

Analyse de BitVM : comment valider des preuves de fraude sur la chaîne BTC ? (exécution d'opcodes EVM ou d'autres machines virtuelles)
TechFlow SélectionTechFlow Sélection
Analyse de BitVM : comment valider des preuves de fraude sur la chaîne BTC ? (exécution d'opcodes EVM ou d'autres machines virtuelles)
BitVM ne nécessite pas de données on chain ; celles-ci sont d'abord publiées et stockées off chain, tandis que seule une commitment (preuve de engagement) est conservée sur la blockchain.
Auteurs : Wuyue & Faust, Geekweb3
Conseiller : Kevin He, initiateur de la communauté chinoise BitVM, ancien responsable technique Web3 chez Huobi
Introduction : Actuellement, les couches 2 (Layer2) du Bitcoin sont devenues une tendance forte. Sur le marché, il existerait déjà des dizaines de projets se définissant eux-mêmes comme « Layer2 Bitcoin ». Parmi eux, bon nombre prétendent être des « Rollups » et affirment utiliser l'approche proposée dans le livre blanc de BitVM, faisant ainsi de BitVM un sujet central dans l'écosystème Bitcoin.
Malheureusement, la plupart des documents disponibles à ce jour sur BitVM ne parviennent pas à expliquer clairement ses principes fondamentaux.
Cet article constitue notre synthèse simplifiée après lecture du livre blanc de BitVM (seulement 8 pages), complétée par des recherches sur Taproot, les arbres MAST et Bitcoin Script. Afin de faciliter la compréhension, certaines formulations utilisées ici diffèrent légèrement de celles du livre blanc original. Nous supposons que le lecteur possède quelques connaissances préalables sur les Layer2 et comprend aisément le concept simple de « preuve de fraude ».

Résumé en quelques phrases : BitVM repose sur l'idée de ne pas stocker les données directement sur la chaîne (on chain), mais de les publier et conserver hors chaîne, en conservant uniquement un Commitment (engagement) sur la chaîne.
Lorsqu'une contestation ou preuve de fraude intervient, seules les données nécessaires sont publiées sur la chaîne afin de démontrer leur lien avec l’engagement initial. Ensuite, le réseau principal BTC vérifie si ces données on chain contiennent des erreurs ou si le producteur de données (le nœud traitant les transactions) a commis une malversation. Tout ceci suit le principe du rasoir d'Occam — “Pluralitas non est ponenda sine necessitate” (“Ne rien ajouter inutilement”) — autrement dit, minimiser au maximum les opérations on chain.

Contenu principal : Résumé vulgarisé du schéma de vérification par preuve de fraude sur BTC basé sur BitVM :
1.L'idée centrale de BitVM
Tout d’abord, un ordinateur ou processeur est un système entrée-sortie composé d’un grand nombre de portes logiques. Un des principes fondamentaux de BitVM consiste à simuler l’effet entrée-sortie de ces portes logiques à l’aide de Bitcoin Script.
Dès lors qu’on peut simuler des portes logiques, on peut théoriquement implémenter une machine de Turing et réaliser toute tâche calculable. Autrement dit, avec suffisamment de personnes et de ressources financières, on pourrait mobiliser une équipe d’ingénieurs pour utiliser le langage rudimentaire de Bitcoin Script afin de simuler d’abord des portes logiques, puis assembler un très grand nombre de ces portes pour reproduire les fonctionnalités de l’EVM ou de WASM.
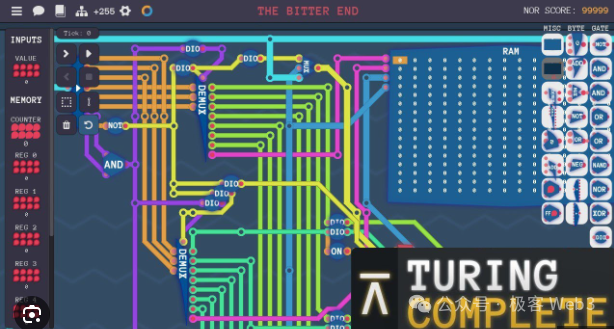
(Capture d’écran issue d’un jeu pédagogique intitulé « Turing Complete », dont l’objectif principal est de construire un processeur complet à partir de portes logiques, notamment des portes NAND)
On compare parfois l’approche de BitVM à la construction d’un processeur M1 à l’aide de circuits redstone dans « Minecraft », ou encore à la reproduction de l’Empire State Building avec des briques de Lego.

