

Vitalik : Qu'est-ce que le Danksharding ?
TechFlow SélectionTechFlow Sélection
Vitalik : Qu'est-ce que le Danksharding ?
Danksharding est une nouvelle conception de sharding proposée pour Ethereum. Quels avantages cette technologie pourrait-elle apporter ?
Auteur : Vitalik Buterin
Qu'est-ce que le Danksharding ?
Le Danksharding est une nouvelle conception du sharding proposée pour Ethereum, introduisant plusieurs simplifications notables par rapport aux conceptions antérieures.
Toutes les propositions récentes de sharding d'Ethereum depuis 2020 (y compris le Danksharding et ses prédécesseurs) diffèrent des autres propositions non-Ethereum principalement par sa feuille de route centrée sur les Rollups : le sharding d'Ethereum ne fournit pas davantage d'espace pour les transactions, mais pour des données que le protocole Ethereum lui-même n'essaie pas d'interpréter. La validation des blobs consiste simplement à vérifier la disponibilité des blobs, c’est-à-dire qu’ils peuvent être téléchargés depuis le réseau. L’espace dans ces blobs sera utilisé par des protocoles Rollup de couche 2 (Layer 2) permettant des transactions à haut débit.
L'innovation principale introduite par le Danksharding est la fusion des marchés de frais : plus de nombre fixe de shards avec chacun leur bloc et leur proposeur de bloc ; dans le Danksharding, un seul proposeur sélectionne toutes les transactions et toutes les données entrant dans ce slot.
Pour éviter des exigences systémiques trop élevées pour les validateurs dans cette conception, nous introduisons la séparation Proposer/Builder (PBS) : une catégorie spéciale d’acteurs appelés « block builders » enchérissent pour le droit de choisir le contenu d’un slot, tandis que le proposeur doit seulement sélectionner l’en-tête valide avec la plus haute offre. Seul le builder a besoin de traiter l’intégralité du bloc (on peut aussi utiliser ici un oracle décentralisé tiers pour implémenter un builder distribué) ; tous les autres validateurs et utilisateurs peuvent valider efficacement le bloc via l’échantillonnage de disponibilité des données (rappelons que la partie « volumineuse » du bloc est juste des données).
Qu'est-ce que le proto-danksharding (alias EIP-4844) ?
Le proto-danksharding (alias EIP-4844) est une proposition d'amélioration d'Ethereum (EIP) qui implémente la majorité de la logique et de la « structure » du spécification complète de Danksharding (par exemple, format des transactions, règles de validation), sans toutefois implémenter réellement le sharding. Dans cette implémentation, tous les validateurs et utilisateurs doivent encore valider directement la disponibilité complète des données.
La caractéristique principale introduite par le proto-danksharding est un nouveau type de transaction, appelé transaction avec blob. Une telle transaction ressemble à une transaction normale, sauf qu’elle transporte des données supplémentaires appelées « blob ». Un blob est très grand (~125 Ko) et bien moins coûteux que la même quantité de calldata. Toutefois, l’exécution EVM ne peut pas accéder aux données du blob ; l’EVM ne voit que l’engagement (commitment) vers le blob.
Comme les validateurs et clients doivent toujours télécharger intégralement le contenu des blobs, l’objectif de bande passante dans le proto-danksharding est de 1 Mo par slot, et non 16 Mo complets. Cependant, comme ces données ne concurrencent plus l’utilisation de gaz des transactions existantes d’Ethereum, il existe quand même des gains significatifs en termes d’évolutivité.
Pourquoi ajouter 1 Mo de données que tout le monde doit télécharger est acceptable, alors que rendre le calldata 10 fois moins cher ne l’est pas ?
Cela concerne la différence entre charge moyenne et charge maximale. Aujourd’hui, la taille moyenne d’un bloc est d’environ 90 Ko, mais la taille théoriquement maximale d’un bloc (si les 30 M gas étaient entièrement utilisés pour du calldata) est d’environ 1,8 Mo. Le réseau Ethereum a déjà connu des blocs proches de cette taille maximale. Mais si nous réduisions simplement le coût en gaz du calldata par 10, bien que la taille moyenne des blocs reste acceptable, la situation la pire atteindrait 18 Mo, ce qui serait trop élevé pour le réseau Ethereum.
