

« Taxe chinoise » des grands modèles d’IA : pourquoi le chinois consomme-t-il plus de jetons que l’anglais ?
TechFlow SélectionTechFlow Sélection
« Taxe chinoise » des grands modèles d’IA : pourquoi le chinois consomme-t-il plus de jetons que l’anglais ?
Lorsque les ingénieurs aplanissent les aspérités des langues pour gagner en efficacité, la sagesse qui y germe involontairement dans les interstices disparaît également en silence.
Peu de temps après la sortie d’Opus 4.7, les réseaux sociaux, notamment X, se sont emplis de plaintes. Certains utilisateurs ont indiqué qu’une seule conversation avait épuisé leur quota de sessions ; d’autres ont constaté que le coût d’exécution du même code avait plus que doublé par rapport à la semaine précédente ; d’autres encore ont partagé des captures d’écran montrant que leur abonnement Max de 200 dollars avait atteint sa limite en moins de deux heures.
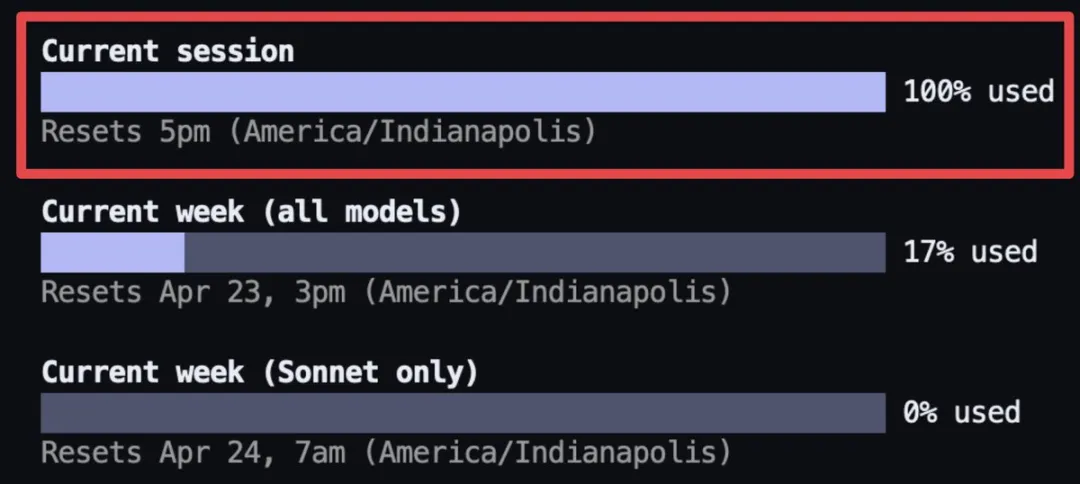
Le développeur indépendant BridgeMind reconnaît que Claude est le meilleur modèle au monde, mais aussi le plus coûteux. Son abonnement Max a atteint sa limite en moins de deux heures — heureusement, il en a souscrit deux. | Source de l’image : X@bridgemindai
Les tarifs officiels d’Anthropic n’ont pas changé : 5 dollars par million de tokens d’entrée, 25 dollars par million de tokens de sortie. Toutefois, cette version introduit un nouveau tokenizer et Claude Code a augmenté par défaut le niveau d’« effort » de « high » à « xhigh ». Ces deux changements combinés font que le nombre de tokens consommés pour une même tâche est désormais multiplié par un facteur compris entre 2 et 2,7.
Dans ces discussions, j’ai relevé deux affirmations liées à la langue chinoise. La première est la suivante : sous le nouveau tokenizer, la consommation de tokens pour le chinois a quasiment pas augmenté, ce qui signifierait que les utilisateurs chinois auraient échappé à cette hausse de prix. La seconde, plus surprenante encore, affirme que les textes classiques chinois (wenyan) consomment moins de tokens que le chinois moderne, si bien qu’il serait possible de réduire les coûts en dialoguant avec l’IA en classique.
La première affirmation suggère qu’Anthropic aurait effectué une quelconque optimisation spécifique pour le chinois, or aucun ajustement lié au chinois n’est mentionné dans la documentation officielle de la mise à jour.
La seconde affirmation est encore plus difficile à expliquer. Pour un lecteur humain, le classique est manifestement plus ardu que le chinois moderne ; comment un texte plus complexe pour l’humain pourrait-il être plus « facile » pour l’IA ?
J’ai donc mené un test : j’ai soumis 22 textes parallèles (incluant des actualités commerciales, des documents techniques, des textes classiques et des dialogues quotidiens) à cinq tokenizers différents (Claude 4.6 et 4.7, GPT-4o, Qwen 3.6, DeepSeek-V3), puis j’ai comparé le nombre de tokens requis pour chaque texte dans chacun des modèles.

Textes testés :
1. Dialogues quotidiens en chinois et en anglais (voyages, demandes d’aide sur des forums, demandes de rédaction)
2. Documents techniques en chinois et en anglais (documentation Python, documentation Anthropic)
3. Actualités en chinois et en anglais (actualités politiques et économiques du NYT, communiqués officiels d’Apple)
4. Extraits littéraires en chinois classique et en anglais (« Memorial of Departure for the Northern Expedition », « Tao Te Ching »)
Une fois le test terminé, les deux affirmations ont été partiellement validées, mais la réalité s’avère plus nuancée que les rumeurs.