(On raconte qu’il s’agit d’un « processeur » construit dans Minecraft après un an de travail)
2. Pourquoi utiliser Bitcoin Script pour simuler EVM ou WASM ?
N’est-ce pas trop compliqué ? Oui, mais parce que la plupart des Layer2 Bitcoin souhaitent supporter des langages avancés comme Solidity ou Move, alors que le seul langage pouvant actuellement s’exécuter directement sur la chaîne Bitcoin est Bitcoin Script — un langage rudimentaire, composé d’opcodes spécifiques, non Turing-complet.

(Exemple de code Bitcoin Script)
Si un Layer2 Bitcoin souhaite, comme Arbitrum sur Ethereum, valider les preuves de fraude sur sa Layer1 tout en bénéficiant pleinement de la sécurité de BTC, il doit pouvoir vérifier directement sur la chaîne BTC une « transaction litigieuse » ou un « opcode contesté ». Cela signifie qu’il faut réexécuter sur la chaîne Bitcoin les opcodes correspondant au langage Solidity / EVM utilisés sur le Layer2. Le problème revient donc à :
Implémenter les fonctionnalités de l’EVM ou d’autres machines virtuelles à l’aide du langage natif Bitcoin, à savoir Bitcoin Script, extrêmement limité.
Ainsi, du point de vue des principes de compilation, BitVM traduit les opcodes de l’EVM / WASM / JavaScript en opcodes de Bitcoin Script, les portes logiques servant d’étape intermédiaire (IR) entre « opcode EVM → opcode Bitcoin Script ».
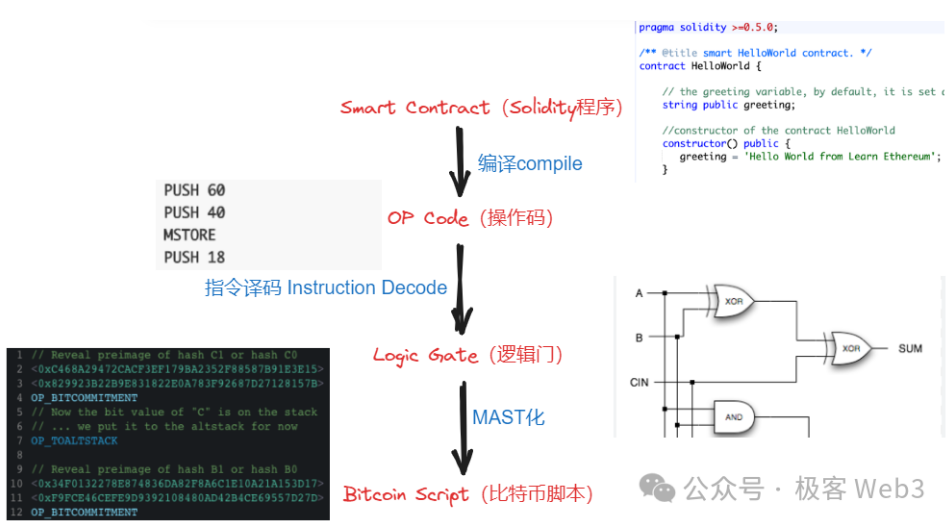
(Dans le livre blanc de BitVM, illustration de l’idée générale pour exécuter certains « instructions litigieuses » sur la chaîne Bitcoin)
En fin de compte, l’objectif est d’exécuter sur la chaîne Bitcoin des instructions qui normalement ne peuvent être traitées que sur l’EVM ou WASM. Bien que réalisable, cette approche soulève une difficulté majeure : comment représenter tous les opcodes EVM/WASM via un grand nombre de portes logiques en tant qu’étape intermédiaire ? De plus, exprimer directement certains processus complexes de traitement de transaction via des combinaisons de portes logiques pourrait entraîner une charge de travail colossale.
3. La « preuve de fraude interactive », fortement inspirée d’Arbitrum
Passons maintenant à un autre concept central mentionné dans le livre blanc de BitVM : la « preuve de fraude interactive », très similaire à celle d’Arbitrum.
Ce mécanisme fait intervenir un terme appelé « assert » (affirmation). Généralement, le Proposer du Layer2 (souvent le séquenceur) publie sur la Layer1 une assertion affirmant que certaines données de transaction ou résultats de transition d’état sont valides.
Si quelqu’un juge que l’assertion publiée par le Proposer est incorrecte (données associées erronées), un différend survient. À ce moment-là, le Proposer et le Challenger échangent des informations de manière itérative, et effectuent une recherche dichotomique sur les données litigieuses afin d’identifier rapidement une instruction très fine et son fragment de données associé.
