

エッジで生まれる:分散型計算ネットワークはどのようにしてCryptoとAIに力を与えるのか?
TechFlow厳選深潮セレクト
エッジで生まれる:分散型計算ネットワークはどのようにしてCryptoとAIに力を与えるのか?
現実的な観点から見ると、分散型計算ネットワークは、現在の需要の掘り起こしと将来の市場空間の両方を同時に考慮する必要がある。
執筆:Jane Doe、Chen Li
1 AI と Crypto の接点
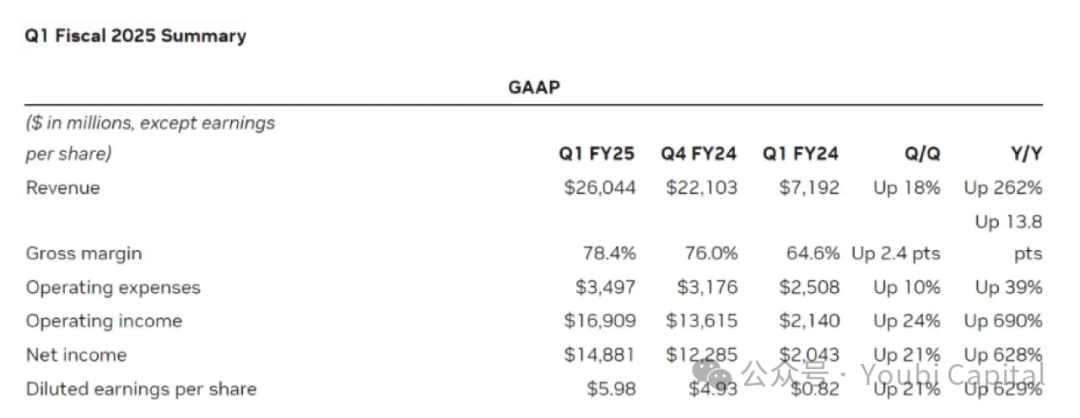
5月23日、半導体大手のNVIDIAは2025会計年度第1四半期決算を発表した。同決算によると、NVIDIAの第1四半期売上高は260億ドルに達した。そのうちデータセンター事業の売上高は前年比427%増の226億ドルという驚異的な数字となった。NVIDIAが単独で米国株式市場の景気を支える財務成績の裏には、AI分野を巡るグローバルなテック企業による計算能力(算力)需要の爆発的増加が背景にある。最先端のテクノロジー企業ほどAI分野への進出意欲が強く、それに伴い算力に対する需要も指数関数的に増加している。TrendForceの予測によれば、2024年に米国の主要クラウドサービスプロバイダーであるMicrosoft、Google、AWS、Metaが求めるハイエンドAIサーバーの需要は、それぞれ世界全体の需要の20.2%、16.6%、16%、10.8%を占め、合計で60%以上となる見込みだ。
「チップ不足」はここ数年間、毎年のキーワードとなっている。一方で、大規模言語モデル(LLM)のトレーニングや推論(inference)には膨大な算力が必要であり、モデルの反復更新に伴って算力コストと需要は指数関数的に増加している。他方、Metaのような大企業が大量のチップを購入することで、世界的な算力リソースはこれらのテック大手に偏り、中小企業が必要な算力を得るのがますます困難になっている。中小企業が直面する課題は、需要急増による供給不足だけでなく、供給構造の矛盾にも起因している。現在、供給側には依然として多数のアイドル状態のGPUが存在する。例えば、一部のデータセンターでは算力使用率が12~18%にとどまっており、多数の算力が未使用のままになっている。また、暗号資産(クリプト)マイニングにおいても利益低下により、多くの算力リソースが放置されている。こうした算力は必ずしもAIトレーニングなどの専門的用途に適しているわけではないが、コンシューマー向けハードウェアはAI推論、クラウドゲームレンダリング、クラウドスマホなど他の分野でも大きな役割を果たすことができる。このような未利用算力を統合・活用するチャンスは非常に大きい。
視点をAIからクリプトへ移すと、3年間にわたり低迷していた暗号資産市場が再びブルマーケットを迎え、ビットコイン価格は連日最高値を更新し、さまざまなミームコインが次々と登場している。AIとCryptoはここ数年、 buzzword として注目を集めてきたが、人工知能とブロックチェーンという二つの重要な技術は、まるで平行線のように、「交点」を見つけることができていない。今年初頭、Vitalikは「The promise and challenges of crypto + AI applications」と題する記事を発表し、今後のAIとCryptoの融合シナリオについて考察した。彼はその中で、ブロックチェーンとMPCなどの暗号技術を活用してAIの分散型トレーニングや推論を行うことで、機械学習のブラックボックスを解き明かし、より信頼性の高いAIモデルを実現できる可能性に言及している。しかし、こうしたビジョンの実現にはまだ長い道のりがある。ただ、彼が挙げたユースケースの一つ――Cryptoの経済インセンティブをAIに活かす――は、重要かつ短期間で実現可能な方向性の一つである。分散型算力ネットワークは、現時点でのAI+Cryptoにとって最も適した応用シナリオの一つと言える。
