

AI大規模言語モデルにおける「中国語ペナルティ」:中国語は英語よりもトークンを多く消費するが、その理由は?
TechFlow厳選深潮セレクト
AI大規模言語モデルにおける「中国語ペナルティ」:中国語は英語よりもトークンを多く消費するが、その理由は?
エンジニアたちが効率性を追求して言語の角を削り取ると、その隙間に無意識に育った知恵もまた、静かに消え去ってしまう。
Opus 4.7 がリリースされた直後の数日間、X(旧Twitter)上では不満の声が相次ぎました。あるユーザーは、1回の会話ですべてのセッションクォータを消費してしまったと報告し、別のユーザーは、同一コードを実行するコストが先週と比べて2倍以上に跳ね上がったと述べています。さらに、あるユーザーは、200米ドルのMaxサブスクリプションを購入してから2時間も経たないうちに利用上限に達したスクリーンショットを公開しました。
独立開発者BridgeMind氏は、「Claudeは世界で最も優れたモデルだが、同時に最も高価なモデルでもある」と認めています。彼のMaxサブスクリプションも2時間足らずで利用上限に達しましたが、幸運にも——彼は2つのサブスクリプションを購入していました。|出典:X@bridgemindai
Anthropic社の公式価格は変更されておらず、100万トークンの入力あたり5米ドル、出力は25米ドルのままです。しかし、このバージョンでは新しいトーカナイザ(分詞器)が導入され、さらにClaude Codeのデフォルト「effort」設定が「high」から「xhigh」へ引き上げられました。この2つの変更が重なり、同一タスクで消費されるトークン数は従来の2~2.7倍に増加しました。
こうした議論の中で、中国語に関連する2つの主張が目立ちました。1つ目は、「新トーカナイザ下では中国語のトークン増加はほとんど見られず、中国語ユーザーは今回の値上げを回避できた」というもの。もう1つは、より興味深い主張で、「文言文は現代中国語よりもトークン消費が少なく、AIとの会話に文言文を使うことでコストを節約できる」というものです。
1つ目の主張は、Claudeが中国語に対して何らかの最適化を行ったことを示唆していますが、Anthropic社のリリースドキュメントには、中国語に関する調整について一切言及されていません。
