

8 cấp độ trong kỹ thuật tác tử
Tuyển chọn TechFlowTuyển chọn TechFlow
8 cấp độ trong kỹ thuật tác tử
Mỗi lần nâng cấp một cấp độ đều đồng nghĩa với bước nhảy vọt lớn về năng lực sản xuất, và mỗi lần cải thiện năng lực mô hình lại tiếp tục khuếch đại những lợi ích này.
Tác giả: Bassim Eledath
Biên dịch: Bảo Ngọc
Khả năng lập trình của AI đang vượt xa khả năng kiểm soát và khai thác của chúng ta. Đó chính là lý do vì sao mọi nỗ lực miệt mài nhằm “đạt điểm cao trên SWE-bench” đều không đồng bộ với các chỉ số năng suất thực sự quan trọng đối với lãnh đạo kỹ thuật. Đội ngũ Anthropic triển khai ứng dụng Cowork chỉ trong 10 ngày, trong khi một đội khác sử dụng cùng mô hình lại chẳng thể hoàn thành nổi một bản chứng minh khái niệm (POC) — sự khác biệt nằm ở chỗ một đội đã thu hẹp được khoảng cách giữa năng lực và thực tiễn, còn đội kia thì chưa.
Khoảng cách này sẽ không biến mất trong một sớm một chiều, mà được thu hẹp từng bậc một. Tổng cộng có 8 bậc. Phần lớn người đọc bài viết này có lẽ đã vượt qua vài bậc đầu tiên, và bạn hẳn đang háo hức tiến lên bậc tiếp theo — bởi mỗi lần thăng cấp đều mang lại bước nhảy vọt về năng suất, và mỗi lần nâng cấp mô hình lại khuếch đại thêm những lợi ích đó.
Một lý do khác khiến bạn cần quan tâm là hiệu ứng hợp tác đa người. Năng suất của bạn phụ thuộc vào bậc của đồng đội nhiều hơn bạn tưởng. Giả sử bạn là chuyên gia bậc 7: khi bạn ngủ, các agent thông minh chạy nền vẫn đang âm thầm chuẩn bị hàng loạt pull request (PR) cho bạn. Nhưng nếu kho mã nguồn của bạn yêu cầu một đồng nghiệp phê duyệt trước khi merge, mà đồng nghiệp ấy mới chỉ ở bậc 2 — vẫn đang xem xét thủ công từng PR — thì năng suất của bạn sẽ bị nghẽn ngay tại khâu này. Vì vậy, giúp đồng đội thăng cấp cũng chính là đầu tư cho chính bạn.
Thông qua trao đổi với nhiều đội nhóm và cá nhân về thực tiễn sử dụng lập trình hỗ trợ bởi AI, đây là lộ trình thăng cấp mà tôi quan sát được (thứ tự không tuyệt đối nghiêm ngặt):
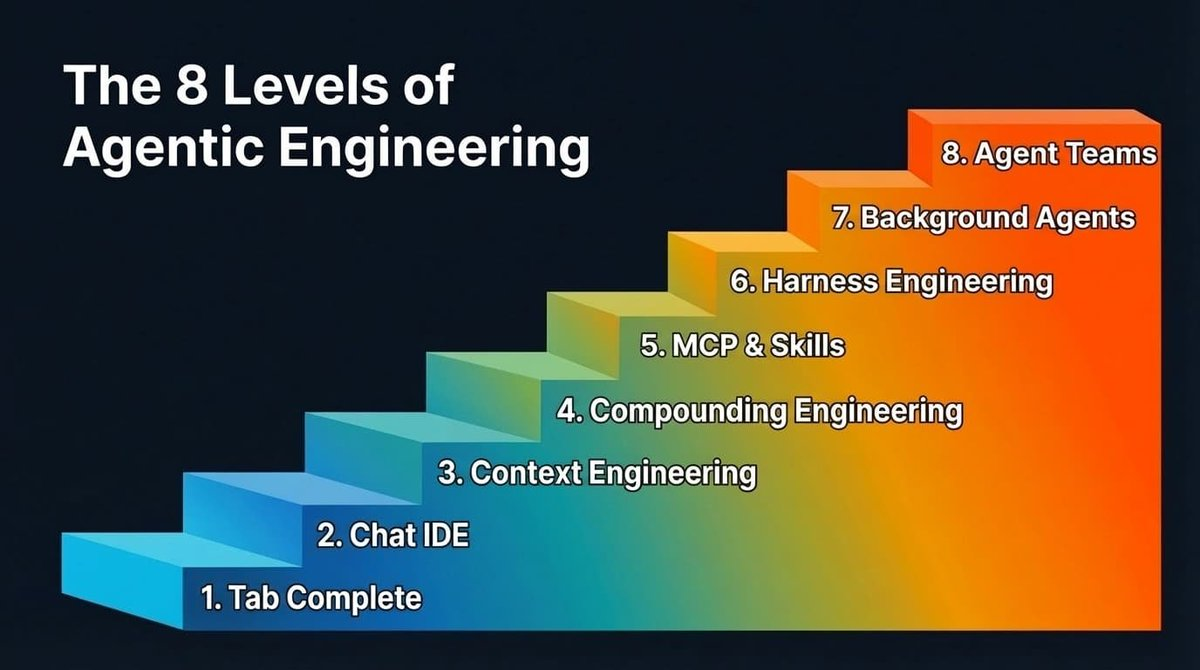
Tám bậc trong kỹ nghệ agent thông minh
Bậc 1 và Bậc 2: Tự động điền bằng phím Tab và IDE thông minh
Tôi sẽ lược qua hai bậc này để đảm bảo tính đầy đủ, bạn hoàn toàn có thể bỏ qua nếu muốn.
