

中美 AI 競速邁向 2027 臨界點,WHY Monad?
TechFlow Selected深潮精選
中美 AI 競速邁向 2027 臨界點,WHY Monad?
Monad 是區塊鏈 AI 項目 Build 的不二選擇。
作者:Harvey C
從去年開始,全球對人工智能的熱情就開始持續升溫。無論是海外科技巨頭還是國內研究機構,都在瘋狂加大對AI模型的投入與發佈節奏。
今天,我們從中美AI的賽跑現狀、對2027年可能出現的里程碑時刻的預期,以及為什麼AI項目應該選擇在Monad上構建,來聊聊AI未來的巨大潛能與機遇。
1. 中美AI競速:算力受限下依然進展神速
近年來,美方對中國AI產業的算力芯片封鎖廣受關注。然而,從實際成果來看,“硬件瓶頸”並沒有如想象般大幅延緩大陸AI的研究進程。就拿近期中美大模型的迭代速度來說,差距已經縮小到幾個月甚至更短。
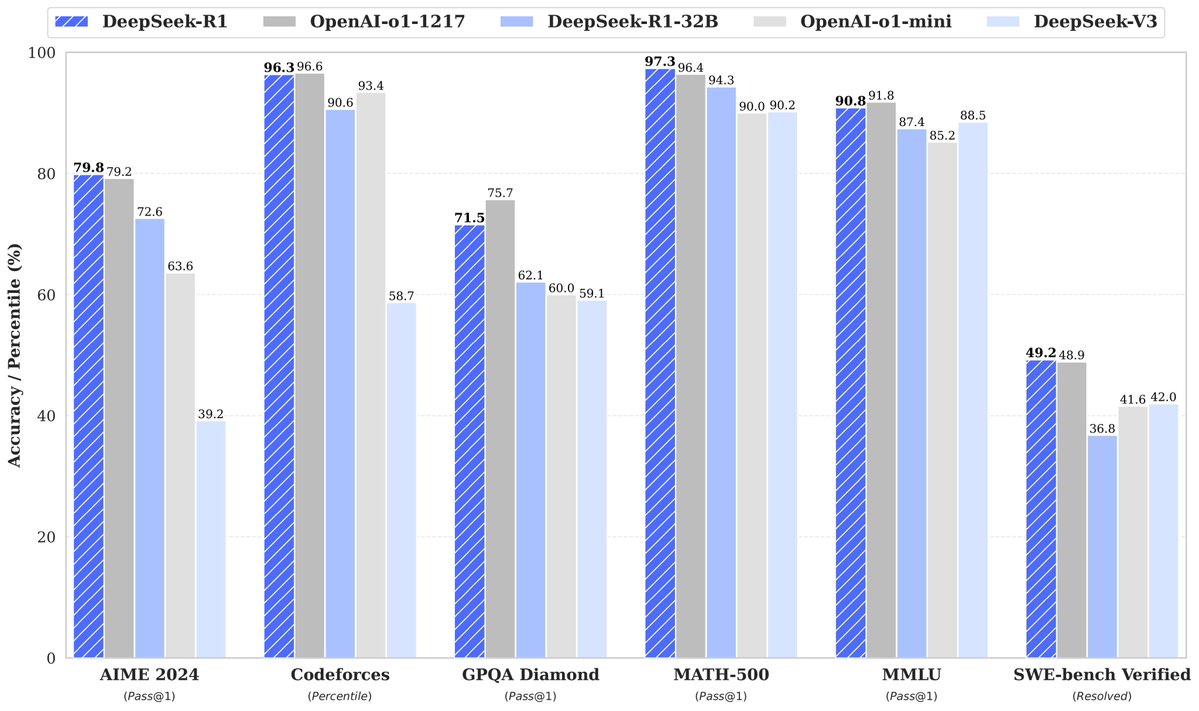
-
追趕者的實力:OpenAI推出的“o1-preview”不過四個月前,o1正式版也只是在一個月前上線。幾乎在同一時間段,大陸就有了與之指標相當的推理模型。量化巨頭幻方旗下大模型公司DeepSeek就推出開源推理模型DeepSeek-R1在多項指標上與o1難分伯仲,甚至在一些定製化場景上更加“接地氣”,此前DeepSeek的 V3 的發佈,已經強烈讓 Llama 4感受東方趕超的壓力。另外,Kimi發佈了全新的強化學習模型k1.5,OpenAI之後首個多模態類o1模型,能同時對文本與圖像進行聯合推理。
