

Người sáng lập SemiAnalysis phân tích cuộc cạnh tranh AI nghìn tỷ đô la: Công suất tính toán là tiền tệ trong thế giới AI, Nvidia là "ngân hàng trung ương"
Tuyển chọn TechFlowTuyển chọn TechFlow
Người sáng lập SemiAnalysis phân tích cuộc cạnh tranh AI nghìn tỷ đô la: Công suất tính toán là tiền tệ trong thế giới AI, Nvidia là "ngân hàng trung ương"
AI không chỉ là cuộc cách mạng thuật toán, mà còn là một cuộc di cư công nghiệp do năng lực tính toán, vốn và địa chính trị cùng thúc đẩy.
编译:Grace
编辑:Siqi

在 AI 带来的新一轮全球基础设施重构中,算力、资本与能源正以前所未有的方式交织在一起。
本文是 SemiAnalysis 创始人兼 CEO Dylan Patel 在 Invest Like The Best 的最新访谈。Dylan Patel 是业内最知名的 AI 与半导体分析师之一,他和团队长期跟踪半导体供应链和 AI 基建,甚至通过卫星影像监测数据中心的建设,非常熟悉前沿技术的发展进程,具有极强的行业影响力。
在采访中,他从产业链、能源网络与资本流动出发,勾勒出一个极少被公开讨论的事实:AI 不只是算法革命,而是一场由算力、资金与地缘政治共同驱动的产业迁徙。
• 算力—资本—基础设施正形成闭环,算力就是 AI 时代的货币;
• 谁掌控数据、接口与切换成本,谁就拥有了 AI 市场的话语权;
•Neo clouds 与推理服务商承担最大的需求与信用不确定性,而稳定利润最终流向英伟达;
•Scaling Law 不会出现边际效益递减现象;
• 模型“更大”不等于“更聪明”,真正进步来自模型算法或者架构的优化、模型推理时间的延长;
•在 AI Factory 范式下,企业竞争的关键因素在于用最低 token 成本提供稳定、可规模化的智能服务;
•硬件创新的重心在芯片互联、光电与电力设备等老工业环节,因此能真正推动硬件创新的仍是巨头。
01.AI 掌控之争:谁在博弈?如何取胜?
三千亿美元的三角交易是什么?
在当下的 AI infra 竞赛中,OpenAI–Oracle–Nvidia 之间形成了一个独特结构性合作,这一交易模式被市场称为“三角交易(Triangle Deal)”,三方在资金流与产能上形成了深度捆绑。
•OpenAI 向甲骨文购买云服务;
•甲骨文作为硬件基础设施供应商,负责建设并运营庞大的数据中心,因此需要向英伟达采购大量的 GPU 芯片,资金会在很大程度上流回英伟达;
•之后,英伟达再将自身部分利润以战略投资的形式返还给 OpenAI,支持 OpenAI 的 AI 基础设施建设。
2025 年 6 月,甲骨文 Orcl 首次披露与 OpenAI 的重大云服务交易,OpenAI 将在未来五年内向甲骨文购买总额约 3000 亿美元的算力服务(年均支出约 600 亿美元),监管文件显示,这项协议将在 2027 财年起,为甲骨文带来超过 300 亿美元收入,这成为史上规模最大的云端合约之一。
2025 年 9 月,英伟达宣布将向 OpenAI 投资最高 1000 亿美元,双方将合作建设至少 10 吉瓦的 AI 数据中心,用于训练与运行下一代模型,耗电量相当于 800 万户美国家庭。英伟达股价当日上涨超 4%,市值逼近 4.5 万亿美元。
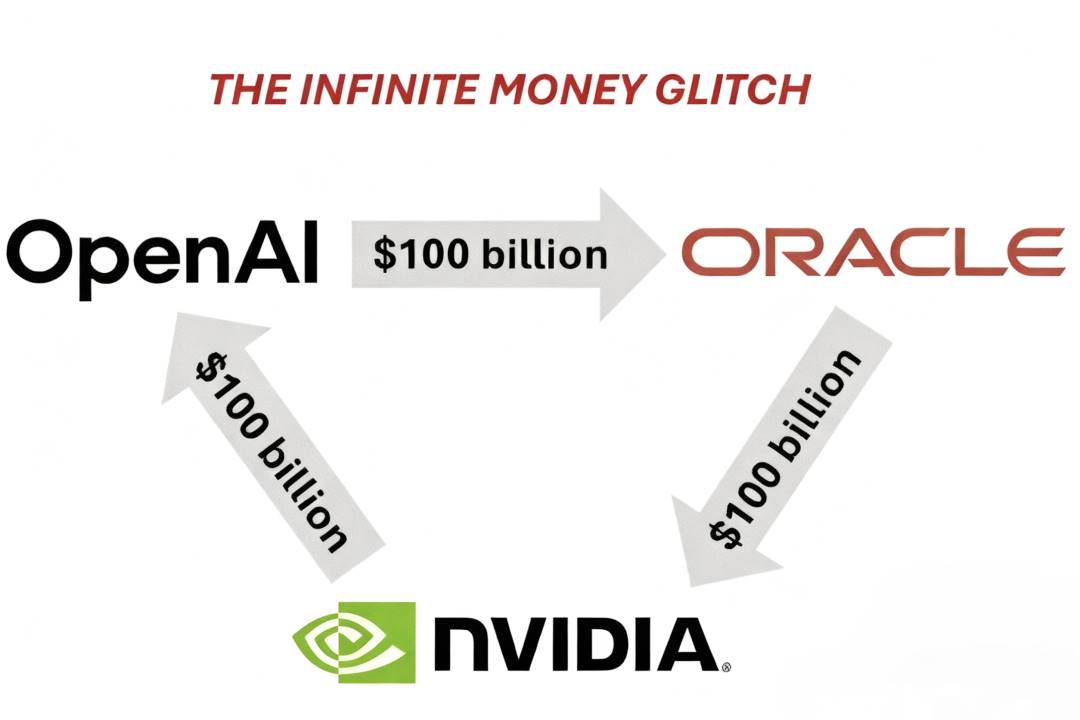
