

Transcription intégrale de 10 000 caractères du discours principal de Jensen Huang à COMPUTEX 2024 : Nous traversons une inflation informatique
TechFlow SélectionTechFlow Sélection
Transcription intégrale de 10 000 caractères du discours principal de Jensen Huang à COMPUTEX 2024 : Nous traversons une inflation informatique
Le PDG de Nvidia, Jensen Huang, a présenté lors du salon ComputeX 2024 à Taipei les dernières réalisations de Nvidia dans les domaines du calcul accéléré et de l'IA générative.
Préparation : Youxin

Le 2 juin au soir, lors du salon ComputeX 2024 à Taipei, Jensen Huang, PDG de NVIDIA, a présenté les dernières avancées de l'entreprise en matière d'informatique accélérée et d'intelligence artificielle générative, tout en esquissant la feuille de route future du calcul et des technologies robotiques.

Cette présentation couvre depuis les bases techniques de l’IA jusqu’aux applications futures des robots et de l’IA générative dans divers secteurs, illustrant pleinement les réalisations exceptionnelles de NVIDIA dans la transformation technologique du calcul.

Jensen Huang a indiqué que NVIDIA se situe à l'intersection de la synthèse d'images, de la simulation et de l'IA — c’est l’âme de l’entreprise. Tout ce qui est montré aujourd’hui est simulé ; il s'agit d'une combinaison de mathématiques, de sciences, d'informatique et d'architectures informatiques impressionnantes. Rien n'est animé : tout est produit par nous-mêmes, intégré entièrement dans le monde virtuel Omniverse.
Calcul Accéléré et IA
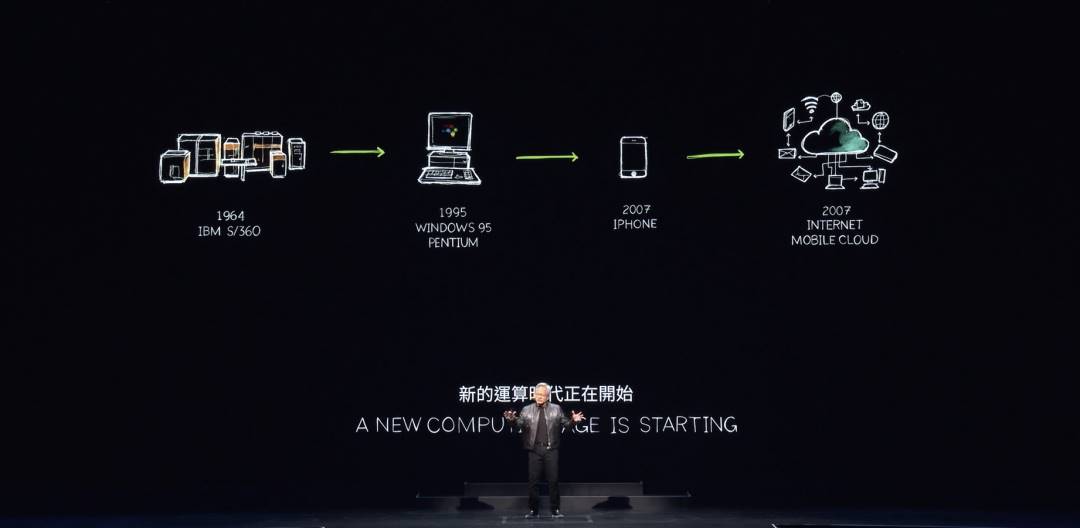
Selon Jensen Huang, deux technologies fondamentales sous-tendent tout ce que nous voyons : le calcul accéléré et l’intelligence artificielle fonctionnant au sein d’Omniverse. Ces deux forces fondamentales du calcul vont redéfinir l’industrie informatique. L’informatique existe depuis 60 ans. En bien des aspects, tout ce que nous faisons aujourd’hui repose sur des inventions datant de 1964, soit un an après la naissance de Jensen Huang.
L’IBM System 360 a introduit l’unité centrale de traitement (CPU), le calcul universel, la séparation entre matériel et logiciel via les systèmes d’exploitation, le multitâche, les sous-systèmes d’entrée-sortie, le DMA, ainsi que diverses technologies encore utilisées aujourd’hui. La compatibilité architecturale, la rétrocompatibilité, la compatibilité de gamme — presque tous les concepts que nous connaissons en informatique ont été définis dès 1964. Bien sûr, la révolution PC a démocratisé l’informatique, la plaçant dans chaque foyer et entre toutes les mains.
En 2007, l’iPhone a lancé le calcul mobile, mettant un ordinateur dans nos poches. Depuis lors, tout est connecté et fonctionne constamment via le cloud mobile. Au cours de ces 60 années, nous n’avons assisté qu’à deux ou trois changements technologiques majeurs — pas plus —, trois transformations structurelles du calcul. Et nous sommes sur le point d’en vivre une nouvelle.

Deux phénomènes fondamentaux sont en cours. Premièrement, les processeurs — le moteur de l’industrie informatique — voient leurs performances ralentir considérablement. Pourtant, le volume de calcul requis continue de croître exponentiellement. Si la demande de traitement augmente de façon exponentielle alors que les performances stagnent, une inflation du calcul surviendra. C’est déjà ce que nous observons. La consommation électrique mondiale des centres de données augmente fortement. Le coût du calcul grimpe aussi. Nous traversons une inflation du calcul.
Bien entendu, cette situation ne peut perdurer. Les volumes de données continueront à croître exponentiellement, tandis que l’amélioration des performances des CPU ne reviendra jamais à son rythme antérieur. Heureusement, nous disposons d’une meilleure approche. Depuis près de vingt ans, NVIDIA étudie le calcul accéléré. CUDA améliore le CPU en déchargeant vers des processeurs spécialisés les tâches qu’ils peuvent exécuter plus efficacement. Les gains de performance sont si spectaculaires qu’il devient évident qu’avec le ralentissement puis l’arrêt marqué de l’évolution des CPU, tout doit désormais être accéléré.

Jensen Huang prévoit que toutes les applications nécessitant un traitement intensif seront accélérées, et que chaque centre de données sera bientôt accéléré. Le calcul accéléré devient aujourd'hui incontournable. Prenons une application typique : ici, 100t représente 100 unités de temps — cela pourrait être 100 secondes ou 100 heures. Comme vous le savez, certaines applications d’IA prennent actuellement 100 jours à s’exécuter.
Le code 1T désigne les opérations devant être traitées séquentiellement, où un CPU monocœur joue un rôle critique. La logique de contrôle du système d’exploitation est essentielle, requérant une exécution instruction après instruction. Mais de nombreux algorithmes — comme le traitement graphique, le traitement d’image, la simulation physique, l’optimisation combinatoire, le traitement de graphes, les bases de données, et surtout l’algèbre linéaire célèbre en apprentissage profond — peuvent être parfaitement parallélisés.
Ainsi, une architecture a été créée en ajoutant un GPU au CPU. Un processeur spécialisé peut transformer une tâche longue en une opération ultra-rapide. Grâce à leur travail conjoint, autonomes et indépendants, ils peuvent réduire une tâche de 100 unités de temps à 1 seule. Le gain de vitesse est incroyable : multiplication par 100, avec une consommation d’énergie augmentée d’environ 3 fois seulement, et un coût accru d’environ 50 %. C’est ce que nous faisons depuis toujours dans l’industrie PC : ajouter une carte GeForce de 500 dollars à un PC de 1000 dollars multiplie sa performance. Nous faisons de même dans les centres de données : ajouter 500 millions de dollars de GPU à un centre de données valant un milliard de dollars le transforme soudainement en usine d’IA. Cela se produit partout dans le monde.
