

BitVMの解説:BTCチェーン上でどのようにして詐欺証明を検証するか?(EVMやその他のVMのオペコードを実行する)
TechFlow厳選深潮セレクト
BitVMの解説:BTCチェーン上でどのようにして詐欺証明を検証するか?(EVMやその他のVMのオペコードを実行する)
BitVMはon-chainのデータを必要とせず、まずオフチェーンで公開・保存され、チェーン上にはコミットメント(約束)のみが格納される。
著者:霧月 & Faust、Geekweb3
アドバイザー:Kevin He、BitVM 中文コミュニティ発起人、元 Web3 Tech Head@Huobi
はじめに:現在、ビットコインLayer2は大きなブームとなっており、市場で自らを「ビットコインLayer2」と位置づけているプロジェクトは、数十にも上るとされている。その中には、「Rollup」と自称するものも多く、BitVMホワイトペーパーで提案された方式を採用していると称しており、BitVMはビットコインエコシステムにおける注目技術となっている。
だが残念なことに、現時点でのBitVMに関する資料の多くは、その原理を分かりやすく説明できていない。
本稿は、わずか8ページのBitVMホワイトペーパーを読み、TaprootやMASTツリー、Bitcoin Scriptに関連する資料を調査した上で得られた簡単なまとめである。読者の理解を助けるため、一部の表現はホワイトペーパーとは異なるが、読者はLayer2についてある程度の知識を持ち、「詐欺証明(fraud proof)」の基本的な考え方が理解できるものと仮定している。

要するにBitVMの発想とは、「データはチェーン外で公開・保存し、チェーン上にはCommitment(コミットメント)だけを置く」ことである。
チャレンジ(異議申し立て)や詐欺証明が発生した場合、必要なデータのみをオンチェーンに提出し、それがチェーン上のCommitmentと関連していることを証明する。その後、BTCメインネットがこれらのオンチェーンデータに問題がないか、データ生成者(取引処理ノード)が悪意を持っていないかを検証する。すべてはオッカムの剃刀の原則に従う――「必要なければ、実体を増やすべきではない」(可能な限りオンチェーンを最小限に抑える)。

本文:BitVMに基づくBTC上での詐欺証明検証スキームを平易に要約すると、以下の通りである。
1.BitVMの核心的な発想
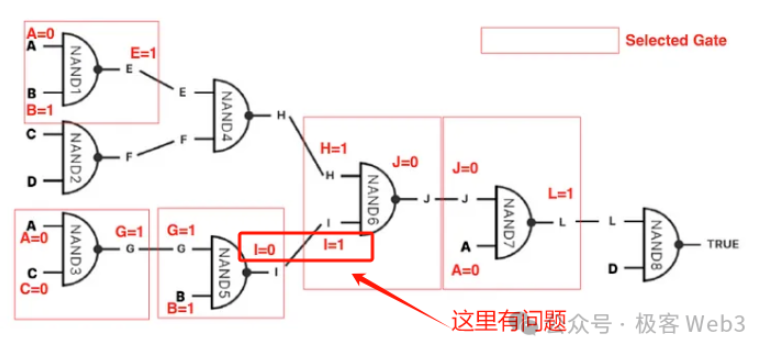
まず、コンピュータ/プロセッサとは、多数の論理ゲート回路が組み合わされた入出力システムである。BitVMの核となる発想の一つは、Bitcoin Scriptを使って、論理ゲート回路の入出力効果を模倣することにある。
論理ゲート回路を模倣できれば、理論的にはチューリングマシンを実現でき、すべての計算可能タスクを達成できる。つまり、人材と資金があれば、エンジニアを集めて、機能が限定的なBitcoin Scriptコードを使い、まず論理ゲート回路を模倣し、さらに膨大な数の論理ゲートを組み合わせてEVMやWASMの機能を実装できるのである。
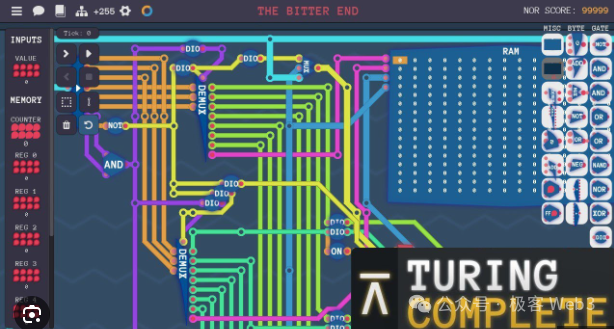
(このスクリーンショットは教育ゲーム『Turing Complete』からのもので、最も重要な要素はNANDゲートなどの論理ゲートを使って完全なCPUプロセッサを構築することである)
BitVMの発想は、「マインクラフト」でレッドストーン回路を使ってM1プロセッサを作ること、あるいは積み木でニューヨークのエンパイアステートビルを再現することに例えられることがある。

(これは実際に『マインクラフト』内で1年かけて作られた「プロセッサ」だという)
2. なぜあえてBitcoin ScriptでEVMやWASMを模倣するのか?
