
Sora xuất hiện, năm 2024 có thể trở thành năm đầu tiên của cuộc cách mạng AI+Web3?
Tuyển chọn TechFlowTuyển chọn TechFlow
Sora xuất hiện, năm 2024 có thể trở thành năm đầu tiên của cuộc cách mạng AI+Web3?
Web3 và AI còn có thể tạo ra những tia lửa như thế nào khi giao thoa?
Tác giả: YBB Capital Zeke

Lời mở đầu
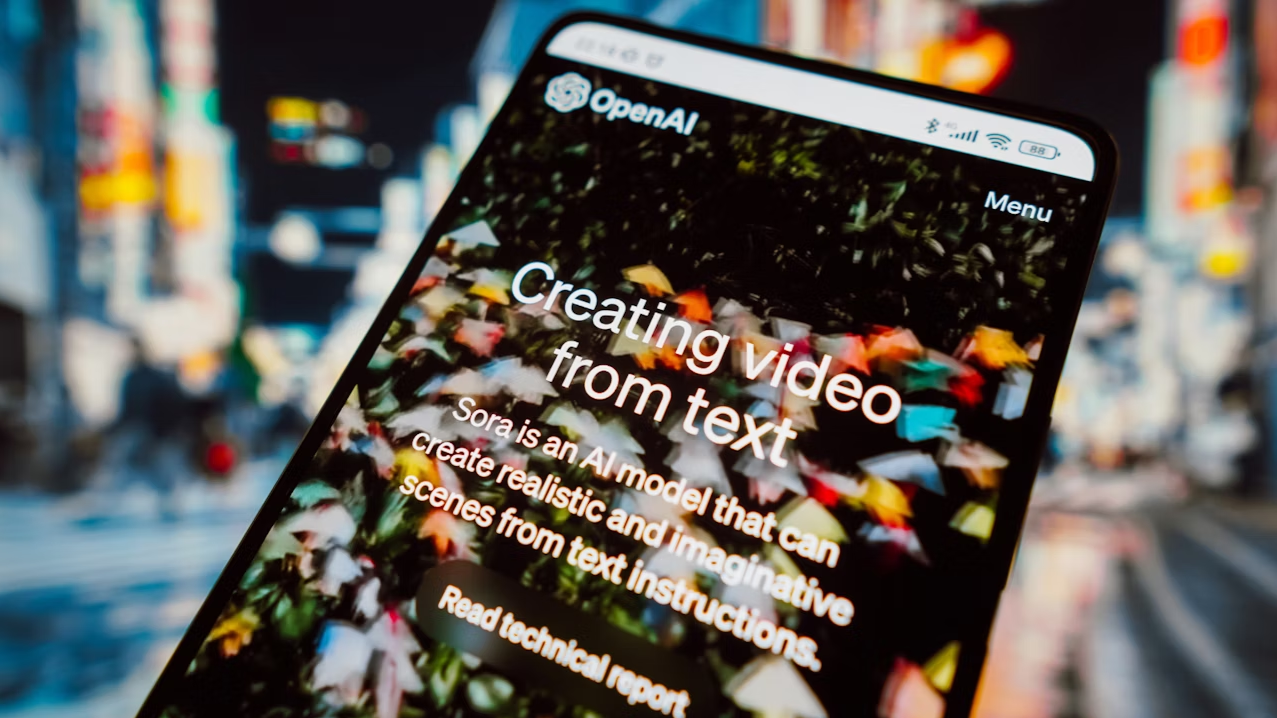
Ngày 16 tháng 2, OpenAI đã công bố mô hình khuếch tán tạo video điều khiển bằng văn bản mới nhất “Sora”, thông qua nhiều đoạn video chất lượng cao bao phủ các loại dữ liệu hình ảnh đa dạng, cho thấy một cột mốc mới nữa của AI tạo sinh. Khác với những công cụ tạo video AI như Pika vẫn đang ở trạng thái tạo vài giây video từ nhiều hình ảnh, Sora được huấn luyện trong không gian tiềm ẩn nén của video và hình ảnh, phân tách chúng thành các mảnh vị trí thời-không, từ đó đạt được khả năng tạo video quy mô lớn. Ngoài ra, mô hình này còn thể hiện khả năng mô phỏng thế giới vật lý và thế giới số, đoạn demo 60 giây cuối cùng được trình bày thậm chí có thể xem như một “bộ mô phỏng tổng quát của thế giới vật lý”.
