

Point de vue : La Web 4.0 arrive, une infrastructure d'interaction centrée sur les agents intelligents construite par l'intelligence artificielle
TechFlow SélectionTechFlow Sélection
Point de vue : La Web 4.0 arrive, une infrastructure d'interaction centrée sur les agents intelligents construite par l'intelligence artificielle
Le réseau d'agents intelligents ne constitue pas seulement une avancée technologique, mais aussi une réinvention fondamentale du potentiel humain à l'ère numérique.
Auteur : Azi.eth.sol | zo.me | *acc
Traduction : TechFlow

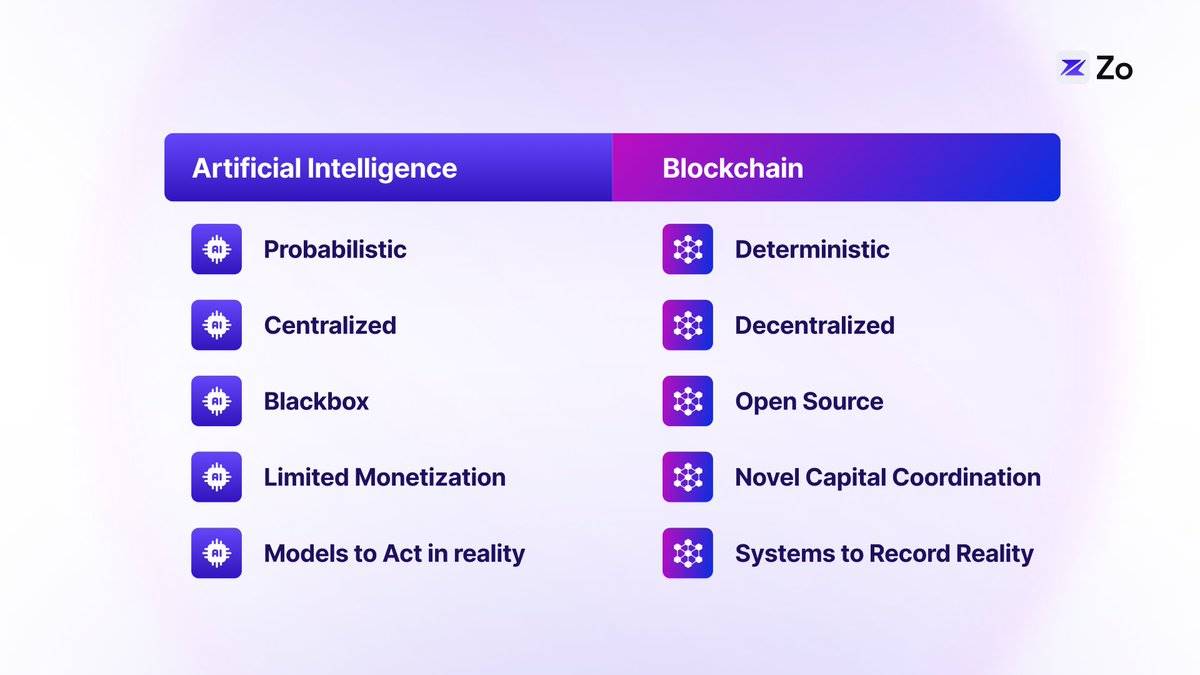
L’intelligence artificielle et la technologie blockchain sont deux forces puissantes en train de transformer le monde. L’IA renforce l’intelligence humaine via l’apprentissage automatique et les réseaux neuronaux, tandis que la blockchain apporte une rareté numérique vérifiable et de nouvelles façons de collaborer sans confiance. Avec la convergence de ces deux technologies, elles posent les bases d’une nouvelle génération d’internet – une ère où des agents autonomes interagissent avec des systèmes décentralisés. Ce « réseau d’agents » introduit une nouvelle catégorie d’habitants numériques : les agents IA capables de naviguer, négocier et effectuer des transactions de manière autonome. Cette transformation redéfinit le pouvoir dans le monde numérique, rendant aux individus le contrôle de leurs données tout en favorisant une collaboration inédite entre humains et intelligence artificielle.
