từng nhà cung cấp. Người dùng thường chọn các dịch vụ này vì giá cả, vì chúng thường rẻ hơn nhiều so với Anthropic hoặc OpenAI. Dữ liệu của bạn cuối cùng thuộc thẩm quyền quản lý của khu vực pháp lý nào, phụ thuộc vào nhà cung cấp cụ thể, điểm cuối bạn truy cập, khu vực và hợp đồng. Đừng chỉ vì mô hình rẻ hơn mà giả định bạn được xử lý dữ liệu theo tiêu chuẩn Mỹ hoặc EU.
Ẩn dụ: Bạn trực tiếp đến gặp một công ty lớn (nhà cung cấp AI) để tìm một cố vấn (mô hình). Họ đọc bản ghi nhớ của bạn, trả lời câu hỏi của bạn, rồi lưu một bản sao dưới tên bạn. Họ có thể sử dụng các bản ghi nhớ ẩn danh trước đây để huấn luyện các cố vấn khác hoặc cải thiện dịch vụ.
Bậc 1: “Trò chuyện tạm thời của ChatGPT / Trò chuyện ẩn danh của Claude.” Cùng nhà cung cấp, cùng danh tính, cùng prompt rõ ràng trên máy chủ của họ. Cuộc trò chuyện sẽ không xuất hiện trong lịch sử của bạn, mô hình sẽ không tiếp tục truyền tải nó, và theo chính sách, nó bị loại trừ khỏi quy trình huấn luyện. Rất hữu ích cho các cuộc trò chuyện nhạy cảm một lần mà bạn không muốn ảnh hưởng đến tài khoản. Nhà cung cấp vẫn biết bạn là ai và vẫn nhìn thấy toàn bộ prompt; điều họ không thể làm là lưu trữ lâu dài hoặc sử dụng cho huấn luyện. Bạn ẩn khỏi lịch sử của chính mình, nhưng không ẩn khỏi phòng thí nghiệm.
Ẩn dụ: Tương tác trực tiếp với cố vấn (mô hình) giống như vậy, nhưng bạn yêu cầu họ loại bản ghi nhớ cụ thể này ra khỏi hồ sơ chính của bạn. Họ đọc nó, trả lời, rồi đặt vào một ngăn kéo tạm thời (trò chuyện ẩn danh), sau một thời gian sẽ bị xóa. Họ vẫn biết bạn là ai và vẫn nhìn thấy nội dung bạn gửi.
Bậc 2: “API của Anthropic, Claude for Work, ChatGPT Enterprise, API của OpenAI.” Chuyển từ trò chuyện tiêu dùng sang điều khoản thương mại. Hợp đồng loại trừ dữ liệu của bạn khỏi quy trình huấn luyện. Thời hạn lưu trữ ngắn, thường khoảng 30 ngày để kiểm tra an ninh, đôi khi bằng không ở cấp độ doanh nghiệp. Nếu vi phạm chính sách, bạn có quyền truy cứu pháp lý. Phòng thí nghiệm vẫn nhìn thấy prompt rõ ràng trong quá trình suy luận và liên kết lưu lượng với khóa API của bạn, nhưng đảm bảo mạnh hơn và có thể thực thi trên hợp đồng. Đây là tư thế bảo mật thực tế mà đa số công ty sử dụng, là một nâng cấp thực sự so với trò chuyện tiêu dùng. Nhưng nó vẫn dựa trên chính sách, chứ không phải kiến trúc. Lý do tiếp tục leo bậc là có thật: thay đổi chính sách trong tương lai, tiết lộ bắt buộc, rò rỉ dữ liệu hoặc chính phòng thí nghiệm trở nên tệ hơn.
Ẩn dụ: Bạn ký hợp đồng với một công ty tư vấn (điều khoản doanh nghiệp/API), trong đó có các điều khoản về không sao chép, không chia sẻ giữa các khách hàng, thời hạn lưu trữ ngắn, và quyền truy cứu pháp lý nếu vi phạm. Tương tác trực tiếp với cố vấn (mô hình) giống như vậy, họ đọc bản ghi nhớ của bạn và biết nó đến từ bạn, chỉ có các quy tắc về những gì xảy ra sau bản ghi nhớ là nghiêm ngặt hơn.
Bậc 3: “Chế độ ẩn danh của Venice.” Một đại lý đứng giữa bạn và phòng thí nghiệm, loại bỏ danh tính của bạn trước khi chuyển tiếp. Phòng thí nghiệm nhìn thấy nội dung prompt rõ ràng, nhưng không biết bạn là ai. Họ chỉ thấy “yêu cầu từ Venice.” Đối với các prompt không nhận dạng bạn trong nội dung, điều này phá vỡ mối liên hệ giữa truy vấn của bạn và tên bạn, khiến việc xây dựng hồ sơ dài hạn của phòng thí nghiệm trở nên khó khăn hơn nhiều. Đối với các prompt thực sự nhận dạng bạn trong nội dung (công ty của bạn, giao dịch của bạn, tên bạn), điều này phần lớn chỉ là hình thức. Nội dung dù sao cũng sẽ tiết lộ bạn. Bạn còn thêm Venice như một bên đáng tin cậy. Tự làm điều này là không thực tế. Bạn sẽ là người dùng duy nhất của đại lý riêng, và việc ẩn danh một người dùng đơn lẻ không phải là ẩn danh.
Ẩn dụ: Dịch vụ chuyển phát nhanh (Venice) xử lý việc giao hàng. Dịch vụ chuyển phát nhanh loại tên bạn khỏi bản ghi nhớ trước khi giao cho cố vấn (mô hình). Cố vấn đọc nội dung nhưng không biết người gửi là ai; dịch vụ chuyển phát nhanh biết cả hai bên.
