

비탈릭: 덱스샤딩(Danksharding)이 대체 뭘까?
저자: Vitalik Buterin
Danksharding이란 무엇인가?
Danksharding은 이전 설계에 비해 상당한 단순화를 도입한, 이더리움을 위한 새로운 샤딩 설계이다.
2020년 이후의 최근 모든 이더리움 샤딩 제안들(Danksharding 및 그 이전 버전 포함)은 대부분의 비-이더리움 샤딩 제안들과 주로 한 가지 점에서 차이가 있다. 바로 롤업(Rollup) 중심의 로드맵이라는 점이다. 이더리움 샤딩은 트랜잭션 공간을 더 제공하는 대신, 이더리움 프로토콜 자체가 해석하지 않는 데이터 공간을 제공한다. 검증자는 blob이 사용 가능한지(즉, 네트워크에서 다운로드 가능한지)만 확인하면 된다. 이러한 blob 내 데이터 공간은 고처리량 트랜잭션을 지원하는 2단계(Layer 2) 롤업 프로토콜에 의해 활용될 것으로 예상된다.
Danksharding이 도입한 주요 혁신은 수수료 시장의 통합이다. 이제 더 이상 고정된 수의 샤드를 각기 다른 블록과 블록 제안자가 존재하는 방식이 아니라, 하나의 제안자가 해당 슬롯(slot)에 들어가는 모든 트랜잭션과 모든 데이터를 선택하게 된다.
이러한 설계가 검증자에게 과도한 시스템 요구사항을 만들지 않도록 하기 위해 우리는 제안자/빌더 분리(PBS, Proposer-Builder Separation)를 도입하였다. 블록 구축자라 불리는 특수한 참여자들이 슬롯 권리를 입찰하며 경쟁하고, 제안자는 가장 높은 유효 헤더를 선택하기만 하면 된다. 오직 블록 구축자만 전체 블록을 처리해야 하며(여기서는 탈중앙화된 오라클 프로토콜을 통해 분산된 블록 구축자도 가능하다), 다른 모든 검증자와 사용자들은 데이터 가용성 샘플링(DAS)을 통해 매우 효율적으로 블록을 검증할 수 있다(기억하라: 블록의 "큰" 부분은 순전히 데이터일 뿐이다).
proto-danksharding(또는 EIP-4844)이란 무엇인가?
proto-danksharding(또는 EIP-4844)은 완전한 Danksharding 명세의 대부분의 논리와 "골격"(예: 트랜잭션 형식, 검증 규칙 등)을 구현하는 이더리움 개선 제안(EIP)이지만, 아직 실제적인 샤딩은 구현하지 않는다. proto-danksharding 구현에서는 모든 검증자와 클라이언트가 여전히 전체 blob 데이터의 가용성을 직접 검증해야 한다.
proto-danksharding이 도입한 주요 기능은 새로운 트랜잭션 유형으로, 우리는 이를 "blob을 포함한 트랜잭션"이라 부른다. blob을 포함한 트랜잭션은 일반 트랜잭션과 유사하지만, 추가로 blob이라 불리는 큰 데이터를 포함한다는 점이 다르다. blob은 매우 크며(~125KB), 동일한 양의 calldata보다 훨씬 저렴하다. 그러나 EVM 실행은 blob 데이터에 접근할 수 없고, blob에 대한 커밋만 확인할 수 있다.
검증자와 클라이언트가 여전히 전체 blob 내용을 다운로드해야 하므로, proto-danksharding의 데이터 대역폭 목표는 각 슬롯당 1MB이며, 완전한 16MB는 아니다. 하지만 이러한 데이터는 기존 이더리움 트랜잭션의 가스 사용량과 경쟁하지 않기 때문에 여전히 상당한 확장성 이점이 있다.
모두가 다운로드해야 하는 블록에 1MB 데이터를 추가하는 것이 괜찮은 반면, 왜 calldata를 10배 저렴하게 만들지 않는가?
이는 평균 부하와 최악의 경우 부하 사이의 차이와 관련이 있다. 현재 우리는 평균 블록 크기가 약 90KB인 반면, 이론적으로 가능한 최대 블록 크기(블록 내 모든 30M 가스가 호출 데이터에 사용되는 경우)는 약 1.8MB이다. 이더리움 네트워크는 과거에 최대치에 근접한 블록들을 처리한 적이 있다. 그러나 만약 우리가 간단히 calldata 가스 비용을 10배 낮춘다면, 평균 블록 크기는 여전히 수용 가능한 수준으로 증가하겠지만, 최악의 경우는 18MB가 되어 이더리움 네트워크에는 너무 많아진다.
