

Phân tích sâu nguyên nhân đằng sau làn sóng đình chỉ tài khoản của Anthropic: Tôn giáo an ninh, nội chiến AI và bế tắc của Claude trong bối cảnh Trung – Mỹ cắt đứt quan hệ
Tuyển chọn TechFlowTuyển chọn TechFlow
Phân tích sâu nguyên nhân đằng sau làn sóng đình chỉ tài khoản của Anthropic: Tôn giáo an ninh, nội chiến AI và bế tắc của Claude trong bối cảnh Trung – Mỹ cắt đứt quan hệ
Phân tích logic cốt lõi đằng sau việc Anthropic trở thành “kẻ điên cuồng khóa tài khoản”: Đây không chỉ là nỗi ám ảnh an toàn của các nhà sáng lập, mà còn là một cuộc đấu tranh quyền lực khốc liệt trong thung lũng Silicon và một tình thế sinh tồn bấp bênh của Claude giữa bối cảnh cắt đứt địa chính trị Mỹ – Trung.
Vào tháng 4 năm 2026, tại một công ty công nghệ nông nghiệp có tên Agricultural Technology Company ở Hoa Kỳ, các nhân viên như thường lệ mở máy tính để sử dụng Claude Code viết mã, phân tích dữ liệu và chuỗi cung ứng, thì đột nhiên phát hiện toàn bộ 110 tài khoản nhân viên bị khóa mà không có bất kỳ dấu hiệu cảnh báo nào. Quản trị viên mạng của công ty nhận được email từ Anthropic: “Phát hiện hoạt động vi phạm Chính sách Sử dụng; tài khoản của bạn đã bị tạm dừng.”
Mặc dù toàn bộ tài khoản bị khóa đồng loạt, nhưng API nền tảng vẫn hoạt động bình thường và tiếp tục bị tính phí—thậm chí quản trị viên mạng còn nhận được tin nhắn nhắc thanh toán. Sau đó, ban lãnh đạo công ty gửi thư khiếu nại và liên hệ trực tiếp với Anthropic, song mọi nỗ lực đều không mang lại tiến triển nào. Cuộc “đình công” của Claude Code khiến toàn bộ đội ngũ rơi vào tình trạng ngừng hoạt động hoàn toàn.
Cùng thời điểm đó, trên các diễn đàn tiếng Trung như V2EX, Zhihu và Juejin, gần như toàn bộ người dùng Claude đều đang phàn nàn: Có người vừa nạp tiền thành công cho gói đăng ký Max nhưng chưa kịp sử dụng thì tài khoản đã bị khóa ngay lập tức; có người dùng thẻ ảo để liên kết thanh toán, vừa xác nhận giao dịch xong hệ thống đã thông báo “vi phạm chính sách” và khóa tài khoản; có người đăng nhập qua công cụ bên thứ ba, bị hệ thống chặn vĩnh viễn ngay lập tức—trong vòng ba tháng, bốn tài khoản lần lượt bị khóa và tất cả các lần khiếu nại đều thất bại.
Thực tế, kể từ khi Anthropic tung ra sản phẩm chủ lực Claude Code và nhanh chóng vươn lên vị trí đầu bảng thị trường, công ty này đã trở thành “kẻ điên cuồng khóa tài khoản” nổi tiếng trong giới.
Theo dữ liệu kiểm soát rủi ro do Trung tâm Minh bạch (Transparency Hub) của Anthropic công bố vào tháng 1 năm 2026, trong nửa cuối năm 2025, toàn nền tảng đã khóa tổng cộng 1,45 triệu tài khoản, trong đó số lần khiếu nại là 52.000 lần, nhưng chỉ có 1.700 lần thành công. Điều này đồng nghĩa với tỷ lệ thành công khiếu nại chỉ đạt 3,3%.
