

Vitalik:Dankshardingとは一体何なのか?
TechFlow厳選深潮セレクト
Vitalik:Dankshardingとは一体何なのか?
Dankshardingはイーサリアム向けに提案された新しいシャーディング設計ですが、この技術は一体何をもたらすのでしょうか?
著者:Vitalik Buterin
Dankshardingとは何か?
Dankshardingは、イーサリアム向けに提案された新しいシャーディング設計であり、以前の設計と比較していくつかの顕著な簡素化を導入している。
2020年以降のすべての最近のイーサリアム・シャーディング提案(Dankshardingおよびそれ以前のものも含む)は、ほとんどの非イーサリアム・シャーディング提案と主に「ロールアップ中心」のロードマップという点で異なる。すなわち、イーサリアムのシャーディングはトランザクションのためのスペースを増やすのではなく、イーサリアムプロトコル自体が解釈しないデータ用のスペースを提供する。検証者は、blob(バイナリ大型オブジェクト)が利用可能であるか、つまりネットワークからダウンロードできるかどうかだけをチェックすればよい。これらのblob内のデータ領域は、高スループットのトランザクションをサポートする第2層(Layer 2)ロールアッププロトコルによって使用されると予想されている。
Dankshardingが導入する主要な革新は、料金市場の統合である。固定数のシャードを持ち、それぞれ異なるブロックとブロック提案者がいる従来型とは異なり、Dankshardingでは単一の提案者がそのスロットに入るすべてのトランザクションとすべてのデータを選択する。
この設計がバリデータに過度なシステム要件を課さないよう、我々は「提案者/ブロッカー分離(PBS)」を導入している。特殊な参加者クラスである「ブロックビルダー」がスロット取得権を入札し、提案者は最も高い有効ヘッダーを選べばよい。ブロック全体を処理するのはブロックビルダーだけであり(ここでも、分散型ブロックビルダーを実現するために第三者の分散型オラクルプロトコルを利用可能)、他のすべてのバリデータやユーザーはデータ可用性サンプリングによりブロックを非常に効率的に検証できる(ここで言う「大きな」部分はデータそのものであることに注意)。
プロトDanksharding(別名EIP-4844)とは何か?
プロトDanksharding(別名EIP-4844)は、完全なDanksharding仕様の大部分のロジックと「足場」(トランザクション形式、検証ルールなど)を実装するイーサリアム改善提案(EIP)であるが、実際にシャーディングを実装していない。プロトDankshardingの実装では、すべてのバリデータとユーザーが依然として完全なデータの可用性を直接検証しなければならない。
プロトDankshardingが導入する主な特徴は、新たなトランザクションタイプであり、「blob付きトランザクション」と呼んでいる。このトランザクションは通常のものと似ているが、blobと呼ばれる追加データを保持する点が異なる。Blobは非常に大きく(約125KB)、同等量のcalldataよりもはるかに安価である。ただし、EVMの実行ではblobデータにアクセスできない。EVMはblobへのコミットメントのみを参照できる。
バリデータとクライアントは依然として完全なblob内容をダウンロードする必要があるため、プロトDankshardingでのデータ帯域目標は1スロットあたり1MBであり、完全な16MBではない。しかし、これらのデータは既存のイーサリアム取引のガス使用量と競合しないため、依然として大きなスケーラビリティの利点がある。
なぜ全員がダウンロードするブロックに1MBのデータを追加することは許容されるが、calldataのコストを10倍安くすることはできないのか?
