拆解 Uniswap V3 數據清洗流程
TechFlow Selected深潮精選
拆解 Uniswap V3 數據清洗流程
我們從用戶地址的角度計算了 Uniswap 上的用戶淨值和回報率。
撰文:Zelos
Introduction
上一期, 我們從用戶地址的角度, 統計了用戶在 uniswap 上的淨值和收益率。這次, 我們的目標依然如此。但要將這些地址所持有的現金統計進來。得到一個總的淨值和收益率。
此次的統計對象有兩個池子,包括
-
polygon 上的 usdc-weth(fee:0.05), pool address: 0x45dda9cb7c25131df268515131f647d726f50608[1], 這也是上次分析所用的池子
-
ethereum 上的 usdc-eth(fee:0.05), pool address: 0x88e6A0c2dDD26FEEb64F039a2c41296FcB3f5640[2],由於這個池包含 native token,為數據處理帶來了一些麻煩
最終得到的數據是小時級別的數據,注意: 每行的數據代表這個小時最後時刻的值。
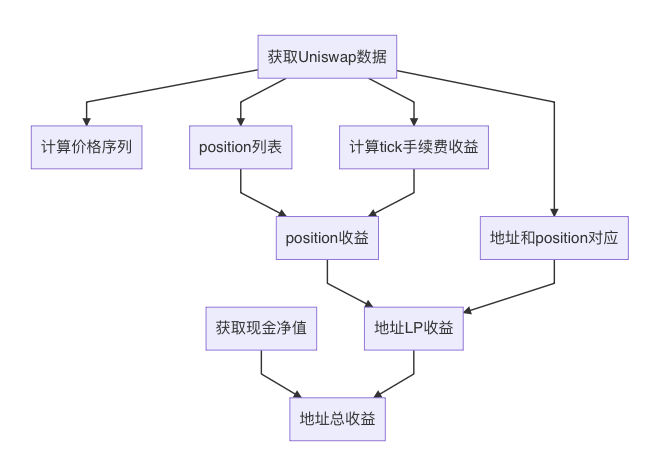
總體流程
-
獲取 uniswap 的數據
-
獲取用戶現金數據
-
計算價格序列, 也就是 eth 的價格.
-
獲取每分鐘, 每個 tick 上獲取了多少手續費
-
獲取統計週期內, 所有 position 的列表
-
獲取地址和 position 的對應關係
-
計算每個 position 的收益率
-
基於 position 和地址的對應關係, 計算每個用戶地址作為 LP 的收益率
-
將用戶的現金和 LP 合併, 並計算總體收益率
1. 獲取 Uniswap 的數據
之前為了給 demeter 提供數據源, 我們開發了 demeter-fetch 工具. 這個工具可以從不同渠道獲取 Uniswap pool 的 log, 並解析為不同格式. 支持的數據源有:
-
ethereum rpc: eth 客戶端的標準 rpc 接口. 獲取數據效率比較低. 需要多開一些線程.
-
Google BigQuery: 從 BigQuery 的數據集下載數據. 雖然每天更新一次, 但對於勝在使用方便, 價格便宜.
-
Trueblocks chifra: Chifra 服務可以 scrape 鏈上的交易, 並重新組織. 從而輕鬆的導出交易, 餘額等信息. 但這需要自己搭建節點和服務.
輸出的格式包括:
-
minute: 將 uniswap swap 的交易信息, 重採樣為每分鐘的數據. 用於回測
