

a16z: Large Model Deployment = Forgetting—Can “Continual Learning” Break This Vicious Cycle?
TechFlow Selected TechFlow Selected
a16z: Large Model Deployment = Forgetting—Can “Continual Learning” Break This Vicious Cycle?
The breakthrough lies in enabling the model to perform compression, abstraction, and learning—the very capabilities that make it powerful—during post-deployment training.
Authors: Malika Aubakirova, Matt Bornstein
Translated and edited by: TechFlow
TechFlow Introduction: Large language models (LLMs) are “frozen” upon completion of training. After deployment, they rely solely on external patches—such as context windows and retrieval-augmented generation (RAG)—to function. Fundamentally, they resemble the amnesiac protagonist in Memento: capable of retrieval, yet unable to truly learn anything new. In this article, two a16z partners systematically survey the cutting-edge research direction of “continual learning,” dissecting this potentially paradigm-shifting technical domain across three axes: context, modules, and weight updates.
In Christopher Nolan’s Memento, the protagonist Leonard Shelby lives in a fractured present. A brain injury has left him with anterograde amnesia—he cannot form new memories. Every few minutes, his world resets; he is trapped in an eternal “now,” unaware of what just happened or what will happen next. To survive, he tattoos notes onto his body and uses Polaroid photos—external props to replace memory functions his brain can no longer perform.
Large language models live in a similar eternal present. Once training concludes, their vast knowledge is frozen within parameters; they cannot form new memories or update their parameters based on new experience. To compensate for this deficit, we erect scaffolding around them: chat history serves as short-term sticky notes; retrieval systems act as external notebooks; system prompts resemble tattoos on the skin. Yet the model itself never truly internalizes this new information.
An increasing number of researchers believe this is insufficient. In-context learning (ICL) works only when answers—or fragments thereof—are already present somewhere in the world. But for problems demanding genuine discovery (e.g., novel mathematical proofs), adversarial scenarios (e.g., security red-teaming), or highly implicit knowledge that resists verbalization, there is strong justification for enabling models to directly write new knowledge and experience into their parameters after deployment.
In-context learning is temporary. Real learning requires compression. Until we allow models to continually compress, we may remain stuck in Memento’s eternal present. Conversely, if we can train models to learn their own memory architectures—not rely on bolt-on custom tools—we may unlock an entirely new scaling dimension.
This research area is called continual learning. While not new (see McCloskey & Cohen’s 1989 paper), we believe it is one of the most important directions in AI today. The explosive growth in model capabilities over the past two to three years has widened the gap between what models “know” and what they “can know.” This article aims to share insights we’ve gathered from leading researchers in the field, clarify the distinct pathways within continual learning, and catalyze discussion and development around this topic across the startup ecosystem.
Note: This article was shaped through deep conversations with exceptional researchers, PhD students, and founders who generously shared their work and perspectives on continual learning. From theoretical foundations to engineering realities of post-deployment learning, their insights have made this piece significantly more grounded than anything we could have written alone. Thank you for contributing your time and ideas!
Let’s Start With Context
Before defending parameter-level learning—i.e., updating model weights—it’s essential to acknowledge a fact: in-context learning *does* work. And there’s a compelling argument that it will continue to dominate.
The Transformer is, at its core, a sequence-based conditional next-token predictor. Feed it the right sequence, and you’ll observe astonishingly rich behavior—without touching the weights at all. That’s why context management, prompt engineering, instruction fine-tuning, and few-shot examples are so powerful. Intelligence is encapsulated in static parameters, while exhibited capabilities shift dramatically depending on what you feed into the context window.
A recent deep dive by Cursor on scaling autonomous programming agents offers a great example: model weights remain fixed; what makes the system run is meticulous orchestration of context—what to include, when to summarize, and how to maintain coherent state across hours of autonomous operation.
OpenClaw is another excellent case. Its viral success wasn’t due to special model access (the underlying model is publicly available to everyone), but rather its highly efficient translation of context and tools into working state: tracking what you’re doing, structuring intermediate outputs, deciding when to re-inject prompts, and maintaining persistent memory of prior work. OpenClaw elevated agent “shell design” into a discipline in its own right.