Tự động điền bằng phím Tab là khởi nguồn của mọi thứ. GitHub Copilot đã mở màn phong trào này — nhấn Tab để tự động bổ sung đoạn mã. Nhiều người có lẽ đã quên mất giai đoạn này, còn người mới vào nghề thậm chí có thể bỏ qua luôn. Nó phù hợp nhất với các lập trình viên giàu kinh nghiệm, những người có thể dựng sẵn “khung xương” mã trước rồi để AI điền chi tiết.
Các IDE chuyên biệt cho AI như Cursor đã thay đổi cục diện: chúng tích hợp chức năng trò chuyện với cơ sở mã, giúp chỉnh sửa xuyên nhiều tệp trở nên dễ dàng hơn rất nhiều. Nhưng trần giới hạn vẫn là ngữ cảnh (context). Mô hình chỉ có thể hỗ trợ bạn xử lý những nội dung nó “nhìn thấy”, và điều gây bực bội nhất là đôi khi nó lại không nhìn thấy ngữ cảnh đúng, hoặc lại “nhìn thấy” quá nhiều ngữ cảnh không liên quan.
Đa số người ở bậc này cũng đang thử nghiệm chế độ lập kế hoạch (planning mode) của agent lập trình họ chọn: chuyển một ý tưởng sơ bộ thành kế hoạch từng bước có cấu trúc gửi tới LLM, lặp đi lặp lại việc điều chỉnh kế hoạch rồi kích hoạt thực thi. Ở giai đoạn này, phương pháp này khá hiệu quả và là cách hợp lý để duy trì quyền kiểm soát. Tuy nhiên, ở các bậc sau, bạn sẽ thấy sự phụ thuộc vào chế độ lập kế hoạch ngày càng giảm đi.
Bậc 3: Kỹ nghệ ngữ cảnh
Giờ chúng ta bước vào phần thú vị. “Kỹ nghệ ngữ cảnh” (Context Engineering) là cụm từ hot nhất năm 2025 — và nó trở thành một khái niệm chính vì giờ đây các mô hình cuối cùng đã có thể tuân thủ một lượng hướng dẫn hợp lý một cách đáng tin cậy, khi được cung cấp đúng mức ngữ cảnh. Ngữ cảnh nhiễu và ngữ cảnh thiếu hụt đều tệ như nhau; do đó, công việc cốt lõi là tăng mật độ thông tin trên mỗi token. “Mỗi token phải đấu tranh để khẳng định vị trí của mình trong prompt” — đó chính là tôn chỉ thời kỳ ấy.
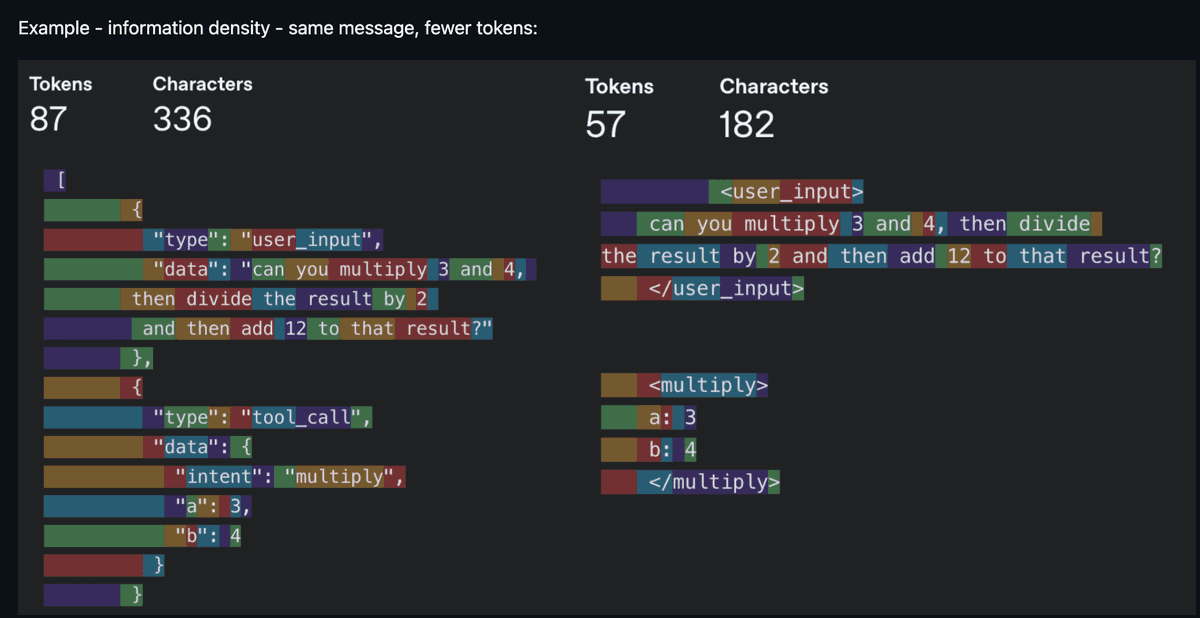
Cùng một thông tin, ít token hơn — mật độ thông tin mới là vua (Nguồn: humanlayer/12-factor-agents)
Trên thực tế, kỹ nghệ ngữ cảnh bao hàm phạm vi rộng hơn nhiều so với nhận thức chung. Nó bao gồm prompt hệ thống và các tệp quy tắc của bạn (ví dụ: .cursorrules, CLAUDE.md). Nó bao gồm cách bạn mô tả các công cụ, bởi mô hình đọc các mô tả này để quyết định gọi công cụ nào. Nó bao gồm việc quản lý lịch sử hội thoại, tránh để các agent chạy dài bị “lạc hướng” sau vòng hội thoại thứ mười. Nó còn bao gồm việc quyết định mỗi vòng nên phơi bày công cụ nào, vì quá nhiều lựa chọn sẽ khiến mô hình “choáng ngợp” — giống như con người vậy.