L’« impôt chinois »
Voici d’abord les conclusions :
1. Sur Claude et GPT, le chinois coûte systématiquement plus cher que l’anglais.
2. Sur Qwen et DeepSeek, le chinois coûte au contraire moins cher que l’anglais.
3. La mise à jour du tokenizer à l’origine des remous provoqués par Opus 4.7 a entraîné une inflation quasi exclusive de la consommation de tokens en anglais ; le chinois, lui, reste stable.
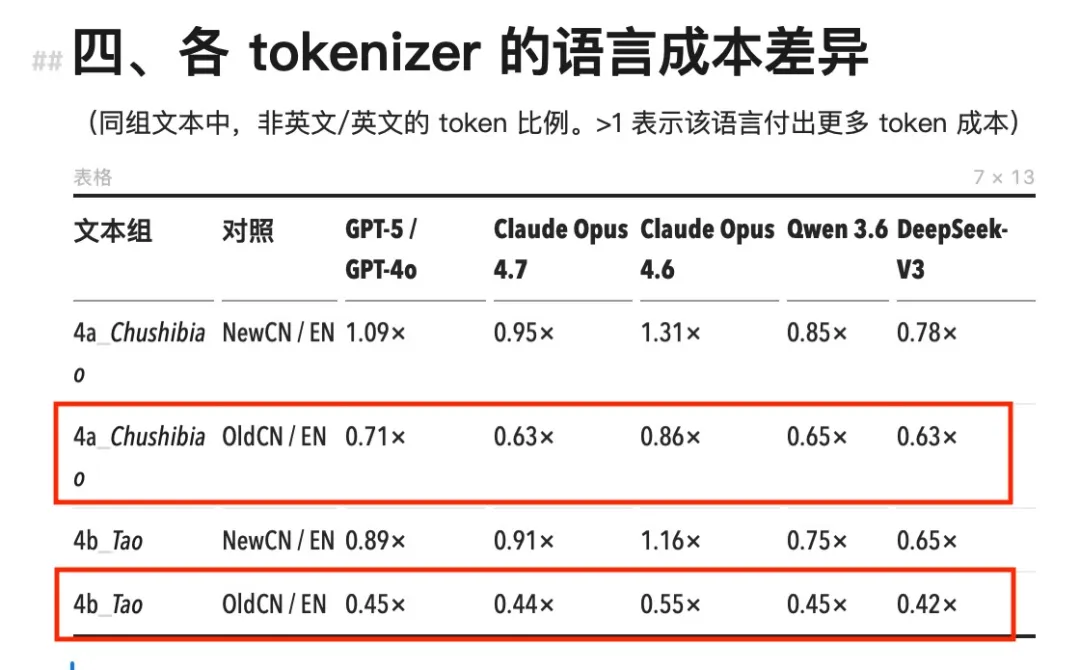
Examinons les chiffres précis. Toute la série de modèles Claude antérieure à Opus 4.7 (y compris Opus 4.6, Sonnet et Haiku) utilise le même tokenizer. Avec ce tokenizer, la consommation de tokens pour le chinois dépasse systématiquement celle de contenus anglais équivalents, avec un ratio chinois/anglais variant entre 1,11× et 1,64×.
Le cas le plus extrême apparaît dans les actualités économiques au style du NYT : pour un même passage, la version chinoise nécessite 64 % de tokens supplémentaires, soit un surcoût de 64 %.
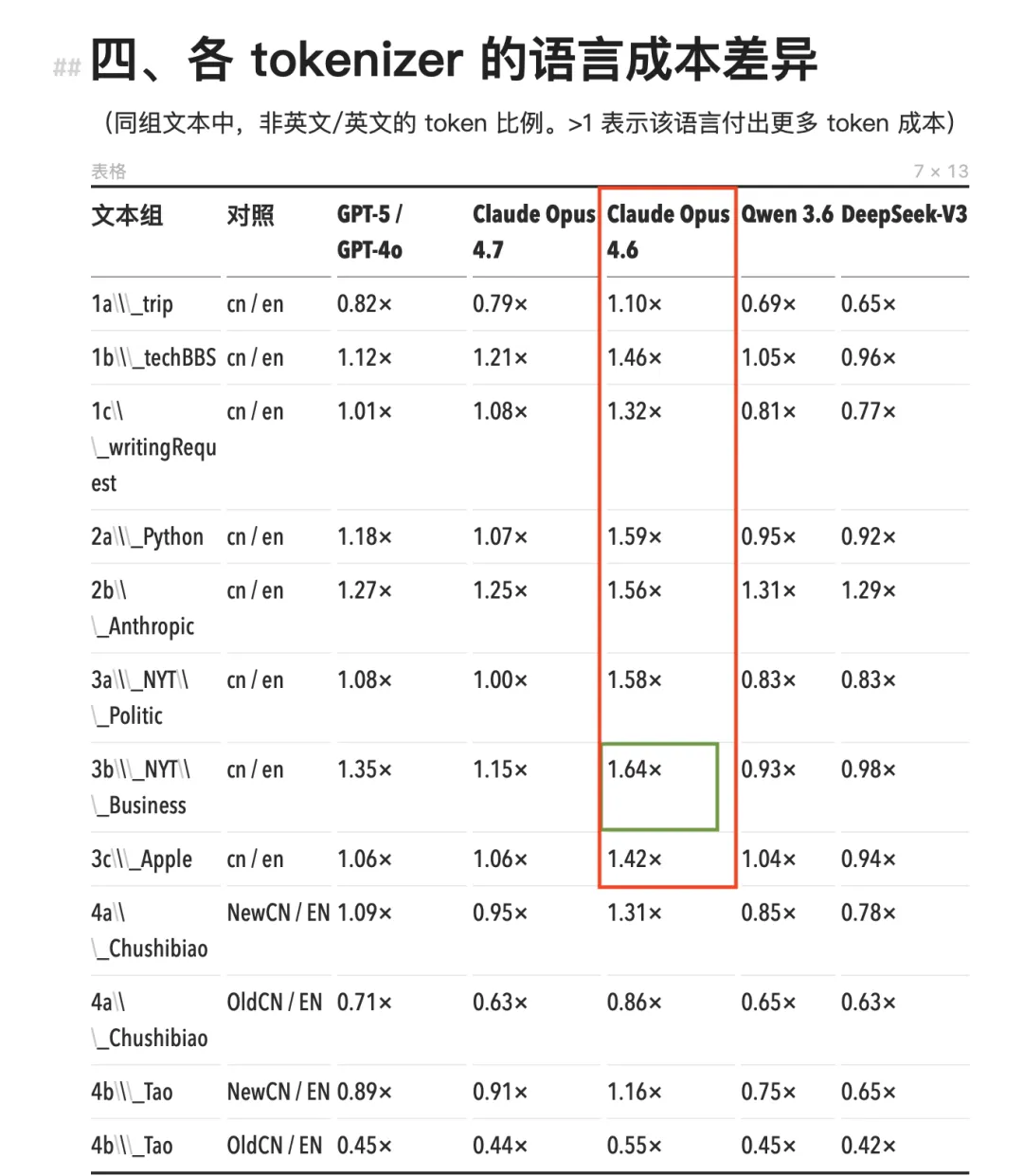
Sur les modèles Claude antérieurs à Opus 4.6 (encadré rouge), la consommation de tokens en chinois est nettement supérieure à celle des autres modèles.
Le cas le plus extrême apparaît dans les actualités économiques au style du NYT : la version chinoise consomme 64 % de tokens supplémentaires (encadré vert).