2 分散型算力ネットワーク
現在、すでに多くのプロジェクトが分散型算力ネットワーク分野で開発を進めている。これらのプロジェクトの基本的な発想は類似しており、次のように要約できる:トークンによるインセンティブを通じて、算力保有者にネットワークへの参加と算力提供を促し、断片化された算力リソースを一定規模の分散型算力ネットワークに集約する。これにより、アイドル算力の利用率を高め、同時に顧客の算力需要をより低コストで満たし、需給双方のウィンウィンを実現する。
読者が短期間でこの分野の全体像を把握できるよう、本稿ではミクロとマクロの両視点から具体的なプロジェクトおよび業界全体を分析し、各プロジェクトの核心的競争優位性と分散型算力ネットワーク分野の発展状況を理解するための分析フレームワークを提供する。以下では、Aethir、io.net、Render Network、Akash Network、Gensynの5つのプロジェクトを紹介・分析し、それらの状況と業界全体の発展について総括・評価する。
分析枠組みに関して言えば、個別の分散型算力ネットワークに注目する場合、以下の4つの核心的構成要素に分解することが可能である:
-
ハードウェアネットワーク:分散した算力リソースを統合し、世界中に配置されたノードを通じて算力の共有と負荷分散を実現する。これが分散型算力ネットワークの基盤層である。
-
バイラテラルマーケット:適切な価格設定と発見メカニズムを通じて、算力提供者と需要者をマッチングさせ、安全な取引プラットフォームを提供し、需給両者の取引が透明・公正・信頼できるように確保する。
-
コンセンサスメカニズム:ネットワーク内のノードが正しく稼働し、作業を完了していることを保証するもの。主に二つのレベルを監視する:1)ノードがオンラインで、いつでもタスクを受け入れられる状態にあるかどうか;2)ノードの作業証明:ノードがタスクを受け取った後、正しく効率的にそれを完了し、算力が他の目的に流用されていないか。
-
トークンインセンティブ:より多くの参加者がサービスを提供または利用するようインセンティブを与え、ネットワーク効果をトークンによって捕捉し、コミュニティ内での利益共有を実現する。
一方、分散型算力ネットワーク業界全体を俯瞰する場合、Blockworks Researchのレポートが有用な分析枠組みを提供している。この分野のプロジェクトを3つの異なるレイヤーに分類することができる。
-
Bare metal layer:分散型コンピューティングスタックの基盤層。主な任務は、原始的な算力リソースを収集し、API経由で呼び出せるようにすること。
-
Orchestration layer:分散型コンピューティングスタックの中間層。主な任務は、算力の調整・抽象化であり、算力のスケジューリング、拡張、操作、負荷分散、フォールトトレランスなどを担当する。主な目的は、下位のハードウェア管理の複雑さを「抽象化」し、エンドユーザーに対してより高度なインターフェースを提供し、特定の顧客層にサービスを提供すること。
