

Mức độ tối ưu hóa tốt nhất: Rút ra kinh nghiệm về tối đa hóa mục tiêu từ học máy
Tuyển chọn TechFlowTuyển chọn TechFlow
Mức độ tối ưu hóa tốt nhất: Rút ra kinh nghiệm về tối đa hóa mục tiêu từ học máy
Hiệu suất thấp thì không được, nhưng hiệu suất cao là chắc chắn tốt sao?
Tác giả: DAN SHIPPER
Biên dịch: Ines
Midjourney prompt: "Góc nhìn từ người sắp qua cầu, hình dung một cây cầu treo bằng ván gỗ bắc ngang qua vực sâu rộng và nguy hiểm, tranh màu nước."
Tôi nên tối ưu đến mức độ nào? Đây là câu hỏi tôi thường tự đặt ra, và tôi nghĩ bạn cũng vậy. Nếu bạn đang cố gắng đạt được một mục tiêu nào đó — ví dụ như xây dựng một công ty tồn tại lâu dài, tìm kiếm người bạn đời lý tưởng hay thiết kế một kế hoạch tập luyện hoàn hảo — thì xu hướng tự nhiên của bạn sẽ là nỗ lực hết sức để đạt đến sự hoàn hảo.
Tối ưu hóa là hành trình theo đuổi sự hoàn mỹ — chúng ta tối ưu vì không muốn thỏa hiệp. Nhưng liệu việc cứ mãi theo đuổi sự hoàn hảo có thực sự tốt hơn? Nói cách khác, tối ưu đến đâu thì coi là quá đà?
Lâu nay, con người luôn cố gắng hiểu rõ mức độ khó khăn khi tối ưu hóa. Bạn có thể xếp các quan điểm này trên một phổ liên tục.
Một phía là John Mayer, người tin rằng “ít hơn chính là nhiều hơn”. Trong ca khúc nổi tiếng "Gravity" của mình, anh hát:
"Ồ, gấp đôi niềm vui không thực sự mang lại gấp đôi hạnh phúc / Cũng chẳng kéo dài được như một nửa / Càng tham lam, ta càng dễ gục ngã."
Dolly Parton lại giữ quan điểm ngược lại. Bà từng nói: “Ít chưa chắc đã nhiều. Nhiều mới là nhiều.”
Aristotle (A-ri-stốt) không đồng tình với cả hai. Hơn 2000 năm trước, ông đã đưa ra khái niệm “điểm trung dung”: Khi bạn tối ưu cho một mục tiêu, điều bạn cần là một mức độ nằm giữa thái quá và thiếu sót.
Vậy ta nên chọn ai? Giờ đây là năm 2023. Chúng ta mong muốn tiếp cận vấn đề này một cách định lượng hơn là suông. Lý tưởng nhất là ta có thể đo lường hiệu quả của việc tối ưu hóa theo một cách nào đó.
Ngày nay, chúng ta thường có thể nhờ đến máy móc. Tối ưu mục tiêu là một chủ đề trọng tâm trong nghiên cứu học máy và trí tuệ nhân tạo. Để mạng thần kinh làm được bất kỳ điều gì hữu ích, bạn phải đặt cho nó một mục tiêu và cố gắng giúp nó đạt được mục tiêu ấy tốt hơn. Những gì các nhà khoa học máy tính tìm ra trong lĩnh vực mạng thần kinh có thể dạy chúng ta rất nhiều về việc tối ưu hóa nói chung.
Gần đây, một bài viết của nhà nghiên cứu học máy Jascha Sohl-Dickstein khiến tôi đặc biệt hào hứng, khi ông đưa ra lập luận sau:
Học máy cho thấy rằng việc quá mức tối ưu hóa mục tiêu sẽ khiến mọi chuyện lệch lạc nghiêm trọng — và bạn có thể thấy điều này một cách định lượng. Khi các thuật toán học máy quá mức tối ưu mục tiêu, chúng thường bỏ qua bức tranh tổng thể, dẫn đến hiện tượng mà các nhà nghiên cứu gọi là “quá khớp” (overfitting). Trên thực tế, khi chúng ta quá tập trung vào việc hoàn thiện một quy trình hay nhiệm vụ cụ thể, ta có thể trở nên quá thích nghi với nhiệm vụ đó đến mức không còn xử lý hiệu quả được những thay đổi hay thử thách mới.