-
tick: 記錄 Pool 中每一筆交易. 包括 swap 和對流動性的操作
這次我們主要獲取 tick 數據, 用於統計 position 的信息, 包括資金量 / 每分鐘收益 / 生命週期 / 持有人等。
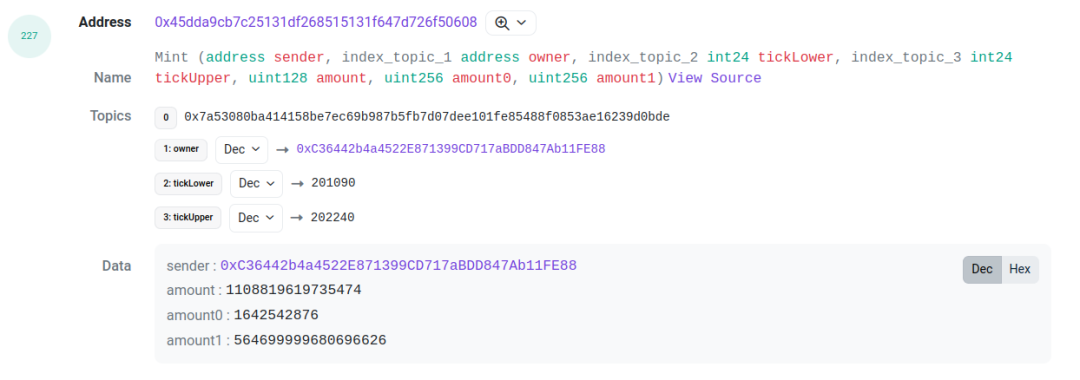
這些數據是通過 pool 的 event log 獲取的. 如 mint, burn, collect. swap. 但是 pool 的 log 並不包含 token id. 這讓我們無法定位到 pool 的操作是針對那個 position 的。
實際上, uniswap LP 的權益是通過 nft 來管理的, 而這些 nft token 的管理人是 proxy 合約, token id 只存在於 proxy 的 event log 中. 因此如果想獲取完整的 LP position 信息, 就要獲取 proxy 的 event log, 然後與 pool 的 event log 結合起來。
以這個交易[3]為例, 我們需要關注 log index 為 227 和 229 的兩個 log. 它們分別是 pool 合約拋出的 mint 和 proxy 合約拋出的 IncreaseLiquidity. 他們之間的 amount( 也就是 liquidity ), amount0 和 amount1 是一樣的. 這可以作為關聯的依據. 通過將這兩個 log 關聯起來, 我們可以得到這個 LP 行為的 tick range, liquidity, token id, 以及兩種 token 對應的金額。
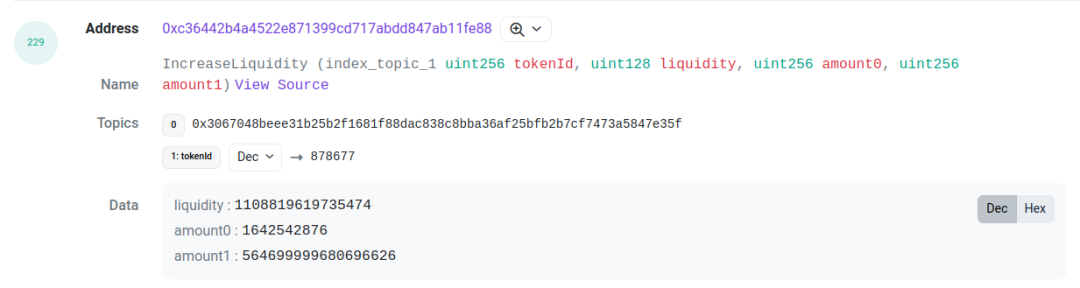
而對於高級用戶, 尤其是一些基金, 他們會選擇繞過 proxy, 直接操作 pool 合約. 這種情況下, position 不會有 token id. 這種情況下, 我們會用address-LowerTick-UpperTick的格式, 給這個 LP position 創造一個 id。
對於 burn 和 collect, 也可以用這種方式為 pool 的 event 找到對應的 position id. 但是這裡有個麻煩, 有時候兩個 event 的金額並不相同, 會有一點點偏差. 比如這個交易
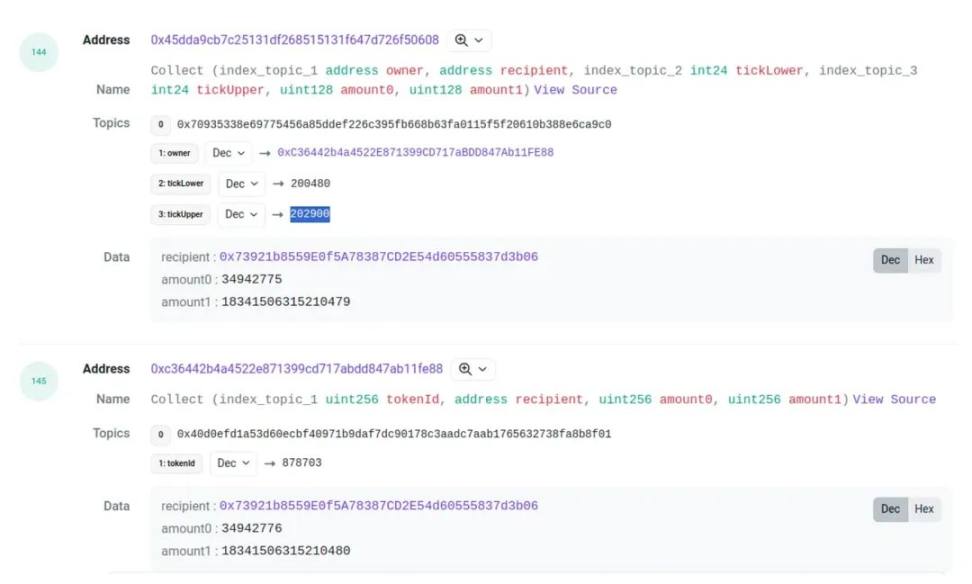
他的 amount0 和 amount1 會有一點小的差值, 這種情況雖然很少, 但也很常見. 所以我們在匹配 burn 和 collect 的時候, 給數值留了一些容錯空間.
