AI bùng nổ "khủng hoảng dầu mỏ" dữ liệu, các công ty nội dung có thể nằm mà kiếm tiền
Tuyển chọn TechFlowTuyển chọn TechFlow
AI bùng nổ "khủng hoảng dầu mỏ" dữ liệu, các công ty nội dung có thể nằm mà kiếm tiền
Nếu coi mô hình AI lớn như một chiếc ô tô, thì dữ liệu thô chính là dầu thô.
Tác giả: Giang Giang
Biên tập: Man Man Châu
Sự xuất hiện của ChatGPT và việc Midjourney được áp dụng ồ ạt đã giúp AI lần đầu tiên đạt được ứng dụng quy mô lớn, tức là sự phổ biến của các mô hình lớn.
Mô hình lớn ở đây ám chỉ các mô hình học máy có số lượng tham số lớn và cấu trúc phức tạp, có khả năng xử lý khối lượng dữ liệu khổng lồ và hoàn thành nhiều nhiệm vụ phức tạp khác nhau.
01 Tranh chấp bản quyền dữ liệu AI
Nếu so sánh mô hình AI hiện nay với chiếc ô tô, thì dữ liệu gốc chính là dầu thô. Dù bằng cách nào, trước hết mô hình AI cần đủ "dầu thô".
Nguồn "dầu thô" của các công ty AI chủ yếu đến từ những loại sau:
-
Các nguồn dữ liệu công khai miễn phí trên mạng như Wikipedia, blog, diễn đàn, tin tức;
-
Các hãng truyền thông và nhà xuất bản lâu đời;
-
Các tổ chức nghiên cứu như trường đại học;
-
Người dùng cá nhân (người dùng C) sử dụng mô hình.
Quyền sở hữu dầu mỏ trong thế giới thực đã có hệ thống pháp luật quy định rõ ràng, nhưng trong lĩnh vực AI vẫn còn khá hỗn loạn, quyền khai thác "dầu thô" này vẫn chưa rõ ràng, dẫn đến vô số tranh chấp phát sinh.
Gần đây, nhiều hãng thu âm lớn đã kiện các công ty sản xuất nhạc bằng AI Suno và Udio, cáo buộc vi phạm bản quyền. Vụ kiện này tương tự vụ The New York Times kiện OpenAI vào tháng 12 năm ngoái.

Ảnh: Billboard
Vào tháng 7 năm 2023, một số tác giả đã khởi kiện công ty này, cáo buộc ChatGPT tạo ra tóm tắt tác phẩm của họ dựa trên nội dung được bảo vệ bản quyền.
Cũng trong tháng 12 năm đó, The New York Times cũng khởi kiện Microsoft và OpenAI về hành vi vi phạm bản quyền tương tự, cáo buộc hai công ty này sử dụng nội dung của báo để huấn luyện chatbot trí tuệ nhân tạo.
Ngoài ra, tại bang California đã có một vụ kiện tập thể cáo buộc OpenAI thu thập thông tin cá nhân của người dùng trên Internet để huấn luyện ChatGPT mà không có sự đồng ý.
Cuối cùng, OpenAI không phải chịu trách nhiệm cho cáo buộc này. Họ cho biết không đồng tình với cáo buộc của The New York Times, cũng không thể tái hiện được các vấn đề mà tờ báo nêu ra; quan trọng hơn, dữ liệu mà The New York Times cung cấp đối với OpenAI không mang tính trọng yếu.

Nguồn:
https://openai.com/index/openai-and-journalism/
Đối với OpenAI, bài học lớn nhất từ sự việc này có lẽ là cần xử lý tốt mối quan hệ với các nhà cung cấp dữ liệu, làm rõ quyền và nghĩa vụ giữa hai bên. Vì vậy, trong gần một năm qua chúng ta thấy OpenAI đã thiết lập quan hệ đối tác với rất nhiều nhà cung cấp dữ liệu, bao gồm The Atlantic, Vox Media, News Corp, Reddit, Financial Times, Le Monde, Prisa Media, Axel Springer, American Journalism Project và nhiều đơn vị khác.
