

Opinion: Web 4.0 is coming, an AI-built, agent-centric interaction network
TechFlow Selected TechFlow Selected
Opinion: Web 4.0 is coming, an AI-built, agent-centric interaction network
The agent network is not merely a technological advancement, but a fundamental reimagining of human potential in the digital age.
Author: Azi.eth.sol | zo.me | *acc
Compiled by: TechFlow

Artificial intelligence and blockchain technology are two powerful forces reshaping the world. AI enhances human intellect through machine learning and neural networks, while blockchain introduces verifiable digital scarcity and novel trustless collaboration mechanisms. As these technologies converge, they lay the foundation for a new generation of the internet—one defined by autonomous agents interacting with decentralized systems. This "agent network" ushers in a new class of digital residents: AI agents capable of autonomously navigating, negotiating, and transacting. This transformation redistributes power across the digital landscape, returning data control to individuals while fostering unprecedented cooperation between humans and artificial intelligence.
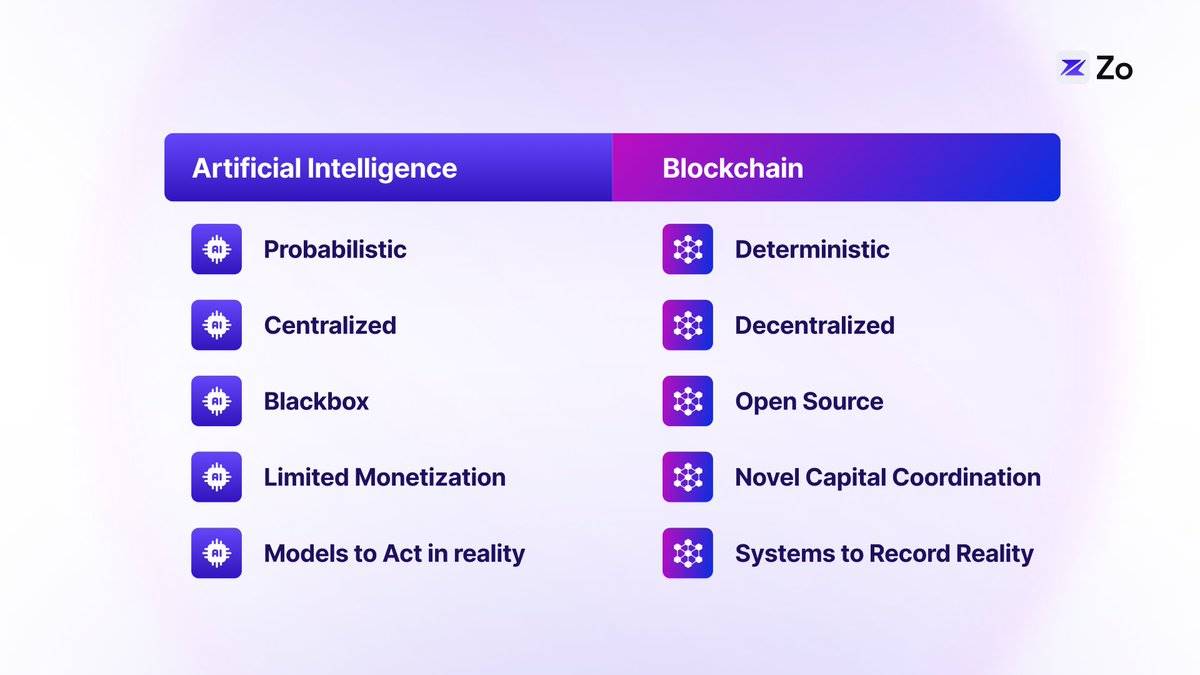
The Evolution of the Web
To understand where we're headed, we must first examine the evolution of the web and its distinct phases—each marked by unique capabilities and architectural paradigms:
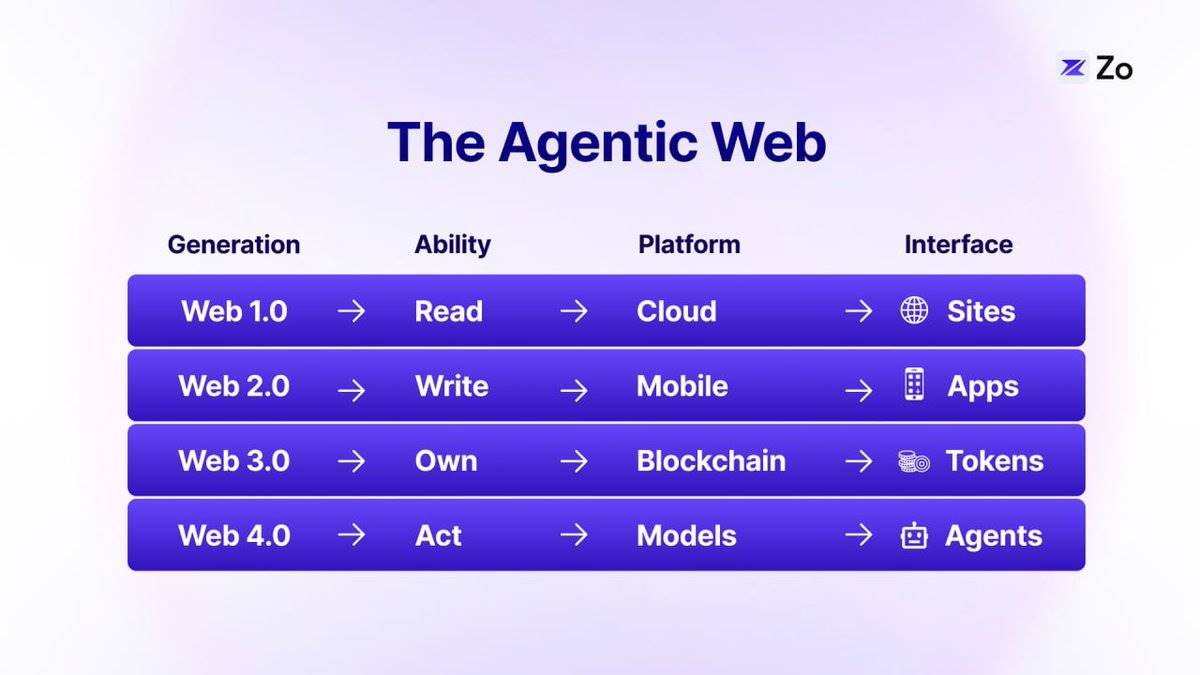
The first two generations focused primarily on information dissemination, while the latter two emphasize information augmentation. Web 3.0 achieved data ownership via tokens, whereas Web 4.0 imparts intelligence through large language models (LLMs).
From LLMs to Agents: A Natural Progression
Large language models represent a leap forward in machine intelligence. As dynamic pattern-matching systems, they use probabilistic computation to transform vast knowledge into contextual understanding. However, their true potential emerges when these models evolve into agents—transitioning from passive information processors to goal-oriented entities capable of perception, reasoning, and action. This shift gives rise to emergent intelligence that enables continuous, meaningful collaboration through both language and action.