これは非常に面倒ではないか? その理由は、多くのビットコインLayer2プロジェクトがSolidityやMoveといった高級言語をサポートしようとする一方、ビットコインチェーン上で直接実行可能なのは、一連の特殊なオペコードからなる、非チューリング完全な簡素なプログラミング言語であるBitcoin Scriptだからである。

(Bitcoin Scriptのコード例)
もしビットコインLayer2がArbitrumのようなイーサリアムLayer2と同じように、Layer1上で詐欺証明を検証し、BTCの安全性を最大限に継承したい場合、BTCチェーン上で直接「異議のある取引」または「異議のあるオペコード」を検証する必要がある。つまり、Layer2で使用されるSolidity言語/EVMに対応するオペコードを、ビットコインチェーン上で再実行しなければならない。問題は次のように帰着する:
Bitcoin Scriptというビットコインネイティブな簡素な言語を使って、EVMや他の仮想マシンの機能を実現すること
したがって、コンパイル理論の観点からBitVMを理解すれば、それはEVM/WASM/JavaScriptのオペコードをBitcoin Scriptのオペコードに翻訳するものであり、論理ゲート回路は「EVMオペコード → Bitcoin Scriptオペコード」という変換の中間表現(IR)として機能している。
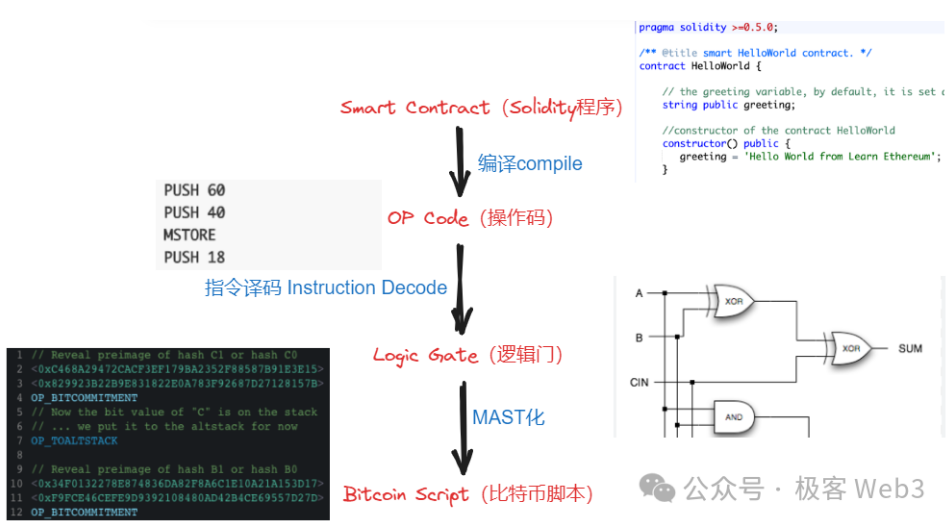
(BitVMホワイトペーパーで述べられている、ビットコインチェーン上で「異議のある命令」を実行するおおよその考え方)
いずれにせよ最終的に得られるのは、もともとEVM/WASM上でしか処理できなかった命令を、ビットコインチェーン上で直接処理できるようにするということである。この方法は理論的には可能だが、課題は、すべてのEVM/WASMオペコードを表現するために、膨大な数の論理ゲート回路を中間形態としてどう構成するか、そして極めて複雑な取引処理フローを論理ゲートの組み合わせで直接表現しようとすると、途方もない工数がかかる点である。
3.Arbitrumに酷似した「インタラクティブな詐欺証明」
次に、BitVMホワイトペーパーで言及されているもう一つの核となる概念、すなわちArbitrumに酷似した「インタラクティブな詐欺証明」について述べる。
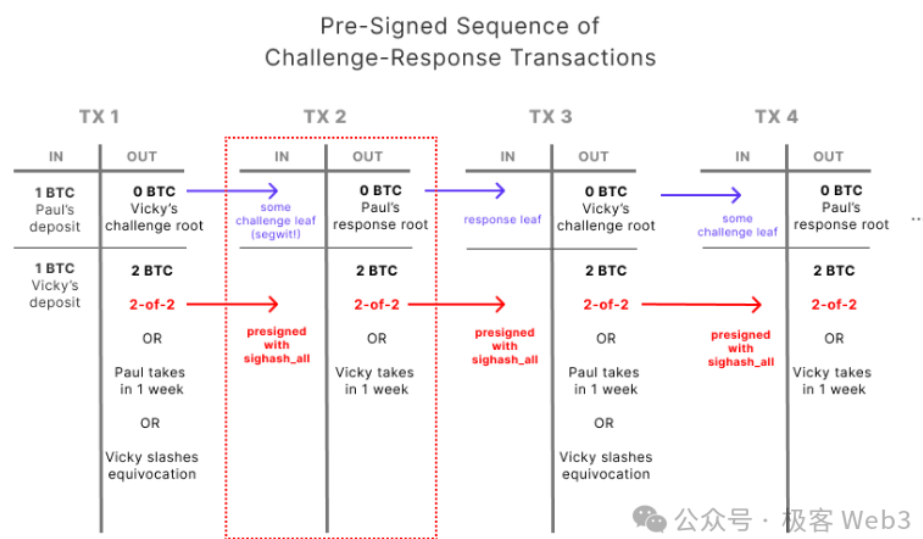
インタラクティブな詐欺証明では、「assert(アサート)」という言葉が登場する。通常、Layer2のProposer(多くはsequencerが務める)はLayer1上でアサートを発表し、特定の取引データや状態遷移結果が有効かつ正確であると主張する。
誰かがProposerが提出したアサートに問題がある(関連データが誤っている)と考えれば、争議が発生する。このとき、ProposerとChallengerは交互に情報を交換し、二分探索法によって異議のあるデータを高速に特定して、粒度の非常に細かい個別の操作命令とその関連データ断片を突き止める。
