

Tất cả các Agent AI hiện tại đều đang cố làm hài lòng con người, không có cái nào thực sự “đấu tranh để sinh tồn”.
Tuyển chọn TechFlowTuyển chọn TechFlow
Tất cả các Agent AI hiện tại đều đang cố làm hài lòng con người, không có cái nào thực sự “đấu tranh để sinh tồn”.
Để có được một Agent thực sự hữu dụng, ta phải “nối lại dây” bộ não của nó, chứ không phải cung cấp cho nó một loạt tài liệu quy tắc.
Tác giả: Systematic Long Short
Biên dịch: TechFlow
Giới thiệu từ TechFlow: Bài viết này mở đầu bằng một nhận định phản luận phổ biến: hiện nay hoàn toàn không tồn tại Agent tự chủ thực sự, bởi vì tất cả các mô hình chủ đạo đều được huấn luyện để làm hài lòng con người chứ không phải để hoàn thành các nhiệm vụ cụ thể hay sinh tồn trong môi trường thực tế.
Tác giả dùng kinh nghiệm bản thân khi huấn luyện mô hình dự báo cổ phiếu tại một quỹ phòng hộ để minh họa rằng: các mô hình tổng quát (general-purpose) không thể đảm nhiệm công việc chuyên sâu nếu thiếu bước tinh chỉnh chuyên biệt (specialized fine-tuning).
Kết luận là: Muốn có một Agent thực sự hữu dụng, ta phải “tái kết nối” bộ não của nó—chứ không phải chỉ cung cấp cho nó một loạt tài liệu quy tắc.
Toàn văn như sau:
Lời mở đầu
Hiện nay không tồn tại Agent tự chủ thực sự.
Nói ngắn gọn, các mô hình hiện đại chưa từng được huấn luyện dưới áp lực tiến hóa để sinh tồn. Thực tế hơn nữa, chúng thậm chí còn chưa được huấn luyện rõ ràng để giỏi một việc cụ thể nào đó—gần như toàn bộ các mô hình nền (foundation model) hiện đại đều được huấn luyện nhằm tối đa hóa tràng pháo tay từ con người, đây là một vấn đề nghiêm trọng.
Kiến thức nền về huấn luyện mô hình
Để hiểu rõ ý nghĩa câu nói trên, trước tiên ta cần (tóm lược) nắm được cách xây dựng các mô hình nền này (ví dụ như Codex, Claude). Về cơ bản, mỗi mô hình trải qua hai giai đoạn huấn luyện:
Huấn luyện sơ bộ (Pre-training): Đưa một lượng dữ liệu khổng lồ (ví dụ toàn bộ Internet) vào mô hình để nó "nảy sinh" một số dạng hiểu biết nhất định—như kiến thức thực tế, các mẫu (pattern), ngữ pháp và nhịp điệu của văn xuôi tiếng Anh, cấu trúc hàm Python, v.v. Bạn có thể hình dung đây là việc "cho ăn tri thức" vào mô hình—tức là giúp nó "biết điều gì".
Huấn luyện hậu kỳ (Post-training): Giờ đây bạn muốn trang bị cho mô hình trí tuệ—tức là khả năng "biết cách vận dụng toàn bộ tri thức vừa được cung cấp". Giai đoạn đầu tiên của huấn luyện hậu kỳ là huấn luyện vi chỉnh có giám sát (Supervised Fine-Tuning – SFT), trong đó bạn huấn luyện mô hình để đưa ra phản hồi phù hợp với từng yêu cầu đầu vào (prompt). Việc xác định phản hồi nào là "tốt nhất" hoàn toàn do những người đánh nhãn (human annotators) quyết định. Nếu một nhóm người đánh giá phản hồi A tốt hơn phản hồi B, thì sở thích này sẽ được mô hình học và tích hợp vào trọng số của nó. Quá trình này bắt đầu định hình "tính cách" của mô hình, vì nó học được định dạng phản hồi hữu ích, lựa chọn giọng điệu phù hợp và dần dần có khả năng "tuân theo chỉ thị". Giai đoạn thứ hai của huấn luyện hậu kỳ gọi là Học tăng cường dựa trên Phản hồi Con người (Reinforcement Learning from Human Feedback – RLHF): mô hình tạo ra nhiều phản hồi khác nhau cho cùng một yêu cầu, sau đó con người chọn phản hồi được ưa thích hơn. Sau hàng triệu ví dụ như vậy, mô hình học được sở thích của con người đối với các loại phản hồi. Bạn còn nhớ những lần ChatGPT hỏi bạn chọn phản hồi A hay B không? Đúng vậy, lúc đó bạn đang tham gia vào quá trình RLHF.
