

Loài bi kịch công cộng mã hóa: Nỗi đau của việc lập chỉ mục dữ liệu trên Polymarket
Tuyển chọn TechFlowTuyển chọn TechFlow
Loài bi kịch công cộng mã hóa: Nỗi đau của việc lập chỉ mục dữ liệu trên Polymarket
Bài viết này tập trung vào một trong những ứng dụng "vượt ra ngoài cộng đồng" nổi bật nhất trong hệ sinh thái Ethereum: Polymarket và công cụ lập chỉ mục dữ liệu của nó.
Bài viết: shew
Tóm tắt
Chào mừng bạn đến với loạt bài "Thảm kịch đồng cỏ" trong chuyên mục GCC Research.
Trong loạt bài này, chúng tôi sẽ tập trung vào những "sản phẩm công cộng" then chốt nhưng đang dần mất kiểm soát trong thế giới tiền mã hóa. Chúng là cơ sở hạ tầng của toàn bộ hệ sinh thái, nhưng thường đối mặt với tình trạng thiếu động lực, quản trị mất cân bằng, thậm chí ngày càng tập trung hóa. Những lý tưởng mà công nghệ tiền mã hóa theo đuổi và sự ổn định dư thừa trong thực tế đang chịu thử thách nghiêm trọng tại những góc khuất này.
Kỳ này, chúng tôi tập trung vào một trong những ứng dụng nổi bật nhất trong hệ sinh thái Ethereum: Polymarket và công cụ chỉ mục dữ liệu của nó. Đặc biệt từ đầu năm nay, các sự kiện như việc thao túng oracles liên quan đến chiến thắng của Trump, giao dịch đất hiếm Ukraine, hay cá cược chính trị về màu sắc vest của Zelenskyy đã khiến Polymarket nhiều lần trở thành tâm điểm dư luận, quy mô vốn và ảnh hưởng thị trường mà nó nắm giữ khiến những tranh cãi này không thể xem nhẹ.
Tuy nhiên, mô-đun nền tảng then chốt của sản phẩm đại diện cho "thị trường dự báo phi tập trung" này – việc chỉ mục dữ liệu – liệu có thực sự đạt được tính phi tập trung? Vì sao những cơ sở hạ tầng công cộng như The Graph lại không đảm nhận được vai trò kỳ vọng? Một sản phẩm công cộng chỉ mục dữ liệu thực sự khả dụng và bền vững nên có hình thái như thế nào?
I. Phản ứng dây chuyền do một nền tảng dữ liệu tập trung ngừng hoạt động
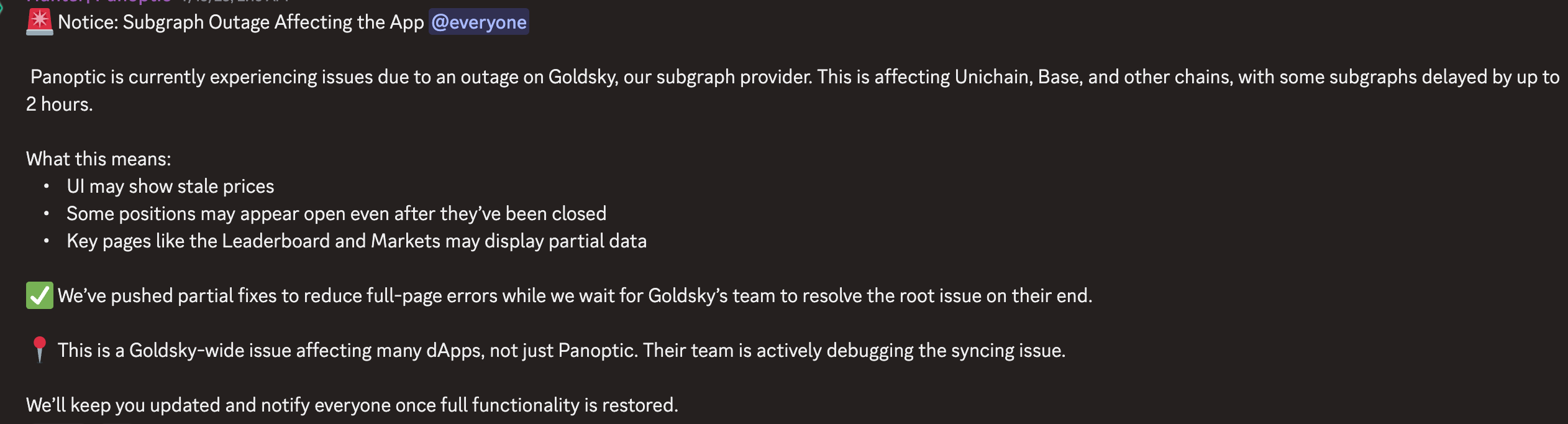
Tháng 7 năm 2024, Goldsky gặp sự cố ngừng hoạt động kéo dài sáu giờ (Goldsky là nền tảng cơ sở hạ tầng dữ liệu chuỗi khối thời gian thực dành cho nhà phát triển Web3, cung cấp dịch vụ chỉ mục, subgraph và dữ liệu luồng, hỗ trợ xây dựng nhanh các ứng dụng phi tập trung dựa trên dữ liệu), khiến phần lớn dự án trong hệ sinh thái Ethereum rơi vào tình trạng tê liệt, ví dụ như giao diện DeFi không thể hiển thị vị thế và số dư tài khoản người dùng, thị trường dự báo Polymarket không thể hiện thị dữ liệu chính xác, vô số dự án trông như hoàn toàn không sử dụng được đối với người dùng cuối.