Về cách xây dựng, Sora tiếp nối con đường công nghệ “dữ liệu nguồn - Transformer - Khuếch tán - Xuất hiện” trước đó của mô hình GPT, điều này có nghĩa là sự trưởng thành của nó cũng cần sức mạnh tính toán làm động cơ, và do dữ liệu huấn luyện video yêu cầu khối lượng lớn hơn nhiều so với dữ liệu huấn luyện văn bản, nhu cầu về sức mạnh tính toán sẽ càng được mở rộng. Tuy nhiên, trong bài viết trước đó của chúng tôi “Tiền cảnh về các lĩnh vực tiềm năng: Thị trường tính toán phi tập trung”, chúng tôi đã thảo luận về tầm quan trọng của sức mạnh tính toán trong kỷ nguyên AI, và khi nhiệt độ AI gần đây liên tục tăng cao, thị trường đã xuất hiện một lượng lớn các dự án tính toán, đồng thời các dự án Depin khác (lưu trữ, tính toán, v.v.) hưởng lợi thụ động cũng đã trải qua một đợt tăng giá mạnh. Vậy ngoài Depin, Web3 và AI khi kết hợp sẽ tạo ra những tia lửa nào? Trong lĩnh vực này còn ẩn chứa những cơ hội gì? Mục đích chính của bài viết này là cập nhật và bổ sung cho bài viết trước đó, đồng thời suy ngẫm về những khả năng tồn tại của Web3 trong kỷ nguyên AI.
Ba hướng phát triển chính trong lịch sử AI
Trí tuệ nhân tạo (Artificial Intelligence) là một ngành khoa học kỹ thuật mới nhằm mô phỏng, mở rộng và tăng cường trí tuệ con người. Từ khi ra đời vào những năm 50-60 của thế kỷ XX, trải qua hơn nửa thế kỷ phát triển, AI hiện đã trở thành công nghệ then chốt thúc đẩy sự thay đổi trong đời sống xã hội và mọi lĩnh vực. Trong quá trình này, ba hướng nghiên cứu chủ đạo là Chủ nghĩa ký hiệu, Chủ nghĩa kết nối và Chủ nghĩa hành vi đã đan xen và phát triển lẫn nhau, trở thành nền tảng cho sự phát triển thần tốc của AI ngày nay.
Chủ nghĩa ký hiệu (Symbolism)
Còn gọi là Chủ nghĩa logic hay Chủ nghĩa quy tắc, cho rằng việc xử lý các ký hiệu để mô phỏng trí tuệ con người là khả thi. Phương pháp này dùng ký hiệu để biểu diễn và thao tác các đối tượng, khái niệm và mối quan hệ giữa chúng trong lĩnh vực vấn đề, đồng thời dùng suy luận logic để giải quyết vấn đề, đặc biệt đã đạt được thành tựu đáng kể trong hệ chuyên gia và biểu diễn tri thức. Quan điểm cốt lõi của chủ nghĩa ký hiệu là hành vi thông minh có thể thực hiện thông qua thao tác ký hiệu và suy luận logic, trong đó các ký hiệu đại diện cho sự trừu tượng hóa cao độ của thế giới thực;
Chủ nghĩa kết nối (Connectionism)
Hay còn gọi là phương pháp mạng nơ-ron, nhằm đạt được trí tuệ bằng cách mô phỏng cấu trúc và chức năng của não người. Phương pháp này xây dựng mạng lưới gồm nhiều đơn vị xử lý đơn giản (giống tế bào thần kinh), thông qua điều chỉnh độ mạnh kết nối giữa các đơn vị (giống synapse) để thực hiện học máy. Chủ nghĩa kết nối đặc biệt nhấn mạnh khả năng học và tổng quát hóa từ dữ liệu, rất phù hợp với nhận dạng mẫu, phân loại và ánh xạ đầu vào - đầu ra liên tục. Học sâu (Deep Learning), như một bước phát triển của chủ nghĩa kết nối, đã đạt được đột phá trong các lĩnh vực như nhận dạng hình ảnh, nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên;
Chủ nghĩa hành vi (Behaviorism)
Chủ nghĩa hành vi gắn liền chặt chẽ với nghiên cứu robot bắt chước sinh học và các hệ thống trí tuệ tự chủ, nhấn mạnh rằng tác nhân thông minh có thể học thông qua tương tác với môi trường. Khác với hai hướng trên, chủ nghĩa hành vi không tập trung vào mô phỏng biểu diễn nội bộ hay quá trình tư duy, mà thông qua vòng lặp cảm nhận và hành động để đạt được hành vi thích nghi. Chủ nghĩa hành vi cho rằng trí tuệ thể hiện qua tương tác động lực, học hỏi với môi trường; phương pháp này đặc biệt hiệu quả khi áp dụng cho robot di động và hệ thống điều khiển thích ứng hoạt động trong môi trường phức tạp và khó dự đoán.
