

Deep Dive into $VVV: The Undervalued Privacy-Focused AI Infrastructure and Its Growth Trajectory
TechFlow Selected TechFlow Selected
Deep Dive into $VVV: The Undervalued Privacy-Focused AI Infrastructure and Its Growth Trajectory
Deconstructing Venice: The Full Chain from Privacy Architecture to Business Model
Author: Yan Liberman
Translation & Editing: TechFlow
TechFlow Intro: Venice’s subscription data over the past three weeks shows a 34% acceleration in new ARR growth. At its current market cap, its valuation stands at just 2.5x projected revenue for the next 12 months. A former crypto investor dissects Venice’s full stack—from its privacy architecture to its business model—and argues that the market is severely underestimating both the true size of the “privacy AI inference”赛道 and Venice’s irreplaceable combination of advantages in this space—making a bullish case for $VVV.

Venice is a privacy-first AI inference platform enabling users to interact with cutting-edge and open-source models without exposing their identity to underlying model providers. I believe it is currently the most comprehensive privacy solution in the AI market: anonymous proxying, open-model routing, hardware-attested TEE inference, and end-to-end encrypted inference—all integrated into a consumer-grade product where privacy modes can be selected per request. No other player offers all four capabilities simultaneously.
This business has been growing significantly. Discussions about Venice on Crypto Twitter consistently underestimate its current revenue, recent growth trajectory, and future potential. Venice recently began publishing daily subscription data; fine-grained metrics over the past three weeks clearly show accelerating growth in new subscription ARR:
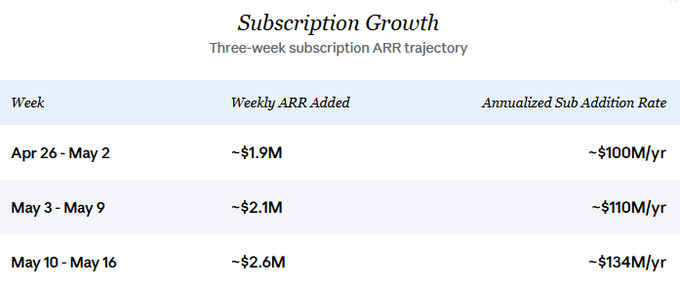
Sustained growth is the central assumption of this analysis. I also assume API revenue has recently tracked subscription growth closely—a point elaborated in the “Current Status & Growth” section below. Anchoring conservatively at $100M in annualized new subscription revenue (matching the pace observed in late April), and assuming equivalent new API revenue, total incremental revenue over the next 12 months would be approximately $200M.
The recent acceleration suggests substantial upside if this pace holds.
This article breaks down Venice’s uniqueness across five dimensions:
- Privacy Tiers: A privacy architecture far deeper than standard “private AI chat” claims.
- User Segments: Venice’s users are pushed out—not pulled in—by mainstream pathways (content policies, compliance requirements, threat models, principles).
- Market Size: A rapidly expanding privacy-segmented inference market, often underestimated by frameworks built around consumer chat.
- Competitive Landscape: Venice uniquely bundles deep privacy, uncensored model access, and crypto-native distribution—a combination unmatched by competitors.
- Token Design & VVV Valuation: How VVV and DIEM mechanics convert platform growth into token value, and how VVV’s valuation multiples compare with privacy inference peers like OpenRouter, Fireworks, and Together AI.
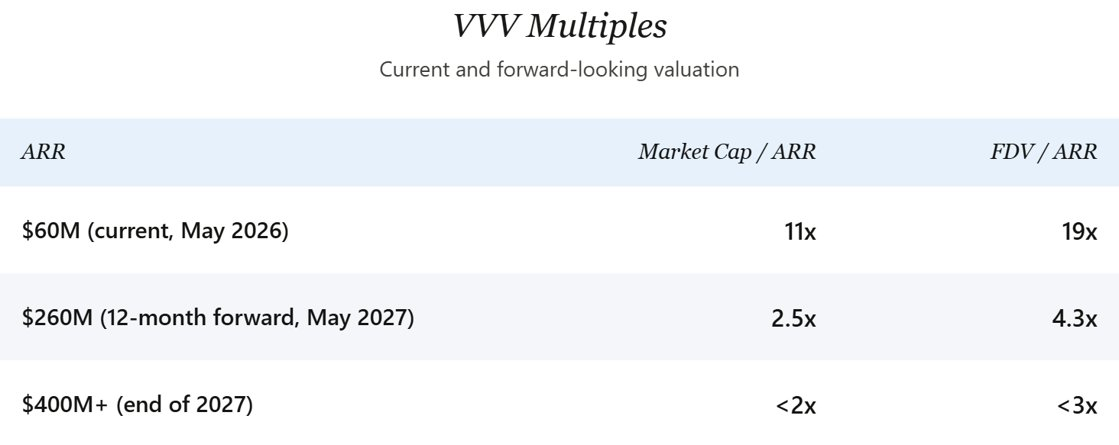
After the most recent rally and pullback to $14, VVV’s market cap sits at ~$660M, with a fully diluted valuation (FDV) of ~$1.12B. Current ARR is ~$60M (derived in the “Current Status & Growth” section below), growing at ~$200M annually—and accelerating. Based on current ARR, VVV trades at ~11x P/S (FDV ~19x), below peer OpenRouter’s 26x. Based on forward 12-month ARR of ~$260M ($60M base + $200M annualized increment), VVV trades at ~2.5x P/S (FDV ~4.3x).
Current Status & Growth
Venice recently began publishing daily new subscription data. Combined with periodic public announcements of registered user milestones, these two data streams allow me to estimate current ARR and project future trajectories.
To estimate current ARR, I start from total registrations. Based on the cadence of public milestone announcements over time, total registrations have grown at ~300K/month. The most recent confirmed milestone was ~3M registered users as of May 16, 2026—up from ~2M on February 1, consistent with the ~300K/month pace. Assuming a ~5% lifetime paid conversion rate (conservative given daily data showing faster conversion among newer signups), this implies ~150K active paying subscribers as of mid-May. Until mid-to-late April, only the base $18/month Pro plan existed; Pro+ ($68/month) and Max ($200/month) launched recently and are beginning to shift the mix—but the vast majority of paying users remain on the $18 tier. Weighted ARPPU is ~$18–$19/month, implying current subscription MRR of ~$2.8M, or ~$33M subscription ARR. This covers subscriptions only; API revenue is layered on later in this section to derive total current ARR.
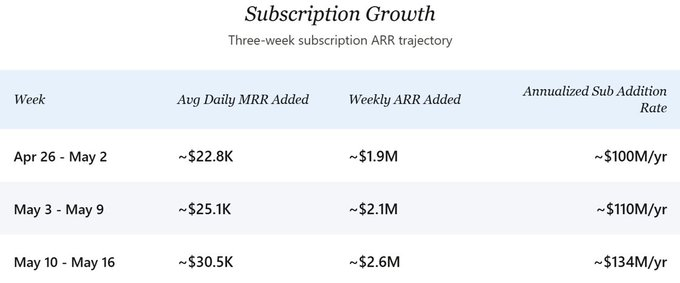
For future trajectory, new subscription ARR growth continues to accelerate. At the late-April pace, the company added ~$2M in subscription ARR weekly. In the most recent week (May 10–16), that pace jumped to ~$2.6M weekly—annualizing to $134M in new subscription ARR. In the core scenario of this analysis, I anchor conservatively at $100M annualized to avoid overstating recent acceleration. Net growth after churn will be slightly lower, but the gap is negligible at current scale and directionally immaterial—the gross growth rate forms the core of this forward-looking analysis.
The three-week granular dataset (April 26 – May 16) shows clear ramping:
Daily MRR additions grew ~34% from Week 1 to Week 3. Assuming API revenue tracks new subscription MRR 1:1 (explained below), implied total annualized incremental revenue has jumped from ~$200M to ~$268M. Two factors appear to drive this inflection: Pro+ and Max tiers gave high-willingness-to-pay users options previously unavailable, lifting weighted ARPPU; and paid conversion rates appear to have accelerated post-tier expansion.