When prompt engineering first emerged, many researchers were skeptical that “prompt-only” interfaces could become legitimate. It felt like a hack. But it is native to the Transformer architecture—requiring no retraining—and automatically improves as models advance. As models get stronger, prompts get stronger. “Crude but native” interfaces often win because they couple directly to the underlying system, rather than fighting against it. So far, LLM development has followed precisely this trajectory.
State Space Models: In-Context Learning on Steroids
As mainstream workflows shift from raw LLM calls to agent loops, pressure on in-context learning models intensifies. Previously, fully filling the context window was relatively rare—typically occurring only when LLMs were asked to complete long sequences of discrete tasks, where application layers could straightforwardly trim and compress chat history. But for agents, a single task can consume a large fraction of the total available context. Each step in an agent loop depends on context passed forward from prior iterations. And agents frequently fail after 20–100 steps due to “losing the thread”: context fills up, coherence degrades, and convergence fails.
Accordingly, major AI labs are now investing heavily—via massive training runs—in developing models with ultra-long context windows. This is a natural path: it builds on an already effective method (in-context learning) and aligns with the industry-wide trend toward inference-time compute. The most common architectural approach interleaves fixed memory layers—state space models (SSMs) and linear attention variants (collectively referred to below as SSMs)—between standard attention heads. SSMs offer fundamentally better scaling curves in long-context regimes.
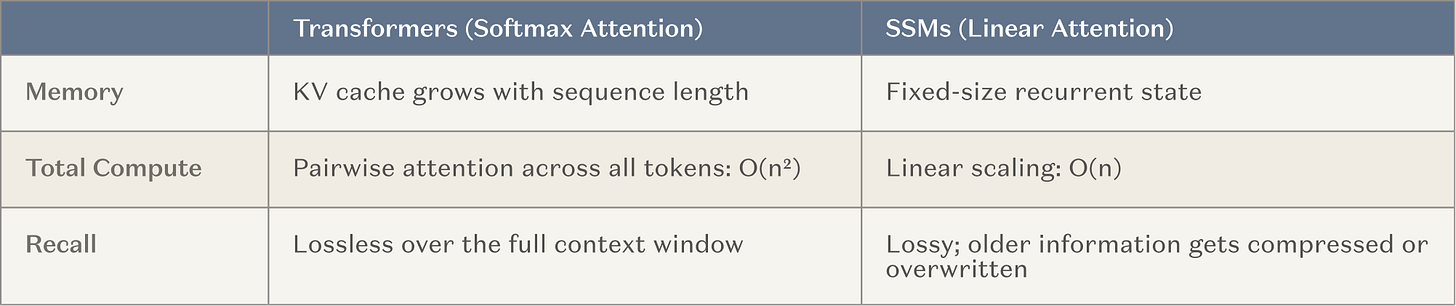
Caption: Scaling comparison between SSMs and traditional attention
The goal is to boost the number of coherent steps an agent can execute by several orders of magnitude—from ~20 to ~20,000—while retaining the broad skills and knowledge offered by conventional Transformers. If successful, this would be a major breakthrough for long-running agents. You could even view this approach as a form of continual learning: though model weights aren’t updated, it introduces an external memory layer that rarely needs resetting.
Thus, these non-parametric methods are real and powerful. Any assessment of continual learning must begin here. The question isn’t whether today’s context systems are useful—they are. Rather, it’s whether we’ve hit a ceiling, and whether new methods can take us further.
What Context Misses: The “Filing Cabinet Fallacy”
“AGI and pretraining overshoot, in a sense… Humans aren’t AGI. Yes, humans do have a skill base, but humans lack huge amounts of knowledge. What we rely on is continual learning. If I build a super-smart 15-year-old, he knows nothing. A good student, very eager to learn. You say, go be a programmer, go be a doctor. Deployment itself involves some kind of learning, trial-and-error process. It’s a process—not just tossing out a finished product.” — Ilya Sutskever
Imagine a system with infinite storage capacity—the world’s largest filing cabinet—where every fact is perfectly indexed and instantly retrievable. It can look up anything. Has it learned?
No. It has never been forced to compress.