Vì vậy, xét về tối ưu hóa — thật ra, “nhiều” không đồng nghĩa với “nhiều hơn”. Xin chào, Dolly Parton.
Bài viết này là nỗ lực của tôi nhằm tóm tắt bài viết của Jascha và giải thích quan điểm của ông bằng ngôn ngữ dễ hiểu. Để hiểu rõ hơn, hãy cùng xem quá trình huấn luyện mô hình học máy diễn ra như thế nào.
Mindsera sử dụng trí tuệ nhân tạo để giúp bạn khám phá những mô hình tư duy tiềm ẩn, vạch ra những điểm mù trong suy nghĩ và hiểu rõ bản thân hơn.
Bạn có thể xây dựng tư duy của riêng mình thông qua các mẫu nhật ký dựa trên các khuôn khổ và mô hình tư duy hữu ích, từ đó ra quyết định tốt hơn, cải thiện sức khỏe và nâng cao năng suất làm việc.
Giáo viên AI của Mindsera mô phỏng cách tư duy của những bậc thầy tư tưởng như Marcus Aurelius và Socrates, mở ra những con đường mới cho nhận thức của bạn.
Hệ thống phân tích thông minh sẽ tạo ra tác phẩm gốc dựa trên bài viết của bạn, đo lường trạng thái cảm xúc, phản ánh tính cách và đưa ra lời khuyên cá nhân hóa để bạn tiến bộ hơn.
Xây dựng nhận thức bản thân, làm rõ tư duy và thành công trong một thế giới ngày càng bất định.
Hãy bắt đầu ngay hôm nay.
Muốn trở thành tình nguyện viên? Bấm vào đây.
👉https://www.passionfroot.me/every
Hiệu quả quá mức khiến mọi thứ tệ đi
Hãy tưởng tượng bạn muốn tạo một mô hình học máy có khả năng phân loại ảnh chó xuất sắc. Bạn muốn đưa vào một bức ảnh chó và nhận về giống chó tương ứng. Nhưng bạn không chỉ muốn một bộ phân loại ảnh chó thông thường. Bạn muốn một cỗ máy phân loại học máy phi thường, bất chấp chi phí, mã hóa không ngừng nghỉ và hàng tá cà phê. (Dù sao thì chúng ta đang tối ưu hóa.)
Vậy làm thế nào để đạt được điều đó? Dù có nhiều chiến lược, nhưng bạn có lẽ sẽ chọn học có giám sát (supervised learning). Học có giám sát giống như gán một gia sư cho mô hình học máy của bạn: liên tục đặt câu hỏi và sửa sai khi mô hình trả lời sai, dần dần giúp mô hình nắm bắt câu trả lời đúng. Trong quá trình huấn luyện này, độ chính xác của mô hình sẽ tăng dần.
Đầu tiên, bạn cần chuẩn bị một tập dữ liệu ảnh để huấn luyện mô hình. Bạn gán nhãn sẵn cho các ảnh này: “Poodle”, “Cockapoo”, “Dandie Dinmont Terrier”, v.v. Sau đó, bạn đưa các ảnh và nhãn tương ứng vào mô hình để bắt đầu quá trình học.
Phương pháp học của mô hình giống như một quá trình “thử và sai”. Bạn đưa một ảnh cho nó, nó đoán xem đó là nhãn gì. Nếu sai, bạn điều chỉnh nhẹ mô hình để lần sau nó đoán chính xác hơn. Theo thời gian, bạn sẽ thấy mô hình ngày càng giỏi hơn trong việc dự đoán nhãn của các ảnh trong tập huấn luyện.