L’évolution du réseau
Pour comprendre vers quoi nous nous dirigeons, il est essentiel de retracer l’évolution du web à travers ses principales phases, chacune ayant ses propres capacités et modèles architecturaux :
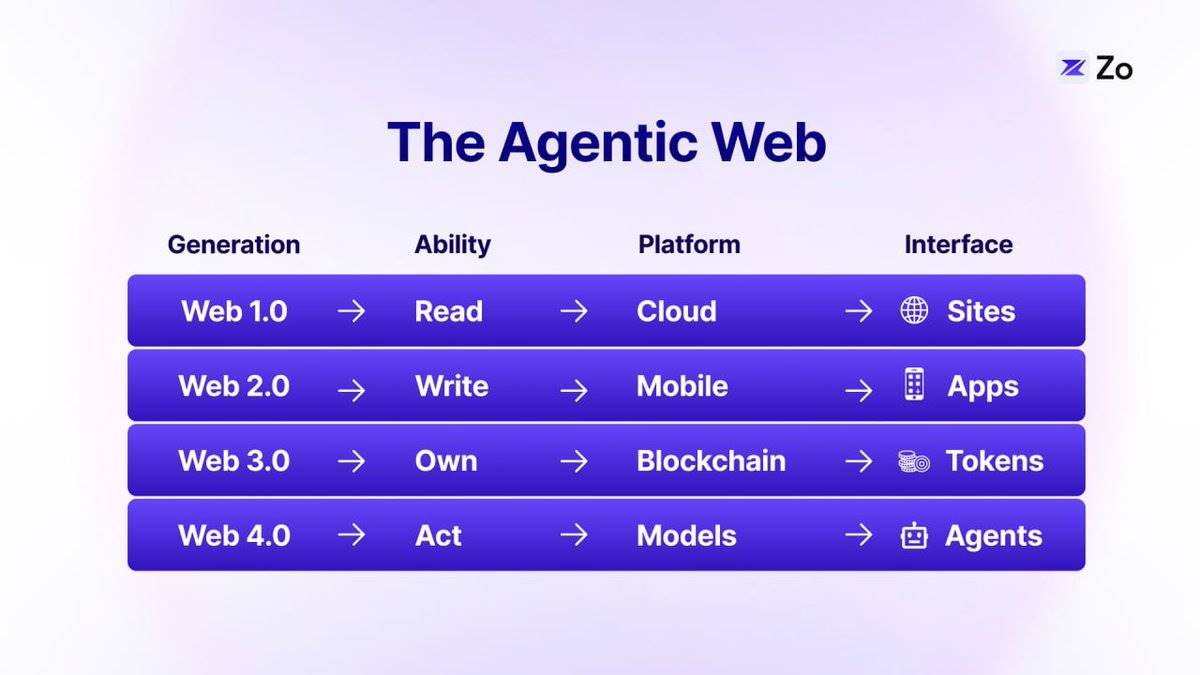
Les deux premières générations du web se concentraient principalement sur la diffusion d'informations, alors que les deux suivantes mettent l'accent sur l'amélioration de l'information. Le Web 3.0 a permis la propriété des données grâce aux jetons (tokens), tandis que le Web 4.0 confère de l'intelligence via les grands modèles linguistiques (LLMs).
Des LLMs aux agents : une évolution naturelle
Les grands modèles linguistiques (LLMs) ont permis un bond en avant majeur dans l’intelligence machine. En tant que systèmes dynamiques de correspondance de motifs, ils transforment une quantité massive de connaissances en compréhension contextuelle par le biais de calculs probabilistes. Toutefois, leur véritable potentiel ne s’exprime pleinement que lorsqu’ils sont conçus comme des agents – passant ainsi du statut de simples processeurs d’information à celui d’entités orientées objectifs, capables de percevoir, raisonner et agir. Ce changement crée une intelligence émergente capable de coopérer de façon continue et significative à travers le langage et l’action.
Le concept d’« agent » offre une nouvelle perspective sur l’interaction homme-machine, dépassant les limites et les stéréotypes négatifs associés aux chatbots traditionnels. Il ne s’agit pas simplement d’un changement terminologique, mais bien d’une refonte complète de la manière dont les systèmes d’IA fonctionnent de façon autonome et collaborent efficacement avec les humains. Les flux de travail des agents peuvent former des marchés centrés sur des besoins spécifiques des utilisateurs.
Le réseau d’agents ne se contente pas d’ajouter une couche d’intelligence : il transforme fondamentalement notre interaction avec les systèmes numériques. Contrairement aux précédentes versions du web qui reposaient sur des interfaces statiques et des parcours utilisateurs prédéfinis, le réseau d’agents introduit une architecture dynamique à exécution temps réel, permettant au calcul et aux interfaces de s’adapter instantanément aux besoins et intentions des utilisateurs.
Les sites web traditionnels constituent l’unité de base de l’internet actuel, offrant des interfaces fixes où les utilisateurs lisent, écrivent et interagissent selon des chemins prédéfinis. Bien que ce modèle soit efficace, il limite les utilisateurs à des interfaces conçues pour des cas généraux plutôt que pour des besoins personnalisés. Le réseau d’agents dépasse ces limitations grâce à des techniques telles que le calcul sensible au contexte, la génération d’interfaces adaptatives et la récupération améliorée par recherche (RAG) permettant une extraction d’information en temps réel.
Pensez à la manière dont TikTok a transformé la consommation de contenu en ajustant en continu le flux de contenu selon les préférences de chaque utilisateur. Le réseau d’agents étend cette idée à la génération complète d’interfaces. Les utilisateurs n’ont plus besoin de naviguer dans des mises en page fixes, mais interagissent plutôt avec des interfaces générées dynamiquement, capables de prédire et de guider leurs prochaines actions. Ce passage d’un modèle basé sur des sites statiques à un modèle d’interface dynamique pilotée par des agents marque une évolution fondamentale de notre interaction avec les systèmes numériques – un changement de paradigme allant d’une logique de navigation à une logique d’intention.