현재의 가스 가격 책정 방식은 이 두 요소를 분리할 수 없다: 평균 부하와 최악의 경우 부하의 비율은 사용자가 calldata와 다른 자원에 얼마만큼의 가스를 쓰는지에 따라 달라지며, 이는 가스 가격이 최악의 경우 가능성에 따라 설정되어야 함을 의미하며, 결과적으로 시스템이 처리할 수 있는 부하보다 평균 부하가 불필요하게 낮아진다. 그러나 만약 우리가 가스 가격 책정 방식을 더 명시적으로 다차원 수수료 시장을 만들어 평균 사례/최악 사례 부하 불일치를 피한다면, 안전하게 처리할 수 있는 최대 데이터량에 근접하는 데이터를 각 블록에 포함시킬 수 있다. Proto-danksharding과 EIP-4488은 바로 이런 일을 하는 두 가지 제안이다.

proto-danksharding은 EIP-4488과 어떻게 비교되는가?
EIP-4488은 동일한 평균/최악 사례 부하 불일치 문제를 해결하기 위한 초기이자 더 단순한 시도이다. EIP-4488은 두 가지 간단한 규칙으로 이를 수행한다:
Calldata 가스 비용을 바이트당 16 가스에서 바이트당 3 가스로 감소
각 블록당 1MB 제한 + 각 트랜잭션당 추가 300바이트(이론적 최대치: ~1.4MB)
하드 리밋은 평균 부하의 큰 증가가 최악의 경우 부하 증가로 이어지는 것을 막는 가장 간단한 방법이다. 가스 비용 감소는 롤업 사용을 크게 늘려 평균 블록 크기를 수백 KB까지 증가시킬 수 있지만, 하드 리밋은 10MB 단일 블록을 포함하려는 최악의 경우 가능성을 직접 차단한다. 실제로 최악의 경우 블록 크기는 지금보다 작아진다(1.4MB vs 1.8MB).
반대로 proto-danksharding은 더 저렴한 데이터를 저장할 수 있는 별도의 트랜잭션 유형을 만들고, 각 블록에 포함할 수 있는 blob 수를 제한한다. 이러한 blob은 EVM에서 접근할 수 없으며(커밋만 가능), blob은 실행 계층이 아닌 컨센서스 계층(비콘 체인)에 의해 저장된다.
EIP-4488과 proto-danksharding 사이의 주요 실질적 차이점은 EIP-4488이 오늘날 필요한 변경을 최소화하려는 반면, proto-danksharding은 오늘날 많은 변경을 수행하여 장래에 완전한 샤딩으로 업그레이드할 때 거의 변경이 필요없게 만든다는 점이다. 완전한 샤딩(데이터 가용성 샘플링 등 사용)을 구현하는 것은 복잡한 작업이며 proto-danksharding 이후에도 여전히 복잡하지만, 이러한 복잡성은 컨센서스 계층에 포함된다. once proto-danksharding이 출시되면, 실행 계층 클라이언트 팀, 롤업 개발자, 사용자들은 전환을 위해 추가 작업을 할 필요가 없다.
둘 중 하나만 선택해야 하는 것은 아니라는 점에 유의하자. 우리는 가능한 빠르게 EIP-4488을 시행하고, 6개월 후에 proto-danksharding을 추가로 시행할 수 있다.
proto-danksharding은 완전한 danksharding의 어떤 부분을 구현했으며, 아직 구현해야 할 부분은 무엇인가?
EIP-4844 인용:
이 EIP에서 이미 완료된 작업은 다음과 같다:
· "완전한 샤딩"에서 존재해야 할 것과 정확히 동일한 형식의 새로운 트랜잭션 유형
· 완전한 샤딩에 필요한 모든 실행 계층 로직
· 완전한 샤딩에 필요한 모든 실행/컨센서스 교차 검증 로직
· BeaconBlock 검증과 데이터 가용성 샘플링 blob 사이의 계층 분리
· 완전한 샤딩에 필요한 대부분의 BeaconBlock 로직
· blob의 자체 조정 독립 가스 가격
완전한 샤딩을 구현하기 위해 아직 완료되어야 할 작업은 다음과 같다:
· 2D 샘플링을 허용하기 위한 컨센서스 계층 내 blob_kzgs의 저차원 확장
· 데이터 가용성 샘플링의 실제 구현
· 단일 검증자가 한 슬롯 내에 32MB 데이터를 처리해야 하는 것을 방지하기 위한 PBS(제안자/구축자 분리)
· 각 검증자의 위탁 증명 또는 유사한 프로토콜 내 요구사항으로, 각 블록에서 샤딩된 데이터의 특정 부분을 검증하도록 한다.