Le schéma actuel de tarification du gaz ne permet pas de séparer ces deux facteurs : le ratio entre charge moyenne et charge maximale dépend des choix des utilisateurs sur combien de gaz ils dépensent pour le calldata versus d'autres ressources, ce qui signifie que le prix du gaz doit être fixé selon le scénario le plus pessimiste, rendant la charge moyenne inutilement inférieure à ce que le système pourrait supporter. En revanche, en modifiant la tarification du gaz pour créer explicitement un marché multidimensionnel, on peut éviter cette inadéquation et inclure par bloc une quantité de données proche du maximum que nous pouvons traiter en toute sécurité. Le proto-danksharding et l’EIP-4488 sont deux propositions allant dans ce sens.

Comment se compare le proto-danksharding à l’EIP-4488 ?
L’EIP-4488 est une tentative antérieure et plus simple de résoudre ce problème de désajustement entre cas moyen et cas extrême. L’EIP-4488 utilise deux règles simples :
Le coût en gaz du calldata passe de 16 gaz par octet à 3 gaz par octet
Une limite de 1 Mo par bloc plus 300 octets par transaction supplémentaire (maximum théorique : ~1,4 Mo)
La limite stricte est la manière la plus simple d’empêcher une forte augmentation de la charge moyenne de conduire à une explosion de la charge maximale. La réduction du coût en gaz augmentera fortement l’utilisation des rollups, portant potentiellement la taille moyenne des blocs à plusieurs centaines de Ko, mais la limite stricte empêchera directement la possibilité d’un bloc de 10 Mo. En fait, la taille maximale du bloc deviendrait plus petite qu’aujourd’hui (1,4 Mo contre 1,8 Mo).
Le proto-danksharding, en revanche, crée un type de transaction distinct capable de transporter des données moins chères dans de gros blobs de taille fixe, et limite le nombre de blobs par bloc. Ces blobs ne sont pas accessibles depuis l’EVM (seul l’engagement vers le blob l’est), et sont stockés par la couche de consensus (la Beacon Chain) plutôt que par la couche d’exécution.
La principale différence pratique entre l’EIP-4488 et le proto-danksharding est que l’EIP-4488 cherche à minimiser les changements nécessaires aujourd’hui, tandis que le proto-danksharding implémente beaucoup de changements dès maintenant afin que la mise à niveau vers le sharding complet exige très peu de modifications ultérieurement. Bien que l’implémentation du sharding complet (avec échantillonnage de disponibilité des données, etc.) soit une tâche complexe — et reste complexe après le proto-danksharding — cette complexité est contenue au niveau de la couche de consensus. Une fois le proto-danksharding lancé, les équipes clientes d’exécution, les développeurs de rollups et les utilisateurs n’auront plus aucun travail à faire pour compléter la transition vers le sharding complet.
Notez que le choix entre les deux n’est pas exclusif : nous pourrions implémenter l’EIP-4488 dès que possible, puis le suivre six mois plus tard avec le proto-danksharding.
Quelles parties du danksharding complet le proto-danksharding implémente-t-il, et quelles parties restent à implémenter ?
D’après l’EIP-4844 :
Les travaux déjà accomplis dans cet EIP incluent :
• Un nouveau type de transaction dont le format est exactement celui requis dans le « full sharding ».
• Toute la logique nécessaire au niveau de l’exécution pour le full sharding.
• Toute la logique de validation croisée entre exécution et consensus requise pour le full sharding.
• La séparation des couches entre la validation de BeaconBlock et l’échantillonnage de disponibilité des données des blobs.
• La majeure partie de la logique de BeaconBlock requise pour le full sharding.
• Un prix du gaz indépendant auto-régulé pour les blobs.