Pour cette instruction litigieuse (opcode), il faut exécuter directement sur la Layer1 l’instruction avec ses paramètres d’entrée, puis vérifier le résultat obtenu (les nœuds de la Layer1 comparent le résultat calculé localement avec celui publié initialement par le Proposer). Dans Arbitrum, cela s’appelle une « preuve de fraude pas à pas ».

(Dans le protocole de preuve de fraude interactive d’Arbitrum, une recherche dichotomique permet de localiser rapidement l’instruction litigieuse et son résultat, avant d’envoyer une preuve pas à pas à la Layer1 pour validation finale)
Référence : Ancien ambassadeur technique d’Arbitrum expliquant l’architecture d’Arbitrum (partie 1)

(Schéma du processus de preuve de fraude interactive d’Arbitrum, présenté de façon sommaire)
À ce stade, le principe de la preuve pas à pas devient clair : la grande majorité des instructions exécutées sur le Layer2 n’ont pas besoin d’être vérifiées sur la chaîne BTC. Seuls les fragments de données ou opcodes litigieux doivent être rejoués sur la Layer1 en cas de contestation.
Selon le résultat de la vérification :
-
Si les données publiées précédemment par le Proposer sont erronées, ses fonds mis en gage sont confisqués (Slash) ;
-
Si c’est le Challenger qui est en tort, ses fonds mis en gage sont slashés ;
-
Si le Prover ne répond pas pendant une longue période, il peut également être slashé.
Arbitrum utilise des contrats sur Ethereum pour obtenir cet effet, tandis que BitVM doit s’appuyer sur Bitcoin Script pour implémenter des fonctions telles que les verrous temporels (time locks) et les signatures multiples (multisig).
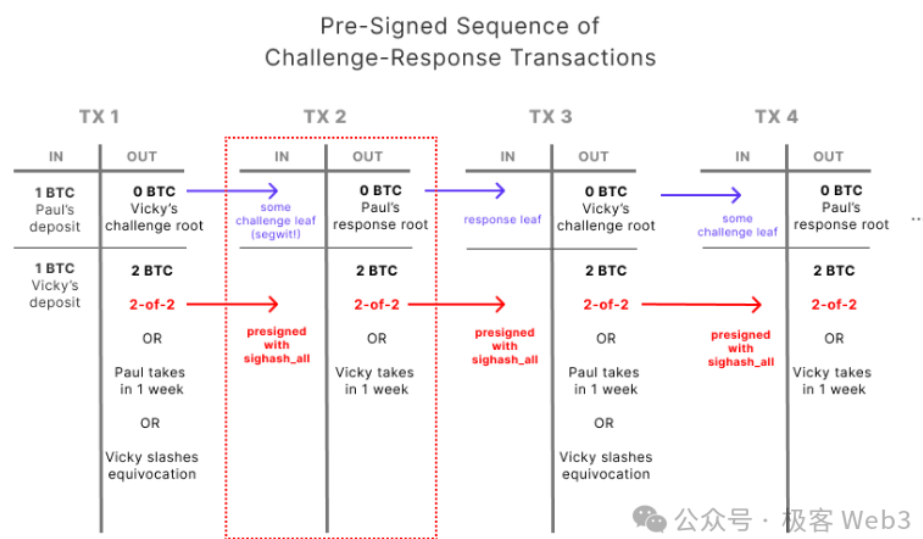
4. Arbre MAST et Preuve de Merkle
Après avoir brièvement expliqué la « preuve de fraude interactive » et la « preuve pas à pas », abordons les notions d’arbre MAST et de preuve de Merkle.
Comme mentionné précédemment, dans le cadre de BitVM, les grandes quantités de données transactionnelles traitées hors chaîne et les vastes circuits logiques ne sont pas directement publiés sur la chaîne. Seules des données très limitées ou des circuits logiques sont publiés sur la chaîne en cas de besoin.
Cependant, nous avons besoin d’un moyen de prouver que ces données, initialement hors chaîne mais désormais publiées sur la chaîne, ne sont pas inventées arbitrairement — c’est ce que la cryptographie appelle un Commitment (engagement). La preuve de Merkle est une forme de Commitment.
Introduisons d’abord l’arbre MAST. MAST signifie Merkelized Abstract Syntax Trees, soit des arbres AST (arbres syntaxiques abstraits) transformés en arbres de Merkle.
Qu’est-ce qu’un arbre AST ? Son nom chinois est « arbre syntaxique abstrait ». En termes simples, il s’agit de diviser une instruction complexe, via une analyse lexicale, en unités élémentaires d’opération, puis de les organiser sous forme d’une structure de données arborescente.