Điều này đáng lẽ không nên xảy ra trong thế giới ứng dụng phi tập trung. Rốt cuộc, mục đích ban đầu trong thiết kế công nghệ blockchain không phải là loại bỏ điểm lỗi đơn lẻ sao? Sự cố Goldsky phơi bày một thực tế đáng lo ngại: mặc dù bản thân blockchain đã tận dụng tối đa tính phi tập trung, nhưng cơ sở hạ tầng mà các ứng dụng xây dựng trên đó sử dụng thường chứa đựng rất nhiều dịch vụ tập trung.
Nguyên nhân sâu xa, việc chỉ mục và truy xuất dữ liệu blockchain thuộc nhóm "sản phẩm công cộng kỹ thuật số" phi độc quyền và phi cạnh tranh, người dùng thường mong đợi miễn phí hoặc chi phí cực thấp, nhưng đằng sau đó đòi hỏi đầu tư liên tục vào phần cứng mạnh, lưu trữ, băng thông và nhân lực vận hành. Khi thiếu mô hình sinh lời bền vững, sẽ dẫn đến cục diện tập trung kiểu "người thắng duy nhất": chỉ cần một nhà cung cấp chiếm ưu thế ban đầu về tốc độ và vốn, các nhà phát triển sẽ có xu hướng chuyển toàn bộ lưu lượng truy vấn tới dịch vụ đó, từ đó lại tạo ra sự phụ thuộc vào điểm đơn lẻ. Các dự án công ích như Gitcoin đã nhiều lần nhấn mạnh rằng "cơ sở hạ tầng mã nguồn mở có thể tạo ra giá trị hàng tỷ đô la Mỹ, nhưng tác giả lại thường không thể dùng nó để trả tiền thuê nhà".
Điều này cảnh tỉnh chúng ta rằng, thế giới phi tập trung khẩn thiết cần làm phong phú thêm sự đa dạng của cơ sở hạ tầng Web3 thông qua tài trợ sản phẩm công cộng, tái phân phối hoặc các sáng kiến do cộng đồng dẫn dắt, nếu không sẽ gặp phải vấn đề tập trung hóa. Chúng tôi kêu gọi các nhà phát triển DApp xây dựng sản phẩm theo nguyên tắc ưu tiên cục bộ (local-first), đồng thời kêu gọi cộng đồng kỹ thuật khi thiết kế DApp cần tính đến trường hợp dịch vụ truy xuất dữ liệu bị sập, đảm bảo người dùng vẫn có thể tương tác với dự án ngay cả khi không có cơ sở hạ tầng truy xuất dữ liệu.
II. Dữ liệu bạn thấy trên Dapp đến từ đâu
Để hiểu vì sao xảy ra sự cố như Goldsky, chúng ta cần đi sâu vào cơ chế hoạt động phía sau hậu trường của DApp. Với người dùng thông thường, DApp thường chỉ gồm hai phần: hợp đồng trên chuỗi và giao diện người dùng. Phần lớn người dùng đã quen với việc dùng Etherscan và các công cụ khác để tra cứu trạng thái giao dịch trên chuỗi, lấy thông tin cần thiết trên giao diện, đồng thời dùng giao diện để khởi tạo giao dịch tương tác với hợp đồng. Nhưng dữ liệu được hiển thị trên giao diện người dùng này rốt cuộc đến từ đâu?
Dịch vụ truy xuất dữ liệu không thể thiếu
Giả sử bạn đang xây dựng một giao thức cho vay, giao thức này cần hiển thị tình trạng nắm giữ tài sản của người dùng cũng như mức ký quỹ và nợ của từng vị thế. Một ý tưởng đơn giản là giao diện trực tiếp đọc dữ liệu này từ chuỗi. Nhưng trong thực tế, hợp đồng của giao thức cho vay không cho phép truy vấn dữ liệu vị thế bằng địa chỉ người dùng, hợp đồng sẽ cung cấp hàm truy vấn dữ liệu cụ thể của vị thế bằng ID vị thế. Do đó, nếu muốn hiển thị vị thế người dùng trên giao diện, ta cần truy xuất tất cả các vị thế hiện có trong hệ thống, rồi tìm xem những vị thế nào thuộc về người dùng hiện tại. Điều này giống như yêu cầu ai đó thủ công tìm kiếm thông tin đặc biệt trong hàng triệu trang sổ sách — về mặt kỹ thuật là khả thi, nhưng cực kỳ chậm và kém hiệu quả. Thực tế, giao diện rất khó hoàn thành quy trình truy xuất này, ngay cả các dự án DeFi lớn khi thực hiện nhiệm vụ truy xuất dữ liệu trực tiếp trên máy chủ bằng nút cục bộ cũng thường mất vài giờ.
Vì vậy, chúng ta phải đưa vào cơ sở hạ tầng để tăng tốc độ thu thập dữ liệu. Các công ty như Goldsky chính là cung cấp dịch vụ chỉ mục dữ liệu này cho người dùng. Hình dưới minh họa các loại dữ liệu mà dịch vụ chỉ mục có thể cung cấp cho ứng dụng.

Tại đây, có thể có độc giả thắc mắc rằng trong hệ sinh thái Ethereum dường như tồn tại một nền tảng truy xuất dữ liệu phi tập trung là TheGraph, nền tảng này có mối liên hệ gì với Goldsky? Và tại sao phần lớn dự án DeFi lại không dùng TheGraph vốn phi tập trung hơn mà lại dùng Goldsky làm nhà cung cấp dữ liệu?
Mối quan hệ giữa TheGraph / Goldsky và SubGraph
Để trả lời câu hỏi trên, chúng ta cần hiểu trước một số khái niệm kỹ thuật.
-
SubGraph là một khuôn khổ phát triển, nhà phát triển có thể dùng khuôn khổ này viết mã để đọc và tổng hợp dữ liệu trên chuỗi, đồng thời dùng một số phương pháp để đọc và hiển thị dữ liệu này lên giao diện.