Les travaux restants pour atteindre le sharding complet incluent :
• L’extension de bas degré des blob_kzgs au niveau de la couche de consensus pour permettre l’échantillonnage 2D.
• L’implémentation effective de l’échantillonnage de disponibilité des données.
• La PBS (Proposer/Builder Separation), afin d’éviter d’exiger qu’un seul validateur traite 32 Mo de données en un seul slot.
• Des preuves de custody par validateur ou un mécanisme similaire intégré au protocole, pour vérifier chaque bloc une partie spécifique des données shardisées.
Notez que tous les travaux restants concernent uniquement la couche de consensus, et n’exigent aucun effort supplémentaire des équipes clientes d’exécution, des utilisateurs ou des développeurs de Rollup.
Que faire de la demande accrue en espace disque due à tous ces très grands blocs ?
L’EIP-4488 et le proto-danksharding entraînent tous deux une utilisation maximale à long terme d’environ 1 Mo par slot (12 secondes). Cela correspond à environ 2,5 To par an, bien supérieur au taux de croissance actuel d’Ethereum.
Dans le cas de l’EIP-4488, la solution requiert un mécanisme d’expiration historique (EIP-4444), où les clients n’ont plus besoin de stocker l’historique au-delà d’une certaine période (des durées allant d’un mois à un an ont été proposées).
Dans le cas du proto-danksharding, la couche de consensus peut implémenter une logique distincte supprimant automatiquement les données des blobs après une certaine durée (ex. : 30 jours), indépendamment de l’implémentation ou non de l’EIP-4444. Cependant, quelle que soit la solution choisie, il est fortement recommandé d’implémenter rapidement l’EIP-4444.
Ces deux stratégies limitent le surplus de charge disque pour les clients de consensus à quelques centaines de Go au maximum. À long terme, adopter un mécanisme d’expiration historique est essentiellement obligatoire : le sharding complet ajoutera environ 40 To de données d’historique par an en blobs, donc les utilisateurs ne pourront pratiquement en stocker qu’une petite fraction pendant une courte période. Il est donc préférable de fixer tôt cette attente.
Si les données sont supprimées après 30 jours, comment les utilisateurs accéderont-ils aux anciens blobs ?
L’objectif du protocole de consensus d’Ethereum n’est pas de garantir le stockage permanent de toute l’histoire. Il s’agit plutôt de fournir un tableau d’affichage temps réel hautement sécurisé, tout en laissant place à d’autres protocoles décentralisés pour le stockage à long terme. Ce tableau d’affichage garantit que les données publiées y restent disponibles suffisamment longtemps pour que tout utilisateur ou protocole de sauvegarde ait le temps de les récupérer et de les importer dans leurs propres applications ou protocoles.
En général, le stockage à long terme de l’historique est facile. Bien que 2,5 To par an soient trop lourds pour un nœud standard, cela reste très gérable pour des utilisateurs spécialisés : vous pouvez acheter de très grands disques durs à environ 20 $ par To, parfaitement abordable même pour un amateur. Contrairement au consensus N/2-sur-N, le stockage historique suit un modèle 1-sur-N : il suffit qu’un seul gardien des données soit honnête. Chaque donnée historique n’a donc besoin d’être stockée que quelques centaines de fois, et non par les milliers complets de nœuds validant le consensus en temps réel.
Quelques méthodes pratiques pour stocker l’historique et le rendre accessible :
Des protocoles spécifiques à une application (ex. : Rollups) pourraient exiger que leurs nœuds stockent la partie de l’historique liée à leur application. La perte de données historiques ne met pas en danger le protocole global, seulement l’application concernée. Il est donc logique que chaque application supporte elle-même le coût du stockage des données qui la concernent.
Stockage de l’historique via BitTorrent, par exemple : générer et distribuer quotidiennement un fichier de 7 Go contenant les données des blobs des blocs.
Le réseau Portal d’Ethereum (actuellement en développement) pourrait facilement être étendu pour stocker l’historique.
Les explorateurs de blocs, fournisseurs d’API et autres services de données pourraient stocker l’historique complet.