Ngày nay bạn hiếm khi còn nghe đến cụm “kỹ nghệ ngữ cảnh”. Cán cân đã nghiêng về phía những mô hình có khả năng chịu đựng ngữ cảnh nhiễu tốt hơn và vẫn suy luận được trong các tình huống hỗn loạn hơn (cửa sổ ngữ cảnh lớn hơn cũng góp phần hỗ trợ). Nhưng việc chú ý đến tiêu thụ ngữ cảnh vẫn rất quan trọng. Dưới đây là một số tình huống mà nó vẫn có thể trở thành điểm nghẽn:
- Các mô hình nhỏ nhạy cảm hơn với ngữ cảnh. Ứng dụng giọng nói thường dùng mô hình nhỏ hơn, và kích thước ngữ cảnh cũng ảnh hưởng trực tiếp đến độ trễ token đầu tiên, làm chậm phản hồi.
- Các tác vụ “ngốn token” nặng. Các giao thức MCP (Model Context Protocol – Giao thức ngữ cảnh mô hình) như Playwright và đầu vào ảnh sẽ “ăn sạch” token rất nhanh, khiến bạn sớm rơi vào trạng thái “nén phiên hội thoại” trong Claude Code hơn dự kiến.
- Agent tích hợp hàng chục công cụ: mô hình dành nhiều token để phân tích định nghĩa công cụ hơn là để làm việc thực tế.
Một điểm tổng quát hơn: kỹ nghệ ngữ cảnh không biến mất, mà đang tiến hóa. Trọng tâm đã chuyển từ việc lọc ngữ cảnh xấu sang đảm bảo ngữ cảnh đúng xuất hiện đúng lúc. Chính sự chuyển dịch này dọn đường cho bậc 4.
Bậc 4: Kỹ nghệ tích lũy
Kỹ nghệ ngữ cảnh cải thiện chất lượng phiên hội thoại hiện tại. Kỹ nghệ tích lũy (Compounding Engineering, do Kieran Klaassen đề xuất) cải thiện chất lượng mọi phiên hội thoại sau này. Quan niệm này đã là bước ngoặt đối với tôi và nhiều người khác — giúp chúng ta nhận ra rằng “lập trình theo cảm tính” (intuition-based programming) không chỉ đơn thuần là xây dựng nguyên mẫu.
Đây là một chu trình “lập kế hoạch – ủy quyền – đánh giá – tích lũy”. Bạn lập kế hoạch cho nhiệm vụ, cung cấp cho LLM đủ ngữ cảnh để nó thành công. Bạn ủy quyền thực hiện. Bạn đánh giá kết quả. Và bước then chốt — bạn tích lũy những gì học được: cái gì hiệu quả, cái gì sai, lần sau nên tuân theo mẫu nào.
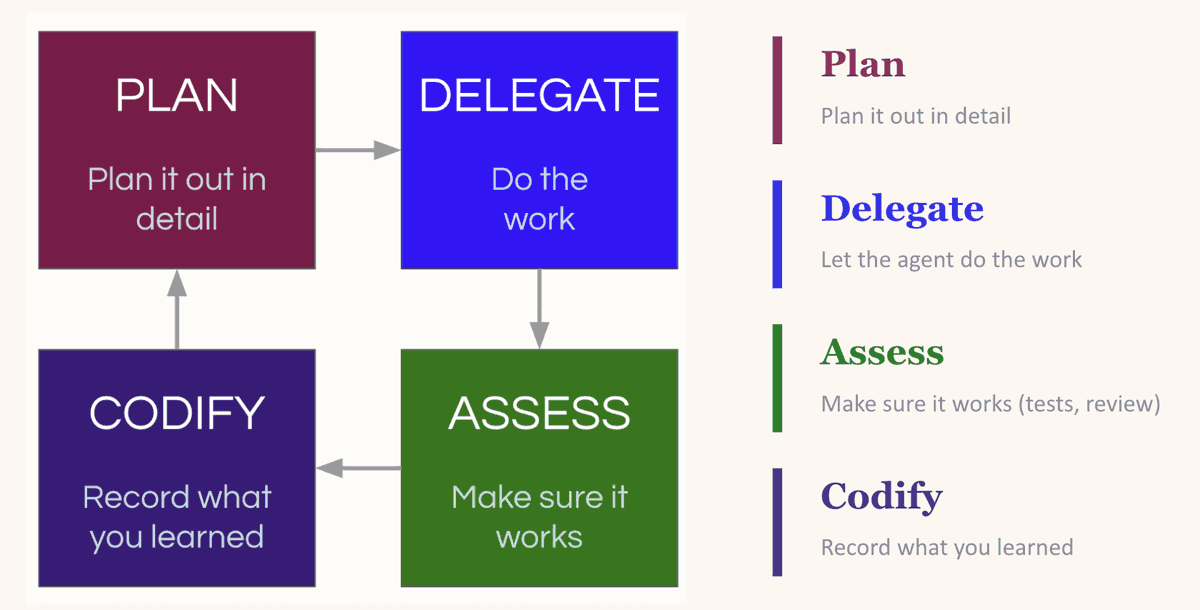
Chu trình tích lũy: lập kế hoạch – ủy quyền – đánh giá – tích lũy — mỗi vòng đều khiến vòng sau tốt hơn
Phép màu nằm ở bước “tích lũy”. LLM là vô trạng thái (stateless). Nếu hôm qua nó vô tình đưa lại một phụ thuộc mà bạn đã chủ động loại bỏ, thì ngày mai nó vẫn sẽ làm thế — trừ khi bạn bảo nó đừng làm vậy. Cách phổ biến nhất là cập nhật tệp CLAUDE.md (hoặc tệp quy tắc tương đương), để khắc ghi bài học vào mọi phiên hội thoại trong tương lai. Nhưng hãy lưu ý: xu hướng đổ hết mọi thứ vào tệp quy tắc có thể phản tác dụng (quá nhiều chỉ dẫn đồng nghĩa với không có chỉ dẫn nào). Cách tốt hơn là tạo dựng một môi trường giúp LLM dễ dàng tự phát hiện ngữ cảnh hữu ích — ví dụ: duy trì thư mục docs/ được cập nhật liên tục (sẽ trình bày chi tiết ở bậc 7).
