

“Thuế tiếng Trung” của các mô hình AI lớn: Vì sao tiếng Trung tốn nhiều token hơn tiếng Anh?
Tuyển chọn TechFlowTuyển chọn TechFlow
“Thuế tiếng Trung” của các mô hình AI lớn: Vì sao tiếng Trung tốn nhiều token hơn tiếng Anh?
Khi các kỹ sư làm phẳng những góc cạnh của ngôn ngữ để đổi lấy hiệu suất, những tri thức vô tình mọc lên trong những khe nứt ấy cũng dần biến mất một cách lặng lẽ.
Phiên bản Opus 4.7 vừa ra mắt, mạng xã hội X ngập tràn những lời phàn nàn. Có người cho biết chỉ một cuộc trò chuyện đã tiêu hết toàn bộ hạn mức session của họ; có người nói chi phí chạy cùng một đoạn mã đã tăng hơn gấp đôi so với tuần trước; lại có người đăng ảnh chụp màn hình cho thấy gói đăng ký Max 200 USD của mình đã chạm trần trong chưa đầy hai giờ.
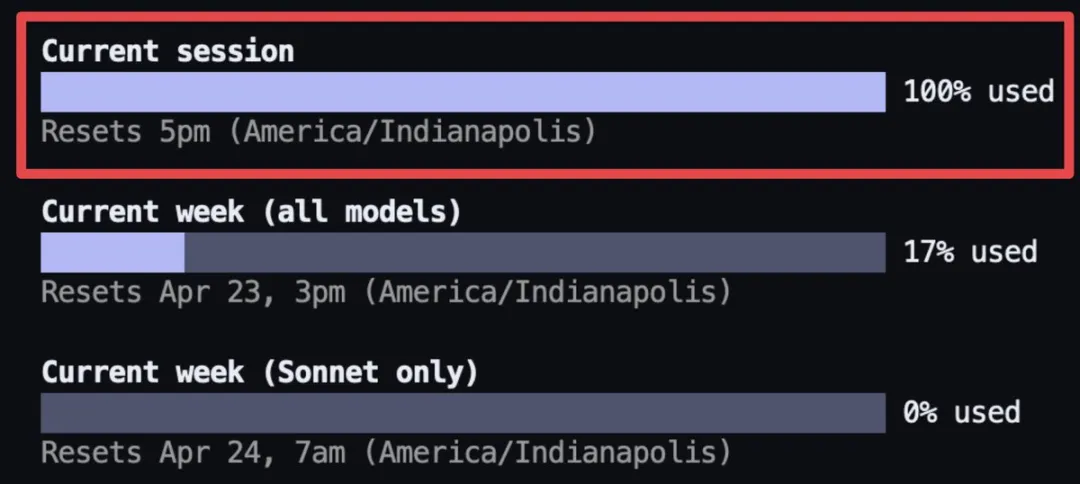
Nhà phát triển độc lập BridgeMind thừa nhận Claude là mô hình tốt nhất thế giới, nhưng đồng thời cũng là mô hình đắt nhất. Gói đăng ký Max của anh ấy đã đạt giới hạn trong chưa đầy hai giờ, nhưng may thay—anh ấy đã mua hai bản.|Nguồn ảnh: X@bridgemindai
Giá chính thức do Anthropic công bố không thay đổi: mỗi triệu token đầu vào vẫn là 5 USD, mỗi triệu token đầu ra là 25 USD. Tuy nhiên, phiên bản này giới thiệu một bộ tách từ (tokenizer) mới, đồng thời Claude Code nâng mức độ nỗ lực mặc định từ “high” lên “xhigh”. Hai thay đổi này cộng dồn khiến số token tiêu thụ cho cùng một tác vụ tăng lên 2–2,7 lần so với trước đây.
Trong các thảo luận này, tôi bắt gặp hai nhận định liên quan đến tiếng Trung. Một là: tiếng Trung gần như không bị ảnh hưởng bởi bộ tokenizer mới, nghĩa là người dùng tiếng Trung đã “né” được đợt tăng giá lần này. Nhận định thứ hai thú vị hơn: văn ngôn (cổ văn) còn tiết kiệm token hơn cả tiếng Hán hiện đại—nói chuyện với AI bằng văn ngôn giúp giảm chi phí.
Nhận định đầu tiên hàm ý rằng Claude đã thực hiện một số tối ưu hóa đặc biệt cho tiếng Trung, nhưng trong tài liệu phát hành chính thức của Anthropic, hoàn toàn không đề cập bất kỳ điều chỉnh nào liên quan đến tiếng Trung.
Còn nhận định thứ hai lại càng khó giải thích hơn. Đối với người đọc, văn ngôn rõ ràng khó hiểu hơn tiếng Hán hiện đại; vậy thì tại sao một văn bản càng phức tạp đối với con người lại lại dễ xử lý hơn đối với AI?
Vì vậy, tôi tiến hành một thử nghiệm: sử dụng 22 đoạn văn bản song ngữ (bao gồm tin tức kinh doanh, tài liệu kỹ thuật, văn ngôn, hội thoại thường ngày…), đồng thời đưa vào năm bộ tokenizer khác nhau (Claude 4.6 và 4.7, GPT-4o, Qwen 3.6, DeepSeek-V3), rồi ghi lại số token mà mỗi đoạn văn bản tiêu thụ trên từng mô hình để so sánh ngang hàng.

Các văn bản thử nghiệm:
1. Hội thoại thường ngày (tiếng Anh & tiếng Trung): du lịch, hỏi trợ giúp trên diễn đàn, yêu cầu viết văn bản
2. Tài liệu kỹ thuật (tiếng Anh & tiếng Trung): tài liệu Python, tài liệu của Anthropic
3. Tin tức (tiếng Anh & tiếng Trung): tin chính trị và kinh doanh của NYT, thông cáo báo chí chính thức của Apple
4. Đoạn trích văn học (tiếng Anh & tiếng Trung, cổ văn Hán): “Xuất sư biểu”, “Đạo đức kinh”
Sau khi thử nghiệm xong, cả hai nhận định trên đều được xác nhận một phần, nhưng sự thật lại phức tạp hơn những đồn đoán.