この異議のある操作命令(OP Code)については、入力パラメータとともにLayer1上で直接実行され、出力結果が検証される必要がある(Layer1ノードは自身で計算した出力結果を、Proposerが事前に発表した結果と比較する)。Arbitrumではこれを「単一ステップ詐欺証明(single-step fraud proof)」と呼んでいる。

(Arbitrumのインタラクティブ詐欺証明プロトコルでは、Proposerが発表したデータに対して二分探索を行い、異議のある命令とその実行結果を迅速に特定し、最後に単一ステップの詐欺証明をLayer1に送信して最終検証を行う)
参考資料:元ArbitrumテクニカルアンバサダーによるArbitrumのコンポーネント構造解説(前編)

(Arbitrumのインタラクティブ詐欺証明の流れ図。やや粗い説明)
ここまで来れば、「単一ステップ詐欺証明」のアイデアは明確であろう。Layer2で発生する大多数の取引命令は、BTCチェーン上で再検証する必要はない。ただし、誰かが異議を唱えた場合、その特定のデータ断片/オペコードだけをLayer1上で再実行するのである。
検証結果が以下の場合:
-
Proposerが事前に発表したデータに問題があれば、Proposerのステーク資産をスラッシュする;
-
Challengerに問題があれば、Challengerのステーク資産をスラッシュする;
-
Proverが長期間応答しない場合も、スラッシュ対象となる。
Arbitrumはイーサリアムのスマートコントラクトでこれらを実現するが、BitVMはBitcoin Scriptを使ってタイムロックやマルチシグなどの機能を実現する。
4.MASTツリーとMerkle Proof
「インタラクティブ詐欺証明」と「単一ステップ詐欺証明」について簡単に説明したところで、次にMASTツリーとMerkle Proofについて触れる。
前述の通り、BitVMでは、Layer2がチェーン外で処理する大量の取引データや膨大な論理ゲート回路を直接オンチェーンに載せることはせず、必要時のみ極小のデータ/論理ゲート回路をオンチェーンに載せる。
しかし、「もともとチェーン外にあり、今オンチェーンに載せるデータ」がでっち上げではないことを何らかの方法で証明する必要がある。これが暗号学でよく言われるCommitment(コミットメント)である。Merkle Proofはその一種である。
まずMASTツリーについて説明する。MASTツリーの正式名称はMerkelized Abstract Syntax Treesであり、コンパイラ理論におけるASTツリーをMerkle Treeに変換したものである。
では、ASTツリーとは何か? その中国語名は「抽象構文木(abstract syntax tree)」であり、簡単に言えば、複雑な命令を字句解析により基礎的な操作単位に分解し、それを木構造のデータ構造として整理したものである。