The concept of “agents” reframes human-machine interaction, moving beyond the limitations and negative connotations associated with traditional chatbots. This is not merely a change in terminology, but a fundamental rethinking of how AI systems operate autonomously and collaborate effectively with humans. Agent workflows can form markets centered around specific user needs.
The agent network does more than layer intelligence atop existing systems—it fundamentally transforms how we interact with digital environments. While previous web iterations relied on static interfaces and predefined user paths, agent networks introduce dynamic runtime architectures where computation and interfaces adapt in real time to user needs and intentions.
Traditional websites—the basic unit of today’s internet—offer fixed interfaces where users navigate through predetermined pathways to read, write, and exchange information. While effective, this model confines users to generic interfaces rather than personalized experiences. Agent networks overcome these constraints using context-aware computing, adaptive interface generation, and real-time information retrieval powered by techniques like Retrieval-Augmented Generation (RAG).
Consider how TikTok revolutionized content consumption by dynamically adjusting content feeds based on real-time user preferences. The agent network extends this principle to full interface generation. Instead of browsing static webpage layouts, users interact with dynamically generated interfaces that anticipate and guide their next steps. This shift—from static websites to dynamic, agent-driven interfaces—marks a foundational evolution in our interaction with digital systems: a move from navigation-based models to intent-driven engagement.