Thuế tiếng Trung
Trước tiên, kết luận:
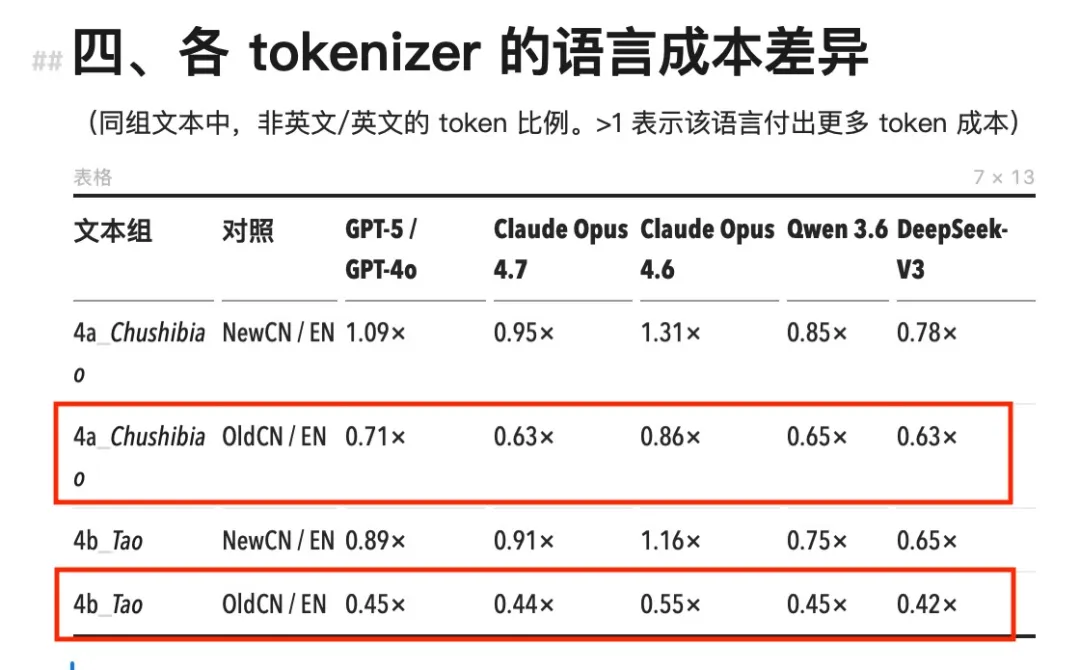
1. Trên Claude và GPT, tiếng Trung luôn đắt hơn tiếng Anh
2. Trên Qwen và DeepSeek, tiếng Trung thậm chí còn rẻ hơn tiếng Anh
3. Đợt nâng cấp tokenizer gây chấn động lần này ở Opus 4.7 chủ yếu làm lạm phát token đối với tiếng Anh, trong khi tiếng Trung hầu như không thay đổi
Xem xét cụ thể các con số. Toàn bộ dòng mô hình Claude trước Opus 4.7 (bao gồm Opus 4.6, Sonnet và Haiku) đều sử dụng chung một bộ tokenizer. Với bộ tokenizer này, lượng token tiêu thụ cho tiếng Trung luôn cao hơn đáng kể so với nội dung tiếng Anh tương đương, tỷ lệ tiếng Trung/tiếng Anh dao động trong khoảng 1,11×–1,64×.
Tình huống cực đoan nhất xuất hiện trong các bản tin kinh doanh theo phong cách NYT: cùng một nội dung, bản tiếng Trung tiêu tốn nhiều hơn 64% token, tương đương phải trả thêm 64% chi phí.
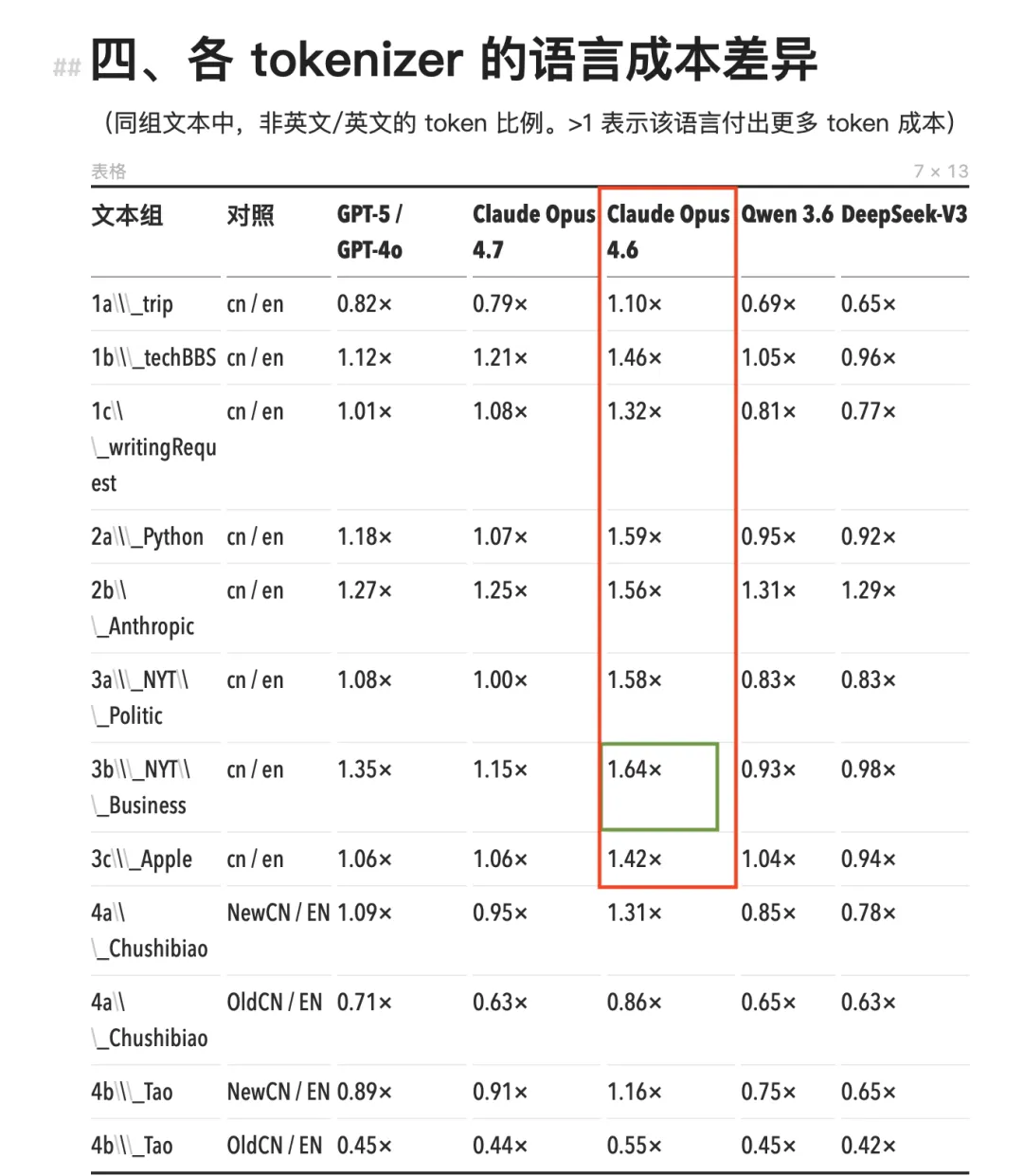
Các mô hình Claude Opus 4.6 và các phiên bản trước đó tiêu thụ token tiếng Trung cao hơn rõ rệt so với các mô hình khác (khung đỏ)
Tình huống cực đoan nhất xuất hiện trong bản tin kinh doanh theo phong cách NYT: bản tiếng Trung tiêu thụ nhiều hơn 64% token so với bản tiếng Anh (khung xanh lá)
Bộ tokenizer o200k của GPT-4o tốt hơn một chút, tỷ lệ tiếng Trung/tiếng Anh đa số nằm trong khoảng 1,0–1,35×, một số trường hợp còn dưới 1. Tiếng Trung vẫn đắt hơn về mặt tổng thể, nhưng chênh lệch nhỏ hơn nhiều so với Claude.