これは平均負荷と最悪ケース負荷の違いに関係している。現在、平均ブロックサイズは約90KBだが、理論上の最大ブロックサイズ(30Mガス全てをcall dataに使う場合)は約1.8MBである。イーサリアムネットワークは過去に最大値に近いブロックを処理したことがある。しかし、もしcalldataのガスコストを単に10倍下げた場合、平均ブロックサイズはまだ許容範囲内になるものの、最悪ケースは18MBとなり、イーサリアムネットワークにとっては大きすぎる。
現在のガス価格設定方式では、この二つの要素を分離できない。平均負荷と最悪ケース負荷の比率は、ユーザーがcalldataに他のリソースよりもどれだけ多くのガスを使うかの選択に依存しており、つまりガス価格は最悪ケースの可能性に基づいて設定されなければならないため、平均負荷がシステムが処理可能な負荷より不必要に低くなる。しかし、ガス価格設定をより明示的に多次元料金市場とするように変更すれば、平均/最悪ケース負荷の不一致を回避し、各ブロックに安全に処理可能な最大データ量に近いデータを含めることができる。プロトDankshardingとEIP-4488はまさにそれを実現しようとする試みである。

プロトDankshardingとEIP-4488の比較
EIP-4488は、同じ平均/最悪ケース負荷不一致問題に対処するための、より初期かつシンプルな試みである。EIP-4488は次の2つの簡単なルールを使用する:
Calldataのガスコストを1バイトあたり16ガスから3ガスに削減
ブロックごとに1MBの制限+トランザクションあたり追加300バイト(理論的最大値:約1.4MB)
ハード制限は、平均負荷の大幅な増加が最悪ケース負荷の増加を招かないようにする最も簡単な方法である。ガスコストの低下はロールアップの利用を大幅に促進し、平均ブロックサイズを数百KBまで拡大する可能性があるが、ハード制限は10MBの単一ブロックを含むような最悪ケースの可能性を直接阻止する。実際、最悪ケースのブロックサイズは現在よりも小さくなる(1.4MB対1.8MB)。
一方、プロトDankshardingは、より安価なデータを格納できる別のトランザクションタイプを導入し、大規模な固定サイズのblobに保存し、1ブロックあたりに含まれるblobの数を制限する。これらのblobはEVMからアクセスできず(blobへのコミットメントのみ可)、実行レイヤーではなくコンセンサスレイヤー(ビーコンチェーン)によって保存される。
EIP-4488とプロトDankshardingの主な実際的違いは、EIP-4488が今日必要な変更を最小限に抑えようとするのに対し、プロトDankshardingは今日多くの変更を行うことで、将来の完全なシャーディングへのアップグレードに必要な変更を最小限に抑える点にある。完全なシャーディング(データ可用性サンプリングなど)の実装は複雑な作業であり、プロトDanksharding後もなお複雑な作業であるが、その複雑性はコンセンサスレイヤーに内包される。一度プロトDankshardingが導入されれば、実行レイヤークライアントチーム、ロールアップ開発者、ユーザーは完全なシャーディングへの移行のためにさらなる作業を必要としない。
なお、両者の選択は排他的ではない。EIP-4488をできるだけ早く実装し、半年後にプロトDankshardingでフォローすることも可能である。
プロトDankshardingは完全なDankshardingのどの部分を実装し、残りは何が必要か?
EIP-4844からの引用:
本EIPで完了している作業は以下の通り:
・「完全なシャーディング」で必要となるものとまったく同じ形式の新しいトランザクションタイプ
・完全なシャーディングに必要なすべての実行レイヤーロジック
・完全なシャーディングに必要なすべての実行/コンセンサス間検証ロジック
・BeaconBlock検証とデータ可用性サンプリング用blobの層分離
・完全なシャーディングに必要な大部分のBeaconBlockロジック
・blob専用の自己調整型独立ガス価格
完全なシャーディングを実現するためにまだ必要な作業は以下の通り:
・2次元サンプリングを可能にするための、コンセンサスレイヤーにおけるblob_kzgsの低次元拡張
・データ可用性サンプリングの実際の実装
・単一バリデータが1スロットで32MBのデータを処理する必要がないようにするためのPBS(提案者/ブロッカー分離)
・各バリデータに対するホスティング証明または類似のプロトコル内要件で、各ブロック内のシャードデータの特定部分を検証する
なお、残りの作業はすべてコンセンサスレイヤーの変更であり、実行クライアントチーム、ユーザー、ロールアップ開発者による追加作業は不要である。
このような非常に大きなブロックはディスク容量要求を増加させるが、どう対処するのか?