Les économies réalisées sont stupéfiantes. Chaque dollar dépensé rapporte 60 fois plus de performance, avec une vitesse multipliée par 100, une consommation x3 et un coût x1,5. Ces gains sont extraordinaires et se traduisent directement en économies monétaires.
Il est clair que de nombreuses entreprises dépensent des centaines de millions de dollars dans le traitement de données dans le cloud. Si ces processus sont accélérés, on imagine aisément des économies similaires. Car nous avons subi pendant longtemps une inflation du calcul généraliste.

Maintenant que nous adoptons massivement le calcul accéléré, d’énormes pertes accumulées peuvent être récupérées, et de nombreux gaspillages peuvent être éliminés. Cela se traduira par des économies financières et énergétiques — d’où l’expression favorite de Jensen Huang : « Plus tu achètes, plus tu économises ».
Jensen Huang ajoute que le calcul accéléré apporte des résultats exceptionnels, mais qu’il n’est pas facile à mettre en œuvre. Pourquoi permet-il de telles économies sans avoir été adopté plus tôt ? Parce que c’est extrêmement difficile. Aucun logiciel compilé via un compilateur C ne verra ses performances multiplier instantanément par 100. Ce serait absurde. S’il était possible, les CPU auraient déjà été conçus ainsi.
En réalité, il faut réécrire complètement les logiciels — la partie la plus ardue. Il faut reformuler entièrement les algorithmes écrits pour CPU afin qu’ils puissent être accélérés, déchargés et exécutés en parallèle. Cet exercice de science informatique est extrêmement complexe.

Au cours des 20 dernières années, NVIDIA a rendu cette transition plus accessible au monde entier. Par exemple, cuDNN, la célèbre bibliothèque d’apprentissage profond pour les réseaux neuronaux. NVIDIA dispose d’une bibliothèque d’IA physique, utilisable en dynamique des fluides et dans bien d’autres domaines, où les réseaux neuronaux doivent respecter les lois physiques. Elle possède aussi Arial Ran, une formidable bibliothèque CUDA accélérant les radios 5G, capable de définir et d’accélérer les réseaux télécoms comme on définit Internet. Cette capacité d’accélération permet de transformer entièrement les télécommunications en une plateforme similaire aux plateformes cloud.
cuLITHO est une plateforme de lithographie computationnelle qui traite la partie la plus gourmande en calcul de la fabrication des puces : la création des masques. TSMC l’utilise déjà en production, économisant d’importantes quantités d’énergie et d’argent. L’objectif de TSMC est d’accélérer toute sa chaîne logicielle pour préparer des algorithmes plus poussés et des transistors plus fins. Parabricks est la bibliothèque de séquençage génomique de NVIDIA, celle offrant le débit le plus élevé au monde. cuOpt est une bibliothèque incroyable pour l’optimisation combinatoire et la planification de trajets, capable de résoudre le problème du voyageur de commerce, très complexe.
Les scientifiques pensaient généralement qu’un ordinateur quantique était nécessaire pour ce type de problèmes. NVIDIA a créé un algorithme fonctionnant sur calcul accéléré, exécuté à une vitesse fulgurante, battant 23 records mondiaux. cuQuantum est un simulateur d’ordinateur quantique. Si vous voulez concevoir un ordinateur quantique, vous avez besoin d’un simulateur. Pour concevoir des algorithmes quantiques, vous avez besoin d’un simulateur quantique. Comment créer ces algorithmes sans ordinateur quantique existant ? Vous utilisez les ordinateurs les plus rapides du monde — bien sûr, ceux de NVIDIA avec CUDA. Sur cette base, NVIDIA propose un simulateur capable de modéliser un ordinateur quantique. Il est utilisé par des dizaines de milliers de chercheurs à travers le monde, intégré dans tous les principaux frameworks quantiques, largement employé dans les centres de supercalcul scientifiques.
cuDF est une bibliothèque incroyable de traitement de données. Ce traitement consomme la majeure partie des dépenses cloud actuelles — tout cela doit être accéléré. cuDF accélère les principales bibliothèques utilisées dans le monde, comme Spark — que beaucoup d’entreprises utilisent probablement — Pandas, une nouvelle bibliothèque appelée Polars, ainsi que NetworkX, une base de données de traitement de graphes. Ce ne sont là que quelques exemples parmi de nombreux autres.
Jensen Huang souligne que NVIDIA a dû créer ces bibliothèques pour permettre à l’écosystème d’exploiter le calcul accéléré. Sans cuDNN, même avec CUDA, les chercheurs mondiaux en apprentissage profond n’auraient pu l’utiliser, car l’écart entre CUDA et les algorithmes utilisés dans TensorFlow ou PyTorch aurait été trop grand. Cela aurait été comme faire de la synthèse d’images sans OpenGL, ou du traitement de données sans SQL. Ces bibliothèques spécialisées sont des trésors pour NVIDIA — au total, 350 bibliothèques — qui ont permis d’ouvrir tant de marchés.
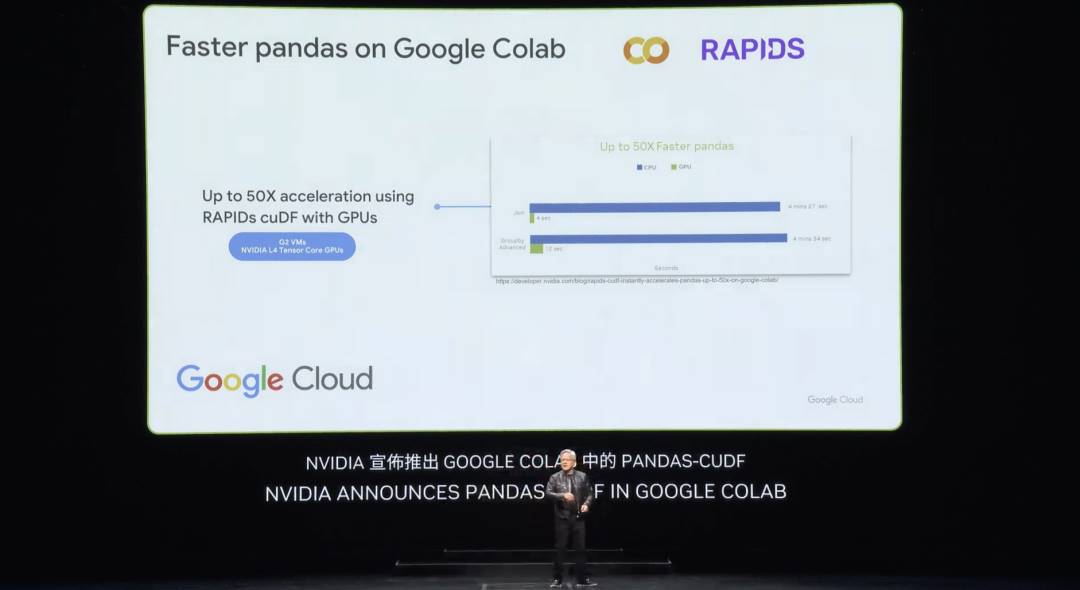
La semaine dernière, Google a annoncé l’accélération de Pandas dans le cloud — la bibliothèque de science des données la plus populaire au monde. Beaucoup d’entre vous utilisent probablement Pandas, utilisé par 10 millions de data scientists dans le monde, téléchargé 170 millions de fois par mois. C’est le tableur des data scientists. Désormais, d’un simple clic, vous pouvez utiliser Pandas accéléré par cuDF sur la plateforme Colab de Google Cloud, avec des gains de performance vraiment stupéfiants.