Dữ liệu từ các mô hình nội địa Qwen 3.6 và DeepSeek-V3 lại hoàn toàn ngược lại. Tỷ lệ tiếng Trung/tiếng Anh của cả hai mô hình đều rộng rãi dưới 1, nghĩa là với cùng một nội dung, bản tiếng Trung lại tiết kiệm token hơn bản tiếng Anh. DeepSeek đạt mức thấp nhất là 0,65×, tức bản tiếng Trung rẻ hơn bản tiếng Anh tới một phần ba.
Bộ tokenizer mới của Opus 4.7 gần như chỉ gây lạm phát đối với tiếng Anh. Số token tiếng Anh tăng 1,24×–1,63×, trong khi tiếng Trung phần lớn giữ nguyên ở mức 1,000×, gần như không thay đổi. Những cú “giật mình” về hóa đơn của các lập trình viên tiếng Anh ở đầu bài thực tế không hề ảnh hưởng đến người dùng tiếng Trung. Nguyên nhân có thể là tiếng Trung trên phiên bản cũ đã được cắt ở mức độ từng ký tự, nên khả năng chia nhỏ thêm là cực kỳ hạn chế.
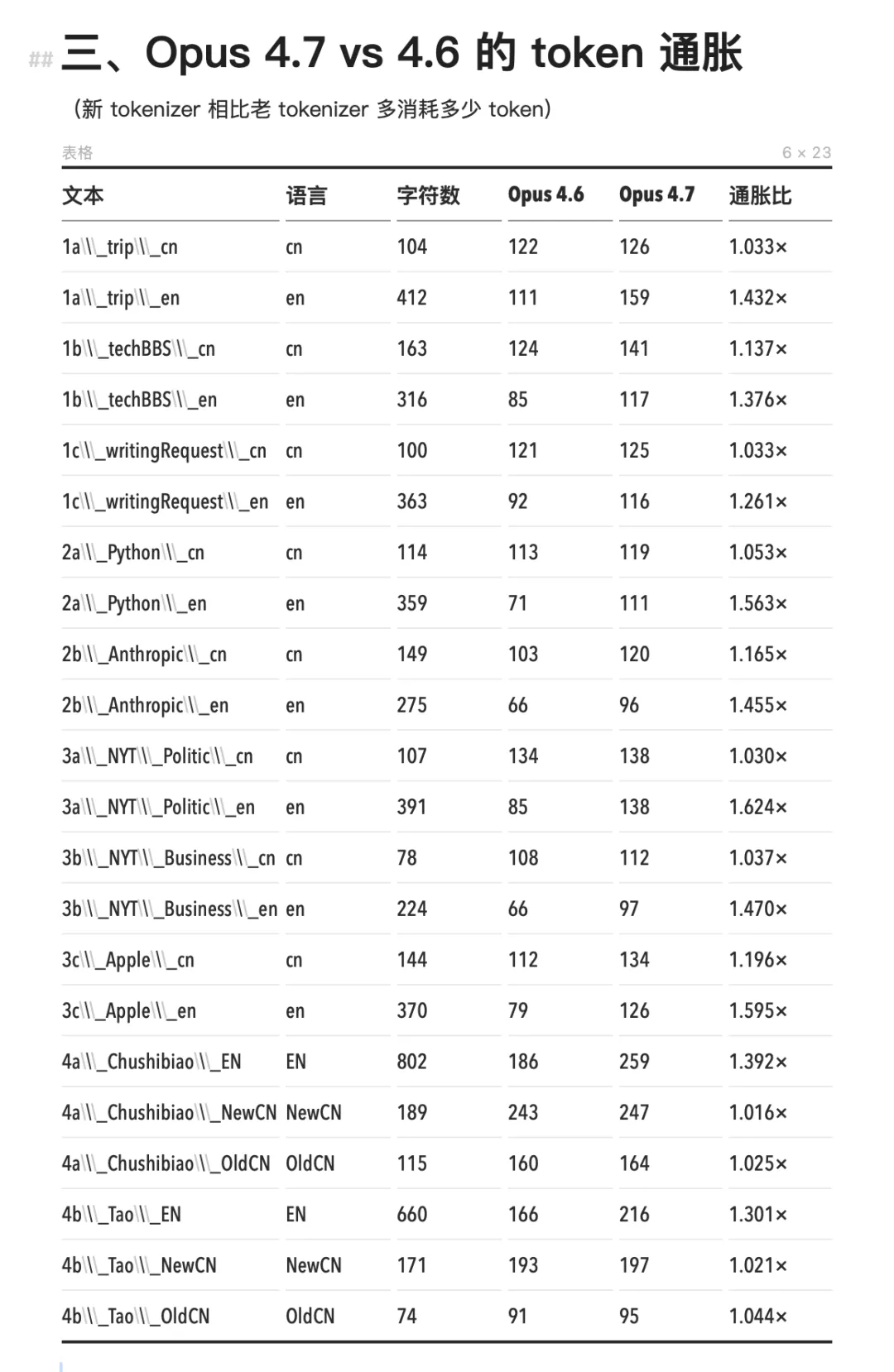
So sánh Opus 4.7 với 4.6: tiếng Anh tiêu thụ nhiều token hơn, tiếng Trung lại không thay đổi
Trong quá trình thử nghiệm, tôi còn để ý thấy một điều: sự chênh lệch về tiêu thụ token không chỉ là vấn đề hóa đơn, mà còn trực tiếp ảnh hưởng đến kích thước không gian làm việc. Cùng một cửa sổ ngữ cảnh khoảng 200K, nếu dùng bộ tokenizer cũ của Claude để nạp tài liệu tiếng Trung, lượng nội dung có thể chứa sẽ ít hơn 40–70% so với tiếng Anh.