-
TheGraph là nền tảng truy xuất dữ liệu phi tập trung ra đời sớm, nền tảng này phát triển khung SubGraph viết bằng AssemblyScript, nhà phát triển có thể dùng khung subgraph viết chương trình bắt sự kiện hợp đồng và ghi các sự kiện này vào cơ sở dữ liệu, sau đó người dùng có thể dùng phương pháp Graphql để đọc dữ liệu hoặc trực tiếp dùng mã SQL đọc cơ sở dữ liệu.
-
Chúng ta thường gọi nhà cung cấp dịch vụ chạy SubGraph là nhà điều hành SubGraph. TheGraph và Goldsky thực chất đều là nhà lưu trữ SubGraph. Bởi vì SubGraph chỉ là một khuôn khổ phát triển, chương trình được phát triển bởi khung này cần được chạy trên máy chủ. Chúng ta có thể thấy trong tài liệu của Goldsky có nội dung sau:
Tại đây có thể có độc giả thắc mắc vì sao SubGraph lại có nhiều nhà điều hành?
Lý do là vì khung SubGraph thực chất chỉ quy định cách dữ liệu được đọc từ khối và ghi vào cơ sở dữ liệu.
Còn việc dữ liệu chảy vào chương trình SubGraph như thế nào và kết quả đầu ra cuối cùng được ghi vào loại cơ sở dữ liệu nào thì chưa được hiện thực hóa, những nội dung này cần các nhà điều hành SubGraph tự hiện thực.
Nói chung, các nhà điều hành SubGraph đều sẽ thực hiện sửa đổi nút để đạt tốc độ nhanh hơn, các nhà điều hành khác nhau (như TheGraph, Goldsky) có các chiến lược và giải pháp kỹ thuật khác nhau.
TheGraph hiện tại đang dùng giải pháp công nghệ Firehouse, sau khi áp dụng giải pháp này, TheGraph có thể đạt tốc độ truy xuất dữ liệu nhanh hơn trước đây, còn Goldsky thì không công khai mã nguồn chương trình lõi chạy SubGraph của mình.