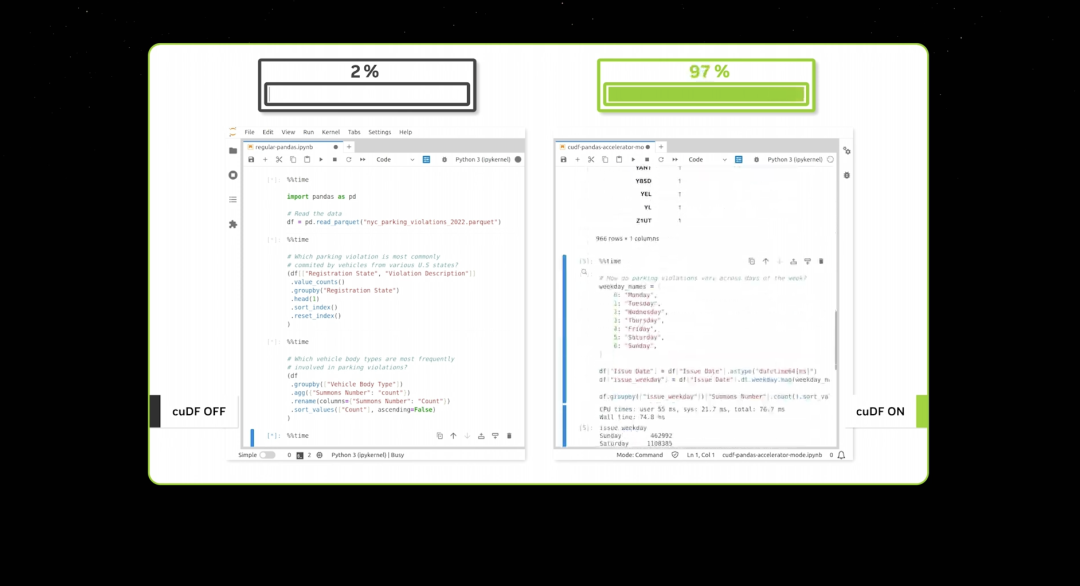
Quand le traitement de données devient aussi rapide, la démonstration ne prend pas longtemps. CUDA a maintenant atteint ce que l’on appelle un point critique — et même mieux : il est entré dans un cercle vertueux.
Cela est rare. Regardons l’histoire de toutes les plates-formes d’architecture informatique. Prenons le microprocesseur CPU, existant depuis 60 ans sans changement fondamental à ce niveau. Créer une nouvelle plateforme autour du calcul accéléré est extrêmement difficile, car on tombe dans le dilemme du « chien qui se mord la queue ».
Sans développeurs utilisant votre plateforme, il n’y a pas d’utilisateurs. Mais sans utilisateurs, pas de base installée. Sans base installée, les développeurs ne s’y intéressent pas. Les développeurs veulent écrire pour de grandes bases installées, mais celles-ci nécessitent de nombreuses applications pour attirer les utilisateurs et créer cette base.
Ce cercle vicieux est rarement brisé. NVIDIA y est parvenu en 20 ans, une bibliothèque après l’autre, une bibliothèque accélérée après l’autre. Aujourd’hui, 5 millions de développeurs dans le monde utilisent la plateforme NVIDIA.
NVIDIA dessert tous les secteurs — santé, services financiers, industrie automobile, informatique — pratiquement tous les grands secteurs, presque tous les domaines scientifiques. Avec autant de clients, les fabricants OEM et fournisseurs de cloud s’intéressent à construire des systèmes NVIDIA. De bons fabricants, comme ceux présents à Taïwan, veulent construire des systèmes NVIDIA, ce qui offre davantage de choix sur le marché, créant ainsi de nouvelles opportunités pour amplifier notre échelle et notre recherche-développement, accélérant davantage les applications.
À chaque accélération d’application, le coût du calcul baisse. Une accélération par 100 correspond à une économie de 97 %, 96 %, 98 %. Quand nous passons d’une accélération par 100 à 200, puis à 1000, le coût marginal du calcul continue de diminuer.
NVIDIA croit que, grâce à la baisse drastique du coût du calcul, les marchés, développeurs, scientifiques et inventeurs découvriront toujours plus d’algorithmes consommant toujours plus de ressources de calcul, menant à un saut qualitatif : le coût marginal du calcul devient si bas qu’un nouveau mode d’utilisation du calcul émerge.
C’est exactement ce que nous observons aujourd’hui. Au cours des 10 dernières années, NVIDIA a réduit d’un million de fois le coût marginal du calcul pour certains algorithmes spécifiques. Aujourd’hui, entraîner un modèle de langage (LLM) contenant toutes les données d’Internet est raisonnable et courant — personne n’en doute. L’idée qu’un ordinateur puisse traiter autant de données pour écrire ses propres logiciels est devenue plausible. L’IA est apparue parce que nous croyions fermement que, si le calcul devient suffisamment bon marché, quelqu’un finira par en trouver un usage extraordinaire.
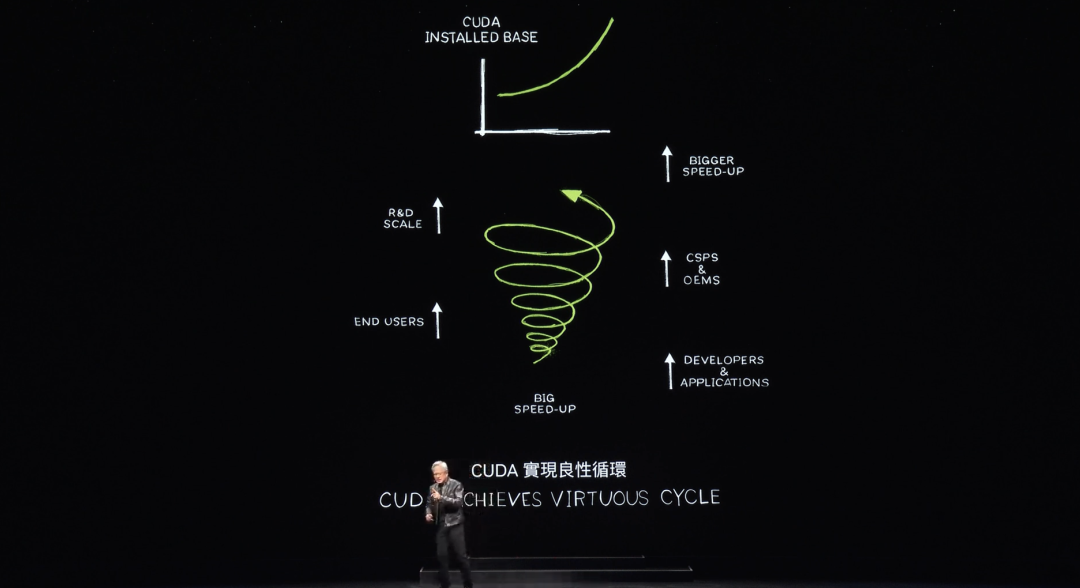
Aujourd’hui, CUDA est entré dans un cercle vertueux. La base installée croît, le coût du calcul baisse, attirant plus de développeurs avec de nouvelles idées, stimulant davantage la demande. Nous sommes maintenant à un point de départ crucial.
Jensen Huang aborde ensuite l’idée de la Terre 2, la création d’un jumeau numérique de la Terre. En simulant la Terre, nous pourrons mieux prédire l’avenir, éviter les catastrophes, comprendre les effets du changement climatique et mieux nous adapter.

Les chercheurs ont découvert CUDA en 2012 — la première interaction de NVIDIA avec l’IA, une date très importante. Nous avons eu la chance de collaborer avec des scientifiques pour rendre l’apprentissage profond possible.