按照 Dylan 的估算,1GW 数据中心的建设成本约为每年 100–150 亿美元,合同期一般为 5 年,总额约在 500–750 亿美元之间。如果 OpenAI 的目标是构建 10GW 级别的计算集群,那么总资金需求将达到数千亿美元规模。
以 Nvidia 与 OpenAI 的交易为例,1GW 集群对应约 100 亿美元的 Nvidia 股权投资,但完整建设一座 1GW 级别的 AI 数据中心的总成本约为 500 亿美元,其中会有大约 350 亿美元直接流向 Nvidia,这部分的毛利率高达 75%。换句话说,Nvidia 实际上将一半的毛利转化为 OpenAI 的股权,达成一种结构性让利。
这一三角交易不仅是对算力稀缺的回应,更代表了 AI 行业资本化的新阶段:在这个阶段,算力成为新的货币,基础设施成为价值分配的高地,技术创新的速度被金融结构不断放大。
数据、接口与切换成本:掌控 AI 市场话语权的关键
AI 产业的竞争表面上是模型与平台之争,实质上是权力链条的重构。Dylan 认为,谁掌控数据、接口与切换成本,谁就掌控了 AI 市场的话语权。
以 Cursor与 Anthropic 为例,表面上 Anthropic 作为模型提供方赚取了大部分毛利,但 Cursor 作为应用方掌握了用户与代码库数据,且可在多模型之间自由切换,最终仍保有议价空间。
这种博弈也存在于 OpenAI 与微软之间。2023 年,微软几乎完全掌控 OpenAI 的算力与资本合作,但到了 2024 年下半年,为避免承担约 3000 亿美元的长期支出,微软暂停了部分数据中心建设,放弃独家算力供应,OpenAI 转向了 Oracle。OpenAI 与微软目前正就利润分配(微软的封顶利润为 49%)和知识产权共享进行重新谈判,双方的控制权正从以微软为主逐渐转向更加平衡的合作关系。
在硬件层面也是如此,Nvidia 无法通过并购来扩大控制力,只能依靠资产负债表来“兜底”——通过需求担保、回购协议,甚至提前分配算力等方式巩固自身生态体系。Dylan 将这一过程称为“GPU 货币化”:GPU 已成为整个 AI 行业的通用货币,而 Nvidia 则像一座中央银行,通过融资与供给规则来掌控流通。
这种前置分配机制还被大量复制——Oracle、CoreWeave 等公司都在向合作伙伴提供“首年免付算力窗口”,让对方能够先行进行模型训练、获得推理补贴、扩大用户规模,再在随后的四年内以现金流方式偿还成本。
由此,AI 行业形成了一个跨越硬件—资本—云服务—应用的多层权力链条。算力、资金与信用在这条链上循环流转,构成 AI 世界的金融基础设施。
Neo Clouds:AI 产业链的新商业分层
Nebius、CoreWeave 的崛起本质上是 AI 产业链正在形成一个新的商业分层:Neo Clouds 介于芯片制造、云算力等底层供给与大模型、应用产品等上层生态之间,承担着算力租赁、模型托管与推理服务的角色。
Neo Clouds 有两种模式:
1. 短期合同:
通过购买 GPU、搭建数据中心,用高溢价租出算力。这一模式现金流充足但价格风险极高。以英伟达 Blackwell 为例,如果按六年摊销计算,每小时算力成本约 2 美元,短期合同可卖到 3.5 至 4 美元,利润非常高。但当下一代芯片发布之后,芯片性能提升了十倍,价格仅提高了三倍,这类资产价值就会迅速下滑。
2. 长期绑定:
通过多年期合同锁定客户。这一模式毛利稳定但非常依赖对手方信用,如果无法履约,风险将集中落在 middle layer players 身上:
•Nebius 与 Microsoft 签订了一份 190 亿美元的长期合同,确保了稳定的现金流和高额利润,市场甚至认为这个信用水平高于美国国债;
•CoreWeave 早期主要依赖微软的订单,是微软重要的算力合作伙伴。后来,Microsoft 减少了采购规模,CoreWeave 转而与 Google 和 OpenAI 建立合作关系,向这些公司提供 GPU 计算资源和数据中心服务。这让它在短期内维持了高利润,但也带来了新的风险,尤其是 OpenAI 的偿付能力不足,让这些合同的长期稳定性存在隐忧。