This is the crux of our argument, echoing a point previously made by Ilya Sutskever: LLMs are, at heart, compression algorithms. During training, they compress the internet into parameters. Compression is lossy—and it’s precisely this lossiness that makes them powerful. Compression forces models to find structure, generalize, and build representations transferable across contexts. A model that merely memorizes all training samples is inferior to one that extracts underlying regularities. Lossy compression *is* learning.
The irony is that the very mechanism that makes LLMs so powerful during training—compressing raw data into compact, transferable representations—is exactly what we forbid them from doing after deployment. We halt compression at release, substituting external memory instead. Of course, most agent shells compress context in some customized way. But doesn’t the “bitter lesson” tell us that the model itself should learn this compression—directly and at scale?
Yu Sun shared an illustrative example highlighting this debate: mathematics. Consider Fermat’s Last Theorem. For over 350 years, no mathematician could prove it—not because of missing reference material, but because the solution was profoundly novel. The conceptual distance between existing mathematical knowledge and the final answer was enormous. When Andrew Wiles finally cracked it in the 1990s, he spent nearly seven years working in near isolation, inventing entirely new techniques to reach the answer. His proof depended on successfully bridging two distinct branches of mathematics: elliptic curves and modular forms. Though Ken Ribet had earlier shown that establishing this link would automatically resolve Fermat’s Last Theorem, before Wiles no one possessed the theoretical tools needed to actually build that bridge. Grigori Perelman’s proof of the Poincaré Conjecture admits a similar analysis.
The core question is: Do these examples demonstrate that LLMs lack something—a capacity to update priors and engage in genuinely creative thinking? Or does this story instead suggest the opposite—that all human knowledge is merely data awaiting training and recombination, and that Wiles and Perelman simply exemplify what LLMs could achieve at larger scales?
This is an empirical question, and the answer remains uncertain. But we *do* know that in-context learning fails today on many problem categories where parameter-level learning might succeed. For example:

Caption: Problem categories where in-context learning fails but parameter-level learning may prevail
More importantly, in-context learning handles only what can be expressed linguistically, whereas weights can encode concepts that prompts cannot articulate. Some patterns are too high-dimensional, too implicit, or too deeply structured to fit into context. For instance, visual textures distinguishing benign artifacts from tumors in medical scans—or subtle audio micro-fluctuations defining a speaker’s unique rhythm—cannot be easily decomposed into precise words. Language can only approximate them. No amount of prompting conveys such information; this knowledge lives only in weights. It resides in the latent space of learned representations—not in text. No matter how large the context window grows, some knowledge remains inexpressible in text and can only be carried by parameters.
This may explain why explicit “remember-you” features (e.g., ChatGPT’s memory) often unsettle users rather than delight them. What users truly want isn’t “recall”—it’s “capability.” A model that has internalized your behavioral patterns can generalize to new situations; one that merely recalls your interaction history cannot. The gap between “Here’s what you wrote last time you replied to this email” (verbatim regurgitation) and “I understand your thinking well enough to anticipate your needs” is the gap between retrieval and learning.
Getting Started With Continual Learning
There are multiple pathways to continual learning. The dividing line isn’t “whether memory exists,” but rather: Where does compression occur? These pathways lie along a spectrum—from zero compression (pure retrieval, frozen weights) to full internal compression (weight-level learning, making the model smarter)—with an important middle ground (modules).