Mặc dù ba hướng nghiên cứu này có sự khác biệt căn bản, nhưng trong nghiên cứu và ứng dụng AI thực tế, chúng có thể tương tác và kết hợp với nhau, cùng thúc đẩy sự phát triển của lĩnh vực AI.
Tổng quan nguyên lý AIGC
AIGC (Nội dung do trí tuệ nhân tạo tạo ra – Artificial Intelligence Generated Content), đang trải qua sự phát triển bùng nổ trong giai đoạn hiện nay, là một sự tiến hóa và ứng dụng của chủ nghĩa kết nối, AIGC có khả năng bắt chước sức sáng tạo của con người để tạo ra nội dung mới lạ. Các mô hình này được huấn luyện bằng tập dữ liệu lớn và các thuật toán học sâu, từ đó học được cấu trúc, mối quan hệ và mẫu hình ẩn sâu bên trong dữ liệu. Dựa trên gợi ý đầu vào của người dùng, chúng tạo ra kết quả đầu ra độc đáo và mới mẻ, bao gồm hình ảnh, video, mã code, âm nhạc, thiết kế, dịch thuật, trả lời câu hỏi và văn bản. Hiện tại, AIGC cơ bản bao gồm ba yếu tố: Học sâu (Deep Learning, viết tắt DL), Dữ liệu lớn và Sức mạnh tính toán quy mô lớn.
Học sâu
Học sâu là một lĩnh vực con của học máy (ML). Các thuật toán học sâu được mô hình hóa theo não người. Ví dụ, não người chứa hàng triệu tế bào thần kinh liên kết với nhau, phối hợp để học và xử lý thông tin. Tương tự, mạng nơ-ron học sâu (hoặc mạng nơ-ron nhân tạo) bao gồm nhiều lớp nơ-ron nhân tạo phối hợp bên trong máy tính. Nơ-ron nhân tạo là các mô-đun phần mềm gọi là nút, sử dụng phép tính toán học để xử lý dữ liệu. Mạng nơ-ron nhân tạo là các thuật toán học sâu sử dụng các nút này để giải quyết các vấn đề phức tạp.
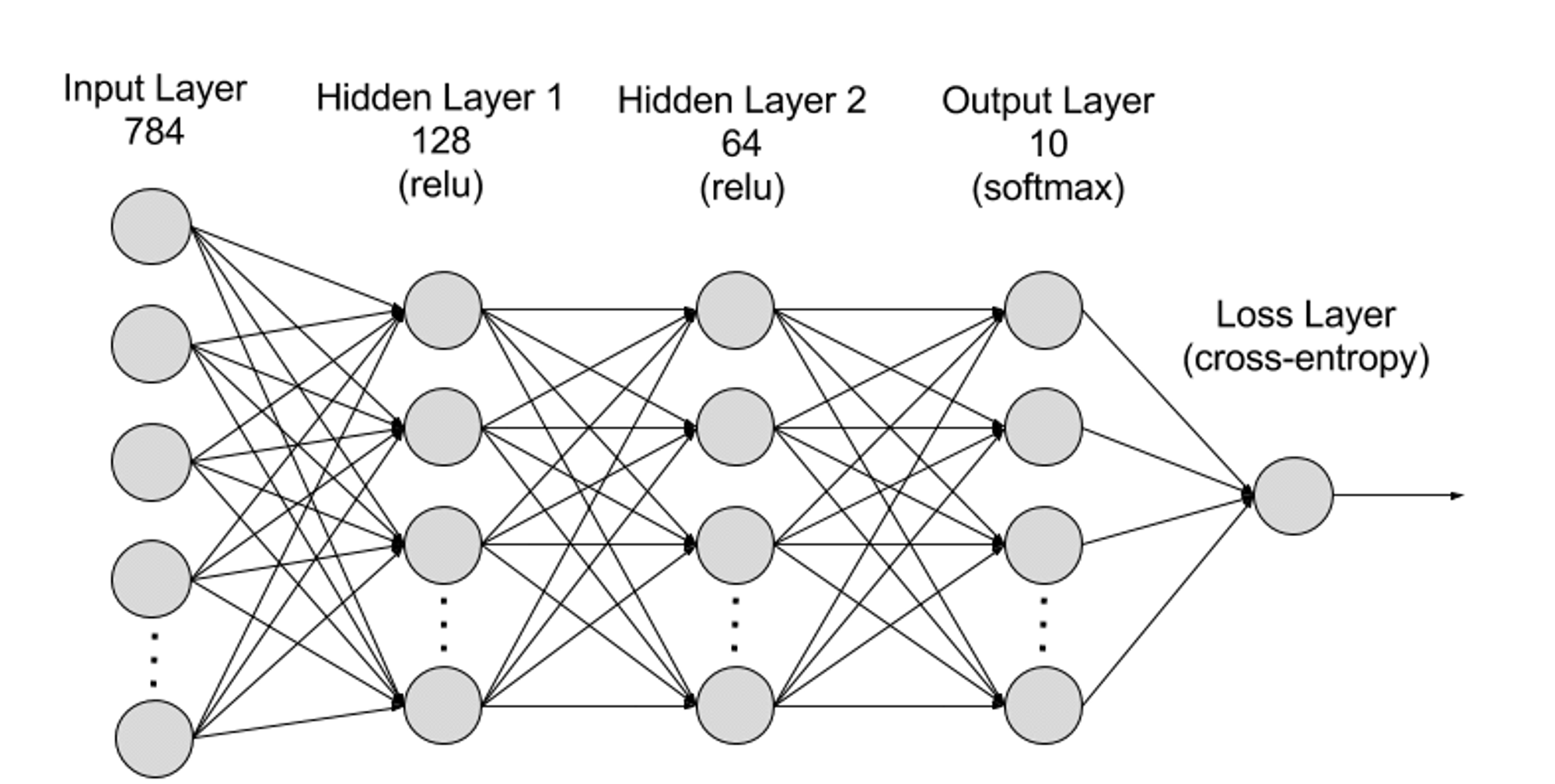
Xét về cấp độ, mạng nơ-ron có thể được chia thành lớp đầu vào, lớp ẩn và lớp đầu ra, và các tham số nối giữa các lớp khác nhau.