-
Aggregation layer:分散型コンピューティングスタックの最上層。主な任務は統合であり、ユーザーが一箇所でAIトレーニング、レンダリング、zkMLなど多様な計算タスクを実行できる統一インターフェースを提供する。複数の分散型コンピューティングサービスの編成と配布層に相当する。
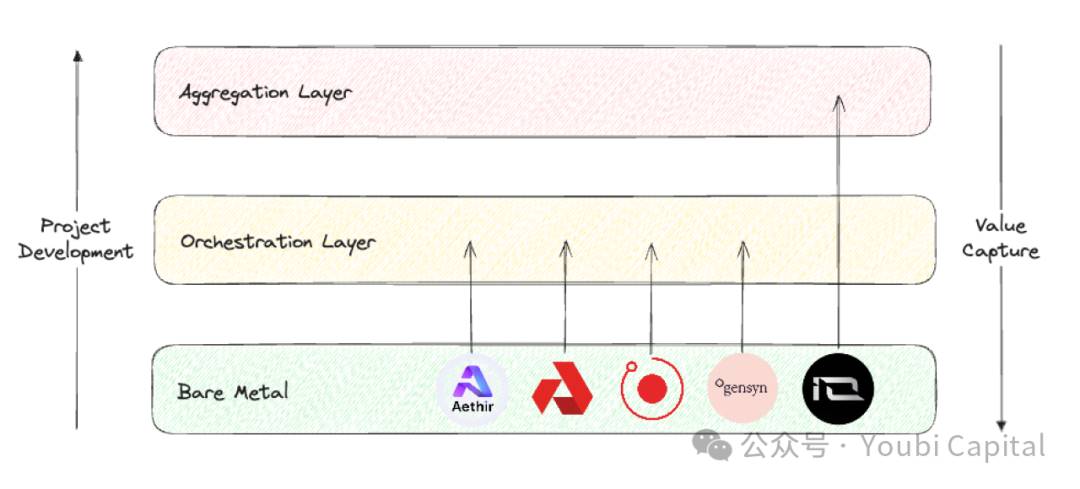
出典: Youbi Capital
以上の二つの分析フレームワークに基づき、選定した5つのプロジェクトを横断的に比較し、核心業務、市場ポジショニング、ハードウェア設備、財務パフォーマンスの4つの観点から評価を行う。
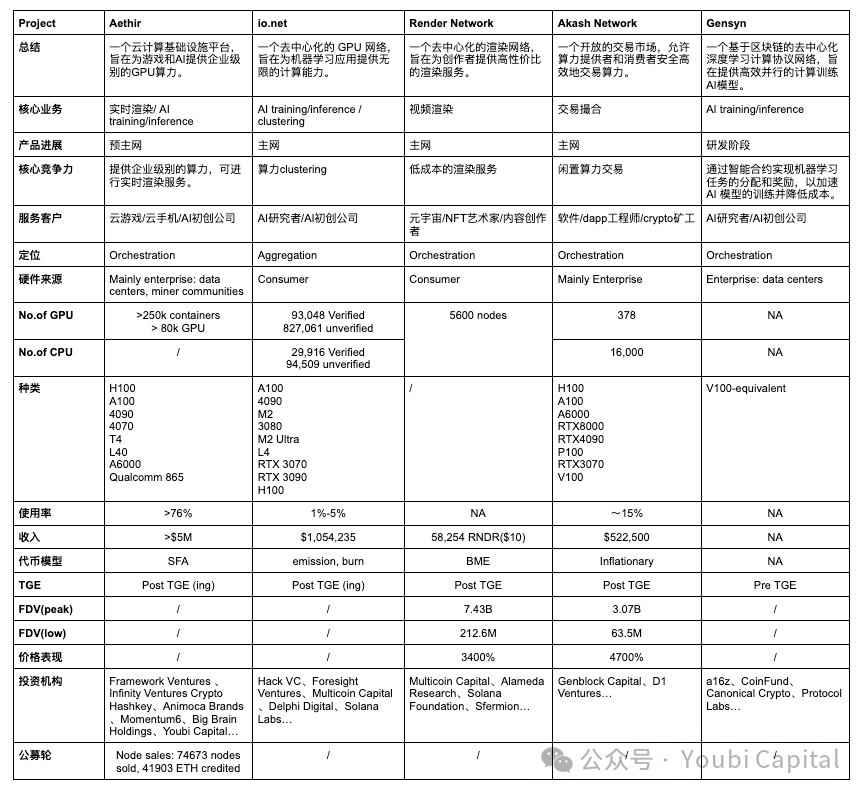
2.1 核心業務
根本的なロジックから見ると、分散型算力ネットワークは極めて均質的であり、すなわち「トークンインセンティブを通じてアイドル状態の算力保有者に算力提供を促す」ことにある。この根本ロジックを軸に、以下の3つの差異を通じて各プロジェクトの核心業務の違いを理解できる:
-
アイドル算力の出所:
-
市場におけるアイドル算力には主に二つの出所がある:1)データセンター、マイナーなどの企業が保有するアイドル算力;2)個人ユーザーが保有するアイドル算力。データセンターの算力は通常、プロフェッショナルグレードのハードウェアだが、個人ユーザーは一般的にコンシューマーグレードのチップを購入する。
-
Aethir、Akash Network、Gensynの算力は主に企業から調達している。企業から算力を調達する利点は以下の通り:1)企業やデータセンターは通常、より高品質なハードウェアと専門のメンテナンスチームを持ち、算力リソースの性能と信頼性が高い;2)企業の算力リソースはより均質的であり、集中管理と監視により、リソースのスケジューリングとメンテナンスがより効率的になる。ただし、この方式はプロジェクト側に高い要求を課す。つまり、算力を保有する企業とのビジネス関係を築く必要がある。また、拡張性と分散化の程度が一定程度制限される。
-
Render Networkとio.netは、主に個人ユーザーに自身のアイドル算力を提供させるようインセンティブを与えている。個人ユーザーから算力を調達する利点は以下の通り:1)個人のアイドル算力の顕在コストが低く、より経済的な算力リソースを提供できる;2)ネットワークの拡張性と分散化度合いが高く、システムの弾力性と堅牢性が強化される。一方で、個人のリソースは広範囲かつ非統一的であり、管理とスケジューリングが複雑になり、運用管理の難易度が上がる。さらに、個人の算力を利用して初期のネットワーク効果を形成することはより困難である(kickstartが難しい)。最後に、個人のデバイスにはセキュリティリスクが多く、データ漏洩や算力の悪用の危険がある。
-
算力消費者
-
算力消費者の観点から見ると、Aethir、io.net、Gensynのターゲット顧客は主に企業である。BtoB顧客の場合、AIやゲームのリアルタイムレンダリングには高性能計算が必要とされる。こうしたワークロードは算力リソースに極めて高い要求を示し、通常、ハイエンドGPUまたはプロフェッショナルグレードのハードウェアを必要とする。また、BtoB顧客は算力リソースの安定性と信頼性に非常に高い要求を持つため、高品質なSLA(サービスレベルアグリーメント)を提供し、プロジェクトの正常稼働と迅速な技術サポートを保証しなければならない。さらに、BtoB顧客の移行コストは非常に高く、分散型ネットワークが成熟したSDKを提供できなければ(例えばAkash Networkはユーザー自身がリモートポートに基づいて開発する必要がある)、顧客の移行は困難である。顕著な価格優位性がない限り、顧客の移行意思は非常に低い。