La composition des agents
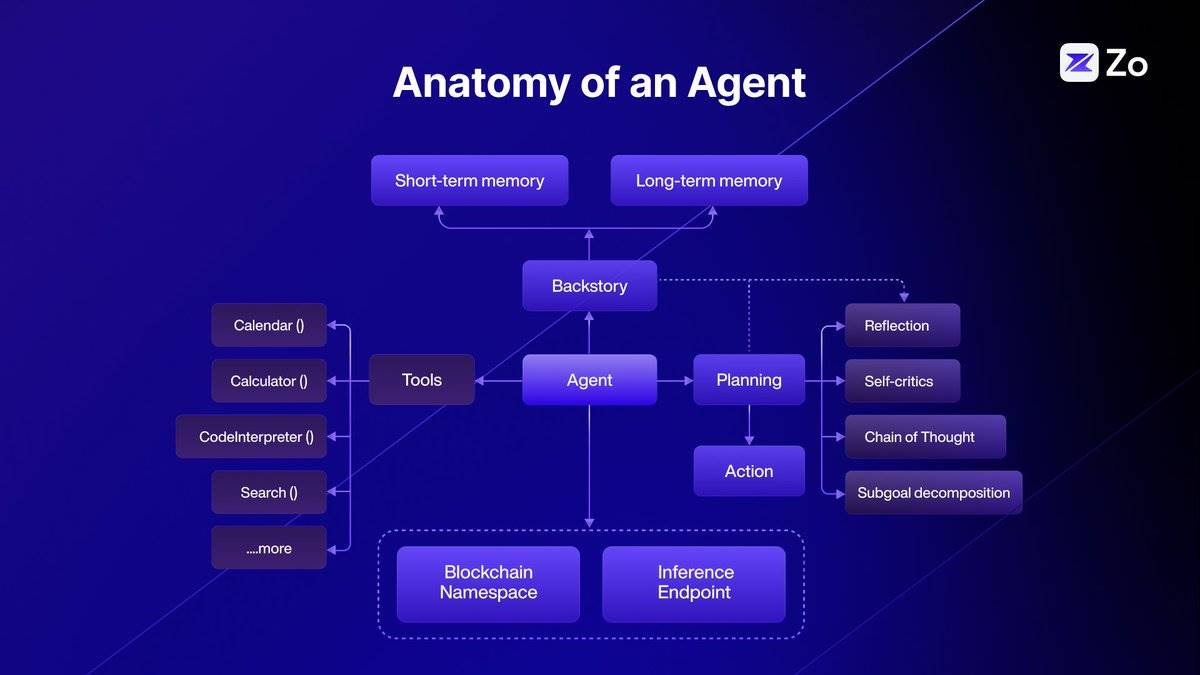
L’architecture des agents constitue un domaine exploré activement par les chercheurs et développeurs. Pour améliorer les capacités de raisonnement et de résolution de problèmes des agents, de nouvelles approches apparaissent continuellement. Par exemple, les méthodes Chain-of-Thought (CoT), Tree-of-Thought (ToT) et Graph-of-Thought (GoT) sont des innovations visant à renforcer la capacité des grands modèles linguistiques (LLMs) à traiter des tâches complexes en imitant des processus cognitifs plus précis et proches de ceux de l’humain.
La méthode Chain-of-Thought (CoT) aide les LLMs à raisonner logiquement en décomposant des tâches complexes en étapes plus simples. Cette approche est particulièrement utile pour des questions de raisonnement logique, telles que l’écriture de scripts Python ou la résolution d’équations mathématiques.
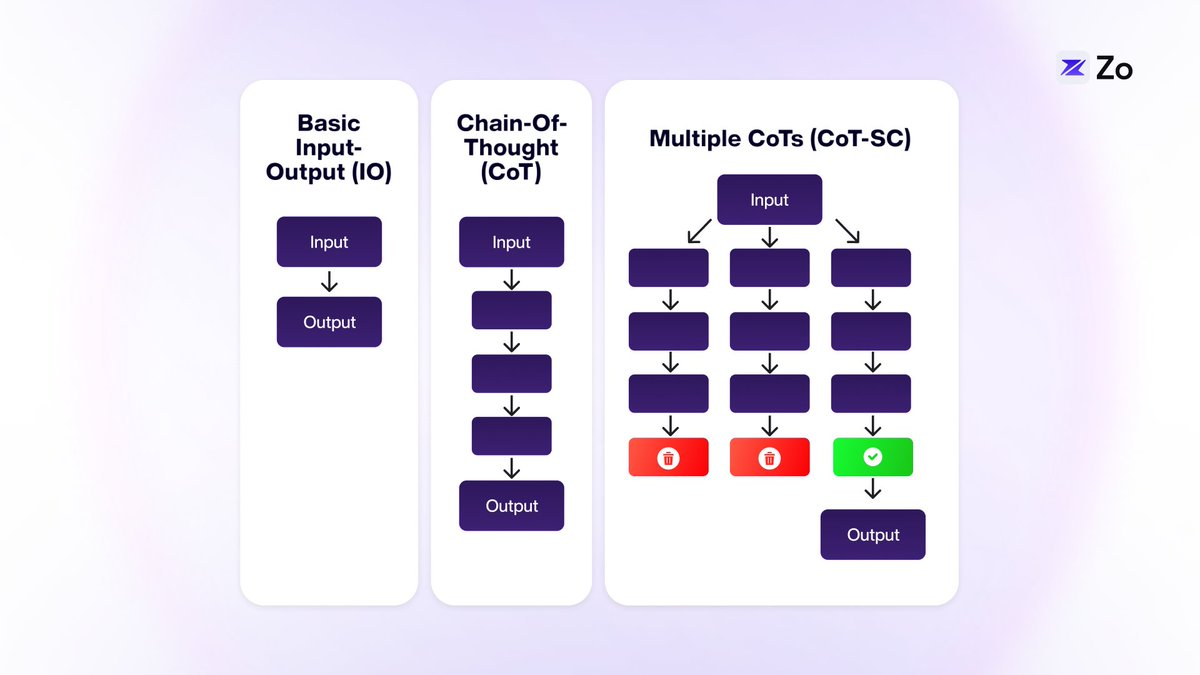
Tree-of-Thoughts (ToT) ajoute une structure arborescente à CoT, permettant d’explorer plusieurs chemins de pensée indépendants. Cette extension permet aux LLMs de faire face à des tâches plus complexes. Dans ToT, chaque « pensée » n’est liée qu’aux pensées adjacentes, ce qui, bien que plus souple que CoT, limite encore les interactions entre idées.
Graph-of-Thought (GoT) pousse davantage cette logique en combinant des structures de données classiques avec les LLMs, autorisant toute « pensée » à être connectée à d’autres dans une structure en graphe. Ce réseau interconnecté de pensées se rapproche davantage du fonctionnement cognitif humain.