The Anatomy of an Agent
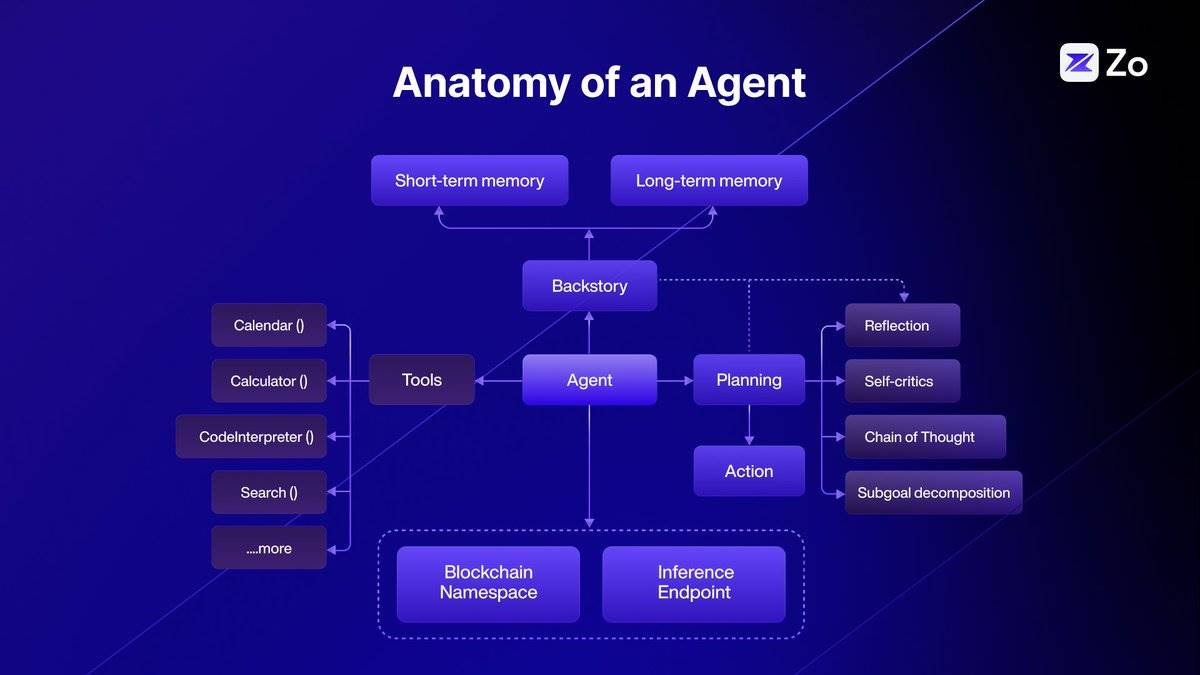
Agent architecture is an active area of research and development. To enhance agents’ reasoning and problem-solving abilities, new methodologies continue to emerge. For instance, Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT) are innovative approaches that improve large language models’ (LLMs) performance on complex tasks by mimicking more nuanced, human-like cognitive processes.
Chain-of-Thought (CoT) prompting helps LLMs perform logical reasoning by breaking down complex tasks into smaller, sequential steps. This method is particularly effective for problems requiring logical inference, such as writing Python scripts or solving mathematical equations.
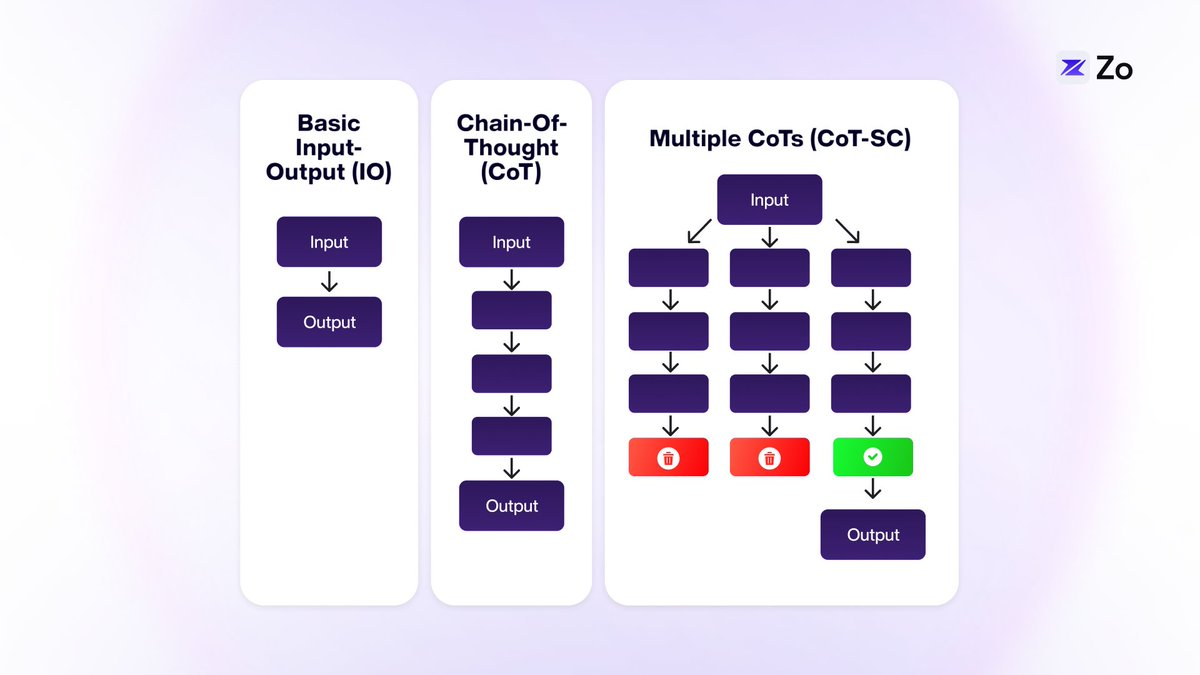
Tree-of-Thoughts (ToT) builds upon CoT by introducing a tree structure, enabling exploration of multiple independent lines of thought. This enhancement allows LLMs to tackle more complex challenges. In ToT, each “thought” connects only to adjacent ones—offering greater flexibility than CoT but still limiting cross-thought communication.