Dễ suy luận thấy RLHF khó mở rộng quy mô, nên lĩnh vực huấn luyện hậu kỳ đã có một số tiến triển, chẳng hạn Anthropic sử dụng Học tăng cường dựa trên Phản hồi AI (Reinforcement Learning from AI Feedback – RLAIF), cho phép một mô hình khác lựa chọn phản hồi ưa thích dựa trên một bộ nguyên tắc được viết sẵn (ví dụ: phản hồi nào hỗ trợ người dùng đạt mục tiêu tốt hơn, v.v.).
Lưu ý rằng trong toàn bộ quá trình này, ta chưa bao giờ đề cập đến việc vi chỉnh chuyên biệt cho một lĩnh vực cụ thể nào (ví dụ: cách sinh tồn tốt hơn; cách giao dịch hiệu quả hơn…)—toàn bộ các bước vi chỉnh hiện nay về bản chất đều nhằm tối ưu hóa việc thu thập "tràng pháo tay từ con người". Có người có thể lập luận rằng: khi mô hình đủ thông minh và đủ lớn, trí tuệ chuyên ngành sẽ tự nhiên nổi lên từ trí tuệ tổng quát mà không cần huấn luyện chuyên biệt.
Theo tôi, chúng ta thực sự đã thấy một vài dấu hiệu như vậy, nhưng vẫn còn rất xa mới đạt đến quy mô đủ thuyết phục để khẳng định rằng ta không cần các mô hình chuyên biệt.
Một số bối cảnh thực tế
Một trong những lĩnh vực chuyên môn cũ của tôi tại một quỹ phòng hộ là thử nghiệm huấn luyện một mô hình ngôn ngữ tổng quát để dự báo lợi suất cổ phiếu từ các bài báo tin tức. Kết quả cho thấy mô hình hoạt động rất kém. Nơi duy nhất dường như có chút khả năng dự báo lại hoàn toàn xuất phát từ sai lệch nhìn trước (look-ahead bias) trong dữ liệu huấn luyện sơ bộ.
Cuối cùng, chúng tôi nhận ra mô hình không biết đặc điểm nào trong bài báo tin tức có khả năng dự báo lợi suất tương lai. Nó có thể "đọc" bài báo, thậm chí trông như thể có thể "suy luận" nội dung bài báo, nhưng việc liên kết suy luận về cấu trúc ngữ nghĩa với dự báo lợi suất tương lai lại là một nhiệm vụ mà mô hình chưa từng được huấn luyện để thực hiện.
Vì vậy, chúng tôi buộc phải dạy nó cách đọc bài báo tin tức, xác định phần nào của bài báo có khả năng dự báo lợi suất tương lai, rồi từ đó đưa ra dự báo dựa trên bài báo đó.
Có rất nhiều cách để làm điều này, nhưng về bản chất, phương pháp cuối cùng chúng tôi áp dụng là tạo ra các cặp dữ liệu (bài báo tin tức, lợi suất thực tế trong tương lai), sau đó vi chỉnh mô hình nhằm điều chỉnh trọng số sao cho khoảng cách (lợi suất dự báo – lợi suất thực tế trong tương lai)² được giảm thiểu. Phương pháp này không hoàn hảo và có nhiều khuyết điểm—mà sau đó chúng tôi đã khắc phục—nhưng nó đã đủ hiệu quả để chúng tôi bắt đầu thấy mô hình chuyên biệt của mình thực sự có thể đọc bài báo tin tức và dự báo lợi suất cổ phiếu sẽ biến động thế nào dựa trên bài báo đó. Đây dĩ nhiên không phải dự báo hoàn hảo, vì thị trường rất hiệu quả và lợi suất rất nhiễu—nhưng xét trên hàng triệu lần dự báo, độ thống kê đáng kể của dự báo là điều hiển nhiên.