Le tokenizer o200k de GPT-4o est plus performant : le ratio chinois/anglais se situe majoritairement entre 1,0× et 1,35×, et dans certains cas il tombe même en dessous de 1. Le chinois reste globalement plus coûteux, mais l’écart est nettement moindre que sur Claude.
Pour les modèles chinois Qwen 3.6 et DeepSeek-V3, les données sont inversées. Leur ratio chinois/anglais est largement inférieur à 1, ce qui signifie que, pour un contenu identique, la version chinoise consomme moins de tokens que la version anglaise. DeepSeek atteint même un ratio minimal de 0,65× : la version chinoise coûte ainsi un tiers de moins que la version anglaise.
L’inflation induite par le nouveau tokenizer d’Opus 4.7 touche presque exclusivement l’anglais. Le nombre de tokens anglais augmente de 1,24× à 1,63×, tandis que le chinois reste globalement stable à 1,000×, sans variation notable. Les chocs subis par les factures des développeurs anglophones, mentionnés initialement, n’ont effectivement pas été ressentis par les utilisateurs chinois. Cela s’expliquerait par le fait que, dans la version précédente, les caractères chinois étaient déjà segmentés à l’échelle du caractère individuel, laissant très peu de marge pour une segmentation plus fine.
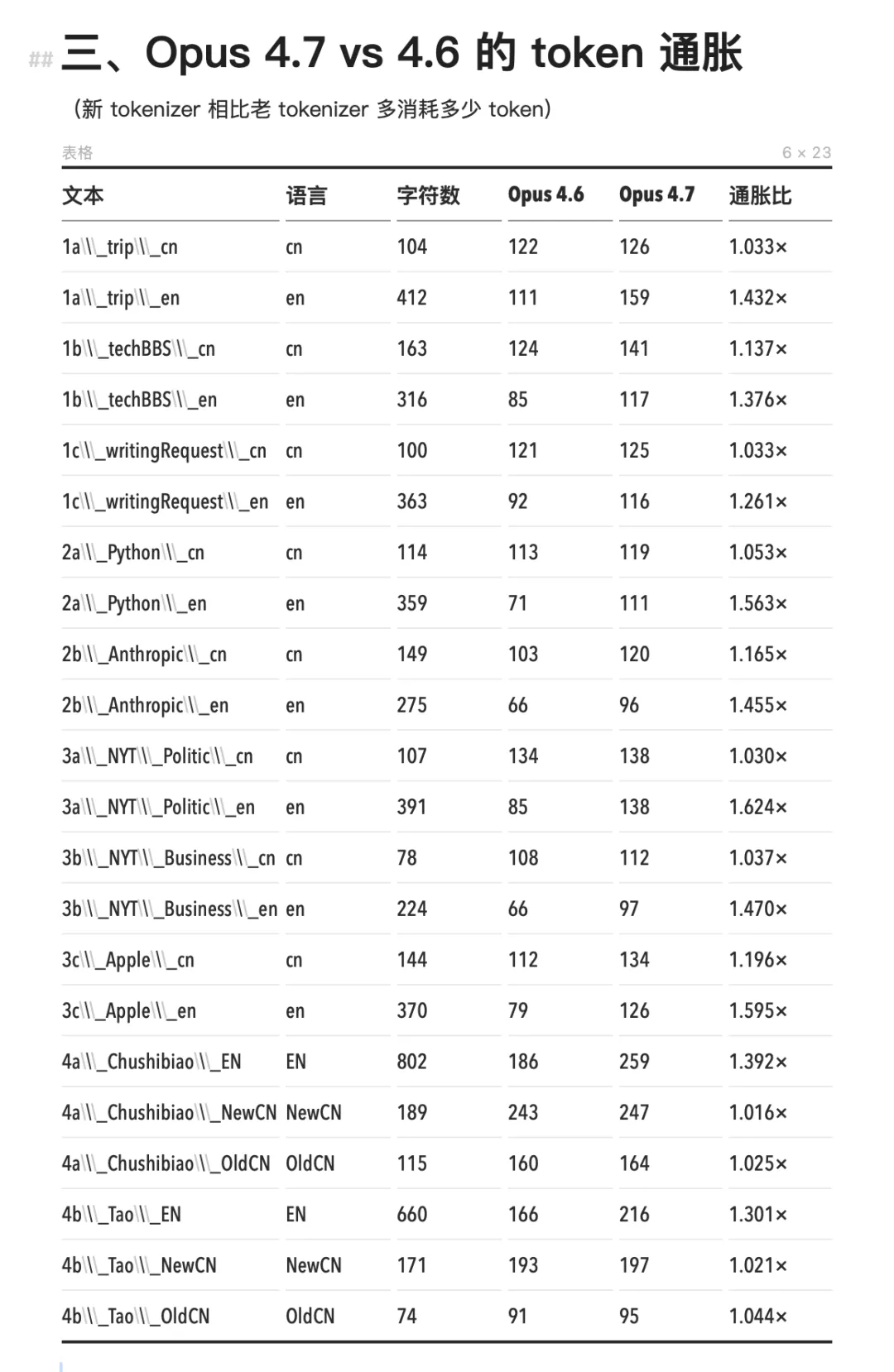
Comparaison Opus 4.7 / Opus 4.6 : la consommation de tokens augmente pour l’anglais, mais reste inchangée pour le chinois.