Des passionnés ou chercheurs effectuant des analyses de données pourraient stocker l’historique complet. Dans ce dernier cas, le stockage local procure une valeur importante car il facilite les calculs directs.
Des protocoles d’indexation tiers comme TheGraph pourraient stocker l’historique complet.
À des niveaux supérieurs d’historique (ex. : 500 To/an), le risque d’oubli de certaines données augmente (et le système de vérification de disponibilité devient plus tendu). Cela pourrait représenter la véritable limite d’évolutivité des blockchains shardisées. Toutefois, tous les paramètres proposés actuellement sont très loin de ce seuil.
Quel est le format des données blob, et comment sont-elles engagées ?
Un blob est un vecteur de 4096 éléments de champ, nombres dans la plage :
Mathématiquement, un blob est vu comme représentant un polynôme de degré < 4096 sur le corps fini de module donné.
L’engagement vers le blob est un engagement KZG, hashé de ce polynôme. Pourtant, du point de vue de l’implémentation, les détails mathématiques du polynôme ne sont pas importants. On aura simplement un vecteur de points de courbe elliptique (trusted setup de type Lagrange), et l’engagement KZG vers le blob sera une combinaison linéaire. D’après le code de l’EIP-4844 :
BLS_MODULUS est le module mentionné ci-dessus, et KZG_SETUP_LAGRANGE est le vecteur de points de courbe elliptique issu du trusted setup de type Lagrange. Pour les implémentateurs, il est raisonnable de le considérer pour l’instant comme une fonction de hachage spécialisée boîte noire.
Pourquoi utiliser un hachage du KZG plutôt que le KZG directement ?
L’EIP-4844 n’utilise pas directement le KZG pour représenter le blob, mais un hachage versionné : un seul octet 0x01 (indiquant cette version) suivi des 31 derniers octets du hachage SHA256 du KZG.
Cela vise la compatibilité EVM et future : les engagements KZG font 48 octets, alors que l’EVM manipule plus naturellement des valeurs de 32 octets. Si nous passions du KZG à autre chose (par exemple, pour la résistance quantique), l’engagement pourrait continuer à faire 32 octets.
Quels sont les deux précompilés introduits dans le proto-danksharding ?
Le proto-danksharding introduit deux précompilés : le précompilé de validation de blob et le précompilé d’évaluation de point.
Le précompilé de validation de blob est auto-explicatif : il prend comme entrées un hachage versionné et un blob, et vérifie que le hachage versionné fourni est bien un hachage valide du blob. Ce précompilé est destiné aux Optimistic Rollups. D’après l’EIP-4844 :
Un Optimistic Rollup n’a besoin de fournir les données sous-jacentes qu’au moment de soumettre une preuve de fraude. La fonction de soumission de preuve de fraude exigera que l’intégralité du blob frauduleux soit envoyée comme partie du calldata. Elle utilisera la fonction de validation de blob pour vérifier les données par rapport au hachage versionné précédemment soumis, puis procédera à la validation de la preuve de fraude comme aujourd’hui.
Le précompilé d’évaluation de point prend comme entrées un hachage versionné, une coordonnée x, une coordonnée y, et une preuve (l’engagement KZG du blob et la preuve d’évaluation KZG). Il vérifie la preuve pour s’assurer que P(x) = y, où P est le polynôme représenté par le blob ayant le hachage versionné donné. Ce précompilé est destiné aux ZK Rollups. D’après l’EIP-4844 :
Un ZK Rollup fournira deux engagements pour ses données de transactions ou d’incréments d’état : l’engagement KZG dans le blob, et un autre engagement utilisant le système de preuve interne au ZK Rollup. Il utilisera la preuve d’équivalence des engagements, via le précompilé d’évaluation de point, pour prouver que le KZG (qui garantit l’accès aux données) et son propre engagement référencent les mêmes données.
Notez que la plupart des designs majeurs d’Optimistic Rollup utilisent des schémas de fraude multi-tours, où le dernier tour nécessite peu de données. Par conséquent, il est imaginable qu’un Optimistic Rollup utilise aussi le précompilé d’évaluation de point au lieu de celui de validation de blob, ce qui serait plus économique.