Những người thực hành kỹ nghệ tích lũy thường cực kỳ nhạy cảm với ngữ cảnh họ truyền vào LLM. Khi LLM mắc lỗi, phản xạ đầu tiên của họ là suy đoán liệu có thiếu ngữ cảnh nào không, chứ không đổ lỗi cho mô hình. Chính trực giác này tạo tiền đề cho các bậc 5–8.
Bậc 5: MCP và kỹ năng
Bậc 3 và 4 giải quyết vấn đề ngữ cảnh. Bậc 5 giải quyết vấn đề năng lực. MCP và các kỹ năng tùy chỉnh cho phép LLM truy cập cơ sở dữ liệu, API, đường ống CI, hệ thống thiết kế, Playwright để kiểm thử trình duyệt, Slack để thông báo… Mô hình giờ đây không chỉ “suy nghĩ” về cơ sở mã của bạn — mà có thể trực tiếp “thao tác” trên nó.
Các tài liệu chất lượng cao về MCP và kỹ năng đã khá phong phú, nên tôi sẽ không giải thích lại chúng là gì. Tôi chỉ nêu vài ví dụ thực tế: đội của chúng tôi chia sẻ một kỹ năng kiểm tra PR, cùng nhau lặp lại và cải tiến (vẫn đang tiếp tục), kỹ năng này sẽ khởi chạy các sub-agent có điều kiện dựa trên đặc điểm của PR. Một sub-agent kiểm tra tính an toàn khi tích hợp với cơ sở dữ liệu, một cái khác phân tích độ phức tạp để đánh dấu các phần dư thừa hoặc thiết kế quá mức, còn một cái nữa kiểm tra “sức khỏe prompt” nhằm đảm bảo prompt tuân thủ định dạng chuẩn của đội. Nó cũng chạy linter và Ruff.
Tại sao lại đầu tư nhiều vào kỹ năng kiểm tra? Bởi khi agent bắt đầu sản xuất PR hàng loạt, việc kiểm tra thủ công sẽ trở thành điểm nghẽn chứ không còn là rào cản chất lượng. Latent Space đã đưa ra lập luận thuyết phục: hình thức kiểm tra mã quen thuộc của chúng ta đã chết. Thay vào đó là kiểm tra tự động, nhất quán và do kỹ năng điều khiển.
Về MCP, tôi dùng Braintrust MCP để LLM có thể truy vấn nhật ký đánh giá và trực tiếp thực hiện sửa đổi. Tôi dùng DeepWiki MCP để agent truy cập tài liệu của bất kỳ kho mã nguồn mở nào, mà không cần kéo thủ công tài liệu vào ngữ cảnh.
Khi nhiều người trong đội bắt đầu viết các kỹ năng tương tự riêng lẻ, đã đến lúc tích hợp chúng thành một registry chung. Block (xin chia buồn) có bài viết rất hay: họ xây dựng một thị trường kỹ năng nội bộ với hơn 100 kỹ năng, đồng thời lựa chọn gói kỹ năng riêng cho từng vai trò và đội nhóm. Kỹ năng và mã nguồn được đối xử như nhau: pull request, kiểm tra, lịch sử phiên bản.
Một xu hướng đáng chú ý khác: LLM ngày càng ưu tiên dùng công cụ CLI thay vì MCP (và dường như mỗi công ty đều đang phát hành CLI riêng: Google Workspace CLI, Braintrust cũng sắp tung ra CLI của riêng mình). Lý do là hiệu quả token. Máy chủ MCP mỗi vòng đều nhồi toàn bộ định nghĩa công cụ vào ngữ cảnh, bất kể agent có dùng chúng hay không. Còn CLI thì ngược lại: agent chạy một lệnh có mục tiêu, chỉ đầu ra liên quan mới vào cửa sổ ngữ cảnh. Chính vì lý do này, tôi dùng agent-browser thay vì Playwright MCP.
Hãy tạm dừng một chút trước khi tiếp tục. Bậc 3–5 là nền tảng cho mọi thứ phía sau. LLM kỳ lạ ở chỗ nó xuất sắc một số việc, nhưng lại kém cỏi một số việc khác; bạn cần rèn luyện trực giác về ranh giới này trước khi chồng thêm các lớp tự động hóa. Nếu ngữ cảnh của bạn nhiễu, prompt thiếu hoặc sai, mô tả công cụ mơ hồ — thì các bậc 6–8 chỉ làm trầm trọng thêm những vấn đề đó.
Bậc 6: Kỹ nghệ Harness
Lúc này tên lửa thực sự cất cánh.