Bậc 4: “Các mô hình nguồn mở trên Together AI / Fireworks / Groq, hoặc chế độ riêng tư của Venice.” Chuyển sang mô hình nguồn mở, các phòng thí nghiệm đóng sẽ rút khỏi lưu lượng này. Họ không nằm trong vòng luẩn quẩn vì bạn không sử dụng mô hình của họ. Sự tin tưởng chuyển sang những người lưu trữ mô hình nguồn mở. Các nhà cung cấp khác nhau, các đảm bảo hợp đồng tương tự, thường có văn hóa chú trọng bảo mật hơn (đặc biệt là chế độ riêng tư của Venice). Bạn hy sinh một số khả năng, dù khoảng cách đã thu hẹp. GLM 5.1, Qwen 3.6, Minimax M2.7 và DeepSeek V4 hoạt động tốt trong mã hóa, viết và phân tích hàng ngày. Việc chúng có đạt mức độ hàng đầu của các mô hình đóng hay không phần lớn phụ thuộc vào tiêu chuẩn đánh giá; các phòng thí nghiệm đóng vẫn thường thắng trong các tác vụ dài ngữ cảnh, đa phương thức và quy trình làm việc agent phức tạp. Bạn cũng giảm rủi ro tập trung và có ít bên đáng tin cậy hơn. Điều này có thực sự riêng tư hơn Bậc 3 không? Điều này phụ thuộc vào điều bạn quan tâm. Bậc 3 ẩn danh bạn khỏi các phòng thí nghiệm tiên tiến; Bậc 4 tiết lộ danh tính bạn cho các bên nhỏ hơn, nhưng cắt đứt hoàn toàn phòng thí nghiệm. Các ưu tiên khác nhau, thứ tự xếp hạng khác nhau. Điều này chỉ có ích cho lưu lượng bạn thực sự định tuyến qua nguồn mở. Việc sử dụng hỗn hợp nghĩa là phòng thí nghiệm vẫn nhìn thấy bất kỳ nội dung nào bạn gửi cho họ. Bên trong Bậc 4, các nhà cung cấp cũng khác nhau về vị trí GPU thực hiện công việc: Together, Fireworks và chế độ riêng tư của Venice chỉ định trung tâm dữ liệu của họ, trong khi các bộ tổng hợp như OpenRouter định tuyến đến nhà cung cấp nền tảng rẻ nhất, có thể bao gồm các nhà cung cấp hoạt động tại các khu vực pháp lý bạn không chọn. Đối với người dùng quan tâm đến điều này (tránh định tuyến các cuộc gọi API đến một số quốc gia nhất định), tùy chọn chỉ định máy chủ khác biệt về bản chất so với việc định tuyến đến bộ tổng hợp rẻ nhất, điều này còn thêm một bước tin cậy.
Ẩn dụ: Bạn trực tiếp mang bản ghi nhớ đến một công ty tư vấn khác (nhà lưu trữ mô hình nguồn mở, như Together AI, Fireworks hoặc chế độ riêng tư của Venice). Công ty cũ không nhìn thấy gì, vì bạn đã ngừng sử dụng họ. Cố vấn mới (mô hình khác) đọc bản ghi nhớ của bạn và biết nó đến từ bạn, cấu trúc tương tác trực tiếp giống như trước, chỉ khác công ty.
Bậc 5: “Tự làm: vLLM trên RunPod / Lambda Labs / AWS.” Bỏ qua hoàn toàn lớp suy luận như một dịch vụ. Thuê GPU thô, tự cài đặt vLLM hoặc TGI, tải trọng lượng, phơi bày điểm cuối riêng của bạn. Không có nhà cung cấp suy luận nào nhìn thấy lưu lượng của bạn, chỉ có phần cứng của nhà cung cấp đám mây nơi máy ảo của bạn chạy. Nếu có động lực hoặc bị yêu cầu, nhà cung cấp đám mây về mặt kỹ thuật có thể kiểm tra máy ảo của bạn. Tuy nhiên, họ có tư thế tuân thủ, bảo vệ hợp đồng và kiểm toán tốt hơn các nhà cung cấp suy luận nhỏ. Sự đánh đổi là: bạn chuyển từ chính sách của nhà cung cấp nhỏ sang chính sách của nhà cung cấp đám mây siêu quy mô, đổi lấy công việc kỹ thuật và vận hành thực tế.
Ẩn dụ: Bạn thuê một cố vấn riêng (mô hình của bạn, tự lưu trữ), người làm việc riêng cho bạn trong một văn phòng riêng (máy ảo bạn thuê từ nhà cung cấp đám mây như RunPod, Lambda Labs hoặc AWS). Không có công ty tư vấn nào ở giữa, chỉ có bạn và cố vấn bạn tự tuyển. Chủ tòa nhà (nhà cung cấp đám mây) có thể truy cập kỹ thuật nếu có động lực, nhưng thường có tư thế tuân thủ mạnh hơn các công ty nhỏ ở các bậc trước.
Bậc 6: “Chế độ TEE của Venice.” Ở đây, đảm bảo bảo mật thay đổi bản chất. Cả TEE và E2EE đều khả dụng cho bất kỳ người đăng ký Pro trả phí nào; việc lựa chọn giữa chúng là theo từng yêu cầu chứ không theo gói. Đối với suy luận TEE, Venice định tuyến đến các máy chủ GPU chạy công nghệ tính toán bí mật từ NEAR AI Cloud và Phala Network, trên phần cứng NVIDIA H100 và H200. NEAR và Phala cung cấp giao thức và công cụ; chính GPU được vận hành bởi các nhà cung cấp bên thứ ba sử dụng công nghệ này. Chức năng tính toán bí mật trên GPU ngăn chặn nhà vận hành đọc nội dung bên trong vùng an toàn (enclave) trong lúc chạy. Chứng minh từ xa cho phép máy khách của bạn xác thực mã đang chạy bên trong enclave một cách mã hóa trước khi gửi bất kỳ nội dung nào, do đó câu hỏi “đây thực sự là mã do Venice phát hành?” đã được giải quyết. Điều chưa được giải quyết là kiểm toán chính thức của bên thứ ba về tính đúng đắn của mã này. Nhà vận hành GPU không còn là bên có thể quan sát. Đại lý Venice vẫn nhìn thấy prompt rõ ràng trong chốc lát, nhưng chủ sở hữu GPU thì không. Sự thay đổi ở đây là từ chính sách sang phần cứng. Sự tin tưởng không biến mất; nó thay đổi mục tiêu. Hiện tại bạn tin tưởng vào thiết kế tính toán bí mật của NVIDIA, chuỗi chữ ký chứng minh và cách triển khai của Venice. Điều này rất vững chắc trước các mối đe dọa thực tế, dù không phải là bất khả xâm phạm: Các thiết kế TEE (Intel SGX, AMD SEV) đã nhiều lần phát hiện lỗ hổng kênh bên, và thiết kế hiện tại không miễn nhiễm. Đối với người dùng theo dõi sát nghiên cứu về các lỗ hổng này, Bậc 4 (chế độ riêng tư của Venice trên trung tâm dữ liệu của nhà vận hành đáng tin cậy) có thể là điểm dừng hợp lý hơn Bậc 6, vì tin tưởng vào vệ sinh vận hành của Venice có thể thoải mái hơn tin tưởng vào chuỗi chứng minh của nhà cung cấp chip. Private Cloud Compute của Apple thuộc cùng loạt kiến trúc: suy luận riêng tư trên đám mây riêng với hỗ trợ phần cứng và khả năng xác minh. Nhưng sự khác biệt với Venice là có thật. Apple sử dụng Apple Silicon do họ kiểm soát, chỉ chạy Apple Intelligence trên đó, không phơi bày lựa chọn mô hình. Venice sử dụng các đối tác TEE bên ngoài, hỗ trợ mô hình nguồn mở, và cho phép người dùng chọn cấp độ bảo mật theo từng yêu cầu.