Inference Providers 也在 Neo Clouds Business Model 中寻找到了新的增长空间。它们为客户提供模型托管和高效推理服务,主要面向 Roblox、Shopify 等企业。这些企业虽然具备自建模型的能力,但推理部署过程往往非常复杂,尤其是在大模型和多任务场景下。Inference Providers 通过提供开源模型微调、稳定算力和可靠服务,成为整个系统运行中的关键一环。
Inference Providers:提供模型推理服务的第三方平台或企业,是已经部署了某个模型并允许用户通过 API 或其他接口使用这个模型的服务商,也就是说用户可以付费使用这些服务商提供的 API。
然而,这些 Inference Providers 自身也处于高度不确定的环境中。它们的客户多为资金有限的初创企业或中小型 SaaS开发者,项目周期短、合同履约风险高,一旦资金链断裂,风险便会层层传导。最终,产业链的利润依然集中在英伟达:它通过销售 GPU 实现稳定收益,却几乎不受市场波动影响。所有的不确定性与信用风险,都由 Inference Providers 来承担。
AI 军备竞赛
Dylan 同样认为,AI 已成为新的战略赛道,尤其在大国博弈的语境下,竞争不再局限于技术维度,而是国家经济与体系的整体对抗。尤其对美国而言,AI 是维持其全球主导地位的最后关键点,如果没有这场 AI 浪潮,美国可能会在本世纪末失去世界霸权。
今天来看,美国社会的增长动力正在枯竭:债务高企、制造业回流缓慢、基础设施老化,而 AI 是唯一能让经济重新进入增长通道的加速器。因此,美国必须依靠 AI 来维持 GDP 扩张、控制债务风险并延续制度秩序。当前,美国的模式依然建立在资本市场与创新驱动之上,依靠开放生态与私营部门的巨额投入,通过超大规模算力建设维持领先地位。
中国采取的则是截然不同的长期战略。中国政府常以“以亏损换份额”的方式推动产业崛起,无论是钢铁、稀土、太阳能、电动车,还是 PCB 行业,中国都依靠国家资本与政策扶持,逐步取得全球市场份额。如今,这一模式被复制到半导体与 AI 领域。中国政府通过“五年规划”、“国家大基金”及地方财政政策,对半导体产业的累计投入已达 400–5000 亿美元。这些投资的目标并不是要实现性能领先,而是要构建完整、可控的供应链体系,实现从材料到封装的全链自给,来确保地缘紧张环境下的产业安全。
同时,在执行层面,中国展现出显著的速度优势与组织动员能力。如果中国决定建设一个 2–5GW 级的数据中心,可能只需数年,而美国在同等规模的建设上通常需要两到三倍时间。
02.AI 技术路线讨论
Scaling Law 不会出现边际效益递减现象
Dylan 不认为 Scaling Law 会出现边际效益递减的现象。在对数-对数坐标下,即使没有模型架构的改进,只要不断增加计算量、数据量和模型规模,模型的性能仍会按一定的速度提升。
Dylan 将这种现象比作人类智能的成长曲线:人类从 6 岁到 16 岁的变化不是连续加法,而是阶段性的跨越。换句话说,模型的智能提升是质变式的,虽然实现下一个阶段的能力可能需要投入 10 倍算力,但带来的经济回报足以支撑这种投入。
但 Scaling Law 也隐含着风险。当模型规模与算力投入暴涨到数千亿美元级别后,如果算法创新停滞或推理效率下降,投资回报率会迅速塌陷。所以,Dylan 认为,必须在巨额投入与时间窗口之间精准押注才能成为赢家。如果 Scaling Laws 的回报消失,整个行业可能面临系统性过度建设的风险。
Scaling Laws 不仅是技术议题,更是资本结构问题。它迫使企业在“模型更大”与“模型更可用”之间做出抉择:过大模型意味着推理成本高企、延迟难降、用户体验下降,而适度规模化则能兼顾效率与可服务性。这种平衡成为当前 AI 工程最核心的挑战之一
如何平衡 Inference Latency 与 Capacity?