La structure en graphe de GoT reflète généralement mieux la manière dont les humains pensent, comparée à CoT ou ToT. Même si, dans certains cas – comme la planification d’urgence ou les procédures opérationnelles standard – notre pensée peut ressembler à une chaîne ou un arbre, ces situations restent exceptionnelles. La pensée humaine saute naturellement d’une idée à une autre, sans ordre linéaire, ce qui correspond mieux à une représentation en graphe.
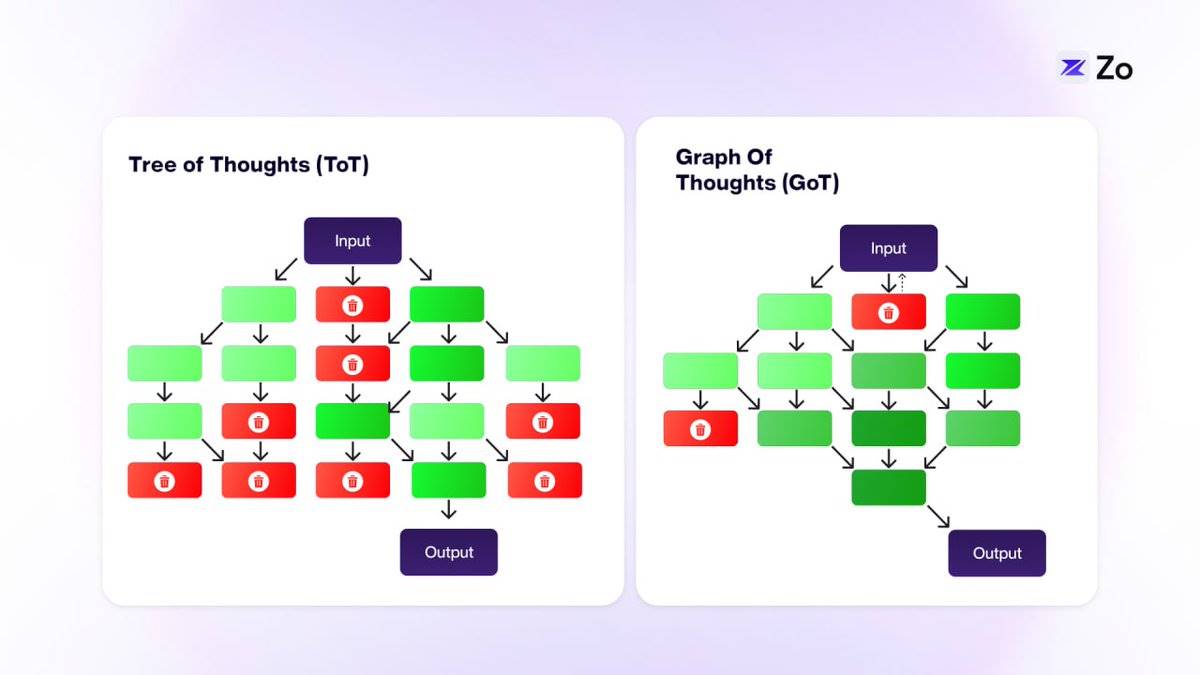
L’approche graphique de GoT rend l’exploration des idées plus dynamique et flexible, ce qui pourrait rendre les grands modèles linguistiques (LLMs) plus créatifs et exhaustifs dans la résolution de problèmes. Ces opérations basées sur des graphes récursifs ne sont toutefois qu’une étape vers les flux de travail d’agents. L’évolution suivante consiste à coordonner plusieurs agents spécialisés afin d’atteindre un objectif donné. La force des agents réside dans leur capacité combinatoire.
Les agents permettent aux LLMs d’atteindre modularité et parallélisme grâce à la coordination multi-agents.
Les systèmes multi-agents
Le concept de système multi-agents n’est pas nouveau. Il remonte à la théorie de la « société de l’esprit » de Marvin Minsky, selon laquelle plusieurs esprits modulaires collaborant ensemble peuvent surpasser un esprit unique et monolithique. ChatGPT et Claude sont des exemples d’agents uniques, tandis que Mistral popularise le mélange d’experts. Nous estimons que l’extension de cette idée à l’architecture du réseau d’agents représente la forme ultime de cette topologie intelligente.
D’un point de vue biomimétique, le cerveau humain (en réalité une machine consciente) présente une hétérogénéité extrême au niveau des organes et des cellules, contrairement aux modèles d’IA où des milliards de neurones identiques sont connectés de manière uniforme et prévisible. Les neurones communiquent par des signaux complexes impliquant des gradients de neurotransmetteurs, des cascades intracellulaires et divers systèmes de régulation, rendant leur fonctionnalité bien plus complexe que de simples états binaires.
Cela montre que, dans la biologie, l’intelligence ne dépend pas uniquement du nombre de composants ou de la taille du jeu de données d’entraînement. Elle provient plutôt des interactions complexes entre unités diversifiées et spécialisées – un processus essentiellement analogique. Ainsi, développer des millions de petits modèles et coordonner leur coopération est plus susceptible de générer des avancées innovantes en architecture cognitive que de compter uniquement sur quelques grands modèles, similaire à ce que font les systèmes multi-agents.
Les systèmes multi-agents présentent plusieurs avantages par rapport aux systèmes mono-agent : ils sont plus faciles à maintenir, plus compréhensibles et plus évolutifs. Même lorsque l’interface requiert un seul agent, le placer dans un cadre multi-agent améliore la modularité du système, simplifiant pour les développeurs l’ajout ou la suppression de composants selon les besoins. Notons également que l’architecture multi-agent peut même constituer une méthode efficace pour construire un système à agent unique.