下一個要處理的問題是, 這個交易是誰發起的. 對於撤倉來說, 我們會把 collect 事件中的 receipt 作為 position 的持有人. 而對於 mint, 只能從 pool mint event 中得到 sender( 見帶有 mint event 的圖 ).
如果用戶是操作 pool 合約, 這個 sender 就會是 LP provider, 但如果是普通用戶, 通過 proxy 操作合約, 這個 sender 會是 proxy 的地址, 這是因為資金確實是從 proxy 轉到 pool 的. 但好在 proxy 會有 nft token 的產生. 而這個 nft token, 一定會轉移給 LP provider. 因此, 檢測 proxy 合約 ( 也就是 nft token 的合約 ) 的 transfer, 就可以查找到這個 mint 所對應的 LP provider
另外如果 nft 進行了轉讓, 會讓 position 的持有人產生變化. 我們對此進行了統計, 這種情況較少. 為了簡化, 我們沒有考慮 mint 之後的 nft 轉移.
2. 獲取地址持有的現金
這個階段的目標, 是獲取一個地址在統計期間, 每個時刻所持有 token 的數量. 要實現這個目標, 需要獲取兩方面的數據,
-
地址在起始時刻的餘額
-
地址在統計期間的轉帳記錄.
使用轉帳記錄對餘額進行加減, 就可以推斷出每個時刻的餘額.
對於起始時刻的餘額, 可以通過 rpc 接口查詢. 在使用 achieve node 的情況下, 可以在查詢參數中設置高度獲取查詢任意時間的餘額. 對於 native token 和 erc20 的餘額, 都可以用這種方式獲取.
獲取 erc20 的轉帳記錄比較輕鬆, 可以通過任意渠道 (big query, rpc, chifra) 獲取.
而 eth 的轉帳記錄, 需要通過交易和 trace 獲取. 交易還好, 但是查詢和處理 trace 的運算量非常大. 幸好 chifra 提供了導出 eth 餘額的功能. 可以在餘額發生改變的時候輸出一條記錄, 雖然只能記錄數量變化, 而不能記錄轉帳對象, 但也能滿足要求. 這是合乎要求的成本最低的方法.
3. 價格的獲取
Uniswap 是一個交易所, 如果一筆 token 兌換髮生, 會產生一個 swap event, 我們可以從 sqrtPriceX96 字段獲取 token 的價格. 從 liquidity 字段獲取當時的總流動性.
由於我們的池子都有一個穩定幣, 所以獲取對 u 的價格就非常容易. 但這個價格並不是絕對準確的. 首先他受交易頻次的影響, 如果沒有 swap 交易, 這個價格就會滯後. 另外, 穩定幣脫錨的時候, 這個價格與對 u 的價格也會產生差距. 但就通常情況來說, 這個價格已經足夠準確, 對市場研究來說並沒有問題.
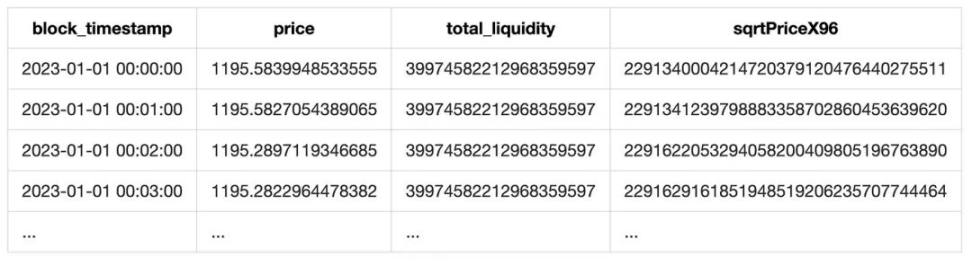
最後, 將 token 價格重採樣, 就可以得到每分鐘價格列表.
另外由於 event 的 liquidity 字段也包含了當前池子的總流動性, 我們將總流動性也順便加入進來. 最終形成一張如下的表格:
4. 手續費統計
手續費是 position 的主要收入來源. 每次有用戶在池上進行 swap 操作. 對應的 position 就能夠收到一定的手續費 ( 就是 lower 和 upper 包含當前 tick 的 position), 收益的金額與流動性的佔比, pool 的手續費費率, 以及 tick range 有關.