남은 모든 작업은 컨센서스 계층 변경이며, 실행 클라이언트 팀, 사용자, 롤업 개발자의 추가 작업이 필요하지 않다는 점에 유의하자.
이렇게 큰 블록들이 디스크 공간 요구량을 증가시키는 문제는 어떻게 해결할 것인가?
EIP-4488과 proto-danksharding 모두 각 슬롯(12초)마다 장기적으로 약 1MB의 최대 사용량을 초래한다. 이는 연간 약 2.5TB에 해당하며, 현재 이더리움이 요구하는 성장률보다 훨씬 높다.
EIP-4488의 경우, 이 문제를 해결하기 위해 일정 기간 후 더 이상 클라이언트가 역사적 기록을 저장할 필요가 없는 만료 방안(EIP-4444)이 필요하다(1개월에서 1년 사이의 지속 시간이 제안됨).
proto-danksharding의 경우, EIP-4444 시행 여부와 관계없이 컨센서스 계층이 일정 기간(예: 30일) 후 자동으로 blob 데이터를 삭제하는 별도의 로직을 구현할 수 있다. 그러나 어떤 단기 데이터 확장 솔루션을 채택하더라도 EIP-4444를 조기에 시행하는 것이 강력히 권장된다.
이러한 전략들 모두 컨센서스 클라이언트의 추가 디스크 부하를 수백GB 이하로 제한한다. 장기적으로는 일부 역사적 만료 메커니즘이 본질적으로 필수적이다: 완전한 샤딩은 매년 약 40TB의 역사적 blob 데이터를 추가하므로, 사용자는 그 중 일부만 일정 기간 동안 저장할 수 있을 뿐이다. 따라서 이를 조기에 예상하도록 설정하는 것이 중요하다.
30일 후 데이터가 삭제되면, 사용자는 오래된 blob에 어떻게 접근할 수 있는가?
이더리움 컨센서스 프로토콜의 목적은 모든 역사적 데이터의 영구 저장을 보장하는 것이 아니다. 오히려, 그것은 높은 보안성을 갖춘 실시간 게시판을 제공하고, 다른 탈중앙화 프로토콜이 장기 저장을 위해 공간을 마련하는 것이다. 게시판의 존재는 게시된 데이터가 충분히 오랫동안 사용 가능하여, 해당 데이터를 원하는 사용자나 백업 데이터를 장기 저장하는 프로토콜이 충분한 시간 내에 데이터를 가져와 자신의 다른 애플리케이션이나 프로토콜로 가져올 수 있도록 보장하기 위한 것이다.
일반적으로 장기 역사 저장은 쉽다. 연간 2.5TB는 정규 노드에게는 너무 크지만, 전용 사용자에게는 매우 관리 가능하다: TB당 약 20달러에 매우 큰 하드디스크를 구입할 수 있으며, 이는 아마추어 수준에서도 충분하다. N/2-of-N 신뢰 모델을 갖는 컨센서스와 달리, 역사 저장은 1-of-N 신뢰 모델을 갖는다: 당신은 데이터 저장자 중 하나만 정직하면 된다. 따라서 각 역사 데이터는 수천 개의 실시간 컨센서스 검증을 수행하는 노드가 아니라 수백 번만 저장하면 된다.
전체 역사 기록을 저장하고 쉽게 접근 가능하게 만드는 실용적인 방법들은 다음과 같다:
특정 애플리케이션 프로토콜(예: 롤업)은 자신의 노드가 관련된 역사 부분을 저장하도록 요구할 수 있다. 잃어버린 역사 데이터는 프로토콜에 위험이 없고, 단지 개별 애플리케이션에만 위험을 준다. 따라서 애플리케이션이 자신과 관련된 데이터 저장 부담을 지는 것이 합리적이다.
BitTorrent에 역사 데이터를 저장, 예를 들어 매일 블록에서 blob 데이터를 포함하는 7GB 파일을 자동 생성하고 배포.
이더리움 포털 네트워크(현재 개발 중)는 역사 저장을 쉽게 확장할 수 있다.
블록 브라우저, API 제공업체 및 기타 데이터 서비스는 전체 역사를 저장할 수 있다.
