

Proof of Validator: The Key Security Puzzle Piece on Ethereum's Scaling Journey
TechFlow Selected TechFlow Selected
Proof of Validator: The Key Security Puzzle Piece on Ethereum's Scaling Journey
Performance and security are paramount for Ethereum. The former determines the upper limit, while the latter defines the baseline.
By TechFlow

Today, a new concept quietly emerged on the Ethereum Research Forum: Proof of Validator.
This protocol mechanism allows network nodes to prove they are Ethereum validators without revealing their specific identities.

What does this have to do with us?
Typically, the market tends to focus more on surface-level narratives brought by technological innovations on Ethereum, rarely diving deep into the underlying technology ahead of time. For example, with Ethereum's Shanghai upgrade, the Merge, the transition from PoW to PoS, and scaling efforts, the market only remembers the narratives around LSD, LSDFi, and restaking.
But don't forget, performance and security are Ethereum's top priorities. The former determines the ceiling; the latter determines the floor.
It is evident that while Ethereum continues to actively pursue various scaling solutions to improve performance, it must also defend against external attacks along the way—not just rely on internal improvements.
For instance, if validator nodes are attacked, leading to data unavailability, every narrative and scaling solution built upon Ethereum’s staking logic could collapse as a result. However, such risks and impacts remain hidden behind the scenes, often unnoticed or even ignored by end users and speculators.
And the Proof of Validator discussed in this article might just be the critical security puzzle piece for Ethereum’s scaling journey.
Since scaling is inevitable, reducing the risks embedded within the process is an unavoidable security issue—one that concerns each and every one of us in the ecosystem.
Therefore, it is necessary to fully understand the newly proposed Proof of Validator. However, because the original forum post is too fragmented and technically dense—touching on numerous scaling schemes and concepts—TechFlow Research has consolidated the original thread and essential background information to interpret the context, necessity, and potential implications of Proof of Validator.
Data Sampling (Data Availability Sampling): The Breakthrough for Scaling
Hold on—before formally introducing Proof of Validator, it’s important to first understand Ethereum’s current scaling logic and its associated risks.
The Ethereum community is actively advancing multiple scaling initiatives. Among them, Data Availability Sampling (DAS) is considered one of the most crucial technologies.
The principle involves splitting complete block data into several “samples,” allowing nodes in the network to verify the entire block by retrieving only a few relevant samples.
This greatly reduces storage and computational requirements for individual nodes. To put it simply, it’s similar to a poll or survey: by sampling responses from different individuals, we can infer the overall condition of the entire population.