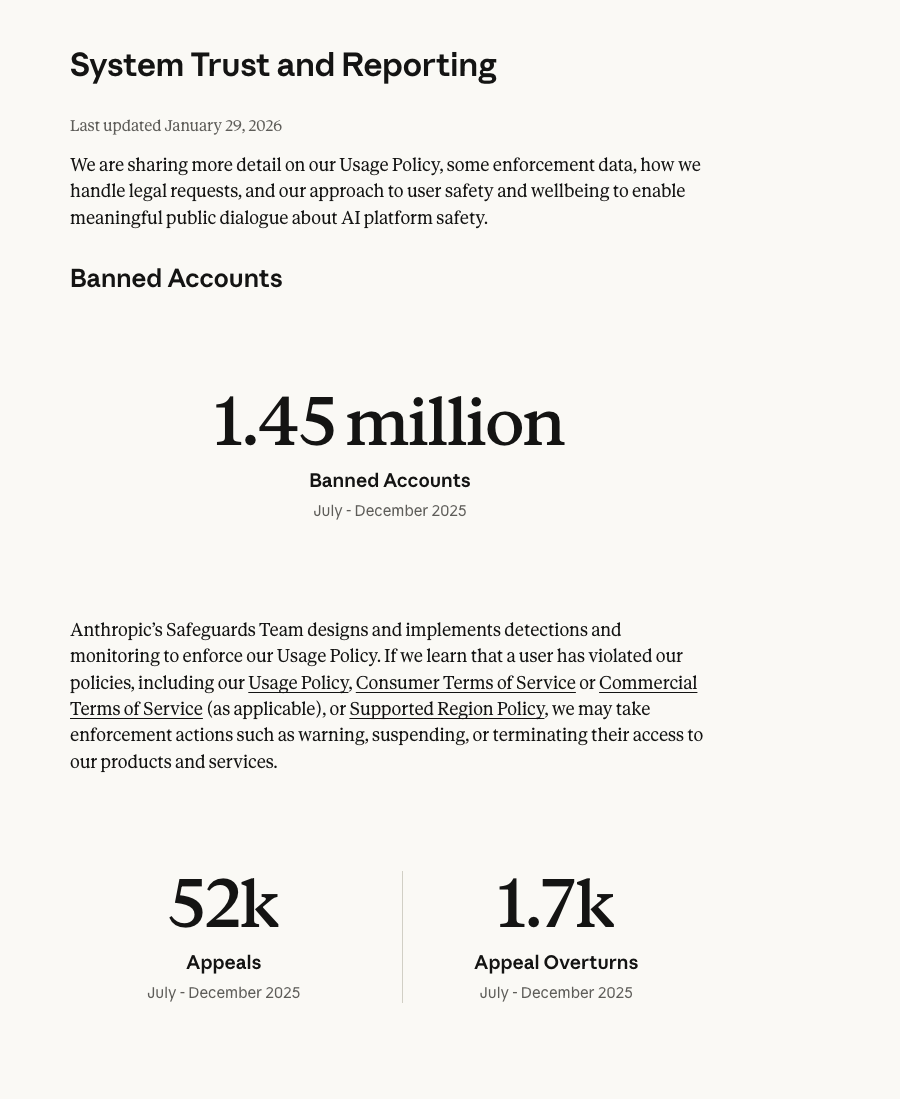
Nguồn ảnh:Anthropic
Nói cách khác, trong số 100 người dùng cảm thấy oan uổng nhất khi bị khóa tài khoản, chỉ khoảng 3 người có thể lấy lại được tài khoản, còn lại 97 người đành phải tự nhận vận đen.
Điều này cho thấy rõ ràng Anthropic vốn dĩ không tuân theo nguyên tắc “xác minh sự thật trước, xử phạt theo quy định sau” mà chúng ta thường hiểu. Thay vào đó, công ty áp dụng mô hình “thực thi phòng ngừa”: Mục tiêu cốt lõi là ngăn chặn rủi ro ngay từ giai đoạn manh nha bằng cách thiết lập hàng rào kiểm soát rộng khắp—“thà giết nhầm một ngàn, chứ không để sót một”.
So sánh với các đối thủ cạnh tranh gần kề như ChatGPT và Google Gemini, cách tiếp cận của Anthropic tương đối cứng rắn hơn.
ChatGPT dung thứ hơn với các công cụ bên thứ ba và các kỹ thuật gợi ý (prompt) biên giới; việc khóa tài khoản cũng ít nghiêm khắc hơn;
Gemini dù thỉnh thoảng siết chặt kiểm soát rủi ro, nhưng hiếm khi thực hiện các biện pháp khóa đồng loạt, không cảnh báo trước hoặc trừng phạt liên đới.
Duy chỉ Anthropic coi “khóa tài khoản” như cơm bữa—đặc biệt là Claude Code, nơi tập trung đông đảo nhất các vụ khóa tài khoản.
Vậy vì sao chính sách người dùng của Anthropic lại khắt khe đến vậy? Theo tôi, nguyên nhân đằng sau khá phức tạp.
Đây vừa là biểu hiện của niềm ám ảnh cá nhân của nhà sáng lập Dario Amodei, vừa là hệ quả của cuộc chia rẽ phe phái tại OpenAI, cuộc đấu tranh quyền lực giữa các nhà đầu tư Thung lũng Silicon, và nội chiến sâu sắc giữa hai phe “An toàn” và “Tăng tốc” trong ngành AI Hoa Kỳ. Đồng thời, nó cũng gắn liền với cục diện địa chính trị “ly khai AI Trung-Mỹ”—một trận chiến lớn ẩn giấu đằng sau dòng mã nguồn, quyết định quyền kiểm soát tương lai của trí tuệ nhân tạo và các rào cản công nghệ toàn cầu.