Như đã nói ở trên, TheGraph là một nền tảng truy xuất dữ liệu phi tập trung, lấy subgraph Unisawp v3 làm ví dụ, chúng ta có thể thấy có rất nhiều nhà điều hành đang cung cấp dịch vụ truy xuất dữ liệu cho Uniswap v3, do đó chúng ta cũng có thể coi TheGraph như một nền tảng tích hợp các nhà điều hành SubGraph, người dùng có thể gửi mã SubGraph do mình viết cho TheGraph, sau đó bên trong TheGraph sẽ có một số nhà điều hành giúp người dùng truy xuất dữ liệu.
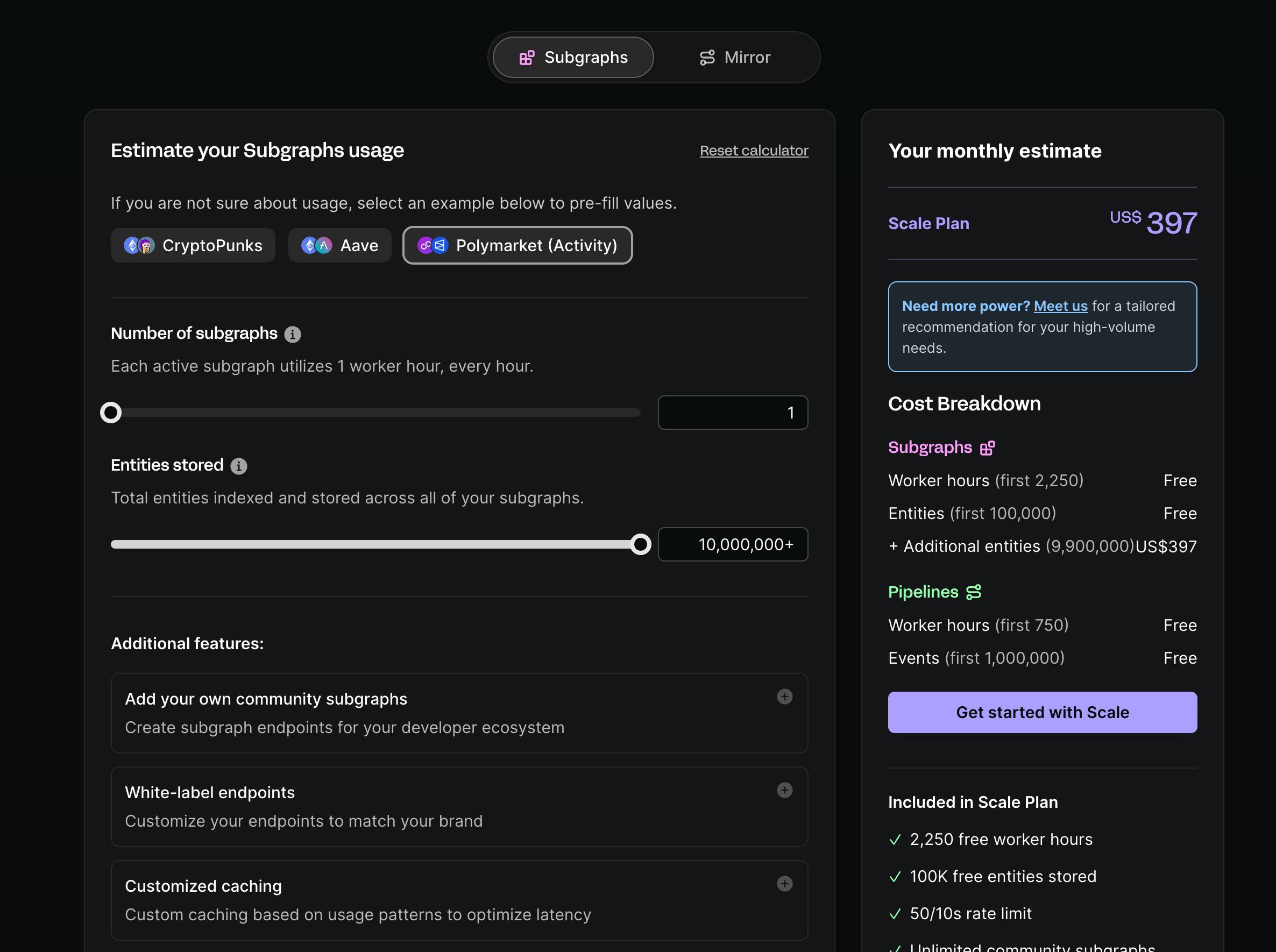
Mô hình tính phí của Goldsky
Đối với nền tảng tập trung như Goldsky, Goldsky có một tiêu chuẩn tính phí đơn giản, dựa trên việc sử dụng tài nguyên, đây là cách tính phí phổ biến nhất của nền tảng SaaS trên Internet, phần lớn kỹ thuật viên rất quen thuộc với cách này. Hình dưới minh họa máy tính giá của Goldsky:
Mô hình tính phí của TheGraph
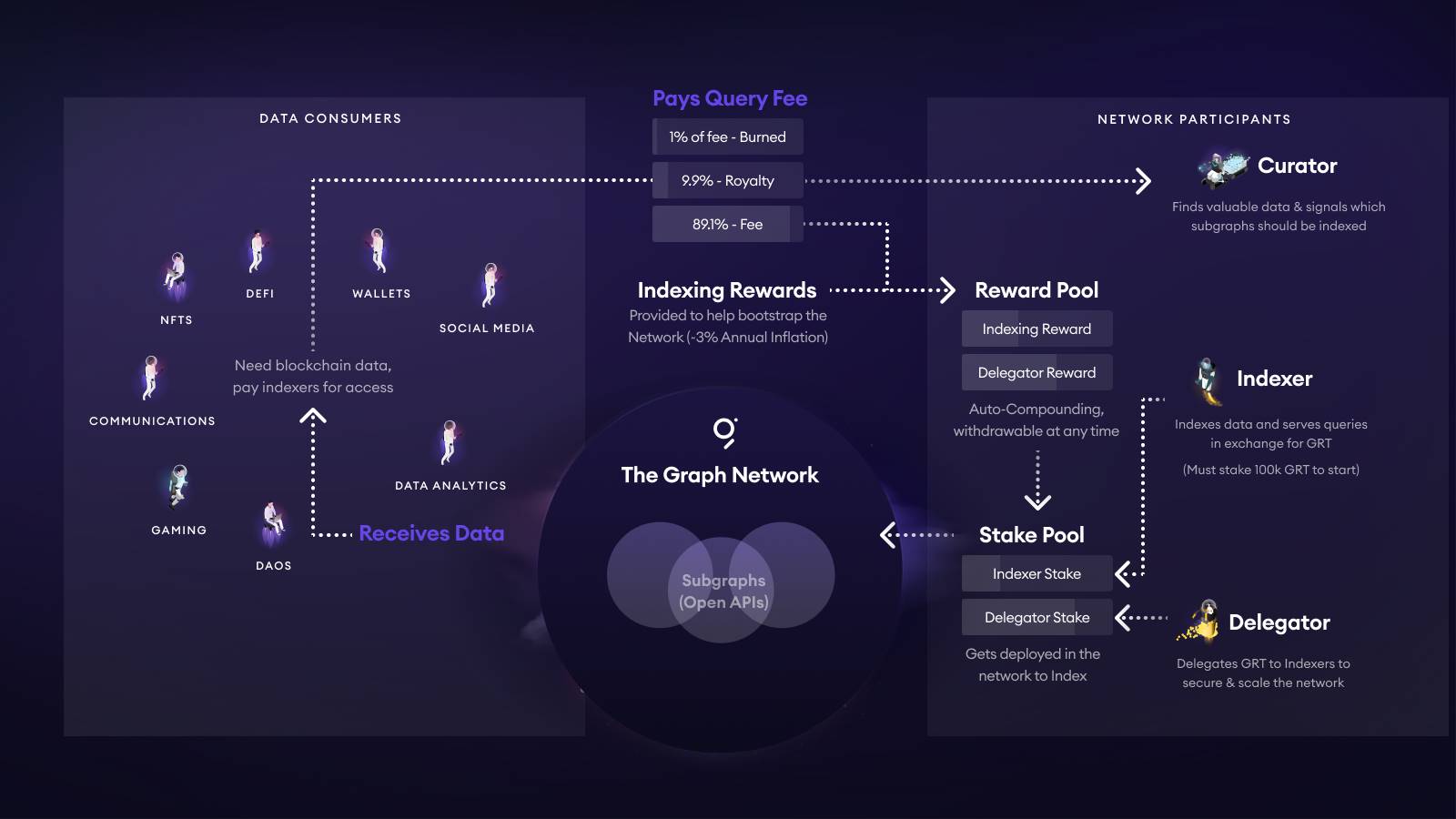
TheGraph thì có một kế hoạch phí hoàn toàn khác biệt so với cách tính phí thông thường, kế hoạch phí này liên quan đến kinh tế học token GRT, hình dưới minh họa toàn bộ kinh tế học token GRT:
-
Mỗi khi DApp hoặc ví gửi yêu cầu đến một Subgraph nhất định, phí truy vấn (Query Fee) sẽ được tự động chia nhỏ: 1% bị đốt cháy, khoảng 10% chảy vào hồ bồi thường (Curator/Nhà phát triển) của Subgraph đó, phần còn lại ~89% được trả thưởng theo cơ chế hàm mũ cho Indexer cung cấp năng lực tính toán và Delegator của họ.