EIP-4488とプロトDankshardingの両方とも、各スロット(12秒)の長期的な最大使用量を約1MBとする。これは年間約2.5TBに相当し、現在のイーサリアムの成長率をはるかに上回る。
EIP-4488の場合、この問題に対処するには履歴期限スキーム(EIP-4444)が必要で、クライアントは一定期間を超えた履歴を保存する必要がなくなる(1か月から1年程度の期間が提案されている)。
プロトDankshardingの場合、EIP-4444の実施有無に関わらず、コンセンサスレイヤーが一定期間(例:30日)後にblobデータを自動削除する個別のロジックを実装できる。ただし、短期的なデータ拡張ソリューションにかかわらず、EIP-4444の早期実施が強く推奨される。
いずれの戦略も、コンセンサスクライアントの余分なディスク負荷を数百GB以内に制限する。長期的には、何らかの履歴期限メカニズムの採用は本質的に必須である:完全なシャーディングでは年間約40TBの履歴blobデータが増加するため、ユーザーはその一部しか長期間保存できない。したがって、早い段階でその期待を定めることが重要である。
30日後にデータが削除された場合、ユーザーは古いblobにどうやってアクセスするのか?
イーサリアムコンセンサスプロトコルの目的は、すべての履歴データの永久保存を保証することではない。むしろ、非常に安全なリアルタイム掲示板を提供し、他の分散型プロトコルに長期保存の余地を残すことである。 掲示板の存在意義は、掲示板に投稿されたデータが十分な長さ利用可能であることを保証し、そのデータを欲するユーザーまたは長期プロトコルが、データを入手して他のアプリケーションやプロトコルに取り込むのに十分な時間を確保することにある。
一般に、長期履歴保存は容易である。年間2.5TBは通常ノードにとって大きすぎるが、専用ユーザーにとっては非常に管理しやすい。1TBあたり約20ドルで非常に大きなHDDを購入でき、これはアマチュアでも十分に可能である。N/2-of-N信頼モデルを持つコンセンサスとは異なり、履歴保存は1-of-N信頼モデルを持つ:データ保管者のうち1人だけが誠実であればよい。したがって、各履歴データは数千のリアルタイムコンセンサス検証ノードではなく、数百回程度の保存で十分である。
完全な履歴を保存し、簡単にアクセス可能にする実用的な方法には以下がある:
・特定アプリケーションプロトコル(例:ロールアップ)は、そのアプリケーションに関連する履歴部分をノードが保存するよう要求するかもしれない。失われた履歴データはプロトコル全体にリスクを及ぼすことはなく、個々のアプリケーションにのみリスクを及ぼすため、各アプリケーションが関連データの保存負担を持つのは妥当である。
・BitTorrentなどで履歴データを保存。例:毎日自動生成・配布される7GBのファイルにブロックのblobデータを含める。
・イーサリアムポータルネットワーク(現在開発中)を拡張して履歴を保存することが容易に可能。
・ブロックエクスプローラー、APIプロバイダー、その他のデータサービスが完全な履歴を保存するかもしれない。
・個人の愛好家やデータ分析を行う研究者が完全な履歴を保存するかもしれない。後者の場合、履歴をローカルに保存することで、直接計算を容易にする重要な価値を得られる。
・TheGraphなどのサードパーティ索引プロトコルが完全な履歴を保存するかもしれない。
より高度な履歴保存(例:年間500TB)では、一部のデータが忘れられるリスクが高くなる(さらに、データ可用性検証システムもより緊迫する)。これはシャード化ブロックチェーンのスケーラビリティの真の限界かもしれない。しかし、現在提案されているすべてのパラメータはこの点から非常に遠い。
blobデータのフォーマットは何か、またどのようにコミットされるのか?
blobは、4096個のフィールド要素からなるベクトルであり、以下の範囲の数値を持つ:
blobは数学的には、上記モジュラスを持つ有限体上の多項式として表現される
blobへのコミットメントは、その多項式のハッシュであるKZGコミットメントである。しかし、実装の観点からは、多項式の数学的詳細に注目する必要はない。むしろ、信頼できるセットアップに基づくラグランジュ形式の楕円曲線点のベクトルが存在し、blobに対するKZGコミットメントは単なる線形結合となる。EIP-4844のコードからの引用:
BLS_MODULUSは上記のモジュラスであり、KZG_SETUP_LAGRANGEは信頼できるセットアップに基づく楕円曲線点のベクトルである。実装者にとっては、これを単なる黒箱の特殊ハッシュ関数と見なすのが妥当である。
なぜKZGのハッシュを使い、直接KZGを使わないのか?