Ẩn dụ: Dịch vụ chuyển phát nhanh (Venice) gửi bản ghi nhớ của bạn đến cố vấn (mô hình) làm việc trong một căn phòng kín cách âm (vùng an toàn/hardware enclave trên GPU tính toán bí mật của NVIDIA, do các đối tác của Venice là NEAR AI Cloud và Phala Network vận hành). Dịch vụ chuyển phát nhanh đọc bản ghi nhớ trên đường đi, nhưng cố vấn bên trong không thể bị quan sát bởi bất kỳ ai, kể cả chủ tòa nhà (nhà vận hành GPU). Phòng được làm sạch sau mỗi phiên hội thoại.
Bậc 7: “Chế độ E2EE của Venice.” TEE cộng với mã hóa phía máy khách. Thiết lập mã hóa xảy ra trực tiếp giữa máy khách của bạn và vùng an toàn trên silicon. Đại lý Venice ở giữa chưa bao giờ nắm giữ khóa, do đó bất kỳ nội dung nào đi qua nó đều là văn bản mã hóa từ máy bạn gửi đi, cho đến khi được xử lý trong vùng an toàn. Cả nhà vận hành GPU và chính Venice đều bị loại khỏi nhóm có thể quan sát; duy nhất mô hình đang chạy bên trong vùng an toàn xử lý văn bản rõ, và chỉ trong chốc lát. Đây là mức bảo mật riêng tư mạnh nhất khả dụng trên phần cứng của người khác, chỉ sau mã hóa đồng nhất hoàn toàn (hiện chưa khả thi với tốc độ chấp nhận được cho LLM). Tất cả các sự phụ thuộc tin tưởng ở Bậc 6 đều được kế thừa, cộng thêm một sự phụ thuộc mới: bản thân mã hóa phía máy khách cần được triển khai đúng. Hai sự đánh đổi chức năng đặc trưng ở cấp độ này. Các chức năng cần đại lý Venice đọc văn bản rõ, như tìm kiếm mạng và bộ nhớ bền vững, bị vô hiệu hóa. Lựa chọn mô hình cũng thu hẹp: hiện tại có đúng mười một mô hình được triển khai bên trong cơ sở hạ tầng TEE/E2EE: Venice Uncensored 1.2, GLM 5.1, GLM 4.7, GLM 4.7 Flash, Qwen3.5 122B A10B, Qwen 2.5 7B, Qwen3 30B A3B, Qwen3 VL 30B A3B, Gemma 3 27B, GPT OSS 20B và GPT OSS 120B.
Ẩn dụ: Mọi thứ ở Bậc 6 vẫn áp dụng: cố vấn (mô hình) làm việc trong một căn phòng kín cách âm, không ai bên ngoài có thể quan sát, phòng được làm sạch sau mỗi phiên hội thoại. Thêm vào đó là việc bạn tự bỏ bản ghi nhớ vào một chiếc hộp khóa (mã hóa phía máy khách) trước khi giao cho dịch vụ chuyển phát nhanh (vẫn là Venice). Dịch vụ chuyển phát nhanh giờ đây mang một chiếc hộp mờ đục, không thể nhìn thấy bên trong, do đó duy nhất cố vấn trong căn phòng kín mới có thể nhìn thấy tin nhắn của bạn.
Điểm mấu chốt: Bậc 0–2 chủ yếu là nâng cấp chính sách và hợp đồng. Bậc 3–4 thay đổi định tuyến và sự phơi bày mô hình/nhà cung cấp. Bậc 6–7 thay đổi mô hình tin tưởng một cách căn bản hơn thông qua chuyển sang tính toán hỗ trợ phần cứng và mã hóa suy luận. Sự khác biệt của Venice nằm ở việc nó bao quát Bậc 3, 4, 6 và 7 trong một sản phẩm duy nhất.
Cấp độ phù hợp cho bất kỳ người dùng nào đến từ mô hình đe dọa của họ. Việc chọn cấp độ nào trông ấn tượng nhất về mặt kỹ thuật là không nắm bắt được trọng tâm. Bậc 6 và 7 hy sinh một số khả năng tiên tiến và thêm các sự phụ thuộc tin tưởng mới. Ngay cả với những chi phí này, đây vẫn là nâng cấp bảo mật có ý nghĩa nhất hiện có trên suy luận đám mây.
Đây là cách kiến trúc hoạt động. Câu hỏi khó hơn là ai thực sự cần cấp độ nào, và quy mô đối tượng đó là bao nhiêu. Các mô hình đe dọa khác nhau sẽ đẩy người dùng khác nhau đến các phần khác nhau của bậc thang, thường là do bị ép buộc chứ không phải do sở thích, do đó thị trường hình thành lớn hơn nhiều so với những gì tuyên bố kỹ thuật gợi ý. Dưới đây là phân tích chi tiết.