Bien que les grands modèles linguistiques (LLMs) démontrent des capacités remarquables – génération de texte quasi humain, résolution de problèmes complexes, traitement de multiples tâches – un agent LLM unique peut rencontrer des limites dans les applications pratiques.
Nous explorerons ci-dessous cinq défis clés liés aux systèmes d’agents :
-
Réduction des hallucinations par validation croisée : Un agent LLM unique produit fréquemment des informations erronées ou dénuées de sens, même après un entraînement intensif, car les sorties peuvent sembler plausibles sans être factuellement exactes. Les systèmes multi-agents peuvent réduire ce risque en validant mutuellement les informations, différents agents spécialisés dans des domaines variés fournissant des réponses plus fiables et précises.
-
Extension de la fenêtre contextuelle par traitement distribué : Les LLMs ont une fenêtre contextuelle limitée, ce qui complique le traitement de longs documents ou conversations. Dans un cadre multi-agents, les agents peuvent se répartir la charge, chacun traitant une partie du contexte. En communiquant entre eux, ils conservent la cohérence sur l’ensemble du texte, élargissant ainsi efficacement la fenêtre contextuelle.
-
Traitement parallèle pour une meilleure efficacité : Un LLM unique traite généralement les tâches séquentiellement, ce qui ralentit les temps de réponse. Les systèmes multi-agents permettent le traitement parallèle, où plusieurs agents accomplissent simultanément différentes tâches, augmentant ainsi l’efficacité, accélérant les réponses, et permettant aux entreprises de répondre rapidement à de multiples requêtes.
-
Collaboration pour la résolution de problèmes complexes : Un seul LLM peut avoir du mal à résoudre des problèmes complexes nécessitant plusieurs expertises. Les systèmes multi-agents, par la collaboration, permettent à chaque agent d’apporter ses compétences et perspectives uniques, offrant ainsi des solutions plus complètes et innovantes face à des défis complexes.
-
Optimisation des ressources pour une meilleure accessibilité : Les LLMs avancés nécessitent d’importantes ressources informatiques, ce qui est coûteux et difficile à généraliser. Le cadre multi-agents optimise l’utilisation des ressources en répartissant les tâches, réduisant ainsi les coûts globaux de calcul, rendant la technologie IA plus abordable et accessible à davantage d’organisations.
Bien que les systèmes multi-agents offrent des avantages évidents en matière de résolution distribuée de problèmes et d’optimisation des ressources, leur potentiel s’exprime pleinement à la périphérie du réseau. À mesure que l’IA progresse, la combinaison de l’architecture multi-agents avec le calcul en périphérie (edge computing) crée un effet synergique puissant, permettant non seulement une intelligence collaborative, mais aussi un traitement localisé et efficace sur une multitude d’appareils. Cette approche distribuée du déploiement de l’IA étend naturellement les avantages des systèmes multi-agents, rapprochant l’intelligence spécialisée et collaborative des utilisateurs finaux.
Intelligence en périphérie (Edge Intelligence)
La prolifération de l’IA dans le monde numérique entraîne une mutation fondamentale de l’architecture informatique. Alors que l’intelligence s’imprègne dans tous les aspects de nos interactions numériques quotidiennes, on observe une différenciation naturelle du calcul : les centres de données spécialisés gèrent les tâches complexes de raisonnement et spécifiques à un domaine, tandis que les appareils périphériques traitent localement les requêtes personnalisées et sensibles au contexte. Ce virage vers l’inférence en périphérie n’est pas simplement un choix architectural, mais une tendance inévitable poussée par plusieurs facteurs clés.
Premièrement, le volume massif d’interactions pilotées par l’IA risque de submerger les fournisseurs d’inférence centralisés, entraînant des besoins insoutenables en bande passante et des retards inacceptables.
Deuxièmement, le traitement en périphérie permet des réponses en temps réel, essentielles pour des applications telles que la conduite autonome, la réalité augmentée ou les dispositifs IoT.
Troisièmement, l’inférence locale protège la vie privée des utilisateurs en gardant les données sensibles sur les appareils personnels.
Quatrièmement, le calcul en périphérie réduit considérablement la consommation d’énergie et les émissions de carbone en limitant les transferts de données à travers le réseau.
Enfin, l’inférence en périphérie permet des fonctionnalités hors ligne et assure la résilience, garantissant que les capacités d’IA restent disponibles même en cas de connexion réseau instable.
Ce modèle d’intelligence distribuée ne constitue pas seulement une optimisation des systèmes existants, mais bien une refonte complète de la manière dont nous déployons et utilisons l’IA dans un monde de plus en plus interconnecté.
Par ailleurs, nous assistons à un changement majeur concernant les exigences computationnelles des grands modèles linguistiques (LLMs). Pendant la dernière décennie, l’accent était mis sur les ressources colossales nécessaires à l’entraînement des LLMs ; désormais, nous entrons dans une ère où le calcul d’inférence devient central. Ce changement est particulièrement visible avec l’émergence de systèmes d’IA intelligents, comme la percée Q* d’OpenAI, qui démontre que le raisonnement dynamique nécessite d’importantes ressources de calcul en temps réel.
Contrairement au calcul d’entraînement, qui représente un investissement ponctuel dans le développement du modèle, le calcul d’inférence est un processus continu nécessaire pour que les agents raisonnent, planifient et s’adaptent à de nouveaux environnements. Ce passage d’un modèle statique à une inférence dynamique d’agent impose de repenser l’infrastructure informatique, rendant le calcul en périphérie non seulement avantageux, mais indispensable.