À quoi ressemble le trusted setup KZG ?
Voir :
https://vitalik.ca/general/2022/03/14/trustedsetup.html
Description générale du fonctionnement du trusted setup powers-of-tau
https://github.com/ethereum/research/blob/master/trusted_setup/trusted_setup.py
Implémentation d'exemple pour tous les calculs importants liés au trusted setup
Dans notre cas particulier, le plan actuel est d’exécuter en parallèle quatre cérémonies de tailles différentes (n1=4096,n2=16), (n1=8192,n2=16), (n1=16834,n2=16) et (n1=32768,n2=16) (avec des secrets différents). Théoriquement, seule la première serait nécessaire, mais exécuter des tailles plus grandes améliore la flexibilité future en permettant d’augmenter la taille des blobs. Nous ne pouvons pas avoir un seul setup plus grand, car nous avons besoin d’une limite stricte sur le degré des polynômes pouvant être engagés, égale à la taille du blob.
Une approche pratique envisageable serait de partir du setup Filecoin, puis d’exécuter une cérémonie pour l’étendre. Plusieurs implémentations, y compris dans le navigateur, permettront à beaucoup de participants de s’impliquer.
Ne pourrait-on pas utiliser un autre schéma d’engagement sans trusted setup ?
Malheureusement, tout autre schéma que le KZG (par exemple IPA ou SHA256) rendrait la feuille de route du sharding plus difficile. Plusieurs raisons :
Les engagements non arithmétiques (comme les fonctions de hachage) ne sont pas compatibles avec l’échantillonnage de disponibilité des données, donc même dans ce cas, nous devrions passer au KZG lors de la transition vers le sharding complet.
L’IPA pourrait être compatible avec l’échantillonnage, mais conduirait à des schémas plus complexes et moins performants (par exemple, l’autoréparation et la construction distribuée de blocs deviendraient plus difficiles).
Ni le hachage ni l’IPA ne permettent une implémentation économique du précompilé d’évaluation de point. Ainsi, une implémentation basée sur le hachage ou l’IPA ne pourrait pas efficacement servir les ZK Rollups ni supporter les preuves de fraude bon marché dans les Optimistic Rollups multi-tours.
Par conséquent, malheureusement, les pertes de fonctionnalités et la complexité accrue d’un autre schéma que le KZG surpassent largement les risques associés au KZG lui-même. De plus, tout risque lié au KZG est circonscrit : une faille KZG n’affecterait que les Rollups et autres applications dépendant des blobs, et non le reste du système.
À quel point le KZG est-il « complexe » et « nouveau » ?
Les engagements KZG ont été présentés dans un article de 2010 et sont largement utilisés depuis 2019 dans les protocoles de type PLONK-ZK-SNARK. Toutefois, les mathématiques sous-jacentes au KZG sont une arithmétique relativement simple reposant sur les opérations de courbes elliptiques et les couplages.
La courbe spécifique utilisée est BLS12-381, inventée en 2002 par Barreto-Lynn-Scott. Les couplages de courbes elliptiques, nécessaires pour vérifier les engagements KZG, sont des mathématiques très complexes, inventées dans les années 1940 et appliquées à la cryptographie depuis les années 1990. Dès 2001, de nombreux algorithmes cryptographiques utilisant les couplages avaient été proposés.
Du point de vue de la complexité d’implémentation, le KZG n’est pas plus difficile que l’IPA : la fonction de calcul de l’engagement (voir ci-dessus) est identique, à l’exception d’un jeu différent de constantes de points de courbe elliptique. Le précompilé d’évaluation de point est plus complexe car il implique l’évaluation d’un couplage, mais les mathématiques sont les mêmes que celles déjà implémentées dans l’EIP-2537 (précompilés BLS12-381), et très proches de celles du précompilé de couplage bn128 (voir aussi : implémentation Python optimisée). Ainsi, l’implémentation de la vérification KZG ne nécessite pas de « nouveaux travaux » complexes.