几乎所有 AI 工程问题都可以理解为是在一条曲线上的权衡,其中 inference latency 与 capacity 是最关键的平衡点。比如在硬件层面,GPU 可以在一定范围内降低延迟,但成本会急剧上升;反之,追求高吞吐量则会牺牲响应速度。企业必须在用户体验与资金压力之间找到平衡点。
Dylan 认为,如果有一个“魔法按钮”可以同时解决 inference latency 与 capacity 的问题,AI 模型的潜能将被彻底释放。但现实中,cost 仍是首要约束,推理速度已经足够快,而算力却严重不足。 即便我们现在能训练出比 GPT-5 大 10 倍的模型,也无法为这个模型提供稳定的部署。因此,OpenAI 等公司需要思考这样一个问题:是推出一个人人可用的高速模型,还是发布一个更强但昂贵的模型?同时,这也意味着,AI 的发展不仅受限于硬件性能,还取决于人类愿意接受怎样的使用体验。
但模型性能的真正突破并不完全取决于“更大”,单纯把模型规模变化会面临“过参数化(over-parameterization)”的陷阱:当模型规模持续扩大而数据量没有同步增长时,模型只是在“记忆”数据,而非真正“理解”内容。真正的智能源自 grokking,也就是顿悟式的理解,就像人类从死记硬背到真正领会知识的瞬间。
可交互环境是 RL 发展的新方向
如前文所述,当今的挑战已不再是如何让模型更大,而是如何构建更高效的数据与学习环境。过去,人类只是采集并过滤互联网数据,但互联网上没有教人只用键盘操作 Excel 的教程,也缺乏关于数据清洗或业务流程的真实训练素材,模型无法仅凭阅读互联网获取这些能力,因此模型需要新的体验式学习空间。
为模型构建可交互的环境就是 RL 发展的新方向,这些环境可能是虚拟电商平台,让模型学会浏览、比较、下单;也可能是数据清洗任务,让模型可以在无数格式中反复尝试、逐步优化;甚至可以是游戏、数学谜题或医学案例,模型通过不断试错、验证与反馈,逐步形成真正的理解能力。Dylan 表示,湾区目前已有数十家初创公司专注构建 AI 学习环境。
而且,在 Dylan 看来,当下的 AI 所处的发展阶段只是“我们刚投出的一球”。AI 依旧像一个婴儿,还需要通过不断的尝试与失败来校准感知。就像人类在成长中会遗忘大量无用信息,仅保留少数关键经验,AI 模型也会在训练中生成大量数据,却只保留极少部分。因此,要让模型真正理解世界,必须让它进入环境中学习。
有些研究者认为,通向 AGI 的关键是具身化(embodiment),即让模型能够与物理世界互动。这种理解无法通过视频或文本获得,而需通过行动与反馈实现,因此 RL 的重要性将持续上升。
值得注意的是,Dylan 认为,在传统的训练范式中,AI 是通过数据去“读懂世界”,而在 post-training 时代,AI 应该在环境中去“创造世界”。如前文所说,模型规模的扩大并不意味着智能的增长。真正的突破来自算法和架构的优化,让模型能以更少的算力、更高的效率完成学习。因此,虽然 pre-training 依然是 AI 发展的基础,但 post-training 将成为未来算力消耗的主要来源。
Dylan 表示,随着 RL 的成熟,AI 将从“回答问题”走向“直接行动”。未来,AI 可能不再只是帮用户决策,而是能在电商平台上直接为他们下单。事实上,人类已经在不知不觉中把部分决策外包了 AI,从 Uber Eats 的首页推荐到 Google Maps 的路线规划。如今已有迹象显示这一趋势正在加速:Etsy超过 10% 的流量直接来自 GPT,如果亚马逊没有屏蔽 GPT,这一比例可能更高。OpenAI 的应用团队也在推进 shopping agent,作为商业化的核心路径。
而这种“执行智能”也将催生新的商业模式——AI 执行抽成。未来的平台可能像信用卡体系一样,从 AI 的执行环节中收取 0.1% 或者 1% 的费用,从而形成巨大的利润空间。
模型的记忆系统不必模仿人脑
在算力有限的前提下,“推理时间”成为提升模型能力的另一条路径:在模型规模不变的情况下,通过延长思考步数和推理深度,模型可以获得显著性能提升。