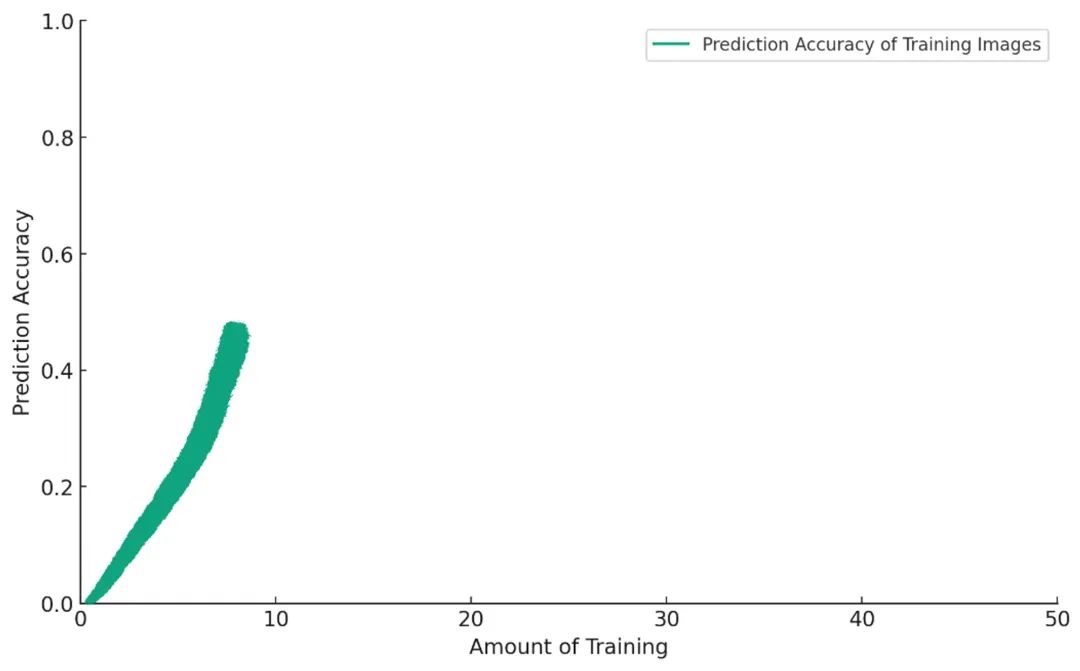
Khi mô hình ngày càng giỏi trong việc dự đoán ảnh thuộc tập huấn luyện, bạn đưa ra một thử thách mới: yêu cầu mô hình gán nhãn cho những ảnh chó mà nó chưa từng thấy trong quá trình huấn luyện.
Đây là một bài kiểm tra quan trọng: nếu bạn chỉ hỏi về những ảnh mà mô hình đã thấy, thì giống như để nó quay cóp trong kỳ thi. Vì vậy, bạn tìm thêm một số ảnh chó mà bạn chắc chắn mô hình chưa từng gặp.
Ban đầu, mọi chuyện diễn ra rất thuận lợi. Càng huấn luyện, mô hình càng hoạt động tốt hơn:
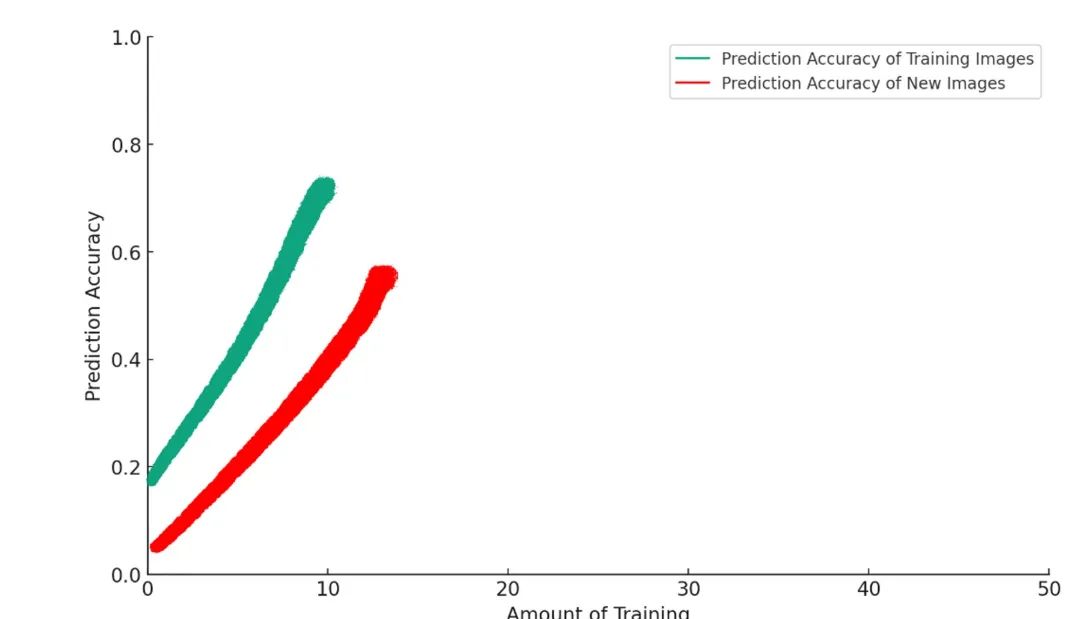
Nhưng nếu bạn tiếp tục huấn luyện, mô hình sẽ bắt đầu hành xử như kiểu “AI đi vệ sinh lên thảm”: chuyện gì đang xảy ra vậy?