EIP-4844は、KZGを直接blob表現に使わず、バージョン付きハッシュを使用する:1バイトの0x01(このバージョンを示す)に続き、KZGのSHA256ハッシュの下位31バイト。
これはEVM互換性と将来互換性のためである:KZGコミットメントは48バイトだが、EVMは32バイト値をより自然に扱う。もし将来的にKZGから他のもの(例:量子耐性のため)に切り替える場合でも、KZGコミットメントは引き続き32バイトに保てる。
プロトDankshardingで導入される2つのプリコンパイルとは?
プロトDankshardingは2種類のプリコンパイルを導入する:blob検証プリコンパイルと点評価プリコンパイル。
blob検証プリコンパイルはそのままの意味である:バージョン付きハッシュとblobを入力として受け取り、提供されたバージョン付きハッシュがblobの有効なバージョン付きハッシュであることを検証する。このプリコンパイルはOptimistic Rollup用に設計されている。EIP-4844からの引用:
Optimistic Rollupは、詐欺証明を提出するときだけ基礎データを実際に提供する必要がある。詐欺証明提出機能は、詐欺blobの全内容をcalldataの一部として提出する。そしてblob検証機能を使って、以前に提出されたバージョン付きハッシュに対してデータを検証し、その後通常通り詐欺証明の検証を実行する。
点評価プリコンパイルは、バージョン付きハッシュ、x座標、y座標、証明(blobのKZGとKZG評価証明)を入力として受け取り、P(x) = yが成り立つかどうかを検証する。ここでPは与えられたバージョン付きハッシュを持つblobで表される多項式である。このプリコンパイルはZK Rollup用に設計されている。EIP-4844からの引用:
ZK rollupは、取引または状態増分データに対して2つのコミットメントを提供する:blob内のKZGと、ZK rollup内部で使用される任意の証明システムによるコミットメント。彼らは等価性プロトコルのコミットメント証明を用いて、点評価プリコンパイルを通じて、kzg(可用データを指すことを保証するプロトコル)とZK rollup自身のコミットメントが同じデータを参照していることを証明する。
なお、主要なOptimistic Rollupの設計のほとんどは多段階防詐欺スキームを使用しており、最終段階では少量のデータしか必要としない。そのため、Optimistic Rollupもblob検証プリコンパイルではなく点評価プリコンパイルを使用することが想像でき、しかもその方が安価である。
KZG信頼できるセットアップとはどのようなものか?
参照:
https://vitalik.ca/general/2022/03/14/trustedsetup.html
powers-of-tau信頼できるセットアップの一般的な説明
https://github.com/ethereum/research/blob/master/trusted_setup/trusted_setup.py
すべての重要な信頼できるセットアップ関連計算のサンプル実装
特に私たちのケースでは、現在の計画は4つのサイズ(n1=4096,n2=16)、(n1=8192,n2=16)、(n1=16834,n2=16)および(n1=32768,n2=16)の儀式を並列に実行することである(異なるシークレットを持つ)。理論的には最初の一つだけでよいが、より大きなサイズの儀式を実行することで将来の適用性を高め、blobサイズを増加させられる。ただ大きなセットアップだけにするわけにはいかない。それは、有効にコミットできる多項式の次数に硬制限を設ける必要があり、それがblobサイズに等しくなければならないためである。
実用的なアプローチとしては、Filecoinのセットアップから始め、それを拡張する儀式を実行することが考えられる。ブラウザ実装を含む複数の実装により、多くの人々が参加できるようになる。
信頼できるセットアップなしで他のコミットメント方式を使えないのか?