Dylan 认为,Transformer 架构的 attention 机制使模型在有限上下文中具备较强的回溯与关联能力,但在长上下文和稀疏记忆(sparse memory)场景下仍存在明显瓶颈。随着上下文窗口不断扩大,内存与带宽的压力急剧上升,HBM已成为支撑大模型推理的关键资源。这一趋势正在驱动新一轮底层创新,未来模型性能的突破将取决于更高效的存储架构与多芯片互连共享机制,从而缓解当前系统在长上下文处理中的物理限制。
Now, models are amazing. But what they really suck at is having infinite context....This is a big challenge with reasoning. This is why we had this HBM bullish pitch for a while. You need a lot of memory when you extend the context. Simple thesis.——Dylan Patel
但 Dylan 并不认为模型的记忆系统必须模仿人脑,外部写作空间、数据库、甚至文档系统都可以成为模型的外部记忆,关键在于让模型学会如何写入、提取、复用信息,从而在任务过程中建立长期语义关联。
OpenAI 的 Deep Research 就是这一理念的实践。它让模型能够在较长时间内持续生成中间文本,不断进行压缩与回看,从而完成复杂的分析与创作任务。Dylan 将这一过程形容为“人工推理的显微镜”,它展示了 agent 未来可能的工作方式,也就是在长时记忆与短时计算之间持续循环,从而实现真正意义上的“思考”。
Dylan 认为这种新型的推理与记忆框架,将彻底改变算力需求结构。未来的百万 GPU 集群,不仅用于训练更大的模型,更用于支撑这些长思考的 agent。
能真正推动硬件创新的仍是巨头
• 半导体制造(semiconductor manufacturing)
当今的半导体制造的难度已进入“太空时代级别”,成为人类工程中最复杂的系统之一,但背后的软件体系仍然滞后。即便是一台价值数亿美元的制造设备,仍依赖过时的控制系统和低效的开发工具。
即便英伟达已占据半导体行业的领先地位,它的供应链中仍保留着大量旧时代的部件。以电力系统为例,变压器的基本工作原理几十年来几乎未曾改变。而如今,真正的创新正在发生在固态变压器上:它们能将超高压交流电逐级转换为芯片可用的低压直流电,大幅提升能源利用效率。正是这些看似传统的工业环节,正在成为 AI 基础设施新的利润与创新源头。
但 Dylan 并不看好加速器公司(accelerator companies),也就是那些试图与英伟达、AMD、谷歌 TPU 或亚马逊 Trainium 竞争的新兴芯片公司。在他看来,这个行业资本密集、风险极高、技术创新空间有限。除非出现一次真正突破性的硬件跃迁,否则这些新玩家几乎不可能撼动现有格局。
•芯片互联(networking between chips)
随着模型上下文长度不断增加,内存需求激增。由于 DRAM行业创新受限,相比之下,反而是在网络层面更容易取得突破:
1. 通过紧密互连实现芯片间的内存共享,例如英伟达在 Blackwell 架构中的 NVL72 模块,已将大规模网络互连能力集成于单一系统,显著提升了数据交换效率;
2. 光学互连(optics space)仍是关键前沿,如何在电信号与光信号之间实现更高效的转换与传输,将直接决定下一代数据中心的性能上限。
3. 在极端性能条件下,Blackwell 的超高带宽互连也让系统在可靠性与散热方面逼近物理极限:同一机架中的每颗芯片都能以每秒 1.8TB 的速率与其他芯片通信。
Dylan 认为,芯片互联领域仍存在大量创新空间,并对硬件技术的持续进步极度乐观。但是需要注意的是,产业内部的结构性问题正在阻碍效率:
1. 英特尔落后的部分原因在于内部缺乏数据共享文化,比如光刻团队与刻蚀团队往往拒绝共享实验数据,这些数据也无法上传至云端(如 AWS)进行关联分析,导致整体的学习与迭代效率极低;
2. 台积电虽在制造能力上更强,但同样不允许数据外发,实验与分析流程也很缓慢。
而要打破这一障碍,则需要改变企业文化。比如,陈立武正在推动这种转变,希望能让制造企业更加开放地利用自身数据,构建更好的仿真器,并以更高精度模拟现实世界。
• 世界模型(world model)