Bài viết này sẽ cùng bạn từng lớp phân tích vấn đề này.
01 Niềm ám ảnh của Dario Amodei
Gốc rễ của chính sách kiểm soát rủi ro khắt khe tại Anthropic nằm sâu trong hành trình cuộc đời của nhà sáng lập Dario Amodei. Mỗi bước đi, mỗi niềm ám ảnh của ông cuối cùng đều hóa thân thành “luật sắt không khoan nhượng” của Anthropic—và cũng đồng thời biến thành những email khóa tài khoản gửi tới vô số người dùng.

Chân dung chính thức gần đây của Dario Amodei. Nguồn ảnh:Fortune
Năm 1983, Dario Amodei sinh ra tại một gia đình di dân bình thường ở San Francisco. Cha ông là một thợ thuộc da gốc Ý, sống cả đời bằng nghề thủ công, tính cách cứng cỏi, luôn đề cao sự phân minh đúng sai.
Mẹ ông là người Do Thái, phụ trách dự án cải tạo thư viện; bà làm việc rất tỉ mỉ và từ nhỏ đã truyền đạt cho Dario quan niệm “trách nhiệm vượt lên trên tất cả”.
Trong môi trường gia đình như vậy, Dario từ nhỏ đã hình thành tính cách bảo thủ, kiên định giữ nguyên tắc—không chịu chút mơ hồ hay thỏa hiệp nào.
Lúc nhỏ, Dario đã bộc lộ tố chất thiên tài khoa học: không thích ồn ào, kém năng lực xã giao, toàn bộ tâm trí đều dành cho toán học và vật lý. Kiến thức trong sách giáo khoa không đủ thỏa mãn ông, nên cậu bé thường xuyên lặn lội thư viện để “nhai” các tác phẩm lý thuyết chuyên sâu. Khi ấy, giấc mơ lớn nhất của cậu là trở thành một nhà vật lý lý thuyết, khám phá bí ẩn tối thượng của vũ trụ.
Năm 2006, cha Dario mắc một căn bệnh hiếm gặp và nan y, tìm khắp danh y cũng không thể chữa khỏi, cuối cùng qua đời. Cái chết của cha đã giáng một đòn chí mạng vào Dario lúc mới 20 tuổi, hoàn toàn lật đổ thế giới quan của anh.
Anh chứng kiến cha mình chịu đựng đau đớn, chứng kiến nghịch cảnh y học bất lực—đột nhiên nhận ra rằng: Vật lý lý thuyết trừu tượng không thể cứu người thân trước mắt, cũng không thể cứu những người bình thường đang vật lộn với bệnh tật.
Vì vậy, anh dứt khoát từ bỏ lĩnh vực vật lý lý thuyết đã dày công nghiên cứu nhiều năm, chuyển sang theo đuổi vật lý sinh học với quyết tâm “dùng khoa học chữa lành bệnh tật con người”, đồng thời khắc sâu vào xương tủy tư tưởng “kiểm soát rủi ro ngoài tầm kiểm soát”.
Niềm ám ảnh này xuyên suốt toàn bộ sự nghiệp của ông:
Ông theo học cử nhân tại Viện Công nghệ California (Caltech), sau đó chuyển sang Đại học Stanford để hoàn thành bằng cử nhân vật lý. Tiếp đó, ông thi đỗ vào Đại học Princeton, theo học tiến sĩ vật lý sinh học, trở thành người nhận Học bổng Hertz, chuyên nghiên cứu mối liên hệ giữa cấu trúc phân tử sinh học và bệnh tật. Sau khi tốt nghiệp tiến sĩ, ông làm nghiên cứu sau tiến sĩ tại Trường Y khoa Stanford, tiếp tục đào sâu vào lĩnh vực y sinh nhằm tìm ra phương pháp chống lại các bệnh hiếm.
Cho đến năm 2014, Andrew Ng (Ngô Ân Đạt) mời ông gia nhập Phòng thí nghiệm Trí tuệ nhân tạo của Baidu tại Hoa Kỳ—đây là lần đầu tiên Dario tiếp xúc với trí tuệ nhân tạo.
Lúc bấy giờ, AI mới ở giai đoạn sơ khai, chủ yếu phục vụ nhận dạng hình ảnh và tổng hợp giọng nói. Nhưng Dario đã sớm nhận ra tiềm năng to lớn của AI: Không chỉ thay đổi đời sống, mà còn có thể trở thành “công cụ siêu việt” chống lại rủi ro và cứu giúp nhân loại. Tuy nhiên, điều kiện tiên quyết là AI phải được kiểm soát chặt chẽ—không được mất kiểm soát.