-
Render NetworkとAkash Networkは主に個人ユーザーに算力サービスを提供している。CtoCユーザーにサービスを提供する場合、プロジェクトは使いやすいインターフェースとツールを設計し、良好なユーザーエクスペリエンスを提供する必要がある。また、消費者は価格に敏感であるため、プロジェクトは競争力のある価格設定を行う必要がある。
-
ハードウェアタイプ
-
一般的な計算ハードウェアリソースにはCPU、FPGA、GPU、ASIC、SoCなどがある。これらは設計目的、性能特性、応用分野において明確な違いがある。要するに、CPUは汎用計算に優れ、FPGAは高並列処理とプログラマブル性に長け、GPUは並列計算に秀でており、ASICは特定タスクにおいて最も効率的であり、SoCは複数機能を一体に集積し、高度に統合されたアプリケーションに適している。どのハードウェアを選ぶかは、具体的な用途の要求、性能要件、コスト考慮に依存する。本稿で取り上げる分散型算力プロジェクトの多くはGPU算力の収集に焦点を当てており、これはプロジェクトのビジネスタイプとGPUの特徴によるものである。GPUはAIトレーニング、並列計算、マルチメディアレンダリングなどで独自の優位性を持っている。
-
これらのプロジェクトはいずれもGPUの統合に関与しているが、異なる用途ではハードウェア仕様に対する要求が異なるため、ハードウェアには異種混合の最適化コアとパラメータが存在する。これらのパラメータには並列性/直列依存性、メモリ、遅延などがある。例えば、レンダリングワークロードは実際にはコンシューマーグレードGPUに適しており、データセンター用GPUには向かない。なぜならレンダリングはレイトレーシングなどの要求が高く、RTX 4090などのコンシューマーチップはRTコアを強化しており、レイトレーシングタスクに特化した計算最適化が施されているためである。一方、AIトレーニングと推論にはプロフェッショナルグレードのGPUが必要となる。そのため、Render Networkは個人ユーザーからRTX 3090や4090などのコンシューマーグレードGPUを集約できるが、IO.NETはAIスタートアップのニーズに対応するため、H100やA100などのプロフェッショナルグレードGPUをより多く必要とする。
2.2 市場ポジショニング
プロジェクトのポジショニングに関して、bare metal layer、orchestration layer、aggregation layerはそれぞれ解決すべき核心問題、最適化重点、価値捕獲能力が異なる。
-
Bare metal layerは物理リソースの収集と活用に注力し、orchestration layerは算力のスケジューリングと最適化に注力し、物理ハードウェアを顧客層のニーズに応じて最適に設計する。Aggregation layerは汎用的であり、異なるリソースの統合と抽象化に注力する。バリューチェーンの観点から言えば、各プロジェクトはbare metal層から始まり、上方へと進化していくべきである。
-