2つ目の主張は、さらに説明が難しいものです。文言文は人間読者にとって明らかに現代中国語よりも理解が難しく、人間にとってより複雑なテキストが、なぜAIにとってはより容易なのでしょうか?
そこで私はテストを実施しました。商業ニュース、技術文書、文言文、日常会話など、22種類の平行テキストを用意し、Claude 4.6および4.7、GPT-4o、Qwen 3.6、DeepSeek-V3の5種類のトーカナイザにそれぞれ送信し、各テキストが各モデルで生成するトークン数を計測・横断比較しました。

テストテキスト:
1.日常会話(旅行、掲示板での相談、ライティング依頼など)の英中対訳
2.技術文書(Python公式ドキュメント、Anthropic公式ドキュメントなど)の英中対訳
3.ニュース(NYTの政治ニュース、商業ニュース、Apple社の公式声明など)の英中対訳
4.文学作品(『出師表』『道德經』など)の英中対訳および文言文
テストの結果、両方の主張はある程度裏付けられましたが、実際の状況は噂よりも複雑でした。
中国語税(チャイニーズ・タックス)
まず結論から述べます。
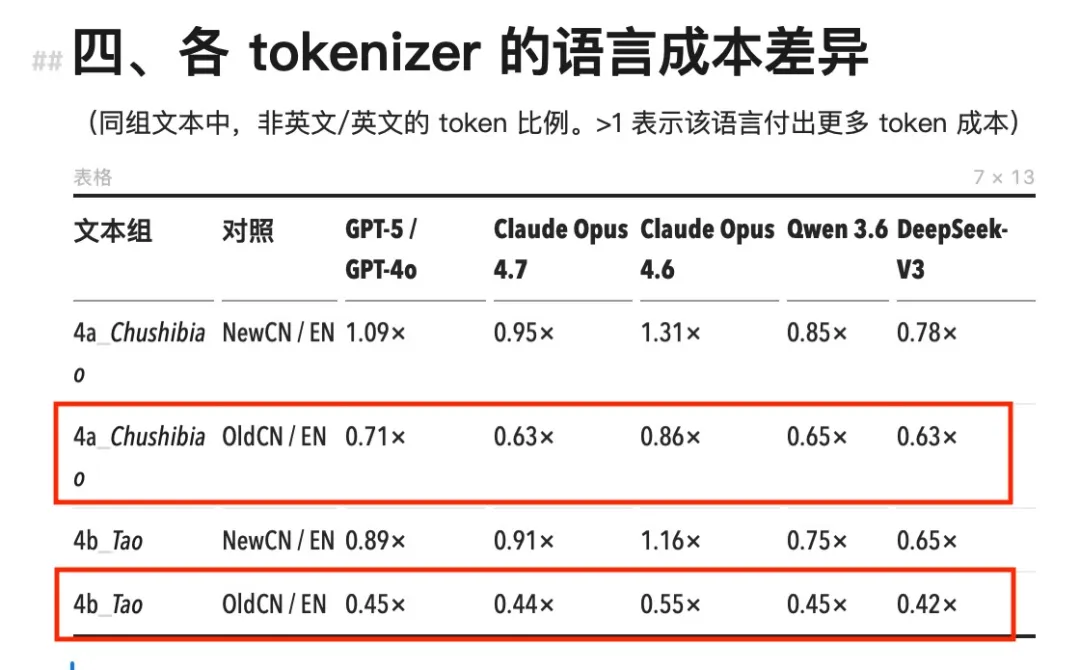
1.ClaudeおよびGPTでは、中国語は常に英語よりも高コストである
2.QwenおよびDeepSeekでは、中国語はむしろ英語よりも低コストである
3.Opus 4.7で話題となったこのトーカナイザアップグレードによるインフレは、ほぼ英語のみに生じており、中国語はほとんど影響を受けていない
具体的な数字を見てみましょう。Claude Opus 4.7以前の全モデル(Opus 4.6、Sonnet、Haikuを含む)は、同一のトーカナイザを使用していました。このトーカナイザでは、中国語のトークン消費量は、同等の英語コンテンツと比較して一貫して高くなっており、cn/en比(中国語/英語)は1.11×~1.64×の範囲でした。
最も極端なケースは、NYTスタイルの商業ニュースで現れました。同一内容の中国語版は、英語版と比較してトークンを64%多く消費し、つまり64%多く支払う必要がありました。