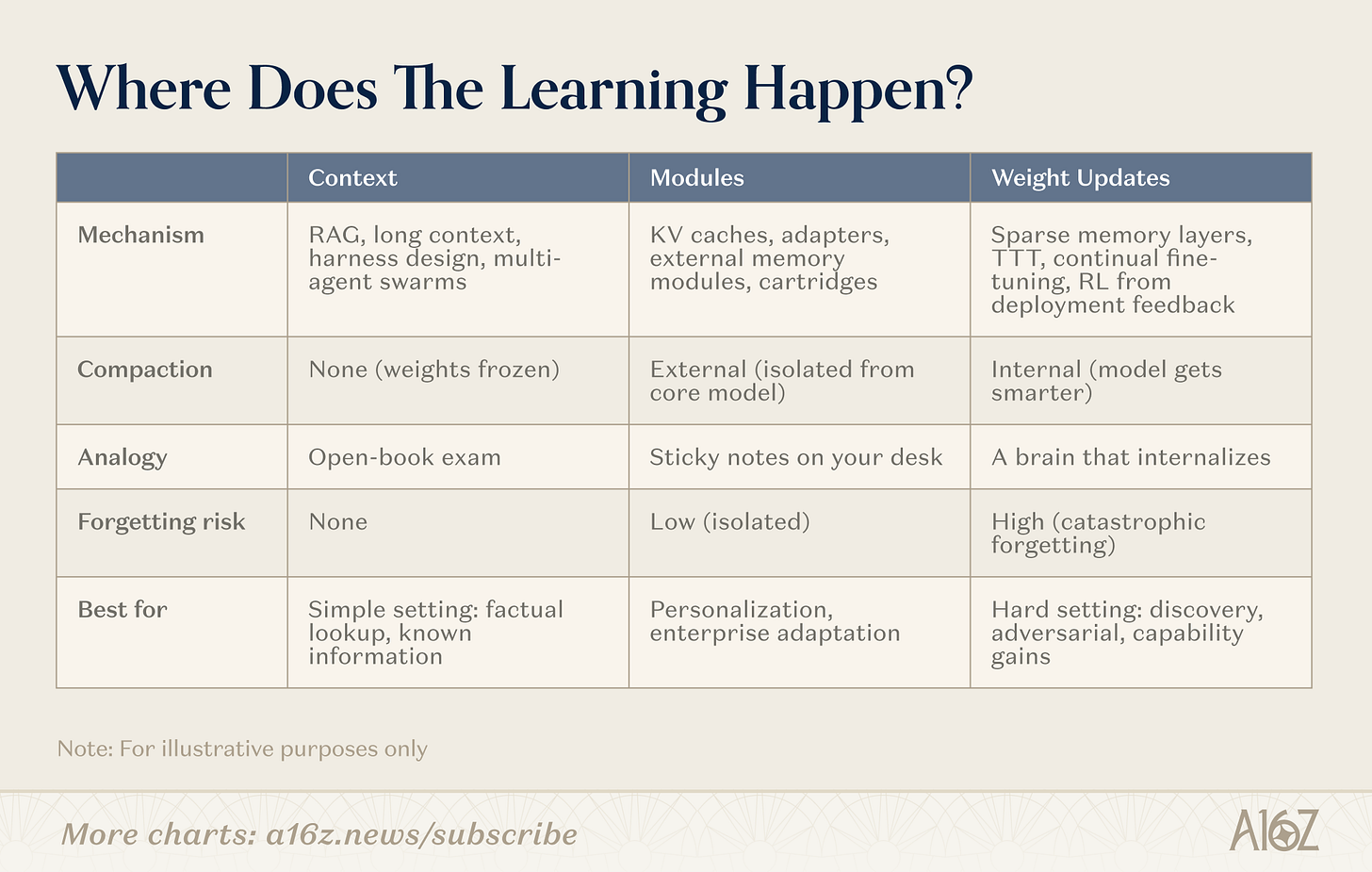
Caption: Three pathways to continual learning—context, modules, weights
Context
At the context end, teams build smarter retrieval pipelines, agent shells, and prompt orchestrations. This is the most mature category: infrastructure is battle-tested, and deployment paths are clear. Its limitation lies in depth: context length.
A notable emerging direction: multi-agent architectures as a scaling strategy for context itself. If a single model is constrained to a 128K-token window, a coordinated swarm of agents—each holding its own context, focusing on a slice of the problem, and communicating results—can collectively approximate infinite working memory. Each agent performs in-context learning within its own window; the system aggregates outcomes. Karpathy’s recent autoresearch project and Cursor’s web browser agent example are early cases. This is a purely non-parametric approach (no weight changes), yet it dramatically raises the ceiling of what context systems can achieve.
Modules
In the module space, teams build plug-and-play knowledge modules (compressed KV caches, adapter layers, external memory stores), enabling general-purpose models to specialize without retraining. An 8B model plus appropriate modules can match the performance of a 109B model on targeted tasks, using only a fraction of its memory footprint. Its appeal lies in compatibility with existing Transformer infrastructure.