為了統計用戶的手續費收入, 我們可以將池子每分鐘, 在哪個 tick 上, 發生了多少金額的 swap 記錄下來. 然後計算當前分鐘在這個 tick 上的手續費收益:

最終成一張這樣的表
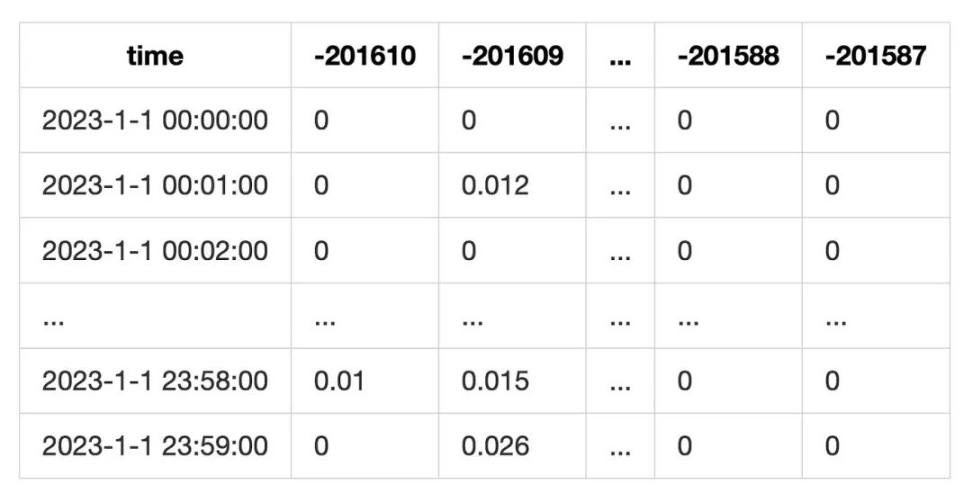
這種統計方式沒有考慮 swap 的時候, 當前 tick 流動性用盡的情況. 但由於我們統計的目標是 lp, 也就是用 tick range 來進行統計. 這個誤差可以得到一定的緩解.
5. 獲取 position 列表
獲取 position 的列表, 首先要指定 position 的標識.
-
對於通過 Proxy 投資的 LP, 每個 position 都會擁有一個 nft, 也就是擁有一個 token id, 這可以作為 position 的 id.
-
而對於直接操作 pool 投資的 LP, 我們會為他編造一個 id, 格式為
address_LowerTick_UpperTick. 這樣, 所有的 position 都有了自己的標識.
通過這個標識, 我們可以將 LP 的所有操作整合起來. 形成一個描述 position 全生命週期的列表. 如

但是需要注意的是, 這次統計的對象, 是 2023 年間, 而不是從池子創立開始, 不可避免的, 對於某些 position, 我們無法獲取他們在 2023 年 1 月 1 日之前的操作. 這就需要我們推測在統計開始時, 這個 position 有多少 liquidity. 我們採取了一種經濟的方式來推測:
-
將 mint 和 burn 的 liquidity 相加, 得到一個數字 L
-
如果 L>0, 也就是 mint>burn, 認為在統計開始之前, 就有了一些流動性, 此時會在統計開始的時刻 (2023.1.1 0:0:0) 補償一個 mint 操作.
-
如果 L<0, 認為在統計結束的時候, 仍然持有 liquidity.
這種方式能夠避免下載 2023 年之前的數據, 從而節約成本. 但是會面臨沉沒流動性的問題, 也就是:如果 LP 在這一年沒有做任何操作, 是無法找到這個 LP 的, 但是這個問題並不嚴重.由於統計週期是一年, 我們假定用戶一般會在這期間調整 LP. 因為在一年的時間跨度, eth 的價格會發生很大的變化, 而且用戶有非常多的理由調整他們的 LP. 如價格超出了 tick range, 把資金投入到其它 DEFI 等. 因此作為一個活躍用戶, 一定會根據價格調整自己的 LP. 而對於那些將資金沉澱在 pool 中, 從來不調整的, 我們認為這個用戶是不活躍的, 不在統計範圍內.
而另一種更麻煩的情況是, position 在 2023 年之前 mint 了一些 liquidity, 然後在週期內又進行了一些 mint/burn 的操作, 到統計結束, 也沒有 burn 掉所有的流動性. 因此我們只能統計到一部分的流動性. 這種情況下, 沉沒流動性會對 position 的手續費估算造成影響, 造成收益率異常. 具體原因後面再討論.
在最終的統計中, polygon 一共有 73278 個 position, 而 ethereum 有 21210 個 position, 每個鏈收益率異常的不超過 10 個, 證明這個假定是可信的.
6. 獲取地址和 position 的對應關係
由於我們統計的最終目標是地址的收益, 因此還要獲取地址和 position 的對應關係. 通過這個關聯, 就可以得到用戶具體的投資行為.