AlexNet a marqué une percée majeure en vision par ordinateur. Mais surtout, en reculant, il faut comprendre le contexte, les bases, et le potentiel à long terme de l’apprentissage profond. NVIDIA a réalisé que cette technologie avait un potentiel d’extension énorme. Un algorithme inventé il y a des décennies a soudain accompli des choses impossibles pour les algorithmes humains, grâce à plus de données, des réseaux plus grands, et surtout, bien plus de puissance de calcul.
Imaginez maintenant ce qui serait possible en allant plus loin : des architectures plus grandes, plus de données, plus de calcul. Après 2012, NVIDIA a modifié l’architecture GPU en ajoutant des cœurs Tensor. NVIDIA a inventé NVLink — il y a dix ans — CUDA, puis TensorRT, NCCL, acquis Mellanox, TensorRT-ML, le serveur d’inférence Triton… Le tout intégré dans un nouvel ordinateur. Personne ne comprenait, personne ne demandait, personne ne saisissait sa signification.
Jensen Huang affirme être certain que personne n’en voulait. NVIDIA l’a annoncé au GTC, et OpenAI, une petite entreprise de San Francisco, a demandé à NVIDIA de leur en fournir un.
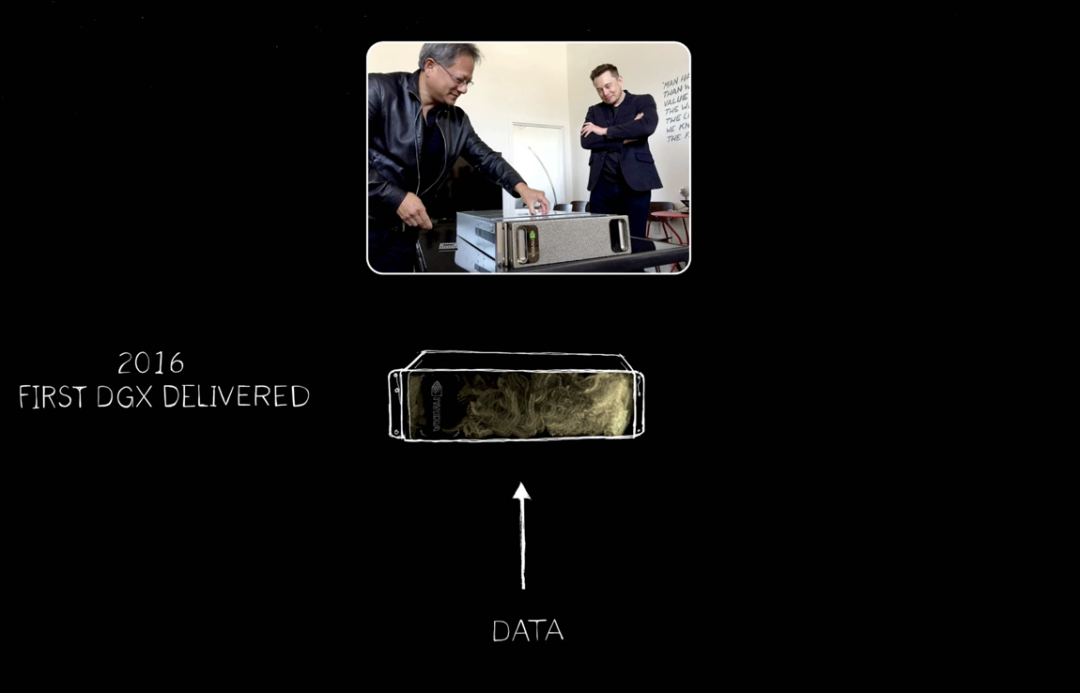
En 2016, Jensen Huang a livré à OpenAI le premier DGX, le premier supercalculateur d’IA au monde. Ensuite, nous avons continué à agrandir : d’un supercalculateur d’IA, d’un appareil d’IA, vers des supercalculateurs géants, encore plus grands.
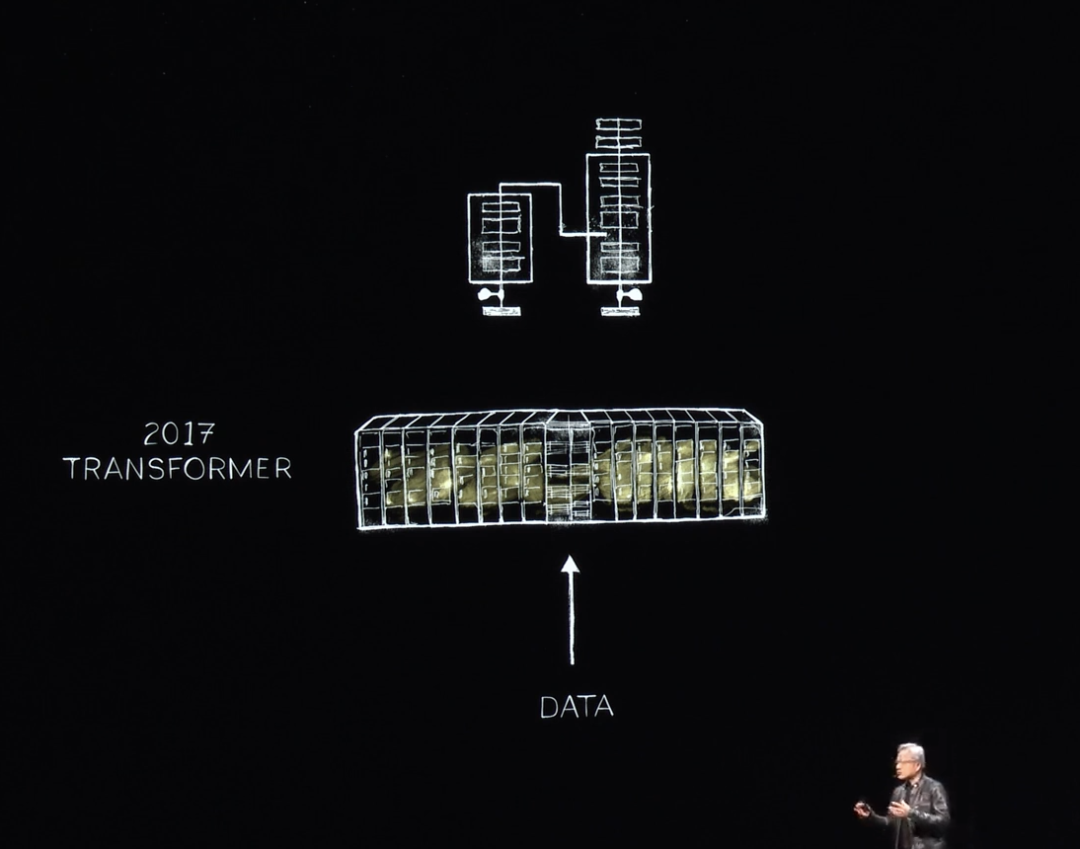
En 2017, le monde découvre le Transformer, permettant d’entraîner sur d’immenses quantités de données, reconnaissant et apprenant des motifs séquentiels longs. NVIDIA peut désormais entraîner ces LLM, les comprendre, et réaliser des percées en compréhension du langage naturel. Nous continuons, construisant des systèmes plus grands.