価値捕獲の観点からは、bare metal layer → orchestration layer → aggregation layerと進むにつれて、価値捕獲能力は段階的に増加する。Aggregation layerが最も多くの価値を捕獲できる理由は、最大のネットワーク効果を得られ、最も多くのユーザーに直接アクセスできるため、分散型ネットワークのトラフィック入口となり、算力リソース管理スタック全体の中で最も高い価値捕獲位置を占めるからである。
-
一方、aggregation platformを構築する難易度も最も高く、技術的複雑性、異種リソース管理、システム信頼性と拡張性、ネットワーク効果の実現、セキュリティとプライバシー保護、複雑な運用管理など、多岐にわたる課題を総合的に解決する必要がある。これらの課題はプロジェクトの冷启动(cold start)に不利であり、業界の発展状況とタイミングに依存する。orchestration layerがまだ成熟せず、一定の市場シェアを獲得していない段階で、aggregation layerを構築するのは現実的ではない。
-
現在、Aethir、Render Network、Akash Network、GensynはいずれもOrchestration layerに属しており、特定の目的と顧客層にサービスを提供することを目指している。Aethirの主力業務はクラウドゲームのリアルタイムレンダリングであり、BtoB顧客向けに開発・展開環境とツールを提供している;Render Networkは動画レンダリングを主業務とし、Akash Networkは「淘宝」のような取引プラットフォームを提供することを任務としている;GensynはAIトレーニング分野に特化している。io.netはAggregation layerを志向しているが、現時点での機能は完全なaggregation layerに至っておらず、Render NetworkやFilecoinのハードウェアを収集しているものの、ハードウェアリソースの抽象化と統合はまだ完了していない。
2.3 ハードウェア設備
-
現時点で、すべてのプロジェクトがネットワークの詳細データを公開しているわけではない。比較的、io.net explorerのUIが最も洗練されており、GPU/CPUの台数、種類、価格、分布、ネットワーク使用量、ノード収益などのパラメータを確認できる。ただし、4月末にio.netのフロントエンドが攻撃を受け、PUT/POSTインターフェースに認証(Auth)がなかったため、ハッカーがフロントエンドデータを改ざんした。これは他のプロジェクトにとっても、プライバシーとネットワークデータの信頼性に関する警鐘である。
-
GPUの台数とモデルに関して言えば、aggregation層であるio.netが収集するハードウェア台数は理論上最も多くなるはずである。Aethirがそれに続くが、他のプロジェクトのハードウェア状況はそれほど透明ではない。GPUモデルを見てみると、ioはA100のようなプロフェッショナルグレードGPUだけでなく、4090のようなコンシューマーグレードGPUも収集しており、品種が豊富で、io.netのaggregationポジショニングに合致している。ioは具体的なタスク要件に応じて最適なGPUを選択できる。ただし、異なるモデルやブランドのGPUは異なるドライバーと設定を必要とし、ソフトウェアも複雑な最適化を要するため、管理とメンテナンスの複雑さが増す。現在、ioのタスク割り当ては主にユーザー自身が選択している。