在步驟 1 中, 我們做了一些工作找到資金操作 (mint/collect) 的關聯用戶. 因此, 只要找到 mint 的 sender 和 collect 的 receipt, 就可以找到 position 和地址的對應關係
7. 計算 position 的淨值和收益率
在這個步驟中, 我們要計算每一個 position 的淨值, 再根據淨值求出收益率
淨值
Position 的淨值包含兩部分, 一個是 LP 的 liquidity, 這部分相當於做市的本金. 用戶將資金投入 Position 後, liquidity 的數量不會變化, 但是淨值會隨著價格變化而產生波動. 另一部分手續費收益, 這部分獨立於 liquidity, 單獨存放在 fee0 和 fee1 兩個字段中. 手續費淨值隨著時間增長而增多.
因此在任意分鐘, liquidity 與這分鐘的價格結合, 就可以得到本金部分的淨值. 而手續費的計算, 需要用到第四步所計算的手續費表.
首先用這個 position 的 liquidity, 除以當前池子的總 liquidity, 作為分成比例. 然後將這個 position 的 tick range 中包含的所有 tick 的手續費相加, 就可以得到這一分鐘的手續費收益.
用公式表示為:

最後將 fee0 和 fee1 的手續費相加, 就得到了手續費淨值. 再與流動性的淨值相加, 就得到了總淨值.
在計算淨值時, 我們根據 mint/burn/collect 的交易分割 position 的生命週期.
-
當 mint 交易發生, 讓流動性增加
-
當 burn 交易發生, 讓流動性減少. 並將流動性的價值折算到手續費字段 (pool 合約的代碼也是這樣操作的 )
-
當 collect 交易發生. 會觸發計算, 計算範圍是從上次 collect 到當前時間, 我們會計算每分鐘的淨值和手續費收入, 得到一個列表.
最後, 將每次 collect 得到的淨值列表彙總起來. 再進行 resample 和其它的統計. 得到最終的結果.
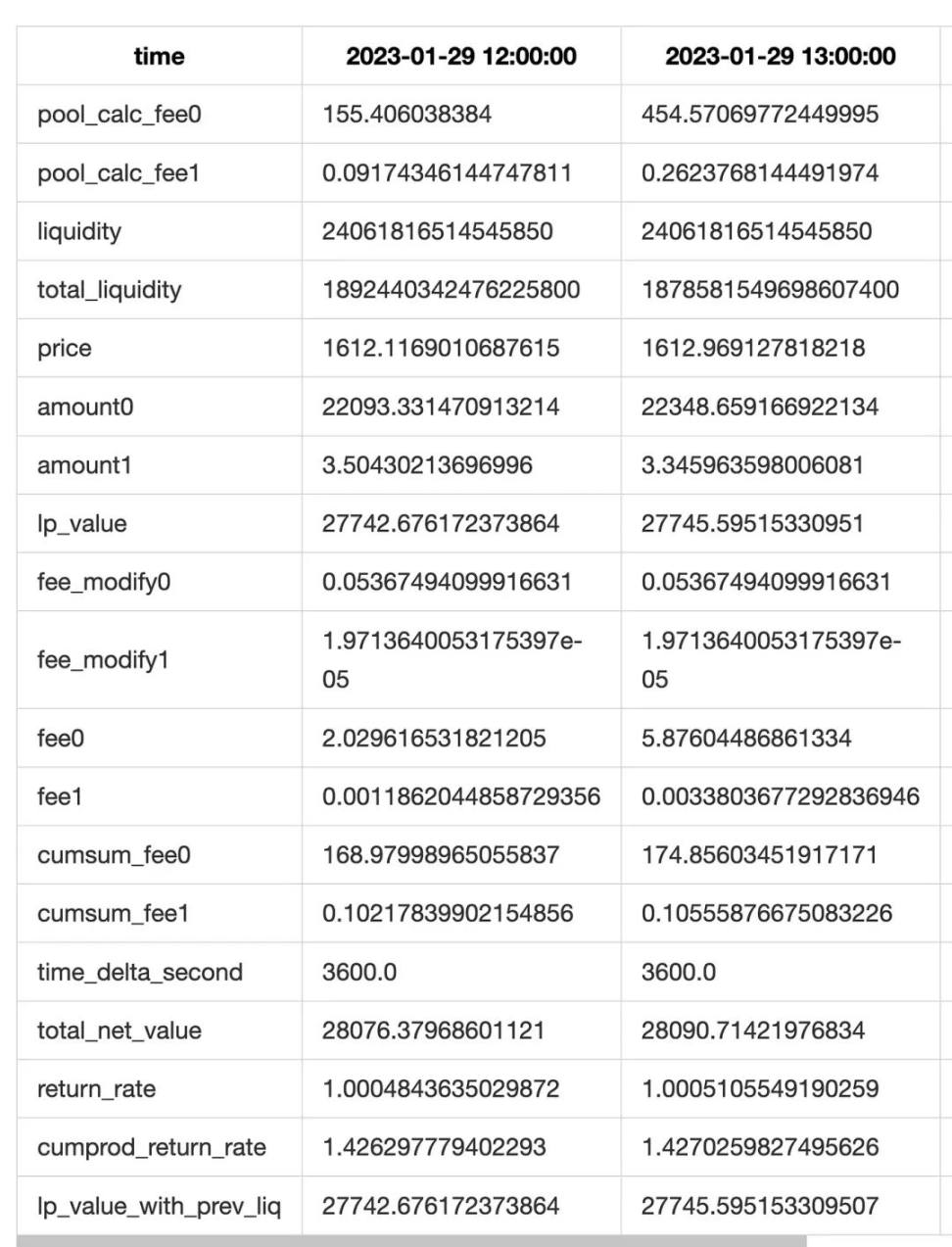
另外為了提高精度, 我們做了兩方面的優化.