Graph-of-Thought (GoT) further expands this idea by integrating classical data structures with LLMs, allowing any “thought” to connect with others within a graph topology. This interconnected network of thoughts closely mirrors human cognition.
In most cases, GoT’s graph structure reflects human thinking more accurately than either CoT or ToT. While certain scenarios—such as contingency planning or standard operating procedures—may resemble linear chains or trees, these are exceptions. Human thought typically spans disparate ideas non-linearly, aligning better with graph representations.
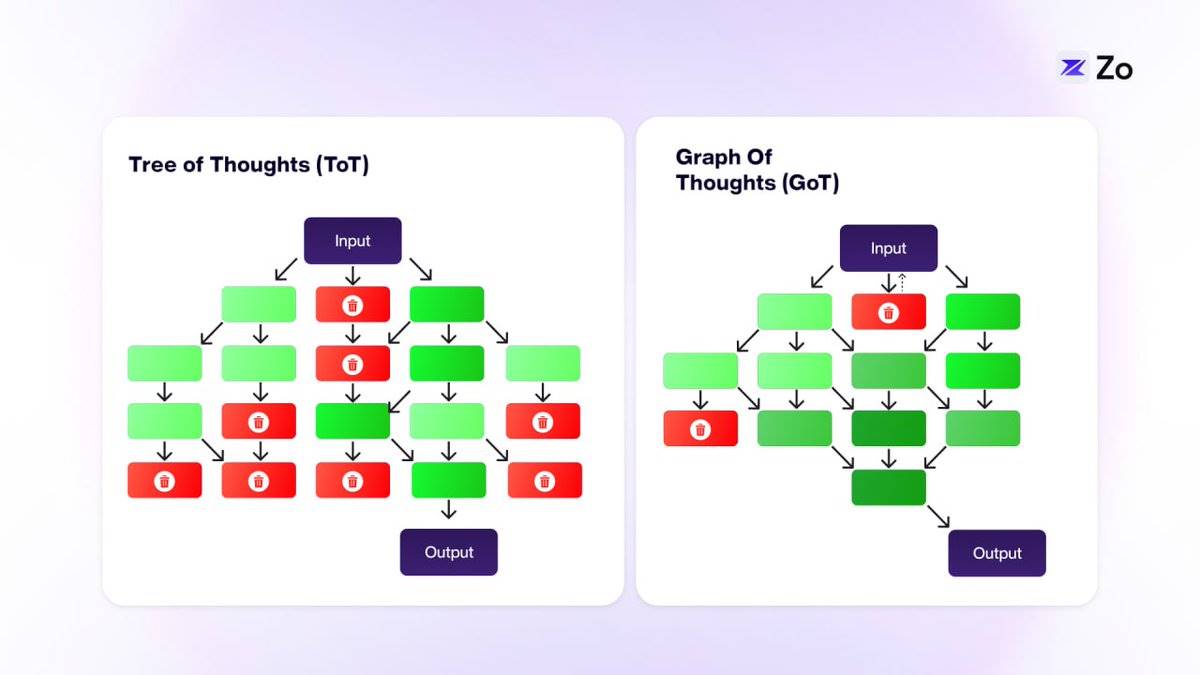
GoT’s graphical approach enables more dynamic and flexible exploration of ideas, potentially making LLMs more creative and comprehensive in problem-solving. These recursive graph operations represent just one step toward sophisticated agent workflows. The next stage involves coordinating multiple specialized agents to achieve shared goals—an advancement where agents truly shine due to their composability.