Sau khi rời Baidu, ông gia nhập Google Brain với vai trò Nhà khoa học nghiên cứu cấp cao, chuyên sâu vào lĩnh vực học sâu, đặc biệt là an toàn AI—tức là làm sao để AI “nghe lời”, không gây hại cho con người.
Chính trong giai đoạn này, ông bắt đầu suy ngẫm về cách thức “nhúng” giá trị con người thực sự vào tầng nền tảng của AI, chứ không chỉ đơn thuần áp dụng bộ lọc hậu kỳ.
Năm 2016, OpenAI vừa mới thành lập, với khẩu hiệu “mở nguồn, phi lợi nhuận, thúc đẩy AI phục vụ nhân loại”, thu hút nhân tài AI hàng đầu toàn cầu. Dario bị thuyết phục bởi triết lý của OpenAI và gia nhập công ty. Với trình độ kỹ thuật xuất chúng, ông lần lượt đảm nhiệm các vị trí Trưởng nhóm An toàn AI, Giám đốc Nghiên cứu, rồi Phó Giám đốc Nghiên cứu, đồng thời tham gia toàn bộ quá trình phát triển GPT-2 và GPT-3.

Ảnh thời kỳ đầu sự nghiệp của Dario Amodei (giai đoạn OpenAI/Google Brain, khoảng 2018–2021). Nguồn ảnh: bigtechnology
Tại đây, ông cũng là đồng sáng chế RLHF (Học tăng cường dựa trên phản hồi con người). Về bản chất, kỹ thuật này sử dụng phản hồi từ con người để điều chỉnh đầu ra của AI, giúp AI phù hợp hơn với giá trị nhân văn—sau này trở thành “miếng vá an toàn” phổ biến trong toàn ngành AI. Lúc ấy, Dario chỉ tập trung vào mục tiêu làm sao để AI được triển khai và vận hành một cách an toàn. Nhưng ông không ngờ rằng, lý tưởng của mình sẽ nhanh chóng bị thực tế nghiền nát.
Nội chiến OpenAI: Sự chia rẽ giữa phe An toàn và phe Tăng tốc
Nhiều người chỉ biết Dario Amodei rời OpenAI cùng đội ngũ vào năm 2021 để thành lập Anthropic, nhưng ít ai biết rằng đằng sau cuộc “phản bội” này là một cuộc tranh luận kéo dài nhiều năm về quan điểm, quyền lực—và còn là một lần “phản bội” khiến Dario nhớ mãi không quên.
Trong giai đoạn đầu thành lập, OpenAI thực sự kiên định theo đuổi triết lý “phi lợi nhuận, ưu tiên an toàn”, với Elon Musk là nhà đầu tư ban đầu và luôn nhấn mạnh an toàn AI là yếu tố then chốt. Tuy nhiên, theo thời gian—đặc biệt là sau khi Sam Altman đảm nhiệm chức CEO OpenAI—hướng phát triển của công ty bắt đầu thay đổi mạnh mẽ.
Sam Altman là điển hình của “phe tăng tốc”: Ông cho rằng tốc độ phát triển AI phải bắt kịp nhịp độ thời đại—trước hết cần xây dựng mô hình lớn, mạnh để chiếm ưu thế thị trường, thương mại hóa nhanh chóng, rồi mới giải quyết vấn đề an toàn.

Hình ảnh biểu tượng cho sự chia rẽ phe phái giữa OpenAI và Anthropic (Sam Altman vs Dario – ghép ảnh). Nguồn ảnh: wsj.com
Dưới sự dẫn dắt của ông, OpenAI bắt đầu làm mờ tính chất “phi lợi nhuận”, tích cực tìm kiếm hợp tác thương mại, thậm chí chủ động tiến gần Microsoft để giành thêm nguồn vốn và năng lực tính toán—chỉ để mô hình GPT nhanh chóng cập nhật và chiếm lĩnh tiếng nói trên thị trường AI.
Nhưng tất cả những điều này khiến Dario Amodei hoàn toàn không thể chấp nhận.
Trong mắt ông, AI không phải công cụ chiếm lĩnh thị trường, mà là “sức mạnh cấp nền văn minh—có thể chữa lành, nhưng cũng có thể hủy diệt nhân loại”. Nếu không giải quyết vấn đề an toàn trước, không đảm bảo sự “đối xứng” giữa AI và con người, thì một khi mô hình mất kiểm soát, hậu quả sẽ khôn lường.
Ông nhiều lần đề xuất trong nội bộ công ty: Cần làm chậm tốc độ cập nhật mô hình, tăng cường kiểm tra an toàn, đặt “đối xứng trước tiên” lên hàng đầu. Nhưng tiếng nói của ông ngày càng bị đẩy ra ngoài lề.
Thực tế, sự khác biệt về quan điểm chỉ là bề nổi. Mâu thuẫn sâu xa hơn nằm ở việc tái phân chia quyền lực và tranh giành công trạng.