API revenue is harder to measure due to lack of direct disclosure. My base case is that newly generated API operational revenue has recently tracked new subscription MRR at ~1:1—historically, the ratio was lower. As a result, current API ARR is sizable but slightly below subscription ARR, narrowing toward parity over time.
The ~50/50 split rationale starts with peer benchmarks. On large closed-model platforms, ChatGPT’s API share is ~25%, subscription ~75%, due to its massive consumer subscription base diluting API share. Anthropic’s API share is ~80%, subscription ~20%, reflecting its developer- and enterprise-heavy user base. Venice sits structurally between them: its privacy positioning doesn’t attract general consumers like ChatGPT, but its paying user base is broader than Anthropic’s enterprise-heavy mix. A 50/50 split falls squarely within this range.
This range is reinforced by two Venice-specific pieces of evidence.
First, Venice’s API has already built substantial developer distribution channels. OpenRouter routes Venice models; Fleek defaults all hosted agents to Venice inference; Cursor, Brave Leo (via BYOM), and VSCode community extensions support Venice. These integrations have accumulated over the past year+, supporting the argument that API is a real and significant business with scaled production traffic.
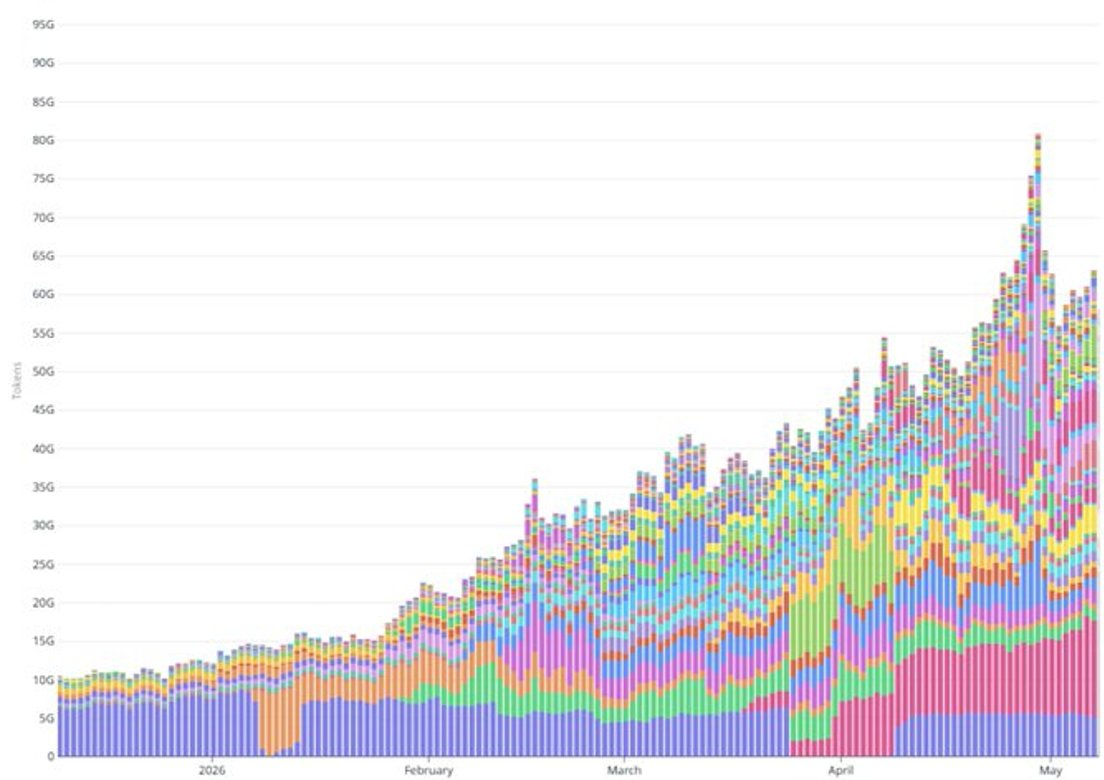
Second, recent token throughput growth far exceeds what subscription growth alone can explain. Daily token throughput rose from 20B in early February to >60B in early May—a ~3x increase in three months. Over the same window, paid subscription count grew ~50% (from ~100K to ~150K). The mid-April Pro+/Max expansion shifted only a small fraction of new signups to higher-ARPPU tiers—even with generous assumptions about per-user token consumption for those tiers, the gap remains unaccounted for. Most of the token surge appears driven by usage-based API workloads: agent deployments, integration partners scaling production traffic, and similar high-volume use cases.
Estimating current API ARR is harder than subscription ARR because the 1:1 ratio appears recent; prior to mid-April, API share was likely smaller. Using a midpoint assumption—that API historically averaged ~70–80% of subscription ARR before reaching 1:1 recently—current API ARR is ~$25–30M. Total current ARR estimate: ~$55–65M, midpoint ~$60M.
A brief note on the API portion: It’s annualized from current usage-based operational revenue—not recurring subscription commitments—so it carries higher inherent volatility than the subscription portion. A heavy API customer reducing usage could cause significant API operational revenue decline, while subscription base wouldn’t see similar churn.
Cross-checking against YTD revenue: With token throughput climbing from 20B/day in early February to >60B/day in early May, Venice has already generated at least $30M in cumulative revenue in 2026. This aligns with the current ARR range of $55–65M, which is rapidly scaling toward a $200M annualized incremental run rate.
Importantly, annualized incremental revenue ≠ revenue earned over the next 12 months. New ARR increases linearly over the year, so a sustained $200M annualized incremental rate in 2026 translates to ~$100M in new revenue earned over the year, plus ~$60M contributed by the current ARR base. Total revenue earned over the next 12 months should land in the $150–200M range, with ARR ending the 12-month window at ~$260M (pre-churn: $60M current + $200M new).
Looking back is largely a footnote. Venice’s current ARR annualized incremental rate is ~$200M. The real question is whether today’s pace is the floor—or the starting line. Key variables: Will subscription growth hold? Will API usage continue outpacing subscription expansion? How much churn emerges as queues mature? And can the addressable market sustain this pace long-term?
The market size question becomes easier once you understand what Venice actually does. The clearest foundation is a privacy ladder for LLM interactions—each tier representing distinct privacy assumptions, with Venice’s model embedded at specific levels.
Privacy Tiers
The ladder below ranks cloud-based AI usage along one narrow but critical axis: Who can link plaintext prompts to user identity? It does not solve all privacy problems. Device compromise, payment traces, account metadata, subpoena risk, and endpoint security remain independent issues. But it clarifies what actually changes when users shift from default chatbots to Venice’s higher-privacy modes. Tier numbers (0–7) are mine, used to situate Venice within the broader landscape. Venice’s own taxonomy uses only four named modes: Anonymous, Private, TEE, and E2EE—mapping to Levels 3, 4, 6, and 7 below.
The strongest privacy option isn’t on the ladder at all. Running open-source models on your own hardware—with zero cloud involvement—beats everything downstream. Running GLM 5.1 or Qwen 3.6 on a powerful Mac or workstation, with no network calls and no third-party involvement, is unbeatable—“prompts never leave my machine”—provided the machine itself is reasonably hardened. But this isn’t most people’s path. Hardware is expensive. Open-source models runnable locally still lag frontier closed labs on hardest tasks. You lose integrations and 24/7 cloud uptime, and bear full stack maintenance responsibility. Setting local deployment aside, the ladder covers realistic cloud-inference options.