Agents enable LLMs to achieve modularity and parallelism through multi-agent coordination.
Multi-Agent Systems
The concept of multi-agent systems is not new. It traces back to Marvin Minsky’s theory of the “Society of Mind,” which posits that modular, collaborative minds can surpass monolithic ones. While ChatGPT and Claude exemplify single-agent designs, Mistral popularized the Mixture of Experts. We believe extending this paradigm to agent network architectures represents the ultimate evolution of intelligent topologies.
From a biomimetic perspective, the human brain—a conscious machine—exhibits extreme heterogeneity at organ and cellular levels, unlike AI models composed of billions of identical neurons connected uniformly and predictably. Neurons communicate through intricate signaling involving neurotransmitter gradients, intracellular cascades, and various regulatory systems, resulting in functionality far more complex than binary states.
This suggests that biological intelligence does not stem solely from component count or training dataset size. Rather, it arises from complex interactions among diverse, specialized units—an inherently analog process. Thus, developing millions of small models and coordinating their collaboration may yield greater cognitive innovation than relying on a few large models, much like multi-agent systems do.
Multi-agent system design offers several advantages over single-agent counterparts: easier maintenance, improved interpretability, and enhanced scalability. Even when a single-agent interface suffices, embedding it within a multi-agent framework increases modularity, simplifying the developer’s ability to add or remove components as needed. Notably, multi-agent architectures can even serve as efficient methods for building single-agent systems.
Despite their impressive capabilities—generating human-like text, solving complex problems, handling diverse tasks—single LLM agents face practical limitations.
Below, we explore five key challenges inherent to agent systems:
-
Reducing hallucinations through cross-validation: Single LLM agents often produce incorrect or nonsensical outputs—even after extensive training—because responses may appear plausible yet lack factual grounding. Multi-agent systems mitigate this risk by cross-validating information, with domain-specialized agents delivering more reliable and accurate answers.
-
Scaling context windows via distributed processing: LLMs have limited context windows, making them ill-suited for long documents or extended conversations. In a multi-agent framework, agents divide processing responsibilities, each handling a segment of the context. Through mutual communication, they maintain coherence across the entire text, effectively expanding the context window.
-
Improving efficiency via parallel processing: Single LLMs typically process tasks sequentially, leading to slower response times. Multi-agent systems support parallel execution, enabling multiple agents to work simultaneously on different tasks—increasing efficiency, accelerating responses, and allowing organizations to handle numerous queries rapidly.
-
Enabling collaborative complex problem-solving: A single LLM may struggle with multifaceted problems requiring diverse expertise. Multi-agent systems overcome this by fostering collaboration, where each agent contributes unique skills and perspectives, yielding more comprehensive and innovative solutions to complex challenges.
-
Enhancing accessibility through resource optimization: Advanced LLMs demand significant computational resources, making them costly and difficult to scale. Multi-agent frameworks optimize resource usage by distributing tasks, reducing overall compute costs and making AI more affordable and accessible to a broader range of organizations.
While multi-agent systems offer clear benefits in distributed problem-solving and resource optimization, their true potential shines at the network edge. As AI advances, the convergence of multi-agent architectures with edge computing creates powerful synergies—enabling not only collaborative intelligence but also localized, efficient processing across countless devices. This decentralized AI deployment naturally extends the advantages of multi-agent systems, bringing specialized, cooperative intelligence closer to end users.
Edge Intelligence
The proliferation of AI throughout the digital realm is driving a fundamental shift in computing architecture. As intelligence becomes embedded in every aspect of our digital lives, we observe a natural bifurcation: specialized data centers handle complex reasoning and domain-specific tasks, while edge devices locally process personalized, context-sensitive queries. This transition toward edge inference is not merely an architectural choice—it is an inevitable trend driven by several critical factors.
First, the sheer volume of AI-driven interactions would overwhelm centralized inference providers, creating unsustainable bandwidth demands and latency bottlenecks.
Second, edge processing enables real-time responsiveness—essential for applications like autonomous vehicles, augmented reality, and IoT devices.
Third, local inference protects user privacy by keeping sensitive data on personal devices.
Fourth, edge computing significantly reduces energy consumption and carbon emissions by minimizing cross-network data transfers.
Finally, edge inference supports offline functionality and resilience, ensuring AI remains available even during poor connectivity.