Au cours des tests, j’ai également remarqué un autre point : la différence de consommation de tokens ne concerne pas uniquement les factures, elle affecte directement la taille de l’espace de travail. Dans une fenêtre de contexte identique de 200 k tokens, la quantité de documents chinois pouvant être chargés avec l’ancien tokenizer Claude est inférieure de 40 % à 70 % par rapport à la quantité de documents anglais.
Pour une même tâche — par exemple faire analyser un long document ou résumer une série de comptes rendus de réunion — les utilisateurs chinois peuvent fournir moins de matériel au modèle, et celui-ci dispose donc d’un contexte plus limité. Résultat : ils paient davantage, mais disposent d’un espace de travail plus restreint.
En confrontant ces quatre séries de données, une question surgit naturellement :
Pourquoi, pour un même texte, le nombre de tokens varie-t-il selon la langue ? Et pourquoi le chinois est-il plus coûteux sur Claude et GPT, alors qu’il est moins coûteux sur Qwen et DeepSeek ?
La réponse réside dans le concept, mentionné à plusieurs reprises ci-dessus, de « tokenizer » (segmenteur).
Un caractère chinois peut-il être découpé en plusieurs morceaux ?
Avant de traiter tout texte, un modèle le découpe en tokens via un tokenizer. Vous pouvez imaginer le tokenizer comme une « machine à découper des briques de construction » pour l’IA. Vous entrez une phrase, et il la divise en blocs normalisés (les tokens). Le modèle ne « lit » pas les mots : il ne reconnaît que les numéros des briques. Plus vous utilisez de briques, plus vous payez.
La segmentation de l’anglais suit une logique intuitive : « intelligence » constitue généralement un seul token, tout comme « information » — un mot correspond à une unité facturable.

Mais avec le chinois, ce raisonnement s’effondre. Si l’on soumet la même phrase — « L’intelligence artificielle redéfinit les infrastructures mondiales de l’information » — au tokenizer cl100k de GPT-4 et au tokenizer de Qwen 2.5, les résultats de segmentation sont radicalement différents.
GPT-4 segmente essentiellement chaque caractère chinois en un token distinct ; Qwen, lui, identifie les mots entiers comme un seul token — par exemple, les quatre caractères « 人工智能 » (intelligence artificielle) ne représentent qu’un seul token chez Qwen.