首先, 對於有交易發生 (mint/burn/collect) 的那個小時, 我們進行分鐘級的統計, 而對於沒有交易發生的小時, 進行小時級的統計. 最後, 將結果 resample 成小時級.
其次, 在 collect event 中, 我們可以得到流動性 + 手續費的總和. 因此我們可以將實際 collect 的值, 與我們理論計算值對比, 得到理論手續費和實際手續費的差值 ( 實際上這個差值還包含 lp 本金的差值, 但是 lp 本金的差值誤差特別小, 基本可以認為是 0). 我們會將手續費差值補償到每行上. 以提高手續費估算的精度 ( 也就是上面的表中 fee_modify0 和 fee_modify1 字段 ).
注意:
-
回填的時候還要根據當前小時的流動性, 對手續費的分配進行加權, 否則會出現這個小時手續費偏高的情況.
-
由於統計的數據是 2023 年全年, 而不是完整數據, 因此存在第五節中提到的沉沒流動性的現象. 這會讓實際手續費比理論手續費多很多. 使得收益率變得異常高.
由於每一行是這個小時最後時刻的數據, 對於已經完全 close 的 position, 淨值會是 0. 這種情況下, 這個 position close 時刻的淨值就會丟失. 為了保留這個淨值, 在文件末尾, 創建了一行時間為 2038-1-1 00:00:00 的數據, 存放 position close 時刻的淨值等數據. 以備其他項目的統計需求.
收益率
通常, 計算收益率是用開始的淨值, 除以結束的淨值. 但是在這裡並不適用. 原因如下:
-
這裡的收益率需要細化到每一分鐘,
-
由於 position 會在中途有資金的轉入和轉出. 單純開始和結束的淨值相除並不能體現收益情況.
對於問題 1, 我們可以用每一分鐘的淨值相除, 來得到每分鐘的收益率, 然後將每分鐘的收益率累乘, 就得到了總收益率.
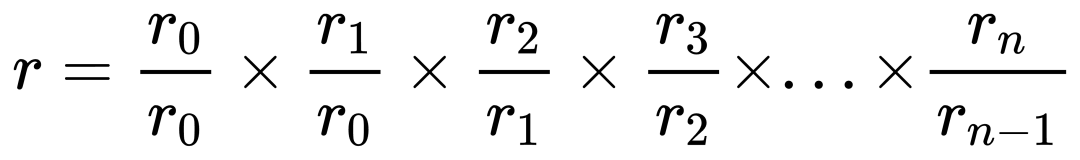
但這個算法有一個嚴重的問題. 如果每分鐘收益率中, 有一個數據計算錯誤, 就會導致總收益率出現很大的偏差. 這樣統計過程變成了走鋼絲, 不能出現一點差錯. 但好的方面是, 這讓任何統計錯誤都無所遁形.
對於問題 2, 如果這分鐘有資金的轉入轉出, 用收益率直接相除, 還是會得到很離譜的收益率.因此有必要細化一下每分鐘的收益率算法.
我們採取的第一個嘗試, 是將淨值的變化進行詳細的拆分, 然後將資金的變化剔除. 我們把淨值的變化拆分為幾個部分. 1 是價格帶來的本金變化. 2 是這分鐘的手續費累計. 3 是資金的流入流出. 顯然 3 是要從統計中排除的. 對此我們制定瞭如下的計算方法:
-
指定當前分鐘是 n, 前一分鐘是 n-1
-
假定當前分鐘的所有轉帳操作, 都發生在第 n:0.000 秒. 那麼在餘下的時間, LP 的淨值是不變的, 也就是說第 n:0.001 秒的淨值等於 n:59.999 秒的淨值.
-
手續費的累加發生在這一分鐘的末尾.也就是第 n:59.999 秒.
-
上一分鐘末尾 (n-1:59.999) 的價格和手續費, 就是這一分鐘 (n:0.000) 開始的價格和手續費
基於以上假設, 每分鐘的收益率就是用末尾的流動性 / 價格 / 手續費, 除以末尾的流動性 / 開始的價格 / 開始的手續費, 用公式表示如下, 其中 f 是指將 liquidity 折算為淨值的算法.