世界模型(World Model)的核心思想,是让 AI 具备模拟世界的能力。这一概念不仅适用于软件层面,也正在向物理层扩展。以 Google 的 Genie 3 为例,模型可以在虚拟环境中自由移动、观察并与物体互动;而更先进的模型则能够模拟分子反应、流体动力或火焰燃烧等复杂过程,用 AI 的方式去学习和重构物理规律。
这一领域的公司也正在快速涌现,其中一些专注于机器人训练,另一些则聚焦在化学和材料的模拟。这类公司使 AI 不再仅仅是语言处理系统,而成为理解和模拟现实的计算框架。受此影响,机器人和物理仿真再次成为近期的创业和投资的焦点。但 Dylan 认为,能真正推动世界模型与硬件创新的,仍是那些巨头公司:台积电、英伟达、安费诺等。
But also I think most of the cool innovation is just happening at big companies or already existing companies. ——Dylan Patel
03.AI 算力,人才和能源
算力是工业产能,token 是产品单元
Nvidia 提出的 AI Factory 概念是 AI 行业的经济学基石。与传统工厂生产物质产品不同,智能工厂生产的是智能(intelligence),也就是通过算力生成的 token。Dylan 形象打了一个比喻:“一座 AI Factory 输出的不是电,而是智能本身。”
AI Factory:由 Marco Iansiti 和 Karim R。 Lakhani 于 2020 年在 Competing in the Age of AI 中提出。它指一种专用计算基础架构,能够覆盖整个 AI 生命周期,从数据获取、训练、微调,到大规模推理,从而将数据转化为价值。AI Factory 的核心产品是智能,产出以 token 传输量衡量,这些传输量推动决策、自动化以及全新的 AI 解决方案。
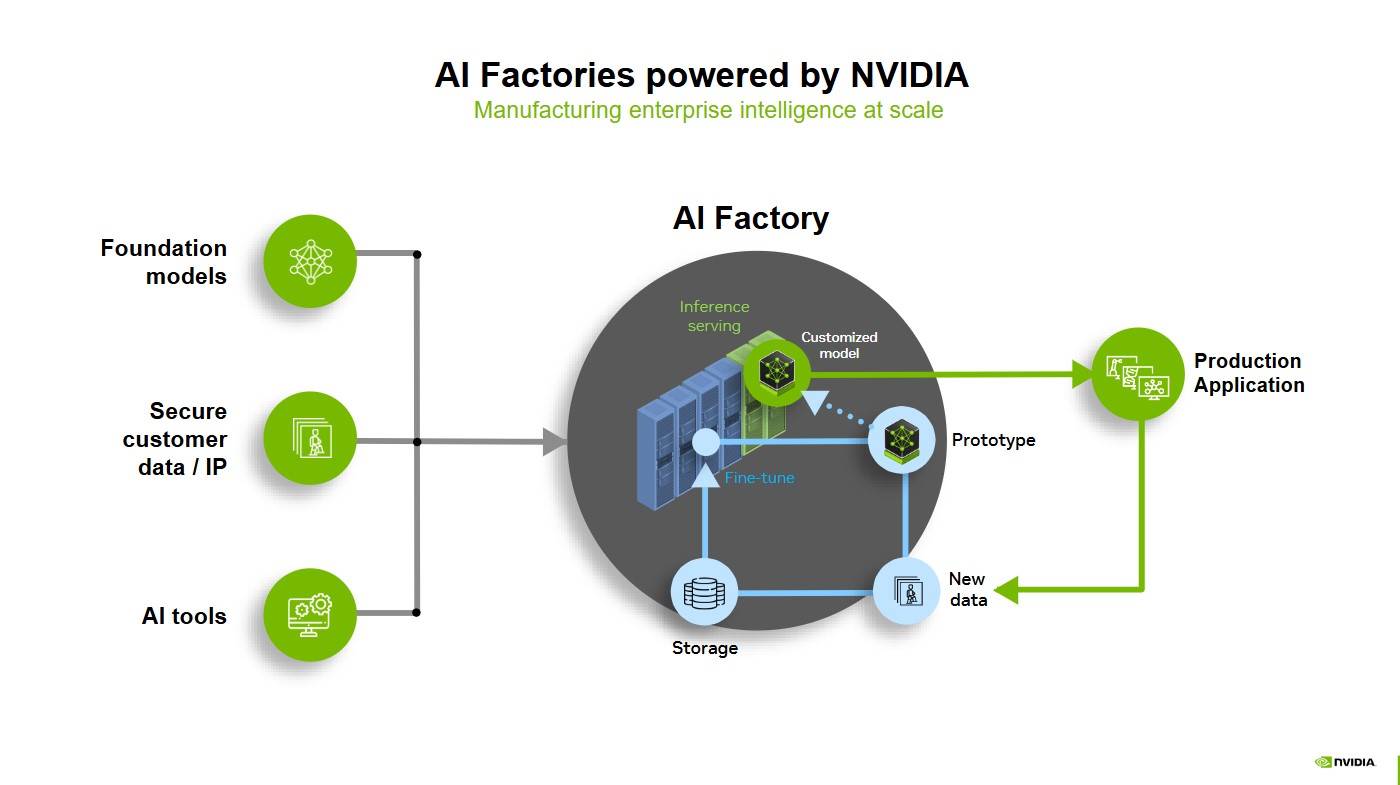
在 AI Factory 的概念下,每个 token 都体现了计算能力、算法效率与能源投入的成果。AI 企业要解决的问题不再是造出最强模型,而是如何在相同功率下实现最优的 token 产能配置。这意味着需要在“多次调用较弱模型”与“少量调用强模型”之间做出权衡。算力分配、模型规模、用户数量以及推理延迟等因素,共同决定了 AI 工厂的经济效率。
近两年来,算法优化显著降低了模型的服务成本。例如,对于 GPT-3 级别的推理,成本已比两年前下降约 2000 倍,但成本的下降并没有带来 AI 普及速度的提升,因为算力依然是稀缺资源。因此,在 GPT-5 阶段,OpenAI 选择保持与 GPT-4 相近的模型规模和推理成本,来提高“思考模式”下的推理效率,让更多用户能够实际使用,而不是盲目追求更大模型。
Dylan 认为,算力是工业产能,token 是产品单元。未来的竞争不在于谁训练了最大的模型,而在于谁能以最低的 token 成本提供稳定、可规模化的智能服务。
能高效使用 GPU 的人比 GPU 更稀缺
虽然 GPU 非常稀缺,但更稀缺的是能高效使用 GPU 的人。
每一次无效实验都意味着大量算力的浪费,因此,能够将算力利用率提高 5% 的研究者的边际贡献在训练和推理环节都能产生长期复利效应,这种效率提升足以抵消数亿美元的设备投资成本。在这种背景下,天价年薪和股权激励并非市场泡沫,而是一种理性的回报。
需要注意的是,虽然目前行业普遍存在浪费 H100 的现象,但这不是失败,而是成长的代价。AI 研究的真正瓶颈在于实验密度与反馈周期,而非理论匮乏。少数顶级研究者提升全局效率的价值,远高于成千上万的低效尝试。
但人才扩张也会带来副作用。随着巨头公司在全球范围内收购式挖人,大量研究机构出现组织迟滞与算力浪费。Dylan 直言有太多人只会“说”却不会“做”,规模化挖人往往导致结构性失配,他甚至主张美国应在高端制造与物理化学领域“反向挖人”,将关键工艺与实验知识迁回本土。
美国必须重新掌握发电能力
AI 的崛起确实带来了前所未有的能源需求,但实际上,目前数据中心的电力消耗并不算庞大。整个美国的数据中心用电仅占美国全国总电力的 3%–4%,其中大约一半来自 AI 数据中心。
根据美国能源信息管理局(EIA),2024 年美国的电力消耗为 40860 亿千瓦时,预计在 2025 年达到 41650 亿千瓦时。按照 1.5%-2%的比例估算,美国 AI 数据中心的 2025 年电力消耗量约为 624-833 亿千瓦时。