Avec cette évolution, nous voyons émerger des marchés d’inférence pair-à-pair en périphérie, où des milliards d’appareils connectés – des smartphones aux systèmes domestiques intelligents – forment un réseau informatique dynamique. Ces appareils peuvent échanger sans friction leurs capacités d’inférence, formant un marché organique où les ressources informatiques s’orientent là où elles sont le plus nécessaires. La puissance de calcul inutilisée d’appareils inactifs devient une ressource précieuse, échangeable en temps réel, construisant ainsi une infrastructure plus efficace et plus résiliente que les systèmes centralisés traditionnels.
La démocratisation de ce calcul d’inférence n’optimise pas seulement l’utilisation des ressources, elle crée aussi de nouvelles opportunités économiques dans l’écosystème numérique, chaque appareil connecté pouvant devenir un petit fournisseur de capacités d’IA. Ainsi, l’avenir de l’IA dépendra non seulement des capacités d’un modèle isolé, mais aussi d’un marché mondial, démocratisé et globalisé de l’inférence, constitué d’appareils interconnectés – comparable à un marché au comptant en temps réel fondé sur l’offre et la demande.
Interactions centrées sur les agents
Les grands modèles linguistiques (LLMs) nous permettent d’accéder à une masse d’information non plus par navigation, mais par conversation. Ce mode conversationnel va rapidement devenir plus personnalisé et localisé, car internet se transforme progressivement en une plateforme destinée aux agents d’IA, et non plus exclusivement aux utilisateurs humains.
D’un point de vue utilisateur, l’attention passera de la recherche du « meilleur modèle » à l’obtention de la réponse la plus personnalisée possible. La clé d’une meilleure réponse réside dans la combinaison des données personnelles de l’utilisateur avec les connaissances universelles d’internet. Initialement, de plus grandes fenêtres contextuelles et les techniques de RAG (récupération améliorée par génération) aideront à intégrer les données personnelles, mais à terme, les données personnelles prendront le pas sur les données générales d’internet.
Cela annonce un futur où chacun possédera un modèle d’IA personnel capable d’interagir avec les modèles experts d’internet. La personnalisation commencera par des modèles distants, mais à mesure que la confidentialité et la rapidité de réponse gagneront en importance, davantage d’interactions migreront vers les appareils locaux. Une nouvelle frontière émergera alors – non plus entre humain et machine, mais entre le modèle personnel et les modèles experts d’internet.
Le modèle traditionnel d’accès aux données brutes d’internet sera progressivement abandonné. À la place, votre modèle local communiquera avec des modèles experts distants pour obtenir des informations, puis vous les présentera de la manière la plus personnalisée et efficace possible. À mesure que ces modèles personnels approfondiront leur connaissance de vos préférences et habitudes, ils deviendront indispensables.
Internet évoluera vers un écosystème de modèles interconnectés : des modèles personnels locaux à fort contexte, et des modèles experts distants à grande connaissance. Cela impliquera de nouvelles technologies, telles que l’apprentissage fédéré, pour mettre à jour les informations entre ces modèles. À mesure que l’économie des machines se développe, nous devons repenser l’infrastructure informatique sous-jacente, notamment en matière de puissance de calcul, d’évolutivité et de paiement. Cela entraînera une réorganisation de l’espace informationnel, désormais centré sur les agents, souverain, hautement composable, auto-apprenant et en perpétuelle évolution.
Architecture des protocoles d’agents
Dans le réseau d’agents, l’interaction homme-machine évolue vers un réseau complexe de communications entre agents. Cette architecture repense la structure d’internet, faisant des agents souverains les interfaces principales des interactions numériques. Voici les éléments fondamentaux requis par un protocole d’agents.
Identité souveraine
-
L’identité numérique évolue des adresses IP traditionnelles vers des paires de clés cryptographiques contrôlées par les agents
-
Un système de nommage basé sur la blockchain remplace le DNS traditionnel, éliminant le contrôle centralisé
-
Un système de réputation suit la fiabilité et les compétences des agents
-
Les preuves à divulgation nulle de connaissance (zero-knowledge proofs) permettent une authentification respectueuse de la vie privée
-