-
語音多模態的爆發:豆包GPT-4o高級語音模式對標Gemini 2.0和GPT-4o,也同樣在國內迅速亮相。這些技術原本被認為是高算力專屬,但顯然大陸廠商通過多種繞行和優化算法,做到了在算力不充分的條件下依舊快速迭代。
從這一系列跡象可以看出,即便算力仍存在差距,大陸的AI研究者也在快速追隨海外腳步。只要有前人試錯鋪路,後來者往往能省下昂貴的“碰壁成本”。
2. 海外領跑者的經驗,給追趕者提供“抄作業”的機會
在深度學習蓬勃發展的這些年,行業對AI範式的理解也在不斷演進。大型語言模型(LLM)成了當前的熱點,但與此同時,另一條路線——強化學習(Reinforcement Learning),正在重新獲得更多關注。
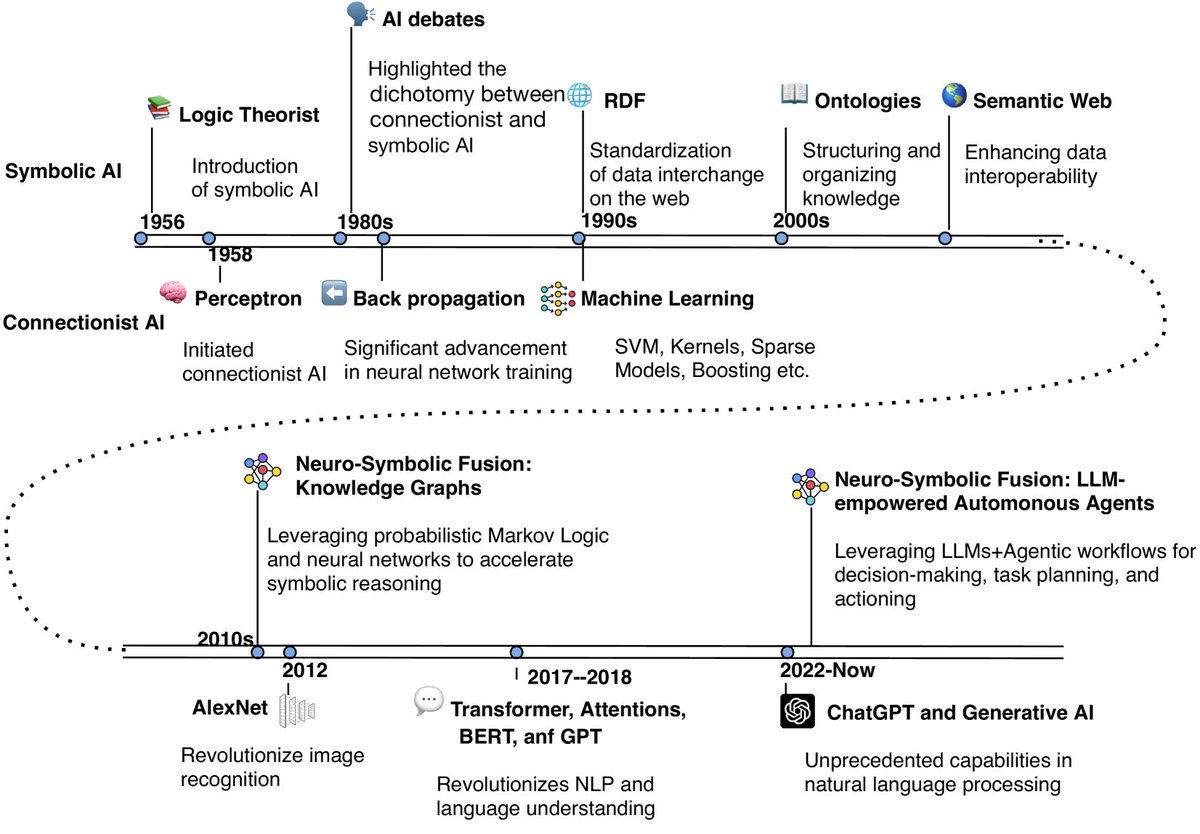
AI範式演進
-
AI範式隨時代轉變:人工智能發展分為幾個主要分支,符號主義(基於邏輯的 AI)以規則推理和形式邏輯為核心,擅長處理確定性任務;連接主義(神經網絡)模仿人腦的計算方式,通過分層結構從數據中識別模式。貝葉斯人工智能(概率 AI)強調通過概率建模不確定性,強化學習(RL)通過動態環境中的試錯優化行為,進化人工智能利用自然選擇的原理來進化解決方案,混合人工智能結合多個範式的優勢,打造更強大、更靈活的系統。這些範式隨著時間演進而各領千秋。
-