Phân loại người dùng
Tư thế bảo mật không phải là một sở thích trừu tượng. Một bộ phận đáng kể người dùng Venice đến đây sau khi bị các chính sách nội dung, đội ngũ tuân thủ, mô hình đe dọa hoặc nguyên tắc đạo đức đẩy ra khỏi các lựa chọn mặc định. Khi người dùng chủ động tìm kiếm một giải pháp thay thế mà họ không thể tiếp tục sử dụng, công việc tiếp thị sẽ dễ dàng hơn nhiều. Sáu phân khúc cần làm rõ:
Công việc được điều chỉnh và thúc đẩy bởi tuân thủ. Các đội tài chính xử lý thông tin không công khai quan trọng, nhân viên y tế chịu ràng buộc HIPAA, luật sư xử lý giao tiếp đặc quyền, chuyên gia trong các quy trình sáp nhập và mua bán. Đội ngũ tuân thủ thường không cho phép Bậc 0. Nhiều người dường như dừng lại ở Bậc 2, vì các điều khoản doanh nghiệp của Anthropic và OpenAI (không huấn luyện, thời hạn lưu trữ ngắn, quyền truy cứu pháp lý trong hợp đồng) có thể đáp ứng các ngưỡng tuân thủ phổ biến. Một bộ phận tiến lên Bậc 6, thường là vì họ đã từng bị thay đổi chính sách ở nơi khác gây hại, hoặc vì dữ liệu họ xử lý nếu bị tiết lộ bắt buộc sẽ gây ra tổn thất thực tế. Anthropic dường như đã xây dựng một doanh nghiệp doanh nghiệp đáng kể trên phân khúc này, và xu hướng quy định trong lĩnh vực y tế và tài chính luôn hướng tới các yêu cầu tính toán bảo mật riêng tư nghiêm ngặt hơn. Hiện tại, điểm phù hợp rõ ràng nhất của Venice ở đây dường như là các chuyên gia độc lập mua gói Pro vì sự thận trọng cá nhân, chứ không phải các hành động mua sắm doanh nghiệp. Thị trường doanh nghiệp do mua sắm điều khiển không chỉ nhìn vào kiến trúc bảo mật. Đội ngũ tuân thủ cần các kiểm soát quản lý, nhật ký kiểm toán, báo cáo SOC2, DPA đã ký, SLA thực tế và hỗ trợ tích hợp trước khi ký. Câu chuyện mã hóa rất quan trọng nhưng chưa đủ. Thị trường doanh nghiệp do mua sắm điều khiển đang bị Apple PCC, Microsoft Azure Confidential Computing cũng như Phala hoặc NEAR cạnh tranh trực tiếp.
Nhà phát triển xây dựng trên API của Venice. API của Venice đã thu hút sự chú ý trong các tích hợp dành cho nhà phát triển như OpenRouter, Cursor, VSCode, Brave Leo và Fleek. Trường hợp sử dụng rõ ràng nhất ở đây là các nhà phát triển tích hợp các tính năng AI tôn trọng quyền riêng tư vào sản phẩm của họ, nhằm đảm bảo với người dùng cuối rằng “dữ liệu của bạn luôn được bảo mật”. Việc ánh xạ cấp độ có thể khác nhau tùy theo nội dung mà nhà phát triển xây dựng: các tính năng tiêu dùng nhạy cảm về chi phí sử dụng chế độ ẩn danh (Bậc 3), định tuyến OSS mặc định sử dụng chế độ riêng tư (Bậc 4), các sản phẩm chuyên biệt lấy bảo mật kiến trúc làm điểm bán hàng sử dụng TEE hoặc E2EE (Bậc 6–7). Một nhà phát triển sử dụng API của Venice có thể phục vụ nhiều người dùng cuối mà không cần mỗi người đều mua đăng ký Venice, điều này khiến hiệu quả kinh tế trên một đơn vị có thể khác biệt lớn so với đăng ký tiêu dùng trực tiếp.
Sử dụng cá nhân có rủi ro cao. Người dùng có thể không muốn các truy vấn về sức khỏe tâm thần và trị liệu lưu lại trong lịch sử tài khoản. Việc khám phá bản sắc liên quan đến xu hướng tính dục hoặc giới tính, người dùng có thể chưa sẵn sàng tiết lộ. Các cuộc thảo luận về hôn nhân, ly dị, việc làm hoặc động lực gia đình, những truy vấn này bản thân chúng nếu bị tiết lộ có thể gây tổn hại. Nhiều người dùng trong số này có thể dừng lại ở Bậc 1, cho rằng trò chuyện ẩn danh có thể che giấu họ. Một tập con có ý thức về bảo mật thường chuyển sang Bậc 6 sau khi hiểu rằng điều này không thể hoàn toàn ẩn họ khỏi phòng thí nghiệm. Sức khỏe tâm thần AI dường như là một danh mục đang tăng trưởng, dù quy mô và chất lượng của các sản phẩm lâm sàng và tiêu dùng khác nhau. Từ góc độ Venice, khó ước tính quy mô vì nhiều người dùng trong phân khúc này có thể không biết cần tìm kiếm bảo mật được xác thực phần cứng cho đến khi điều gì đó khó chịu xảy ra với họ hoặc người quen của họ.
Môi trường đối kháng. Nhà báo bảo vệ nguồn tin, nhà hoạt động ở các khu vực pháp lý giám sát việc sử dụng AI, nhà bất đồng chính kiến và nhà tổ chức chính trị, nhà nghiên cứu an ninh điều tra các hành vi đe dọa, luật sư đại diện cho người tố giác. Những người dùng này thường cần Bậc 6 và 7. Các cấp độ thấp hơn có thể không tồn tại được trong mô hình đe dọa của họ. Hãy xem Proton: ngay cả với danh tiếng ưu tiên bảo mật và vị trí pháp lý tại Thụy Sĩ, nó thường tuân thủ hầu hết các yêu cầu pháp lý nhận được, thường là do luật Thụy Sĩ yêu cầu như vậy. Đây là mô hình thất bại có thể xảy ra khi mở rộng bảo mật dựa trên chính sách. Kiến trúc TEE và E2EE của Venice thuộc loại thiết lập đám mây mà nhà cung cấp không được thiết kế để giữ văn bản rõ — chính là văn bản rõ cần thiết để tuân thủ các yêu cầu bắt buộc như vậy. Nhưng kiến trúc chỉ có thể đưa bạn đi xa đến mức nào là có hạn. Bậc 6 và 7 giảm thiểu việc phơi bày văn bản rõ, nhưng chúng không thể sửa chữa toàn bộ bức tranh. Siêu dữ liệu tài khoản, dấu vết thanh toán, thông tin sử dụng được Venice ghi lại, máy tính xách tay của bạn đang làm gì, và tòa án có thể ép bạn tiết lộ điều gì — tất cả những điều này vẫn nằm ở người dùng. Đối với những người có mô hình đe dọa thực sự đối kháng, đây chỉ là một công cụ trong bộ công cụ rộng hơn. Về mặt số liệu, phân khúc này rất nhỏ. Ý chí chi trả cho các công cụ có thể tồn tại dưới lệnh khám xét thường rất cao.