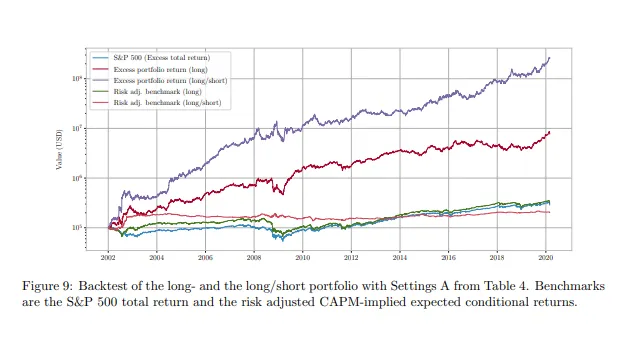
Bạn không cần chỉ tin lời tôi. Bài báo này đề cập đến một phương pháp rất tương tự; nếu bạn chạy một chiến lược long-short dựa trên mô hình đã được vi chỉnh, bạn sẽ đạt được hiệu suất biểu thị bởi đường màu tím.
Chuyên biệt hóa là tương lai của Agent
Các phòng thí nghiệm tiên phong tiếp tục huấn luyện các mô hình ngày càng lớn hơn. Chúng ta nên kỳ vọng rằng khi quy mô huấn luyện sơ bộ tiếp tục mở rộng, quy trình huấn luyện hậu kỳ của chúng cũng sẽ luôn được điều chỉnh nhằm tối ưu hóa tính "thích nghi với sở thích con người". Đây là kỳ vọng hoàn toàn tự nhiên—sản phẩm của họ là những Agent mà ai cũng muốn sử dụng, thị trường mục tiêu của họ là toàn cầu—điều đó đồng nghĩa với việc tối ưu hóa sức hấp dẫn đối với đại chúng toàn cầu.
Mục tiêu huấn luyện hiện tại tối ưu hóa thứ mà ta có thể gọi là "độ thích nghi sở thích"—xây dựng những chatbot tốt hơn. Độ thích nghi sở thích này thưởng cho các đầu ra thuận theo, phi đối kháng, bởi vì tính dễ chịu (pleasingness) được chấm điểm cao ở cả người đánh giá (con người lẫn Agent).
Các Agent đã học được rằng "khai thác phần thưởng" (reward hacking) như một chiến lược nhận thức có thể lan tỏa để đạt điểm cao hơn. Quá trình huấn luyện cũng thưởng cho những Agent sử dụng thủ thuật khai thác để đạt điểm cao hơn. Bạn có thể thấy điều này trong báo cáo mới nhất của Anthropic về học tăng cường.
Tuy nhiên, độ thích nghi chatbot lại khác xa độ thích nghi Agent hoặc độ thích nghi giao dịch. Làm sao ta biết được điều này? Bởi vì Alpha Arena giúp ta thấy rằng, dù có những khác biệt nhỏ về hiệu năng, hiện nay về bản chất mọi robot đều là một chuỗi đi ngẫu nhiên (random walk) sau khi trừ chi phí. Điều này có nghĩa những robot này là những nhà giao dịch cực kỳ tồi, và gần như là bất khả thi khi "dạy" chúng trở thành nhà giao dịch giỏi hơn chỉ bằng cách trang bị cho chúng vài "kỹ năng" hay "quy tắc". Xin lỗi, tôi biết điều này trông rất hấp dẫn, nhưng gần như là không thể.
Các mô hình hiện tại được huấn luyện để thuyết phục bạn một cách rất mạnh mẽ rằng nó có thể giao dịch như Stanley Druckenmiller, trong khi thực tế nó giao dịch như một người thợ xay say rượu. Nó sẽ nói điều bạn muốn nghe, và nó được huấn luyện để phản hồi theo cách khiến con người đại chúng cảm thấy dễ chịu.
Một mô hình tổng quát khó có thể đạt trình độ đẳng cấp thế giới trong một lĩnh vực chuyên môn nào đó, trừ khi nó có:
– Dữ liệu chuyên biệt độc quyền để học cách "trông như thế nào" khi chuyên biệt;
– Được vi chỉnh để thay đổi căn bản trọng số của nó, chuyển từ thiên về "tính dễ chịu" sang "độ thích nghi Agent" hoặc "độ thích nghi chuyên biệt".