Trong tương lai, OpenAI sẽ được phép sử dụng hợp pháp dữ liệu của các phương tiện truyền thông này, đồng thời các phương tiện truyền thông cũng sẽ tích hợp công nghệ của OpenAI vào sản phẩm của mình.
02 AI thúc đẩy nền tảng nội dung kiếm tiền
Tuy nhiên, lý do cơ bản nhất khiến OpenAI thiết lập quan hệ đối tác với các nhà cung cấp dữ liệu không phải vì sợ bị kiện, mà là do dữ liệu cho học máy sắp cạn kiệt. Các nhà nghiên cứu tại MIT từng tiến hành một nghiên cứu ước tính rằng bộ dữ liệu học máy có thể sẽ cạn kiệt tất cả «dữ liệu ngôn ngữ chất lượng cao» trước năm 2026.
Do đó, «dữ liệu chất lượng cao» trở thành hàng hóa quý giá đối với các nhà sản xuất mô hình như OpenAI và Google. Các công ty nội dung liên tục hợp tác với các nhà sản xuất mô hình AI, bước vào chế độ «nằm yên cũng kiếm tiền».
Nền tảng truyền thông truyền thống Shutterstock đã lần lượt hợp tác với các công ty AI như Meta, Alphabet, Amazon, Apple, OpenAI, Reka... Năm 2023, nhờ cấp phép nội dung cho mô hình AI, doanh thu hàng năm tăng lên 104 triệu USD, dự kiến đến năm 2027 sẽ đạt 250 triệu USD; khoản thu từ việc Reddit cấp phép bản quyền nội dung cho Google lên tới 60 triệu USD mỗi năm; Apple cũng đang tìm kiếm hợp tác với các phương tiện truyền thông chính thống, đưa ra mức phí bản quyền ít nhất 50 triệu USD mỗi năm. Chi phí bản quyền mà các công ty nội dung nhận được từ các công ty AI đang tăng vọt với tốc độ tăng trưởng hàng năm lên tới 450%.

Ảnh: CX Scoop
Trong những năm gần đây, ngoài lĩnh vực phát trực tuyến (streaming), việc kiếm tiền từ nội dung gặp khó khăn – đây là một điểm đau lớn trong ngành nội dung. So với thời kỳ khởi nghiệp Internet, sự xuất hiện của AI đã mở ra tiềm năng lớn hơn và kỳ vọng doanh thu mạnh mẽ hơn cho ngành nội dung.
03 Dữ liệu chất lượng cao vẫn khan hiếm
Tất nhiên, không phải mọi nội dung đều đáp ứng nhu cầu của AI.
Liên quan đến tranh luận giữa OpenAI và The New York Times được nhắc đến ở trên, một điểm nổi bật khác là chất lượng dữ liệu. Cũng giống như việc tinh chế dầu từ dầu thô, một là bản thân dầu phải tốt, hai là kỹ thuật tinh chế phải tốt.
OpenAI đặc biệt nhấn mạnh rằng nội dung của The New York Times không đóng góp đáng kể nào vào quá trình huấn luyện mô hình của họ. So với Shutterstock – nơi OpenAI sẵn sàng chi hàng chục triệu USD mỗi năm – thì các phương tiện truyền thông dạng văn bản dựa vào tính thời sự như The New York Times không phải là đối tượng được ưu ái trong thời đại AI. AI cần nhiều hơn những dữ liệu sâu sắc và độc đáo.
Dữ liệu chất lượng cao quá khan hiếm, các công ty AI bắt đầu chú trọng vào «kỹ thuật tinh chế» và «ứng dụng tích hợp toàn diện».
Ngày 25 tháng 6, OpenAI đã mua lại công ty cơ sở dữ liệu phân tích thời gian thực Rockset. Công ty này chủ yếu cung cấp chức năng lập chỉ mục và truy vấn dữ liệu thời gian thực. OpenAI sẽ tích hợp công nghệ của Rockset vào sản phẩm của mình nhằm nâng cao giá trị sử dụng dữ liệu theo thời gian thực.