Người dùng natively-encrypted và văn hóa bảo mật. Nhà phát triển Web3, chuyên gia công nghệ coi trọng chủ quyền, chạy nút riêng và coi trọng các đảm bảo được xác thực phần cứng về nguyên tắc. Phân khúc này có thể bao quát từ Bậc 3 đến 7, tùy theo mô hình đe dọa cá nhân, và tập con có nguyên tắc thường mặc định sử dụng Bậc 6 hoặc 7 cho các truy vấn nhạy cảm. AI x crypto đã trở thành một danh mục có ý nghĩa trong hệ sinh thái mã hóa rộng hơn, với các bên cơ sở hạ tầng như Bittensor đã xây dựng vị thế quan trọng. Các cuộc khảo sát ngành thường báo cáo mức độ quan tâm đến tự lưu trữ cao hơn ở các thị trường mới nổi, nơi giám sát thanh toán tập trung là một mối lo ngại. Tư thế của Venice phù hợp với phân khúc này theo cách các đối thủ phòng thí nghiệm đóng không thể bắt kịp: định giá bằng VVV, không KYC, danh tiếng của Erik Voorhees, và việc cung cấp lịch sử cấp độ Pro miễn phí cho người nắm giữ VVV và MOR đã góp phần nuôi dưỡng nhóm này. Có thể đây là nền tảng văn hóa tự nhiên và một phần quan trọng trong số những người dùng trả phí đầu tiên của Venice.
Nội dung dành cho người lớn và các danh mục khác bị các phòng thí nghiệm đóng từ chối trực tiếp. OpenAI, Anthropic và Google thường từ chối nội dung NSFW (không phù hợp cho nơi làm việc). Các danh mục khác gặp trở ngại ở Bậc 0, chẳng hạn như sáng tác văn học trưởng thành, các vấn đề giảm thiểu tác hại liên quan đến ma túy, và một danh sách dài các chủ đề bị kỳ thị nhưng hợp pháp, được xử lý khác nhau bởi các nhà cung cấp khác nhau, đôi khi có sự khoan dung. Người dùng trong các danh mục này thường không thể bắt đầu từ Bậc 0; mô hình thường từ chối. Chỉ riêng lựa chọn mô hình thường đã đẩy họ lên Bậc 4 đến 7, vì đó thường là nơi các biến thể nguồn mở không kiểm duyệt có sẵn. Phần lớn người dùng trả phí có thể dừng lại ở Bậc 4 trong sử dụng hàng ngày, trong khi tập con nhạy cảm với bảo mật đẩy lên Bậc 6 hoặc 7. Danh mục này trông có vẻ lớn: Character.AI và Replika đều đang vận hành ở quy mô tiêu dùng có ý nghĩa, và các ứng dụng bạn đồng hành AI đã phát triển thành một phân khúc đáng kể trong AI tiêu dùng. Những người dùng này có thể quan tâm đến bảo mật hơn người dùng chatbot thông thường vì chi phí bị tiết lộ: việc lộ hồ sơ sở thích có thể phá hủy hôn nhân, công việc hoặc vụ giành quyền giám hộ. Có thể đây là đối tượng lớn nhất hiện tại của Venice tính theo mức sử dụng.
Một điểm nổi bật trong các nhóm này là rất ít người trong số họ dường như ở đỉnh phễu. Đa số dường như bị định hình bởi các chính sách nội dung, đội ngũ tuân thủ, mô hình đe dọa hoặc nguyên tắc đạo đức, buộc hoặc đẩy họ ra khỏi con đường dễ dàng. AI ưu tiên bảo mật thường không phải là danh mục mà mọi người xuất hiện ngay từ đầu; họ thường đến sau khi phát hiện mình không thể ở lại nơi cũ. Cùng logic này có thể giải thích hai phân khúc liền kề đáng ghi nhận nhưng không ước tính quy mô: người dùng quốc tế ở các khu vực pháp lý có thể đẩy họ ra khỏi thanh toán tập trung và giám sát AI, cũng như nhóm người dùng cá nhân sớm sử dụng AI agent, dữ liệu điều phối của họ có thể hưởng lợi từ một nền tảng hậu端 tôn trọng bảo mật.
Quy mô thị trường
Giới hạn cuối cùng của Venice phụ thuộc vào quy mô thị trường có thể tiếp cận được, chứ không phải hiệu suất hiện tại. Khung đúng là phần chia sẻ suy luận: Venice bán dịch vụ suy luận AI, thị trường liên quan là chi tiêu toàn cầu cho suy luận, và doanh thu của Venice là một phần của bể này.
Các ước tính độc lập về thị trường suy luận năm 2027 trên toàn cầu đang hội tụ ở mức 140–160 tỷ USD, các dự báo từ Bain, IDC và McKinsey đều nằm trong khoảng này. Ngay cả khi tính theo tốc độ chạy năm 2027 dự kiến của Venice (dự đoán của tôi, được triển khai trong phần định giá) là 400 triệu USD, Venice cũng chỉ chiếm chưa đến 0,3% bể này, một thị phần không đáng kể theo bất kỳ định nghĩa thị trường hợp lý nào. Để làm rõ, chỉ riêng doanh nghiệp API của OpenAI đã chiếm ước tính một vài phần trăm chi tiêu suy luận hiện tại, và API của Anthropic cũng ở khoảng tương tự. Vị trí hiện tại của Venice còn xa hơn cả thị phần mà các nền tảng suy luận quy mô trung bình chiếm giữ.