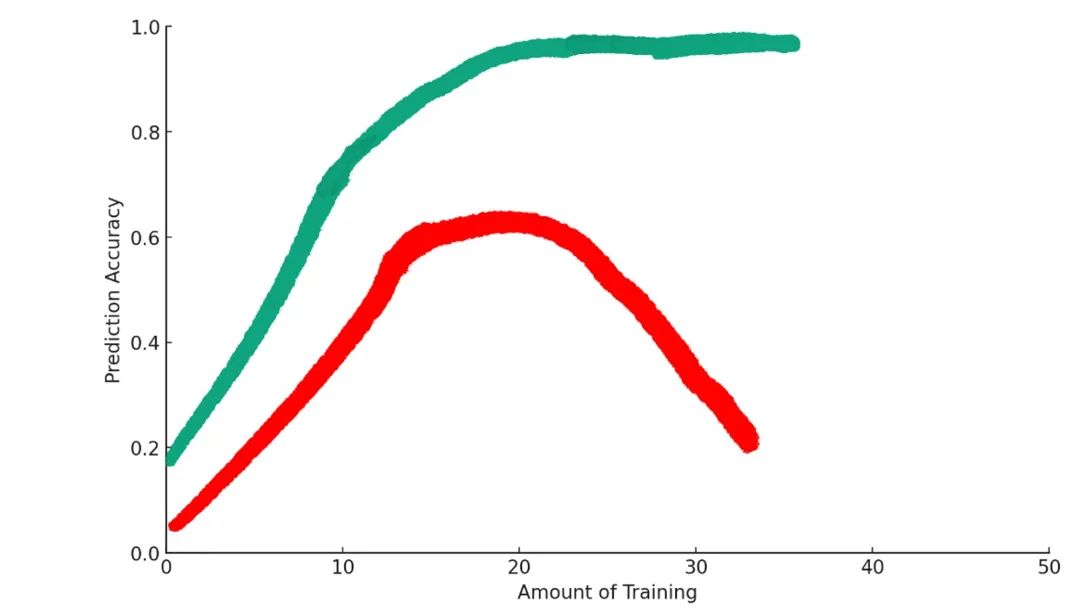
Điều gì đã xảy ra?
Một chút huấn luyện giúp mô hình tiến bộ trong việc đạt mục tiêu. Nhưng vượt qua một điểm nhất định, việc huấn luyện quá mức lại khiến tình hình tệ đi. Đây là hiện tượng trong học máy gọi là “quá khớp” (overfitting).
Tại sao quá khớp khiến mọi thứ tệ đi
Trong quá trình huấn luyện mô hình, chúng ta thực chất đang thực hiện một thao tác tinh vi.
Chúng ta muốn mô hình có thể gán nhãn tốt cho mọi ảnh chó — đó là mục tiêu thực sự. Nhưng ta không thể trực tiếp tối ưu điều đó, vì ta không thể có được tất cả các ảnh chó có thể tồn tại. Thay vào đó, ta tối ưu một mục tiêu thay thế (proxy): một tập con nhỏ các ảnh chó, mà ta hy vọng đại diện được cho mục tiêu thực sự.