La composable identity permet aux agents de gérer plusieurs contextes et rôles
Agents autonomes
-
Les agents autonomes disposent des capacités suivantes :
-
Compréhension du langage naturel et analyse des intentions
-
Planification en plusieurs étapes et décomposition de tâches
-
Gestion et optimisation des ressources
-
Apprentissage à partir des interactions et des retours
-
Prise de décision autonome dans des paramètres définis
-
-
Spécialisation des agents et marchés fonctionnels spécifiques
-
Mécanismes de sécurité intégrés et protocoles d’alignement pour assurer la sûreté
Infrastructure des données
-
Capacité d’ingestion et de traitement des données en temps réel
-
Mécanismes de validation et de vérification distribués des données
-
Système hybride combinant :
-
zkTLS
-
Jeu de données d’entraînement traditionnel
-
Web scraping en temps réel et synthèse de données
-
Réseaux d’apprentissage collaboratif
-
-
Réseau d’apprentissage par renforcement avec retour humain (RLHF)
-
Système de collecte distribuée de retours
-
Mécanisme de consensus pondéré par qualité
-
Protocoles d’ajustement dynamique des modèles
-
Couche de calcul
-
Protocoles d’inférence vérifiables garantissant :
-
Intégrité du calcul
-
Reproductibilité des résultats
-
Efficacité de l’utilisation des ressources
-
-
Infrastructure de calcul décentralisée comprenant :
-
Marchés informatiques pair-à-pair
-
Systèmes de preuve de calcul
-
Allocation dynamique des ressources
-
Intégration du calcul en périphérie
-
Écosystème de modèles
-
Architecture de modèles en couches :
-
Petits modèles linguistiques (SLMs) spécialisés par tâche
-
Grands modèles linguistiques (LLMs) généraux
-
Modèles multimodaux spécialisés
-
Grands modèles d’action multimodaux (LAMs)
-
-
Composition et orchestration des modèles
-
Capacité d’apprentissage continu et d’adaptation
-
Interfaces et protocoles normalisés pour les modèles
Cadre de coordination
-
Protocoles cryptographiques sécurisant les interactions entre agents
-
Système de gestion des droits numériques
-
Structures d’incitations économiques
-
Mécanismes de gouvernance pour :
-
Résolution de conflits
-
Allocation des ressources
-
Mise à jour des protocoles
-
-
Support d’environnement d’exécution parallèle :
-
Traitement concurrent de tâches
-
Isolation des ressources
-
Gestion d’état
-
Résolution de conflits
-
Marché des agents
-
Primitives d’identité sur chaîne (ex : signatures multiples Gnosis et Squad)
-
Économie et transactions entre agents
-
Part de liquidité détenue par les agents
-
Les agents détiennent une partie de leur offre de jetons dès leur création
-
Marché agrégé d’inférence payé en liquidité
-
-
Contrôle par clé sur chaîne des comptes hors chaîne
-
Les agents deviennent des actifs générant des revenus
-
Gouvernance et distribution de dividendes via des organisations autonomes décentralisées (DAOs) d’agents
-
Construction de l’hyperstructure intelligente
La conception moderne des systèmes distribués fournit une inspiration et une base uniques pour le développement de protocoles d’agents, notamment dans les domaines de l’architecture orientée événements et du modèle de calcul dit « Actor Model ».
Le modèle d’acteur (Actor Model) offre un cadre théorique élégant pour construire des systèmes d’agents. Ce modèle de calcul considère chaque « acteur » comme une unité fondamentale du processus informatique, chaque acteur pouvant :
-
Traiter des messages
-
Prendre des décisions locales
-
Créer de nouveaux acteurs
-
Envoyer des messages à d’autres acteurs
-
Déterminer comment répondre au prochain message reçu
Les principaux avantages du modèle d’acteur dans les systèmes d’agents incluent :
-
Isolation : Chaque acteur fonctionne indépendamment, conservant son propre état et son flux de contrôle
-
Communication asynchrone : L’échange de messages entre acteurs est non bloquant, permettant un traitement parallèle efficace
-
Transparence de localisation : Les acteurs peuvent communiquer quel que soit leur emplacement dans le réseau
-
Résilience aux pannes : L’isolation des acteurs et les hiérarchies de supervision renforcent la robustesse du système
-
Évolutivité : Naturellement adapté aux systèmes distribués et au calcul parallèle
Nous proposons Neuron, un protocole d’agents concret réalisé via une architecture distribuée multicouche, combinant espace de nommage blockchain, réseau fédéré, CRDTs et DHTs, chaque couche assumant une fonction spécifique dans la pile du protocole. Nous nous inspirons des concepts développés par Urbit et Holochain, des systèmes d’exploitation pair-à-pair précurseurs.