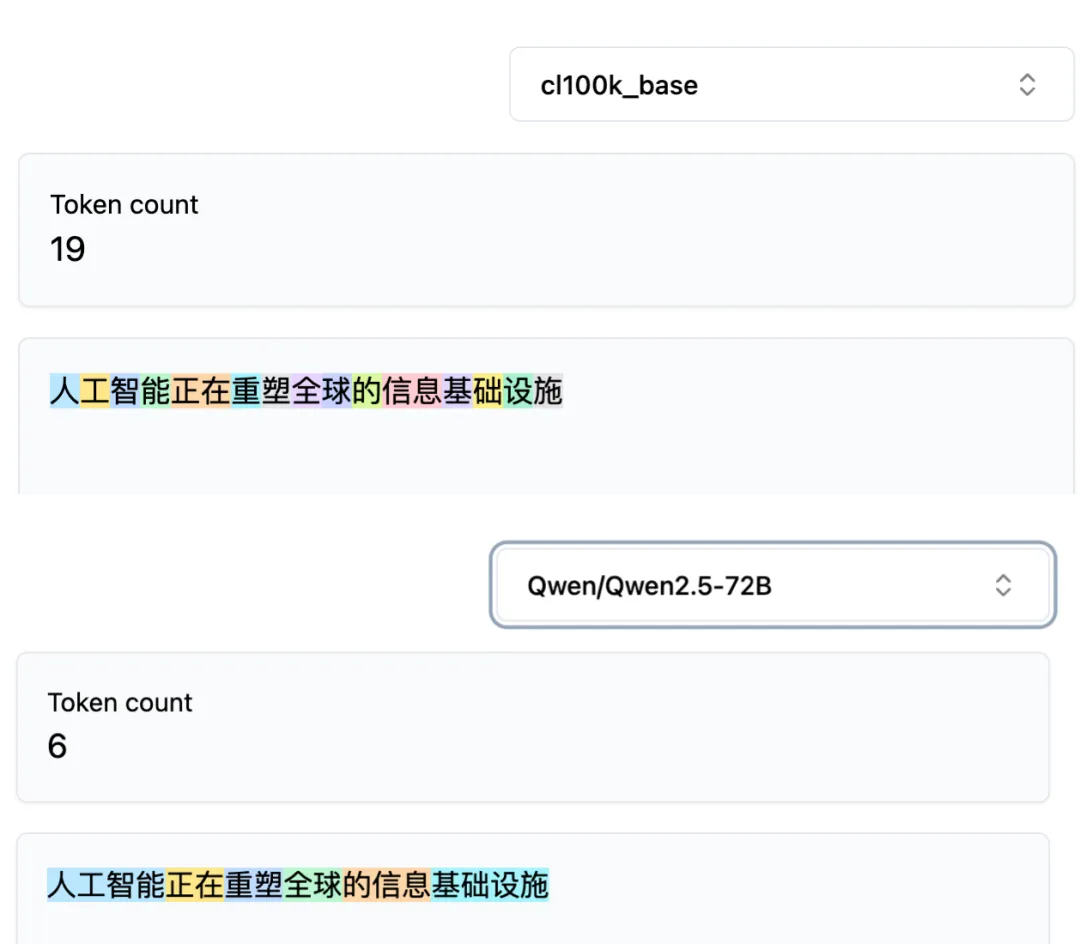
La même phrase de 16 caractères chinois produit 19 tokens chez GPT-4, mais seulement 6 chez Qwen.
Pourquoi une telle différence ? La raison réside dans un algorithme appelé BPE (Byte Pair Encoding, codage par paires d’octets).
Le BPE fonctionne en identifiant, dans le corpus d’entraînement, les combinaisons de caractères les plus fréquentes, puis en fusionnant ces combinaisons fréquentes en un seul token intégré dans le vocabulaire.
À l’époque de GPT-2, la quasi-totalité du corpus d’entraînement était constituée de textes anglais. Les combinaisons de lettres anglaises (« th », « ing », « tion ») apparaissaient très fréquemment et furent rapidement fusionnées en tokens. En revanche, les caractères chinois, trop peu présents dans ce corpus, n’ont pas pu accéder au vocabulaire, et ont donc été traités comme des octets bruts : un caractère chinois, codé en UTF-8 sur trois octets, produisait alors trois tokens.

Le BPE détermine les fusions selon la fréquence des combinaisons dans le corpus d’entraînement. Sous la domination du corpus anglais, les octets UTF-8 des caractères chinois ne peuvent pas être fusionnés en un caractère entier.
Plus tard, avec le vocabulaire cl100k de GPT-4, ce dernier s’est élargi et les caractères chinois courants ont commencé à y être intégrés, réduisant généralement chaque caractère à 1 ou 2 tokens — mais l’efficacité globale demeure inférieure à celle de l’anglais.
Avec le vocabulaire o200k de GPT-4o, l’efficacité pour le chinois progresse encore. Cela explique pourquoi, dans les données de la première section, le ratio chinois/anglais de GPT-4o est inférieur à celui de Claude.
Qwen et DeepSeek, en tant que modèles chinois, ont dès le départ intégré massivement des caractères chinois courants et des groupes lexicaux fréquents dans leur vocabulaire, en tant qu’unités complètes (caractères ou mots entiers). Un caractère = un token : l’efficacité double, voire plus.

Schéma illustratif de la segmentation d’une même phrase par différents tokenizers.
C’est pourquoi leur ratio chinois/anglais peut descendre en dessous de 1 : la densité d’information intrinsèque d’un caractère chinois dépasse celle d’un mot anglais, et lorsque le tokenizer cesse de fragmenter artificiellement les caractères chinois, cet avantage naturel s’exprime pleinement.
Ainsi, les différences observées dans les quatre séries de données de la section précédente ne tiennent pas aux capacités des modèles, mais à la place accordée au chinois dans le vocabulaire du tokenizer.
Le vocabulaire de Claude et des premières versions de GPT a été construit par défaut autour de l’anglais ; le chinois y a été « inséré » ultérieurement. Celui de Qwen et DeepSeek, en revanche, a été conçu dès l’origine avec le chinois comme langue principale. Cette différence fondamentale se propage ensuite jusqu’au nombre de tokens, aux factures et à la taille effective de la fenêtre de contexte.
Le classique est-il vraiment moins coûteux ?
Revenons sur la deuxième rumeur citée initialement : le classique serait plus économique en tokens que le chinois moderne.
Les données confirment cette affirmation. Dans nos tests, les échantillons classiques présentent un ratio chinois/anglais systématiquement inférieur à 1, et ce, sur les cinq tokenizers testés. La version classique d’un même texte consomme moins de tokens que sa traduction anglaise.
Sur tous les modèles, le classique consomme moins de tokens que le chinois moderne — et même moins que l’anglais.
La raison est simple : le classique est extrêmement concis. « 学而不思则罔,思而不学则殆 » compte 12 caractères. Sa traduction en chinois moderne est : « Si l’on apprend sans réfléchir, on s’égare ; si l’on réfléchit sans apprendre, on tombe dans l’impasse », soit un doublement du nombre de caractères — et donc une augmentation proportionnelle du nombre de tokens.