Đối với cùng một loại công việc—ví dụ như yêu cầu AI phân tích một tài liệu dài hoặc tóm tắt loạt biên bản họp—người dùng tiếng Trung có thể cung cấp cho mô hình ít dữ liệu hơn, và mô hình cũng có ít ngữ cảnh để tham chiếu hơn. Kết quả là họ phải trả nhiều tiền hơn, nhưng lại nhận được không gian làm việc nhỏ hơn.
Khi đặt bốn nhóm dữ liệu này cạnh nhau, một câu hỏi tự nhiên nổi lên:
Tại sao cùng một nội dung, khi chuyển sang ngôn ngữ khác, số token lại khác nhau? Vì sao tiếng Trung lại đắt trên Claude và GPT, trong khi lại rẻ hơn trên Qwen và DeepSeek?
Câu trả lời nằm ở khái niệm “tokenizer” (bộ tách từ)—một thuật ngữ đã được nhắc đến nhiều lần ở trên.
Một chữ Hán có thể bị cắt thành mấy mảnh?
Trước khi mô hình đọc bất kỳ văn bản nào, nó sẽ sử dụng tokenizer để chia đầu vào thành từng token riêng lẻ. Bạn có thể hình dung tokenizer như một “máy cắt khối xây dựng” dành riêng cho AI. Bạn nhập vào một câu, và nó chịu trách nhiệm cắt câu đó thành từng khối chuẩn hóa (tức là các token). Mô hình AI không đọc chữ, mà chỉ nhận diện mã số của các khối. Bạn dùng bao nhiêu khối, thì bạn trả bấy nhiêu tiền.
Cách cắt tiếng Anh khá phù hợp với trực giác: ví dụ “intelligence” thường là một token, “information” cũng thường là một token—mỗi từ ứng với một đơn vị tính phí.

Nhưng đến tiếng Trung thì vấn đề bắt đầu xuất hiện. Cùng một câu “Nhân công trí năng đang tái cấu trúc cơ sở hạ tầng thông tin toàn cầu”, khi đưa vào bộ tokenizer cl100k của GPT-4 và bộ tokenizer của Qwen 2.5, kết quả cắt ra hoàn toàn khác nhau.
GPT-4 gần như cắt từng chữ Hán thành một token riêng; còn Qwen lại nhận diện từ vựng thành một token, ví dụ cụm “nhân công trí năng” gồm bốn chữ Hán chỉ tính là một token trên Qwen.
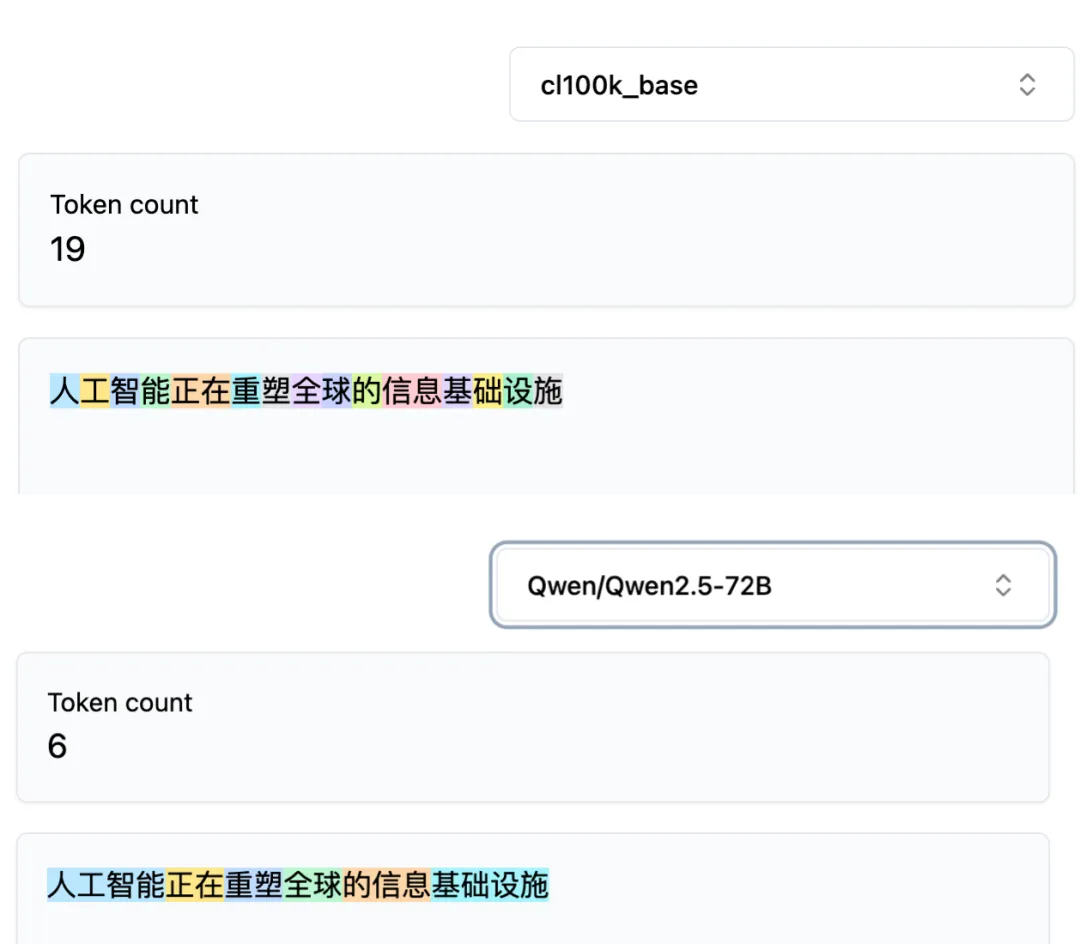
Cùng một câu gồm 16 chữ Hán, GPT-4 cắt ra 19 token, trong khi Qwen chỉ cắt ra 6 token.