-
Indexer phải tự đặt cọc ≥100k GRT mới được上线; nếu trả về dữ liệu sai sẽ bị phạt (slashing). Delegator ủy thác GRT cho Indexer, được chia phần lớn khoản 89% trên theo tỷ lệ.
-
Curator (thường là nhà phát triển) đặt cọc GRT trên đường cong trái phiếu của Subgraph nhà bằng Signal; số Signal càng cao, càng thu hút Indexer phân bổ tài nguyên. Kinh nghiệm cộng đồng khuyên nên huy động tự thân 5k–10k GRT để đảm bảo vài Indexer nhận đơn. Đồng thời, người làm vườn còn nhận được khoản Royalty 10% đó.
Phí truy vấn theo lần của TheGraph:
Đăng ký API KEY trong nền tảng TheGraph và dùng API KEY này yêu cầu dữ liệu truy xuất từ các nhà điều hành trong TheGraph, phần yêu cầu này tính phí theo số lần, nhà phát triển cần nạp trước một phần token GRT trên nền tảng làm chi phí cho yêu cầu API.
Phí đặt cọc Signal của TheGraph:
Đối với người triển khai SubGraph, cần các nhà điều hành trong nền tảng TheGraph giúp truy xuất dữ liệu, theo cách phân phối lợi nhuận đã nêu, cần thông báo cho các bên tham gia khác rằng dịch vụ truy vấn của tôi tốt hơn, có thể chia được nhiều tiền hơn, do đó cần đặt cọc GRT, tương tự như quảng cáo và bảo đảm có lợi nhuận, mọi người mới đến.
Khi thử nghiệm, nhà phát triển có thể triển khai SubGraph miễn phí lên nền tảng TheGraph, lúc này TheGraph chính thức sẽ giúp người dùng thực hiện một số truy xuất, cung cấp hạn mức dùng thử miễn phí, nhưng không thể dùng cho môi trường sản xuất. Nếu nhà phát triển cho rằng SubGraph hoạt động tốt trong môi trường thử nghiệm chính thức của TheGraph, có thể công bố lên mạng công cộng để chờ các nhà điều hành khác tham gia truy xuất. Nhà phát triển không thể trực tiếp trả phí cho một nhà điều hành cụ thể và nhận được đảm bảo truy xuất, mà để nhiều nhà điều hành cạnh tranh cung cấp dịch vụ, tránh tạo ra sự phụ thuộc điểm đơn lẻ. Quá trình này cần dùng token GRT thực hiện thao tác làm vườn (Curating) cho SubGraph của mình (cũng có thể gọi là thao tác Signal), tức là nhà phát triển đặt cọc một lượng nhất định GRT vào SubGraph do mình triển khai, nhưng khi số lượng GRT đặt cọc đạt đến mức nhất định (dữ liệu tham khảo trước đó là 10.000 GRT), nhà điều hành mới tham gia công việc truy xuất SubGraph.
Trải nghiệm thanh toán tệ hại làm khó nhà phát triển và kế toán truyền thống
Đối với phần lớn nhà phát triển dự án, dùng TheGraph thực ra là việc khá rắc rối, mua token GRT đối với dự án Web3 còn dễ, nhưng thao tác Curating SubGraph đã triển khai và chờ nhà điều hành là khâu cực kỳ kém hiệu quả. Khâu này ít nhất có hai vấn đề:
-
Vấn đề bất định về số lượng GRT đặt cọc và thời gian thu hút nhà điều hành. Khi tôi triển khai SubGraph trước đây đã trực tiếp hỏi đại sứ cộng đồng TheGraph để xác định số lượng GRT đặt cọc, nhưng đối với phần lớn nhà phát triển, dữ liệu này không dễ thu được, ngoài ra sau khi đặt cọc đủ GRT, nhà điều hành tham gia truy xuất cũng cần một khoảng thời gian
-
Vấn đề phức tạp trong tính toán chi phí và kế toán. Do TheGraph dùng cơ chế kinh tế học token để thiết kế tiêu chuẩn phí, điều này khiến việc tính toán chi phí trở nên phức tạp đối với phần lớn nhà phát triển. Vấn đề thực tế hơn là, nếu doanh nghiệp muốn hạch toán kế toán khoản chi này, kế toán có thể cũng không hiểu được cấu thành chi phí này.
"Ừ thì, hóa ra dịch vụ tập trung vẫn tốt hơn?"
Rõ ràng, đối với phần lớn nhà phát triển, chọn trực tiếp Goldsky là việc đơn giản hơn, cách tính phí ai cũng hiểu được, đồng thời chỉ cần trả phí gần như có thể dùng ngay lập tức, mức độ bất định giảm mạnh, điều này cũng dẫn đến tình trạng trong dịch vụ chỉ mục và truy xuất dữ liệu blockchain, xuất hiện sự phụ thuộc vào một sản phẩm duy nhất.
Rõ ràng kinh tế học token GRT phức tạp của TheGraph đã ảnh hưởng đến việc áp dụng rộng rãi TheGraph. Kinh tế học token có thể mang tính phức tạp, nhưng rõ ràng những phức tạp này không nên phơi bày cho người dùng, ví dụ cơ chế đặt cọc làm vườn GRT không nên phơi bày cho người dùng, biện pháp tốt hơn của TheGraph là trực tiếp cung cấp cho người dùng một trang thanh toán đơn giản hóa.