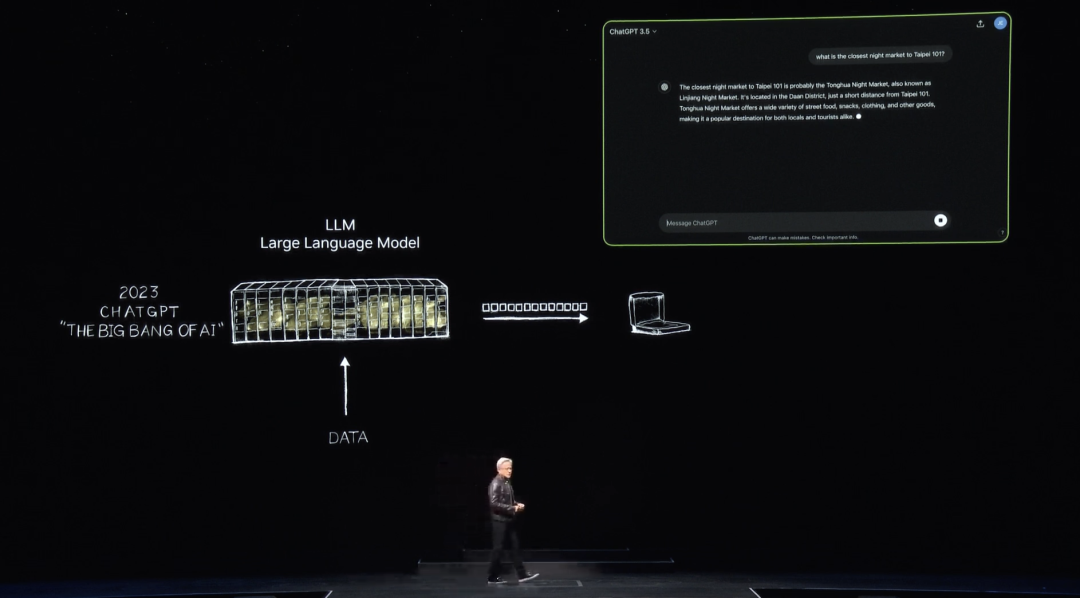
Puis, en novembre 2022, entraîné sur des milliers de GPU NVIDIA et d’énormes supercalculateurs d’IA, OpenAI lance ChatGPT — un million d’utilisateurs en cinq jours, cent millions en deux mois, devenant l’application à croissance la plus rapide de l’histoire.
Avant que ChatGPT ne soit présenté au monde, l’IA concernait la perception : compréhension du langage naturel, vision par ordinateur, reconnaissance vocale. Tout portait sur la perception et la détection. Pour la première fois, le monde découvrait l’IA générative : produire token après token, mot après mot. Bien sûr, ces tokens peuvent désormais être des images, diagrammes, tableaux, chansons, mots, voix, vidéos. Un token peut être n’importe quoi ayant un sens — un token chimique, protéique, génétique. Ce que vous avez vu précédemment dans le projet Terre 2, c’était la génération de tokens météorologiques.
Nous pouvons comprendre, apprendre la physique. Si vous pouvez apprendre la physique, vous pouvez enseigner la physique à un modèle d’IA. Le modèle peut en comprendre le sens, puis en générer. Nous pouvons le réduire à 1 km, non pas par filtrage, mais par génération. Ainsi, nous pouvons générer presque tout type de token utile. Nous pouvons générer des commandes de volant pour une voiture, des mouvements pour un bras robotique. Tout ce que nous pouvons apprendre peut désormais être généré.
Usines d’IA
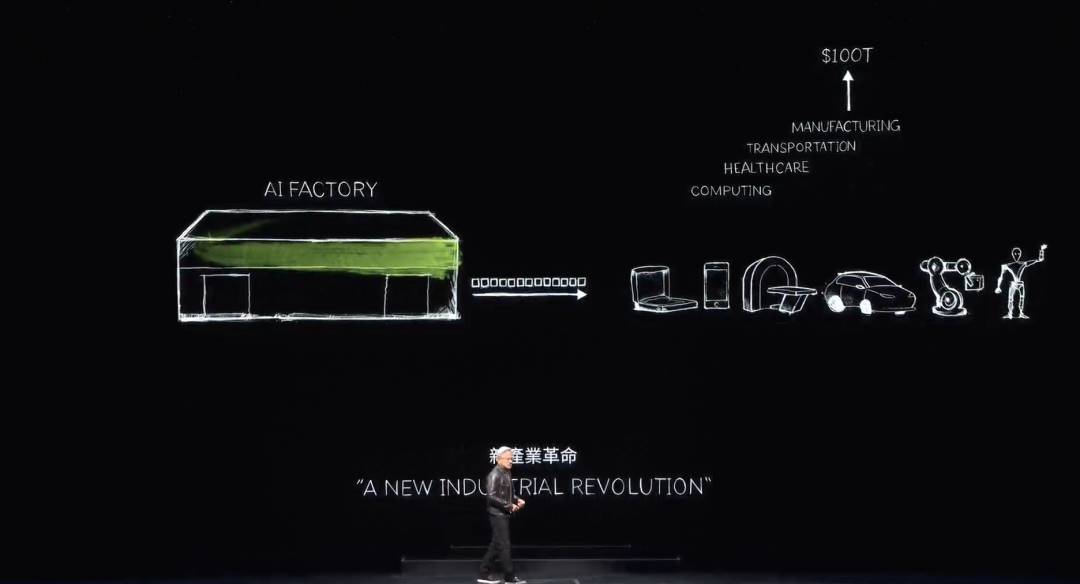
Nous sommes désormais entrés dans l’ère de l’IA générative. Mais ce qui compte vraiment, c’est que cet ordinateur, initialement un supercalculateur, s’est transformé en un centre de données produisant une seule chose : des tokens. C’est une usine d’IA, générant, créant et produisant une nouvelle marchandise d’une valeur exceptionnelle.
À la fin des années 1890, Nikola Tesla a inventé l’alternateur. NVIDIA a inventé le générateur d’IA. L’alternateur produit des électrons ; le générateur d’IA de NVIDIA produit des tokens. Ces deux produits ont un énorme potentiel sur le marché, interchangeables dans presque tous les secteurs. Voilà pourquoi nous sommes à l’aube d’une nouvelle révolution industrielle.
NVIDIA possède désormais une nouvelle usine produisant pour chaque secteur une nouvelle marchandise d’une valeur extraordinaire. Cette méthode est hautement scalable et reproductible.
Observez combien de modèles d’IA générative différents sont inventés chaque jour. Chaque secteur afflue maintenant. Pour la première fois, l’industrie IT, valorisée à 3 000 milliards de dollars, crée quelque chose qui peut directement servir des industries de 100 000 milliards. Ce n’est plus simplement un outil de stockage ou de traitement de données, mais une usine générant de l’intelligence pour chaque secteur. Cela deviendra une industrie manufacturière, mais pas de matériel informatique — une industrie utilisant l’informatique pour fabriquer.
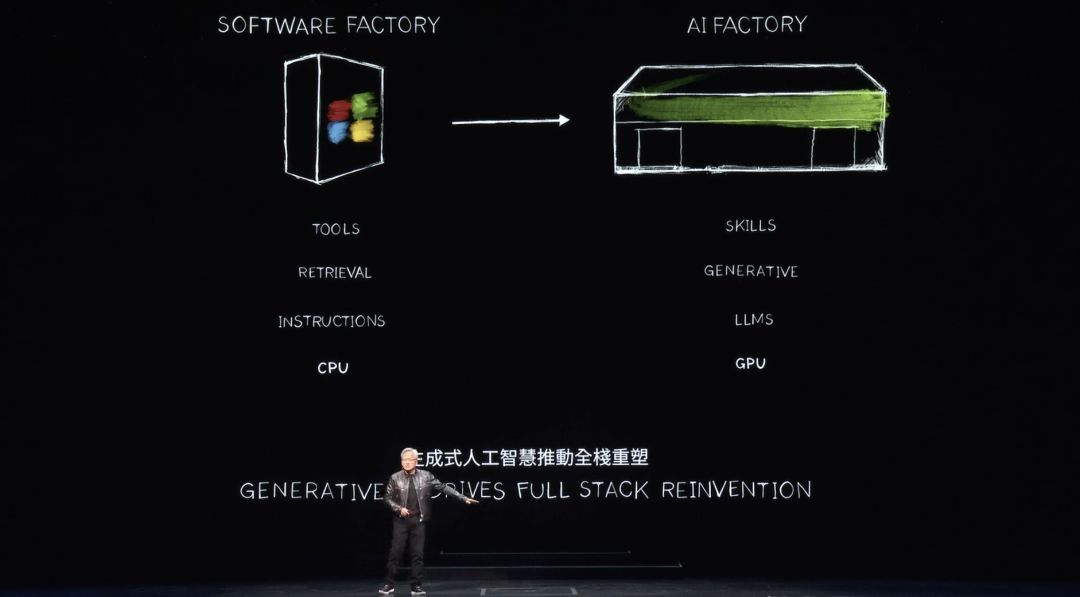
Cela ne s’était jamais produit auparavant. Le calcul accéléré a amené l’IA, puis l’IA générative, et maintenant une révolution industrielle. L’impact sur les secteurs est également marquant : créer une nouvelle marchandise, un nouveau produit — les tokens — mais l’effet sur notre propre secteur est tout aussi profond.