More specifically, DAS works as follows:
-
Block producers divide block data into multiple samples.
-
Each network node retrieves only a few samples it cares about, rather than the full block data.
-
Network nodes can randomly sample different pieces to verify whether the complete block data is available.
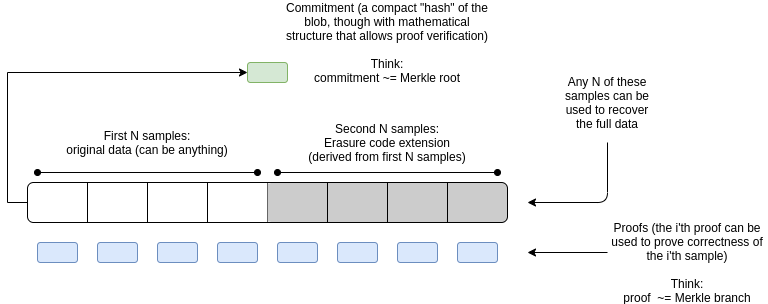
Through this method, even though each node processes only a small amount of data, collectively they can fully verify the data availability of the entire blockchain. This enables significantly larger block sizes and rapid scaling.
However, this sampling approach raises a key question: where should these massive samples be stored? This requires a full decentralized network infrastructure to support it.
Distributed Hash Table (DHT): The Home for Samples
This is where the Distributed Hash Table (DHT) comes into play.
A DHT can be seen as a massive distributed database that uses hash functions to map data into an address space, with different nodes responsible for storing and retrieving data from different segments of that space. It enables fast lookup and storage of samples across a vast number of nodes.
Specifically, after DAS divides block data into multiple samples, these samples need to be distributed across different nodes in the network for storage. DHT provides a decentralized method for storing and retrieving these samples. The basic idea is:
-
Use a consistent hash function to map each sample to a large address space.
-
Each node in the network is responsible for storing and providing data samples within a certain address range.
- When a sample is needed, its corresponding address is found via hashing, and the network locates the node responsible for that address range to retrieve the sample.
For example, following a set rule, each sample is hashed to an address. Node A handles addresses 0–1000, and Node B handles 1001–2000.
Then, the sample with address 599 would be stored on Node A. To retrieve it, the same hash function finds address 599, and the network locates Node A—the node responsible for that range—and fetches the sample from it.
This approach breaks the limitations of centralized storage, greatly enhancing fault tolerance and scalability—the very network infrastructure required by DAS for sample storage.
Compared to centralized storage and retrieval, DHT improves fault tolerance by avoiding single points of failure and enhances network scalability. Additionally, DHT helps defend against attacks like “sample hiding” mentioned in DAS.
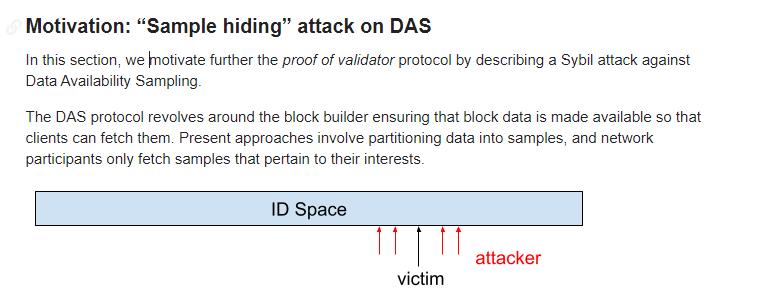
The Weakness of DHT: Sybil Attacks
However, DHT has a fatal flaw: it is vulnerable to Sybil attacks. An attacker can generate a large number of fake nodes, overwhelming genuine ones in the network.
To draw an analogy, an honest vendor surrounded by rows of counterfeit goods makes it difficult for users to find the real product. In this way, attackers can control the DHT network, rendering samples unavailable.
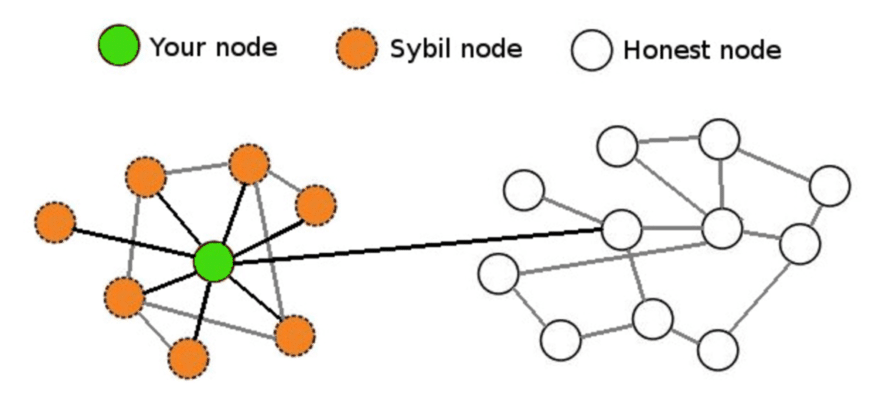
For example, to retrieve the sample at address 1000, one must locate the node responsible for that address. But if the network is flooded with thousands of fake nodes created by an attacker, requests will be misdirected to fake nodes instead of reaching the legitimate one. As a result, the sample cannot be retrieved, and both storage and verification fail.
To solve this, a high-trust network layer needs to be established on top of DHT, composed solely of validator nodes. However, the DHT network itself cannot identify whether a node is actually a validator.
This severely hinders DAS and Ethereum’s scaling efforts. Is there a way to resist this threat and ensure network trustworthiness?
Proof of Validator: A ZK Solution to Secure Scaling
Now, let’s return to the main topic of this article: Proof of Validator.
On the Ethereum Research Forum today, George Kadianakis, Mary Maller, Andrija Novakovic, and Suphanat Chunhapanya jointly proposed this scheme.
The core idea is this: if we can devise a way to allow only honest validators to join the DHT in the previous section’s scaling design, then any malicious actor attempting a Sybil attack would also need to stake significant amounts of ETH, thereby substantially increasing the economic cost of attacking the network.
To put it in more familiar terms: I want to know you’re trustworthy without knowing your identity—and be able to identify bad actors.
Zero-knowledge proofs are clearly well-suited for such scenarios involving limited-information verification.
Thus, Proof of Validator (PoV) can be used to build a highly trusted DHT network composed exclusively of honest validator nodes, effectively resisting Sybil attacks.
The basic idea is: each validator registers a public key on-chain, then uses zero-knowledge proof techniques to demonstrate knowledge of the corresponding private key. This acts as a form of identity verification proving that the node is indeed a validator.
Moreover, to protect validators against DoS (Denial-of-Service) attacks, PoV aims to hide the identities of validators at the network layer. In other words, the protocol ensures attackers cannot determine which DHT node corresponds to which validator.
So how exactly is this achieved? The original post includes extensive mathematical formulas and derivations, which we won’t repeat here. Instead, we provide a simplified version:

In practice, this uses structures like Merkle trees or lookup tables. For example, using a Merkle tree, a node proves that its registered public key exists within a public key list (represented as a Merkle tree), and further proves that the network communication public key derived from it matches. The entire process relies on zero-knowledge proofs and does not reveal actual identities.
Skipping over these technical details, the ultimate effect achieved by PoV is:
Only nodes that pass identity verification can join the DHT network, greatly enhancing security, effectively resisting Sybil attacks, and preventing samples from being deliberately hidden or altered. PoV provides a reliable foundational network for DAS, indirectly supporting Ethereum’s rapid scaling.
However, PoV is currently still in the theoretical research phase, and its practical implementation remains uncertain.
Still, the researchers behind the proposal have conducted small-scale experiments, which show promising results in terms of both the efficiency of generating ZK proofs and the speed at which validators verify them. Notably, their test setup was just a regular laptop equipped with a five-year-old Intel i7 processor.
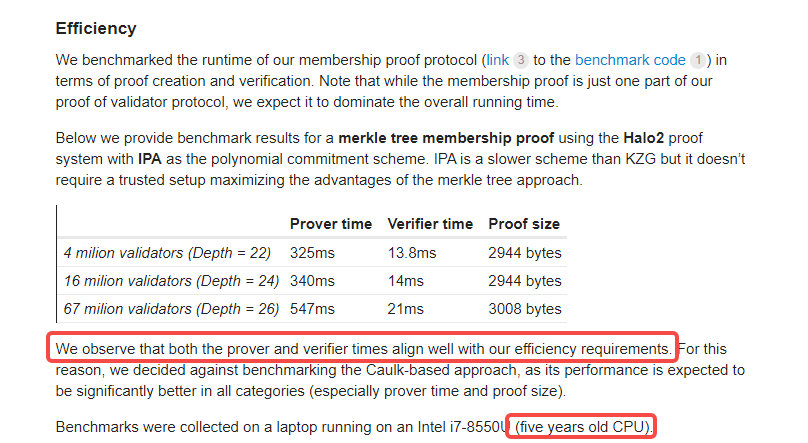
Finally, while PoV remains in the theoretical stage and its real-world deployment is uncertain, it nonetheless represents a significant step toward greater blockchain scalability. As a key component in Ethereum’s scaling roadmap, it deserves sustained attention from the entire industry.
Original PoV post: Link
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