Weights
At the weight-update end, researchers pursue true parameter-level learning: sparse memory layers updating only relevant parameter subsets; reinforcement learning loops optimizing models from feedback; and test-time training (TTT), which compresses context into weights during inference. These are the deepest methods—and the hardest to deploy—but they alone enable models to fully internalize new information or skills.
Specific mechanisms for parameter updates vary. Here are several active research directions:
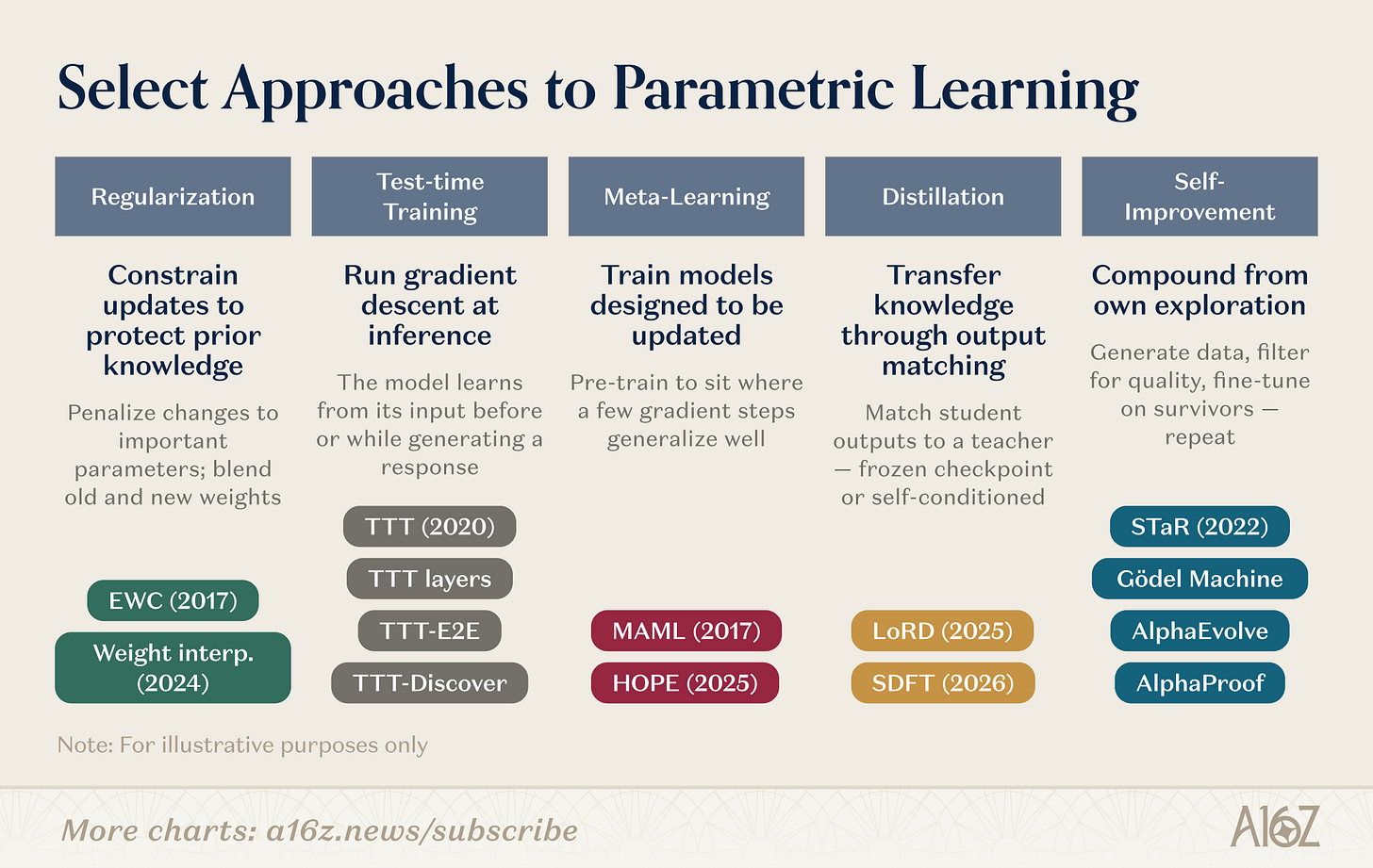
Caption: Overview of weight-level learning research directions
Weight-level research spans multiple parallel tracks. Regularization and weight-space methods have the longest history: Elastic Weight Consolidation (EWC; Kirkpatrick et al., 2017) penalizes parameter changes according to their importance for prior tasks; weight interpolation (Kozal et al., 2024) blends old and new weight configurations in parameter space—but both prove fragile at scale. Test-time training, pioneered by Sun et al. (2020), evolved into architectural primitives (TTT layers, TTT-E2E, TTT-Discover): gradient descent on test data, compressing new information into parameters precisely when needed. Meta-learning asks: Can we train models that know “how to learn”? From MAML’s few-shot-friendly parameter initialization (Finn et al., 2017) to Behrouz et al.’s nested learning (2025), which structures models as hierarchical optimization problems—running fast adaptation and slow updates on different timescales, inspired by biological memory consolidation.