Việc hạ thấp TheGraph như trên không phải là quan điểm cá nhân tôi, kỹ sư hợp đồng thông minh nổi tiếng và người sáng lập dự án Sablier Paul Razvan Berg cũng từng bày tỏ quan điểm này trong bài đăng . Bài đăng này nhắc đến trải nghiệm người dùng khi phát hành SubGraph và tính phí GRT là cực kỳ tồi tệ.
III. Một số giải pháp hiện có
Về cách giải quyết điểm lỗi đơn lẻ trong truy xuất dữ liệu, thực ra phần trên đã đề cập một chút, tức là nhà phát triển có thể cân nhắc dùng dịch vụ TheGraph, chỉ là quy trình sẽ phức tạp hơn, nhà phát triển cần mua token GRT để đặt cọc làm vườn và trả phí API.
Hiện tại, trong hệ sinh thái EVM có rất nhiều phần mềm truy xuất dữ liệu, cụ thể có thể tham khảo The State of EVM Indexing do Dune biên soạn hoặc Tổng hợp phần mềm truy xuất dữ liệu EVM do rindexer biên soạn, một thảo luận mới hơn có thể tham khảo bài đăng này.
Bài viết này sẽ không bàn về nguyên nhân cụ thể dẫn đến sự cố Glodsky, vì hiện tại theo nội dung trong báo cáo Glodsky , Glodsky biết nguyên nhân cụ thể, nhưng chỉ chuẩn bị tiết lộ cho người dùng doanh nghiệp. Điều này có nghĩa bất kỳ bên thứ ba nào hiện tại cũng không thể biết Glodsky rốt cuộc gặp sự cố gì. Theo nội dung báo cáo có thể suy đoán, có thể là vấn đề khi ghi dữ liệu sau truy xuất vào cơ sở dữ liệu, trong báo cáo ngắn gọn này, Glodsky nhắc đến cơ sở dữ liệu không thể truy cập bình thường, chỉ sau khi hợp tác với AWS mới giành lại quyền truy cập cơ sở dữ liệu.
Trong phần này, chúng tôi chủ yếu giới thiệu các phương pháp giải quyết khác:
-
ponder là phần mềm dịch vụ truy xuất dữ liệu đơn giản, trải nghiệm phát triển tốt và triển khai thuận tiện, nhà phát triển có thể tự thuê máy chủ triển khai
-
local-first là một triết lý phát triển thú vị, triết lý này kêu gọi nhà phát triển dù thiếu mạng vẫn có thể mang lại trải nghiệm tốt cho người dùng. Trong trường hợp có blockchain, chúng ta có thể phần nào nới lỏng giới hạn local-first, đảm bảo người dùng có thể kết nối blockchain thì có thể có trải nghiệm tốt.
ponder
Tại sao tác giả lại đề xuất dùng ponder thay vì phần mềm khác? Lý do cụ thể bao gồm các điểm sau:
-
Ponder không phụ thuộc nhà cung cấp. Ban đầu ponder là dự án do nhà phát triển cá nhân xây dựng, nên so với các phần mềm truy xuất dữ liệu do doanh nghiệp cung cấp, ponder chỉ cần người dùng nhập URL RPC Ethereum và liên kết cơ sở dữ liệu postgres
-
Ponder cung cấp trải nghiệm phát triển tốt, tác giả trước đây đã nhiều lần dùng ponder để phát triển, do ponder viết bằng typescript, đồng thời thư viện lõi chủ yếu dựa vào viem, trải nghiệm phát triển rất tuyệt vời
-
Ponder có hiệu năng cao hơn
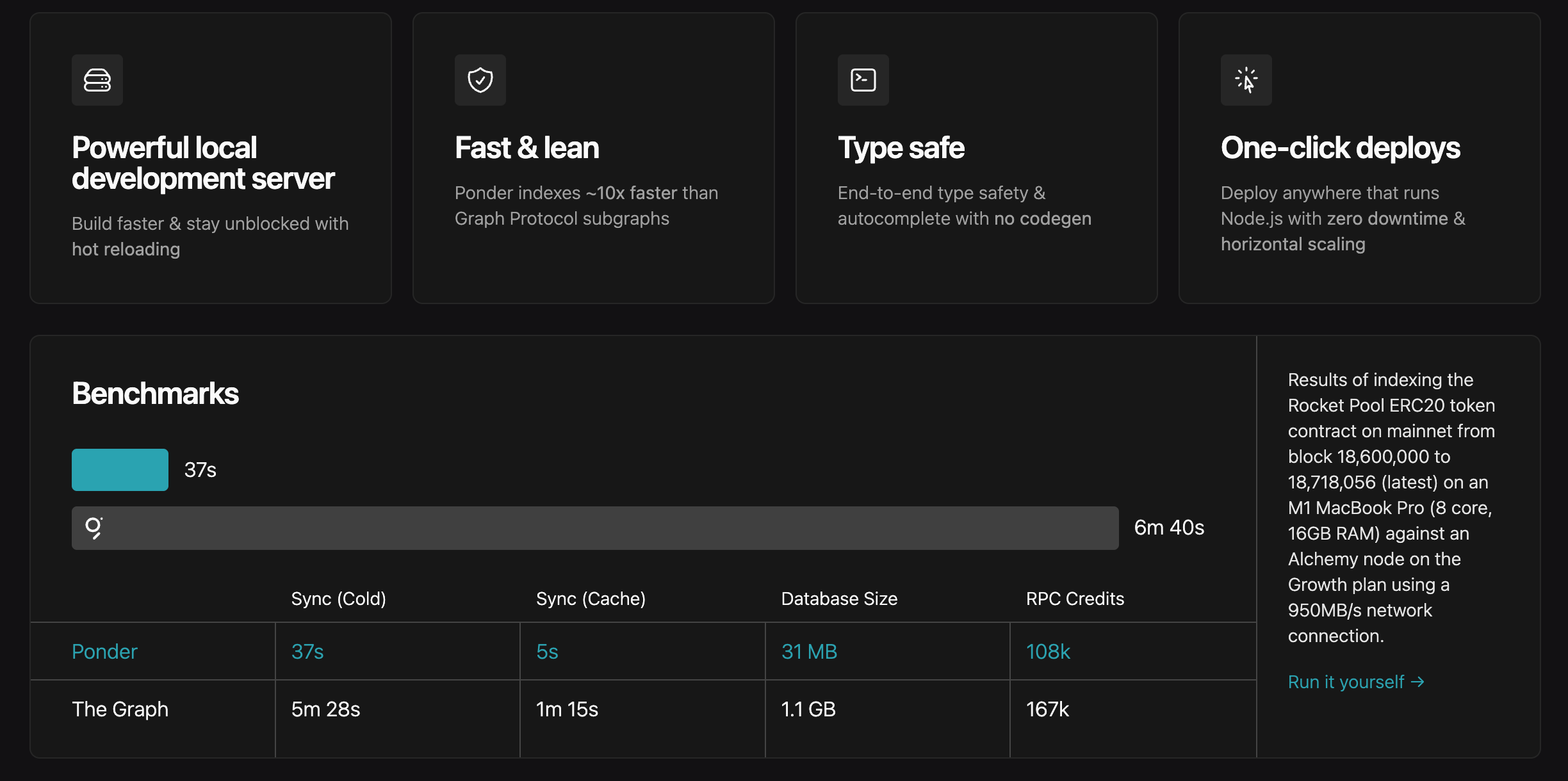