Quelles sont les différentes composantes logicielles d’une implémentation du proto-danksharding ?
Il y a quatre composantes principales :
1. Changements de consensus au niveau de l’exécution (voir EIP) :
• Nouveau type de transaction contenant un blob
• Opcode produisant le hachage versionné du i-ème blob dans la transaction courante
• Précompilé de validation de blob
• Précompilé d’évaluation de point
2. Changements de consensus au niveau de la couche de consensus (voir ce dossier dans le dépôt) :
• Liste des KZG des blobs dans le BeaconBlockBody
• Mécanisme « sidecar », où le contenu complet des blobs est transmis séparément de BeaconBlock
• Vérification croisée entre le hachage versionné des blobs au niveau de l’exécution et les KZG des blobs au niveau du consensus
3. Mempool
• BlobTransactionNetworkWrapper (voir section réseau de l’EIP)
• Protection anti-DoS renforcée pour compenser la grande taille des blobs
4. Logique de construction de bloc
• Accepter les enveloppes de transactions du mempool, placer les transactions dans ExecutionPayload, insérer les KZG dans le corps du beacon block et du sidecar
• Gérer le marché de frais multidimensionnel
Notez que pour une implémentation minimale, nous n’avons pas besoin de mempool (nous pouvons compter sur un marché de bundles de couche 2), et qu’un seul client a besoin d’implémenter la logique de construction de bloc. Seuls les changements de consensus aux niveaux exécution et consensus exigent des tests de consensus étendus, relativement légers. Toute configuration intermédiaire entre cette implémentation minimale et un déploiement « complet » où tous les clients supportent production de blocs et mempool est possible.
À quoi ressemble le marché de frais multidimensionnel du proto-danksharding ?
Le proto-danksharding introduit un marché de frais EIP-1559 multidimensionnel, avec deux ressources — le gaz et les blobs — ayant chacune leur propre prix flottant et leur propre limite.
Autrement dit, deux variables et quatre constantes :

Les frais pour les blobs sont payés en gaz, mais c’est une quantité variable de gaz ajustée pour que, à long terme, le nombre moyen de blobs par bloc corresponde effectivement au nombre cible.
La nature bidimensionnelle signifie que les constructeurs de blocs feront face à un problème plus difficile : plutôt que de simplement accepter les transactions offrant les frais prioritaires les plus élevés jusqu’à épuisement ou atteinte de la limite de gaz, ils devront éviter simultanément deux limites différentes.
Exemple : supposons une limite de gaz à 70 et une limite de blobs à 40. Le mempool contient beaucoup de transactions suffisantes pour remplir un bloc, de deux types (le gaz de la tx inclut le gaz par blob) :
Frais prioritaires de 5 par gaz, 4 blobs, 4 gaz au total
Frais prioritaires de 3 par gaz, 1 blob, 2 gaz au total
Un mineur suivant naïvement l’algorithme « frais décroissants » remplirait le bloc avec 10 transactions du premier type (40 gaz), obtenant un revenu de 5 * 40 = 200 gaz. Comme ces 10 transactions atteignent la limite complète de blobs, il ne pourrait inclure aucune autre transaction. Or, la stratégie optimale consiste à prendre 3 transactions du premier type et 28 du second. Cela donne un bloc de 40 blobs et 68 gaz, pour un revenu de 5 * 12 + 3 * 56 = 228.

Les clients d’exécution doivent-ils maintenant implémenter des algorithmes complexes de sac à dos multidimensionnel pour optimiser leur production de blocs ? Non, pour plusieurs raisons :
L’EIP-1559 assure que la plupart des blocs n’atteignent aucune des limites, donc en pratique seuls quelques blocs rencontrent ce problème d’optimisation multidimensionnel. Quand le mempool n’a pas assez de transactions (payantes) pour atteindre une limite, tout mineur peut maximiser ses revenus en incluant toutes les transactions visibles.