Tại sao lại cắt như vậy? Nguyên nhân nằm ở một thuật toán tên là BPE (Byte Pair Encoding).
Cách hoạt động của BPE là thống kê trong kho dữ liệu huấn luyện xem tổ hợp ký tự nào xuất hiện với tần suất cao nhất, sau đó gộp tổ hợp đó thành một token và đưa vào bảng từ vựng.
Thời kỳ GPT-2, phần lớn dữ liệu huấn luyện là tiếng Anh. Các tổ hợp chữ cái tiếng Anh (th, ing, tion…) xuất hiện lặp đi lặp lại, nên nhanh chóng được gộp thành token. Còn các ký tự tiếng Trung xuất hiện quá hiếm trong kho dữ liệu đó, không đủ xếp vào bảng từ vựng, nên chỉ được xử lý như các byte gốc—mỗi chữ Hán chiếm ba byte, do đó biến thành ba token.

BPE quyết định gộp dựa trên tần suất xuất hiện ký tự trong dữ liệu huấn luyện. Khi dữ liệu chủ đạo là tiếng Anh, các byte UTF-8 của tiếng Trung không thể gộp thành chữ Hán hoàn chỉnh
Sau này, bảng từ vựng cl100k của GPT-4 được mở rộng, các chữ Hán thông dụng bắt đầu được đưa vào, mỗi chữ thường được rút gọn xuống còn 1–2 token, nhưng hiệu quả tổng thể vẫn không bằng tiếng Anh.
Đến bảng từ vựng o200k của GPT-4o, hiệu quả tiếng Trung lại tiến thêm một bước nữa. Điều này cũng giải thích vì sao trong dữ liệu ở đoạn đầu, tỷ lệ tiếng Trung/tiếng Anh của GPT-4o thấp hơn Claude.
Qwen và DeepSeek là các mô hình nội địa, ngay từ đầu đã đưa một lượng lớn chữ Hán thông dụng và tổ hợp từ vựng thường gặp vào bảng từ vựng dưới dạng từng chữ hoặc từng từ hoàn chỉnh. Mỗi chữ một token, hiệu quả tăng gấp đôi hoặc hơn.

Sơ đồ minh họa kết quả cắt cùng một câu trên các bộ tokenizer khác nhau
Đây chính là lý do vì sao tỷ lệ tiếng Trung/tiếng Anh của chúng có thể dưới 1: mật độ thông tin trung bình của mỗi chữ Hán vốn đã cao hơn từ tiếng Anh, và khi tokenizer không còn cố tình cắt nát chữ Hán, lợi thế tự nhiên này liền lộ rõ.
Vì vậy, sự khác biệt giữa bốn nhóm dữ liệu ở phần trước không bắt nguồn từ năng lực mô hình, mà từ việc bảng từ vựng của tokenizer dành bao nhiêu “vị trí” cho tiếng Trung.
Bảng từ vựng của Claude và các phiên bản GPT sơ khai được xây dựng dựa trên tiếng Anh như giá trị mặc định, tiếng Trung là thứ được “đẩy vào sau”; còn bảng từ vựng của Qwen và DeepSeek từ lúc thiết kế đã coi tiếng Trung là ngôn ngữ mặc định. Sự khác biệt khởi đầu này truyền dẫn thẳng đến số token, hóa đơn và kích thước cửa sổ ngữ cảnh.
Văn ngôn thực sự rẻ hơn sao?
Tiếp tục xem xét nhận định thứ hai ở đầu bài: văn ngôn rẻ hơn tiếng Hán hiện đại.
Dữ liệu xác nhận nhận định này. Trong thử nghiệm, tỷ lệ tiếng Trung/tiếng Anh của mẫu văn ngôn đều dưới 1 trên cả năm bộ tokenizer. Bản văn ngôn của cùng một nội dung tiêu thụ ít token hơn cả bản dịch tiếng Anh tương ứng.
Trên mọi mô hình, văn ngôn tiêu thụ ít token hơn cả tiếng Hán hiện đại và thậm chí còn ít hơn tiếng Anh
Nguyên nhân cũng không phức tạp: văn ngôn cực kỳ súc tích. Câu “Học nhi bất tư tắc võng, tư nhi bất học tắc đãi” chỉ gồm 12 chữ. Dịch ra tiếng Hán hiện đại là “Chỉ học mà không suy nghĩ thì sẽ mê muội, chỉ suy nghĩ mà không học thì sẽ rơi vào bế tắc”—số chữ tăng gấp đôi, số token tất nhiên cũng tăng theo.
Hơn nữa, các chữ thường dùng trong văn ngôn (chi, dã, giả, nhi, bất…) đều là ký tự có tần suất cao, nên trong bảng từ vựng của bất kỳ tokenizer nào cũng đều có vị trí riêng, không bị cắt thành các byte. Vì vậy, văn ngôn thực sự hiệu quả ở cấp độ mã hóa.
Nhưng ở đây ẩn chứa một cái bẫy.
Văn ngôn tiết kiệm token ở phía mã hóa, nhưng gánh nặng suy luận của mô hình lại không giảm. Chỉ một chữ “võng”, mô hình phải xác định trong ngữ cảnh này nó mang nghĩa “mê muội”, “bị che lấp” hay “không có”. Tiếng Hán hiện đại có thể dùng 26 chữ để làm rõ ý này, còn văn ngôn lại nén phần đã được làm rõ ấy trở lại, để lại phần suy luận cho mô hình đảm nhiệm. Nói một cách hình tượng, một tập tin nén dưới dạng zip có kích thước nhỏ hơn, nhưng việc giải nén lại đòi hỏi nhiều phép tính hơn.
Token thì tiết kiệm được, nhưng chi phí suy luận lại tăng lên, độ chính xác hiểu cũng giảm xuống. Như vậy, khoản chi này thực tế không hợp lý.