快速複製與迭代:海外先跑一步,大陸就能在模式驗證後以更低成本迅速跟進。例如多模態甚至o1推理模型等。互聯網時代的歐美研發、大陸商業化的老路讓人感覺似曾相似,實現路徑已在歐美踩過坑,大陸團隊通過復現和改良,用時往往大大縮短。
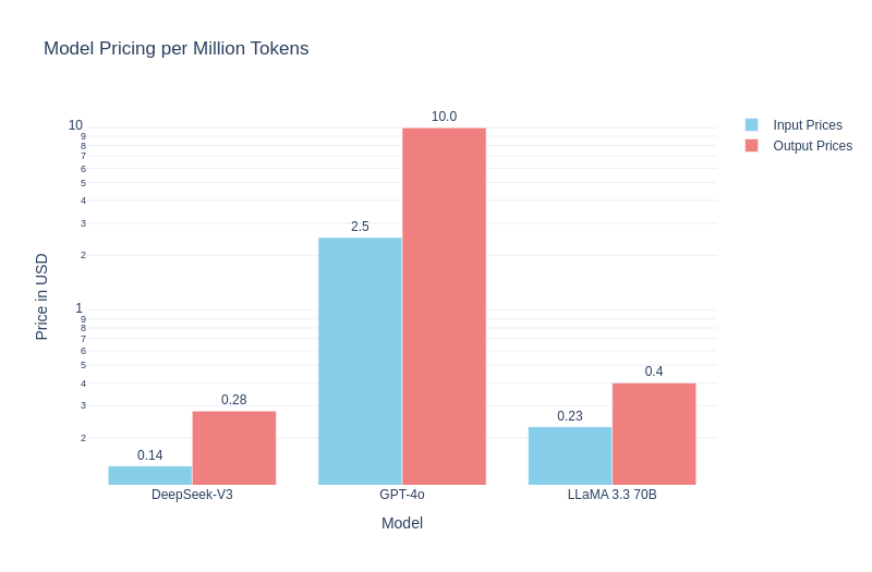
大陸的DeepSeek通過增強訓練以更低成本帶給美國競爭對手極大壓力
一方面,海外的一線實驗室為行業打下了前沿探索的基礎;另一方面,大陸團隊也並非只是被動追隨,而是不斷“融會貫通”,並且在算力資源相對受限情況下,另闢蹊徑,在強化學習與推理方面做出更靈活的落地方案。
3. 強化學習或許是近期AI新的突破口
DeepSeek近期推出的新模型,用強化學習取代大部分有監督微調(SFT),從而降低了對特定領域數據標註的依賴。這打開了垂直領域泛化的可能性:只要有一個明確的獎勵函數,模型就能在自我迭代中持續提升推理能力,在1的開源分享中,我型在強化學習環境裡自我探索,讓該模型具備一定程度的自我優化能力。
這意味著不需大量只要有足夠算力,模型就能依賴RL路徑持續進化。儘管美國在硬件和技術上對中國施加限制,但這種“另闢蹊徑”的方法降低了對傳統大規模訓練資源的需求,也讓更多大陸研究者看到快速追上的可行性,值得其他希望擁有自身大模型能力的組織仿效學習。
4. 2027年或許是AI時刻,大量工作會被取代或重新定義
AI的突飛猛進,讓我們思考究竟速度有多快和極限在哪裡,近日Anthropic的CEO Dario表示:“2027年會看到模型在絕大多數領域超過人類,背後的原因不脫以下因素:
-
強化學習的連續迭代:與過去“訓練-測試-推理”嚴格分離的方式不同,在深度學習高度發展的情況下,新一波AI能力的突破可能會採用混合方式比如結合強化學習方式進行自我迭代,“在線”反思與更新,讓它們的認知能力快速躍升。
-
產業資本的強力支持:芯片製造龍頭臺積電近期在業績發佈會上給出的預期顯示,AI業務在2024~2029年的年複合增長率可達45%左右,到2029年可能是2024年的近20倍。背後的需求主要來自OpenAI等巨頭的算力投入。這同樣預示著AI將滲透到幾乎所有能夠想象的應用領域。
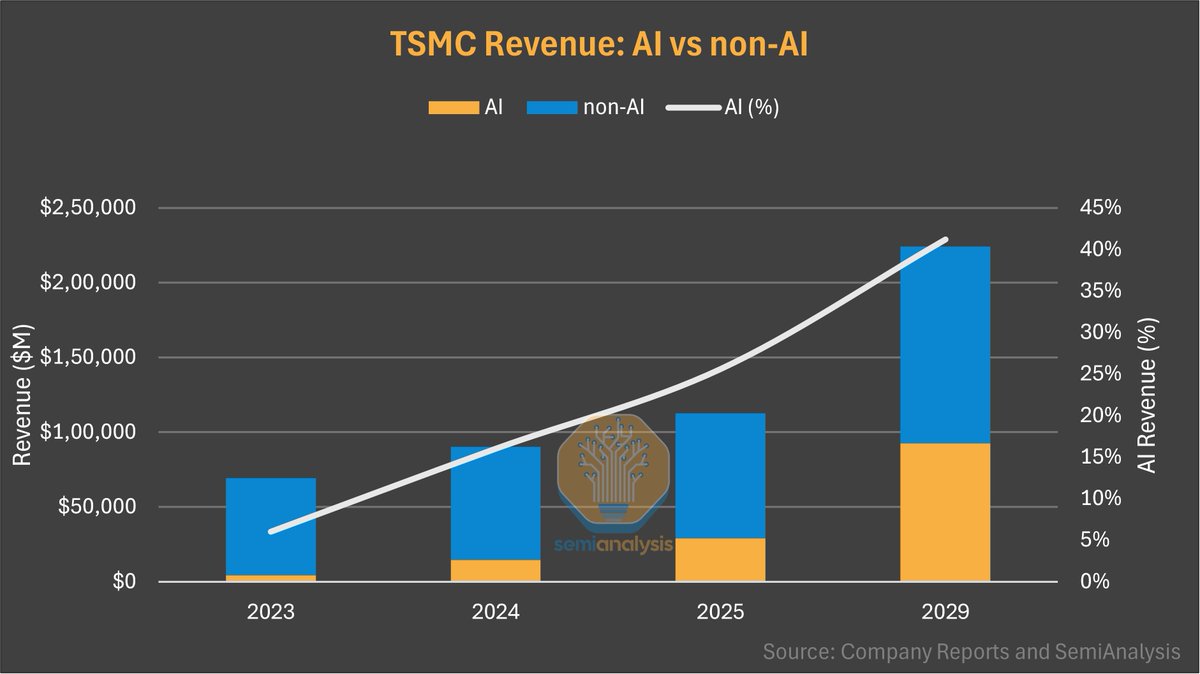
AI成為臺積電未來業務增長最快的領域
2027年很可能成為AI能力快速爬升的關鍵節點。在這個時間點前後,許多過去需要人力評估和創造的工作,將逐步被模型替代或重新定義,帶來社會形態與經濟模式的深刻變化。
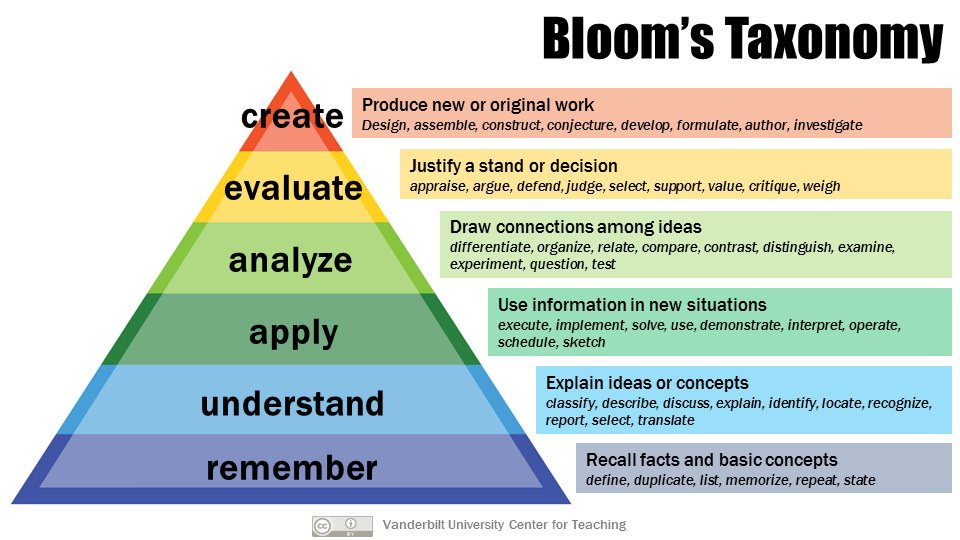
例如我很喜歡的一個由Benjamin Bloom提出並進過一系列的修訂後的布魯姆分類學(Bloom's Taxonomy),就把人類的認知領域分成六大塊,而AI的飛速發展,也許在2027年,除了評價和創造,甚至除了創造以外,大模型也許都能完成所有的事務。留給人類的時間不多了,人類要幹嘛?這值得開啟另一個話題。

銀翼殺手 (Blade Runner) (1982)