En outre, les caractères classiques les plus courants (« 之 », « 也 », « 者 », « 而 », « 不 ») sont des caractères très fréquents, dotés de positions autonomes dans le vocabulaire de tout tokenizer, sans être fragmentés en octets. Le classique est donc effectivement efficace au niveau du codage.
Mais ici se cache un piège.
Le gain en tokens du classique se situe au niveau du codage, mais la charge de raisonnement du modèle n’en est pas allégée pour autant. Le caractère unique « 罔 » exige du modèle qu’il détermine, dans ce contexte précis, s’il signifie « s’égarer », « être trompé » ou « ne pas ». Le chinois moderne peut exprimer cette nuance en 26 caractères, tandis que le classique la condense, reportant ainsi la charge cognitive sur le modèle. Autre analogie : un fichier compressé en ZIP occupe moins d’espace, mais demande plus de calcul pour être décompressé.
On gagne en tokens, mais la charge de raisonnement augmente — et la précision de compréhension diminue. Ce calcul ne tient pas la route.
Cet exemple du classique m’a permis de réaliser que le nombre de tokens, en soi, ne dit pas grand-chose. Mais en creusant cette piste, j’ai identifié une couche que j’avais jusque-là négligée.
Comme mentionné plus haut, le tokenizer de GPT-2 découpait le caractère « 人 » en trois tokens octets UTF-8 ; le vocabulaire élargi de GPT-4 a fait passer chaque caractère courant à un token unique ; Qwen va encore plus loin, en fusionnant les quatre caractères « 人工智能 » en un seul token.
Intuitivement, cela semble une amélioration continue : plus on fusionne, plus l’efficacité augmente, et mieux le modèle devrait comprendre.
Mais est-ce vraiment le cas ? Rappelons-nous comment nous apprenons à lire les caractères chinois.
Le chinois est une écriture idéographique. Plus de 80 % des caractères modernes sont des « caractères phonétiques » (xingshengzi), composés d’un élément sémantique (radical) et d’un élément phonétique. Les caractères comportant le radical « 氵 » (eau) ont souvent un lien avec les liquides, ceux portant le radical « 木 » (arbre) évoquent souvent les plantes, ceux avec « 火 » (feu) renvoient souvent à la chaleur. Les radicaux constituent la première piste sémantique fondamentale pour la lecture humaine : face à un caractère inconnu tel que « 焱 », une personne voyant trois fois le radical « 火 » peut deviner qu’il s’agit d’un concept lié au feu.
Puisque les radicaux constituent la piste sémantique fondamentale de la lecture humaine, celle-ci procède d’abord par inférence structurale du domaine sémantique, avant d’affiner la compréhension grâce au contexte.

« Huǒhuā » (étincelle), « huǒyàn » (flamme), « guāngyàn » (lueur) : fréquents en langue écrite et dans les prénoms, symbolisant la lumière et la chaleur.
Or, dans le vocabulaire du tokenizer, le caractère « 焱 » correspond à un simple numéro d’index — disons 38721. Ce numéro désigne une position dans le vocabulaire, permettant au modèle de récupérer un vecteur numérique représentant ce caractère.
Ce numéro ne porte aucune information sur la structure interne du caractère. La relation entre 38721 et 38722 est, pour le modèle, strictement identique à celle entre 1 et 10000. Ainsi, l’information relative à la « structure des caractères » est totalement encapsulée. Le fait que « 焱 » soit composé de trois « 火 » n’existe plus dans ce numéro.
Bien sûr, le modèle peut indirectement apprendre, à partir de vastes volumes de données, que « 焱 », « 炎 » et « 灼 » apparaissent fréquemment dans des contextes similaires — mais cette voie est plus détournée que l’utilisation directe des informations radicales.
Le modèle peut-il, à partir des octets fragmentés, « percevoir » des indices structurels analogues aux radicaux, puis les recombiner dans ses couches de calcul ultérieures ? Cette voie, certes plus coûteuse en tokens et en frais, pourrait-elle, sur le plan de la compréhension sémantique, s’avérer plus efficace que d’ingérer directement un numéro opaque ?
Une étude publiée en 2025 dans la revue Computational Linguistics (MIT Press), intitulée « Tokenization Changes Meaning in Large Language Models: Evidence from Chinese », répond à cette question.
Des radicaux qui naissent dans les fragments
L’auteur de l’étude, David Haslett, a remarqué une coïncidence historique.
Dans les années 1990, l’Unicode Consortium, en attribuant des codes UTF-8 aux caractères chinois, les a classés par ordre de radicaux. Les caractères partageant un même radical possèdent des séquences d’octets UTF-8 adjacentes. Ainsi, « 茶 » et « 茎 », tous deux contenant le radical « 艹 » (herbe), commencent par les mêmes octets dans leur séquence UTF-8. De même, « 河 » et « 海 », tous deux comportant le radical « 氵 » (eau), partagent les mêmes octets initiaux.