Ví dụ về văn ngôn khiến tôi nhận ra rằng số token bản thân nó không nói lên được nhiều điều. Nhưng nếu tiếp tục suy luận theo hướng này, còn có một lớp vấn đề mà tôi trước đây đã bỏ qua.
Như đã nói ở trên, tokenizer thời kỳ GPT-2 chia chữ “nhân” thành ba byte UTF-8, sau đó bảng từ vựng của GPT-4 được mở rộng khiến các chữ Hán thông dụng trở thành một chữ một token, còn Qwen tiến xa hơn nữa khi gộp cả cụm “nhân công trí năng” thành một token.
Trực quan cho rằng đây là một quá trình cải tiến liên tục: gộp càng nhiều, hiệu quả càng cao, và mô hình cũng hiểu càng tốt.
Nhưng thực sự có phải như vậy không? Hãy thử hồi tưởng lại cách chúng ta học chữ Hán.
Chữ Hán là hệ chữ biểu ý, hơn 80% chữ Hán hiện đại là chữ hình thanh, được tạo thành từ một bộ thủ biểu thị nghĩa và một bộ phận biểu thị âm. Các chữ có bộ “thủy” (ba chấm nước) thường liên quan đến chất lỏng, chữ có bộ “mộc” (cây) thường liên quan đến thực vật, chữ có bộ “hỏa” (lửa) thường liên quan đến nhiệt lượng. Bộ thủ chính là manh mối ngữ nghĩa cơ bản nhất khi con người học chữ: người chưa biết chữ “diễm” (ba chữ “hỏa” chồng lên nhau) chỉ cần nhìn thấy ba chữ “hỏa” cũng có thể đoán được nó liên quan đến lửa.
Vì bộ thủ là manh mối ngữ nghĩa cơ bản nhất khi con người học chữ, nên người ta thường suy luận phạm vi nghĩa từ cấu trúc trước, rồi kết hợp với ngữ cảnh để hiểu nghĩa cụ thể.

Hỏa hoa, hỏa diễm, quang diễm — thường xuất hiện trong văn viết và tên người, mang ý nghĩa ánh sáng, nóng bỏng.
Nhưng trong bảng từ vựng của tokenizer, chữ “diễm” tương ứng với một mã số. Giả sử đó là số 38721, nó đại diện cho một vị trí trong bảng từ vựng, mô hình dùng nó để tra cứu một vector số, và vector này biểu thị chữ “diễm”.
Mã số bản thân nó không mang bất kỳ thông tin nào về cấu trúc bên trong của chữ. Mối quan hệ giữa 38721 và 38722 đối với mô hình cũng giống như giữa 1 và 10000—không có gì đặc biệt. Do đó, “cấu trúc chữ Hán” bị đóng gói mất. Việc ba chữ “hỏa” chồng lên nhau hoàn toàn không tồn tại trong mã số.
Dĩ nhiên, mô hình có thể gián tiếp học được rằng “diễm”, “viêm”, “chước” thường xuất hiện trong các ngữ cảnh tương tự nhờ lượng dữ liệu huấn luyện khổng lồ, nhưng con đường này gián tiếp hơn nhiều so với việc tận dụng trực tiếp thông tin bộ thủ.
Vì vậy, liệu mô hình có thể “nhìn thấy” một số manh mối cấu trúc tương tự bộ thủ từ các byte bị cắt rời, rồi tái tổ hợp chúng ở tầng tính toán tiếp theo không? Con đường này tuy tiêu tốn nhiều token và chi phí cao hơn, nhưng có khả năng lại hiệu quả hơn trong việc hiểu ngữ nghĩa so với việc nuốt chửng một mã số mờ ám?
Một bài báo công bố năm 2025 trên tạp chí Computational Linguistics của MIT Press (tựa đề: “Tokenization Changes Meaning in Large Language Models: Evidence from Chinese”) đã trả lời câu hỏi này.
Từ mảnh vụn mọc lên bộ thủ
Tác giả bài báo, David Haslett, chú ý đến một sự trùng hợp lịch sử.
Vào những năm 1990, Liên minh Unicode khi phân bổ mã UTF-8 cho chữ Hán đã sắp xếp theo thứ tự bộ thủ. Các chữ Hán cùng bộ thủ được gán mã UTF-8 liền kề nhau. Chẳng hạn, “trà” và “cành” đều có bộ “thảo” (ba chấm cỏ), nên chuỗi byte UTF-8 của chúng bắt đầu bằng cùng một byte. “Hà” và “hải” đều có bộ “thủy”, chuỗi byte cũng chia sẻ phần đầu.
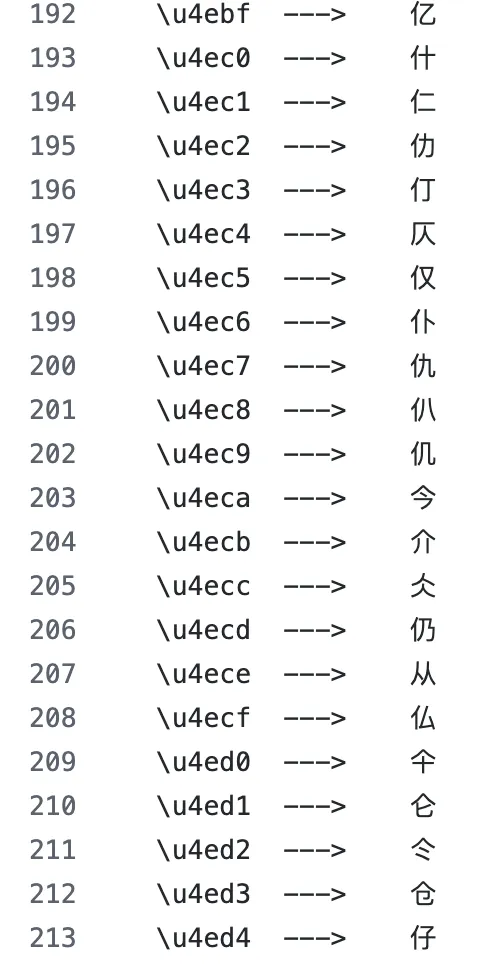
UTF-8 sắp xếp chữ Hán theo thứ tự bộ thủ, các chữ cùng bộ có mã gần nhau|Nguồn ảnh: Github
Điều này có nghĩa là khi tokenizer cắt một chữ Hán thành ba byte UTF-8, các chữ Hán cùng bộ thủ sẽ chia sẻ token đầu tiên. Trong quá trình huấn luyện, mô hình liên tục bắt gặp các mẫu byte chung này, và có khả năng học được rằng “các chữ có token đầu tiên giống nhau thường thuộc cùng một phạm trù nghĩa”. Về chức năng, điều này gần giống với quá trình con người dùng bộ thủ để suy luận nghĩa.