개인 취미 활동가 및 데이터 분석을 수행하는 학자들이 전체 역사를 저장할 수 있다. 후자의 경우, 역사를 로컬에 저장하는 것이 직접 계산을 쉽게 만들어 중요한 가치를 제공한다.
TheGraph 등의 제3자 인덱싱 프로토콜이 전체 역사를 저장할 수 있다.
더 높은 수준의 역사 저장(예: 연간 500TB)에서는 일부 데이터가 잊혀질 위험이 높아진다(또한 데이터 가용성 검증 시스템도 더욱 긴장된다). 이는 샤딩 블록체인 확장성의 진정한 한계일 수 있다. 그러나 현재 제안된 모든 파라미터는 이 지점에서 매우 멀리 떨어져 있다.
blob 데이터의 형식은 무엇이며, 어떻게 커밋되는가?
blob은 다음 범위 내 숫자를 포함하는 4096개의 필드 요소로 구성된 벡터이다:
수학적으로 blob은 위 모듈러스를 갖는 유한체 위의 다항식으로 표현된다.
blob에 대한 커밋은 해당 다항식에 대한 KZG 커밋의 해시이다. 그러나 구현 관점에서는 다항식의 수학적 세부사항에 집중할 필요는 없다. 대신, (라그랑주 기반의 신뢰할 수 있는 설정을 기반으로 한) 타원 곡선 점의 벡터만 있고, blob에 대한 KZG 커밋은 단지 선형 조합일 뿐이다. EIP-4844 코드 인용:
BLS_MODULUS는 위 모듈러스이며, KZG_SETUP_LAGRANGE는 라그랑주 기반의 신뢰할 수 있는 설정을 갖는 타원 곡선 점의 벡터이다. 구현자로서 지금은 이를 단순한 블랙박스 전용 해시 함수로 간주하는 것이 합리적이다.
왜 KZG의 해시를 사용하고 직접 KZG를 사용하지 않는가?
EIP-4844는 blob에 대한 KZG를 직접 사용하는 대신 버전화된 해시를 사용한다: 하나의 0x01 바이트(이 버전임을 나타냄) 뒤에 KZG의 SHA256 해시의 마지막 31바이트를 붙인다.
이는 EVM 호환성과 미래 호환성을 위해서이다: KZG 커밋은 48바이트이지만, EVM은 32바이트 값을 더 자연스럽게 사용하며, 만약 KZG에서 다른 것으로 전환한다면(예: 양자 저항성 이유로) KZG 커밋은 계속해서 32바이트로 유지될 수 있다.
proto-danksharding에서 도입된 두 가지 사전 컴파일은 무엇인가?
Proto-danksharding은 두 가지 사전 컴파일을 도입한다: blob 검증 사전 컴파일과 점 평가 사전 컴파일.
Blob 검증 사전 컴파일은 말 그대로 설명된다: 입력으로 버전화된 해시와 Blob을 받아, 제공된 버전화된 해시가 Blob에 대한 유효한 버전화된 해시인지 검증한다. 이 사전 컴파일은 Optimistic Rollup이 사용하도록 의도되었다. EIP-4844 인용:
Optimistic Rollup은 사기 증명을 제출할 때만 실제 기반 데이터를 제공하면 된다. 사기 증명 제출 기능은 사기 blob의 전체 내용을 calldata의 일부로 제출하도록 요구할 것이다. 그런 다음 blob 검증 기능을 사용하여 이전에 제출된 버전화된 해시에 대해 데이터를 검증하고, 오늘날처럼 해당 데이터에 대해 사기 증명 검증을 수행할 것이다.
점 평가 사전 컴파일은 버전화된 해시, x 좌표, y 좌표, 증명(KZG 커밋과 KZG 평가 증명)을 입력으로 받는다. 증명을 검증하여 P(x) = y인지 확인하며, 여기서 P는 주어진 버전화된 해시를 갖는 blob에 의해 표현되는 다항식이다. 이 사전 컴파일은 ZK Rollup을 위해 의도되었다. EIP-4844 인용:
ZK 롤업은 거래 또는 상태 증분 데이터에 대해 두 가지 커밋을 제공할 것이다: blob 내 KZG와 ZK 롤업 내부에서 사용하는 임의의 증명 시스템의 커밋. 그들은 등가 프로토콜의 커밋 증명을 사용하여, 점 평가 사전 컴파일을 통해 KZG(데이터 가용성을 보장함)와 ZK 롤업 자체의 커밋이 동일한 데이터를 참조함을 증명할 것이다.