-
Aethirは自社のマイニングマシンを発表しており、5月にはQualcommが協力開発したAethir Edgeが正式にリリースされた。これはユーザーから離れた一元的GPUクラスター配置の方式を打破し、算力をエッジに配置するものである。Aethir EdgeはH100クラスター算力と連携し、AIシナリオにサービスを提供する。トレーニング済みモデルを展開し、最適なコストでユーザーに推論計算サービスを提供できる。この方式はユーザーに近く、サービスが迅速で、コストパフォーマンスも高い。
-
供給と需要の観点から見ると、Akash Networkを例に取ると、統計データによれば、CPU総量は約16k、GPU台数は378台であり、ネットワークリース需要に基づくと、CPUとGPUの利用率はそれぞれ11.1%と19.3%である。その中で、プロフェッショナルグレードGPUのH100のみが高いレンタル率を示しており、他のモデルはほとんどがアイドル状態にある。他のネットワークも概ねAkashと同様の状況であり、ネットワーク全体の需要は高くなく、A100、H100といった人気チップ以外の算力は大半が未使用状態にある。
-
価格優位性の観点では、クラウドコンピューティングの大手市場や従来のサービスプロバイダーと比べても、コストメリットは際立っていない。
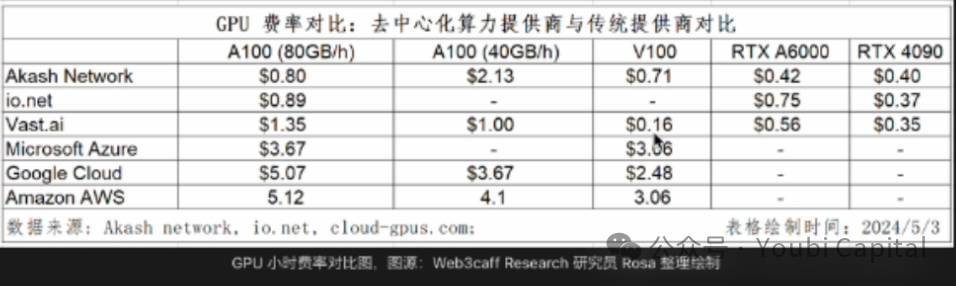
2.4 財務パフォーマンス
-
トークンモデルがどのように設計されていようと、健全なトークノミクスは以下の基本条件を満たす必要がある:1)ネットワークに対するユーザーの需要がトークン価格に反映されること、すなわちトークンが価値を捕捉できること;2)開発者、ノード、ユーザーなどすべての参加者が長期的に公平なインセンティブを得られること;3)中央集権化を防ぎ、内部関係者の過剰保有を回避すること;4)適切なインフレ・デフレメカニズムとトークン放出サイクルを設け、価格の大幅な変動がネットワークの安定性と持続性に影響を与えないようにすること。
-
トークンモデルを大まかにBME(burn and mint equilibrium)とSFA(stake for access)に分ける場合、両者のトークン縮小圧力の源泉は異なる:BMEモデルでは、ユーザーがサービスを購入後にトークンをバーンするため、システムの縮小圧力は需要によって決まる。一方、SFAではサービス提供者/ノードがサービス提供資格を得るためにトークンをステーキングする必要があるため、縮小圧力は供給によって生じる。BMEの利点は、非標準化商品に適していることにある。しかし、ネットワークの需要が不十分な場合、継続的なインフレ圧力に直面する可能性がある。各プロジェクトのトークンモデルは細部に差異があるが、総じてAethirはSFA寄りであり、io.net、Render Network、Akash NetworkはBME寄りであり、Gensynは不明である。
-
収益面では、ネットワークの需要量はネットワーク全体の収益に直接反映される(ここではマイナーの収益は議論しない。なぜならマイナーはタスク報酬に加え、プロジェクトからの補助金も受け取っているため)。公開データによると、io.netの数値が最も高い。Aethirの収益はまだ公表されていないが、公開情報から見ると、多数のBtoB顧客と契約を結んでいることが明らかになっている。
-