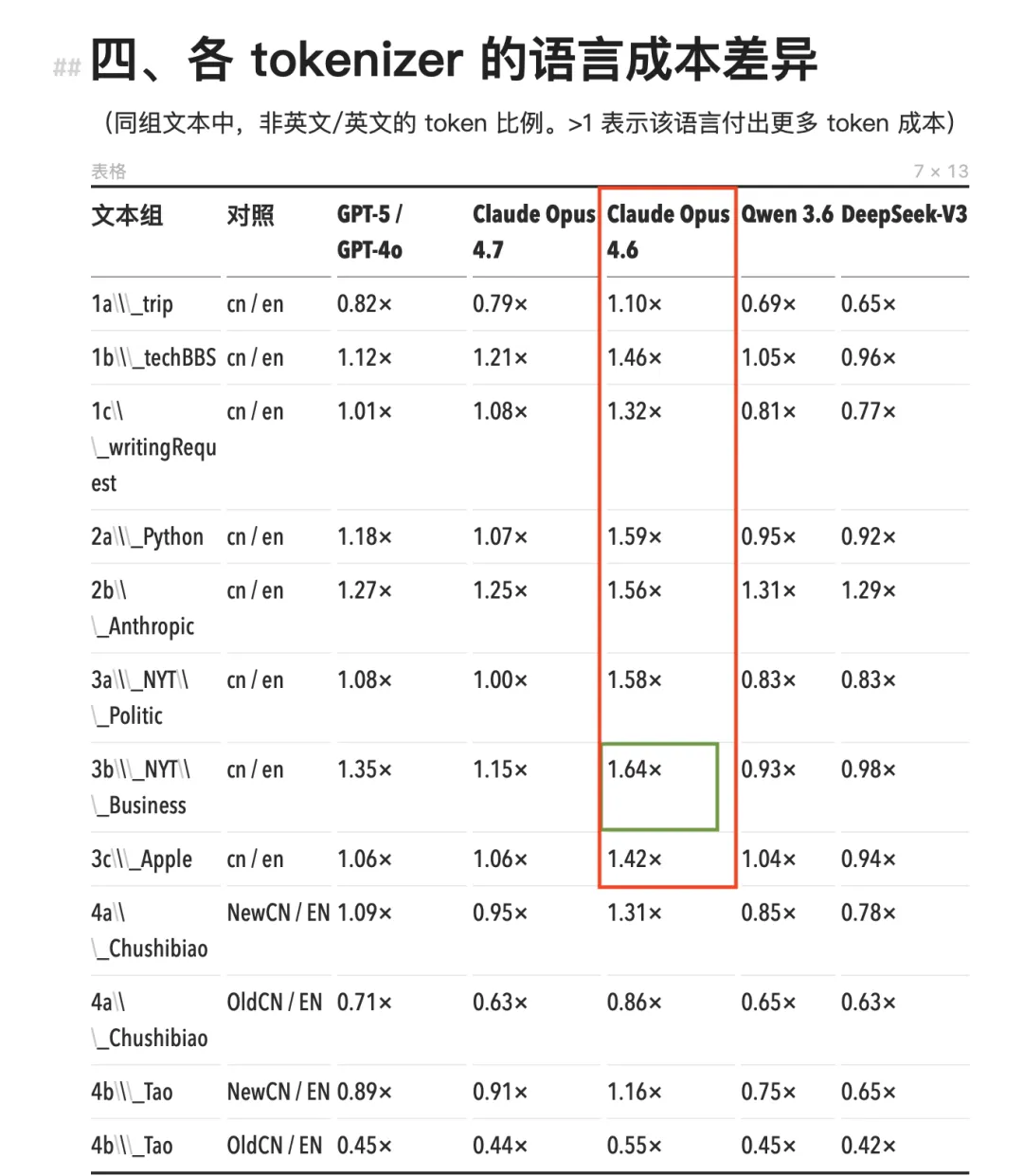
Opus 4.6およびそれ以前のClaudeモデルでは、中国語のトークン消費量が他モデルと比較して著しく高い(赤枠)
最も極端なケースはNYTスタイルの商業ニュースで、同一内容の中国語版はトークンを64%多く消費(緑枠)
GPT-4oのo200kトーカナイザはやや改善されており、cn/en比は多くの場合1.0~1.35×の範囲に収まり、一部のシナリオでは1を下回っています。中国語は依然として全体的に高コストですが、Claudeと比べるとその差は大幅に縮小しています。
国産モデルQwen 3.6およびDeepSeek-V3のデータは、全く逆の傾向を示しています。両モデルのcn/en比は広範囲にわたり1を下回っており、これは同じ内容でも中国語版の方が英語版よりもトークンを節約できることを意味します。DeepSeekでは最低で0.65×まで達しており、同一テキストの中国語版は英語版と比べてトークンコストが約3分の1も安くなります。
Opus 4.7の新トーカナイザによるインフレは、ほぼ英語に限定されています。英語のトークン数は1.24×~1.63×に膨張しましたが、中国語はほとんどすべて1.000×のまま、ほとんど変化がありません。冒頭で紹介した英語圏の開発者たちの請求額の急騰は、中国語ユーザーには実感できませんでした。その理由として、中国語は旧トーカナイザにおいてすでに単字単位で分割されていたため、これ以上細分化する余地が極めて小さかったことが考えられます。
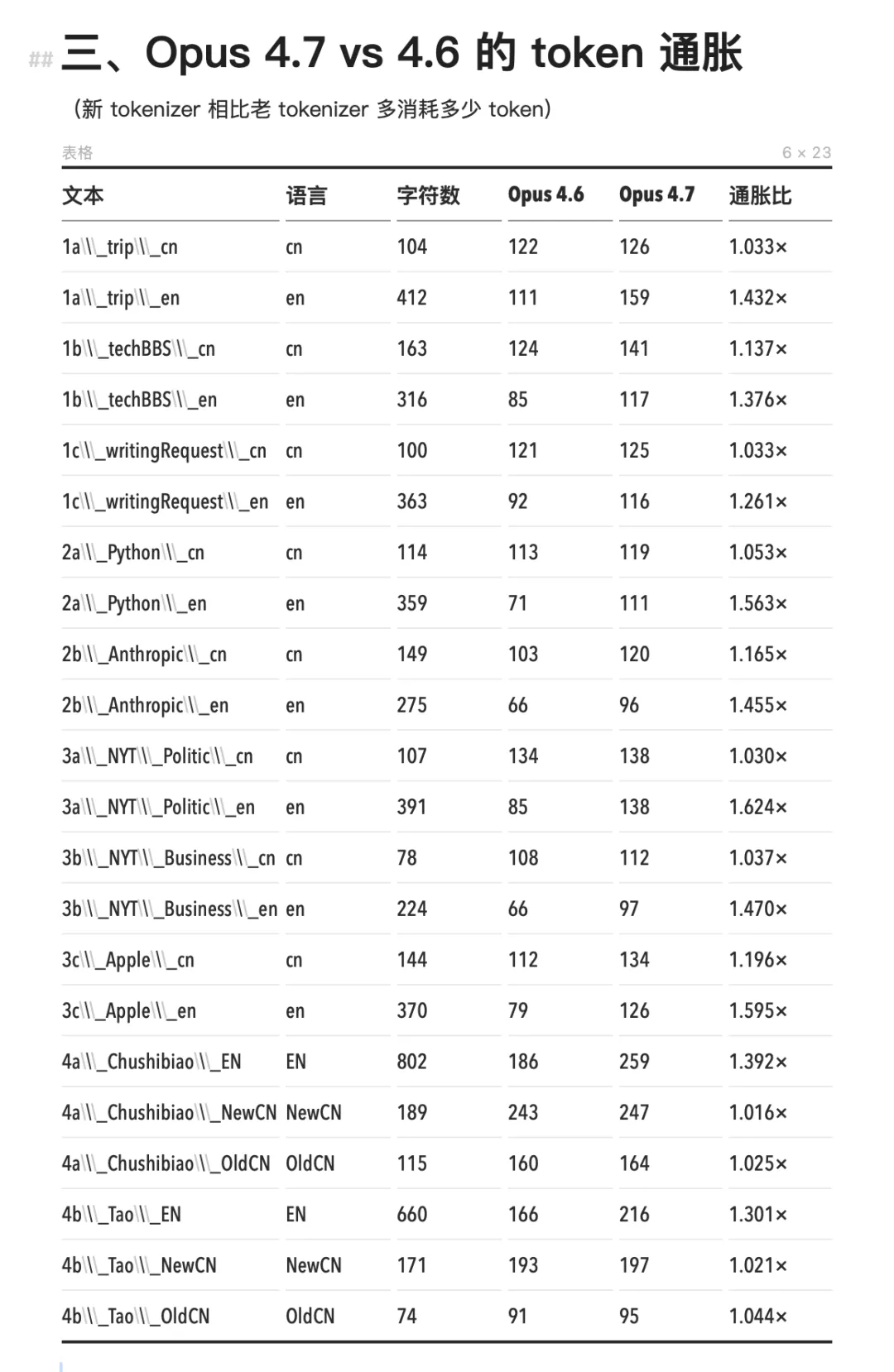
Opus 4.7と4.6を比較すると、英語のトークン消費量は増加しているが、中国語は変化していない
テスト中に私が注目したもう1つの点は、トークン消費量の差異が単なる請求額の問題ではなく、作業領域のサイズに直接影響することです。同様に200kのコンテキストウィンドウを用いる場合、旧版Claudeトーカナイザで中国語資料を処理すると、英語資料と比較して収容可能な情報量が40~70%も減少します。