En pratique, des heuristiques assez simples se rapprochent de l’optimum. Voir l’analyse d’Ansgar sur l’EIP-4488 pour des données à ce sujet.
La tarification multidimensionnelle n’est même pas la source principale de revenus apportée par la spécialisation — le MEV l’est. Les revenus MEV spécialisés (arbitrage sur DEX, liquidations, front-running de ventes NFT, etc.) représentent une grande part des « revenus extractibles » (frais prioritaires) : les revenus MEV spécialisés semblent en moyenne d’environ 0,025 ETH par bloc, contre environ 0,1 ETH en frais prioritaires totaux.
La séparation Proposer/Builder (PBS) est conçue précisément autour de la production de blocs hautement spécialisée. La PBS transforme la construction de bloc en une enchère, où des participants spécialisés peuvent miser pour le privilège de créer un bloc. Les validateurs ordinaires n’ont qu’à accepter la meilleure offre. Cela vise à empêcher l’économie d’échelle induite par le MEV de mener à la centralisation des validateurs, tout en traitant tous les problèmes rendant l’optimisation de la construction plus complexe.
Pour ces raisons, la dynamique plus complexe du marché de frais n’augmente pas significativement la centralisation ou les risques ; en fait, le principe plus large d’application pourrait même réduire le risque d’attaques DoS !
Comment fonctionne le mécanisme d’ajustement exponentiel des frais blob EIP-1559 ?
L’EIP-1559 actuel ajuste les frais de base b pour atteindre un niveau cible d’utilisation du gaz t, comme suit :

où b(n) est le frais de base du bloc courant, b(n+1) celui du prochain bloc, t la cible, u l’utilisation du gaz.
Un grand problème de ce mécanisme est qu’il ne vise pas réellement t. Supposons deux blocs successifs : u=0, puis u=2t. On obtient :

Bien que la moyenne d’utilisation égale t, le frais de base baisse de 63/64. Le frais de base ne se stabilise donc qu’au-dessus légèrement de t ; en pratique, environ 3 % au-dessus, bien que cela dépende de la variance.
Une formule meilleure est l’ajustement exponentiel :
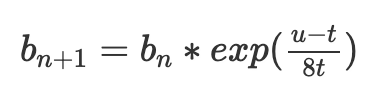
exp(x) est la fonction exponentielle e^x, avec e ≈ 2,71828. Pour de petites valeurs de x, exp(x) ≈ 1+x. Mais elle possède la propriété commode d’être indépendante de l’ordre des transactions : les ajustements multiples
dépendent uniquement de la somme u1+...+un, pas de leur distribution. Pour comprendre pourquoi, faisons les maths :
Ainsi, les mêmes transactions incluses donneront le même frais de base final, quelle que soit leur répartition entre blocs.
La dernière formule ci-dessus a aussi une interprétation mathématique naturelle : le terme (u1+u2+...+un - n·t) peut être vu comme l’excès : la différence entre le gaz total réellement utilisé et le gaz total prévu.
Le fait que le frais de base courant égale
montre clairement que cet excès ne peut pas sortir d’une plage très étroite : s’il dépasse 8t×60, le frais de base devient e^60, astronomiquement élevé, inabordable pour tous ; s’il descend en dessous de zéro, les ressources deviennent quasi gratuites et la chaîne subit un spam jusqu’à ce que l’excès remonte au-dessus de zéro.
Le mécanisme d’ajustement fonctionne exactement ainsi : il suit le total réel (u1+u2+...+un) et calcule le total cible (n·t), puis fixe le prix comme l’exponentielle de la différence. Pour simplifier le calcul, on n’utilise pas e^x mais 2^x ; en réalité, on utilise une approximation de 2^x : la fonction fake_exponential de l’EIP. Cette fausse exponentielle est presque toujours à moins de 0,3 % de la valeur réelle.