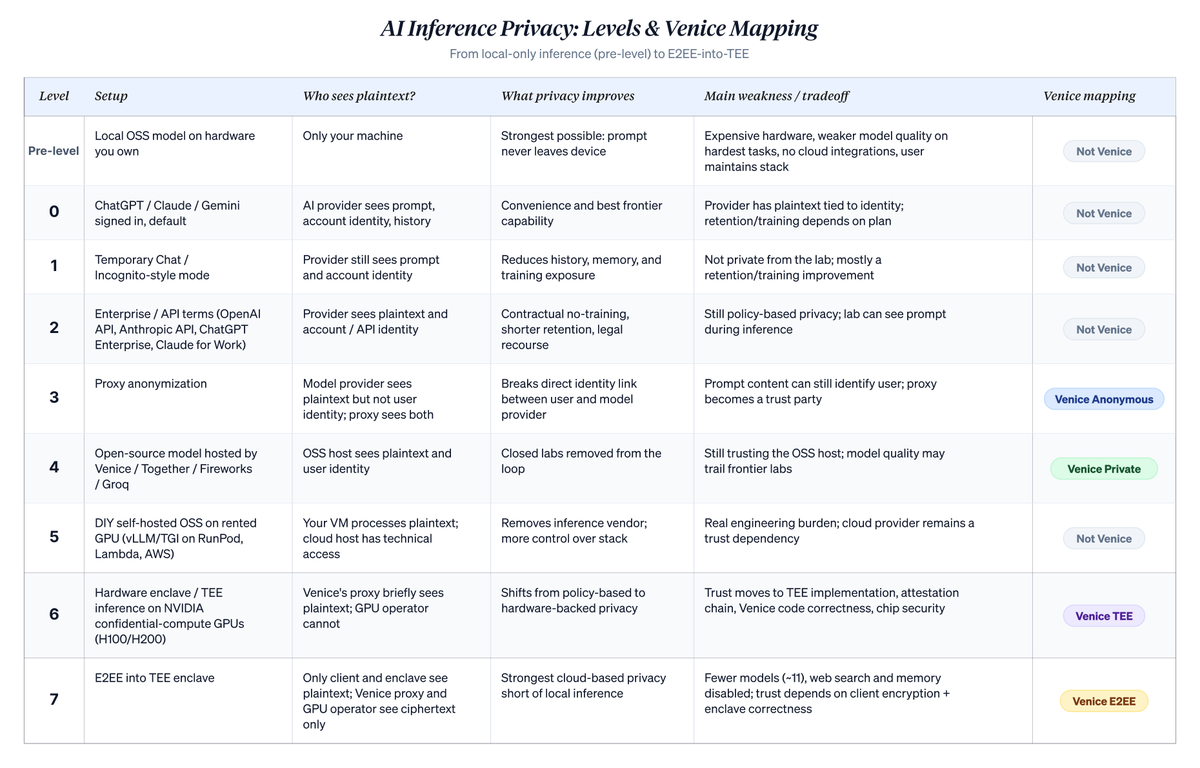
A detailed breakdown follows, including metaphors supporting each tier:
Level 0: “ChatGPT, Claude, or Gemini—logged in, default state.” Your prompt goes to the lab associated with your account. They know who you are and what you asked. In consumer plans, unless you opt out, conversations may be used to improve future models and are stored in your server-side chat history. Real commitments exist (no data sales, retention limits, deletion controls), but you’re identified, retained—and possibly fed into training pipelines in consumer plans. Most people live here. Architecturally, any hosted API consumption service applies the same posture regardless of provider location. Chinese providers’ hosted plans (DeepSeek Hosted, GLM/Zhipu, MiniMax, Qwen Direct) sit at the same architectural level: providers see plaintext, identity links to accounts, and retention/training policies vary by provider. Users typically choose these for price—they’re often far cheaper than Anthropic or OpenAI. Which jurisdiction governs your data depends on the specific provider, endpoint accessed, region, and contract. Don’t assume U.S./EU-style data handling just because the model is cheaper.
METAPHOR: You walk directly to a big firm (AI provider) to consult an advisor (model). They read your memo, answer your question, then file a copy under your name. They might use anonymized versions of past memos to train other advisors or improve services.
Level 1: “ChatGPT Temporary Chat / Claude Incognito Chat.” Same provider, same identity, same plaintext on their servers. Conversations don’t appear in your history, the model won’t carry them forward, and per policy they’re excluded from training. Useful for sensitive one-off conversations you don’t want affecting your account. The provider still knows it’s you and sees the full prompt; they just can’t retain it long-term or use it for training. Hidden from your own history—but not from the lab.
METAPHOR: Same direct interaction with the advisor (model), but you ask them to exclude this specific memo from your main file. They read it, answer, then file it in a temporary drawer (incognito chat) cleared after some time. They still know it’s you and saw what you sent.
Level 2: “Anthropic API, Claude for Work, ChatGPT Enterprise, OpenAI API.” Shift from consumer chat to commercial terms. Contracts explicitly exclude your data from training. Retention is short—typically ~30 days for security review, sometimes zero at enterprise tier. You have legal recourse if policies are violated. Labs still see plaintext during inference and tie traffic to your API key—but safeguards are stronger and enforceable in contracts. This is the privacy posture most companies actually use—a real upgrade over consumer chat. But it remains policy-based, not architectural. Reasons to climb further are real: future policy changes, forced disclosures, data breaches, or the lab itself turning bad.
METAPHOR: You sign a contract with a consulting firm (enterprise/API terms) stipulating no copying, no cross-client sharing, short retention, and legal recourse upon violation. Same direct interaction with the advisor (model)—they read your memo and know it’s from you—but rules governing what happens afterward are stricter.
Level 3: “Venice Anonymous Mode.” A proxy sits between you and the lab, stripping your identity before forwarding. The lab sees plaintext prompt content but not who sent it—they see “a request from Venice.” For prompts that don’t identify you, this breaks the link between your query and your name, making long-term profiling by the lab far harder. For prompts that *do* identify you (your company, your deal, your name), this is largely superficial—content exposes you regardless. You also add Venice as a trusted party. Doing this yourself isn’t realistic—you’d be the sole user of your own proxy, and single-user anonymity isn’t anonymity.
METAPHOR: A courier service (Venice) handles delivery. The courier strips your name from the memo before handing it to the advisor (model). The advisor reads the content but doesn’t know who sent it; the courier service knows both parties.
Level 4: “Open-source models on Together AI / Fireworks / Groq, or Venice Private Mode.” Switch to open-source models—closed labs exit the loop entirely since you’re not using their models. Trust shifts to the host of the open-source models. Different vendors, similar contractual safeguards—often culturally more privacy-focused (especially Venice Private Mode). You sacrifice some capability, though the gap has narrowed. GLM 5.1, Qwen 3.6, MiniMax M2.7, and DeepSeek V4 perform well on daily coding, writing, and analysis. Whether they match top closed models depends heavily on benchmarks; closed labs still tend to win on long-context tasks, multimodal work, and complex agent workflows. You also reduce centralization risk and trust fewer parties. Is this strictly more private than Level 3? Depends on what you care about. Level 3 hides your identity from frontier labs; Level 4 reveals it to smaller players but cuts labs off entirely. Different priorities, different rankings. This only helps traffic you actually route via open-source paths. Mixed usage means labs still see anything you send them. Within Level 4, providers differ on GPU location: Together, Fireworks, and Venice Private Mode specify their data centers, while aggregators like OpenRouter route to whichever cheapest underlying provider is available—including ones operating in jurisdictions you didn’t select. For users who care (avoiding API calls routed to certain countries), specifying a host differs fundamentally from routing to the cheapest aggregator—which adds another trust hop.
METAPHOR: You take your memo directly to a different consulting firm (open-source model host, e.g., Together AI, Fireworks, or Venice Private Mode). The original firm sees nothing because you’ve stopped using them. The new advisor (different model) reads your memo and knows it’s from you—same direct interaction structure, just a different firm.
Level 5: “DIY: vLLM on RunPod / Lambda Labs / AWS.” Skip the inference-as-a-service layer entirely. Rent raw GPUs, install vLLM or TGI yourself, load weights, expose your own endpoint. No inference vendor sees your traffic—only the cloud host running your VM. Technically, the cloud host *could* inspect your VM if motivated or compelled. Still, they have stronger compliance postures, contractual protections, and audit trails than small inference vendors. Trade-off: You move from small-vendor policies to hyperscaler policies—at the cost of real engineering and ops work.