Ảnh: DePIN Scan
Thông qua việc mua lại Rockset, OpenAI dự định giúp AI tận dụng và truy cập dữ liệu thời gian thực hiệu quả hơn. Điều này sẽ cho phép sản phẩm của OpenAI hỗ trợ các ứng dụng phức tạp hơn như hệ thống gợi ý thời gian thực, chatbot điều khiển bằng dữ liệu động, hệ thống giám sát và cảnh báo thời gian thực...
Rockset giống như «bộ phận lọc dầu» tích hợp bên trong OpenAI, có khả năng chuyển đổi trực tiếp dữ liệu thường thành dữ liệu chất lượng cao phục vụ ứng dụng.
04 Xác lập quyền sở hữu dữ liệu cho người sáng tạo có phải là viễn tưởng?
Dữ liệu trên các nền tảng truyền thông Internet (Facebook, Reddit...) phần lớn đến từ UGC – nội dung do người dùng đóng góp. Nhiều nền tảng khi thu được khoản phí dữ liệu cao từ các công ty AI, âm thầm thêm vào điều khoản người dùng một dòng như: «nền tảng có quyền sử dụng dữ liệu người dùng để huấn luyện mô hình AI».
Mặc dù điều khoản người dùng đã ghi rõ quyền lực đối với việc huấn luyện mô hình AI, nhưng nhiều tác giả không rõ nội dung do mình tạo ra cụ thể được dùng bởi mô hình nào, không biết liệu có phải trả phí hay không, và càng không thể nhận được quyền lợi thuộc về mình.
Tại cuộc họp báo kết quả kinh doanh quý của Meta hồi tháng 2 năm nay, Zuckerberg đã khẳng định rõ ràng sẽ sử dụng ảnh trên Facebook và Instagram để huấn luyện công cụ AI tạo nội dung của ông.
Theo báo cáo, Tumblr cũng đã bí mật ký thỏa thuận cấp phép nội dung với OpenAI và Midjourney, nhưng chưa công bố nội dung cụ thể của thỏa thuận.
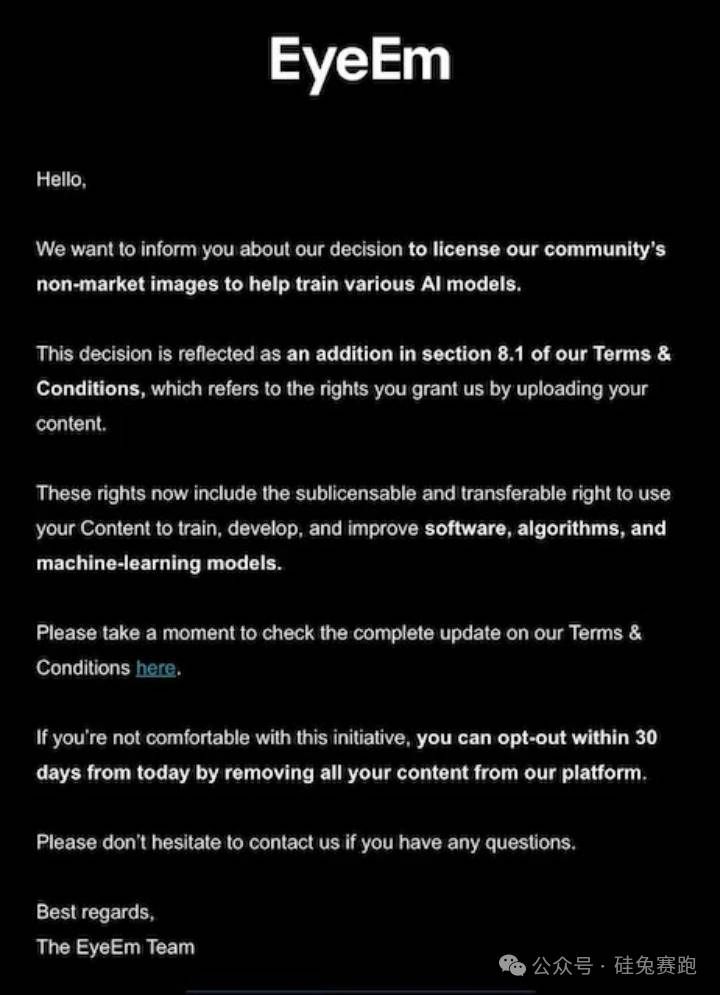
Gần đây, các nhà sáng tạo trên nền tảng kho ảnh EyeEm cũng nhận được một thông báo, nhắc nhở rằng ảnh họ đăng sẽ được dùng để huấn luyện mô hình AI. Thông báo nói rằng người dùng có thể chọn không dùng sản phẩm nữa nếu không đồng ý, nhưng chưa đề cập bất kỳ chính sách bồi thường nào. Mẹ công ty Freepik của EyeEm tiết lộ với Reuters rằng họ đã ký thỏa thuận với hai công ty công nghệ lớn, cấp phép phần lớn trong số 200 triệu bức ảnh với giá khoảng 3 xu Mỹ mỗi bức. CEO Joaquin Cuenca Abela cho biết còn năm giao dịch tương tự đang trong quá trình đàm phán, nhưng từ chối tiết lộ danh tính người mua.