残念ながら、KZG以外のもの(例:IPAやSHA256)を使用すると、シャーディングロードマップがさらに困難になる。これにはいくつかの理由がある:
非算術コミットメント(例:ハッシュ関数)はデータ可用性サンプリングと互換性がないため、そのような方式を使用すると、完全なシャーディングに移行する際に結局KZGに変更しなければならなくなる。
IPAはデータ可用性サンプリングと互換性があるかもしれないが、それによりより複雑な方式になり、属性が弱くなる(例:自己修復や分散型ブロック構築が難しくなる)
ハッシュおよびIPAのどちらも、点評価プリコンパイルの安価な実装と互換性がない。したがって、ハッシュまたはIPAに基づく実装は、ZK Rollupを効率的にサポートしたり、多段階Optimistic Rollupでの安価な詐欺証明をサポートできない。
したがって、残念ながら、KZG以外のものを使用することで生じる機能損失と複雑性の増加は、KZG自体のリスクをはるかに上回る。また、KZGに関連するリスクは限定的である:KZGの故障はロールアップやblobデータに依存する他のアプリケーションにのみ影響し、システムの他の部分には影響しない。
KZGはどれほど「複雑」で「新規」なのか?
KZGコミットメントは2010年の論文で紹介され、2019年以降PLONK型ZK-SNARKプロトコルで広く使用されてきた。しかし、KZGコミットメントの基盤となる数学は、楕円曲線演算とペアリングの基礎の上に構築された比較的単純な算術である。
使用される特定の曲線はBLS12-381であり、Barreto-Lynn-Scottによって2002年に考案された。KZGコミットメントの検証に必要な楕円曲線ペアリングは非常に複雑な数学であるが、1940年代に発明され、1990年代以降暗号学に応用されてきた。2001年までに、ペアリングを使用する多くの暗号アルゴリズムが提案されていた。
実装の複雑性の観点から見ると、KZGはIPAよりも難しいわけではない:コミットメントの計算関数(上記参照)はIPAの場合とまったく同じであり、異なるのは楕円曲線点の定数セットだけである。点評価プリコンパイルの検証はペアリング評価を含むためより複雑だが、その数学はEIP-2537(BLS12-381プリコンパイル)実装です already done 部分と同じであり、bn128ペアリングプリコンパイルとも非常に類似している(参考:最適化されたPython実装)。したがって、KZG検証の実装には複雑な「新規作業」は不要である。
プロトDanksharding実装の異なるソフトウェア部品は何か?
主に4つの構成要素がある:
1. 実行レイヤーのコンセンサス変更(EIP詳細参照):
blobを含む新しいトランザクションタイプ
現在のトランザクション中のi番目のblobバージョン付きハッシュを出力するオペコード
blob検証プリコンパイル
点評価プリコンパイル
2. コンセンサスレイヤーのコンセンサス変更(リポジトリ内のこのフォルダ参照):
BeaconBlockBody内のblob KZGリスト
完全なblob内容がBeaconBlockとは別オブジェクトとして渡される「サイドカー」機構
実行レイヤーのblobバージョン付きハッシュとコンセンサスレイヤーのblob KZG間のクロスチェック
3. メモリプール
BlobTransactionNetworkWrapper(EIPのネットワークセクション参照)
大きなblobサイズを補うための強化されたDoS保護
4. ブロック構築ロジック
メモリプールからのトランザクションラッパーを受け取り、ExecutionPayloadにトランザクションを入れ、KZGをビーコンブロック本体とサイドカーに配置
二次元料金市場への対応
最小実装では、メモリプールは全く不要(第2層取引バンドル市場に依存可能)であり、ブロック構築ロジックは1クライアントだけ実装すればよい。実行レイヤーとコンセンサスレイヤーのコンセンサス変更だけが広範なコンセンサステストを必要とし、比較的軽量である。このような最小実装と、すべてのクライアントがブロック生成とメモリプールをサポートする「完全」展開の間のあらゆる段階が可能である。
プロトDankshardingの多次元料金市場とは?