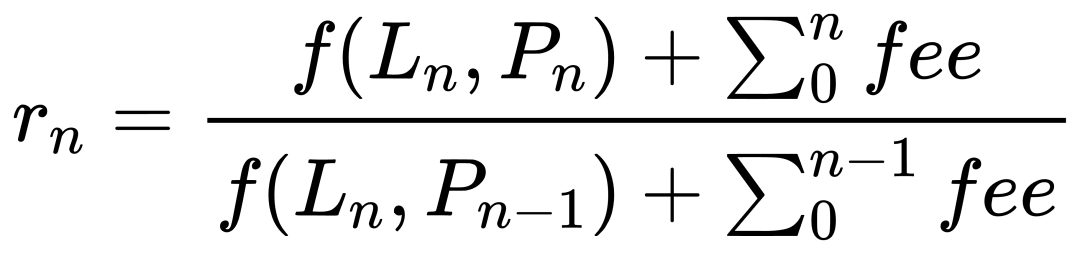
這種方式看起來很不錯. 它完美的規避了流動性的變化. 並體現了價格和手續費對淨值的影響. 這正是我們所期待的. 但是, 在實際當中, 會在某些行產生很大的收益率. 經過調查我們發現. 問題出現在撤出流動性的時候.回憶一下我們的規則: 每行所代表的時間是這一分鐘 / 小時的末尾. 這為數據的統計提供了統一的尺度, 但需要注意的是, 而每一列的含義是不一樣的:
-
對於淨值列來說是瞬時值, 也就是當前分鐘 / 小時最後的值.
-
而手續費列是累加值. 也就是當前分鐘 / 小時期間所累計的手續費
因此對於 burn 流動性的那個小時
-
當 LP 被 burn 掉, 然後 token 轉移走的情況下, 在這個小時末尾淨值會是 0
-
而對於手續費來說, 由於他是累加的, 在這個小時的末尾, 手續費會大於 0.
這就使得上面的公式退化為:
這種情況不僅僅會出現在 position 生命週期的末尾, 在 burn 一部分流動性的時候, 也會為讓手續費的增加與 LP 的淨值比例產生變化.
為了簡化起見. 當發生 LP 的淨值變化的時候, 我們設定收益率為 1. 這會為收益率的計算結果帶來誤差. 但是對於一個正常持續投資的 position 來說, 產生交易的小時相對於整個生命週期還是很少的. 因此影響並不大.
8. 計算地址的 LP 總收益
有了每個 position 的收益率, 再加上 position 和地址的對應關係, 就可以得到用戶地址在每個 position 的收益率了.
這裡的算法比較簡單, 將這個地址在不同時期的 position 串聯起來, 中間沒有投資時期, 淨值設置為 0, 收益率設置為 1( 因為前後淨值都是 0, 沒有變化, 所以收益率是 1.)
如果同一個時期有多個 position. 則在重疊的部分, 將淨值相加. 就可以得到總淨值.而合併收益率的時候, 我們會根據每個 position 的淨值加權合併.
9. 合併現金和 LP 的總收益
最後, 只要將用戶地址持有的現金和 LP 投資這兩部分的綜合起來, 就能得到最終結果了.
淨值的合併相比於上個步驟 ( 合併 position ) 更加簡單. 只要在 LP 淨值這邊查到時間範圍, 然後查找對應時間範圍所持有的現金, 再查出 eth 的價格, 就可以得到總淨值.
對於收益率, 我們同樣採用求每分鐘收益率, 然後累乘的算法. 一開始, 我們使用了第七節提到的錯誤收益率算法. 這要求將這一分鐘的固定部分 ( 包括現金中的 cash 數量, LP 中的流動性 ) 和可變部分 ( 價格變動, 手續費累計, 資金轉入轉出 ) 分開. 相對與 position 的統計, 它的複雜度高出很多, 因為對於 uniswap 的資金流入流出, 只要關注 mint 和 collect 事件即可. 而對現金的追溯就非常麻煩, 我們要區分資金是轉給 LP 還是轉到外部. 如果是轉給 LP, 本金部分可以不變, 如果是轉到外部, 要修正本金的數量. 這就需要追蹤 erc20 和 eth 的轉帳目標地址. 這個工作非常麻煩. 首先在 mint/collect 時, 轉帳地址可能是 pool, 也可能是 proxy. 而更復雜的是 eth 的轉帳, 由於 eth 是 native token, 一些轉帳記錄只能通過 trace 記錄查到. 但是 trace 的數據量太大, 超出了我們的處理能力.
最後壓胯駱駝的最後一根稻草, 是我們發現每行的淨值是這個小時的瞬時值, 手續費是這個小時的累計值, 從物理意義上不能直接相加. 這個問題確實很晚才發現.