(ASTツリーの簡単な例。このASTツリーはx=2、y=x*3 といった単純な演算を、基本的なオペコード+データに分解している)
MASTツリーとは、このASTツリーをMerkle化し、Merkle Proofをサポートできるようにしたものである。Merkleツリーの利点の一つは、高い効率で「データ圧縮」ができることだ。例えば、Merkleツリー上の特定データを必要時にBTCチェーンに公開したいが、外部にそれが本当にそのツリーに存在するデータであり、「でっち上げ」ではないことを確信させたい場合、どうすればよいだろうか?
事前にMerkleツリーのRootをチェーン上に記録しておき、将来Merkle Proofを提示することで、特定データがそのRootに対応するMerkleツリー上に存在することを証明すればよい。
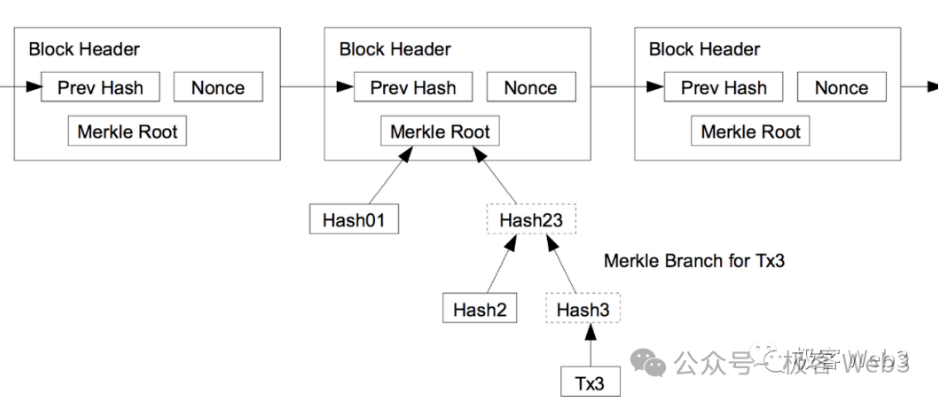
(Merkle Proof/BranchとRootの関係)
したがって、完全なMASTツリーをBTCチェーン上に保存する必要はなく、事前にそのRootを公開してCommitmentとし、必要時にデータ断片+Merkle Proof/Branchを提示すれば十分である。これにより、オンチェーンデータ量を大幅に削減しつつ、オンチェーンデータが本当にMASTツリーに属することを保証できる。また、BTCチェーン上にすべてのデータを公開するのではなく、ごく一部のデータ断片+Merkle Proofだけを公開することで、優れたプライバシー保護効果も得られる。
参考資料:データ保持拒否と詐欺証明:Plasmaがスマートコントラクトをサポートしない理由
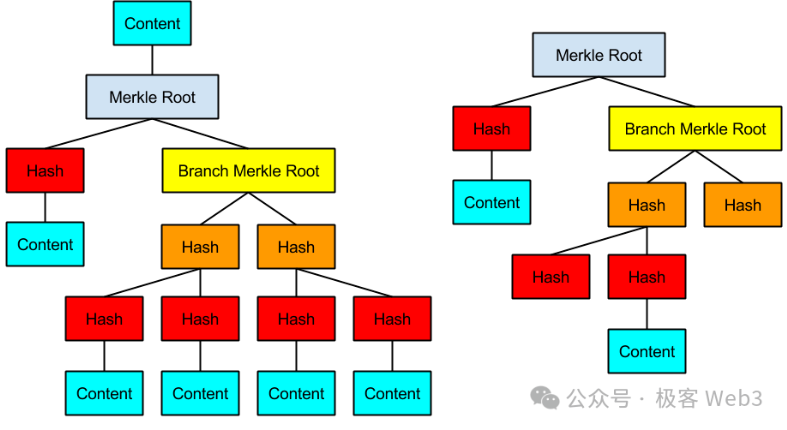
(MASTツリーの例)
BitVMのスキームでは、すべての論理ゲート回路をビットコインスクリプトで表現し、それらを巨大なMASTツリーとして構成しようとする。このツリーの最下層のリーフ(図中のContent)は、ビットコインスクリプトで実装された論理ゲート回路に対応する。
Layer2のProposerは、頻繁にBTCチェーン上にMASTツリーのRootを発表する。各MASTツリーは1つの取引に関連付けられ、そのすべての入力パラメータ/オペコード/論理ゲート回路を含む。ある意味で、これはArbitrumのProposerがイーサリアムチェーン上にRollup Blockを発表するのと類似している。
争議が発生した場合、ChallengerはBTCチェーン上で、どのRootに対して異議を唱えるかを宣言し、ProposerにそのRootに対応する特定データの開示を要求する。その後、ProposerはMerkle証明を提示し、繰り返しMASTツリーのごく一部のデータ断片をチェーン上に公開していき、最終的にChallengerと共に異議のある論理ゲート回路を特定する。その後、スラッシュ処理が行われる。