Pour éviter qu’une longue sous-utilisation ne cause une longue série de blocs pleins doublés, nous ajoutons une fonction supplémentaire : nous n’autorisons pas l’excès à descendre en dessous de zéro. Si le total réel est inférieur au total cible, nous fixons simplement le total réel égal au total cible. Dans des cas extrêmes (gas blob tombant à zéro), cela brise effectivement l’invariance d’ordre des transactions, mais le gain de sécurité justifie ce compromis. Notez aussi un résultat intéressant de ce marché multidimensionnel : au début du proto-danksharding, avec probablement peu d’utilisateurs, le coût d’un blob sera presque sûrement très bas pendant un certain temps, même si l’activité « normale » sur la blockchain Ethereum reste chère.
L’auteur pense que ce mécanisme d’ajustement des frais est meilleur que la méthode actuelle, et que finalement toutes les parties du marché de frais EIP-1559 devraient passer à son utilisation.
Pour une explication plus longue et détaillée, voir le billet de Dankrad.
Comment fonctionne fake_exponential ?
Par commodité, voici le code de fake_exponential :
Voici le mécanisme central exprimé mathématiquement, sans arrondis :
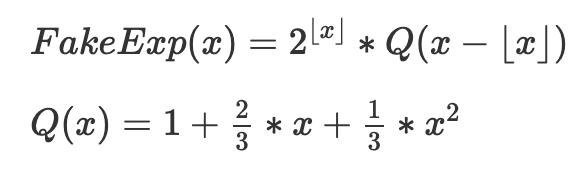
L’objectif est d’assembler plusieurs instances de (QX), chacune correctement décalée et agrandie pour chaque intervalle [2^k, 2^(k+1)]. Q(x) elle-même est une approximation de 2^x pour 0 ≤ x ≤ 1, choisie pour ses propriétés suivantes :
• Simplicité (c’est une équation quadratique)
• Exactitude au bord gauche (Q(0)=2^0=1)
• Exactitude au bord droit (Q(1)=2^1=2)
• Pente lisse (on assure Q’(1)=2×Q’(0), donc la pente de chaque copie décalée+redimensionnée de Q à son bord droit égale celle de la copie suivante à son bord gauche)
Les trois dernières conditions donnent trois équations linéaires à trois inconnues, dont Q(x) donné ci-dessus est la solution unique.
L’approximation est étonnamment bonne ; pour toutes les entrées sauf les plus petites, fake_exponential donne une réponse à moins de 0,3 % de la valeur réelle de 2^x :

Quels problèmes restent en débat dans le proto-danksharding ?
Note : cette section peut facilement devenir obsolète. Ne vous fiez pas à ses informations pour obtenir les idées les plus récentes sur un sujet donné.
Tous les principaux Optimistic Rollups utilisent des preuves multi-tours, donc ils peuvent utiliser le précompilé d’évaluation de point (bien moins cher) au lieu de celui de validation de blob. Quiconque aurait vraiment besoin de la validation de blob pourrait l’implémenter soi-même : prenant le blob D et le hachage versionné h comme entrées, choisir x=hash(D,h), calculer y=D(x) via évaluation barycentrique, puis utiliser le précompilé d’évaluation de point pour vérifier h(x)=y. Avons-nous vraiment besoin du précompilé de validation de blob, ou pouvons-nous simplement le supprimer et n’utiliser que l’évaluation de point ?
Jusqu’où la chaîne peut-elle gérer des blocs persistants de 1 Mo ou plus à long terme ? Si le risque est trop élevé, faut-il réduire le nombre cible de blobs dès le départ ?
Les blobs doivent-ils être tarifés en gaz ou en ETH (brûlés) ? Faut-il d’autres ajustements au marché de frais ?
Faut-il considérer le nouveau type de transaction comme un blob ou un objet SSZ, et dans ce dernier cas modifier ExecutionPayload en un type union ? (C’est un compromis entre « faire plus de travail maintenant » et « faire plus de travail plus tard »)
Les détails exacts de l’implémentation du trusted setup (techniquement hors du périmètre de l’EIP lui-même, car pour les implémentateurs ce setup « n’est qu’une constante », mais qui doit quand même être réalisé).
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