プロトDankshardingは、ガスとblobという2つのリソースを持つ、それぞれ独立したフロートガス価格と独立した制限を持つ多次元EIP-1559料金市場を導入する。
つまり、2つの変数と4つの定数がある:

blob料金はガスで徴収されるが、可変量のガスであり、長期的には各ブロックの平均blob数が実際に目標値と等しくなるように調整される。
2次元性のため、ブロック構築者はより難しい問題に直面する:単に最高優先順位料金の取引から順に受け入れていき、取引が尽きるかガス上限に達するまで続けるのではなく、2つの異なる制限を同時に超えないようにしなければならない。
例:ガス制限70、blob制限40。メモリプールにはブロックを満たすのに十分な取引があり、2種類ある(tx gasにはper-blob gasを含む):
優先料金5/gas、4 blob、合計4 gas
優先料金3/gas、1 blob、合計2 gas
単純な「優先料金降順」アルゴリズムに従うマイナーは、最初のタイプの取引10件(40 gas)でブロック全体を埋め、5 * 40 = 200 gasの収益を得る。この10件の取引でblob上限が完全に埋まるため、これ以上取引を含められない。しかし最適戦略は、最初のタイプを3件、2番目のタイプを28件取ることである。これにより、40 blobと68 gasのブロックができ、収益は5 * 12 + 3 * 56 = 228となる。

実行クライアントは、ブロック生成の最適化のために複雑な多次元ナップサック問題アルゴリズムを実装する必要があるのか?答えは「いいえ」であり、理由はいくつかある:
EIP-1559により、ほとんどのブロックはいずれの制限にも達しないので、実際には少数のブロックだけが多次元最適化問題に直面する。メモリプールに制限に達するのに十分な(支払い済み)取引がない通常の状況では、マイナーは見えるすべての取引を含めることで最適収益を得られる。
実際には、非常に単純なヒューリスティックでほぼ最適に近づける。同様の状況については、AnsgarのEIP-4488分析を参照。
多次元価格設定は、専門化による最大収益源 even not—MEV である。チェーン上のDEX Arbitrage、清算、NFT販売の先行取りなどから抽出される専用MEV収益は、「抽出可能収益」(=優先料金)総額の大部分を占める:専用MEV収益は平均してブロックあたり約0.025 ETH、総優先料金は通常ブロックあたり0.1 ETH前後である。
提案者/ビルダー分離(PBS)は、高度に専門化されたブロック生成を念頭に設計されている。PBSはブロック構築プロセスをオークションに変え、専門参加者がブロック作成特権を入札する。通常のバリデータは最高入札を受け入れるだけでよい。これはMEV駆動の規模の経済がバリデータの中央集権化に波及するのを防ぐためであり、ブロック構築の最適化をより困難にするすべての問題を処理する。
これらの理由から、より複雑な料金市場ダイナミクスは、中央集権化やリスクを大きく増加させることはない。事実、広く適用される原則はDoS攻撃リスクを実際に低下させる可能性さえある!
指数型EIP-1559 blob料金調整メカニズムの仕組み
現在のEIP-1559は、特定の目標gas使用量tを達成するために基本料金bを調整する:

ここでb(n)は現在のブロックの基本料金、b(n+1)は次のブロックの基本料金、tは目標、uは使用されたgasである。
このメカニズムの大きな問題は、実際にはtをターゲットにしていないことである。最初のブロックu=0、次のブロックu=2tだと仮定する。すると:

平均使用量がtに等しいにもかかわらず、基本料金は63/64に低下する。つまり、使用率がtよりわずかに高いときにだけ基本料金が安定する;実際には明らかに約3%高いが、正確な数値は分散に依存する。
より良い式は指数調整である:
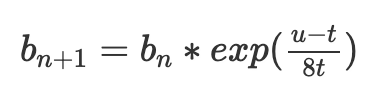
exp(x)は指数関数e^xであり、e≈2.71828。xが小さい場合、exp(x)≈1+x。しかし、取引の順序に依存しない便利な特性を持つ:複数ステップの調整
は合計u1+...+u/nにのみ依存し、分布には依存しない。その理由は数学的に説明できる:
したがって、同じ取引が含まれていれば、それらが異なるブロック間にどのように分配されていても、最終的な基本料金は同じになる。