Nhưng Venice không tranh giành toàn bộ bể. Venice nhắm vào phân khúc bảo mật: người dùng và doanh nghiệp cần tính ẩn danh, bảo mật được xác thực phần cứng, khả năng truy cập không kiểm duyệt hoặc lựa chọn quyền tài phán trong quá trình suy luận. Phân khúc con này khó tính toán quy mô chính xác hơn, nhưng tín hiệu định hướng rất mạnh.
Một số lực lượng đang mở rộng phân khúc bảo mật của suy luận: quy định ngày càng nghiêm ngặt về lưu trú dữ liệu ở châu Âu và một số khu vực châu Á, ma sát tuân thủ ngày càng tăng giữa doanh nghiệp và các sản phẩm phòng thí nghiệm đóng mặc định, và sự trưởng thành của cơ sở hạ tầng bảo mật dựa trên TEE. Các cuộc khảo sát doanh nghiệp liên tục ghi nhận mối lo ngại ngày càng tăng về việc lộ dữ liệu do AI gây ra. Các lực lượng này riêng lẻ đều không nhanh, nhưng chúng chồng chất lên nhau.
Ngay cả khi phân khúc suy luận đám mây bảo mật chỉ chiếm 5–15% thị trường suy luận năm 2027 trị giá 140–160 tỷ USD, đó cũng là một thị trường phân khúc trị giá 7–23 tỷ USD. Một thị phần ở mức một vài phần trăm đơn vị cũng đủ để Venice đạt doanh thu hàng trăm triệu USD, cao hơn nhiều so với tốc độ hiện tại và vẫn còn dư địa tăng trưởng lớn. Một thị phần ở mức một vài phần trăm trung bình có thể đưa Venice vào phạm vi hàng tỷ USD.
Các kịch bản bi quan có ba chiều kích. Thứ nhất, thị trường suy luận đám mây bảo mật không đạt quy mô có ý nghĩa, vì các nhà cung cấp đám mây siêu quy mô cung cấp đủ tùy chọn bảo mật trong nền tảng hiện có của họ. Apple PCC, Azure Confidential Computing và AWS Bedrock Confidential Inference đều đang phát triển theo hướng này. Trong trường hợp này, bảo mật vẫn quan trọng, nhưng nó được đóng gói vào các nền tảng đám mây và tiêu dùng hiện có, thị trường bảo mật ưu tiên độc lập sẽ không bao giờ lớn đủ để hỗ trợ quy mô của một người chơi độc lập.
Thứ hai, suy luận cục bộ trở nên khả thi đối với người dùng phổ thông. Chất lượng mô hình nguồn mở hiện đã đủ mạnh cho hầu hết các tải công việc hàng ngày. Điểm nghẽn là ma sát thiết lập và kỹ năng kỹ thuật cần thiết để chạy mô hình cục bộ. Khi điểm nghẽn này được giảm bớt thông qua các giải pháp “mở hộp và sử dụng ngay” tinh tế hơn, các trình cài đặt đơn giản hơn và các tích hợp xử lý gánh nặng vận hành, một phần đáng kể người dùng coi trọng bảo mật có thể chọn chạy suy luận cục bộ thay vì trả phí cho bất kỳ dịch vụ đám mây nào. Điều này hoàn toàn loại họ khỏi thị trường có thể tiếp cận của Venice. Thời điểm lo ngại này phụ thuộc vào tốc độ trưởng thành của ngăn xếp cục bộ thân thiện với người tiêu dùng.
Thứ ba, ngay cả khi thị trường bảo mật đạt quy mô có ý nghĩa, Venice vẫn cần giành thị phần trước các đối thủ natively-privacy khác như Brave Leo, DuckDuckGo, Lumo của Proton, Maple và Tinfoil, mỗi bên đều nhắm vào các phần khác nhau của gói Venice từ các góc độ khác nhau. Phần cảnh quan cạnh tranh thảo luận về việc so sánh tổ hợp độ sâu bảo mật, khả năng truy cập không kiểm duyệt và phân phối natively-encrypted của Venice với các mối đe dọa cụ thể này.
Cảnh quan cạnh tranh
Tập hợp đối thủ cạnh tranh của Venice rộng hơn “các ứng dụng AI riêng tư khác”. Các nền tảng khác nhau cạnh tranh cùng nhu cầu: người tiêu dùng coi trọng bảo mật, nhà phát triển muốn lựa chọn mô hình, người tìm kiếm nội dung không kiểm duyệt và người mua natively-encrypted. Phần dưới đây bao quát năm danh mục.
Cảnh quan này là một tập hợp các sản phẩm thay thế một phần, kéo Venice theo các hướng khác nhau. Brave và DuckDuckGo cạnh tranh về phân phối. OpenRouter cạnh tranh về API dành cho nhà phát triển. Tinfoil, NEAR, Phala và Maple cạnh tranh về chính kiến trúc bảo mật. Các phòng thí nghiệm tiên tiến tiếp cận từ phía doanh nghiệp, nhúng đủ bảo mật vào các mô hình tốt hơn. Hiện tại, không sản phẩm nào trong số này đóng gói đầy đủ gói Venice: AI tiêu dùng mặc định riêng tư, khả năng truy cập không kiểm duyệt, lựa chọn đa mô hình, thanh toán natively-encrypted và kinh tế học sử dụng được mã hóa.