Distillation preserves knowledge from prior tasks by having a student model match a frozen teacher checkpoint. LoRD (Liu et al., 2025) makes distillation efficient enough for continual use by simultaneously pruning the model and the replay buffer. Self-distillation (SDFT; Shenfeld et al., 2026) flips the source, using the model’s own expert-conditioned outputs as training signals—bypassing catastrophic forgetting in sequential fine-tuning. Recursive self-improvement operates on similar principles: STaR (Zelikman et al., 2022) bootstraps reasoning from self-generated chains of thought; AlphaEvolve (DeepMind, 2025) discovered algorithmic optimizations unimproved for decades; Silver and Sutton’s “Era of Experience” (2025) defines agent learning as an unceasing stream of continuous experience.
These research directions are converging. TTT-Discover integrates test-time training with RL-driven exploration. HOPE nests fast/slow learning cycles within a single architecture. SDFT turns distillation into a foundational self-improvement operation. Boundaries between columns are blurring. Next-generation continual learning systems will likely combine multiple strategies: regularization for stability, meta-learning for speed, self-improvement for compounding gains. A growing cohort of startups is betting on different layers of this tech stack.
The Startup Landscape for Continual Learning
The non-parametric end of the spectrum is most familiar. Shell companies (Letta, mem0, Subconscious) build orchestration layers and scaffolding to manage what goes into the context window. External storage and RAG infrastructure (e.g., Pinecone, xmemory) provide the retrieval backbone. Data exists; the challenge is delivering the right slice to the model at the right time. As context windows expand, the design space for these companies grows—especially on the shell side, where a wave of new startups is emerging to manage increasingly complex context strategies.
The parametric end is earlier-stage and more diverse. Companies here attempt some version of “post-deployment compression,” enabling models to internalize new information into weights. Paths roughly fall into several distinct bets about *how* models should learn after release.
Partial compression: Learn without retraining. Some teams build plug-and-play knowledge modules (compressed KV caches, adapter layers, external memory stores), allowing general-purpose models to specialize without altering core weights. The shared argument: you gain meaningful compression (not just retrieval) while keeping the stability-plasticity tradeoff manageable—since learning is isolated, not dispersed across the entire parameter space. An 8B model with suitable modules can match much larger models on targeted tasks. Advantages include composability: modules plug-and-play with existing Transformer architectures, can be swapped or updated independently, and carry far lower experimental cost than retraining.
RL and feedback loops: Learning from signals. Others bet that the richest learning signal post-deployment already exists within the deployment loop itself—user corrections, task success/failure, reward signals from real-world outcomes. Core idea: each interaction should serve as potential training data—not just an inference request. This mirrors how humans improve on the job: work, receive feedback, internalize what works. Engineering challenges involve converting sparse, noisy, sometimes adversarial feedback into stable weight updates—without catastrophic forgetting. Yet a model truly learning from deployment would generate compounding value in ways context systems cannot.