但目前 AI 数据中心的规模正在迅速扩大,比如 OpenAI 正在建设一座耗电 2 吉瓦的设施,相当于整个费城的电力消耗。在业内,这类规模已逐渐成为常态,甚至不到 1 吉瓦的项目几乎无人关注。实际上,500 兆瓦的项目就意味着约 250 亿美元的资本支出。这样的扩张速度和体量,远超以往任何数据中心建设记录。
因此,目前真正的挑战不在于用电量过高,而是如何新增发电能力:过去 40 年间,美国能源体系在转向天然气后,新增发电能力几乎停滞,如今重启发电项目面临多重障碍,比如监管复杂、劳动力短缺、供应链紧张。而且燃气轮机、变压器之类的关键设备的生产周期长、产能有限,使电厂扩建难度也大幅增加。
此外,模型训练的高波动负载也在考验电网。瞬时功率变化会扰乱频率,造成设备损耗。即使不至于引发断电,也会让附近的家用电器提前老化。
Dylan 指出,美国必须重新掌握发电能力。目前,燃气机组和双循环机组正在恢复建设,部分企业甚至用并联柴油卡车发动机发电。供应链也正在重新活跃,比如马斯克从波兰进口设备,GE 和三菱宣布扩大燃机产量,变压器市场已全面售罄,能够参与数据中心建设的电工工资几乎翻倍。Dylan 认为,如果美国有足够多的电工,这些数据中心能建得更快,但 Google、Amazon、EdgeConneX 等公司的供应链差异很大,导致资源非常分散、效率不一。
在监管方面,为了确保算力设施不会影响居民的日常用电,美国电网制定了“强制减少供电”的规定,比如得克萨斯州的 ERCOT 电网和美国东北地区的 PJM 电网在电力供应紧张的时候,电网运营方有权提前 24-72 小时通知大型用电企业,要求它们把用电量削减一半。
因此,为了维持 AI 运算,企业通常被迫启用自备发电机,包括柴油机、燃气机甚至氢能发电。但这又带来了新问题:如果这些发电机持续运行超过法规规定的时间(如 8 小时),就会违反排放许可,触碰环保红线。
Dylan 认为,这场变化混乱却令人振奋。AI 迫使美国重新启动发电建设,重塑供应链,也让整个国家重新理解电力的意义。
04.AI 让传统软件的行业逻辑失效
今天的软件领域已与 5-10 年前截然不同,软件形态和商业模式都在经历结构性转变。SaaS 行业的繁荣已进入下行周期:估值倍数在 2021 年 4 月触顶,2022 年 10 月仍处高位,但增长势头从 2021 年 11 月开始已经明显放缓。
长期以来,SaaS 一直被视为软件行业中商业逻辑最完善的模式:产品研发成本相对稳定、毛利率极高,公司的主要支出集中在获客成本(CAC)上。通过削减销售和管理费用,SaaS 企业可以释放出可观的业务现金流。换句话说,当 SaaS 企业的用户规模达到一定临界点,即获客成本被充分摊薄,新增用户几乎直接转化为利润时,公司便会成为一台“现金流机器(Cashflow Machine)”。
但这一逻辑成立的前提是:软件开发本身是一件成本极高的事情。只有当自行开发的代价远高于购买现成服务时,企业才会选择以订阅的方式长期租用软件服务。
但如今随着 AI 显著降低了软件开发成本,传统 SaaS 的商业模式正面临瓦解。比如在中国,软件开发成本本就不高,中国软件工程师的薪资大约仅为美国同行的五分之一,但能力还可能更强一倍,这意味着,在中国进行本地化开发的成本远低于在美国购买或租用 SaaS 服务。因此,许多中国企业更倾向于自建系统或采用本地部署(on-prem),而不是长期订阅外部 SaaS。这也解释了为什么中国的 SaaS 与云服务渗透率一直显著低于美国。
如今,AI 工具正在全球范围内压低软件开发成本,让自建变得越来越便宜。当这种趋势扩散开来,SaaS 的原来“租比买更划算”的逻辑也将像在中国市场那样逐渐失效。
此外,SaaS 行业的高获客成本(CAC)依然普遍存在,而 AI 的兴起又进一步抬高了成本结构中的 COGS:
•任何集成了 AI 功能的软件,它的服务成本(例如每个 token 的计算成本)都会显著上升;
• 同时,市场上又充斥着借助 AI 轻松自建产品的竞争者,这会导致 SaaS 企业更容易陷入碎片化的市场,或被客户的内部研发分流;
• 当用户规模难以持续扩大,企业便难以达到足以摊薄 CAC 与研发支出的逃逸速度(escape velocity);