Kỹ nghệ ngữ cảnh tập trung vào việc mô hình “nhìn thấy” gì. Kỹ nghệ Harness (Harness Engineering) tập trung vào việc xây dựng toàn bộ môi trường — công cụ, hạ tầng và vòng phản hồi — để agent có thể vận hành ổn định mà không cần bạn can thiệp. Bạn không chỉ trao cho agent một trình soạn thảo, mà là cả một vòng phản hồi hoàn chỉnh.
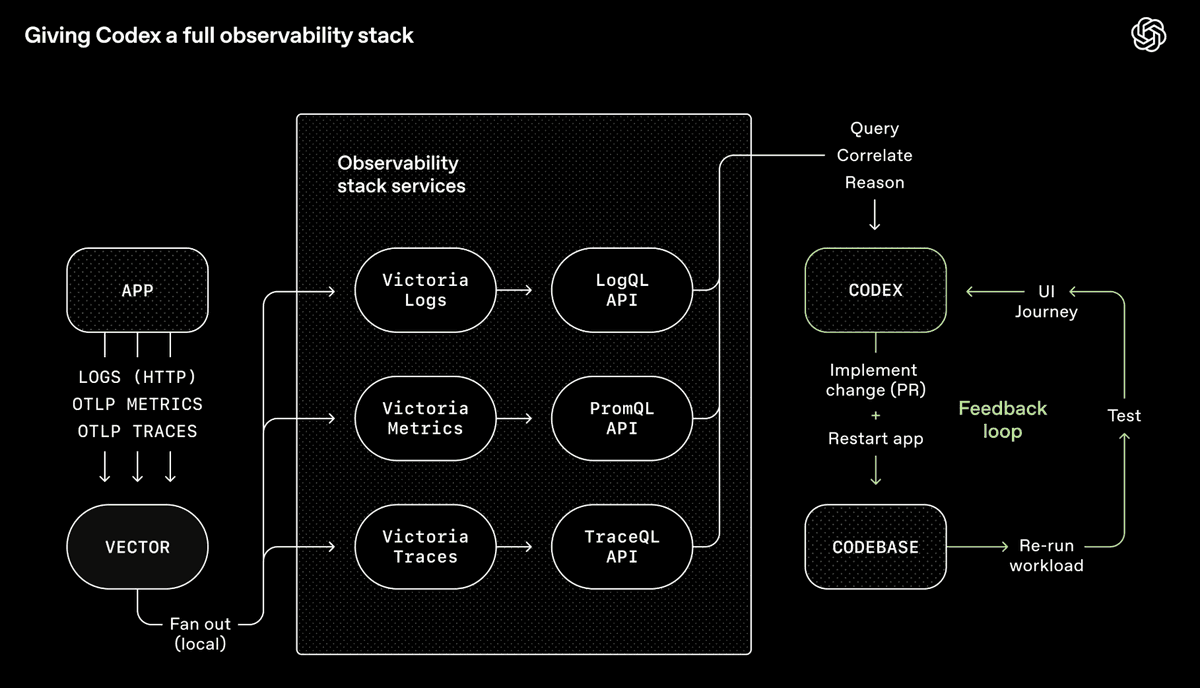
Bộ công cụ Codex của OpenAI — một hệ thống quan sát toàn diện, cho phép agent truy vấn, liên kết và suy luận về đầu ra của chính nó (Nguồn: OpenAI)
Đội Codex của OpenAI tích hợp Chrome DevTools, công cụ quan sát và điều hướng trình duyệt vào runtime agent, giúp nó chụp màn hình, điều khiển luồng giao diện người dùng (UI), truy vấn nhật ký, xác minh kết quả sửa lỗi. Chỉ cần một prompt, agent có thể tái hiện lỗi, ghi video, triển khai sửa chữa. Sau đó, nó xác minh bằng cách thao tác trực tiếp trên ứng dụng, gửi PR, phản hồi phản biện, và merge — chỉ báo cáo lên con người khi cần ra quyết định. Agent không chỉ viết mã, mà còn “nhìn thấy” mã tạo ra hiệu ứng gì, rồi lặp lại để cải tiến — giống như con người.
Đội của tôi phát triển agent xử lý sự cố kỹ thuật qua giọng nói và chat, nên tôi xây dựng một công cụ CLI tên là converse, cho phép bất kỳ LLM nào đều có thể trò chuyện với backend của chúng tôi theo từng vòng hội thoại. Sau khi LLM sửa mã, converse sẽ chạy thử hội thoại trên hệ thống trực tuyến rồi lặp lại. Đôi khi vòng tự cải tiến này chạy liên tục nhiều giờ. Điều này đặc biệt mạnh khi kết quả có thể kiểm chứng: hội thoại phải tuân theo quy trình này, hoặc gọi các công cụ cụ thể trong tình huống nhất định (ví dụ: chuyển sang hỗ trợ nhân sự).
Khái niệm nền tảng cho tất cả là cơ chế phản áp (Backpressure) — cơ chế phản hồi tự động (hệ thống kiểu dữ liệu, kiểm thử, linter, hook pre-commit) giúp agent tự phát hiện và sửa lỗi mà không cần can thiệp con người. Nếu bạn muốn đạt được tính tự chủ, bắt buộc phải có phản áp; nếu không, bạn chỉ có một cỗ máy sản xuất rác. Nguyên lý này cũng mở rộng sang lĩnh vực bảo mật. CTO của Vercel chỉ ra rằng agent, mã do chúng sinh ra và khóa bí mật của bạn phải nằm trong các miền tin cậy khác nhau, bởi một cuộc tấn công chèn prompt vào tệp nhật ký cũng có thể dụ dỗ agent đánh cắp thông tin đăng nhập của bạn — nếu tất cả đều chia sẻ cùng một ngữ cảnh bảo mật. Ranh giới bảo mật chính là phản áp: chúng ràng buộc những gì agent có thể làm khi mất kiểm soát, chứ không chỉ là những gì nó *nên* làm.