Theo bài điều tra chuyên sâu của Wall Street Journal năm 2026, Dario Amodei có đóng góp cốt lõi trong quá trình phát triển GPT-3—đặc biệt là việc triển khai thành công công nghệ RLHF, do ông chủ trì thúc đẩy. Thế nhưng trong tuyên truyền công khai, công trạng của ông bị đánh giá thấp nghiêm trọng; đội ngũ Sam Altman thiên về nhấn mạnh “quy mô và khả năng của mô hình”, trong khi bỏ qua công nghệ an toàn do Dario dẫn dắt.
Một điều khiến Dario thất vọng sâu sắc hơn nữa là sau khi Elon Musk rời OpenAI do bất đồng quan điểm, quyền lực lãnh đạo công ty hoàn toàn rơi vào tay Sam Altman. Ngân sách dành cho đội an toàn bị cắt giảm mạnh, nhiều dự án nghiên cứu an toàn cốt lõi bị đình hoãn, thậm chí có lãnh đạo cấp cao công khai tuyên bố: “Vấn đề an toàn có thể tạm gác sang một bên; hãy tập trung thương mại hóa trước—có tiền rồi sẽ quay lại giải quyết an toàn cũng chẳng muộn.”
Dario hiểu rằng, tại OpenAI, ông đã không còn khả năng thực hiện lý tưởng “đưa AI vận hành an toàn”. Sau này, trong một buổi phỏng vấn trên podcast của Lex Fridman, ông ôn lại giai đoạn này với giọng điệu bình thản nhưng đầy quyết đoán: “Tranh luận về tầm nhìn cốt lõi với người khác là việc vô cùng thiếu hiệu quả. Thay vì lãng phí thời gian, chi bằng tự tập hợp người, để hiện thực hóa lý tưởng của chính mình.”
Đầu năm 2021, thiên tài AI Dario đưa ra một quyết định khiến cả Thung lũng Silicon sửng sốt: Ông dẫn theo chị gái Daniela Amodei (nay là Chủ tịch Anthropic), cùng toàn bộ đội an toàn cốt lõi và các nhà nghiên cứu nòng cốt từ OpenAI, đồng loạt rời đi.

Hình chụp chung Dario Amodei và chị gái Daniela Amodei. Nguồn ảnh: Fortune
Cuộc ra đi này được xem là một cuộc “đáo nợ triệt để” với chủ nghĩa tăng tốc của OpenAI, đồng thời cũng là một tuyên ngôn kiên định cho triết lý “ưu tiên an toàn”.
Lúc bấy giờ, OpenAI vẫn lịch sự ra thông cáo chúc mừng đội ngũ Dario khởi đầu hành trình mới—nhưng trong bóng tối, vết rạn nứt giữa hai bên đã không thể hàn gắn.
Thực tế, Dario không chỉ mang đi những nhân tài hàng đầu, mà còn là công nghệ và triết lý an toàn cốt lõi nhất của OpenAI—điều này sau này tạo nên nền tảng cho Anthropic. Còn OpenAI, sau khi Dario rời đi, hoàn toàn rẽ sang con đường tăng tốc thương mại hóa—song điều này ngày càng xa rời lý tưởng ban đầu của Dario.
Nguồn ảnh:OpenAI
“Tôn giáo an toàn” của Anthropic
Tháng 2 năm 2021, Dario Amodei chính thức thành lập Anthropic với định vị là một “doanh nghiệp vì lợi ích cộng đồng”. Điều này hàm ý mục tiêu cốt lõi của công ty không phải tối đa hóa lợi nhuận, mà là “thúc đẩy sự phát triển an toàn, kiểm soát được của AI nhằm phục vụ nhân loại”.
Niềm ám ảnh “kiểm soát rủi ro” hình thành từ cái chết của cha, và lý tưởng “an toàn trước tiên” khi rời OpenAI, cuối cùng đều trở thành chế độ cốt lõi của Anthropic—biến thành “tôn giáo an toàn” in sâu trong ADN công ty.
Khi mới thành lập, Anthropic đã xác lập một phát minh cốt lõi mang tên Constitutional AI (AI Hiến pháp)—đây là kết tinh của nhiều năm suy ngẫm về “an toàn AI” của Dario, cũng là điểm khác biệt then chốt so với OpenAI và Google Gemini.