Tất nhiên cũng sẽ có một số vấn đề, ponder hiện tại thực ra vẫn đang trong giai đoạn phát triển nhanh, nhà phát triển có thể gặp trường hợp dự án trước đó không thể chạy do cập nhật phiên bản phá vỡ. Xét rằng bài viết này không phải bài hướng dẫn kỹ thuật, nên sẽ không bàn sâu chi tiết phát triển ponder, độc giả có nền tảng kỹ thuật có thể tự đọc tài liệu.
Chi tiết thú vị hơn của ponder là hiện tại ponder cũng đã bắt đầu một phần thương mại hóa, nhưng con đường thương mại hóa của ponder rất phù hợp với "lý thuyết cách ly" được thảo luận trong bài viết trước.
Tại đây, chúng tôi giới thiệu đơn giản "lý thuyết cách ly". Chúng tôi cho rằng tính công cộng của sản phẩm công cộng khiến nó có thể phục vụ số lượng người dùng tùy ý, do đó chỉ cần thu phí sản phẩm công cộng sẽ khiến một bộ phận người dùng ngừng sử dụng, lúc này lợi ích xã hội không còn tối đa (thuật ngữ kinh tế học mô tả là "không còn tối ưu Pareto"). Về lý thuyết, sản phẩm công cộng có thể định giá khác biệt cho mỗi người để thu phí, nhưng chi phí của định giá khác biệt rất có thể lớn hơn thặng dư mang lại từ định giá khác biệt. Vì vậy lý do sản phẩm công cộng miễn phí là không phải sản phẩm công cộng vốn dĩ nên miễn phí, mà là bất kỳ hành vi thu phí cố định nào cũng sẽ gây tổn hại lợi ích xã hội, và hiện tại chưa có phương pháp rẻ tiền nào để định giá khác biệt cho từng người. Lý thuyết cách ly đề xuất một phương pháp định giá bên trong sản phẩm công cộng, tức là dùng một phương pháp nào đó tách một bộ phận nhóm người đồng nhất ra, thu phí nhóm người này. Trước hết, lý thuyết cách ly sẽ không ngăn cản mọi người dùng miễn phí sản phẩm công cộng, nhưng lý thuyết cách ly đề xuất một phương pháp thu phí một bộ phận người dùng.
Ponder đã dùng phương pháp tương tự lý thuyết cách ly:
-
Trước hết, việc triển khai ponder vẫn cần một số kiến thức nhất định, nhà phát triển khi triển khai cần cung cấp các phụ thuộc bên ngoài như RPC, cơ sở dữ liệu.
-
Đồng thời sau khi triển khai xong, nhà phát triển cần vận hành liên tục ponder, ví dụ dùng hệ thống proxy để cân bằng tải, tránh ảnh hưởng dữ liệu yêu cầu ảnh hưởng đến việc ponder truy xuất dữ liệu trên chuỗi trong luồng nền. Điều này đối với nhà phát triển thông thường hơi phức tạp.
-
Hiện tại ponder đang thử nghiệm nội bộ dịch vụ triển khai tự động hoàn toàn marble, người dùng chỉ cần giao mã cho nền tảng này là có thể triển khai tự động.
Rõ ràng đây là một ứng dụng "lý thuyết cách ly", những nhà phát triển không muốn tự vận hành dịch vụ ponder bị tách ra, những nhà phát triển này có thể trả phí để nhận được việc triển khai đơn giản hóa dịch vụ ponder. Tất nhiên, sự xuất hiện của nền tảng marble cũng không ảnh hưởng đến việc các nhà phát triển khác dùng miễn phí khung ponder và tự lưu trữ triển khai.
Đối tượng người dùng của ponder và Goldsky?
-
Sản phẩm công cộng hoàn toàn không phụ thuộc nhà cung cấp như ponder phổ biến hơn khi phát triển dự án nhỏ so với các dịch vụ truy xuất dữ liệu phụ thuộc nhà cung cấp.