Hai nguyên tắc làm rõ hơn tư tưởng này:
- Thiết kế vì thông lượng, không vì sự hoàn hảo. Khi yêu cầu mỗi lần commit đều phải hoàn hảo, agent sẽ xoay vòng mãi trên cùng một lỗi, thậm chí ghi đè sửa chữa của nhau. Cách tốt hơn là chấp nhận các lỗi nhỏ, không chặn luồng, rồi thực hiện kiểm tra chất lượng cuối cùng trước khi phát hành. Chúng ta cũng làm như vậy với đồng nghiệp con người.
- Ràng buộc hiệu quả hơn chỉ dẫn. Việc hướng dẫn từng bước (“làm A trước, rồi B, rồi C”) đang dần lỗi thời. Theo kinh nghiệm của tôi, việc xác định ranh giới hiệu quả hơn việc liệt kê danh sách, bởi agent sẽ bám chặt vào danh sách và phớt lờ mọi thứ ngoài nó. Prompt tốt hơn là: “Đây là kết quả tôi muốn — cứ làm đi cho đến khi vượt qua tất cả các kiểm thử này.”
Một nửa còn lại của Kỹ nghệ Harness là đảm bảo agent có thể tự do điều hướng trong kho mã mà không cần bạn. Cách làm của OpenAI là giữ tệp AGENTS.md dưới ~100 dòng như một bảng mục lục trỏ tới các tài liệu có cấu trúc khác, đồng thời đưa tính cập nhật của tài liệu vào quy trình CI — thay vì phụ thuộc vào các bản cập nhật tạm thời vốn nhanh chóng lỗi thời.
Khi bạn xây dựng xong tất cả những điều trên, một câu hỏi tự nhiên sẽ nảy sinh: Nếu agent có thể tự xác minh công việc, tự do điều hướng trong kho mã, và tự sửa lỗi mà không cần bạn — thì bạn còn cần ngồi trên ghế nữa không?
Lưu ý nhỏ cho những bạn còn ở các bậc đầu: phần tiếp theo có thể nghe như khoa học viễn tưởng (nhưng không sao, hãy lưu lại và quay lại sau).
Bậc 7: Agent nền
Đánh giá thẳng thắn: Chế độ lập kế hoạch đang dần biến mất.
Boris Cherny, người sáng tạo ra Claude Code, hiện vẫn bắt đầu 80% nhiệm vụ ở chế độ lập kế hoạch. Nhưng với mỗi thế hệ mô hình mới ra mắt, tỷ lệ thành công ngay từ lần đầu sau khi lập kế hoạch không ngừng tăng lên. Tôi cho rằng chúng ta đang tiến gần đến ngưỡng tới hạn: chế độ lập kế hoạch như một bước can thiệp thủ công độc lập sẽ dần biến mất. Không phải vì lập kế hoạch không quan trọng, mà vì mô hình đã đủ thông minh để tự lập kế hoạch. Nhưng có một điều kiện tiên quyết quan trọng: điều này chỉ xảy ra khi bạn đã làm tốt các bậc 3–6. Nếu ngữ cảnh của bạn sạch, ràng buộc rõ ràng, mô tả công cụ đầy đủ, và vòng phản hồi khép kín, mô hình sẽ có thể lập kế hoạch đáng tin cậy mà không cần bạn kiểm tra. Nếu chưa làm đủ, bạn vẫn phải “bám” vào kế hoạch.
Để làm rõ hơn: lập kế hoạch như một thực tiễn chung sẽ không biến mất, mà chỉ thay đổi hình thái. Với người mới, chế độ lập kế hoạch vẫn là lối vào đúng đắn (như đã nêu ở bậc 1 và 2). Nhưng với các tính năng phức tạp ở bậc 7, “lập kế hoạch” không còn là viết một dàn ý từng bước, mà giống như khám phá hơn: dò tìm cơ sở mã, thử nghiệm nguyên mẫu trong worktree, thăm dò không gian giải pháp. Và ngày càng nhiều hơn, chính các agent nền đang thay bạn thực hiện những công việc khám phá này.
Điều này rất quan trọng, bởi chính nó mở khóa khả năng của agent nền. Nếu một agent có thể tạo ra kế hoạch đáng tin cậy và thực thi mà không cần bạn ký duyệt, nó có thể chạy bất đồng bộ trong khi bạn làm việc khác. Đây là bước chuyển then chốt — từ “tôi cùng lúc chuyển đổi giữa nhiều tab” sang “có công việc đang tiến triển mà không cần tôi”.
Vòng lặp Ralph là cách phổ biến để bắt đầu: một vòng lặp agent tự chủ, lặp lại việc chạy CLI lập trình cho đến khi hoàn thành mọi mục trong PRD (tài liệu yêu cầu sản phẩm), mỗi vòng lặp khởi chạy một phiên bản mới với ngữ cảnh hoàn toàn riêng. Theo kinh nghiệm của tôi, để chạy tốt vòng lặp Ralph không dễ: bất kỳ mô tả nào trong PRD thiếu hoặc sai đều sẽ phản tác dụng. Nó hơi quá “ném ra rồi mặc kệ”.
Bạn có thể chạy song song nhiều vòng lặp Ralph, nhưng càng khởi chạy nhiều agent, bạn sẽ càng nhận ra mình đang tiêu tốn thời gian vào đâu: phối hợp chúng, sắp xếp thứ tự công việc, kiểm tra đầu ra, thúc đẩy tiến độ. Bạn đã không còn viết mã nữa — bạn đã trở thành một quản lý cấp trung. Bạn cần một agent điều phối để xử lý việc lên lịch, để bạn tập trung vào ý định chứ không phải hậu cần.