Haslett đã thiết kế ba thí nghiệm để kiểm chứng điều này.
Thí nghiệm đầu tiên hỏi GPT-4, GPT-4o và Llama 3: “trà” và “cành” có cùng bộ thủ ngữ nghĩa không?
Thí nghiệm thứ hai yêu cầu mô hình đánh giá mức độ tương đồng ngữ nghĩa giữa hai chữ Hán.
Thí nghiệm thứ ba yêu cầu mô hình thực hiện nhiệm vụ “tìm ra từ khác loại”.
Mỗi thí nghiệm đều kiểm soát hai biến: hai chữ Hán thực sự có chung bộ thủ hay không, và hai chữ Hán có chia sẻ token đầu tiên trong tokenizer hay không. Thiết kế 2×2 này giúp ông tách biệt được ảnh hưởng riêng biệt của “hiệu ứng bộ thủ” và “hiệu ứng token”.
Kết luận của cả ba thí nghiệm đều nhất quán: khi các chữ Hán bị cắt thành nhiều token (ví dụ, trong bộ tokenizer cũ của GPT-4, 89% chữ Hán bị cắt thành nhiều token), độ chính xác nhận diện bộ thủ chung của mô hình cao hơn; khi các chữ Hán được mã hóa thành một token duy nhất (trong bộ tokenizer mới của GPT-4o, chỉ còn 57% chữ Hán bị cắt thành nhiều token), độ chính xác giảm đi.
Nói cách khác, giả thuyết ở đoạn trước đã được xác nhận. Việc cắt nát chữ Hán thực sự tốn kém hơn, nhưng chuỗi byte sau khi cắt vẫn lưu giữ dấu vết của bộ thủ, và mô hình thực sự học được một số điều từ đó. Còn khi mã hóa chữ Hán thành token nguyên chữ, chi phí giảm xuống, nhưng thông tin bộ thủ lại bị đóng gói trong một mã số mờ ám, khiến mô hình không thể khai thác manh mối này từ chuỗi byte nữa.
Cần nhấn mạnh đặc biệt rằng kết luận này chỉ áp dụng cho các tác vụ ngữ nghĩa chuyên sâu liên quan đến hình dạng chữ, chứ không đồng nghĩa với việc khả năng hiểu tiếng Trung tổng thể, suy luận logic hay sinh văn bản dài của mô hình bị suy giảm. Đồng thời, việc so sánh giữa GPT-4 và GPT-4o trong thí nghiệm không chỉ khác nhau về tokenizer, mà còn khác biệt đáng kể về kiến trúc mô hình, dữ liệu huấn luyện và số lượng tham số, nên không thể quy toàn bộ sự thay đổi độ chính xác 100% cho việc điều chỉnh độ mịn của tokenizer.
Phát hiện này còn được xác nhận từ phía kỹ thuật. Một nghiên cứu năm 2024 trên GPT-4o phát hiện rằng sau khi bộ tokenizer mới gộp một số tổ hợp ký tự tiếng Trung thành một token dài, mô hình lại xuất hiện lỗi hiểu sai. Khi các nhà nghiên cứu sử dụng bộ tách từ chuyên dụng cho tiếng Trung để tách lại token dài đó và đưa vào mô hình, độ chính xác hiểu lại được khôi phục.
Hiện nay, quan điểm chung của ngành mô hình ngôn ngữ lớn toàn cầu vẫn là: bộ tokenizer được tối ưu cho ngôn ngữ mục tiêu (gộp theo từ hoặc theo chữ) có thể nâng cao đáng kể hiệu năng tổng thể của mô hình. Việc mã hóa theo từ hoặc theo chữ không chỉ giảm mạnh chi phí token và tăng lượng thông tin hiệu dụng trong cửa sổ ngữ cảnh, mà còn rút ngắn độ dài chuỗi, giảm độ trễ suy luận và nâng cao độ ổn định khi xử lý văn bản dài. Lợi thế trong các tác vụ chuyên sâu được nêu trong bài báo không thể bù đắp được lợi ích hiệu năng trên phần lớn các tình huống xử lý ngôn ngữ tự nhiên tiếng Trung.
Tuy nhiên, sự việc này vẫn chạm đến một trong những vấn đề khó xử lý nhất trong các hệ thống lớn: bạn có thể tối ưu phần bạn đã thiết kế, nhưng bạn không thể tối ưu phần bạn không biết mình đang sở hữu. Liên minh Unicode sắp xếp mã theo bộ thủ để thuận tiện cho việc tra cứu của con người. BPE cắt chữ Hán thành byte vì tần suất xuất hiện của chúng trong kho dữ liệu quá thấp. Hai quyết định kỹ thuật không liên quan này tình cờ chồng lên nhau, tạo nên một kênh ngữ nghĩa mà không ai từng lên kế hoạch.
Rồi khi các kỹ sư thế hệ mới “cải tiến” tokenizer bằng cách gộp chữ Hán thành token nguyên chữ, họ đồng thời cũng xóa bỏ một con đường mà chính họ không hề biết tồn tại. Hiệu quả tăng lên, chi phí giảm xuống, nhưng một số thứ cũng lặng lẽ biến mất—mà bạn thậm chí sẽ không nhận được một thông báo lỗi nào.
Vì vậy, vấn đề phức tạp hơn nhiều so với nhận định đơn giản “tiếng Trung phải trả thêm tiền trong AI”. Mỗi bộ tokenizer đều đang được tối ưu cho một giá trị mặc định, và cái giá phải trả luôn ẩn ở nơi khác.
Lâm Ngữ Đường
Chi phí thích nghi tiếng Trung với cơ sở hạ tầng kỹ thuật phương Tây không bắt đầu từ thời đại AI.