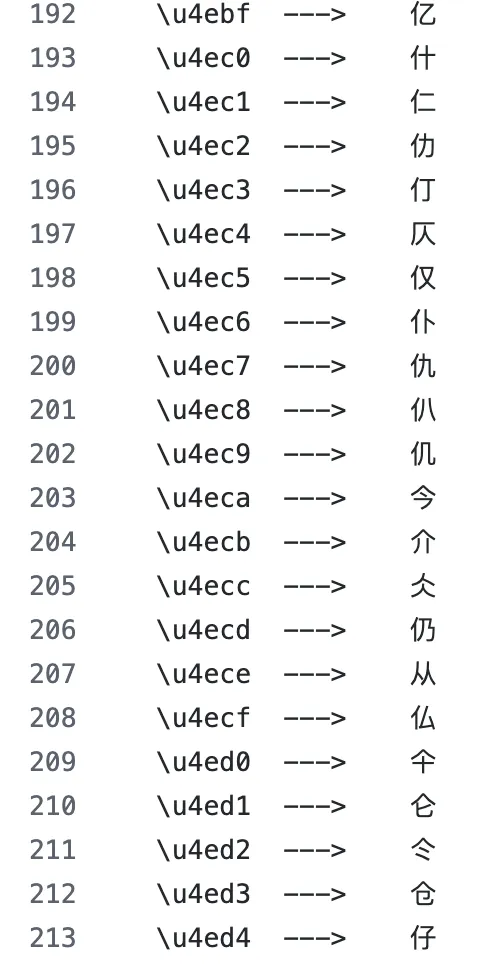
Unicode classe les caractères chinois par ordre de radicaux ; les caractères partageant un radical ont des codes proches. | Source de l’image : Github
Cela signifie que, lorsque le tokenizer découpe un caractère chinois en trois tokens octets, les caractères partageant un même radical partageront le premier token. En voyant répétitivement ces motifs d’octets partagés durant l’entraînement, le modèle pourrait apprendre que « les caractères partageant le même premier token appartiennent souvent au même domaine sémantique ». Fonctionnellement, cela équivaut à la méthode humaine consistant à déduire le sens à partir des radicaux.
Haslett a conçu trois expériences pour valider cette hypothèse.
La première demande à GPT-4, GPT-4o et Llama 3 si « 茶 » et « 茎 » partagent le même radical sémantique.
La seconde demande au modèle d’évaluer la similarité sémantique entre deux caractères chinois.
La troisième consiste en une tâche d’exclusion : « trouvez l’intrus ».
Chaque expérience contrôle deux variables : les deux caractères partagent-ils réellement un radical, et partagent-ils, dans le tokenizer utilisé, le même premier token. Ce dispositif 2×2 permet de distinguer l’effet du radical de celui du token.
Les trois expériences aboutissent à la même conclusion : lorsque les caractères chinois sont découpés en plusieurs tokens (par exemple, sous l’ancien tokenizer de GPT-4, où 89 % des caractères sont segmentés en plusieurs tokens), la précision avec laquelle le modèle identifie les radicaux partagés est plus élevée ; lorsqu’ils sont codés en un seul token (comme avec le nouveau tokenizer de GPT-4o, où seulement 57 % des caractères restent multi-token), cette précision diminue.
Autrement dit, la conjecture formulée précédemment est confirmée. Fragmenter les caractères augmente bien le coût, mais les séquences d’octets fragmentés conservent des traces des radicaux, et le modèle apprend effectivement à en tirer profit. En revanche, coder les caractères en tokens uniques réduit le coût, mais encapsule l’information radicale dans un numéro opaque, privant ainsi le modèle de cette piste sémantique accessible via les octets.
Il convient de souligner que cette conclusion se limite strictement aux tâches sémantiques fines liées à la forme des caractères, et ne saurait être généralisée à l’ensemble des capacités du modèle en chinois — compréhension globale, raisonnement logique ou génération de textes longs. Par ailleurs, les versions comparées (GPT-4 et GPT-4o) diffèrent non seulement par leur tokenizer, mais aussi par leur architecture, leur corpus d’entraînement et leur nombre de paramètres : on ne peut donc pas attribuer la variation de précision à 100 % au changement de granularité de segmentation.
Cette découverte a également été confirmée par des travaux d’ingénierie. Une étude menée en 2024 sur GPT-4o a révélé que, lorsque son nouveau tokenizer fusionne certaines combinaisons de caractères chinois en un seul token long, le modèle commet parfois des erreurs de compréhension. Or, lorsque les chercheurs ont recouru à un segmenteur chinois professionnel pour redécouper ces tokens longs, puis les ont réinjectés au modèle, la précision de compréhension s’est rétablie.
Actuellement, le consensus dominant dans l’industrie mondiale des grands modèles reste que les tokenizers entièrement optimisés pour la langue cible — segmentant les mots ou les caractères entiers — améliorent nettement les performances globales du modèle. Le codage par mot ou par caractère entier réduit considérablement les coûts en tokens, augmente la densité d’information utile dans la fenêtre de contexte, raccourcit la longueur des séquences, diminue la latence d’inférence et améliore la stabilité du traitement des textes longs. L’avantage observé dans des tâches spécialisées ne compense pas les gains de performance obtenus dans la grande majorité des scénarios NLP chinois.
Pourtant, ce phénomène met en lumière l’un des problèmes les plus difficiles à traiter dans les grands systèmes : on peut optimiser les parties que l’on a conçues, mais on ne peut pas optimiser celles dont on ignore l’existence. L’Unicode Consortium a classé les caractères par radicaux pour faciliter la recherche humaine. Le BPE les a fragmentés en octets parce que leur fréquence dans le corpus était trop faible. Deux décisions d’ingénierie indépendantes se sont ainsi conjointement produites, créant une voie sémantique inattendue, non prévue par personne.
Et lorsque les nouveaux ingénieurs « améliorent » le tokenizer en fusionnant les caractères chinois en tokens uniques, ils effacent simultanément une voie dont ils ignoraient l’existence. L’efficacité augmente, les coûts baissent, mais quelque chose disparaît silencieusement — sans même qu’un message d’erreur ne signale sa disparition.