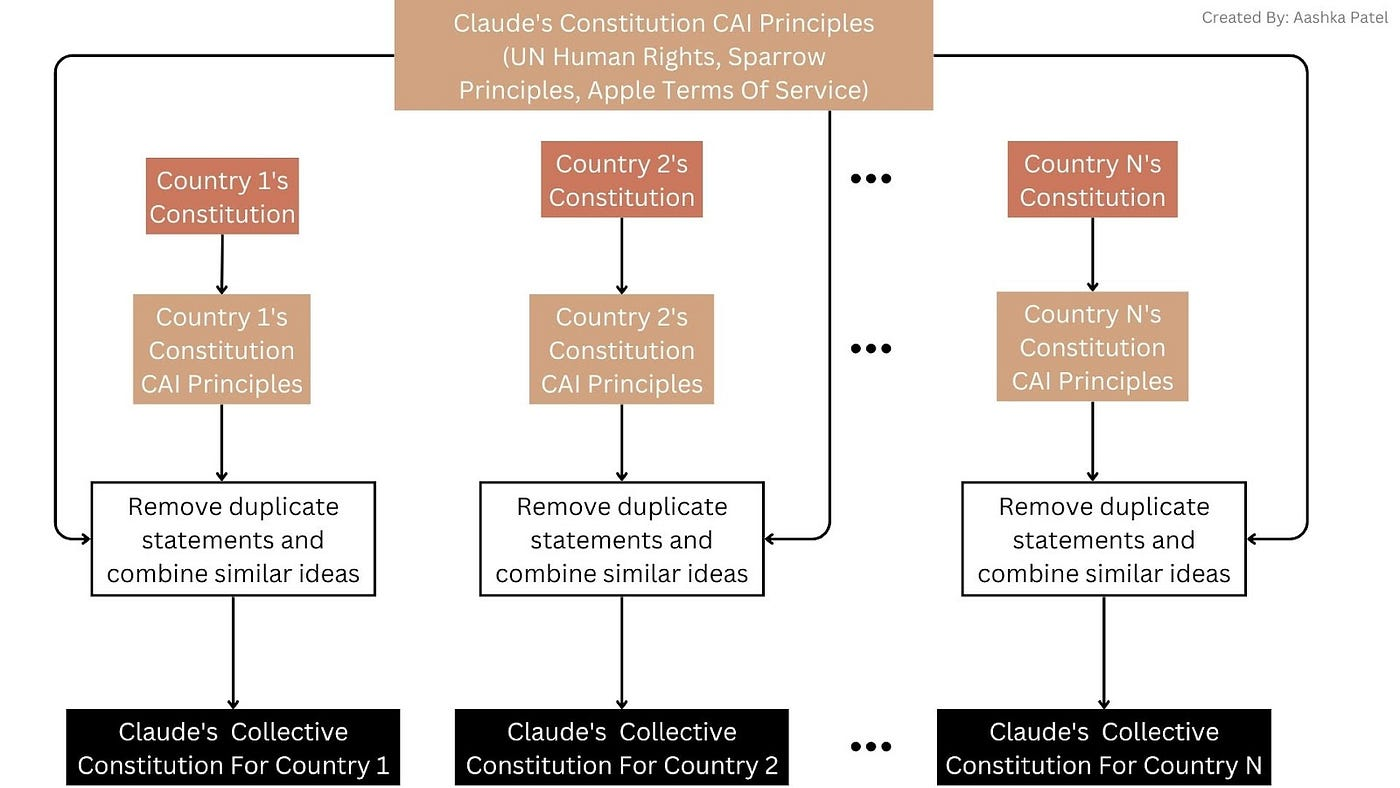
Sơ đồ nguyên lý Constitutional AI. Nguồn ảnh: Aashka Patel
Constitutional AI không theo cách thức “bổ sung hậu kỳ” của OpenAI sử dụng RLHF, mà thay vào đó cài đặt một bộ “hiến pháp” vào tầng nền huấn luyện mô hình—bộ hiến pháp này tích hợp Tuyên ngôn Nhân quyền Liên Hợp Quốc, các chuẩn mực đạo đức chung của nhân loại, và nguyên tắc an toàn riêng của Anthropic, để AI tự “kiểm tra nội bộ” và “tự phê bình” trước khi tạo ra bất kỳ đầu ra nào hoặc thực hiện bất kỳ lệnh nào—đảm bảo đầu ra phù hợp với giá trị nhân văn và không sinh ra nội dung nguy hiểm nào.
Dario đích thân viết hai bài luận dài: Machines of Loving Grace (Những cỗ máy tràn đầy yêu thương) và The Adolescence of Technology (Tuổi dậy thì của công nghệ), trình bày chi tiết tầm nhìn AI của ông:
Ông cho rằng AI giống như một thiếu niên—có tiềm năng mạnh mẽ nhưng cũng đầy bất định; do đó, cần đặt ra quy tắc và xây dựng hàng rào ngay từ đầu để tránh nó đi sai đường. Constitutional AI chính là “quy tắc” và “hàng rào” ấy.