대부분의 주요 Optimistic Rollup 설계는 마지막 라운드에서 소량의 데이터만 필요한 다단계 방지 사기 체계를 사용한다는 점에 유의하자. 따라서 Optimistic Rollup이 blob 검증 사전 컴파일 대신 점 평가 사전 컴파일을 사용할 수도 있으며, 그렇게 하는 것이 더 저렴할 수 있다.
KZG 신뢰할 수 있는 설정은 어떤 형태인가?
보기:
https://vitalik.ca/general/2022/03/14/trustedsetup.html
powers-of-tau 신뢰할 수 있는 설정 작동 방식에 대한 일반 설명
https://github.com/ethereum/research/blob/master/trusted_setup/trusted_setup.py
모든 중요한 신뢰 설정 관련 계산의 예시 구현
특히 우리의 경우, 현재 계획은 네 가지 크기(n1=4096,n2=16), (n1=8192,n2=16), (n1=16834,n2=16), (n1=32768,n2=16)의 의식을 병렬로 실행하는 것이다(다른 비밀을 가짐). 이론적으로 첫 번째만 있으면 되지만, 더 큰 크기의 설정을 실행함으로써 blob 크기를 증가시켜 미래 적용성을 향상시킨다. 우리는 단순히 더 큰 설정을 가질 수 없는데, 이는 효과적으로 커밋할 수 있는 다항식의 차수에 하드 리밋을 두어야 하며, 이 리밋은 blob 크기와 같아야 하기 때문이다.
실용적인 접근법으로는 Filecoin 설정에서 시작하여 이를 확장하는 의식을 실행하는 것을 고려할 수 있다. 브라우저 구현을 포함한 다양한 구현을 통해 많은 사람들이 참여할 수 있다.
신뢰할 수 없는 설정 없이 다른 커밋 방식을 사용할 수는 없는가?
불행히도 KZG 외의 다른 것(예: IPA 또는 SHA256)을 사용하면 샤딩 로드맵이 더 어려워진다. 몇 가지 이유가 있다:
산술적이지 않은 커밋(예: 해시 함수)은 데이터 가용성 샘플링과 호환되지 않으므로, 이러한 방식을 사용한다면 결국 완전한 샤딩으로 전환할 때 KZG로 변경해야 한다.
IPA는 데이터 가용성 샘플링과 호환될 수 있지만, 더 복잡한 방식을 만들고 더 약한 속성을 갖는다(예: 자기 치유 및 분산 블록 구축이 더 어려워진다).
해시와 IPA 모두 점 평가 사전 컴파일의 저렴한 구현과 호환되지 않는다. 따라서 해시 또는 IPA 기반 구현은 ZK 롤업을 효율적으로 지원하거나 다단계 Optimistic Rollup에서 저렴한 사기 증명을 지원할 수 없다.
따라서 불행히도 KZG 외의 다른 것을 사용함으로써 발생하는 기능 손실과 복잡성 증가는 KZG 자체의 위험보다 훨씬 크다. 또한 KZG 관련 위험은 제한적이다: KZG 실패는 롤업 및 blob 데이터에 의존하는 다른 애플리케이션에만 영향을 미치며, 시스템의 나머지 부분에는 영향을 주지 않는다.
KZG는 얼마나 "복잡하고", "새로운가"?
KZG 커밋은 2010년 논문에서 소개되었으며, 2019년 이후 PLONK 유형의 ZK-SNARK 프로토콜에서 널리 사용되어 왔다. 그러나 KZG 커밋의 기반 수학은 타원 곡선 연산과 페어링의 기반 수학 위에 상대적으로 간단한 산술이다.
사용되는 특정 곡선은 BLS12-381이며, Barreto-Lynn-Scott가 2002년에 고안했다. KZG 커밋 검증에 필요한 타원 곡선 페어링은 매우 복잡한 수학이지만, 1940년대에 발명되었으며 1990년대 이후 암호학에 응용되었다. 2001년에는 페어링을 사용하는 많은 암호 알고리즘이 제안되었다.
구현 복잡성 관점에서 보면, KZG는 IPA보다 더 어렵지 않다: 커밋을 계산하는 함수(위 참조)는 IPA와 정확히 동일하며, 다른 타원 곡선 점 상수를 사용할 뿐이다. 점 검증 사전 컴파일은 페어링 평가를 포함하므로 더 복잡하지만, 수학은 EIP-2537(BLS12-381 사전 컴파일) 구현에서 이미 완료된 부분과 동일하며 bn128 페어링 사전 컴파일과 매우 유사하다(또한 참고: 최적화된 Python 구현). 따라서 KZG 검증 구현은 복잡한 "신규 작업"을 필요로 하지 않는다.
proto-danksharding 구현의 다른 소프트웨어 구성 요소는 무엇인가?