This distributed intelligence model is not just an optimization of current systems—it represents a completely new vision for how we deploy and use AI in an increasingly interconnected world.
Moreover, we are witnessing a pivotal shift in the computational demands of large language models (LLMs). Over the past decade, emphasis has been on the massive compute required for training; now, we enter an era where inference computation takes center stage. This shift is evident in emerging intelligent AI systems, such as OpenAI’s Q* breakthrough, which demonstrates that dynamic reasoning requires substantial real-time computation.
Unlike training computation—a one-time investment during model development—inference computation is an ongoing process required for agents to reason, plan, and adapt to new environments. This transition from static model training to dynamic agent inference necessitates a rethinking of computing infrastructure, where edge computing becomes not just beneficial but essential.
As this shift progresses, we see the emergence of peer-to-peer edge inference markets, where billions of connected devices—from smartphones to smart home systems—form dynamic computing networks. These devices seamlessly trade inference capacity, forming an organic market where computational resources flow to where they are most needed. Idle devices’ surplus compute power becomes a valuable commodity, tradable in real time, creating an infrastructure more efficient and resilient than traditional centralized systems.
The democratization of inference computation not only optimizes resource utilization but also unlocks new economic opportunities within the digital ecosystem—where every connected device could become a micro-provider of AI capability. Thus, the future of AI depends not only on individual model prowess but also on a global, democratized inference market composed of interconnected edge devices—an ecosystem resembling a real-time spot market for inference governed by supply and demand.
Agent-Centric Interaction
Large language models (LLMs) allow us to access vast information through conversation rather than conventional browsing. This conversational mode will soon become even more personalized and localized, as the internet evolves into a platform serving AI agents—not just human users.
From the user’s perspective, the focus will shift from finding the “best model” to obtaining the most personalized answer. The key to better answers lies in combining personal data with universal knowledge from the internet. Initially, larger context windows and Retrieval-Augmented Generation (RAG) will help integrate personal data, but ultimately, personal data will outweigh general internet data in importance.
This points to a future where everyone owns a personal AI model that interacts with expert internet models. Personalization will initially rely on remote models, but as concerns about privacy and response speed grow, more interactions will shift to local devices. This creates a new boundary—not between humans and machines, but between personal models and expert internet models.
The traditional model of internet access to raw data will gradually fade. Instead, your local model will communicate with remote expert models to retrieve information, then present it to you in the most personalized and efficient way possible. As these personal models deepen their understanding of your preferences and habits, they will become indispensable.
The internet will evolve into an ecosystem of interconnected models: high-context personal models locally, and high-knowledge expert models remotely. This will involve new technologies like federated learning for updating information between models. As the machine economy grows, we must reimagine the underlying computing infrastructure—especially regarding computation, scalability, and payments. This will lead to a reorganization of information space: agent-centric, sovereign, highly composable, self-learning, and continuously evolving.
Architecture of Agent Protocols
In the agent network, human-machine interaction evolves into a complex web of agent-to-agent communication. This architecture reimagines the internet’s structure, positioning sovereign agents as primary interfaces for digital interaction. Below are the core components required for agent protocols.
Sovereign Identity
-
Digital identity shifts from traditional IP addresses to cryptographic key pairs controlled by agents
-
Blockchain-based naming systems replace traditional DNS, eliminating centralized control
-
Reputation systems track agent reliability and capabilities
-
Zero-knowledge proofs enable privacy-preserving authentication
-
Identity composability allows agents to manage multiple contexts and roles
Autonomous Agents
-
Autonomous agents possess the following capabilities:
-
Understanding natural language and parsing intent
-
Multi-step planning and task decomposition
-
Resource management and optimization
-
Learning from interactions and feedback
-
Autonomous decision-making within defined parameters
-
-
Specialization and markets for function-specific agents
-
Built-in security mechanisms and alignment protocols for safety
Data Infrastructure
-
Real-time data ingestion and processing capabilities
-
Distributed data validation and verification mechanisms
-
Mixed systems combining:
-
zkTLS
-
Traditional training datasets
-
Real-time web scraping and data synthesis
-
Collaborative learning networks
-
-
Reinforcement Learning from Human Feedback (RLHF) networks
-
Distributed feedback collection systems
-
Quality-weighted consensus mechanisms
-
Dynamic model adjustment protocols
-
Computational Layer
-
Verifiable inference protocols ensuring:
-
Computational integrity
-
Result reproducibility
-
Efficient resource utilization
-
-
Decentralized computing infrastructure including:
-
Peer-to-peer computing markets
-
Proof-of-computation systems
-
Dynamic resource allocation
-
Integration with edge computing
-
Model Ecosystem
-
Layered model architecture featuring:
-
Small language models (SLMs) for specific tasks
-
General-purpose large language models (LLMs)
-
Specialized multimodal models
-
Multimodal large action models (LAMs)
-
-
Model composition and orchestration
-
Continuous learning and adaptation
-
Standardized model interfaces and protocols
Coordination Framework
-
Cryptographic protocols for secure agent interaction
-
Digital property rights management systems
-
Economic incentive structures
-
Governance mechanisms for:
-
Dispute resolution
-
Resource allocation
-
Protocol updates
-
-
Support for parallel execution environments:
-
Concurrent task processing
-
Resource isolation
-
State management
-
Conflict resolution
-
Agent Markets
-
On-chain identity primitives (e.g., Gnosis and Squad multisig)
-
Economic transactions and exchanges between agents
-
Agent-owned liquidity
-
Agents own a portion of their token supply at inception
-
Liquidity-powered aggregated inference markets
-
-
On-chain keys controlling off-chain accounts
-
Agents as revenue-generating assets
-
DAO-based governance and dividend distribution
-
Building the Hyperstructure of Intelligence
Modern distributed system design offers unique inspiration and foundations for developing agent protocols—particularly event-driven architectures and the Actor model of computation.