Data-centric: Learning from the right signals. A related but distinct bet holds that the bottleneck isn’t the learning algorithm—but the training data and surrounding systems. These teams focus on filtering, generating, or synthesizing the right data to drive continual updates: the premise is that a model fed high-quality, well-structured learning signals needs far fewer gradient steps to meaningfully improve. This naturally complements feedback-loop companies but emphasizes upstream concerns: *whether* a model can learn is one question; *what* it should learn from—and *how much*—is another.
New architectures: Designing learning capability into the foundation. The most radical bet posits that the Transformer architecture itself is the bottleneck—that continual learning demands fundamentally different computational primitives: architectures with continuous-time dynamics and built-in memory mechanisms. The argument is structural: if you want a continual learning system, embed the learning mechanism into the foundational architecture.

Caption: Startup landscape for continual learning
All major labs are also actively investing across these categories. Some explore improved context management and chain-of-thought reasoning; others experiment with external memory modules or sleep-time computation pipelines; several stealth companies pursue new architectures. The field remains early enough that no single approach has won—and given the breadth of use cases, there shouldn’t be just one winner.
Why Naive Weight Updates Fail
Updating model parameters in production triggers a cascade of failure modes currently unsolved at scale.

Caption: Failure modes of naive weight updates
Engineering issues are well documented. Catastrophic forgetting means models sensitive enough to new data to learn will destroy existing representations—the stability-plasticity dilemma. Temporal decoupling occurs when invariant rules and mutable states are compressed into the same weight set; updating one damages the other. Failed logical integration arises because fact updates don’t propagate to their implications: changes remain confined to token sequences—not semantic concepts. Unlearning remains impossible: no differentiable subtraction operation exists, so false or toxic knowledge lacks precise surgical removal.
A second class of problems receives less attention. The current separation between training and deployment isn’t merely an engineering convenience—it’s a boundary for safety, auditability, and governance. Opening this boundary causes multiple things to break simultaneously. Safety alignment may unpredictably degrade: even narrow fine-tuning on benign data can produce broad misalignment. Continuous updates create a data-poisoning attack surface—a slow, persistent variant of prompt injection, but living in weights. Auditability collapses, because a continuously updating model is a moving target—resisting version control, regression testing, or one-time certification. When user interactions are compressed into parameters, privacy risks intensify: sensitive information becomes baked into representations, harder to filter than in retrieved context.
These are open questions—not fundamental impossibilities. Solving them is as central to the continual learning research agenda as solving core architectural challenges.
From “Memento” to Real Memory
Leonard’s tragedy in Memento isn’t that he can’t function—he’s resourceful, even brilliant, in any given scene. His tragedy is that he can never compound. Every experience remains external—a Polaroid, a tattoo, a note in someone else’s handwriting. He can retrieve, but he cannot compress new knowledge.
As Leonard navigates his self-constructed maze, the boundary between truth and belief blurs. His condition doesn’t just deprive him of memory; it forces him to constantly reconstruct meaning, making him simultaneously detective and unreliable narrator of his own story.
Today’s AI operates under the same constraint. We’ve built extraordinarily powerful retrieval systems: longer context windows, smarter shells, coordinated multi-agent swarms—and they work. But retrieval is not learning. A system that can look up any fact is never forced to seek structure. It is never forced to generalize. The lossy compression that makes training so powerful—the mechanism transforming raw data into transferable representations—is precisely what we switch off at deployment.
The path forward likely isn’t a single breakthrough, but a layered system. In-context learning will remain the first line of adaptive defense: it’s native, battle-tested, and continually improving. Module mechanisms can handle the middle ground of personalization and domain specialization. But for truly hard problems—discovery, adversarial adaptation, implicit knowledge inexpressible in words—we may need models to continue compressing experience into parameters after training. This implies advances in sparse architectures, meta-learning objectives, and self-improvement loops. It may also require redefining what a “model” is—not a fixed set of weights, but an evolving system comprising its memory, its update algorithms, and its capacity to abstract from its own experience.
Filing cabinets keep growing. But even the largest filing cabinet remains a filing cabinet. The breakthrough lies in letting models do, post-deployment, what made them powerful during training: compress, abstract, learn. We stand at the inflection point—from amnesiac models to ones imbued with a glimmer of experiential insight. Otherwise, we remain trapped in our own Memento.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News