● Lớp đầu vào (Input Layer): Lớp đầu vào là lớp đầu tiên của mạng nơ-ron, chịu trách nhiệm nhận dữ liệu đầu vào từ bên ngoài. Mỗi nơ-ron trong lớp đầu vào tương ứng với một đặc trưng của dữ liệu đầu vào. Ví dụ, khi xử lý dữ liệu hình ảnh, mỗi nơ-ron có thể tương ứng với giá trị một pixel của hình ảnh;
● Lớp ẩn (Hidden Layer): Lớp đầu vào xử lý dữ liệu và truyền đến các lớp xa hơn trong mạng nơ-ron. Những lớp ẩn này xử lý thông tin ở các cấp độ khác nhau, điều chỉnh hành vi khi tiếp nhận thông tin mới. Mạng học sâu có thể có hàng trăm lớp ẩn, giúp phân tích vấn đề dưới nhiều góc nhìn khác nhau. Ví dụ, bạn nhận được một hình ảnh con vật chưa biết và phải phân loại, bạn có thể so sánh nó với các con vật đã biết. Chẳng hạn qua hình dạng tai, số chân, kích thước đồng tử để xác định đó là con vật gì. Các lớp ẩn trong mạng nơ-ron sâu hoạt động theo cách tương tự. Nếu thuật toán học sâu cố gắng phân loại hình ảnh động vật, mỗi lớp ẩn sẽ xử lý các đặc điểm khác nhau của con vật và cố gắng phân loại chính xác;
● Lớp đầu ra (Output Layer): Lớp đầu ra là lớp cuối cùng của mạng nơ-ron, chịu trách nhiệm tạo ra đầu ra của mạng. Mỗi nơ-ron ở lớp đầu ra đại diện cho một loại hoặc giá trị đầu ra có thể có. Ví dụ, trong bài toán phân loại, mỗi nơ-ron lớp đầu ra có thể tương ứng với một hạng mục, trong khi bài toán hồi quy có thể chỉ có một nơ-ron ở lớp đầu ra, giá trị của nó biểu thị kết quả dự đoán;
● Tham số: Trong mạng nơ-ron, các kết nối giữa các lớp được biểu thị bằng các tham số trọng số (Weights) và độ lệch (Biases), những tham số này được tối ưu hóa trong quá trình huấn luyện để mạng có thể nhận diện chính xác các mẫu trong dữ liệu và đưa ra dự đoán. Việc tăng số lượng tham số có thể nâng cao dung lượng mô hình của mạng nơ-ron, tức là khả năng học và biểu diễn các mẫu phức tạp trong dữ liệu. Tuy nhiên, tương ứng với đó là nhu cầu về sức mạnh tính toán cũng tăng lên.