例えば、AIに長文書の分析や会議録の要約を依頼するといった同種のタスクにおいて、中国語ユーザーがモデルに入力できる資料量は少なく、モデルが参照できるコンテキストも短くなります。結果として、より多くの金額を支払っているにもかかわらず、得られる作業領域はより狭くなってしまいます。
4つのデータセットを並べてみると、自然と浮かび上がる疑問があります。
なぜ同一のテキストを異なる言語で入力すると、トークン数が異なるのでしょうか?なぜClaudeおよびGPTでは中国語が高コストであり、一方QwenおよびDeepSeekでは中国語の方がむしろ安価なのでしょうか?
その答えは、これまで何度も登場した概念「トーカナイザ(分詞器)」に隠されています。
1つの漢字は、いくつに分割できるか?
モデルが文字列を読み取る前に、トーカナイザによって入力を個々のトークンに分割します。トーカナイザを、AIの「積み木切断機」とイメージしてください。あなたが1文を入力すると、それは標準化された積み木(=トークン)に分割されます。AIモデルは文字列そのものは認識せず、積み木の番号のみを認識します。使った積み木の数だけ、料金が発生します。
英語の分割方法は直感的です。「intelligence」はほぼ確実に1トークン、「information」も1トークンとなります。単語1つが課金単位となります。

ところが、中国語になるとこのプロセスで問題が生じます。「人工知能は、現在世界の情報インフラを再構築しています」という同一の文を、GPT-4のcl100kトーカナイザとQwen 2.5のトーカナイザにそれぞれ入力すると、分割結果はまったく異なります。
GPT-4では基本的に1文字ごとにトークンが分割されますが、Qwenでは「人工知能」のような語彙単位で1トークンとして認識されます。
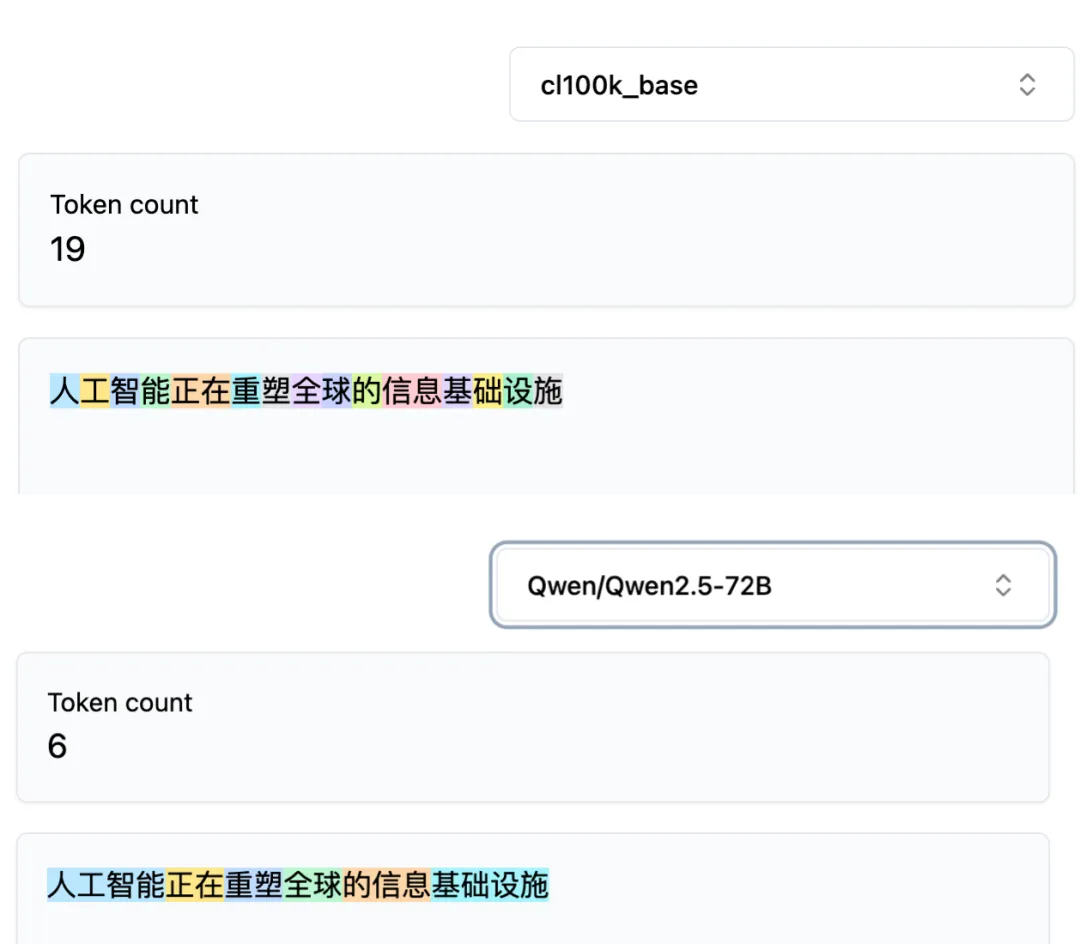
16文字のこの文は、GPT-4では19トークン、Qwenではわずか6トークンに分割されます。
なぜこのような分割になるのでしょうか?その原因は「BPE(Byte Pair Encoding:バイトペアエンコーディング)」というアルゴリズムにあります。