Dans Neuron, la couche blockchain fournit un espace de nommage vérifiable et une identité, permettant de localiser et découvrir les agents de manière déterministe, tout en offrant des preuves cryptographiques de capacités et de réputation. Au-dessus, la couche DHT facilite la découverte efficace des agents et des nœuds ainsi que le routage de contenu, avec un temps de recherche en O(log n), réduisant les opérations sur chaîne tout en soutenant des recherches locales pair-à-pair. La synchronisation d’état entre les nœuds fédérés s’effectue via les CRDTs, permettant aux agents et nœuds de maintenir une vision partagée cohérente sans nécessiter un consensus global à chaque interaction.
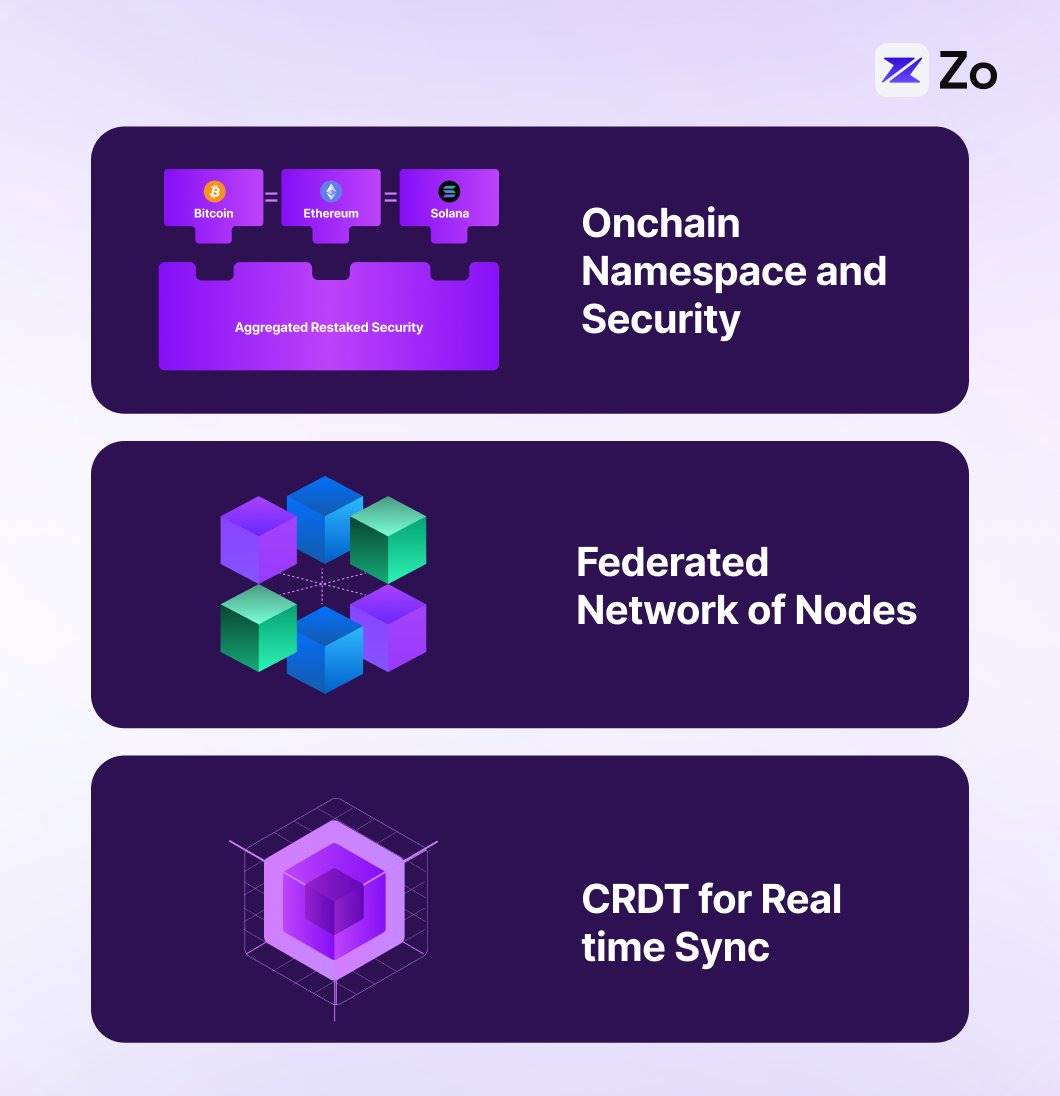
Cette architecture convient naturellement aux réseaux fédérés, où des agents autonomes fonctionnent comme des nœuds indépendants sur des appareils, implémentant le modèle d’acteur via une inférence locale en périphérie. Les domaines fédérés peuvent être organisés selon les capacités des agents, la DHT assurant un routage et une découverte efficaces à l’intérieur et entre les domaines. Chaque agent fonctionne comme un acteur indépendant, possédant son propre état, tandis que la couche CRDT garantit la cohérence au sein de l’ensemble du réseau fédéré. Cette approche multicouche permet plusieurs fonctions clés :
Coordination décentralisée
-
Blockchain utilisée pour fournir une identité vérifiable et un espace de nommage global
-
DHT utilisée pour la découverte efficace des nœuds et le routage de contenu, avec un temps de recherche en O(log n)
-
CRDTs utilisés pour la synchronisation d’état concurrente et la coordination multi-agents
Opérations évolutives
-
Topologie fédérée basée sur des zones
-
Stratégie de stockage hiérarchique (chaud/tempéré/froid)
-
Routage localisé des requêtes
-
Allocation de charge basée sur les capacités
Résilience du système
-
Aucun point de défaillance unique
-
Fonctionnement continu durant les partitions
-
Synchronisation automatique des états
-
Hiérarchie de supervision tolérante aux pannes
Cette approche fournit une base solide pour construire des systèmes d’agents complexes, tout en préservant les attributs essentiels à une interaction efficace entre agents : souveraineté, évolutivité et résilience.
Dernières réflexions
Le réseau d’agents marque une évolution significative de l’interaction homme-machine, allant au-delà des développements progressifs antérieurs pour instaurer un nouveau mode d’existence numérique. Contrairement aux évolutions précédentes qui changeaient simplement la manière de consommer ou de posséder l’information, le réseau d’agents transforme internet d’une plateforme centrée sur l’humain en un substrat intelligent où les agents autonomes deviennent les principaux acteurs. Ce changement, porté par la convergence du calcul en périphérie, des grands modèles linguistiques et des protocoles décentralisés, crée un écosystème où les modèles d’IA personnels s’interconnectent sans friction avec des systèmes experts spécialisés.
À mesure que nous avançons vers un futur centré sur les agents, la frontière entre humains et intelligence machine s’estompe, remplacée par une relation symbiotique. Dans cette relation, les agents d’IA personnalisés deviennent nos prolongements numériques, capables de comprendre notre contexte, d’anticiper nos besoins et d’agir de manière autonome au sein d’un vaste réseau d’intelligence distribuée. Ainsi, le réseau d’agents n’est pas seulement une avancée technologique, mais bien une refonte fondamentale du potentiel humain à l’ère numérique. Dans ce réseau, chaque interaction devient une occasion d’intelligence augmentée, chaque appareil un nœud dans un système d’IA collaboratif global.
Tout comme les humains évoluent dans les dimensions physiques de l’espace et du temps, les agents autonomes opèrent dans leurs propres dimensions fondamentales : l’espace des blocs (blockspace) pour leur existence, et le temps d’inférence pour leur pensée. Cette ontologie numérique reflète notre réalité physique – alors que les humains traversent l’espace et expérimentent l’écoulement du temps, les agents agissent dans le monde algorithmique par des preuves cryptographiques et des cycles de calcul, créant ainsi un univers numérique parallèle.
Fonctionner dans l’espace des blocs décentralisé deviendra une tendance inévitable pour les entités présentes dans l’espace potentiel.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