•在更高的 COGS 约束下,SaaS 公司的净利润拐点被迫延后,盈利情况也会逐渐逐渐恶化。
需要注意的是,Google 依然具备潜在的相对优势。得益于 Google 自研的 TPU 以及垂直一体化的基础设施体系,Google 在每个 token 的边际服务成本上显著低于同行,这使 Google 有机会在 AI 软件的 COGS 结构中取得成本优势。但整体上来说,纯软件公司的日子将越来越难,已经具备规模、生态与平台势能的企业会继续占据优势。随着内容生产与生成成本的持续下降,真正掌控平台的公司将成为最大赢家。比如 YouTube 这样的超级平台,反而可能迎来新一轮的高光时刻。
但在具体厂商层面,许多软件企业都将不得不直面同一个现实:COGS 上升、CAC 居高不下、竞争者急剧增加。随着功能“买不如造”的门槛不断降低,企业原有的竞争优势被迅速压缩,增长飞轮也难以重新启动。这场“软件清算”不仅源于 AI 带来的技术冲击,更是商业结构与成本结构联动变化的结果。
05.对 AI 玩家的快评
• OpenAI:顶级优秀的公司
• Anthropic:Dylan 对 Anthropic 的看法甚至比对 OpenAI 更乐观
Anthropic 的收入增长明显更快,因为它专注的方向与价值约 2 万亿美元的软件市场紧密相关。相比之下,OpenAI 的布局较为分散,同时推进企业软件、AI 科研、消费者应用以及平台抽成等多条路线。虽然这些业务都具有潜力,但在执行上,Anthropic 更加稳健与聚焦,也更符合当前市场需求。
• AMD:
AMD 长期 Intel 和 Nvidia 抗衡,扮演着友善的挑战者角色,这种“弱者精神”让人难以不喜欢。而且,AMD 是 Dylan 人生中第一个十倍股的案例。作为一个从小热爱组装电脑的人,Dylan 对 AMD 这种“逆袭者”公司一直怀有好感。
• xAI:存在无法持续融资的风险
尽管马斯克个人能够吸引资金,但要维持与顶级竞争者相当的算力水平,所需资本规模非常庞大。xAI 正在建设名为“Colossus 2”的超级数据中心,建成后,它将成为全球最大的单体数据中心,可以部署 30 万到 50 万颗 Blackwell GPU。虽然这样的基础设施令人震撼,但公司在商业化上一直没有找到合适的模式。当前唯一的产品 Grok 并未得到理想变现。
在 Dylan 看来,xAI 完全可以把 Grok 商业化做得更好,比如通过个性化内容、虚拟人物或订阅互动模式增加收入,甚至可以与 OnlyFans 合作,将创作者数字化形象整合到 X 生态中,形成真正的超级应用。
总的来说,xAI 虽有出色的团队与计算能力,但除非在商业和产品层面做出突破,否则会在竞争中掉队。马斯克的意志和资金可以支撑一个阶段,但如果没有可持续收入,即便他是世界首富,也无法独力负担一个 3 吉瓦级数据中心的长期投入。
• Meta:手中握有可能可以统治一切的牌
Dylan 特别提到 Meta 新推出的智能眼镜,认为这标志着人机交互方式的又一次革命。从打孔卡到命令行、从图形界面到触控屏,人机界面不断演进,下一阶段将是无接触交互:用户只需对 AI 说出需求,它便能直接执行,如发送邮件、下单购物等。
而 Meta 是唯一拥有完整体系的公司,即既有硬件(智能眼镜),也有强大的模型能力、算力供应能力,以及业界领先的推荐算法系统。这四者叠加,再加上充足的资金,让 Meta 有潜力成为这一代人机接口的主导者。
• Google:在两年前还对 Google 相当悲观,今天则非常看好
Dylan 认为 Google 在多个层面已彻底觉醒:开始对外销售 TPU,积极推进 AI 模型的商业化,并在训练和基础设施投资方面展现出更强的进取心。
尽管 Google 内部仍存在一些低效和官僚问题,但 Google 拥有独特的硬件基础,可在 AI 时代灵活转型。虽然在硬件体验上可能不如 Meta 或 Apple,但 Google 有 Android、YouTube、搜索等庞大生态,一旦人机交互进入新阶段,这些资产能被重新整合。在 Dylan 看来,Meta 可能在消费市场领先,但在专业与企业级应用方面,Google 更具潜力。
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