BPEは、訓練コーパス内でどの文字列の組み合わせが最も頻繁に出現するかを統計し、高頻度の組み合わせを1つのトークンとして合体させ、語彙表(ボキャブラリ)に追加します。
GPT-2時代の訓練コーパスは、大部分が英語で構成されていました。英文字の組み合わせ(th、ing、tionなど)は繰り返し出現するため、すぐにトークンとして合体されました。一方、中国語の文字はそのコーパス内での出現頻度が非常に低く、語彙表に登録されることはなく、原始的なバイト単位で処理されることになりました。1漢字はUTF-8で3バイトを占めるため、3トークンになります。

BPEは訓練コーパス内の文字列出現頻度に基づいて合体を決定する。英語中心のコーパスでは、中国語のUTF-8バイトは漢字単位で合体できない
その後、GPT-4のcl100k語彙表は拡大され、常用漢字が語彙表に取り込まれるようになり、1字あたり1~2トークンに削減されましたが、全体としての効率は依然として英語には及びません。
GPT-4oのo200k語彙表では、中国語の効率がさらに向上しました。これが、前述のデータでGPT-4oのcn/en比がClaudeより低い理由です。
QwenおよびDeepSeekのような国産モデルは、設計段階から大量の常用漢字および高頻度語彙を、漢字単位・語彙単位で語彙表に組み込んでいます。1字=1トークンとすることで、効率が2倍以上に向上します。

同一文を異なるトーカナイザで分割した結果の模式図
そのため、彼らのcn/en比が1を下回ることが可能となり、漢字の情報密度は元々単語単位の英語より高いため、トーカナイザが漢字を無理に分割しなければ、この天然の優位性がそのまま発揮されます。
したがって、前節の4つのデータの差異の根源は、モデルの能力ではなく、トーカナイザの語彙表が中国語にどれだけのスペースを割り当てているかにあります。
Claudeおよび初期のGPTの語彙表は、英語をデフォルトとして構築されており、中国語は後から「押し込まれた」存在です。一方、QwenおよびDeepSeekの語彙表は、設計当初から中国語をデフォルト言語として扱っています。この出発点の違いが、トークン数、請求額、コンテキストウィンドウのサイズへと一貫して伝播しています。
文言文は本当に安価なのか?