Depuis 60 ans, chaque couche du calcul a changé : du CPU universel au calcul GPU accéléré. Les ordinateurs avaient besoin d’instructions. Désormais, ils traitent des LLM, des modèles d’IA. Le modèle de calcul passé était basé sur la récupération. Presque chaque fois que vous touchez votre téléphone, il récupère du texte, image ou vidéo pré-enregistré, le recompose via un système de recommandation et vous le présente.
Jensen Huang explique que les ordinateurs futurs généreront autant que possible, ne récupérant que l’information nécessaire. Car les données générées nécessitent moins d’énergie pour obtenir l’information. Elles sont aussi plus pertinentes contextuellement. Elles coderont la connaissance, vous comprendront. Vous ne demanderez plus à l’ordinateur d’aller chercher une information ou un fichier, mais de répondre directement à votre question. L’ordinateur ne sera plus un outil que vous utilisez, mais un agent générant des compétences et exécutant des tâches.
NIMs, Microservices d’Inférence NVIDIA

Plutôt qu’une industrie produisant des logiciels — une idée révolutionnaire au début des années 90. Souvenez-vous, l’idée de Microsoft de mettre les logiciels en boîte a révolutionné l’industrie PC. Sans logiciels emballés, que ferions-nous des PC ? Cela a propulsé l’industrie. Maintenant, NVIDIA a une nouvelle usine, un nouvel ordinateur. Nous y ferons tourner un nouveau type de logiciel, appelé NIMs — microservices d’inférence NVIDIA.
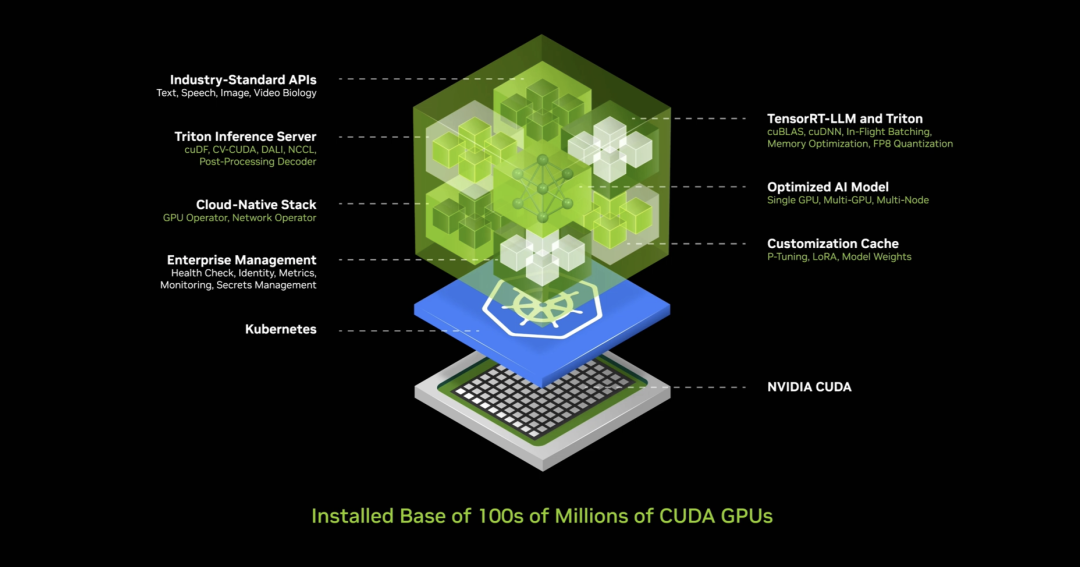
Les NIMs fonctionnent à l’intérieur de cette usine. Un NIM est un modèle pré-entraîné — une IA. Cette IA elle-même est très complexe, mais la pile de calcul derrière elle l’est encore plus. Quand vous utilisez ChatGPT, la pile logicielle derrière est immense. Les prompts sont gérés par une foule de logiciels extrêmement complexes, car le modèle comporte des milliards, voire des trillions de paramètres. Il ne tourne pas sur un seul ordinateur, mais sur plusieurs. Il faut répartir la charge entre plusieurs GPU, utilisant parallélisme tensoriel, par pipeline, par données, par experts — toutes sortes de parallélismes — afin de le traiter le plus rapidement possible.
Car dans une usine, le débit est directement lié aux revenus. Il est directement lié à la qualité du service, et au nombre de personnes pouvant utiliser votre service.
Nous vivons désormais dans un monde où l’utilisation du débit des centres de données est cruciale. Avant, c’était important, mais pas autant qu’aujourd’hui. Avant, c’était important, mais on ne le mesurait pas. Aujourd’hui, chaque paramètre est mesuré : temps de démarrage, temps d’exécution, taux d’utilisation, débit, temps d’inactivité, etc., car c’est une usine. Quand quelque chose est une usine, son fonctionnement est directement lié aux performances financières de l’entreprise — ce qui est extrêmement complexe pour la plupart des entreprises.

Alors, que fait NVIDIA ? Elle crée cette « boîte IA », un conteneur rempli de logiciels. À l’intérieur, CUDA, cuDNN, TensorRT, le serveur d’inférence Triton. C’est natif cloud, pouvant s’auto-évoluer dans Kubernetes. Il inclut des services de gestion et des points d’ancrage pour surveiller votre IA. Il possède des API standards, universelles — vous pouvez discuter avec cette boîte. Téléchargez ce NIM, parlez-lui — dès que vous avez CUDA sur votre machine, ce qui est désormais omniprésent. Disponible dans tous les clouds, auprès de tous les fabricants d’ordinateurs. Présent sur des centaines de millions de PC. Tous les logiciels sont intégrés, 400 dépendances regroupées en une seule.