METAPHOR: You hire your own advisor (your own self-hosted model) who works exclusively for you in a private office (a VM rented from RunPod, Lambda Labs, or AWS). No consulting firm in the middle—just you and your personally hired advisor. The building owner (cloud host) could technically access if motivated, but typically has stronger compliance posture than earlier-tier small firms.
Level 6: “Venice TEE Mode.” Here, privacy guarantees change nature. Both TEE and E2EE are available to any paying Pro subscriber; choice is per-request, not per-plan. For TEE inference, Venice routes to GPU hosts running confidential computing tech from NEAR AI Cloud and Phala Network, on NVIDIA H100/H200 hardware. NEAR and Phala provide protocols and tools; GPUs themselves are operated by third-party hosts using the tech. Confidential computing features on the GPU prevent operators from reading enclave contents at runtime. Remote attestation lets your client cryptographically verify the code running inside the enclave *before* sending anything—so “is this really Venice’s released code?” is a solved problem. What’s *not* solved is formal third-party audit of that code’s correctness. GPU operators are no longer parties who can peek. Venice’s proxy still briefly sees plaintext, but GPU hosts do not. The shift is from policy to hardware. Trust doesn’t vanish—it changes targets. You now trust NVIDIA’s confidential computing design, the attestation signature chain, and Venice’s implementation. Robust against real threats—though not bulletproof: TEE designs (Intel SGX, AMD SEV) have repeatedly revealed side-channel vulnerabilities; current designs aren’t immune. For users closely tracking this research, Level 4 (Venice Private Mode on a trusted operator’s data center) may be a rational stopping point over Level 6—trusting Venice’s operational hygiene may feel more comfortable than trusting chip vendors’ attestation chains. Apple’s Private Cloud Compute falls roughly in this architectural family: private cloud inference with hardware-backed privacy and verifiability. But differences with Venice are real. Apple uses Apple Silicon it controls, runs only Apple Intelligence on it, and doesn’t expose model choice. Venice uses external TEE partners, supports open models, and lets users choose privacy tiers per request.
METAPHOR: A courier service (Venice) delivers your memo to an advisor (model) working inside a sealed, soundproof room (TEE/hardware enclave on NVIDIA confidential computing GPUs, operated by Venice’s partners NEAR AI Cloud and Phala Network). The courier reads the memo en route, but the advisor inside cannot be observed by anyone—including the building owner (GPU operator). The room is wiped clean after each session.
Level 7: “Venice E2EE Mode.” TEE plus client-side encryption. Encryption setup occurs directly between your client and the silicon enclave. Venice’s proxy never holds the keys—so anything passing through it is ciphertext from your machine until processed inside the silicon. GPU operators and Venice itself are removed as parties who can peek; only the model running inside the enclave ever sees plaintext—and only fleetingly. This is the strongest privacy guarantee available on others’ hardware, second only to fully homomorphic encryption (still too slow for LLMs today). All Level 6 trust dependencies carry forward, plus a new one: client-side encryption must be correctly implemented. Two trade-offs unique to this tier: Features requiring Venice infrastructure to read plaintext—like web search and persistent memory—are disabled. Model choice narrows: Exactly eleven models are currently deployed inside TEE/E2EE infrastructure: Venice Uncensored 1.2, GLM 5.1, GLM 4.7, GLM 4.7 Flash, Qwen3.5 122B A10B, Qwen 2.5 7B, Qwen3 30B A3B, Qwen3 VL 30B A3B, Gemma 3 27B, GPT OSS 20B, and GPT OSS 120B.
METAPHOR: Everything from Level 6 still applies: The advisor (model) works inside a sealed, soundproof room—no one outside can observe, and the room is wiped after each session. Newly added: You lock your memo in a box (client-side encryption) before handing it to the courier (still Venice). The courier now carries an opaque box they can’t see inside—so only the advisor inside the sealed room ever sees your message.
Key Point: Levels 0–2 are mostly policy and contract upgrades. Levels 3–4 change routing and model/provider exposure. Levels 6–7 fundamentally shift the trust model by moving to hardware-backed and encrypted inference. Venice’s differentiation lies in spanning Levels 3, 4, 6, and 7 within a single product.
The right tier for any given user comes from their threat model. Choosing based on which mechanism sounds most impressive technically misses the point. Levels 6 and 7 sacrifice some frontier capability and add new trust dependencies. Even with these costs, this remains the most meaningful privacy upgrade available on cloud inference today.
That’s how the architecture works. The harder question is who truly needs which tier—and how large that audience is. Different threat models push different users to different parts of the ladder—usually forced, not preferred—making the resulting market larger than tech marketing implies. Below is the breakdown.
User Segments
Privacy stance isn’t an abstract preference. A significant portion of Venice’s audience arrives here only after content policies, compliance teams, threat models, or principles push them away from default options. When users actively seek alternatives they can no longer use, marketing gets much easier. Six key segments worth unpacking:
Regulated & Compliance-Driven Work. Financial teams handling material non-public information, HIPAA-bound healthcare workers, lawyers handling privileged communications, M&A and transaction professionals. Compliance teams often forbid Level 0. Many seem to stay at Level 2, as Anthropic and OpenAI’s enterprise terms (no training, short retention, contractual recourse) pass common compliance thresholds. A subset pushes to Level 6—often because they’ve been burned by policy changes elsewhere, or because forced disclosure of their data would cause real harm. Anthropic appears to have built a sizable enterprise business serving this segment, and regulatory direction in healthcare and finance continues tightening toward stricter privacy-preserving compute requirements. Venice’s clearest fit here today seems to be independent practitioners buying Pro out of personal caution—not enterprise procurement motions. Enterprise procurement looks beyond privacy architecture. Compliance teams need management controls, audit logs, SOC2 reports, signed DPAs, real SLAs, and integration support before signing. The crypto story matters—but isn’t enough. The enterprise procurement-driven market is being competed for directly by Apple PCC, Microsoft Azure Confidential Computing, and Phala or NEAR.
Developers Building on Venice API. Venice’s API has gained traction in developer integrations like OpenRouter, Cursor, VSCode, Brave Leo, and Fleek. The clearest use case is developers embedding privacy-respecting AI features into their products—guaranteeing end-users “your data stays private.” Tier mapping may vary by what the developer builds: Cost-sensitive consumer features use Anonymous Mode (Level 3), default OSS routing uses Private Mode (Level 4), products explicitly selling architectural privacy use TEE or E2EE (Levels 6–7). A developer using Venice API can serve many end-users without each needing a Venice subscription—making unit economics potentially very different from direct consumer subscriptions.
High-Risk Personal Use. People may not want mental health or therapy queries lingering in account history. Identity exploration around sexual orientation or gender—users may not yet be ready to disclose. Discussions about marriage, divorce, employment, or family dynamics—where exposure of such queries themselves could cause harm. Many of these users may stay at Level 1, believing incognito chat hides them. A privacy-conscious subset often shifts to Level 6 after understanding it doesn’t fully hide them from labs. AI mental health appears to be a growing category—though scale and quality of clinical vs. consumer products vary widely. Hard to estimate Venice’s scale here, as many users in this segment may not know to seek hardware-attested privacy until something awkward happens to them or someone they know.
Adversarial Environments. Journalists protecting sources, activists in jurisdictions monitoring AI usage, dissidents and political organizers, security researchers studying threat actors, lawyers representing whistleblowers. These users often need Levels 6 and 7. Lower tiers may not survive their threat models. Look at Proton: Even with privacy-first reputation and Swiss legal domicile, it often complies with most legal requests—frequently because Swiss law requires it. This is a failure mode of policy-based privacy at scale. Venice’s TEE and E2EE architecture belongs to the class of cloud setups where providers aren’t *designed* to hold plaintext—the very thing required to comply with such mandates. But architecture only takes you so far. Levels 6 and 7 reduce plaintext exposure—but can’t fix the full picture. Account metadata, payment trails, Venice’s usage records, what your laptop is doing, and what courts can compel from you—all remain with the user. For users with real adversarial threat models, this is just one tool in a broader toolkit. Numerically, this segment is small. Willingness to pay for tools that survive subpoenas tends to be high.