最後の式には自然な数学的解釈もある:(u1+u2+...+u/n−nt)という項は超過分と見なせる:実際に使用された総gasと意図された総gasの差異である。
現在の基本料金が
という事実は、超過分が非常に狭い範囲にしか収まらないことを明確に示している:もし8t∗60を超えると、basefeeはe^60となり、あまりに高すぎて誰も支払えず、もし0を下回るとリソースは基本的に無料となり、チェーンはスパムで溢れて超過分が再び0以上に戻るまで続く。
調整メカニズムはまさにこれらの項に従って動作する:実際の合計(u1+u2+...+u/n)を追跡し、目標合計(nt)を計算し、その差異の指数として価格を算出する。計算を簡単にするため、e^xではなく2^xを使用する。実際には2^xの近似値であるEIPのfake_exponential関数を使用する。偽指数はほぼ常に実際の値の0.3%以内である。
長期間の未使用が長期間の2倍完全ブロックを招かないよう、追加機能を追加する:超過分をゼロ以下にしない。actual_totalがtargeted_totalを下回った場合、actual_totalをtargeted_totalに等しく設定する。極端な場合(blob gasがゼロまで下落)には、確かに取引順序の不変性が破られるが、得られる安全性向上が許容できる妥協である。また、この多次元市場の興味深い結果として、プロトDanksharding導入当初はユーザーが少ないため、しばらくの間、blobのコストは非常に安くなり、通常のイーサリアムブロックチェーン活動が依然として高価であってもそうなるだろう。
筆者はこの料金調整メカニズムが現在の方法より優れていると考えており、最終的にはEIP-1559料金市場のすべての部分がこれに移行すべきだと考える。
より長く詳細な説明は、Dankradの投稿を参照。
fake_exponentialの仕組み
便宜上、fake_exponentialのコードを以下に示す:
四捨五入を取り除き、数学的に再表現したコアメカニズムは以下の通り:
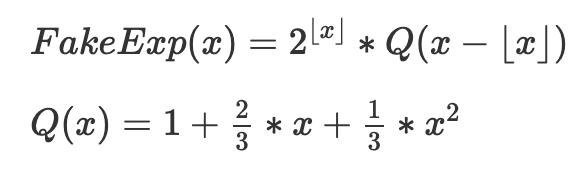
目的は、[2^k,2^(k+1)]の各範囲に適切に移動・拡大された(QX)の多数のインスタンスを接続することである。Q(x)自体は0≤x≤1における2^xの近似であり、以下の特性を持つように選ばれている:
・単純性(二次方程式)
・左端での正確性(Q(0)=2^0=1)
・右端での正確性(Q(1)=2^1=2)
・滑らかな勾配(Q'(1)=2*Q'(0)を保証し、Qの各シフト+スケールコピーの右端の勾配が次のコピーの左端の勾配と同じになるようにする)
最後の3条件は3つの未知係数についての3つの方程式を与え、上記のQ(x)が唯一の解である。
近似は驚くほど良好で、最小入力を除くすべての入力に対して、fake_exponentialの出力は2^xの実際値の0.3%以内である:

プロトDankshardingで議論中の問題は何か?
注意:このセクションはすぐに古くなる可能性がある。特定の問題について最新の考え方を提供するものではない。
すべての主要なOptimistic Rollupは多段階証明を使用しており、そのため(はるかに安い)点評価プリコンパイルをblob検証プリコンパイルの代わりに使用できる。blob検証を本当に必要とする人は自分で実装できる:blob Dとバージョン付きハッシュhを入力として、x=hash(D,h)を選び、重心評価でy=D(x)を計算し、点評価プリコンパイルでh(x)=yを検証する。したがって、blob検証プリコンパイルは本当に必要か?あるいは単に削除して点評価だけにすべきか?
このチェーンが持続的な長期的な1MB以上のブロックを処理する能力はどうか?リスクが大きすぎる場合、最初から目標blob数を減らすべきか?
blobはガスで価格設定すべきかETH(燃焼)で価格設定すべきか?料金市場に他の調整は必要か?
新しいトランザクションタイプをblobとして扱うべきか、それともSSZオブジェクトとして扱い、後者の場合ExecutionPayloadをユニオン型に変更すべきか?(これは「今もっと作業する」対「後でもっと作業する」のトレードオフである)
信頼できるセットアップ実装の正確な詳細(技術的にはEIP自体の範囲外、実装者にとっては「ただの定数」だが、それでも完了する必要がある)。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