Dữ liệu lớn
Để huấn luyện hiệu quả, mạng nơ-ron thường cần lượng lớn dữ liệu, đa dạng, chất lượng cao và đa nguồn. Đây là nền tảng để huấn luyện và kiểm chứng các mô hình học máy. Bằng cách phân tích dữ liệu lớn, mô hình học máy có thể học được các mẫu và mối quan hệ trong dữ liệu, từ đó đưa ra dự đoán hoặc phân loại.
Sức mạnh tính toán quy mô lớn
Cấu trúc phức tạp nhiều lớp của mạng nơ-ron, số lượng lớn tham số, nhu cầu xử lý dữ liệu lớn, cách thức huấn luyện lặp đi lặp lại (trong giai đoạn huấn luyện, mô hình cần lặp đi lặp lại nhiều lần, quá trình huấn luyện cần tính toán lan truyền xuôi và lan truyền ngược ở mỗi lớp, bao gồm tính toán hàm kích hoạt, tính toán hàm mất mát, tính toán gradient và cập nhật trọng số), nhu cầu tính toán độ chính xác cao, khả năng tính toán song song, kỹ thuật tối ưu hóa và chuẩn hóa, cũng như quá trình đánh giá và kiểm chứng mô hình – tất cả những yếu tố này cộng lại dẫn đến nhu cầu cao về sức mạnh tính toán.

Sora
Là mô hình AI tạo video mới nhất do OpenAI phát hành, Sora đại diện cho bước tiến khổng lồ trong khả năng xử lý và hiểu dữ liệu hình ảnh đa dạng của trí tuệ nhân tạo. Bằng cách sử dụng mạng nén video và công nghệ mảnh không-thời gian, Sora có thể chuyển đổi lượng lớn dữ liệu hình ảnh thu thập từ khắp nơi trên thế giới, qua các thiết bị khác nhau, thành một dạng biểu diễn thống nhất, từ đó đạt được xử lý và hiểu nội dung hình ảnh phức tạp một cách hiệu quả. Dựa trên mô hình khuếch tán có điều kiện văn bản, Sora có thể tạo ra video hoặc hình ảnh khớp cực kỳ cao với gợi ý văn bản, thể hiện khả năng sáng tạo và thích nghi rất lớn.
Tuy nhiên, mặc dù Sora đã đạt được đột phá trong tạo video và mô phỏng tương tác thế giới thực, nó vẫn đối mặt với một số hạn chế, bao gồm độ chính xác mô phỏng thế giới vật lý, tính nhất quán khi tạo video dài, khả năng hiểu các chỉ thị văn bản phức tạp, cũng như hiệu suất huấn luyện và tạo. Hơn nữa, bản chất Sora vẫn là sự tiếp nối con đường công nghệ cũ "dữ liệu lớn - Transformer - Khuếch tán - Xuất hiện" theo kiểu thẩm mỹ bạo lực nhờ sức mạnh tính toán mang tính độc quyền và lợi thế tiên phong của OpenAI, nên các công ty AI khác vẫn có khả năng vượt mặt bằng công nghệ đột phá.
Mặc dù Sora không có nhiều liên hệ trực tiếp với blockchain, nhưng cá nhân tôi cho rằng trong một đến hai năm tới, do ảnh hưởng của Sora, sẽ buộc các công cụ tạo nội dung AI chất lượng cao khác xuất hiện và phát triển nhanh chóng, đồng thời ảnh hưởng đến nhiều lĩnh vực trong Web3 như GameFi, mạng xã hội, nền tảng sáng tạo, Depin,... Vì vậy, việc hiểu rõ sơ bộ về Sora là cần thiết. Làm sao để AI trong tương lai kết hợp hiệu quả với Web3 có lẽ là một trọng tâm mà chúng ta cần suy ngẫm.