네 가지 주요 구성 요소가 있다:
1. 실행 계층 컨센서스 변경(자세한 내용은 EIP 참조):
blob을 포함하는 새로운 트랜잭션 유형
현재 트랜잭션의 i번째 blob 버전화된 해시를 출력하는 오퍼코드
Blob 검증 사전 컴파일
점 평가 사전 컴파일
2. 컨센서스 계층 컨센서스 변경(저장소의 이 폴더 참조):
BeaconBlockBody 내 blob KZG 목록
BeaconBlock과 별도 객체로 완전한 blob 내용을 전달하는 "사이드카" 메커니즘
실행 계층의 blob 버전화된 해시와 컨센서스 계층의 blob KZG 사이의 교차 검사
3. 메모리 풀
BlobTransactionNetworkWrapper(EIP의 네트워크 섹션 참조)
큰 blob 크기를 보상하기 위한 더 강력한 반 DoS 보호
4. 블록 구축 로직
메모리 풀로부터 트랜잭션 래퍼를 받아 ExecutionPayload에 트랜잭션을 넣고, KZG를 비콘 블록 본문과 사이드카에 넣음
이차원 수수료 시장 대응
주의: 최소 구현의 경우 메모리 풀이 전혀 필요 없으며(2단계 트랜잭션 번들 시장을 의존할 수 있음), 블록 구축 로직을 구현하기 위해 하나의 클라이언트만 있으면 된다. 실행 계층과 컨센서스 계층의 컨센서스 변경만 광범위한 컨센서스 테스트가 필요하며, 비교적 경량이다. 이러한 최소 구현과 모든 클라이언트가 블록 생산과 메모리 풀을 지원하는 "완전한" 배포 사이의 어느 것이든 가능하다.
proto-danksharding의 다차원 수수료 시장은 어떻게 생겼는가?
Proto-danksharding은 가스와 blob이라는 두 가지 자원에 대해 별도의 변동 가스 가격과 별도의 제한을 갖는 다차원 EIP-1559 수수료 시장을 도입한다.
즉, 두 개의 변수와 네 개의 상수가 있다:

blob 수수료는 가스로 징수되지만, 가변적인 가스 양이며, 장기적으로 각 블록의 평균 blob 수가 실제로 목표 수치와 같아지도록 조정된다.
이 2차원 특성은 블록 구축자에게 더 어려운 문제를 만든다: 트랜잭션을 소진하거나 블록 가스 제한에 도달할 때까지 단순히 가장 높은 우선순위 수수료를 가진 트랜잭션을 수용하는 것이 아니라, 두 가지 서로 다른 제한을 동시에 피해야 한다.
예를 들어 보자. 가스 제한이 70이고 blob 제한이 40라고 하자. 메모리 풀에 블록을 채울 수 있는 많은 트랜잭션이 있으며, 두 가지 유형이 있다(tx 가스는 per-blob 가스 포함):
우선순위 수수료 5 per gas, 4 blobs, 총 4 gas
우선순위 수수료 3 per gas, 1 blob, 총 2 gas
순진한 "우선순위 수수료 감소" 알고리즘을 따르는 마이너는 첫 번째 유형의 10건의 트랜잭션(40 gas)으로 전체 블록을 채우고 5 * 40 = 200 gas의 수익을 얻을 것이다. 이 10건의 트랜잭션이 blob 제한을 완전히 채우기 때문에 더 이상 트랜잭션을 포함할 수 없다. 그러나 최적 전략은 첫 번째 유형의 3건과 두 번째 유형의 28건을 취하는 것이다. 이렇게 하면 40개의 blob과 68가스의 블록, 그리고 5 * 12 + 3 * 56 = 228의 수익을 얻게 된다.

실행 클라이언트가 이제 블록 생산을 최적화하기 위해 복잡한 다차원 배낭 문제 알고리즘을 구현해야 하는가? 그렇지 않다, 몇 가지 이유로:
EIP-1559는 대부분의 블록이 어느 제한에도 도달하지 않도록 보장하므로, 실제로는 소수의 블록만 다차원 최적화 문제에 직면한다. 메모리 풀에 어느 제한에도 도달할 만큼 충분히 지불한 트랜잭션이 없는 일반적인 경우, 마이너는 보이는 모든 트랜잭션을 포함함으로써 최적의 수익을 얻을 수 있다.