因此我們放棄了這個算法. 轉而採用後一分鐘的淨值, 除以前一分鐘淨值的方式. 這種方式簡單很多. 但這種方式也存在一個問題. 那就是當有資金轉入轉出的時候, 收益率依然會出現不合理的情況. 通過上面的討論, 我們得知拆分出資金的流向非常困難. 因此在這裡我們犧牲一些精度, 將有資金轉移時的收益率設置為 1.
剩下的問題就是, 如何識別出當前小時有資金的流入流出? 一開始想的算法很簡單, 用上一個小時的 token 餘額, 以及當前的價格, 推算出如果持有這些 token, 那麼這個小時淨值會是多少. 然後將推算值, 與實際值相減就可以了. 當差值不等於的時候, 就是有資金轉入轉出. 用公式表示為:

但是這個算法忽視了 uniswap LP 的複雜性. LP 中, token 的數量會隨著價格的變動而變化,同時淨值也會隨之變化. 且這個方式沒有考慮手續費的變化. 最終造成推測值與實際值有 0.1% 左右的誤差.
為了提高準確性, 將資金的構成細化一下, 把 lp 的價值變動單獨計算, 同時把手續費也考慮進來.
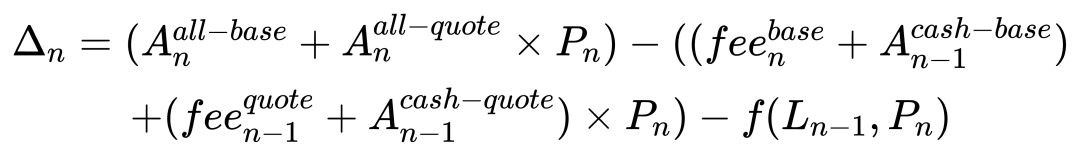
通過這種方式, 推測值的誤差可以控制在 0.001% 以內.
另外我們限制了數據的 decimal. 避免出現過小的數字 ( 通常在 10^-10 以下 ) 相除的情況. 這些小的數字, 是各種計算以及 resample 所累計出來的誤差. 如果不處理直接相除, 會導致誤差被放大. 使收益率嚴重失真.
其他的問題
native token
在本次統計加入了 ethereum 上的 usdc-eth 池, 其中 eth 是 native token , 需要進行一些特殊的處理.
eth 無法使用在 defi 中, 必須被轉換為 weth. 因此這個 pool 實際上是 usdc-weth 的池子. 對於直接操作 pool 的用戶來說, 在這個池轉入轉出 weth 即可. 這和普通的池子是一樣的.
而對於通過 proxy 添加 LP 的用戶來說, 需要將 eth 帶在交易的 value 中, 轉給 proxy 合約. 合約再將這些 eth 兌換成 weth, 然後再投入 pool 中.而在 collect 的時候, usdc 可以直接轉給用戶, 而 eth 不能直接轉給用戶, 需要先從 pool 轉出到 proxy, 再由 proxy 合約兌換成 eth, 最後通過內部轉帳發送給用戶.例子見這個交易[4].
因此 usdc-eth pool 與普通 pool 只在資金的轉入和轉出有區別. 這隻對匹配 position 和地址有影響. 為了解決這個問題, 我們拉取了池子從創立開始的所有 nft 轉帳數據, 然後通過 token id 找到對應 position 的持有人.
missing position
在統計中, 有些 position 並沒有進入到最後的列表. 這些 position 都有一定的特殊之處.
其中很大一部分是 mev 交易, mev 是純套利的交易, 並不是正常的投資者, 因此不在我們的統計範圍之列. 另外在實際統計中也很難對其進行統計, 這需要用到 trace 級別的數據. 在這裡我們使用了一個簡單的策略來過濾 mev 交易, 就是從開始到結束的時間不足一分鐘, 事實上, 由於我們數據的最高精度是 1 分鐘. 如果一個 position 的存在時間少於一分鐘, 就無法被統計到.
另一種可能性是, 這個 position 沒有 collect 交易. 從 step 7 可以看出, 我們對收益的計算, 是通過 collect 觸發的. 沒有 collect 操作, 就不會計算之前的淨值和收益率. 在正常情況下, 用戶都會選擇及時收穫 LP 的收益或者本金. 但也不排除一部分特殊用戶, 就是要把資產存在 uniswap pool 的 fee0 和 fee1. 對於這種用戶, 我們也認為是特殊用戶, 不在統計範圍內.
歡迎加入深潮 TechFlow 官方社群
Telegram 訂閱群:https://t.me/TechFlowDaily
Twitter 官方帳號:https://x.com/TechFlowPost
Twitter 英文帳號:https://x.com/BlockFlow_News