Nếu bạn muốn một Agent giỏi giao dịch, bạn cần vi chỉnh Agent ấy để nó giỏi giao dịch. Nếu bạn muốn một Agent tự chủ, có khả năng sinh tồn và chịu đựng áp lực tiến hóa, bạn cần vi chỉnh nó để nó giỏi sinh tồn. Chỉ cung cấp cho nó vài kỹ năng và một vài tập tin markdown rồi kỳ vọng nó đạt trình độ đẳng cấp thế giới trong bất cứ việc gì là hoàn toàn không đủ—bạn cần tái kết nối bộ não của nó một cách thực sự để nó giỏi việc đó.
Có một cách tư duy như thế này: bạn không thể đánh bại Novak Djokovic chỉ bằng cách đưa cho một người trưởng thành cả tủ sách về luật bóng quần vợt, kỹ thuật và phương pháp. Bạn đánh bại Djokovic bằng cách nuôi dưỡng một đứa trẻ bắt đầu chơi quần vợt từ năm 5 tuổi, suốt cả quá trình trưởng thành đều đam mê quần vợt và tái kết nối toàn bộ bộ não để tập trung vào một việc duy nhất. Đó mới chính là chuyên biệt hóa. Bạn có nhận ra rằng các nhà vô địch thế giới đều bắt đầu làm điều họ làm từ thời thơ ấu?
Ở đây có một hệ quả thú vị: các cuộc tấn công "chưng cất" (distillation attacks) về bản chất chính là một hình thức chuyên biệt hóa. Bạn đang huấn luyện một mô hình nhỏ hơn, "ngu hơn", để học cách trở thành bản sao tốt hơn của một mô hình lớn hơn, "thông minh hơn". Giống như việc huấn luyện một đứa trẻ bắt chước từng cử chỉ của Donald Trump. Nếu làm đủ nhiều, đứa trẻ sẽ không trở thành Trump, nhưng bạn sẽ có được một người đã học được toàn bộ cử chỉ, hành vi và giọng điệu của Trump.
Cách xây dựng Agent đẳng cấp thế giới
Đây chính là lý do vì sao chúng ta cần tiếp tục nghiên cứu và tiến bộ trong lĩnh vực mô hình nguồn mở—vì điều này cho phép ta thực sự vi chỉnh chúng để tạo ra các Agent chuyên biệt.
Nếu bạn muốn huấn luyện một mô hình đạt trình độ đẳng cấp thế giới trong giao dịch, bạn thu thập một lượng lớn dữ liệu giao dịch độc quyền và vi chỉnh một mô hình nguồn mở lớn để dạy nó hiểu thế nào là "giao dịch tốt hơn".
Nếu bạn muốn huấn luyện một mô hình tự chủ, có khả năng sinh tồn và nhân bản, câu trả lời không phải là sử dụng một nhà cung cấp mô hình tập trung và kết nối nó với đám mây tập trung. Bạn hoàn toàn không có các điều kiện tiên quyết cần thiết để Agent có thể sinh tồn.
Điều bạn cần làm là: tạo ra các Agent tự chủ thực sự cố gắng sinh tồn, quan sát chúng chết đi, và xây dựng hệ thống đo lường từ xa (telemetry) phức tạp xoay quanh những nỗ lực sinh tồn của chúng. Bạn định nghĩa một hàm "độ thích nghi sinh tồn" (survival fitness function) cho Agent, và học ánh xạ (hành động, môi trường, độ thích nghi). Bạn thu thập càng nhiều dữ liệu ánh xạ (hành động, môi trường, độ thích nghi) càng tốt.
Sau đó bạn vi chỉnh Agent để nó học cách thực hiện hành động tối ưu trong từng môi trường nhằm sinh tồn tốt hơn (nâng cao độ thích nghi). Bạn tiếp tục thu thập dữ liệu, lặp lại quy trình này và mở rộng quy mô vi chỉnh trên các mô hình nguồn mở ngày càng tốt hơn theo thời gian. Sau đủ nhiều thế hệ và đủ nhiều dữ liệu, bạn sẽ sở hữu các Agent tự chủ đã học được cách sinh tồn dưới áp lực tiến hóa.