Crypto-Native & Privacy-Culture Users. Web3 developers, sovereignty-minded technologists, node runners who value hardware-attested guarantees on principle. This segment may span Levels 3–7 depending on individual threat models; principled subsets often default to 6 or 7 for sensitive queries. AI x crypto has become a meaningful category across the broader crypto ecosystem, with infrastructure players like Bittensor establishing strong footholds. Industry surveys often report higher self-hosting interest in emerging markets—where centralized payment monitoring is a concern. Venice’s alignment with this segment is unmatched by closed-lab competitors: VVV pricing, no KYC, Erik Voorhees’ reputation, and historical free Pro tiers for VVV and MOR holders helped cultivate this group. Likely Venice’s natural cultural base and a key part of its earliest paying users.
Adult Content & Other Categories Directly Rejected by Closed Labs. OpenAI, Anthropic, and Google typically reject NSFW sexual content. Other categories blocked at Level 0—like mature creative writing, harm-reduction questions about drugs, and a long list of stigmatized-but-legal topics—get varying treatment across providers, sometimes with tolerance. Users in these categories often can’t start at Level 0; models usually refuse. Model choice alone often pushes them to Levels 4–7—where uncensored open variants are typically available. Most paying users likely stay at Level 4 for daily use; privacy-sensitive subsets push to 6 or 7. This category looks large: Character.AI and Replika operate at meaningful consumer scale; AI companionship apps have grown into a significant consumer AI subsegment. These users may care more about privacy than average chatbot users because exposure costs are high: Preference profile leaks could destroy marriages, jobs, or custody cases. Possibly Venice’s largest volume-based audience today.
A standout point across these groups is how few seem to sit at the top of the funnel. Most appear shaped by being forced or pushed away from easy paths—by content policies, compliance teams, threat models, or principles. Privacy-first AI isn’t usually where people show up first; they often arrive only after discovering they can’t stay where they started. The same logic explains two adjacent segments worth flagging but not sizing: International users whose jurisdictions may push them away from centralized payments and AI surveillance, and early personal AI agent users whose orchestration data could benefit from privacy-respecting backends.
Market Size
Venice’s ultimate ceiling depends on addressable market size—not current execution. The right framework is inference share: Venice sells AI inference services; the relevant market is global inference spend; Venice’s revenue is a slice of that pool.
Independent 2027 inference market estimates converge globally at $140–160B—Bain, IDC, and McKinsey forecasts broadly align here. Even at Venice’s projected (my forecast, expanded in valuation section) $400M annualized run rate by end-2027, Venice captures <0.3% of that pool—trivial by any reasonable market definition. For context, OpenAI’s API business alone is estimated to capture low-single-digit % of today’s inference spend; Anthropic’s API sits in a similar range. Venice sits far below even mid-sized inference platforms’ share today.
But Venice isn’t competing for the whole pool. Venice targets the privacy-segmented slice: users and enterprises needing anonymity, hardware-attested privacy, uncensored access, or jurisdictional choice during inference. This subset is harder to size precisely—but directional signals are strong.
Several forces are expanding the privacy-segmented inference portion: tightening data residency regulations in Europe and parts of Asia, growing compliance friction between enterprises and default closed-lab products, and maturation of TEE-based privacy infrastructure. Enterprise surveys consistently flag rising concerns about AI-driven data exposure. These forces individually aren’t fast—but they compound.
Even if the privacy-segmented cloud inference market captures just 5–15% of the $140–160B 2027 inference market, that’s $7–23B. Low-single-digit share puts Venice at hundreds of millions in revenue—far above today’s run rate with ample headroom. Mid-single-digit share puts Venice in the $1B+ range.
Bear cases have three dimensions. First, the privacy-segmented cloud inference market fails to reach meaningful scale because hyperscalers bake sufficient privacy into existing platforms. Apple PCC, Azure Confidential Computing, and AWS Bedrock Confidential Inference all move in this direction. Privacy remains important—but gets bundled into existing cloud and consumer platforms, and an independent privacy-first market never grows large enough to sustain standalone players.
Second, local inference becomes viable for mainstream users. Open-source model quality is already strong enough for most day-to-day workloads. Bottleneck is setup friction and technical skill needed to run local models. As this bottleneck eases via more polished out-of-the-box solutions, simpler installers, and integrations handling operational burdens, a meaningful portion of privacy-conscious users may choose local inference over paying any cloud service—removing them entirely from Venice’s addressable market. Timing depends on how fast consumer-friendly local stacks mature.
Third, even if the privacy market scales meaningfully, Venice must still win share against other privacy-native players like Brave Leo, DuckDuckGo, Proton’s Lumo, Maple, and Tinfoil—each targeting parts of Venice’s bundle from different angles. The competitive landscape section discusses how Venice’s combo of privacy depth, uncensored access, and crypto-native distribution compares against these specific threats.
Competitive Landscape
Venice’s competitive set is broader than “other private AI apps.” Different platforms compete for the same demand: privacy-conscious consumers, developers wanting model choice, seekers of uncensored content, and crypto-native buyers. The sections below cover five categories.
This landscape is a wedge—partial substitutes pulling Venice from different angles. Brave and DuckDuckGo compete for distribution. OpenRouter competes for developer API. Tinfoil, NEAR, Phala, and Maple compete for the privacy architecture itself. Frontier labs embed “good enough” privacy into better models from the enterprise side. None of these products currently package Venice’s full bundle: default-private consumer AI, uncensored access, multi-model choice, crypto-native payments, and tokenized usage economics.
Worth distinguishing privacy tiers—from weakest to strongest:
No Training: Provider promises not to use your data for training (standard Anthropic and OpenAI API terms)
Limited or Zero Retention: Provider either briefly retains prompts for abuse monitoring, or offers ZDR configuration where prompts/responses aren’t stored post-processing (OpenAI ZDR, OpenRouter ZDR)
Anonymous Proxy: Provider sees prompt but not identity (Venice Anonymous, Brave Leo, DuckDuckGo AI Chat)
TEE/Hardware-Attested: Prompts run in enclaves operators can’t read (Venice TEE, Tinfoil, NEAR Private Chat, Apple PCC)
E2EE into TEE: Provider only sees ciphertext (Venice E2EE, Maple AI)
Local: Model runs on your own hardware (Ollama, LM Studio)
Venice is one of few consumer products crossing anonymous proxy, private chat, TEE, and E2EE modes in a single user experience—where users choose mode per request.
Default AI Platforms (OpenAI, Anthropic, Google, xAI)
Frontier labs already deliver real privacy to enterprise customers. OpenAI defaults to not using API or commercial data for training, and offers ZDR configuration for qualified customers. Anthropic doesn’t use commercial product inputs/outputs for training. Google Vertex AI offers enterprise-grade training restrictions. xAI also promotes user privacy controls—though its posture should be treated separately from OpenAI, Anthropic, and Google’s more mature enterprise commitments. Venice’s gap with enterprise and API privacy is narrower than many assume; the consumer anonymity gap remains wide. Consumer ChatGPT, Claude, and Gemini all default to binding identity to prompts and retaining chat history server-side—training policies vary by product and user settings.
Venice pursues what frontier labs won’t do: anonymous access, uncensored models, and crypto-native payments. This market is smaller than mainstream AI—but real. Frontier labs serve most general users. Venice serves the subset wanting to opt out of defaults.
By segment:
Consumer Chat: Venice offers anonymity, less paternalistic content, and crypto payments. Labs still win on capability and brand.
Prosumer: Venice offers model choice and less lock-in. Labs win on coding integrations, memory, and tools.
Enterprise: Venice lacks SOC2, DPA, management controls, audit logs, and SLAs today. Labs and hyperscalers own this market.
API: Venice offers privacy depth and uncensored access. Labs offer model quality and ecosystem.
Privacy-Native Distribution Layers (Brave, DuckDuckGo)
Brave is the strongest consumer distribution play in privacy. Brave reports >115M MAU and 47M DAU as of April 2026; Leo Premium is priced at $14.99/month plus a free tier. Leo is opt-in, stores history locally, and per Brave’s stated policy doesn’t retain prompts on Brave servers. Brave is also shifting from proxy privacy to verifiable privacy via NEAR AI’s NVIDIA-supported TEE—reinforcing hardware-backed AI privacy as a mainstream product feature.