-
Một số nhà phát triển vận hành dự án lớn không nhất thiết chọn khung ponder, vì dự án lớn thường yêu cầu dịch vụ truy xuất có hiệu năng đầy đủ, các nhà cung cấp dịch vụ như Goldsky thường cung cấp đảm bảo khả dụng đầy đủ.
Cả hai đều có một số điểm rủi ro, xét từ sự cố Goldsky gần đây, nhà phát triển tốt nhất nên tự duy trì một dịch vụ ponder riêng, để隨時应对可能的第三方服务宕机。以及使用 ponder 时可能要考虑 RPC 返回数据的有效性问题,不久前 safe 就报告了一次因为 RPC 返回错误数据导致检索器崩溃的情况。虽然没有直接证据表明 Goldsky 事件也与 RPC 返回无效事件有关,但笔者怀疑 Goldsky 可能也遇到了类似事件。

Triết lý phát triển local-first
Local-first là chủ đề được bàn luận nhiều trong vài năm qua. Đơn giản, local-first yêu cầu phần mềm có các chức năng sau:
-
Làm việc ngoại tuyến
-
Hợp tác xuyên nền tảng khách hàng
Hiện tại phần lớn thảo luận kỹ thuật liên quan local-first đều liên quan đến công nghệ CRDT (Conflict-free Replicated Data Type),所謂 CRDT là một định dạng dữ liệu không xung đột, định dạng này cho phép người dùng thao tác đa đầu tự động hợp nhất xung đột để giữ tính toàn vẹn dữ liệu. Một cách nhìn đơn giản là có thể coi CRDT như một kiểu dữ liệu có giao thức đồng thuận đơn giản, trong trường hợp phân tán, CRDT có thể đảm bảo tính toàn vẹn và nhất quán dữ liệu.
Nhưng trong phát triển blockchain, chúng ta có thể nới lỏng giới hạn yêu cầu của local-first đối với phần mềm. Chúng ta chỉ yêu cầu khi không có dữ liệu chỉ mục hậu cần do nhà phát triển dự án cung cấp, người dùng trên giao diện vẫn có thể giữ mức độ khả dụng tối thiểu. Đồng thời, yêu cầu của local-first về hợp tác xuyên nền tảng khách hàng thực tế đã được blockchain giải quyết.
Trong bối cảnh DApp, triết lý local-first có thể hiện thực như sau:
-
Bộ nhớ đệm dữ liệu then chốt: giao diện nên bộ nhớ đệm dữ liệu quan trọng của người dùng, như số dư, thông tin nắm giữ tài sản, ngay cả khi dịch vụ chỉ mục không dùng được, người dùng vẫn có thể thấy trạng thái đã biết cuối cùng.
-
Thiết kế chức năng suy giảm: khi dịch vụ chỉ mục hậu cần không dùng được, DApp có thể cung cấp chức năng cơ bản, ví dụ khi dịch vụ truy xuất dữ liệu không dùng được, một phần dữ liệu có thể cân nhắc trực tiếp dùng RPC đọc dữ liệu trên chuỗi, đảm bảo người dùng thấy tình trạng mới nhất của một phần dữ liệu đã có
Triết lý thiết kế DApp local-first này có thể nâng cao đáng kể độ dẻo dai của ứng dụng, tránh ứng dụng không dùng được sau khi dịch vụ truy xuất dữ liệu sập. Trong trường hợp không tính đến tính dễ dùng, ứng dụng local-first tốt nhất nên yêu cầu người dùng chạy nút cục bộ, sau đó dùng công cụ như trueblocks để truy xuất dữ liệu cục bộ. Về một số thảo luận liên quan truy xuất phi tập trung hoặc truy xuất cục bộ, có thể tham khảo bài đăng Literally no one cares about decentralized frontends and indexers.
IV. Lời kết
Sự cố ngừng hoạt động sáu giờ của Goldsky đã gióng lên hồi chuông cảnh báo cho hệ sinh thái. Mặc dù bản thân blockchain có đặc tính phi tập trung và chống điểm lỗi đơn lẻ, nhưng hệ sinh thái ứng dụng xây dựng trên đó vẫn phụ thuộc cao vào các dịch vụ cơ sở hạ tầng tập trung. Sự phụ thuộc này mang lại rủi ro hệ thống cho toàn bộ hệ sinh thái.
Bài viết này giới thiệu đơn giản lý do vì sao dịch vụ truy xuất phi tập trung nổi tiếng TheGraph hiện nay lại không được sử dụng rộng rãi, đặc biệt thảo luận về một số phức tạp do kinh tế học token GRT mang lại. Cuối cùng, bài viết thảo luận về cách xây dựng cơ sở hạ tầng truy xuất dữ liệu kiên cố hơn, tác giả khuyến khích nhà phát triển dùng khung phát triển truy xuất dữ liệu tự lưu trữ ponder như lựa chọn ứng phó khẩn cấp, đồng thời cũng giới thiệu con đường thương mại hóa tốt của ponder. Cuối cùng, bài viết thảo luận triết lý phát triển local-first, khuyến khích nhà phát triển xây dựng ứng dụng có thể dùng được ngay cả khi không có dịch vụ truy xuất dữ liệu.
Xét về hiện tại, không ít nhà phát triển Web3 đã nhận thức được vấn đề điểm lỗi đơn lẻ của dịch vụ truy xuất dữ liệu, GCC hy vọng nhiều nhà phát triển quan tâm hơn đến cơ sở hạ tầng này, và thử xây dựng dịch vụ truy xuất dữ liệu phi tập trung hoặc thiết kế một bộ khung khiến giao diện DApp vẫn có thể chạy khi không có dịch vụ truy xuất dữ liệu.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