Bốn con đường kết hợp AI x Web3
Như đã nêu ở trên, chúng ta có thể biết rằng cơ sở hạ tầng mà AI tạo sinh cần thực ra chỉ có ba điểm: thuật toán, dữ liệu, sức mạnh tính toán. Mặt khác, xét về tính phổ quát và hiệu quả tạo ra, AI là công cụ cách mạng hóa phương thức sản xuất. Trong khi đó, blockchain có hai tác dụng lớn nhất: tái cấu trúc quan hệ sản xuất và phi tập trung. Vì vậy, cá nhân tôi cho rằng sự va chạm giữa hai lĩnh vực này có thể tạo ra bốn con đường sau:
Tính toán phi tập trung
Do trước đây đã từng viết bài về chủ đề liên quan, mục đích chính của đoạn này là cập nhật tình hình gần đây của lĩnh vực tính toán. Khi nói đến AI, sức mạnh tính toán luôn là yếu tố không thể bỏ qua. Nhu cầu tính toán khổng lồ của AI, sau khi Sora ra đời, đã trở nên khó tưởng tượng. Gần đây, tại Diễn đàn Kinh tế Thế giới Davos 2024 ở Thụy Sĩ, CEO OpenAI Sam Altman thẳng thắn cho rằng tính toán và năng lượng là xiềng xích lớn nhất hiện nay, tầm quan trọng của cả hai trong tương lai thậm chí sẽ ngang bằng với tiền tệ. Sau đó, ngày 10 tháng 2, Sam Altman đăng tải trên Twitter một kế hoạch cực kỳ kinh ngạc: huy động 7 nghìn tỷ USD (tương đương 40% GDP toàn quốc Trung Quốc năm 2023) để thay đổi cục diện toàn cầu ngành bán dẫn, thành lập một đế chế chip. Khi viết bài về tính toán, trí tưởng tượng của tôi còn giới hạn ở việc các quốc gia phong tỏa, các tập đoàn lớn độc quyền, giờ đây một công ty lại muốn kiểm soát toàn bộ ngành bán dẫn toàn cầu thì quả thật rất điên rồ.
Do đó, tầm quan trọng của tính toán phi tập trung là hiển nhiên. Đặc tính blockchain thực sự có thể giải quyết vấn đề độc quyền cực đoan hiện nay về sức mạnh tính toán, cũng như vấn đề giá GPU chuyên dụng quá cao. Xét từ góc độ AI cần, việc sử dụng sức mạnh tính toán có thể chia thành hai hướng: suy luận (inference) và huấn luyện (training). Các dự án tập trung vào huấn luyện hiện vẫn rất ít ỏi, do phải kết hợp thiết kế mạng phi tập trung với mạng nơ-ron, cộng thêm yêu cầu phần cứng cực cao, nên chắc chắn đây là hướng có ngưỡng vào rất cao và khó triển khai. Trong khi đó, suy luận đơn giản hơn nhiều, vừa thiết kế mạng phi tập trung không phức tạp, vừa yêu cầu phần cứng và băng thông thấp, hiện là hướng khá phổ biến.
Không gian tưởng tượng của thị trường tính toán tập trung là rất lớn, thường gắn liền với cụm từ khóa “hàng nghìn tỷ đô”, đồng thời cũng là chủ đề dễ bị thổi phồng thường xuyên trong kỷ nguyên AI. Tuy nhiên, xét từ lượng lớn dự án gần đây đổ xô ra mắt, phần lớn đều là chạy theo trào lưu, tranh thủ độ nóng. Luôn giương cao ngọn cờ đúng đắn "phi tập trung" nhưng lại im lặng trước vấn đề hiệu suất thấp của mạng phi tập trung. Thiết kế lại mang tính đồng nhất cao, rất nhiều dự án trông giống nhau (thiết kế L2 một cú nhấp chuột + đào tiền), cuối cùng có thể dẫn đến cảnh tan hoang. Với tình trạng như vậy, muốn giành được miếng bánh từ làn sóng AI truyền thống thực sự rất khó.