トークン価格に関して言えば、現時点でRender NetworkとAkash NetworkのみがICOを実施している。Aethirとio.netも最近トークンを発行しており、価格動向は引き続き注視が必要であり、ここでは深入りしない。Gensynの計画はまだ不明である。トークンを発行した2プロジェクトおよび本稿の対象外だが同一分野で既にトークンを発行しているプロジェクトを総合的に見ると、分散型算力ネットワークはいずれも目覚しい価格パフォーマンスを示しており、巨大な市場ポテンシャルとコミュニティの高い期待を一定程度反映している。
2.5 まとめ
-
分散型算力ネットワーク分野は全体として急速に発展しており、すでに多くのプロジェクトが製品を通じて顧客にサービスを提供し、一定の収益を得ている。この分野は純粋なストーリーから脱却し、初期サービス提供段階に入っている。
-
需要の弱さは分散型算力ネットワークが共通して抱える課題であり、長期的な顧客需要はまだ十分に検証・掘り起こされていない。しかし、需要面の低迷はトークン価格にあまり影響しておらず、既にトークンを発行したプロジェクトは好調な価格パフォーマンスを示している。
-
AIは分散型算力ネットワークの主なストーリーであるが、唯一のビジネスではない。AIトレーニング・推論に加えて、クラウドゲームのリアルタイムレンダリング、クラウドスマホサービスなどにも算力を活用できる。
-
算力ネットワークのハードウェアは高い異種混合性を示しており、算力ネットワークの品質と規模はさらなる向上が必要である。
-
CtoCユーザーにとってはコストメリットが顕著ではない。一方、BtoBユーザーにとってはコスト削減だけでなく、サービスの安定性・信頼性・技術サポート・コンプライアンス・法的サポートなども考慮する必要があり、Web3プロジェクトはこうした点で一般に劣っている。
3 最後に
AIの爆発的成長が算力需要を劇的に押し上げていることは疑いの余地がない。2012年以降、AIトレーニングタスクに使用される算力は指数関数的に増加しており、現在は3.5ヶ月ごとに2倍になっている(対照的に、ムーアの法則は18ヶ月ごとに2倍)。2012年以降、算力に対する需要は30万倍以上に増加しており、ムーアの法則による12倍の伸びを大きく上回っている。予測によると、GPU市場は今後5年間で年平均32%の成長率で2000億ドル以上に達する見込みだ。AMDの予測はさらに高く、2027年までにGPUチップ市場が4000億ドルに達すると見込んでいる。
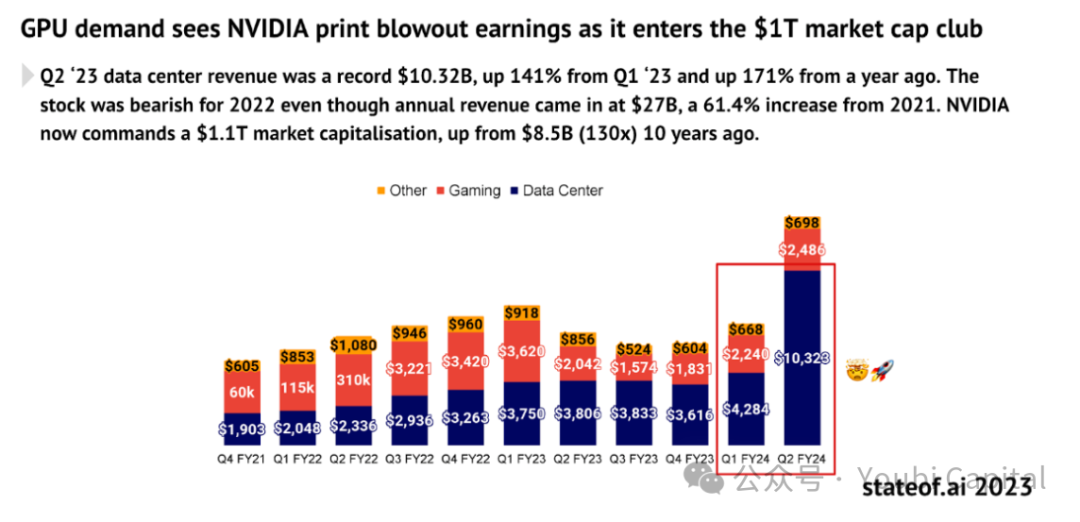
出典: https://www.stateof.ai/
人工知能やAR/VRレンダリングなどの計算集約型ワークロードの爆発的成長により、従来のクラウドコンピューティングや先進的計算市場における構造的非効率性が露呈している。理論的には、分散型算力ネットワークは、分散されたアイドル計算リソースを活用することで、より柔軟で低コストかつ効率的なソリューションを提供し、市場の巨大な計算リソース需要を満たすことができる。したがって、CryptoとAIの融合には巨大な市場ポテンシャルがあるが、伝統企業との激しい競争、高い参入障壁、複雑な市場環境にも直面している。総じて、すべてのCrypto分野を俯瞰すれば、分散型算力ネットワークは暗号領域の中で最も真の需要を得る可能性が高い垂直分野の一つである。