(Exemple simple d’arbre AST : cet arbre décompose une opération simple comme x=2, y=x*3 en opcodes de base + données)
Un arbre MAST est donc un arbre AST converti en arbre de Merkle afin de permettre les preuves de Merkle. Un avantage des arbres de Merkle est leur efficacité en matière de « compression de données ». Par exemple, si vous souhaitez publier à un moment donné un fragment de données provenant de l’arbre de Merkle sur la chaîne BTC, tout en prouvant que ce fragment appartient bien à l’arbre et n’a pas été fabriqué arbitrairement, que faire ?
Il suffit d’enregistrer préalablement la racine (Root) de l’arbre de Merkle sur la chaîne, puis, ultérieurement, de fournir une preuve de Merkle (Merkle Proof) attestant que le fragment de données appartient bien à l’arbre identifié par cette racine.
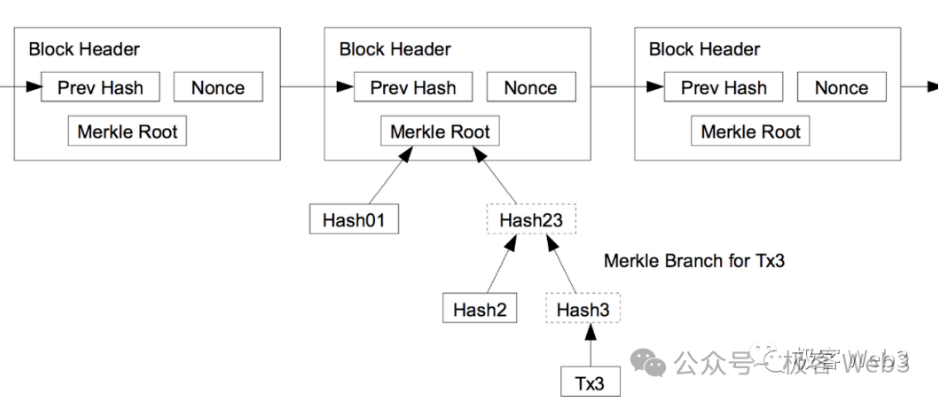
(Relation entre Merkle Proof/Branch et Root)
Ainsi, il n’est pas nécessaire de stocker l’intégralité de l’arbre MAST sur la chaîne BTC. Il suffit de divulguer à l’avance sa racine (Root) comme engagement, et de fournir ultérieurement le fragment de données + preuve de Merkle (ou branche) si nécessaire. Cette méthode réduit considérablement la quantité de données publiées sur la chaîne, tout en garantissant que les données on chain proviennent bien de l’arbre MAST. En outre, ne publier que de petits fragments + preuve de Merkle plutôt que toutes les données offre un bon niveau de protection de la vie privée.
Référence : Données retenues et preuves de fraude : pourquoi Plasma ne prend pas en charge les contrats intelligents
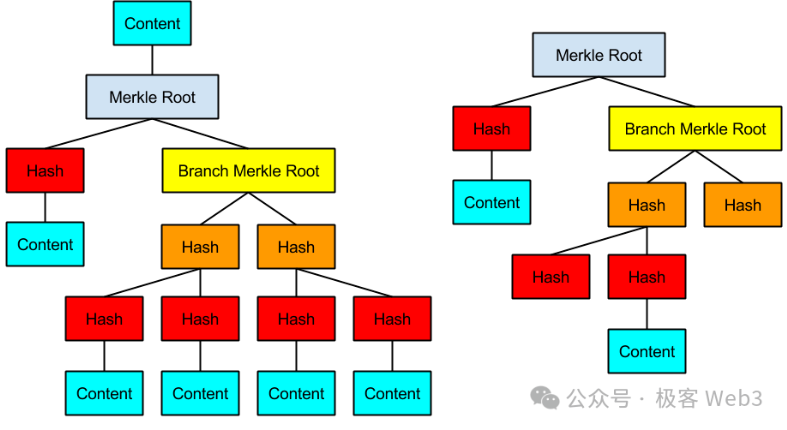
(Exemple d’arbre MAST)
La solution BitVM tente d’exprimer tous les circuits logiques via des scripts Bitcoin, puis de les organiser en un immense arbre MAST. Les feuilles (leaf) situées en bas de cet arbre (appelées « Contenu » sur l’image) correspondent aux portes logiques implémentées en Bitcoin Script.