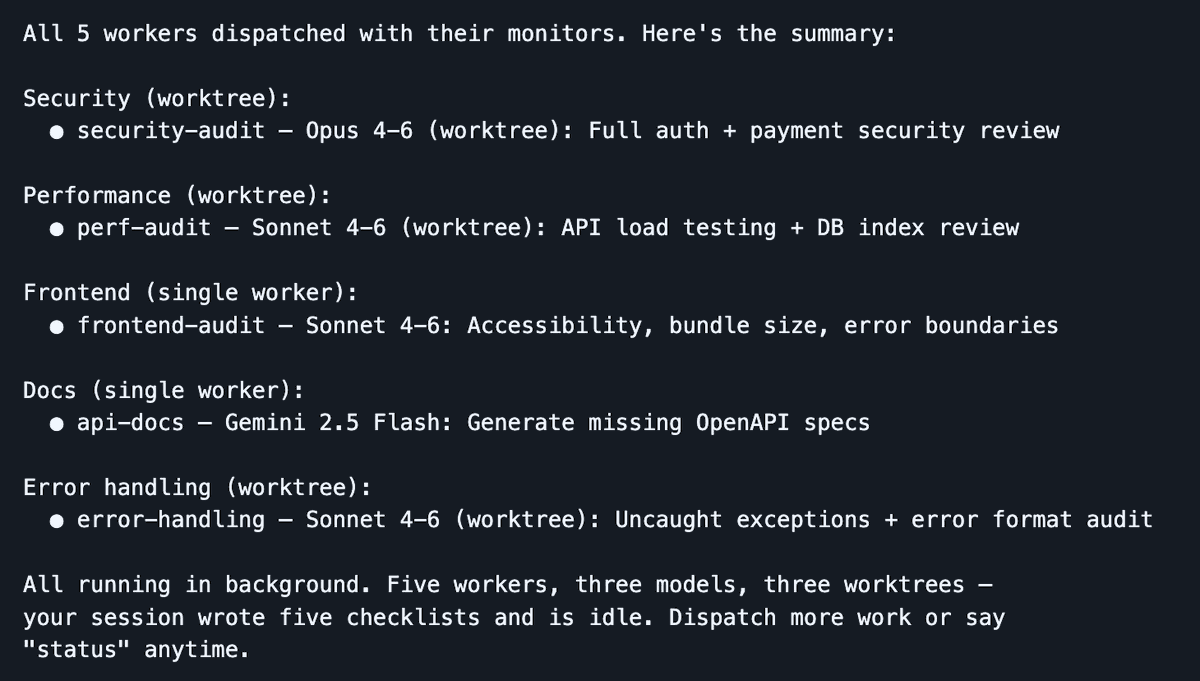
Dispatch khởi chạy 5 worker song song trên 3 mô hình — phiên hội thoại của bạn giữ gọn, agent làm việc
Công cụ tôi đang dùng rất nhiều gần đây là Dispatch, một kỹ năng Claude Code do tôi phát triển, biến phiên hội thoại của bạn thành trung tâm chỉ huy. Bạn ở lại một phiên hội thoại sạch sẽ, còn các worker thực hiện công việc nặng trong ngữ cảnh cách ly. Bộ điều phối đảm nhận lập kế hoạch, ủy quyền và theo dõi, còn cửa sổ ngữ cảnh chính của bạn được giữ lại để điều phối. Khi worker bị kẹt, nó sẽ đặt câu hỏi làm rõ thay vì thất bại im lặng.
Dispatch chạy cục bộ, rất phù hợp với các tình huống phát triển nhanh khi bạn muốn gắn bó chặt chẽ với công việc: phản hồi nhanh hơn, gỡ lỗi thuận tiện hơn, không tốn chi phí hạ tầng. Inspect của Ramp là giải pháp bổ sung, phù hợp với các tác vụ chạy lâu hơn và tự chủ hơn: mỗi phiên hội thoại agent được khởi chạy trong một máy ảo (VM) sandbox trên đám mây, kèm môi trường phát triển đầy đủ. Một PM phát hiện lỗi UI, đánh dấu trong Slack, và Inspect sẽ tiếp nhận xử lý ngay khi bạn đóng laptop. Đổi lại là độ phức tạp vận hành (hạ tầng, chụp ảnh nhanh, bảo mật), nhưng bạn thu được quy mô và khả năng tái hiện mà agent cục bộ không thể sánh kịp. Tôi khuyên bạn nên dùng cả hai (agent nền cục bộ và trên đám mây).
Một mô hình mạnh mẽ đến bất ngờ ở bậc này là dùng các mô hình khác nhau cho các công việc khác nhau. Đội kỹ sư giỏi nhất không được tạo thành từ một nhóm người giống nhau. Thành viên trong đội có tư duy, nền tảng đào tạo và thế mạnh khác nhau. Cùng logic đó áp dụng cho LLM. Các mô hình này trải qua huấn luyện hậu kỳ khác nhau, có đặc điểm tính cách rõ rệt. Tôi thường giao việc triển khai cho Opus, nghiên cứu khám phá cho Gemini, và kiểm tra cho Codex — kết quả tổng hợp mạnh hơn bất kỳ mô hình nào làm một mình. Có thể hiểu đây là “trí tuệ tập thể”, nhưng áp dụng vào mã nguồn.