실제로는 상당히 간단한 휴리스틱이 거의 최적에 근접할 수 있다. 유사한 경우에 대해서는 Ansgar의 EIP-4488 분석을 참조하여 관련 데이터를 확인할 수 있다.
다차원 가격 책정은 전문화로 인한 수익 증가의 가장 큰 원천이 아니다—MEV가 그렇다. 체인상 DEX 아비트리지, 청산, NFT 판매 선점 등을 통해 추출되는 전용 MEV 수익은 "추출 가능한 수익"(즉, 우선순위 수수료) 총액의 상당 부분을 차지한다: 전용 MEV 수익은 평균적으로 블록당 약 0.025 ETH이며, 총 우선순위 수수료는 보통 블록당 0.1 ETH 정도이다.
제안자/건설자 분리(PBS)는 고도로 전문화된 블록 생산을 중심으로 설계되었다. PBS는 블록 구축 과정을 전문 참여자가 블록 생성 특권을 입찰하는 경매로 전환한다. 일반 검증자는 가장 높은 입찰만 수락하면 된다. 이것은 MEV가 검증자 중심화로 이어지는 규모의 경제를 방지하기 위한 것이며, 블록 구축 최적화를 더 어렵게 만들 수 있는 모든 문제를 처리한다.
이러한 이유들로 인해 더 복잡한 수수료 시장 역학은 중심화나 위험을 크게 증가시키지 않는다. 오히려 더 광범위한 원칙을 적용하면 DoS 공격 위험을 실제로 줄일 수 있다!
지수형 EIP-1559 blob 수수료 조정 메커니즘은 어떻게 작동하는가?
오늘날의 EIP-1559는 특정 목표 가스 사용량 t에 도달하기 위해 기본 수수료 b를 다음과 같이 조정한다:

여기서 b(n)은 현재 블록의 기본 수수료, b(n+1)은 다음 블록의 기본 수수료, t는 목표치, u는 사용된 가스이다.
이 메커니즘의 큰 문제는 실제로 t를 목표로 하지 않는다는 점이다. 첫 번째 블록에서 u=0, 다음 블록에서 u=2t라고 가정하자. 그러면 다음과 같은 결과가 나온다:

평균 사용량이 t와 같음에도 불구하고, 기본 수수료는 63/64로 감소한다. 따라서 기본 수수료는 사용률이 t보다 약간 높을 때만 안정된다; 실제로는 약 3% 더 높은 것으로 나타났으며, 정확한 수치는 분산에 따라 달라진다.
더 나은 공식은 지수 조정이다:
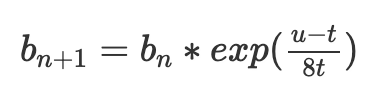
exp(x)는 e^x인 지수 함수이며, e≈2.71828이다. 작은 x 값에서는 exp(x)≈1+x이다. 그러나 트랜잭션 순서와 무관한 편리한 특성이 있다: 다단계 조정
는 총합 u1+...+u/n에만 의존하며, 분포에는 의존하지 않는다. 그 이유를 이해하기 위해 수학적 계산을 수행할 수 있다:
같은 트랜잭션을 포함하면 블록 간 분배 방식에 관계없이 동일한 최종 기본 수수료가 된다.
위의 마지막 공식은 자연스러운 수학적 해석도 있다: 용어 (u1+u2+...+u/n - nt)는 초과분으로 볼 수 있다: 실제로 사용된 총 가스와 계획된 총 가스 사이의 차이.
현재 기본 수수료가
라는 사실은 초과분이 매우 좁은 범위를 벗어날 수 없다는 것을 명확히 보여준다: 만약 8t*60을 초과하면 기본 수수료는 e^60이 되어 너무 높아 아무도 지불할 수 없고, 만약 0 미만이면 자원은 사실상 무료가 되어 체인이 스팸에 노출되어 초과분이 다시 0 이상이 될 때까지 지속된다.
조정 메커니즘은 정확히 이러한 용어로 작동한다: 실제 총합(u1+u2+...+u/n)을 추적하고 목표 총합(nt)을 계산하며, 가격을 그 차이의 지수로 계산한다. 계산을 더 간단하게 하기 위해 e^x 대신 2^x를 사용한다. 실제로는 2^x의 근사치인 EIP의 fake_exponential 함수를 사용한다. 가짜 지수는 거의 항상 실제 값의 0.3% 이내이다.