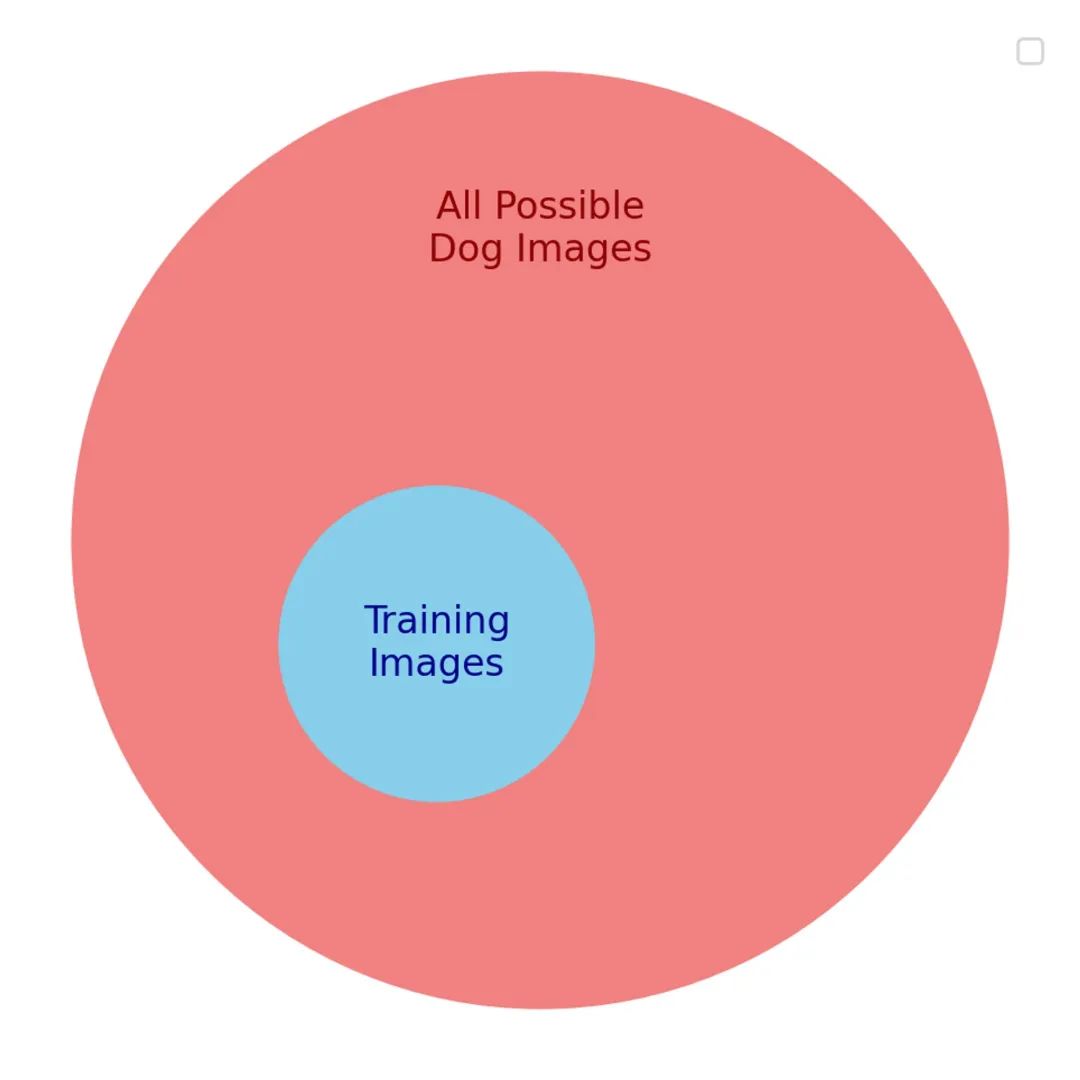
Giữa mục tiêu thay thế và mục tiêu thực tế có nhiều điểm tương đồng. Vì vậy ban đầu, mô hình tiến bộ trên cả hai mục tiêu. Nhưng khi huấn luyện càng sâu, những điểm tương đồng hữu ích này dần biến mất. Mô hình giờ chỉ giỏi nhận diện các ảnh trong tập huấn luyện, còn với ảnh mới thì xử lý kém.
Khi tiếp tục huấn luyện, mô hình bắt đầu phụ thuộc quá mức vào các chi tiết cụ thể trong tập dữ liệu huấn luyện. Ví dụ, tập dữ liệu có thể chứa quá nhiều ảnh chó vàng. Khi bị huấn luyện quá mức, mô hình có thể học sai rằng mọi con chó màu vàng đều là Labradoodle.