Tháng 1 năm 2025, Nelson Felix, một cư dân New York, đăng vài bức ảnh lên một nhóm yêu thích máy đánh chữ trên Facebook. Ông phát hiện một chiếc máy đánh chữ khắc đầy chữ Hán trong đồ vật thừa kế từ ông ngoại vợ, nhưng không biết nguồn gốc. Ngay lập tức hàng trăm bình luận đổ về.

Câu hỏi của Nelson Felix: Máy đánh chữ Minh Khải có giá trị không?|Nguồn ảnh: Facebook
Thomas S. Mullaney, nhà Hán học của Đại học Stanford, nhìn thấy ảnh liền nhận ra ngay: đây là nguyên mẫu duy nhất của “máy đánh chữ Minh Khải” do Lâm Ngữ Đường phát minh năm 1947, đã mất tích gần 80 năm. Đến tháng 4 cùng năm, vợ chồng Felix bán chiếc máy cho Thư viện Đại học Stanford.
Vấn đề mà máy đánh chữ Minh Khải muốn giải quyết, về cấu trúc, chính là vấn đề mà tokenizer ngày nay đang đối mặt: làm thế nào để nhúng tiếng Trung một cách hiệu quả vào một cơ sở hạ tầng kỹ thuật được thiết kế cho ngôn ngữ phương Tây.
Máy đánh chữ tiếng Anh những năm 1940 có 26 phím chữ cái, mỗi phím một chữ—đơn giản và trực tiếp. Tiếng Trung có hàng nghìn chữ thường dùng, không thể mỗi phím một chữ. Lúc ấy, máy đánh chữ tiếng Trung là một bàn phím khổng lồ chứa hàng nghìn con chữ chì, người đánh chữ phải dùng tay chọn từng con chữ, mỗi phút chỉ đánh được chục chữ.

Năm 1899, nhà truyền giáo Mỹ Devello Z. Sheffield phát minh ra máy đánh chữ tiếng Trung đầu tiên—ghi chép sớm nhất về máy đánh chữ tiếng Trung|Nguồn ảnh: Wikipedia
Lâm Ngữ Đường đầu tư 120.000 USD cho nghiên cứu và phát triển, gần như tán gia bại sản, ủy thác Công ty Carl E. Krum ở New York chế tạo một chiếc máy đánh chữ tiếng Trung chỉ có 72 phím. Nguyên lý hoạt động là chia chữ Hán theo cấu trúc hình dạng: phím trên chọn nửa trên của bộ chữ, phím dưới chọn nửa dưới, các chữ ứng cử hiện lên một cửa sổ nhỏ gọi là “mắt thần”, rồi nhấn phím số để chọn. Tốc độ đạt 40–50 chữ/phút, hỗ trợ hơn 8.000 ký tự thường dùng.

(Trái) Cửa sổ kính trong suốt chính là “mắt thần”; (Phải) Cấu trúc bên trong máy đánh chữ Minh Khải|Nguồn ảnh: Facebook
Triệu Nguyên Nhậm đánh giá: “Dù là người Trung Quốc hay người Mỹ, chỉ cần học qua một chút là có thể làm quen với bàn phím này. Tôi cho rằng đây chính là chiếc máy đánh chữ mà chúng ta cần.”
Về mặt kỹ thuật, máy đánh chữ Minh Khải là một bước đột phá, nhưng về mặt thương mại, nó thất bại.
Khi Lâm Ngữ Đường trình diễn trước ban lãnh đạo Công ty Remington, máy bị hỏng, khiến các nhà đầu tư mất hứng thú; cộng thêm chi phí sản xuất cao và dòng tiền cá nhân của ông cạn kiệt, việc sản xuất hàng loạt trở nên bất khả thi. Năm 1948, Lâm Ngữ Đường bán nguyên mẫu và quyền thương mại cho Công ty Mergenthaler Linotype. Công ty này cuối cùng từ bỏ sản xuất hàng loạt, và nguyên mẫu bị một nhân viên mang về nhà ở Long Island trong đợt dọn văn phòng của công ty vào những năm 1950, sau đó mất tích cho đến khi tái xuất hiện năm 2025.
Trong cuốn sách Máy đánh chữ tiếng Trung, Thomas S. Mullaney đưa ra một nhận định: ông cho rằng máy đánh chữ Minh Khải “không thất bại”. Là một sản phẩm những năm 1940, nó thực sự thất bại. Nhưng như một kiểu tương tác người–máy, nó đã chiến thắng.
Lâm Ngữ Đường lần đầu tiên biến việc “đánh chữ tiếng Trung” thành “tìm kiếm và lựa chọn”. Ba hàng phím kết hợp để định vị bộ chữ, rồi chọn từ danh sách ứng cử. Đây chính là logic nền tảng của mọi bộ gõ tiếng Trung hiện đại. Từ Thương Kiệt, Ngũ bút đến Sogou Pinyin, tất cả đều có thể được xem là hậu duệ của máy đánh chữ Minh Khải.

Máy đánh chữ tiếng Trung, tác giả: Thomas S. Mullaney|Nguồn ảnh: Douban
Chiếc máy đánh chữ vượt qua gần tám thập kỷ này, và bộ tokenizer mà chúng ta đang tranh luận không ngừng hôm nay, ẩn chứa một quy luật lịch sử nào đó. Tiếng Trung luôn phải đối mặt với một vấn đề:
Làm thế nào để kết nối với một cơ sở hạ tầng được xây dựng trên nền tảng chữ cái La Mã.
Thú vị ở chỗ, trong hành trình tìm kiếm này, luôn đầy rẫy những sự trùng hợp ngoài ý muốn. Việc Liên minh Unicode sắp xếp mã theo thứ tự bộ thủ nhằm thuận tiện cho việc tra cứu của con người, cộng với việc thuật toán BPE vô tình cắt rời các ký tự, tình cờ tái hiện trong “hộp đen” mạng nơ-ron quá trình con người học chữ. Và khi các kỹ sư chủ động ghép lại các chữ Hán để loại bỏ “thuế tiếng Trung” và hạ chi phí, thì kênh ngữ nghĩa tình cờ ấy cũng khép lại.
Lịch sử không phải một đường thẳng tiến hóa, mà là một dòng chảy liên tục biến dạng dưới áp lực của vô số ràng buộc.
Một số khả năng được thiết kế ra, một số khả năng chỉ tình cờ chưa bị xóa đi.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