5. 為什麼AI項目應該選擇在Monad生態開發
說回正題,區塊鏈與AI的結合不少人還停留在“概念炒作”的印象裡。然而我認為,AI項目結合Monad技術特性,能提供獨特的應用價值,所以 Monad 是區塊鏈 AI 項目 Build 的不二選擇,原因如下:
-
EVM本身豐富的數據:獲得多樣化、高質量的數據,對訓練出更精準、更強大的模型至關重要。以EVM為基礎的生態早已積累了大量合約數據、交易數據以及用戶行為,這些都可為AI提供上下文訓練。 相比一些剛起步的區塊鏈環境,EVM生態早已成熟,能為AI訓練和推理提供“數據富礦”。
-
MonadDB數據庫適配實時數據:抓取實時網絡信息對AI的時效性至關重要特別在Defi領域。MonadDB的高速數據獲取能力與低Gas fee,為模型隨時調取最新的鏈上或鏈外信息提供了強大支持。

-
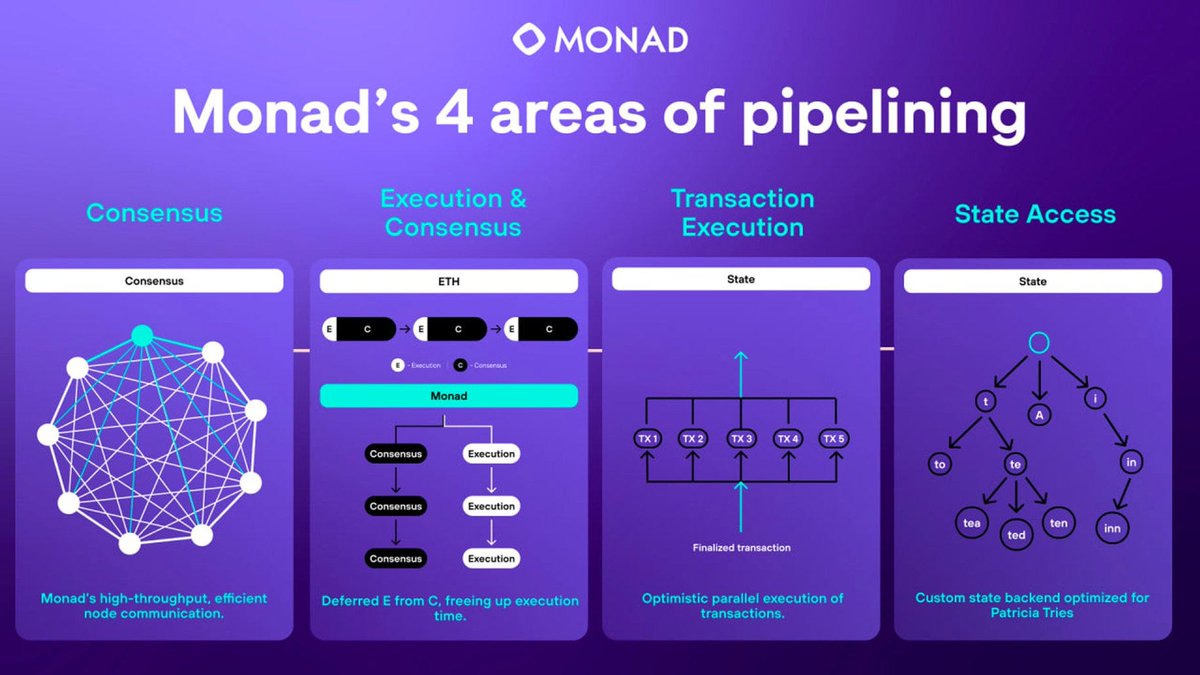
高速度與低成本的環境:Monad 實現了每秒 10,000 筆交易的吞吐量,區塊生成時間為 1 秒,提供AI Agent經濟行為落地的友好環境,通過鏈上交易、抵押、支付等操作。Monad EVM環境提供高效、低成本的落地環境,賦予AI代理“動真格”的工具。低手續費讓“高頻次、微小交易”成為可能,進一步豐富了AI代理互動的使用場景。
-
並行執行:現有研究表明,混合AI協作能提供更復雜與難度更高的任務,Monad的並行執行環境允許在鏈上可同時運行Agentic Swarms讓多個模型協作。