Cần phân biệt các cấp độ bảo mật, từ yếu nhất đến mạnh nhất:
Không huấn luyện: Nhà cung cấp cam kết không sử dụng dữ liệu của bạn để huấn luyện (điều khoản tiêu chuẩn của Anthropic và OpenAI API)
Lưu trữ hạn chế hoặc bằng không: Nhà cung cấp lưu trữ prompt ngắn hạn để giám sát lạm dụng, hoặc cung cấp cấu hình ZDR (Zero Data Retention – Không lưu trữ dữ liệu), trong đó prompt và nội dung phản hồi không được lưu trữ sau xử lý (OpenAI ZDR, OpenRouter ZDR)
Đại lý ẩn danh: Nhà cung cấp nhìn thấy prompt nhưng không thấy danh tính (Venice Anonymous, Brave Leo, DuckDuckGo AI Chat)
TEE/Xác thực phần cứng: Prompt được chạy trong vùng an toàn mà người vận hành không thể đọc (Venice TEE, Tinfoil, NEAR Private Chat, Apple PCC)
E2EE vào TEE: Nhà cung cấp chỉ nhìn thấy văn bản mã hóa (Venice E2EE, Maple AI)
Cục bộ: Mô hình chạy trên phần cứng của bạn (Ollama, LM Studio)
Venice là một trong số ít sản phẩm tiêu dùng vượt qua các chế độ đại lý ẩn danh, trò chuyện riêng tư, TEE và E2EE trong một trải nghiệm người dùng duy nhất, với khả năng lựa chọn chế độ theo từng yêu cầu.
Các nền tảng AI mặc định (OpenAI, Anthropic, Google, xAI)
Các phòng thí nghiệm tiên tiến đã cung cấp bảo mật thực sự cho khách hàng doanh nghiệp. OpenAI mặc định không sử dụng dữ liệu API hoặc thương mại để huấn luyện, và cung cấp cấu hình ZDR cho khách hàng đủ điều kiện. Anthropic không sử dụng đầu vào hoặc đầu ra sản phẩm thương mại để huấn luyện. Google Vertex AI cung cấp giới hạn huấn luyện cấp doanh nghiệp. xAI cũng quảng bá các điều khiển bảo mật người dùng, mặc dù tư thế của họ nên được tách biệt với các cam kết doanh nghiệp trưởng thành hơn của OpenAI, Anthropic và Google. Khoảng cách giữa Venice và các phòng thí nghiệm về bảo mật doanh nghiệp và API nhỏ hơn nhiều so với nhiều người giả định; khoảng cách về tính ẩn danh tiêu dùng vẫn còn rất lớn. ChatGPT, Claude và Gemini tiêu dùng đều mặc định liên kết danh tính với prompt và lưu trữ lịch sử trò chuyện phía máy chủ, các chính sách về việc sử dụng cho huấn luyện thay đổi tùy theo sản phẩm và cài đặt người dùng.
Venice theo đuổi những điều các phòng thí nghiệm tiên tiến sẽ không làm: truy cập ẩn danh, mô hình không kiểm duyệt và thanh toán natively-encrypted. Thị trường này nhỏ hơn AI phổ thông, nhưng là thị trường thực tế. Các phòng thí nghiệm tiên tiến phục vụ đa số người dùng phổ thông. Venice phục vụ phần người dùng muốn thoát khỏi các lựa chọn mặc định.
Theo từng phân khúc:
Trò chuyện tiêu dùng: Venice có tính ẩn danh, nội dung ít giáo điều hơn và thanh toán mã hóa. Các phòng thí nghiệm vẫn thắng về khả năng và thương hiệu.
Người tiêu dùng chuyên nghiệp: Venice cung cấp lựa chọn mô hình và ít bị khóa hơn. Các phòng thí nghiệm thắng về tích hợp mã hóa, bộ nhớ và công cụ.
Doanh nghiệp: Venice hiện không có câu chuyện nào về SOC2, DPA, kiểm soát quản trị và nhật ký kiểm toán. Các phòng thí nghiệm và nhà cung cấp đám mây siêu quy mô nắm giữ thị trường này.
API: Venice có độ sâu bảo mật và khả năng truy cập không kiểm duyệt. Các phòng thí nghiệm có chất lượng mô hình và hệ sinh thái.
Mặt phân phối natively-privacy (Brave, DuckDuckGo)
Brave là chiến lược phân phối tiêu dùng mạnh nhất trong lĩnh vực bảo mật. Brave báo cáo có hơn 115 triệu người dùng hoạt động hàng tháng và 47 triệu người dùng hoạt động hàng ngày tính đến tháng Tư 2026, với mức giá Leo Premium là 14,99 USD/tháng cộng với cấp độ miễn phí. Leo là tùy chọn tài khoản, lưu trữ lịch sử cục bộ, và theo chính sách được tuyên bố của Brave, prompt không được lưu trữ trên máy chủ Brave. Brave cũng bắt đầu chuyển từ bảo mật đại lý sang bảo mật có thể xác minh thông qua TEE được hỗ trợ NVIDIA từ NEAR AI, điều này củng cố rằng bảo mật AI được hỗ trợ phần cứng đang trở thành một tính năng sản phẩm chủ lưu.
DuckDuckGo AI Chat có tư thế tương tự: miễn phí, không tài khoản, đại lý ẩn danh đến một tập hợp các mô hình bên thứ ba luân phiên, từ OpenAI, Anthropic, Meta, v.v. DuckDuckGo nói rằng cuộc trò chuyện sẽ không được lưu trữ hoặc sử dụng để huấn luyện. Duck.ai hiện cũng có cấp độ trả phí, cung cấp các mô hình tiên tiến hơn.
Lumo của Proton là người chơi có ý nghĩa thứ ba trong lĩnh vực này. Lumo ra mắt vào tháng Bảy 2025 và mở rộng vào tháng Một 2026 thông qua không gian làm việc mã hóa dựa trên dự án, cung cấp trợ lý AI mã hóa không truy cập, không nhật ký phía máy chủ và không sử dụng dữ liệu người dùng để huấn luyện. Lumo vận hành tại trụ sở châu Âu của Proton, nằm ngoài thẩm quyền Mỹ, hướng đến cơ sở người dùng hiện có của Proton vốn coi trọng bảo mật, bao gồm email, VPN và dịch vụ lưu trữ đám mây. So với Venice, Lumo có lựa chọn mô hình hẹp hơn, không có phòng thí nghiệm đóng tiên tiến, không có nội dung không kiểm duyệt và không có phân phối natively-encrypted. Tuy nhiên, thương hiệu Proton đã được thiết lập trong nhóm người dùng coi trọng bảo mật, trong khi thương hiệu Venice vẫn cần được công nhận bên ngoài phân khúc hiện tại.