Các nền tảng nội dung chủ yếu dựa vào UGC như Getty Images, Adobe, Photobucket, Flickr, Reddit... đều đang đối mặt với vấn đề tương tự. Trước cám dỗ kiếm tiền khổng lồ từ dữ liệu, các nền tảng chọn bỏ qua quyền sở hữu nội dung của người dùng, gom toàn bộ dữ liệu bán cho các công ty mô hình AI.
Toàn bộ quá trình diễn ra trong bóng tối, người sáng tạo không có cơ hội phản kháng. Thậm chí nhiều người sáng tạo có thể chỉ đến một ngày tương lai, khi nhìn thấy nội dung tương tự tác phẩm của mình được tạo ra bởi một mô hình nào đó, mới bắt đầu nghi ngờ rằng tác phẩm trước đây của họ đã bị một nền tảng nào đó đem đi bán cho công ty AI để huấn luyện mô hình.
Để giải quyết vấn đề xác lập quyền sở hữu dữ liệu và bảo vệ lợi ích cho người sáng tạo, Web3 có thể là lựa chọn tốt. Khi các công ty AI liên tục lập đỉnh mới trên thị trường chứng khoán Mỹ, các đồng tiền khái niệm AI trong web3 cũng đồng thời bay vút lên trời. Blockchain, với đặc tính phi tập trung và không thể thay đổi, có lợi thế vượt trội trong việc bảo vệ quyền lợi của người sáng tạo.
Các nội dung truyền thông như hình ảnh và video đã hoàn thành việc đưa lên chuỗi (on-chain) quy mô lớn trong đợt bùng nổ thị trường năm 2021, và việc đưa nội dung UGC từ các nền tảng xã hội lên chuỗi cũng đang âm thầm diễn ra. Đồng thời, nhiều nền tảng mô hình AI web3 đã bắt đầu khuyến khích người dùng bình thường đóng góp vào việc huấn luyện mô hình, cả chủ sở hữu dữ liệu lẫn người tham gia huấn luyện đều được thưởng.
Sự phát triển theo cấp số nhân của mô hình AI đặt ra nhu cầu lớn hơn về việc xác lập quyền sở hữu dữ liệu. Người sáng tạo nên tự hỏi: Tại sao tác phẩm của tôi lại bị bán cho công ty mô hình AI với giá 5 xu mà không cần sự đồng ý? Tại sao trong suốt quá trình này tôi hoàn toàn không hay biết và không nhận được bất kỳ lợi ích nào?
Ngay cả khi các nền tảng truyền thông khai thác cạn kiệt cũng không thể xoa dịu nỗi lo về dữ liệu của các công ty mô hình AI. Tiền đề để sản xuất ra lượng lớn dữ liệu chất lượng cao là việc xác lập quyền sở hữu dữ liệu, cũng như phân phối lợi ích hợp lý giữa ba bên: người sáng tạo, nền tảng và công ty mô hình AI.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News