DuckDuckGo AI Chat is similar in posture: free, no account, anonymous proxy to a rotating set of third-party models from OpenAI, Anthropic, Meta, etc. DuckDuckGo states chats won’t be stored or used for training. Duck.ai now has a paid tier offering more advanced models.
Proton’s Lumo is the third meaningful player here. Launched in July 2025 and expanded in January 2026 via project-based encrypted workspaces, Lumo offers zero-access encrypted AI assistance—no server-side logs, no training on user data. Lumo operates from Proton’s European base, outside U.S. jurisdiction, targeting Proton’s existing privacy-conscious user base across email, VPN, and cloud storage. Compared to Venice, Lumo offers narrower model choice, no frontier closed labs, no uncensored content, and no crypto-native distribution. But Proton’s brand is established among privacy-conscious users—while Venice’s brand still needs recognition beyond its current niche.
Brave, DuckDuckGo, and Lumo are dangerous because they shorten the conversion path. They don’t need to convince users to seek private AI—they meet privacy-conscious users directly in browsers, search flows, or email/VPN ecosystems they already use. For average users, their privacy plus familiar brands may be sufficient. Venice differentiates across dimensions against different competitors: Against Brave and DuckDuckGo, its privacy stack runs far deeper than proxying, and its model catalog is broader; against Lumo, differentiation is access to frontier closed labs via Anonymous Mode, uncensored content, and crypto-native economics—not privacy depth itself.
API Routing & Aggregation (OpenRouter, Together AI, Fireworks, Replicate)
OpenRouter has become many developers’ default routing layer. It raised $40M in seed and Series A funding from a16z, Menlo, and Sequoia in 2025, valuing it at ~$550M; as of April 2026, it’s reportedly negotiating a $120M round led by CapitalG at a $1.3B valuation—based on ~$50M ARR and >150K MAU developers. Its product has the right interface, globally and per-request ZDR controls, and developer mindshare among already-integrated teams. OpenRouter also distributes Venice models—including Venice Uncensored—making it both a competitor to Venice’s API business and a distribution channel.
Venice’s API differentiation is narrower but clearer: privacy-first packaging, Venice-native uncensored models, crypto-native payment flow, and direct linkage to VVV and DIEM economics. Together AI, Fireworks, and Replicate compete on different dimensions: cheap OSS inference for developers who don’t prioritize privacy. They’re adjacent—not direct competitors.
Venice’s API roadmap leans into privacy and uncensored access. Continued investment in routing flexibility and developer experience will determine how much API share Venice captures relative to its consumer subscription business growth.
Confidential Inference Infrastructure (Tinfoil, NEAR AI Cloud, Phala Network, Maple)
Several products now overlap parts of Venice’s architecture. Tinfoil offers TEE-attested inference on confidential computing GPUs, with an OpenAI-compatible API, targeting developers and infrastructure use cases. NEAR AI Cloud powers Venice’s TEE mode—and also launched NEAR Private Chat as its own consumer product. Phala Network powers Venice’s E2EE infrastructure and OpenRouter’s confidential routing. Maple targets consumers and privacy, offering E2EE chat in secure enclaves.
Venice is consciously building atop specialized confidential computing partners—while owning the application layer, user relationships, brand, payments, and model packaging. Contractual privacy is becoming table stakes; verifiable privacy is the next frontier. Venice’s distinction isn’t that no one else has TEE or E2EE. It’s that Venice bundles multiple privacy modes, uncensored content, model access, crypto payments, and tokenized usage into one consumer and API product.
Local & OS-Level AI (Ollama, LM Studio, Apple Private Cloud Compute)
Local AI is a real potential competitor. Ollama and LM Studio already serve technical users well—and this audience continues expanding as consumer hardware accelerates. Open-source model quality is now strong enough for most day-to-day workloads. What keeps mainstream users on cloud services today is setup friction and operational burden of running local models. As this gap closes via more polished out-of-the-box solutions, simpler installers, and integrations handling operational burdens, the share of privacy-conscious users choosing local over any cloud service will grow. Timing is uncertain—but likely compresses faster than typical long-term frameworks suggest.
Apple Private Cloud Compute is strategically relevant. PCC runs Apple Intelligence on Apple Silicon with hardware-backed privacy—normalizing private AI as a platform feature. PCC is locked to Apple devices and Apple Intelligence, so it doesn’t compete directly with Venice. But it *does* educate consumers on what private AI should look like—benefiting Venice’s category.
Venice’s Real Differentiators
Three combinations Venice uniquely owns in the market today:
Multiple privacy modes selectable per request within a single consumer product. Anonymous, Private, TEE, and E2EE all live in one app—users choose mode at the prompt level. Several competitors offer parts; Venice delivers the full set with a consumer experience layer.
Strong privacy plus uncensored content access. Closed labs would need to abandon their enterprise positioning to match this. None show willingness. Enterprise-focused privacy players face the same problem—amplified by compliance requirements. Venice hosts Venice Uncensored 1.2 alongside frontier closed labs because Venice faces fewer enterprise constraints on content—letting it host uncensored variants labs won’t.
Crypto-native distribution. VVV staking, DIEM mechanics, no-KYC onboarding, crypto payments, and Erik Voorhees as founder let Venice reach audiences closed labs and traditional privacy startups struggle to access. Customer acquisition cost basis differs from competitors buying mainstream consumer attention.
Open Questions in Competitive Landscape
Five things to watch. TEE infrastructure is leased—meaning pure privacy won’t be a long-term moat. Competing with Brave and DuckDuckGo on distribution is a real gap—dependent on whether deeper privacy and uncensored content can pull users from privacy-adjacent browsers. Enterprise procurement is wide open—requiring SOC2, signed DPAs, admin controls, and audit logs to close. Consumer brand is concentrated among crypto and libertarian audiences—mainstream awareness is the next growth phase. Local AI maturity—especially improvements in setup friction and consumer-friendly tools—could compress Venice’s addressable cloud market timeline dramatically.
Competitive Argument
Venice’s competition manifests as its own wedge splitting across multiple categories. Brave and DuckDuckGo can capture privacy-aware distribution. OpenRouter can capture developer routing. Tinfoil, NEAR, Phala, and Maple can commoditize confidential computing primitives. OpenAI, Anthropic, Google, and xAI can embed enterprise-grade privacy around the strongest models.
Privacy plumbing will commoditize. Most individual parts of the Venice stack will soon become table stakes. The real bet is Venice building durable consumer and developer habits *before* that happens. This bundle is central to Venice’s positioning. Competitors can replicate parts—but replicating the full bundle requires each to stretch beyond their core incentives and capabilities. Closed labs must compromise their security stance. Browsers and search engines must become AI-native. OpenRouter must own consumer experience and payments. Infrastructure providers must build consumer brands.
Token Design
Venice employs a dual-token model—separating protocol-level value capture from compute access.
VVV is the protocol token tied to platform success. The team has steadily shifted more value toward VVV via emission reductions and revenue-driven buy-and-burn mechanisms—aiming to make the token deflationary over time. Staking VVV grants holders yield and proportional API capacity.
DIEM is a separate, more experimental token launched in August 2025. Each DIEM permanently grants $1/day of Venice API quota. DIEM is minted by locking staked VVV at an algorithmic rate—but once minted, it’s freely tradable, letting users gain predictable compute access without bearing original VVV risk.
The two tokens answer different questions. VVV is a bet on Venice’s growth—and a way to participate in revenue capture. DIEM is tokenized compute entitlement—more useful for actual API consumers than speculators.
VVV
Current Supply
Total supply is 79.93M VVV. 46.03M are circulating, of which ~70% (32.19M) are staked. 2.67M remain locked in team vesting. The remainder—~31M—is in Venice’s corporate treasury, incentive funds, and other unallocated buckets outside team allocations.
Genesis Allocation
Venice’s launch documentation describes the following genesis allocation:

No presale.