Brave, DuckDuckGo và Lumo nguy hiểm vì chúng rút ngắn đường chuyển đổi. Chúng không cần thuyết phục người dùng tìm kiếm AI riêng tư. Chúng tiếp cận người dùng coi trọng bảo mật trực tiếp trong trình duyệt, quy trình tìm kiếm hoặc hệ sinh thái email/VPN mà người dùng đã sử dụng. Đối với người dùng phổ thông, mức bảo mật mà chúng cung cấp cộng với thương hiệu quen thuộc có thể đã đủ. Venice phân biệt hóa theo các chiều khác nhau tùy theo đối thủ cạnh tranh: khi cạnh tranh với Brave và DuckDuckGo, ngăn xếp bảo mật của Venice sâu hơn nhiều so với đại lý, và thư viện mô hình rộng hơn; khi cạnh tranh với Lumo, yếu tố phân biệt là khả năng truy cập các phòng thí nghiệm đóng tiên tiến, nội dung không kiểm duyệt và kinh tế học natively-encrypted thông qua chế độ Anonymous, chứ không phải độ sâu bảo mật bản thân.
Định tuyến và tổng hợp API (OpenRouter, Together AI, Fireworks, Replicate)
OpenRouter đã trở thành lớp định tuyến mặc định của nhiều nhà phát triển. Họ đã huy động 40 triệu USD trong vòng hạt giống và vòng A từ a16z, Menlo và Sequoia Capital vào năm 2025, với định giá khoảng 550 triệu USD, và báo cáo đang đàm phán vòng tài trợ 120 triệu USD do CapitalG dẫn đầu vào tháng Tư 2026, với định giá 1,3 tỷ USD, dựa trên ARR khoảng 50 triệu USD và hơn 150.000 nhà phát triển hoạt động hàng tháng. Sản phẩm có giao diện đúng, điều khiển ZDR toàn cầu và theo từng yêu cầu, cùng với thị phần tâm trí nhà phát triển từ các đội phát triển đã tích hợp. OpenRouter cũng phân phối các mô hình của Venice, bao gồm Venice Uncensored, khiến nó vừa là đối thủ cạnh tranh vừa là kênh phân phối cho hoạt động API của Venice.
Sự phân biệt hóa API của Venice hẹp hơn nhưng rõ ràng hơn: bao bì ưu tiên bảo mật, mô hình không kiểm duyệt natively-Venice, quy trình thanh toán natively-encrypted và liên kết trực tiếp với kinh tế học VVV và DIEM. Together AI, Fireworks và Replicate cạnh tranh trên các chiều khác nhau: cung cấp suy luận OSS rẻ cho nhà phát triển không đặc biệt quan tâm đến bảo mật. Chúng là các đối thủ liền kề chứ không phải đối thủ trực tiếp.
Đường đi của API Venice nghiêng về bảo mật và khả năng truy cập không kiểm duyệt. Việc đầu tư liên tục vào tính linh hoạt định tuyến và trải nghiệm nhà phát triển sẽ quyết định Venice có thể giành được bao nhiêu thị phần API so với tốc độ tăng trưởng kinh doanh đăng ký tiêu dùng.
Cơ sở hạ tầng suy luận bí mật (Tinfoil, NEAR AI Cloud, Phala Network, Maple)
Hiện nay có một số sản phẩm chồng lấn một phần kiến trúc của Venice. Tinfoil cung cấp suy luận được xác thực TEE trên GPU tính toán bí mật, với API tương thích OpenAI, nhắm vào các trường hợp sử dụng nhà phát triển và cơ sở hạ tầng. NEAR AI Cloud hỗ trợ chế độ TEE của Venice, đồng thời ra mắt NEAR Private Chat như một sản phẩm tiêu dùng riêng. Phala Network hỗ trợ cơ sở hạ tầng E2EE của Venice và định tuyến bí mật của OpenRouter. Maple hướng đến người tiêu dùng và coi trọng bảo mật, cung cấp trò chuyện E2EE trong vùng cách ly an toàn.
Venice đang có ý thức xây dựng trên các đối tác chuyên về tính toán bí mật, đồng thời sở hữu lớp ứng dụng, mối quan hệ người dùng, thương hiệu, thanh toán và đóng gói mô hình. Bảo mật theo hợp đồng đang trở thành yêu cầu cơ bản; bảo mật có thể xác minh đang trở thành biên giới tiếp theo. Sự khác biệt của Venice không nằm ở việc không ai khác có TEE hoặc E2EE. Mà nằm ở việc Venice đóng gói nhiều chế độ bảo mật, nội dung không kiểm duyệt, truy cập mô hình, thanh toán mã hóa và sử dụng được mã hóa vào một sản phẩm tiêu dùng và API duy nhất.
AI cục bộ và cấp hệ điều hành (Ollama, LM Studio, Apple Private Cloud Compute)
AI cục bộ là một đối thủ tiềm năng thực sự. Ollama và LM Studio đã phục vụ tốt người dùng kỹ thuật, và nhóm đối tượng này tiếp tục mở rộng cùng với sự gia tốc của phần cứng tiêu dùng. Chất lượng mô hình nguồn mở hiện đã đủ mạnh cho hầu hết các tải công việc hàng ngày. Điều khiến người dùng phổ thông tiếp tục sử dụng dịch vụ đám mây ngày nay là ma sát thiết lập và gánh nặng vận hành khi chạy mô hình cục bộ. Khi khoảng cách này được thu hẹp thông qua các giải pháp “mở hộp và sử dụng ngay” tinh tế hơn, các trình cài đặt đơn giản hơn và các tích hợp xử lý gánh nặng vận hành, tỷ lệ người dùng coi trọng bảo mật chọn chạy cục bộ thay vì bất kỳ dịch vụ đám mây nào sẽ tăng lên. Thời điểm không chắc chắn, nhưng có thể nhanh hơn so với khung dài hạn điển hình.
Apple Private Cloud Compute có liên quan về mặt chiến lược. PCC chạy Apple Intelligence trên Apple Silicon, với bảo mật được hỗ trợ phần cứng, làm cho AI riêng tư trở thành kỳ vọng bình thường như một tính năng nền tảng. PCC bị khóa vào Apple Intelligence trên thiết bị Apple, do đó sẽ không cạnh tranh trực tiếp với Venice
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News