Hệ thống hợp tác thuật toán, mô hình
Thuật toán học máy là những thuật toán có khả năng học quy luật và mẫu hình từ dữ liệu, từ đó đưa ra dự đoán hoặc quyết định. Thuật toán mang tính công nghệ cao vì việc thiết kế và tối ưu hóa chúng đòi hỏi kiến thức chuyên môn sâu sắc và đổi mới công nghệ. Thuật toán là cốt lõi để huấn luyện mô hình AI, nó định nghĩa cách dữ liệu được chuyển hóa thành những hiểu biết hoặc quyết định hữu ích. Một số thuật toán AI tạo sinh phổ biến như Mạng đối kháng sinh (GAN), Mã hóa biến phân (VAE), Bộ chuyển đổi (Transformer), mỗi thuật toán được sinh ra cho một lĩnh vực cụ thể (ví dụ vẽ, nhận dạng giọng nói, dịch thuật, tạo video) hoặc một mục đích nhất định, sau đó được dùng để huấn luyện ra các mô hình AI chuyên biệt.
Vậy với vô số thuật toán và mô hình như vậy, mỗi cái đều có ưu điểm riêng, liệu chúng ta có thể tích hợp chúng thành một mô hình toàn diện, đa năng không? Gần đây, Bittensor nổi lên như một người dẫn đầu trong hướng đi này, thông qua cơ chế thưởng đào để khuyến khích các mô hình AI và thuật toán khác nhau hợp tác và học hỏi lẫn nhau, từ đó tạo ra mô hình AI hiệu quả và toàn diện hơn. Cũng theo hướng này còn có Commune AI (hợp tác mã nguồn), tuy nhiên thuật toán và mô hình hiện nay đối với các công ty AI đều là bảo bối gia truyền, sẽ không dễ dàng cho mượn bên ngoài.
Do đó, câu chuyện về hệ sinh thái hợp tác AI nghe rất mới mẻ và thú vị, tận dụng ưu thế blockchain để khắc phục điểm yếu "đảo cô lập thuật toán AI", nhưng liệu có thể tạo ra giá trị tương ứng hay chưa vẫn chưa biết. Bởi vì các thuật toán và mô hình đóng nguồn của các công ty AI hàng đầu có khả năng cập nhật, đổi mới và tích hợp rất mạnh, ví dụ OpenAI phát triển chưa đầy hai năm đã tiến hóa từ mô hình tạo văn bản ban đầu thành mô hình tạo đa lĩnh vực, các dự án như Bittensor có thể cần tìm hướng đi khác biệt trong lĩnh vực thuật toán và mô hình mình nhắm đến.
Dữ liệu lớn phi tập trung
Ở góc độ đơn giản, dùng dữ liệu riêng tư để nuôi AI và gắn nhãn dữ liệu là những hướng rất phù hợp với blockchain, chỉ cần chú ý cách ngăn chặn dữ liệu rác và hành vi xấu, đồng thời việc lưu trữ dữ liệu cũng giúp các dự án Depin như FIL, AR được hưởng lợi. Ở góc độ phức tạp hơn, dùng dữ liệu blockchain cho học máy (ML) để giải quyết vấn đề khả năng truy cập dữ liệu blockchain cũng là một hướng thú vị (một trong những hướng thăm dò của Giza).
Về lý thuyết, dữ liệu blockchain có thể truy cập bất cứ lúc nào, phản ánh toàn bộ trạng thái của blockchain. Nhưng đối với những người nằm ngoài hệ sinh thái blockchain, việc lấy được lượng dữ liệu khổng lồ này không dễ dàng. Lưu trữ đầy đủ một blockchain đòi hỏi chuyên môn sâu và tài nguyên phần cứng chuyên biệt lớn. Để vượt qua thách thức truy cập dữ liệu blockchain, trong ngành đã xuất hiện một số giải pháp. Ví dụ, nhà cung cấp RPC cho phép truy cập nút qua API, dịch vụ lập chỉ mục giúp trích xuất dữ liệu thông qua SQL và GraphQL, hai cách này đóng vai trò then chốt trong việc giải quyết vấn đề. Tuy nhiên, những phương pháp này có hạn chế. Dịch vụ RPC không phù hợp với các kịch bản sử dụng mật độ cao cần truy vấn lượng lớn dữ liệu, thường không đáp ứng được nhu cầu. Đồng thời, mặc dù dịch vụ lập chỉ mục cung cấp cách truy xuất dữ liệu có cấu trúc hơn, nhưng sự phức tạp của các giao thức Web3 khiến việc xây dựng truy vấn hiệu quả cực kỳ khó khăn, đôi khi cần viết hàng trăm thậm chí hàng ngàn dòng mã phức tạp. Sự phức tạp này là rào cản lớn đối với các chuyên gia dữ liệu thông thường và những người không am hiểu sâu về chi tiết Web3. Tổng hợp các hạn chế này làm nổi bật nhu cầu về một phương pháp dễ tiếp cận và khai thác dữ liệu blockchain hơn, có thể thúc đẩy ứng dụng và đổi mới rộng rãi hơn trong lĩnh vực này.