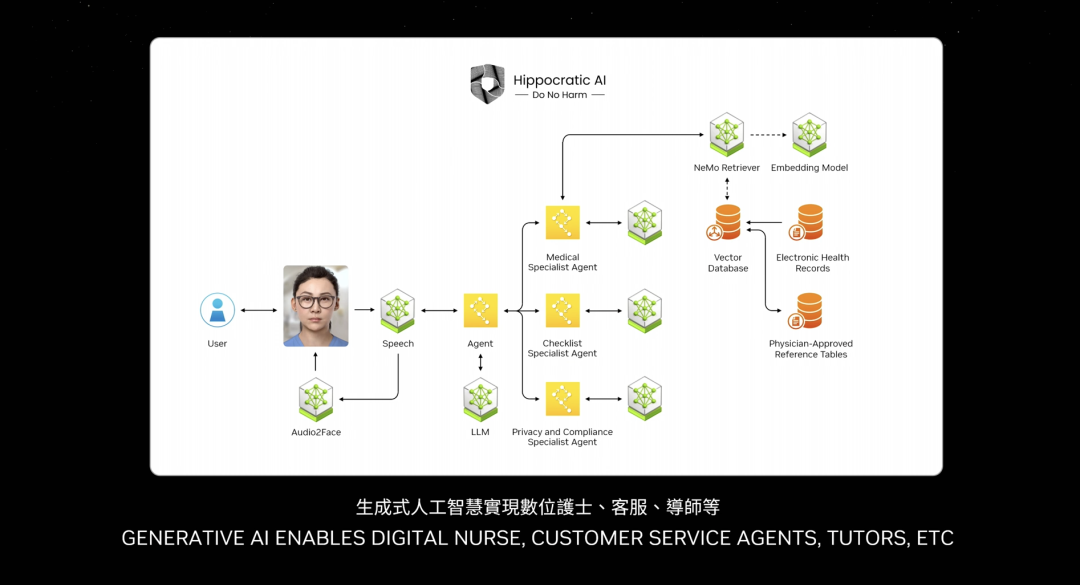
NVIDIA teste chaque NIM, chaque modèle pré-entraîné, sur toute la base installée — toutes les versions Pascal, Ampere, Hopper, et bien d’autres. J’ai même oublié certains noms. Une invention incroyable — l’une de mes préférées.
Jensen Huang précise que NVIDIA propose différentes versions, selon le langage, la vision, l’image, la santé, la biologie numérique, les humains numériques — rendez-vous sur ai.nvidia.com.
Il ajoute que NVIDIA vient de publier sur HuggingFace un NIM Llama3 entièrement optimisé, disponible gratuitement pour essai — vous pouvez même l’emporter. Exécutez-le dans le cloud, dans n’importe quel cloud. Téléchargez ce conteneur, installez-le dans votre propre centre de données, et mettez-le à disposition de vos clients.
NVIDIA propose des versions pour divers domaines : physique, recherche sémantique (RAGs), vision-langage, différentes langues. Vous les utilisez en connectant ces microservices à de grandes applications.
L’une des applications les plus importantes à venir concerne le service client. Presque tous les secteurs ont besoin d’agents. Cela représente des milliers de milliards de dollars en service client. Même les infirmières sont, en un sens, des agents de service client — certaines consultations non diagnostiques relèvent du service client en vente au détail, restauration rapide, finance, assurance. Des dizaines de millions de postes de service client peuvent désormais être renforcés par des modèles linguistiques et l’IA. Ces « boîtes » que vous voyez sont fondamentalement des NIMs.
Certains NIMs sont des agents d’inférence : recevant une tâche, la définissant, la décomposant en un plan. D’autres NIMs récupèrent des informations. Certains effectuent des recherches. D’autres utilisent des outils — comme cuOpt mentionné par Jensen Huang. Ils peuvent utiliser des outils tournant sur SAP, apprenant ainsi un langage spécifique comme ABAP. Peut-être que certains NIMs doivent exécuter des requêtes SQL. Tous ces NIMs sont des experts, désormais assemblés en équipe.
Que change-t-il ? La couche applicative change. Les applications écrites avec des instructions deviennent des applications assemblant des équipes d’IA. Peu savent écrire des programmes, mais presque tout le monde sait décomposer un problème et constituer une équipe. Je crois que chaque entreprise aura bientôt une large collection de NIMs. Vous téléchargerez les experts dont vous avez besoin, les relierez en équipe — vous n’aurez même pas besoin de savoir précisément comment les connecter. Confiez simplement la tâche à un agent, un NIM, qui déterminera comment la distribuer. L’agent chef d’équipe décomposera la tâche, l’assignera aux membres, qui l’exécuteront, renverront les résultats, et l’agent chef raisonnera sur les résultats pour vous les présenter — comme un humain. C’est l’avenir proche, la future forme des applications.
Bien sûr, vous interagirez avec ces grands services IA via des prompts textuels ou vocaux. Mais de nombreuses applications souhaitent interagir sous forme humaine. NVIDIA appelle cela les humains numériques, et travaille activement sur cette technologie.
Jensen Huang poursuit : les humains numériques pourraient devenir d’excellents agents interactifs, rendant les interactions plus engageantes, plus empathiques. Bien sûr, il faut franchir un grand fossé du réalisme, pour que les humains numériques paraissent plus naturels. Imaginez un futur où les ordinateurs interagissent avec nous comme des humains. C’est la réalité stupéfiante des humains numériques. Ils transformeront radicalement des secteurs allant du service client à la publicité et aux jeux. Les possibilités sont infinies.
Utilisant les données de scan de votre cuisine actuelle, via votre téléphone, ils deviendront des designers d’intérieur IA, générant de belles suggestions photoréalistes, avec sources de matériaux et meubles.
NVIDIA a déjà généré plusieurs options de design à choisir. Ils deviendront aussi des agents IA de service client, rendant les interactions plus vivantes et personnalisées, ou des travailleurs médicaux numériques, examinant les patients, prodiguant des soins immédiats et personnalisés. Ils deviendront même des ambassadeurs de marque IA, lançant la prochaine vague de marketing et de publicité.
Les nouvelles percées en IA générative et synthèse d’images permettent aux humains numériques de voir, comprendre et interagir avec nous de manière humaine. D’après ce que je vois, vous êtes peut-être dans un studio d’enregistrement ou de production. La base des humains numériques repose sur des modèles d’IA capables de reconnaissance et synthèse vocale multilingue, et de comprendre et générer du dialogue via des modèles LLM.
Ces IA sont connectées à une autre IA générative, animant dynamiquement une grille faciale 3D réaliste. Enfin, le modèle IA reproduit une apparence réaliste, avec suivi de chemin en temps réel et diffusion subsurface, simulant comment la lumière pénètre la peau, se disperse et ressort en différents points, donnant à la peau un aspect doux et translucide.
NVIDIA ACE est un ensemble de technologies d’humains numériques, empaquetées en microservices entièrement optimisés et faciles à déployer — des NIMs. Les développeurs peuvent intégrer les NIMs ACE dans leurs cadres, moteurs et expériences d’humains numériques existants. Les NIMs SLM et LLM comprennent nos intentions et coordonnent les autres modèles.
Les NIMs Riva Speech pour la parole interactive et la traduction, les NIMs Audio to Face et Gesture pour l’animation faciale et corporelle, Omniverse RTX avec DLSS pour le rendu neural des cheveux et de la peau.
Vraiment incroyable. Ces ACE peuvent fonctionner dans le cloud ou sur PC, et sont inclus dans tous les GPU RTX équipés de cœurs Tensor — NVIDIA vend donc déjà des GPU IA, préparant ce jour. La raison est simple : pour créer une nouvelle plateforme de calcul, il faut d’abord une base installée.
Finalement, les applications viendront. Sans base installée, comment les applications pourraient-elles apparaître ? Donc, si vous construisez, ils viendront peut-être. Mais si vous ne construisez pas, ils ne peuvent pas venir. C’est pourquoi NVIDIA intègre des processeurs à cœurs Tensor dans chaque GPU RTX. NVIDIA a déjà 100 millions de PC GeForce RTX IA dans le monde, et en expédie 200 millions.
Lors de ce Computex, NVIDIA a présenté quatre nouveaux ordinateurs portables impressionnants. Tous peuvent exécuter de l’IA. Les futurs portables, PC, seront eux-mêmes des IA. Ils vous aideront en continu en arrière-plan. Les PC exécuteront aussi des applications renforcées par l’IA.
Bien sûr, tous vos outils — retouche photo, rédaction — seront renforcés par l’IA. Votre PC hébergera aussi des applications IA avec des humains numériques. L’IA se manifestera et sera utilisée de multiples façons dans le PC. Le PC deviendra une plateforme IA très importante.