次に、冒頭の2つ目の噂、「文言文は現代中国語よりもトークンが節約できる」について検証します。
データはこの主張を確認しました。テストでは、文言文サンプルのcn/en比はすべての5種類のトーカナイザで一貫して1を下回り、同一内容の文言文版は、対応する英語訳よりもトークン数が少なくなっていました。
すべてのモデルにおいて、文言文のトークン消費量は現代中国語だけでなく、英語よりも少ない
その理由は単純です。文言文は用字が極めて凝縮されています。「学而不思則罔、思而不學則殆」は12字ですが、現代中国語訳は「ただ学ぶだけで考えないならば迷い、ただ考えるだけで学ばないならば困窮に陥る」で、文字数は2倍になり、当然トークン数も2倍になります。
さらに、文言文の常用字(之、也、者、而、不など)はすべて高頻度文字であり、どのトーカナイザの語彙表にも独立した位置が確保されているため、バイト単位に分割されることはありません。したがって、文言文は符号化レベルでも確かに効率的なのです。
ただし、ここには落とし穴があります。
文言文のトークン節約は符号化側の話であり、モデルの推論負荷は軽減されません。「罔」という1字に対して、モデルはその文脈で「迷う」「欺かれる」あるいは「ない」のいずれを意味するかを判断する必要があります。現代中国語では26字を使ってこの意味を明確に表現できますが、文言文ではそれを圧縮してモデルに推論の負担を押し付けています。たとえるなら、ZIPファイルは容量が小さいが、解凍にはより多くの計算が必要になるのと同じです。
トークンは節約できても、推論のコストは上昇し、理解の正確性も低下します。この帳簿は決して採算が取れません。
文言文のこの例は、トークン数そのものがそれほど多くのことを示していないという事実を私に気づかせてくれました。しかし、この方向でさらに深く考えると、私がこれまで見過ごしていたもう1つの層があります。
前述の通り、GPT-2時代のトーカナイザでは「人」が3つのUTF-8バイトトークンに分割されましたが、GPT-4の語彙表拡大により常用漢字は1字=1トークンとなり、Qwenではさらに「人工知能」4文字が1トークンに統合されました。
直感的には、これは継続的に改善されていくプロセスです:統合が進むほど効率は上がり、モデルの理解も向上するはずです。
しかし、本当にそうでしょうか?私たちが漢字をどのように習得したかを思い出してみてください。
漢字は表意文字であり、現代漢字の80%以上は形声文字で、意味を表す偏旁と音を表す部首から構成されています。「氵(さんずい)」のつく字は液体に関係し、「木(きへん)」のつく字は植物に関係し、「火(ひへん)」のつく字は熱に関係します。偏旁部首は、人が漢字を学ぶ際に最も基本的な意味の手がかりであり、見慣れない「焱(エン)」という字を見ても、3つの「火」からそれが火に関係することを推測できます。
偏旁部首は、人が漢字を識別する際の最も基礎的な意味的線索であり、人はまず構造から意味のカテゴリーを推定し、その後文脈から具体的な意味を理解します。

火花、炎、光炎。文語および人名でよく使われ、光明・熾熱を意味する。
しかし、トーカナイザの語彙表では、「焱」という字に対応するのは単なる番号です。仮にそれが38721号だとすると、それは語彙表内のインデックス位置を示すだけで、モデルはその番号から一連の数値ベクトルを検索し、それによって「焱」を表現します。
この番号自体は、その字の内部構造に関する情報を一切持ちません。38721と38722の関係は、1と10000の関係とモデルにとって何ら変わりません。結果として、「漢字の構造」という情報層は完全に封印されてしまいます。「焱」が3つの「火」から成っているという事実は、この番号には一切反映されていません。
もちろん、モデルは大量の訓練データを通じて間接的に「焱」「炎」「灼」が似た文脈で頻出することを学習できますが、それは偏旁情報を直接活用するよりも間接的な手法です。
では、モデルは分割されたバイトから、偏旁に類似した構造的ヒントを「見て」、その後の計算層で再構成できるのでしょうか?この手法はトークン数が多くコストも高くなりますが、意味理解の観点では、不透明な番号をそのまま受け入れるよりも効果的かもしれません?