Khi gặp ảnh mới khác biệt với đặc điểm của tập huấn luyện, mô hình quá khớp sẽ hoạt động rất tồi tệ.
Quá khớp hé lộ một điểm then chốt trong hành trình tối ưu hóa.
Thứ nhất, khi cố gắng tối ưu bất cứ điều gì, bạn hiếm khi tối ưu trực tiếp điều đó — bạn tối ưu một đại diện. Trong bài toán phân loại chó, ta không thể huấn luyện trên mọi ảnh chó có thể có. Thay vào đó, ta tối ưu trên một tập con và hy vọng điều này khái quát hóa tốt. Và nó thực sự hiệu quả — cho đến khi ta tối ưu quá mức.
Điều này dẫn đến điểm thứ hai: khi bạn quá mức tối ưu một hàm đại diện, bạn thực ra đang rời xa mục tiêu ban đầu.
Một khi bạn hiểu cơ chế này trong học máy, bạn sẽ bắt đầu thấy nó ở khắp nơi.
Áp dụng quá khớp vào thế giới thực
Lấy trường học làm ví dụ:
Ở trường, chúng ta muốn tối ưu việc học kiến thức chuyên môn. Nhưng việc đo lường mức độ hiểu biết sâu sắc là khó, nên ta dùng các bài kiểm tra chuẩn hóa. Các bài kiểm tra này phần nào đại diện tốt cho việc bạn hiểu một môn học đến đâu.
Nhưng khi học sinh và nhà trường quá chú trọng điểm số, áp lực tối ưu điểm thi bắt đầu làm hại đến việc học thực sự. Học sinh trở nên quá thích nghi với việc tăng điểm số. Họ học cách thi (hoặc gian lận) để tối ưu điểm, chứ không thực sự học kiến thức.
Thế giới kinh doanh cũng có hiện tượng quá khớp. Trong cuốn sách “Fooled by Randomness”, Nassim Taleb kể về một ngân hàng tên Carlos, một nhà giao dịch trái phiếu thị trường mới nổi ăn mặc bảnh bao. Phong cách giao dịch của anh ta là “mua lúc giá giảm”: năm 1995, khi tiền tệ Mexico mất giá, Carlos mua vào mức thấp và thu lợi khi trái phiếu tăng giá sau khủng hoảng.
Chiến lược mua lúc giá giảm này mang lại lợi nhuận ròng 80 triệu USD cho công ty. Nhưng Carlos trở nên “quá thích nghi” với thị trường anh ta tiếp xúc, và việc theo đuổi tối ưu lợi nhuận cuối cùng dẫn đến thất bại.
Vào mùa hè năm 1998, anh ta mua vào trái phiếu Nga ở mức đáy. Khi mùa hè trôi qua, giá tiếp tục giảm — Carlos tiếp tục mua thêm. Anh ta liên tục tăng lệnh, đến khi trái phiếu ở mức rất thấp, và cuối cùng mất 300 triệu USD — gấp ba lần tổng lợi nhuận anh kiếm được suốt sự nghiệp.
Như Taleb chỉ ra trong sách: “Trên thị trường, các nhà giao dịch thành công nhất có thể là những người thích nghi tốt nhất với chu kỳ gần nhất.”
Nói cách khác, tối ưu quá mức lợi nhuận có nghĩa là quá thích nghi với chu kỳ thị trường hiện tại. Hiệu suất của bạn tăng mạnh ngắn hạn. Nhưng chu kỳ hiện tại chỉ là một đại diện cho hành vi thị trường tổng thể — khi chu kỳ thay đổi, chiến lược thành công trước đây có thể khiến bạn phá sản.
Cùng logic này áp dụng cho công việc của tôi. Every kinh doanh truyền thông theo mô hình đăng ký, tôi muốn tăng MRR (doanh thu lặp hàng tháng). Để đạt được điều đó, tôi có thể thưởng cho các tác giả khi họ tạo ra nhiều lượt xem trang hơn, từ đó tăng lưu lượng bài viết.