Vì vậy, thông qua ZKML (Machine Learning bằng Chứng minh Không tiết lộ - giảm gánh nặng ML lên chuỗi) kết hợp với dữ liệu blockchain chất lượng cao, có thể tạo ra các bộ dữ liệu giải quyết tính khả dụng của blockchain, và AI có thể giảm đáng kể ngưỡng truy cập dữ liệu blockchain. Theo thời gian, các nhà phát triển, nhà nghiên cứu và những người yêu thích ML sẽ có thể truy cập nhiều bộ dữ liệu chất lượng cao, liên quan hơn để xây dựng các giải pháp hiệu quả và sáng tạo.
AI tăng cường Dapp
Từ năm 2023, kể từ khi ChatGPT3 bùng nổ, AI tăng cường Dapp đã trở thành một hướng đi rất phổ biến. AI tạo sinh có tính ứng dụng cực rộng, có thể tích hợp qua API, từ đó đơn giản hóa và thông minh hóa các nền tảng phân tích dữ liệu, robot giao dịch, bách khoa blockchain... Mặt khác, AI cũng có thể đóng vai trò trợ lý trò chuyện (ví dụ Myshell) hoặc bạn đồng hành AI (Sleepless AI), thậm chí tạo NPC trong game chuỗi bằng AI tạo sinh. Tuy nhiên do rào cản kỹ thuật rất thấp, phần lớn chỉ là tích hợp API rồi tinh chỉnh nhỏ, sự kết hợp với dự án gốc cũng không hoàn hảo, nên hiếm khi được nhắc đến.
Tuy nhiên, sau khi Sora xuất hiện, cá nhân tôi cho rằng hướng AI tăng cường GameFi (bao gồm metaverse) và nền tảng sáng tạo sẽ là trọng tâm cần chú ý tiếp theo. Do đặc tính từ dưới lên của lĩnh vực Web3, chắc chắn rất khó để sản sinh ra các sản phẩm cạnh tranh được với các công ty game hay sáng tạo truyền thống, nhưng sự xuất hiện của Sora rất có thể sẽ phá vỡ tình thế bế tắc này (có thể chỉ trong hai đến ba năm). Nhìn vào demo của Sora, nó đã có tiềm năng cạnh tranh với các công ty làm phim ngắn, văn hóa cộng đồng sôi động của Web3 cũng có thể sản sinh ra vô số ý tưởng thú vị, và khi điều kiện duy nhất là trí tưởng tượng, bức tường ngăn cách giữa ngành từ dưới lên và ngành truyền thống từ trên xuống sẽ bị phá vỡ.
Kết luận
Khi các công cụ AI tạo sinh không ngừng tiến bộ, chúng ta sẽ còn trải qua nhiều "khoảnh khắc iPhone" mang tính bước ngoặt trong tương lai. Mặc dù nhiều người coi thường sự kết hợp giữa AI và Web3, nhưng thực tế tôi cho rằng các hướng đi hiện tại phần lớn không sai, chỉ cần giải quyết ba điểm đau: tính cần thiết, hiệu suất và mức độ phù hợp. Mặc dù sự hòa trộn giữa hai lĩnh vực này vẫn đang trong giai đoạn khám phá, nhưng điều đó không ngăn cản con đường này trở thành chủ lưu của thị trường tăng giá tiếp theo.
Luôn giữ thái độ tò mò và cởi mở đủ lớn đối với những điều mới mẻ là tâm thế chúng ta cần có. Trong lịch sử, sự thay thế xe hơi cho xe ngựa diễn ra trong chớp mắt đã thành định局, cũng giống như Inscriptions và NFT trước đây, ôm quá nhiều thành kiến chỉ khiến ta bỏ lỡ cơ hội.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News