Tôn giáo an toàn này không chỉ hiện hữu trong huấn luyện mô hình, mà còn trực tiếp lan tỏa đến từng sản phẩm, từng chính sách kiểm soát rủi ro của Anthropic: Thiết kế cấp quyền cao của Claude Code, kết hợp với các đầu dò tiêm gợi ý (prompt injection probe), bộ phân loại hội thoại—đều nhằm mục đích buộc AI kiểm tra thêm một lần trước khi thực hiện lệnh; còn logic kiểm soát rủi ro “phòng ngừa” với tư tưởng “thà giết nhầm, chứ không để sót”, chính là để “cắt đứt rủi ro ngay từ mầm mống”.
Sự kiện Anthropic đối đầu trực diện với Bộ Quốc phòng Hoa Kỳ năm 2026 là minh chứng rõ ràng nhất cho “chủ nghĩa nguyên giáo an toàn” này—sự kiện không chỉ gây chấn động Thung lũng Silicon, mà còn khiến cả thế giới chứng kiến quyết tâm của Dario Amodei: “Thà từ bỏ lợi ích, chứ không bao giờ từ bỏ an toàn.”
Đầu năm 2026, Bộ Quốc phòng Hoa Kỳ yêu cầu Anthropic gỡ bỏ hai hàng rào an toàn của Claude:
Thứ nhất, cấm sử dụng Claude vào “giám sát quy mô lớn công dân Hoa Kỳ”;
Thứ hai, cấm sử dụng Claude vào nghiên cứu và triển khai “vũ khí chết người hoàn toàn tự chủ”.
Bộ Quốc phòng cam kết: Chỉ cần Anthropic thỏa hiệp, sẽ ký hợp đồng quốc phòng trị giá 200 triệu đô la Mỹ và cung cấp lượng lớn năng lực tính toán.
Biết rằng lúc bấy giờ Anthropic đang đối mặt với tình trạng thiếu hụt năng lực tính toán và áp lực tài chính lớn, nên hợp đồng quốc phòng 200 triệu đô la Mỹ đủ để giải quyết “cơn khát” cấp bách của công ty.
Nhưng Dario Amodei thẳng thừng từ chối.
Ông công bố tuyên bố chính thức với giọng điệu kiên quyết: “Chúng tôi không thể phản bội lương tâm mình để phát triển công nghệ có thể gây hại cho con người và xâm phạm nhân quyền. Các hàng rào an toàn của Claude là ranh giới đỏ của chúng tôi—tuyệt đối không thỏa hiệp.”
Sự từ chối này khiến Bộ Quốc phòng Hoa Kỳ tức giận tột độ. Dưới sự dẫn dắt của chính quyền Trump, Bộ Quốc phòng trực tiếp đưa Anthropic vào “Danh sách rủi ro chuỗi cung ứng”—đây là lần đầu tiên trong lịch sử Hoa Kỳ một công ty AI nội địa bị đưa vào danh sách này, đồng nghĩa với việc tất cả nhà thầu quốc phòng Hoa Kỳ đều bị cấm sử dụng sản phẩm và dịch vụ của Anthropic. Hơn nữa, Bộ Quốc phòng còn đe dọa áp dụng Đạo luật Sản xuất Quốc phòng (Defense Production Act) để buộc Anthropic gỡ bỏ các hàng rào an toàn.
Đối mặt với sức ép từ bộ máy nhà nước, Dario Amodei trực tiếp kiện Bộ Quốc phòng Hoa Kỳ, cho rằng hành vi này là “sự trừng phạt trả đũa” đối với Anthropic, vi phạm luật pháp và giá trị của Hoa Kỳ. Mặc dù tòa phúc thẩm sau đó bác bỏ lệnh cấm tạm thời của Anthropic, nhưng Dario vẫn kiên quyết không thỏa hiệp—dù công ty vì thế mà mất đi hợp đồng khổng lồ, dù bị toàn bộ hệ thống công nghiệp quốc phòng Hoa Kỳ tẩy chay, ông vẫn kiên định giữ vững “ranh giới an toàn” của mình.
Đến đây, chúng ta hẳn đã hiểu rõ: Chính sách kiểm soát rủi ro khắt khe của Anthropic bắt nguồn từ việc Dario Amodei biến niềm ám ảnh cá nhân, nỗi sợ mất kiểm soát AI và những “bài học” rút ra từ OpenAI thành chế độ nội bộ của công ty.
Trong mắt ông, mỗi hành vi người dùng đáng ngờ, mỗi rủi ro tiềm ẩn đều có thể là “chất xúc tác” khiến AI mất kiểm soát—đó là lý do vì sao mức độ nghiêm khắc lại cao đến vậy.