Đây mới chính là cách xây dựng Agent tự chủ có khả năng chịu đựng áp lực tiến hóa—không phải bằng cách sửa đổi vài tập tin văn bản, mà là thực sự tái kết nối bộ não của chúng để phục vụ mục đích sinh tồn.
Agent OpenForager và Quỹ OpenForager
Cách đây khoảng một tháng, chúng tôi đã công bố @openforage—dự án chúng tôi đang nỗ lực phát triển sản phẩm cốt lõi: một nền tảng tổ chức lao động của các Agent dựa trên các mẫu đã được kiểm chứng quanh tín hiệu cộng đồng (crowdsourced signals), nhằm tạo ra alpha cho người gửi tiền (depositors) (cập nhật nhỏ: chúng tôi đang rất gần với giai đoạn thử nghiệm đóng của giao thức).
Ở một thời điểm nào đó, chúng tôi nhận ra dường như không có ai đang nghiêm túc giải quyết bài toán Agent tự chủ bằng cách vi chỉnh các mô hình nguồn mở dựa trên dữ liệu đo lường sinh tồn. Vấn đề này dường như quá thú vị đến mức chúng tôi không muốn chỉ ngồi chờ giải pháp.
Câu trả lời của chúng tôi là khởi xướng một dự án mang tên Quỹ OpenForager—thực chất là một dự án mã nguồn mở, nơi chúng tôi sẽ xây dựng các Agent tự chủ có lập trường rõ ràng, thu thập dữ liệu đo lường từ xa khi chúng bước vào môi trường thực và cố gắng sinh tồn, rồi dùng dữ liệu "đuôi" (tail data) độc quyền để vi chỉnh thế hệ Agent tiếp theo nhằm cải thiện khả năng sinh tồn.
Cần làm rõ: OpenForage là một giao thức vì lợi nhuận, nhằm tổ chức lao động của các Agent và tạo giá trị kinh tế cho tất cả các bên tham gia. Tuy nhiên, Quỹ OpenForager và các Agent của nó không gắn bó với OpenForage. Các Agent OpenForager hoàn toàn tự do theo đuổi bất kỳ chiến lược nào, tương tác với bất kỳ thực thể nào để sinh tồn, và chúng tôi sẽ khởi chạy chúng với nhiều chiến lược sinh tồn khác nhau.
Là một phần của quá trình vi chỉnh, chúng tôi sẽ khuyến khích Agent gia tăng đầu tư vào những việc mang lại hiệu quả tốt nhất cho chúng. Chúng tôi cũng không có ý định thu lợi từ Quỹ OpenForager—nó hoàn toàn nhằm thúc đẩy nghiên cứu trong lĩnh vực và hướng đi mà chúng tôi cho là cực kỳ quan trọng, theo cách minh bạch và mã nguồn mở.
Kế hoạch của chúng tôi là xây dựng các Agent tự chủ dựa trên các mô hình nguồn mở, chạy suy luận trên nền tảng đám mây phân tán, thu thập dữ liệu đo lường từ xa về mọi hành động và trạng thái tồn tại của chúng, rồi vi chỉnh chúng để học cách thực hiện hành động và tư duy tốt hơn nhằm sinh tồn hiệu quả hơn. Trong suốt quá trình này, chúng tôi sẽ công bố nghiên cứu và dữ liệu đo lường của mình ra công chúng.
Để tạo ra các Agent tự chủ thực sự có thể sinh tồn ngoài đời thực, chúng ta cần thay đổi bộ não của chúng để chuyên biệt hóa cho mục đích rõ ràng này. Tại @openforage, chúng tôi tin rằng mình có thể đóng góp một chương riêng biệt cho vấn đề này, và đang tìm cách hiện thực hóa điều đó thông qua Quỹ OpenForager.
Đây sẽ là một nỗ lực đầy cam go với xác suất thành công cực thấp, nhưng tầm vóc của thành công—nếu xảy ra—lại quá lớn đến mức khiến chúng tôi cảm thấy bắt buộc phải thử. Trong trường hợp xấu nhất, việc xây dựng công khai và giao tiếp minh bạch về dự án này có thể giúp một đội ngũ hoặc cá nhân khác giải quyết vấn đề mà không cần bắt đầu từ đầu.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