Vers où allons-nous maintenant ? J’ai parlé de l’expansion des centres de données. À chaque expansion, nous découvrons un nouveau bond. En passant du DGX au supercalculateur d’IA géant, NVIDIA a permis d’entraîner le Transformer sur d’énormes jeux de données. Initialement, les données étaient supervisées manuellement, nécessitant une annotation humaine pour entraîner l’IA. Malheureusement, les données annotées par l’homme sont limitées.
Le Transformer a rendu l’apprentissage non supervisé possible. Désormais, le Transformer peut analyser d’immenses quantités de données, vidéos ou images, trouvant seul des motifs et relations.
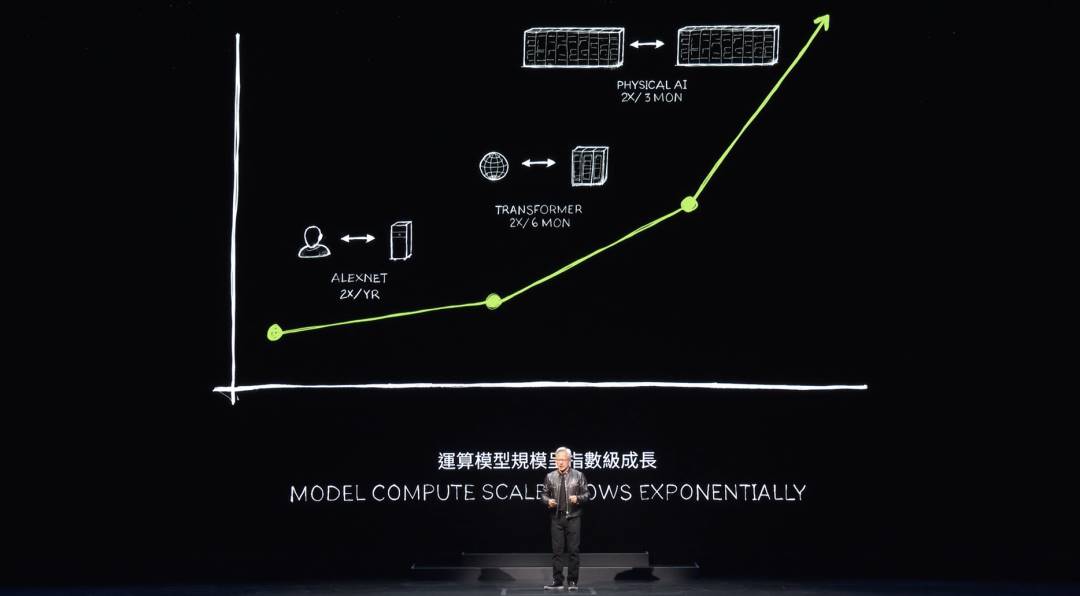
La prochaine génération d’IA devra être basée sur la physique. La plupart des IA actuelles ne comprennent pas les lois physiques ; elles ne sont pas ancrées dans le monde physique. Pour générer des images, vidéos, graphismes 3D et bien des phénomènes physiques, nous avons besoin d’IA basées sur la physique et connaissant ses lois. On peut y parvenir par apprentissage vidéo — une source.
Une autre méthode utilise des données synthétiques, simulées. Une autre consiste à faire apprendre les ordinateurs entre eux. Cela ressemble à AlphaGo s’affrontant à lui-même : en s’entraînant contre des adversaires de même niveau, ils deviennent plus intelligents. Vous commencerez à voir ce type d’IA apparaître.
Si les données d’IA sont générées synthétiquement et utilisent l’apprentissage par renforcement, la vitesse de génération de données continuera d’augmenter. À chaque augmentation de la génération de données, la puissance de calcul requise doit aussi croître.
Nous arrivons à un stade où l’IA pourra apprendre les lois physiques et s’ancrer dans des données issues du monde physique. NVIDIA prévoit donc que les modèles continueront de croître, et que nous aurons besoin de GPU plus grands.
Blackwell

Blackwell est conçu pour cette génération, doté de plusieurs technologies cruciales. D’abord, la taille de la puce. NVIDIA fabrique chez TSMC la plus grande puce, reliant deux puces par une connexion de 10 To/s — le SerDes le plus avancé au monde relie ces deux puces. Puis NVIDIA place deux puces dans un nœud de calcul, reliées par un CPU Grace.
Le CPU Grace a plusieurs usages. En entraînement, il permet des points de reprise rapides. En inférence et génération, il stocke la mémoire contextuelle, permettant à l’IA de comprendre le contexte de votre conversation. C’est le deuxième moteur Transformer de NVIDIA, ajustant dynamiquement la précision selon les besoins du calcul.
C’est la deuxième génération de GPU avec IA sécurisée, permettant aux fournisseurs de service de protéger l’IA contre le vol ou la falsification. C’est le cinquième NVLink, permettant de relier plusieurs GPU — j’y reviendrai.
C’est le premier GPU de NVIDIA doté d’un moteur de fiabilité et disponibilité (RAS). Ce système permet de tester chaque transistor, déclencheur, mémoire on-chip et off-chip, détectant sur site une éventuelle panne. Dans un supercalculateur de 10 000 GPU, l’intervalle moyen entre pannes est de l’ordre de l’heure. Dans un supercalculateur de 100 000 GPU, il est de l’ordre de la minute.
Sans technologie améliorant la fiabilité, il serait presque impossible de faire fonctionner longtemps un supercalculateur pour entraîner des modèles pendant des mois. La fiabilité améliore le temps de fonctionnement, impactant directement les coûts. Enfin, un moteur de décompression : le traitement des données est l’une des tâches les plus cruciales. NVIDIA ajoute un moteur de compression/décompression, permettant d’extraire les données du stockage 20 fois plus vite qu’actuellement.

Blackwell est en production, avec d’innombrables technologies. Chaque puce Blackwell, composée de deux puces reliées, est la plus grande puce au monde. Reliées à 10 To/s, les performances sont stupéfiantes.
Chaque génération de calcul de NVIDIA multiplie par 1000 la puissance de calcul en virgule flottante. La loi de Moore croît d’environ 40 à 60 fois en huit ans. Durant ces huit dernières années, la croissance de la loi de Moore a fortement ralenti. Même à son meilleur, elle ne peut rivaliser avec la performance de Blackwell.
Le volume de calcul est colossal. À chaque hausse de puissance, le coût baisse. En augmentant la puissance, NVIDIA a réduit la demande énergétique pour entraîner GPT-4 de 1000 GWh à 3 GWh. Pascal nécessitait 1000 GWh. 1000 GWh signifie un centre de données de 1 GW. Aucun centre de données de 1 GW n’existe. S’il en existait un, il fonctionnerait un mois. Avec un centre de 100 MW, cela prendrait environ un an. Personne ne construirait une telle infrastructure.
C’est pourquoi, il y a huit ans, un LLM comme ChatGPT était impossible. En améliorant la performance et l’efficacité énergétique, NVIDIA a réduit la demande énergétique de Blackwell de 1000 GWh à 3 GWh — une progression incroyable. Avec 10 000 GPU, cela prend quelques jours — environ 10 jours. Les progrès en huit ans sont stupéfiants.
Ceci concerne l’inférence et la génération de tokens. Générer un token GPT-4 demande l’énergie de deux ampoules fonctionnant deux jours. Générer un mot demande environ trois tokens. Ainsi, générer GPT-4 avec Pascal et offrir l’expérience ChatGPT était presque impossible. Désormais, chaque token consomme seulement 0,4 joule, permettant une génération extrêmement économe.

Blackwell est un énorme bond
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