出典: https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
前途は明るいが、道は険しい。上述のビジョンを達成するには、解決すべき多くの問題と課題がある。要約すると:現時点では、従来型のクラウドサービスを単純に提供しても、プロジェクトの利益率は非常に小さい。需要側から分析すると、大企業は通常自社で算力を構築し、純粋なCtoC開発者はクラウドサービスを選択する傾向が強く、実際に分散型算力ネットワークを利用する中小企業に安定した需要があるかどうかは、さらに掘り起こしと検証が必要である。一方、AIは非常に高い潜在力と想像空間を持つ広大な市場であり、より広い市場を目指す未来の分散型算力サービスプロバイダーは、モデル/AIサービスへの転換を図り、より多くのCrypto+AIの使用シーンを探求し、プロジェクトが創出できる価値を拡大する必要がある。しかし、現時点ではAI分野へのさらなる発展には多くの問題と課題がある:
-
価格優位性が際立たない:前述のデータ比較からわかるように、分散型算力ネットワークのコストメリットは十分に発揮されていない。その原因としては、H100、A100など需要の高いプロフェッショナルチップについては、市場メカニズムにより価格が安くなりにくいことが挙げられる。また、分散型ネットワークはアイドル算力リソースを収集できるが、分散化による規模の経済効果の欠如、高いネットワーク・帯域コスト、極めて高い管理・運用の複雑性といった隠れたコストが算力コストをさらに押し上げている。
-
AIトレーニングの特殊性:分散型方式によるAIトレーニングは、現時点では巨大な技術的ボトルネックがある。このボトルネックはGPUの動作プロセスに直感的に現れている。大規模言語モデルのトレーニングでは、GPUがまず前処理済みのデータバッチを受け取り、順伝播と逆伝播の計算を行い、勾配を生成する。次に、各GPUが勾配を集約し、モデルパラメータを更新することで、すべてのGPUを同期させる。このプロセスは、すべてのバッチが処理されるか、予定されたエポック数に達するまで繰り返される。この過程では大量のデータ転送と同期が発生する。どのような並列・同期戦略を採用すべきか、ネットワーク帯域と遅延をどう最適化し、通信コストをどう削減するかといった問題は、現時点でまだ十分に解決されていない。現時点では、分散型算力ネットワークを用いたAIトレーニングは現実的ではない。
-
データセキュリティとプライバシー:大規模言語モデルのトレーニングプロセスでは、データ配分、モデルトレーニング、パラメータと勾配の集約など、データ処理と転送の各段階で、データの安全性とプライバシーが影響を受ける可能性がある。特に、データプライバシーはモデルプライバシーよりも重要である。もしデータプライバシーの問題が解決できなければ、需要側での真正なスケーリングは不可能である。
最も現実的な観点から言えば、分散型算力ネットワークは、現時点の需要掘り起こしと将来の市場空間の両方に配慮する必要がある。製品のポジショニングとターゲット顧客を正確に定め、例えばAIやWeb3ネイティブプロジェクト以外の、比較的周縁的な需要から始め、早期のユーザーベースを築くべきである。同時に、AIとCryptoの融合シナリオを不断に探求し、技術のフロンティアを追求し、サービスの転換・アップグレードを実現すべきである。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