2025年にMIT Press刊『Computational Linguistics』に掲載された論文(『Tokenization Changes Meaning in Large Language Models: Evidence from Chinese』)が、この問いに答えています。
破片の中に芽吹く偏旁
論文著者のDavid Haslett氏は、ある歴史的な偶然に着目しました。
1990年代、Unicode同盟が漢字にUTF-8符号を割り当てる際、その並び順は部首別に分類されていました。同じ部首を持つ漢字は、UTF-8符号も隣接しています。「茶」と「茎」はどちらも「艹(くさかんむり)」を含み、そのUTF-8バイト列は同じバイトで始まります。「河」と「海」はどちらも「氵(さんずい)」を含み、バイト列も同様に共通のバイトで始まります。
UTF-8は部首順に漢字を並べており、同じ部首の漢字は符号が近い|出典:Github
これは、トーカナイザが漢字を3つのUTF-8バイトトークンに分割する場合、同じ部首を持つ漢字は最初のトークンを共有することを意味します。モデルは訓練中にこうした共通のバイトパターンを繰り返し目にし、その結果「最初のトークンが同じ漢字は、しばしば同じ意味カテゴリーに属する」と学習する可能性があります。これは機能的に、人が偏旁から意味を推定するプロセスに近いものです。
Haslett氏は、これを検証するために3つの実験を設計しました。
1つ目の実験では、GPT-4、GPT-4o、Llama 3に対し、「茶」と「茎」が同じ意味的部首を含むかどうかを尋ねました。
2つ目の実験では、2つの漢字の意味的類似度を評価させました。
3つ目の実験では、「異なるものを選べ」という除外タスクを実施しました。
各実験では、2つの変数を制御しました:2つの漢字が実際に同じ部首を共有するか否か、およびトーカナイザ下で最初のトークンを共有するか否か。この2×2の設計により、部首効果とトークン効果のそれぞれの影響を分離することが可能になりました。
3つの実験の結果は一致していました:漢字が複数トークンに分割される場合(例えばGPT-4の旧トーカナイザでは、89%の漢字が複数トークンに分割される)、モデルが共通部首を認識する正確率は高くなりました。一方、漢字が単一トークンとして符号化される場合(GPT-4oの新トーカナイザでは、57%の漢字しか複数トークンにならない)、正確率は低下しました。
言い換えれば、先述の仮説は成立しました。漢字を細かく分割すると確かにコストは高くなりますが、分割されたバイト列には部首の痕跡が残っており、モデルは実際にそこから何かを学習しているのです。一方、漢字を単一トークンとして符号化するとコストは下がりますが、部首情報は不透明な番号に封じ込められ、モデルはバイト列からこの手がかりを取得できなくなってしまいます。
ただし、この結論は字形に由来する特定の意味的タスクに限定されており、モデル全体の中国語理解力、論理的推論力、長文生成能力の低下を意味するものではありません。また、実験で比較したGPT-4とGPT-4oは、トーカナイザの違い以外にも、モデルアーキテクチャ、訓練コーパス、パラメータ数が大きく異なっており、正確率の変化を100%トーカナイザ粒度の変更に帰することはできません。
この発見は、工学的側面でも裏付けられています。2024年のGPT-4oを対象とした研究では、新トーカナイザが特定の中国語文字列を長い1トークンに統合した後に、モデルが誤解を生じる事例が観測されました。研究者が専門の中国語分かち書きツールを用いてこれらの長トークンを再分割し、再度モデルに入力したところ、理解の正確性が回復しました。
現在、世界の大規模言語モデル業界における主流のコンセンサスは、対象言語に最適化された語彙単位/漢字単位のトーカナイザが、モデルの全体的な性能を大幅に向上させることです。語彙単位/漢字単位の符号化は、トークンコストを大幅に削減し、コンテキストウィンドウの有効情報量を増加させるだけでなく、系列長を短縮し、推論遅延を低減し、長文処理の安定性を向上させます。論文で示された特定タスクにおける優位性は、大多数の中国語NLPシーンにおける性能向上を上回るものではありません。
しかし、この事実は、大規模システムにおいて最も扱いにくい問題の1つを突いています:設計した部分は最適化できますが、自分が所有していることにすら気づかない部分は最適化できません。Unicode同盟が部首順に符号を並べたのは、人間による検索の利便性のためであり、BPEが漢字をバイト単位に分割したのは、コーパス内での漢字の出現頻度が極めて低かったためです。2つの無関係な工学的判断が偶然重なり、誰も意図しなかった意味的チャンネルが生まれてしまったのです。
そして、次世代のエンジニアがトーカナイザを「改良」し、漢字を単一トークンとして統合するとき、彼らは同時に自分自身が存在すら知らなかった道を消し去ってしまうのです。効率は向上し、コストは低下しますが、ある種のものが静かに失われ、しかもエラー通知すら届かないのです。
したがって、事態は「AIにおける中国語は高コストである」という単純な判断よりも複雑です。あらゆるトーカナイザは、あるデフォルト値に向けて最適化されており、その代償は別の場所に隠されています。