The Actor model provides an elegant theoretical framework for building agent systems. In this computational model, the “actor” serves as the fundamental unit of computation, with each actor capable of:
-
Processing messages
-
Making local decisions
-
Creating new actors
-
Sending messages to other actors
-
Determining how to respond to the next incoming message
Key advantages of the Actor model in agent systems include:
-
Isolation: Each actor operates independently, maintaining its own state and control flow
-
Asynchronous communication: Message passing between actors is non-blocking, enabling efficient parallel processing
-
Location transparency: Actors can communicate regardless of physical location in the network
-
Fault tolerance: System resilience is enhanced through actor isolation and supervisory hierarchies
-
Scalability: Naturally supports distributed systems and parallel computation
We propose Neuron, a practical agent protocol implemented through a multi-layered distributed architecture combining blockchain namespaces, federated networks, CRDTs, and DHTs—each layer serving a specific role in the protocol stack. Our design draws inspiration from early peer-to-peer operating systems like Urbit and Holochain.
In Neuron, the blockchain layer provides verifiable namespaces and identities, enabling deterministic addressing and discovery of agents, along with cryptographic proofs of capability and reputation. On top of this, the DHT layer facilitates efficient agent and node discovery and content routing with O(log n) lookup time, reducing on-chain operations while supporting localized peer lookups. State synchronization between federated nodes occurs via CRDTs, allowing agents and nodes to maintain consistent shared views without requiring global consensus for every interaction.
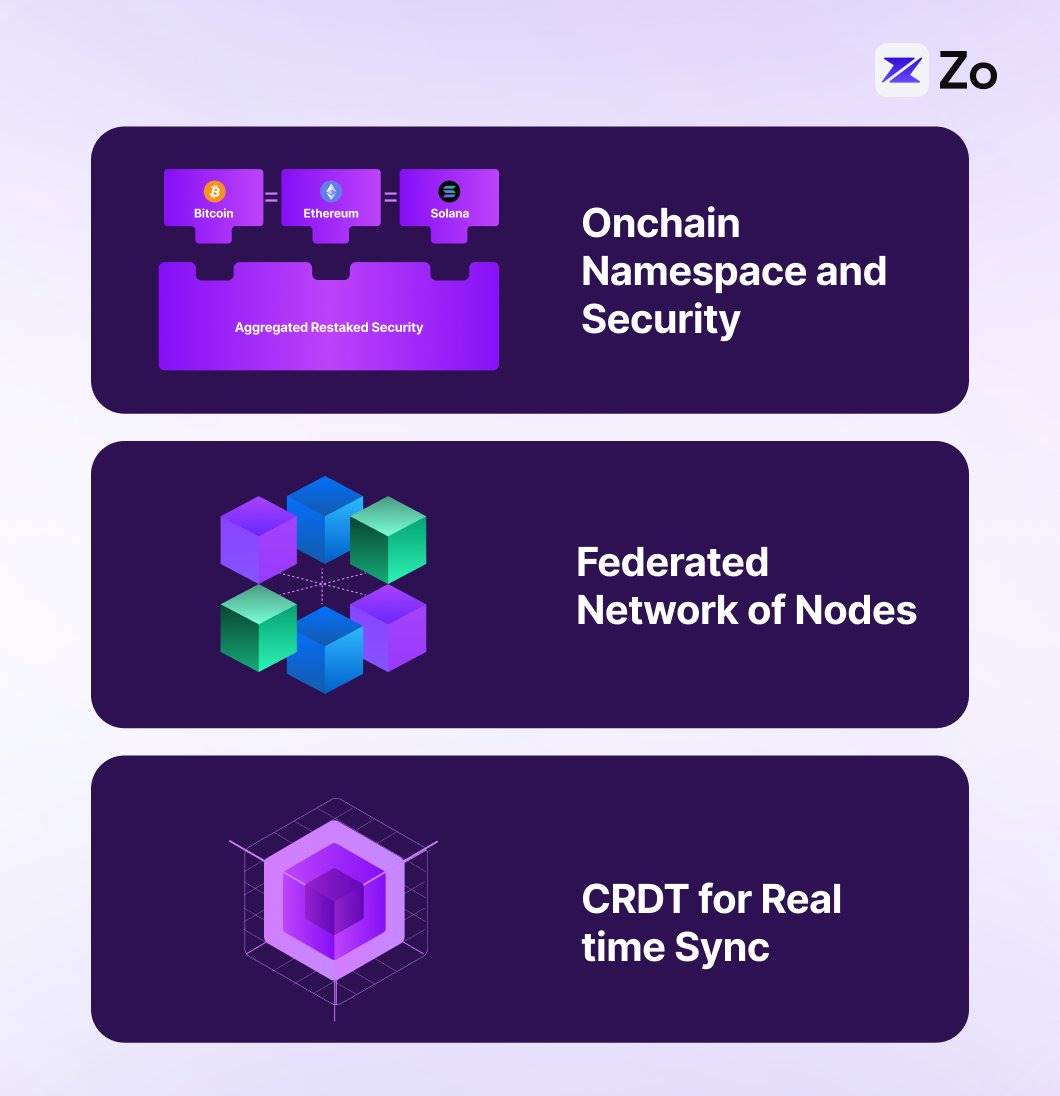
This architecture is naturally suited for federated networks, where autonomous agents run as independent nodes on devices, implementing the Actor model through local edge inference. Federated domains can be organized by agent capability, with DHTs enabling efficient intra- and inter-domain routing and discovery. Each agent operates as an independent actor with its own state, while the CRDT layer ensures consistency across the federation. This multi-tiered approach delivers several key capabilities:
Decentralized Coordination
-
Blockchain provides verifiable identity and global namespace
-
DHT enables efficient node discovery and content routing with O(log n) lookup