總的來說,目標是讓現有或未來的 AI 智能體能夠在Monad上Build從而在 EVM 環境中獲得順暢的使用體驗,並利用已有的各種 DeFi 協議和基礎設施,為打造下一代的 AI 體驗奠定基礎。
6. 面向華語AI開發者的邀請
正如我的同事Jing、Evan的X動態中多次提及的各類AI相關文章和案例等等,Monad一直以來都非常歡迎和支持AI項目在Monad生態上生根發芽,我另外想特別從華語AI開發者的視角來說明原因:
-
在中美AI競爭大背景下,華語開發者可能面臨跨國資源或合作的侷限。
-
然而,區塊鏈世界講究的是全球化與去中心化。在Monad上,您可以面向全球用戶,而不用擔心被"貼標籤",同時運用去中心化的優勢來規避地緣政治與技術壁壘。
Monad誠摯地邀請各位AI從業者與開發者加入Monad生態,一起打造屬於用戶、主權自我的創新產品。歡迎野心勃勃的創業者在Monad上開發,致力於通過多種支持幫助各位成功,這些針對開發者的支持包含目前正在進行的evm/accathon、Mach加速器、Jumpstart計劃、The Studio、The Foundry、Monad Madness等。無論您是想做區塊鏈上的AI金融交易模型,還是希望構建自適應學習的去中心化機器人,都可以在Monad找到更高速、更低成本、更具開放度的技術支持。
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News