Việc này có thể hiệu quả! Tăng lưu lượng thực sự giúp tăng số người đăng ký trả phí — đến một mức nào đó. Vượt qua điểm đó, tôi dám cá các tác giả sẽ bắt đầu dùng tiêu đề giật tít hoặc nội dung nhạy cảm để tăng lượt xem, những bài viết này sẽ không thu hút độc giả trung thành và sẵn sàng trả tiền. Cuối cùng, nếu tôi biến Every thành một nhà máy sản xuất tiêu đề giật tít, số người đăng ký trả phí có thể giảm thay vì tăng.
Nếu bạn quan sát kỹ đời sống hay công việc của mình, bạn chắc chắn sẽ thấy cùng một mô hình. Vấn đề là: chúng ta nên làm gì?
Vậy chúng ta nên làm gì?
Các nhà nghiên cứu học máy sử dụng nhiều kỹ thuật để ngăn ngừa quá khớp. Bài viết của Jascha gợi ý ba biện pháp chính: dừng sớm, thêm nhiễu ngẫu nhiên và chuẩn hóa (regularization).
Dừng sớm (Early stopping)
Nghĩa là luôn kiểm tra hiệu suất của mô hình trên mục tiêu thực sự, và tạm dừng huấn luyện khi hiệu suất bắt đầu giảm.
Trong trường hợp Carlos, một nhà giao dịch mất sạch vốn khi mua trái phiếu đang giảm, điều này có thể nghĩa là cần một cơ chế kiểm soát thua lỗ nghiêm ngặt, buộc anh ta phải đóng lệnh khi tổn thất tích lũy đạt đến một mức nhất định.
Thêm nhiễu ngẫu nhiên (Introducing random noise)
Nếu đưa nhiễu ngẫu nhiên vào đầu vào hoặc tham số của mô hình học máy, sẽ khó xảy ra hiện tượng quá khớp hơn. Nguyên tắc tương tự cũng áp dụng cho các hệ thống khác.
Với học sinh và nhà trường, điều này có thể nghĩa là tổ chức kiểm tra chuẩn hóa vào những thời điểm ngẫu nhiên, làm cho việc học tủ trở nên khó khăn hơn.
Chuẩn hóa (Regularization)
Trong học máy, chuẩn hóa được dùng để phạt mô hình nếu nó trở nên quá phức tạp. Mô hình càng phức tạp càng dễ quá khớp dữ liệu. Chi tiết kỹ thuật không quá quan trọng, nhưng khái niệm này có thể áp dụng ngoài học máy để tạo ma sát trong hệ thống.
Nếu tôi muốn khuyến khích tất cả tác giả của Every tăng MRR bằng cách tăng lượt xem trang, tôi có thể điều chỉnh cách thưởng sao cho các lượt xem vượt ngưỡng nhất định sẽ được tính giảm dần.
Đây là những giải pháp tiềm năng cho vấn đề quá khớp, và một lần nữa đưa ta về câu hỏi ban đầu: mức độ tối ưu lý tưởng là gì?
Mức độ tối ưu lý tưởng
Bài học chính ta rút ra là: bạn gần như không bao giờ có thể tối ưu trực tiếp một mục tiêu — thay vào đó, bạn thường đang tối ưu một thứ trông giống mục tiêu nhưng hơi khác. Đó là một đại diện.
Vì bạn phải tối ưu thông qua đại diện, khi tối ưu quá mức, bạn sẽ quá giỏi trong việc cực đại hóa mục tiêu thay thế — điều này thường khiến bạn rời xa mục tiêu thực sự.
Vì vậy, điều cần ghi nhớ là: hãy biết bạn đang tối ưu cái gì. Hãy nhớ rằng đại diện không phải là mục tiêu. Trong quá trình tối ưu, hãy linh hoạt, và sẵn sàng dừng lại hoặc chuyển chiến lược khi thấy rằng sự tương đồng hữu ích giữa mục tiêu thay thế và mục tiêu thực tế đã cạn kiệt.
Còn về quan điểm của John Mayer, Dolly Parton và Aristotle về trí tuệ tối ưu, tôi nghĩ chúng ta phải trao giải cho Aristotle và điểm trung dung của ông.
Khi tối ưu cho một mục tiêu, mức độ tối ưu lý tưởng nằm giữa thái quá và thiếu sót. Đó là điểm “vừa đủ”.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News