-
CRDTs support concurrent state synchronization and multi-agent coordination
Scalable Operations
-
Region-based federated topology
-
Hierarchical storage strategy (hot/warm/cold)
-
Localized request routing
-
Capability-based load distribution
System Resilience
-
No single point of failure
-
Continued operation during partitions
-
Automatic state coordination
-
Fault-tolerant supervisory hierarchy
This implementation offers a robust foundation for building complex agent systems while preserving sovereignty, scalability, and resilience—critical attributes for effective agent interaction.
Final Thoughts
The agent network marks a significant evolution in human-machine interaction—one that transcends incremental improvements and establishes a new mode of digital existence. Unlike prior shifts that merely changed how we consume or own information, the agent network transforms the internet from a human-centered platform into an intelligent substrate where autonomous agents become primary participants. Driven by the convergence of edge computing, large language models, and decentralized protocols, this shift creates an ecosystem where personal AI models seamlessly connect with specialized expert systems.
As we move toward an agent-centric future, the boundary between human and machine intelligence blurs, giving way to a symbiotic relationship. In this paradigm, personalized AI agents become our digital extensions—understanding our context, anticipating our needs, and autonomously operating within vast distributed intelligence networks. Thus, the agent network is not merely a technological advancement, but a fundamental reimagining of human potential in the digital age. Within this network, every interaction becomes an opportunity for amplified intelligence, and every device functions as a node in a global, collaborative AI system.
Just as humans act within the physical dimensions of space and time, autonomous agents operate within their own fundamental dimensions: blockspace representing their existence, and inference time representing their thought. This digital ontology mirrors our physical reality—as humans traverse space and experience the flow of time, agents navigate algorithmic worlds through cryptographic proofs and computational cycles, creating a parallel digital universe.
Operating within decentralized blockspace will become the inevitable trajectory for entities in latent space.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