장기간의 미사용이 장기간의 2배 블록을 유발하는 것을 방지하기 위해, 우리는 추가적인 기능을 추가한다: 초과분이 0 아래로 내려가지 않도록 한다. actual_total이 targeted_total보다 낮으면, actual_total을 그냥 targeted_total과 같게 설정한다. 극단적인 경우(blob 가스가 0까지 떨어지는 경우) 이는 실제로 트랜잭션 순서 불변성을 깨뜨리지만, 보안성 증가로 인해 수용 가능한 타협이다. 또한 proto-danksharding을 처음 도입할 때 초기에는 사용자가 적어 한동안 blob 비용이 거의 확실히 매우 저렴해질 것이며, "일반적인" 이더리움 블록체인 활동은 여전히 비쌀 수 있다는 흥미로운 결과도 있다.
저자는 이러한 수수료 조정 메커니즘이 현재 방법보다 더 낫다고 생각하며, 궁극적으로 EIP-1559 수수료 시장의 모든 부분이 이것을 사용하도록 전환되어야 한다고 본다.
더 길고 자세한 설명은 Dankrad의 포스트를 참조하라.
fake_exponential은 어떻게 작동하는가?
편의상, fake_exponential 코드는 다음과 같다:
다음은 반올림을 제거하고 수학적으로 재표현한 핵심 메커니즘이다:
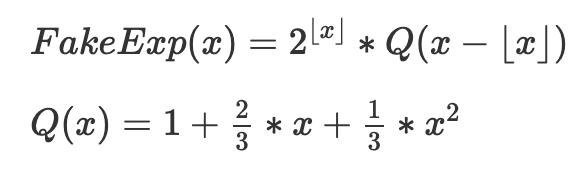
목표는 [2^k,2^(k+1)] 범위마다 적절하게 이동 및 확대된 QX의 여러 인스턴스를 연결하는 것이다. Q(x) 자체는 0≤x≤1에서 2^x의 근사치이며, 다음 속성을 위해 선택되었다:
단순성(이차 방정식)
왼쪽 끝에서 정확성(Q(0)=2^0=1)
오른쪽 끝에서 정확성(Q(1)=2^1=2)
부드러운 기울기(우리가 Q'(1)=2*Q'(0)이 되도록 보장하여 Q의 각 이동+확대 사본이 오른쪽 끝에서의 기울기가 다음 사본의 왼쪽 끝에서의 기울기와 동일하게 만든다)
마지막 세 가지 요구사항은 위에 주어진 Q(x)가 유일한 해가 되는 세 개의 미지수 계수에 대한 세 개의 선형 방정식을 제공한다.
근사는 놀랄 만큼 정확하며, 가장 작은 입력을 제외한 모든 입력에 대해 fake_exponential은 2^x 실제값의 0.3% 이내의 답을 제공한다:

proto-danksharding에서 여전히 논의 중인 문제는 무엇인가?
참고: 이 섹션은 쉽게 오래될 수 있다. 어떤 특정 문제에 대해 최신의 생각을 제공한다고 믿지 마라.
모든 주요 Optimistic Rollup은 다단계 증명을 사용하므로, 훨씬 저렴한 점 평가 사전 컴파일을 사용할 수 있다. blob 검증이 정말 필요한 사람은 직접 구현할 수 있다: blob D와 버전화된 해시 h를 입력으로 받아, x=hash(D,h)를 선택하고 중심 평가를 사용하여 y=D(x)를 계산한 후, 점 평가 사전 컴파일을 사용하여 h(x)=y인지 검증한다. 따라서 blob 검증 사전 컴파일이 정말 필요한가, 아니면 그냥 제거하고 점 평가만 사용해도 되는가?
이 체인이 지속적인 장기 1MB 이상 블록을 처리하는 능력은 어떠한가? 위험이 너무 크다면, 처음부터 목표 blob 수를 줄여야 하는가?
blob은 가스로 가격 책정해야 하는가, 아니면 ETH(소각됨)로 해야 하는가? 수수료 시장에 다른 조정이 필요한가?
새로운 트랜잭션 유형을 blob으로 간주해야 하는가, 아니면 SSZ 객체로 간주해야 하는가(후자의 경우 ExecutionPayload을 유니온 타입으로 변경)?(이는 '지금 더 많은 작업'과 '나중에 더 많은 작업'의 균형이다)
신뢰할 수 있는 설정 구현의 정확한 세부사항(EIP 자체의 범위를 기술적으로 벗어나지만, 구현자에게는 '단지 상수'일 뿐이지만, 여전히 완료되어야 한다).
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