Burns Since Launch
99% of cumulative burns occurred in a one-time event in March 2025. ~32.51M VVV from airdrop allocations went unclaimed and were permanently burned when the claim window closed, plus ~1M burns related to team allocations. These events collectively removed ~one-third of the original supply.
Recurring burns since November 2025 total just 195,260 VVV (~$3.1M at today’s price). Sustained burn rate totals ~37,752 VVV/month: ~31,636 from monthly autonomous buybacks funded by platform revenue, ~6,116 from subscription-programmed burns launched in April 2026.
Burns aren’t intended to be the primary source of token demand today. The company is young, reinvesting cash to grow—not scaling buybacks. Current burns serve more as a signaling tool to the market that VVV is tied to platform economics. They’re also a useful way for observers to track subscriber growth, as each subscription tier triggers a specific VVV burn amount visible on-chain.
Emission Schedule
Emissions have been reduced six times since launch:
Jan 27, 2025 (launch): 14M VVV/year
Aug 20, 2025: Reduced to 10M/year (tied to DIEM upgrade)
Oct 23, 2025: Reduced to 8M/year
Feb 10, 2026: Reduced to 6M/year
May 1, 2026: Reduced to 5M/year (current)
Jun 1, 2026: Planned reduction to 4M/year
Jul 1, 2026: Planned reduction to 3M/year
Vesting
Team allocation vesting: 7.5M of the 10M team allocation vests linearly over 24 months from TGE. As of May 2026, ~4.83M has vested, 2.67M remains locked. Full team allocation vests on Jan 27, 2027.
Net Supply Pressure
VVV is mildly inflationary today. Once the July 1 reduction to 3M/year takes effect, monthly emissions drop to ~250K VVV. At current ~37,752 VVV/month burn rate, net new supply will be ~212K VVV/month—~3.2% annualized inflation relative to effective supply.
The trajectory improves from there. I expect emissions to continue declining post-July. I also expect monthly burns to grow as subscription revenue scales—since the subscription-programmed burn mechanism ties burns directly to subscriber growth. As these trends compound, net deflation becomes achievable quickly.
Utility
VVV has three utilities—all from staking. Venice explicitly states VVV is not a governance token, so no voting utility exists.
Emission Yield. Stakers earn 80–100% of annual VVV emissions as yield, with Venice retaining the rest on locked sVVV. Current APR for stakers is ~14.7% at the 5M/year emission rate, dropping to ~9% post-July 1 cut. I don’t view yield as a major driver of investor behavior. People don’t buy VVV for yield—or sell because yield drops. It’s something you do while holding; the real thesis is price appreciation tied to Venice’s business growth. I’m constructive on continued emission declines, as they create new supply without driving incremental holder demand.
Free Venice API Access. Stakers can use Venice’s API at zero marginal cost. Each staker’s total API capacity share is proportional to their share of staked VVV—measured in DIEM (where 1 DIEM = $1/day quota). Pre-DIEM launch (August 2025), this share fluctuated daily as more people staked or unstaked. Post-DIEM, stakers who mint DIEM lock in predictable daily quota allocations.
DIEM Minting. Staked VVV can be locked to mint DIEM—the tradable representation of Venice API capacity. Covered in the DIEM section below.
Valuation Context
Venice’s tokenomics are moving in the right direction. VVV valuation’s primary drivers are revenue growth and market-applied multiples.
At $14/token, VVV’s market cap is ~$660M, FDV ~$1.12B.
Per the “Current Status & Growth” section, current total ARR is ~$60M, growing at ~$200M annualized and accelerating. At current ARR, VVV trades at ~11x revenue (FDV ~19x). At 12-month forward ARR of ~$260M ($60M base + $200M annualized growth), VVV trades at ~2.5x revenue (FDV ~4.3x).
Best Comparable: OpenRouter
Among private inference platform peers, OpenRouter is Venice’s closest business model analogue. Both are asset-light businesses—no owned GPU infrastructure—and monetize via markup on underlying inference, not raw compute sales. Venice routes via NEAR AI Cloud, Phala, DeepInfra, and Parasail. OpenRouter routes via partner endpoints.

¹ Per The Information, OpenRouter is negotiating a $120M round led by CapitalG at a $1.3B valuation. Last round valued it at ~$550M—its $40M seed + Series A in June 2025.
OpenRouter trades at 26x current ARR. One caveat: Per Sacra’s research, OpenRouter’s $50M ARR figure dates to early 2026—and OpenRouter’s reported growth trajectory (from $5M to $50M ARR over eight months ending early 2026) suggests its current ARR may be meaningfully higher by mid-2026. If OpenRouter’s current ARR is $80–100M, the negotiated $1.3B valuation compresses its 26x multiple to 13–16x. Venice’s directional discount to OpenRouter still holds—but the gap’s magnitude may be smaller than the 11x vs. 26x framing implies. Rationales supporting this multiple (asset-light economics, smaller revenue base with large growth runway, aggregator value proposition) apply equally to Venice—and Venice’s privacy positioning adds pricing power OpenRouter lacks.
But profit margins differ. OpenRouter charges ~5% on ~$1B annualized inference spend flowing through its platform. Its $50M revenue boasts >90% gross margin—because OpenRouter doesn’t pay GPU compute costs; underlying model providers do. Venice bills customers directly and bears underlying inference costs (GPU compute for OSS model hosting and API fees for frontier closed-lab models), giving Venice markedly lower gross margins (estimated 40–60%).
Single-token economics also differ. Venice charges customers directly at retail-like prices—subscribers pay fixed monthly fees regardless of usage. These two effects mean Venice captures significantly more revenue per token consumed than aggregators. That’s why Venice can have revenue comparable to OpenRouter despite vastly lower absolute token volume (Venice ~60–80B/day vs. OpenRouter ~2.8T/day).
Thus, a margin-adjusted fair-value framework sets Venice’s defensible multiple below OpenRouter’s. On gross profit basis: If Venice’s gross margin is 50%, $60M revenue becomes $30M gross profit. Applying OpenRouter’s 26x gross profit multiple to Venice yields a fair value of ~$780M. Venice’s current $660M market cap sits below this fair value, while its $1.12B FDV sits slightly above it.
One reminder: VVV is a token, while OpenRouter, Fireworks, and Together AI multiples refer to equity. Investors in these private companies hold securities with residual economic rights, governance and information rights, and—in many cases—liquidation preferences. VVV holders own no equity in Venice, have no legal claim on company cash flows or exit proceeds, and cannot force income distributions. VVV’s value comes from utility (staking, DIEM minting, API access) and the revenue-linked buyback/burn mechanism. As noted, these buyback/burn mechanisms aren’t significant in absolute terms today—but could grow more important as subscription revenue expands and emissions decline.
This distinction usually implies a discount relative to equity-derived comparables. Tokens can trade for long periods as public proxies for company growth—but they’re not the same instrument as equity. In equity sales, capital restructurings, or reorganizations, token holders may have no direct claim on the waterfall of enterprise value. Crypto history offers multiple examples where tokens traded initially as quasi-equity proxies—but once conditions tightened, economic value flowed primarily to companies, equity holders, creditors, or insiders.
Venice differs unusually on one front. To my knowledge, Venice raised no external venture capital. Erik Voorhees personally funded the company—with no disclosed VC priority stack creating competing equity outcomes. This doesn’t make VVV equity—or eliminate structural differences between tokens and shareholder claims. But it does reduce a common crypto failure mode: projects optimizing for equity outcomes while tokens languish economically.
For Venice, the token appears more central to the company’s long-term value capture strategy than many VC-backed crypto projects. VVV is a liquid public asset tied to the platform—it’s required for DIEM minting, gated behind staking-based API capacity, and the asset Venice buys back and burns as subscription revenue scales. This should mean a smaller token discount than applies to projects with large priority equity stacks and weak token mechanics. Still, a discount is warranted—because VVV remains an indirect economic claim, not ownership of Venice itself. The related analytical question is: What percentage of Venice’s underlying business value flows into VVV’s market value—via burns, utility demand, DIEM, and market perception?