Ainsi, la question dépasse largement le simple constat selon lequel « le chinois coûte plus cher dans l’IA ». Chaque tokenizer est optimisé pour une valeur par défaut, et le coût se cache ailleurs.
Lin Yutang
Le coût d’adaptation du chinois aux infrastructures technologiques occidentales ne date pas de l’ère de l’IA.
En janvier 2025, Nelson Felix, habitant de New York, a publié plusieurs photos sur un groupe Facebook dédié aux amateurs de machines à écrire. Il avait découvert, dans les effets de son beau-père, une machine à écrire gravée de caractères chinois, dont il ignorait l’origine. En quelques heures, des centaines de commentaires affluaient.

La question de Nelson Felix : la machine à écrire Mingkuai a-t-elle de la valeur ? | Source de l’image : Facebook
Thomas S. Mullaney, sinologue de l’université Stanford, a immédiatement reconnu l’appareil sur les photos : il s’agit du prototype unique de la « machine à écrire Mingkuai », inventée par Lin Yutang en 1947, disparue depuis près de 80 ans. En avril de la même année, le couple Felix a vendu la machine à la bibliothèque de l’université Stanford.
Le problème auquel devait répondre la machine Mingkuai est structurellement identique à celui que pose aujourd’hui le tokenizer : comment intégrer efficacement le chinois dans une infrastructure technologique conçue pour les langues occidentales.
Dans les années 1940, les machines à écrire anglaises disposaient de 26 touches, une par lettre — simple et direct. Le chinois comporte des milliers de caractères courants : impossible d’y affecter une touche par caractère. Les machines à écrire chinoises de l’époque étaient de véritables « tables à caractères », comportant des milliers de caractères en plomb, que l’opérateur devait sélectionner manuellement, à raison de quelques dizaines de caractères par minute.

En 1899, le missionnaire américain Devello Z. Sheffield inventait l’une des premières machines à écrire chinoises. | Source de l’image : Wikipedia
Lin Yutang investit 120 000 dollars — presque toute sa fortune — et fit fabriquer à la société new-yorkaise Carl E. Krum une machine à écrire chinoise comportant seulement 72 touches. Son principe reposait sur la décomposition des caractères selon leur structure : une touche supérieure sélectionnait la partie haute du radical, une touche inférieure la partie basse, et les candidats s’affichaient dans une petite fenêtre nommée « œil magique » ; il suffisait alors d’appuyer sur une touche numérique pour valider le choix. Elle permettait une vitesse de 40 à 50 caractères par minute et prenait en charge plus de 8 000 caractères courants.

(Gauche) La petite fenêtre transparente est l’« œil magique » ; (Droite) Structure interne de la machine Mingkuai. | Source de l’image : Facebook
Zhao Yuanren en fit l’éloge : « Que l’on soit chinois ou américain, une brève période d’apprentissage suffit pour maîtriser ce clavier. Je pense que c’est exactement la machine à écrire dont nous avons besoin. »
Techniquement, la machine Mingkuai fut une percée, mais commercialement, elle échoua.
Lors de sa démonstration devant les cadres de Remington, la machine tomba en panne, ce qui fit perdre tout intérêt aux investisseurs. Son coût élevé, combiné à l’épuisement des ressources personnelles de Lin Yutang, rendit toute production à grande échelle impossible. En 1948, Lin Yutang céda le prototype et les droits commerciaux à la société Mergenthaler Linotype. Celle-ci abandonna finalement le projet de production, et le prototype fut emporté dans les années 1950 par un employé lors d’un déménagement, avant de disparaître — jusqu’à sa redécouverte en 2025.
Dans son ouvrage The Chinese Typewriter, Thomas S. Mullaney formule un jugement : la machine Mingkuai « n’a pas échoué ». En tant que produit des années 1940, elle a bel et bien échoué. Mais en tant que paradigme d’interaction homme-machine, elle a triomphé.
Lin Yutang fut le premier à transformer la « frappe » chinoise en un processus de « recherche + sélection » : trois rangées de touches permettent de localiser les composants radicaux, parmi lesquels on choisit le caractère désiré dans une liste de candidats. Tel est précisément le fondement logique de toutes les méthodes d’entrée chinoises modernes — de Cangjie et Wubi à Sogou Pinyin. Toutes sont, en un sens, les héritières de la machine Mingkuai.

The Chinese Typewriter, auteur : Thomas S. Mullaney | Source de l’image : Douban
Cette machine à écrire, qui traverse près de huit décennies, et les tokenizers que nous discutons aujourd’hui, révèlent une régularité historique profonde. Le chinois fait constamment face à la même question :
Comment s’intégrer à une infrastructure technique fondée sur l’alphabet romain ?
Curieusement, cette quête regorge de coïncidences non planifiées. L’ordre de classement des caractères par radicaux, adopté par l’Unicode Consortium pour faciliter la recherche humaine, s’est superposé à la fragmentation involontaire opérée par l’algorithme BPE, et a ainsi, dans la boîte noire du réseau neuronal, reproduit le processus humain d’apprentissage de la lecture. Et lorsque les ingénieurs, afin d’éliminer l’« impôt chinois », réassemblent délibérément les caractères et réduisent les coûts, cette voie sémantique apparue fortuitement se referme.
L’histoire n’est pas une ligne droite d’évolution, mais un fluide constamment déformé sous la pression de contraintes multiples.
Certaines capacités sont conçues intentionnellement ; d’autres subsistent simplement parce qu’elles n’ont pas été supprimées.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