リン・ユータン
中国語が西洋の技術インフラに適合する際に支払う代償は、AI時代になって初めて生じたわけではありません。
2025年1月、ニューヨーク在住のネルソン・フェリックス氏が、Facebook上のタイプライター愛好家グループに数枚の写真を投稿しました。彼は妻の祖父の遺品の中から、漢字が刻まれたタイプライターを発見し、その由来が分からなかったのです。すぐに数百件のコメントが寄せられました。

ネルソン・フェリックス氏の質問:「ミンクアイ・タイプライター」は価値があるか?|出典:Facebook
スタンフォード大学の漢学家トーマス・S・マランイ(墨磊寧)氏が写真を見た瞬間に、それが1947年にリン・ユータンが発明した「ミンクアイ・タイプライター」の唯一のプロトタイプ機であり、約80年間行方不明となっていたことを特定しました。同年4月、フェリックス夫妻はこのタイプライターをスタンフォード大学図書館に売却しました。
ミンクアイ・タイプライターが解決しようとした課題は、今日のトーカナイザが直面している課題と構造的に同一です:いかにして中国語を、西洋言語のために設計された技術インフラに効率的に組み込むか。
1940年代の英語タイプライターは26キーで、1キー=1文字というシンプルかつ直接的な仕組みでした。中国語には数千の常用字があり、1キー=1文字という方式は不可能でした。当時の中国語タイプライターは巨大な字盤を備えており、数千の活字が並べられており、打字員が手で1字ずつ選び出す必要があり、1分間に10字程度しか打てませんでした。

1899年、アメリカの宣教師シェフィールド(Devello Z. Sheffield)が発明した中国語タイプライターは、中国語タイプライターの最古の記録|出典:Wikipedia
リン・ユータンは12万米ドルの研究開発費を投じ、ほぼ全財産をなげうち、ニューヨークのカール・E・クラム社に72キーのみの中国語タイプライターを製造させました。その仕組みは、漢字を字形構造で分解し、上形キーで字根の上半部を、下形キーで下半部を選択し、候補字を「マジックアイ」と呼ばれる小さな窓に表示し、数字キーで選択するというものでした。1分間に40~50字を打て、8000以上の常用文字をサポートしました。

(左)透明ガラスの小窓が「マジックアイ」;(右)ミンクアイ・タイプライターの内部構造|出典:Facebook
趙元任氏はこれを評して、「中国人でもアメリカ人でも、少し練習すればこのキーボードに慣れることができる。これこそ我々が求めていたタイプライターである」と述べました。
技術的にはミンクアイ・タイプライターは画期的でしたが、商業的には失敗しました。
リン・ユータンがレミントン社の幹部にデモンストレーションを行った際、機械に故障が発生し、投資家は興味を失いました。さらに高額な製造コストとリン自身の資金繰りの悪化により、量産は不可能となりました。1948年、リンはプロトタイプ機および商業権をマーゲンターラー・ラインオタイプ社(Mergenthaler Linotype)に売却しましたが、同社は最終的に量産を断念し、プロトタイプ機は1950年代の同社移転時に従業員がロングアイランドの自宅に持ち帰り、その後行方不明となり、2025年に再び発見されたのです。
墨磊寧氏は著書『The Chinese Typewriter(中国語タイプライター)』において、ミンクアイ・タイプライターは「失敗ではなかった」と判断しています。1940年代の製品としては確かに失敗しましたが、人間と機械のインタラクションのパラダイムとしては成功したのです。
リン・ユータンは、中国語の「タイプ入力」を初めて「検索+選択」に変えました。3列のキーで字根を組み合わせ、候補字から選ぶという方式は、現代のすべての中国語入力法の基盤となるロジックです。倉頡、五筆、ソウゴウ拼音など、すべてがミンクアイ・タイプライターの子孫と言えるでしょう。

『The Chinese Typewriter(中国語タイプライター)』著者:墨磊寧|出典:Douban
この約80年を越えて蘇ったタイプライターと、今日私たちが繰り返し議論しているトーカナイザには、ある種の歴史的法則が隠されています。中国語は常に1つの問いに直面しています:
ローマ字で構成されたインフラに、いかにして接続するか。
興味深いことに、この探求の過程には、非人為的な偶然が満ちています。Unicode同盟が人間の検索利便性のために定めた並び順と、BPEアルゴリズムの無心の分割が重なり合い、神経ネットワークのブラックボックス内で、人間の漢字認識プロセスが再現されたのです。そして、エンジニアたちが「中国語税」を解消するために、漢字を意図的に結合し、コストを下げようとするとき、その偶然に生まれた意味的チャンネルも閉じてしまうのです。
歴史は一本の直線的な進化の軌道ではなく、さまざまな制約条件の圧力下で絶えず変形する流体です。
ある能力は設計によって生み出されるが、ある能力は単に偶然削除されなかっただけなのかもしれません。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