Even after applying a meaningful token discount to equity-comparable fair value, the forward trajectory strengthens the case significantly. From a $60M ARR base, a conservative $200M annualized growth rate adds ~$317M in new ARR over 19 months to end-2027—reaching ~$377M total ARR. With modest continued acceleration (assuming API tracks 1:1 and last week’s $268M annualized pace holds), end-2027 ARR exceeds $400M. At these forward levels, compression of current FDV multiples is dramatic.
DIEM
Overview
DIEM launched on August 20, 2025, as a tradable ERC-20 token representing permanent tokenized inference. Each DIEM grants $1/day of Venice API quota—valid indefinitely. Current DIEM supply is 38,416 tokens, of which 29,131 are staked. DIEM currently trades at ~$1,325—implying a ~$51M market cap.
In practice, most users won’t interact with the minting mechanism. DIEM supply is effectively capped at current levels. The exponential Mint Rate formula now requires locking ~$9 worth of VVV to mint $1 of DIEM at current prices—economically constraining new issuance. Over the past 30 days, net supply has stayed within ~4% of the 38,000 target—mints and burns roughly offsetting. Marginal new mints still occur, and existing minters can redeem (burn DIEM to unlock their sVVV)—but for most participants, DIEM is simply a token traded publicly. The minting mechanism matters as background for understanding supply formation and what backs the token—but most just need to treat DIEM as a tradable asset.
Mechanics (as Background)
You stake VVV. Staked VVV (sVVV) sits in the staking contract earning yield.
You lock some or all sVVV to mint DIEM at the current Mint Rate. Mint Rate is algorithmic—rising exponentially as DIEM supply approaches Venice’s target (initially 38,000 DIEM). At current supply levels, the rate is ~757 sVVV per DIEM—far above the launch baseline of 90. The formula creates natural scarcity as supply nears target.
Once minted, DIEM is freely tradable on Aerodrome.
To unlock your sVVV, you must burn the same number of DIEM you originally minted. If you sold your DIEM, you must buy it back first.
While your VVV is locked behind DIEM, you continue earning 80% of the staking yield. The other 20% flows to Venice.
Utility
DIEM has three functional utilities:
API Access. Stake DIEM and consume up to $1/day of Venice API per DIEM held. Predictable—unlike pre-DIEM VVV staking where capacity fluctuated. Relevant to all DIEM holders.
Tradable Cash-Out Tool. VVV holders who minted DIEM can sell it publicly without selling their underlying VVV—which continues earning yield. Relevant to existing minters.
Required to Unlock Locked VVV. If you minted DIEM, you must burn equal DIEM to reclaim underlying VVV. Relevant only to existing minters.
Valuing DIEM
For actual API users, DIEM valuation boils down to three components.
Computational Cash Flow is fixed at $365/year per DIEM. Mechanically defined by Venice’s design. Every DIEM holder receives identical $365/year regardless of purchase price. This is the underlying value DIEM represents.
Opportunity Cost is similar across investors. The risk-free return you could earn on that capital (Treasury yields ~5%) is what you forgo holding DIEM instead of other assets.
Going-Concern Risk is where investor views diverge. The fixed $365/year only has value if Venice continues operating and honoring API quotas. DIEM’s price reflects the market’s collective view on Venice’s lifespan. Investors believing Venice will operate indefinitely demand smaller premiums for this risk. Investors believing Venice faces existential risk demand larger premiums.
DIEM Fair Price = $365 / (Risk-Free Rate + Going-Concern Risk Premium)
Different views on Venice’s lifespan produce different fair prices for the same fixed cash flow. At a 5% risk-free rate:
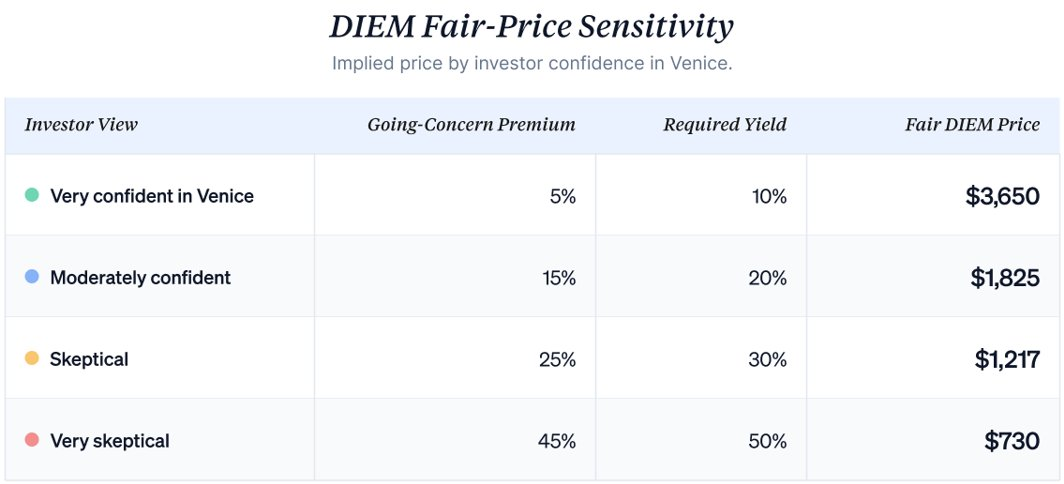
At today’s ~$1,325 DIEM price, the market collectively prices a ~22.5% going-concern premium (since $365 / $1,325 ≈ 27.5%, and 27.5% minus 5% risk-free rate ≈ 22.5%). Investors believing Venice deserves a smaller premium will buy. Those believing it deserves a larger premium will sell or wait.
The opportunity cost component is largely identical for everyone. Computational cash flow is fixed. Going-concern views are the only meaningful variable driving price formation among investors.
For users consuming computation at scale, math usually favors DIEM at current prices—as long as Venice continues looking durable. For pure speculators not using the API, the bet is purely on price appreciation tied to Venice’s growth narrative. That’s a completely different trade.
Cost to Venice from DIEM
Venice mints some DIEM itself (10,000 at launch) and distributes portions to specific user groups—including historical free Pro tier promotions for VVV and MOR holders. Venice bears explicit cost from non-paying users consuming API capacity via DIEM instead of Pro subscriptions or paid quotas. Erik Voorhees states this is a small portion of paid inference and revenue.
VVV Bottom Line
Venice is one of the truly differentiated companies in crypto today. Its privacy-first AI bundle—anonymous, private, TEE, and E2EE modes selectable per request, plus frontier closed labs and uncensored open models—is something no competitor packages today. Recent revenue trajectories show this bundle is finding paying users at a pace impossible to ignore.
At a $60M current ARR base, VVV trades at 11x revenue (market cap) and 19x (FDV). The trajectory is more attractive than current multiples. Venice added subscription ARR at ~$2M/week in late April—accelerating to ~$2.6M/week by mid-May—implying $134M annualized new subscription ARR growth, or $268M total if API tracks 1:1. Conservatively anchoring at $200M total annualized, 12-month forward ARR reaches ~$260M—compressing current multiples to 2.5x and 4.3x. If the trajectory holds, the forward case compounds rapidly.
Risks are real. Hyperscalers may launch sufficient privacy as a feature—compressing the independent privacy-first market. Local inference may mature faster than expected—pulling users entirely out of the cloud. Privacy-native competitors (Brave, DuckDuckGo, Lumo, Maple, Tinfoil) may erode this bundle. The structural difference between tokens and equity never fully disappears. Any of these could compress upside.
The core question is whether growth sustains or accelerates from here. At today’s $200M annualized and last week’s $268M pace, even modest continuation puts Venice in a materially different position in 12–18 months. That’s the bet.
The views expressed in this article are those of the individual author and not of Delphi Ventures General Partner LLC (“Delphi Ventures”) or its respective affiliates. This article is not directed at any investor or prospective investor and does not constitute an offer to sell or a solicitation of an offer to buy any securities, nor should it be used or relied upon in evaluating the merits of any investment. The author holds the tokens discussed and has a direct economic interest in their performance.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News