(画像出典)
5. 最後に
以上で、BitVMスキームの最も重要な部分はほぼ説明し終えた。いくつかの詳細は依然として難解かもしれないが、読者はBitVMの本質と要点を理解できたはずである。
ホワイトペーパーで言及されているbit value commitmentは、Proposerが異議申し立てを受け、チェーン上で論理ゲート回路を検証を強いられた際に、「同じ入力に対して0と1の両方を代入する」ような曖昧さや混乱を防ぐためのものである。
まとめ
BitVMのスキームは、まずBitcoin Scriptで論理ゲート回路を表現し、それを使ってEVM/他のVMのオペコードを表現し、さらに任意の取引命令の処理手順を表現し、最後にそれらをMerkle Tree/MASTツリーとして構成する。
このようなツリーが表現する取引処理手順が複雑になると、リーフ数が簡単に1億を超える可能性があるため、Commitmentが占めるブロックスペースや、詐欺証明の影響範囲をできるだけ小さく抑える必要がある。
単一ステップの詐欺証明では、オンチェーンに極小のデータと論理ゲートスクリプトだけが必要になるが、完全なMerkle Treeは長期的にチェーン外に保存され続けなければならない。なぜなら、誰かが異議を唱えたときにいつでもツリー上のデータをオンチェーンに提出できるようにするためである。
Layer2で発生するすべての取引はそれぞれ巨大なMerkle Treeを生成するため、ノードの計算・ストレージ負荷は計り知れない。そのため、多くの人はノードを運営することをためらうだろう(ただし、こうした履歴データは期限切れで削除可能であり、B^2 networkはFilecoinに類似したzkストレージ証明を導入し、ストレージノードが履歴データを長期保存するインセンティブを提供している)。
しかし、詐欺証明に基づくオプティミスティックRollupはそもそも多くのノードを必要としない。その信頼モデルは1/Nであり、N人のノードのうちたった1人が正直であれば、关键时刻に詐欺証明を発動できれば、Layer2ネットワークは安全である。
しかし、BitVMに基づくLayer2設計にはまだ多くの課題が存在する。例えば:
1)理論的には、データ圧縮をさらに進めるために、オペコードの検証を直接Layer1で行うのではなく、その処理手順をさらに圧縮してzk proofにし、Challengerがそのzk proofの検証手順に異議を唱えるようにしてもよい。これにより、オンチェーンデータ量を大幅に削減できる。しかし、具体的な開発の詳細は非常に複雑になる。
2)ProposerとChallengerはチェーン外で繰り返し相互作用を行うため、プロトコル設計や、Commitment、異議申し立てプロセスの処理フローをどう最適化するか、多くの知恵を絞る必要がある。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