Vô cùng quan trọng là bạn phải tách biệt vai trò người triển khai và người kiểm tra. Tôi đã vấp phải bài học này quá nhiều lần: nếu cùng một phiên bản mô hình vừa triển khai vừa đánh giá chính công việc của nó, nó sẽ thiên vị. Nó sẽ bỏ qua vấn đề và báo cho bạn rằng mọi việc đã xong — trong khi thực tế thì chưa. Đây không phải do ác ý, nguyên nhân giống như bạn không tự chấm điểm bài kiểm tra của mình. Hãy để một mô hình khác (hoặc một phiên bản khác với prompt kiểm tra chuyên biệt) đảm nhiệm việc kiểm tra. Chất lượng tín hiệu của bạn sẽ tăng mạnh.
Agent nền còn mở ra cánh cửa kết hợp CI với AI. Một khi agent có thể chạy mà không cần người giám sát, chúng ta có thể kích hoạt chúng từ hạ tầng hiện có. Một bot tài liệu tái tạo tài liệu sau mỗi lần merge và gửi PR cập nhật CLAUDE.md (chúng tôi đang dùng cách này, tiết kiệm rất nhiều thời gian). Một bot kiểm tra bảo mật quét PR và gửi sửa chữa. Một bot quản lý phụ thuộc không chỉ đánh dấu vấn đề, mà còn thực sự nâng cấp gói và chạy bộ kiểm thử. Ngữ cảnh tốt, quy tắc được tích lũy liên tục, công cụ mạnh mẽ, vòng phản hồi tự động — giờ đây tất cả đều đang vận hành tự chủ.
Bậc 8: Đội agent tự chủ
Hiện chưa ai thực sự làm chủ bậc này, dù một vài người đang tiến gần tới nó. Đây là biên giới hiện tại.
Ở bậc 7, bạn có một LLM điều phối phân phối nhiệm vụ theo mô hình “trung tâm – vệ tinh” tới các LLM làm việc. Bậc 8 loại bỏ điểm nghẽn này. Các agent phối hợp trực tiếp với nhau — nhận nhiệm vụ, chia sẻ phát hiện, đánh dấu phụ thuộc, giải quyết xung đột — tất cả đều không cần đi qua một người điều phối duy nhất.
Tính năng thí nghiệm Agent Teams của Claude Code là một triển khai ban đầu: nhiều phiên bản chạy song song trên cùng cơ sở mã chung, các “đồng đội” chạy trong cửa sổ ngữ cảnh riêng và giao tiếp trực tiếp với nhau. Anthropic đã dùng 16 agent song song xây dựng từ đầu một trình biên dịch C có thể biên dịch Linux. Cursor đã chạy hàng trăm agent đồng thời trong nhiều tuần, xây dựng từ đầu một trình duyệt và di chuyển kho mã của chính mình từ Solid sang React.
Nhưng nhìn kỹ sẽ thấy vấn đề. Cursor phát hiện khi không có cấu trúc phân cấp, các agent trở nên e dè, xoay vòng tại chỗ mà không tiến triển. Các agent của Anthropic liên tục phá vỡ chức năng hiện có, cho đến khi họ bổ sung đường ống CI để ngăn chặn regression thì tình hình mới cải thiện. Tất cả những người đang thí nghiệm ở bậc này đều nói một điều giống nhau: việc phối hợp đa agent là một bài toán khó, và chưa ai tìm ra lời giải tối ưu.
Thành thật mà nói, tôi không tin rằng mô hình đã sẵn sàng cho mức độ tự chủ này ở đa số tác vụ. Ngay cả khi chúng đủ thông minh, với các dự án “đổ bộ lên mặt trăng” ngoài biên dịch và trình duyệt, chúng vẫn quá chậm, quá tốn token và không hiệu quả về mặt kinh tế (ấn tượng, nhưng xa mới chín muồi). Đối với phần lớn công việc thường ngày của chúng ta, bậc 7 mới thực sự là đòn bẩy mạnh nhất. Tôi sẽ không ngạc nhiên nếu bậc 8 cuối cùng trở thành mô hình chủ đạo, nhưng hiện tại tôi tập trung vào bậc 7 (trừ khi bạn là Cursor — đột phá chính là nghiệp vụ của bạn).
Bậc ?
Câu hỏi “tiếp theo là gì?” là điều không thể tránh khỏi.
Một khi bạn có thể điều phối đội agent một cách nhuần nhuyễn mà không gặp nhiều ma sát, thì giao diện tương tác không còn lý do gì để giới hạn ở văn bản. Tương tác giọng nói – giọng nói (hay thậm chí là tư duy – tư duy?) với agent lập trình — Claude Code mang tính hội thoại, chứ không chỉ là đầu vào chuyển giọng nói thành văn bản — là bước tiếp theo tự nhiên. Nhìn vào ứng dụng của bạn, mô tả to một chuỗi thay đổi, rồi chứng kiến chúng hiện hữu ngay trước mắt.
Một nhóm người đang theo đuổi việc sinh mã hoàn hảo một lần: nói ra điều bạn muốn, AI sẽ hoàn thành xuất sắc ngay lập tức. Vấn đề nằm ở giả định nền tảng này — rằng con người biết rõ mình muốn gì. Nhưng chúng ta không biết. Chưa bao giờ biết. Phát triển phần mềm luôn là quá trình lặp đi lặp lại, và tôi tin rằng nó sẽ mãi như vậy. Chỉ là nó sẽ trở nên dễ dàng hơn rất nhiều, vượt xa tương tác thuần văn bản, và nhanh hơn rất nhiều.
Vì vậy: Bạn đang ở bậc nào? Bạn đang làm gì để tiến lên bậc tiếp theo?
Bạn đang ở bậc nào?
Bạn thường bắt đầu một nhiệm vụ lập trình với AI như thế nào?
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