Le Proposer du Layer2 publie fréquemment sur la chaîne BTC la racine (Root) de l’arbre MAST. Chaque arbre MAST est associé à une transaction, incluant tous les paramètres d’entrée, opcodes et circuits logiques concernés. Cela ressemble, dans une certaine mesure, à la publication d’un bloc Rollup par le Proposer d’Arbitrum sur la chaîne Ethereum.
Lorsqu’un litige survient, le challenger déclare sur la chaîne BTC qu’il conteste un certain Root publié par le Proposer, et demande au Proposer de révéler un fragment de données correspondant à ce Root. Le Proposer fournit alors une preuve de Merkle, publiant progressivement de petits fragments de l’arbre MAST sur la chaîne, jusqu’à ce que le circuit logique litigieux soit identifié conjointement avec le challenger. Ensuite, la sanction (Slash) peut être appliquée.
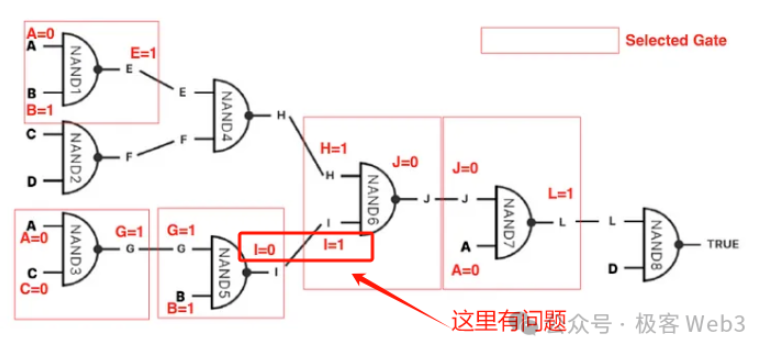
(Source : lien)
5. Conclusion
À ce stade, les éléments les plus importants du projet BitVM ont été couverts. Bien que certains détails restent un peu obscurs, le lecteur devrait maintenant en saisir l’essence.
Quant au bit value commitment mentionné dans le livre blanc, il vise à empêcher le Proposer, lorsqu’il est mis au défi et contraint de valider un circuit logique sur la chaîne, d’attribuer à l’entrée de ce circuit « à la fois 0 et 1 », ce qui créerait une ambiguïté.
Synthèse
Le schéma BitVM consiste d’abord à exprimer des portes logiques via Bitcoin Script, puis à utiliser ces portes pour représenter les opcodes de l’EVM ou d’autres machines virtuelles, ensuite à modéliser via ces opcodes le traitement de toute instruction transactionnelle, et enfin à organiser le tout sous forme d’un arbre de Merkle / arbre MAST.
Un tel arbre, s’il représente un processus de traitement transactionnel complexe, peut facilement compter plus de 100 millions de feuilles. Il est donc crucial de minimiser autant que possible l’espace occupé par l’engagement dans les blocs, ainsi que l’étendue affectée par une preuve de fraude.
Bien que la preuve pas à pas ne nécessite que de très petites portions de données et de scripts logiques publiés sur la chaîne, l’arbre de Merkle complet doit être conservé hors chaîne de manière permanente, afin que ses données puissent être publiées en cas de contestation.
Chaque transaction sur le Layer2 génère un grand arbre de Merkle. La pression de calcul et de stockage pour les nœuds est donc énorme, et la plupart des gens hésiteront probablement à exécuter un nœud (bien que ces données historiques puissent être purgées après expiration, et que B² Network introduise spécifiquement un mécanisme de preuve de stockage zk similaire à Filecoin pour inciter les nœuds à conserver durablement les données historiques).
Cependant, les Rollups optimistes basés sur les preuves de fraude n’ont pas besoin d’un grand nombre de nœuds, car leur modèle de confiance repose sur 1/N : tant qu’un seul nœud parmi N est honnête et capable de lancer une preuve de fraude au moment critique, le réseau Layer2 reste sécurisé.
Néanmoins, la conception de solutions Layer2 basées sur BitVM fait face à de nombreux défis, par exemple :
1) Théoriquement, pour compresser davantage les données, on pourrait éviter de vérifier directement les opcodes sur la Layer1, et plutôt compresser le processus de traitement des opcodes en une preuve zk. Le challenger pourrait alors contester les étapes de vérification de cette preuve zk, réduisant massivement la quantité de données on chain. Toutefois, les détails techniques seraient extrêmement complexes.
2) Le Proposer et le Challenger doivent interagir fréquemment hors chaîne. Comment concevoir le protocole, optimiser au niveau du flux de traitement les engagements et le processus de contestation, demandera beaucoup d’efforts intellectuels.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