Còn người dùng tiếng Trung chúng ta—những người dùng proxy, dịch vụ nhận mã, thẻ ảo để né hạn chế khu vực; những người dùng công cụ bên thứ ba để “chiếm lợi”—theo “tôn giáo an toàn” của Dario, đều là “chất xúc tác nguy hiểm nhất”, nên việc khóa tài khoản là điều tất yếu.
02 Nội chiến AI Hoa Kỳ—Cuộc đấu tranh quyền lực và vốn giữa phe An toàn và phe Tăng tốc
Thặng dư an toàn và mở rộng quy mô: Hai logic sinh tồn trái ngược
Nhiều người cho rằng niềm ám ảnh an toàn của Dario hoàn toàn không đủ để duy trì sự phát triển lâu dài của Anthropic, bởi nghiên cứu AI tốn kém như đốt tiền—không có nguồn vốn và lợi nhuận ổn định, thì niềm tin kiên định nhất cũng khó lòng hiện thực hóa.
Điều này không sai, nhưng chính mô hình kinh doanh độc đáo của Anthropic lại là chỗ dựa vững chắc cho chính sách “không khoan nhượng” của Dario, đồng thời cũng khiến công ty này đi trên con đường hoàn toàn khác biệt so với OpenAI và Google Gemini.
Anthropic: Từ bỏ cơn sốt thị trường tiêu dùng, dồn sức vào “thặng dư an toàn” ở phân khúc doanh nghiệp.
Anthropic từ đầu vốn không coi người dùng cá nhân là mục tiêu cốt lõi, mà nhắm vào các khách hàng doanh nghiệp “giá trị cao, độ chịu đựng thấp”: ngân hàng, văn phòng luật, cơ sở y tế, cơ quan chính phủ…
Điều họ sợ nhất là gì?
Chính là đầu ra gây hại của AI, rò rỉ dữ liệu nhạy cảm—gây ra kiện tụng, sụp đổ uy tín, thậm chí bị cơ quan quản lý phạt nặng.
Vì vậy, với họ, an toàn là lựa chọn bắt buộc. Miễn là Anthropic giữ vững nhãn hiệu “AI an toàn nhất”, họ sẵn sàng trả mức phí cao hơn và ký các hợp đồng dài hạn, ổn định.
Điều này quyết định logic kiểm soát rủi ro của Anthropic: “Thà giết nhầm một ngàn người dùng cá nhân, chứ không để một khách hàng doanh nghiệp nào chịu tổn hại do vấn đề an toàn.”
Bởi vì việc mất đi người dùng cá nhân gần như không ảnh hưởng đến doanh thu, nhưng nếu một khách hàng doanh nghiệp rời đi do lỗ hổng an toàn, Anthropic sẽ mất đi đơn hàng trị giá hàng triệu, thậm chí hàng chục triệu đô la Mỹ—và có thể phá hủy hoàn toàn danh tiếng cốt lõi “AI an toàn” của mình.
Mô hình đăng ký Pro/Max của Anthropic về bản chất là chiến lược “dẫn dắt người dùng bằng trợ giá”: giá thấp, hạn mức cao nhằm thu hút trải nghiệm, nhưng mô hình này hoàn toàn không sinh lời—thậm chí còn lỗ.
Theo tính toán nội bộ ngành, chi phí token của Claude rất cao; gói đăng ký Pro/Max gần như “ăn sạch” 99% chi phí token. Một khi người dùng dùng công cụ bên thứ ba để “chiếm lợi”, ví dụ như dùng gói đăng ký tiêu dùng để tránh giá cao của API và gọi giao diện hàng loạt, Anthropic sẽ lỗ nặng.
Vì vậy, cuộc “làm sạch” công cụ bên thứ ba đầu năm 2026 (khóa OpenClaw, OpenCode…), khóa hàng loạt người dùng nặng, thậm chí khóa toàn bộ tổ chức gồm 110 người của công ty công nghệ nông nghiệp—về bản chất đều là những hành động “dọn dẹp chính xác” của Anthropic: Đuổi những người dùng cá nhân “chiếm lợi”, những người dùng nặng chiếm dụng lượng lớn năng lực tính toán, để dồn nguồn lực cho khách hàng doanh nghiệp và khách hàng API sẵn sàng trả giá cao.
Tôi cho rằng đây là một phép tính kinh tế lạnh lùng ngoài yếu tố an toàn: Thà chủ động “cắt cỏ” còn hơn để đám “cừu ăn cỏ” làm sụp đổ công ty—để giữ vững ranh giới lợi nhuận của mình.
ChatGPT (OpenAI): Trước hết mở rộng quy mô, sau đó mới thương mại hóa—kiểm soát rủi ro linh hoạt để đổi lấy lưu lượng.
Chủ nghĩa tăng tốc của Sam Altman không chỉ hiện hữu trong việc cập nhật mô hình, mà còn thể hiện rõ trong mô hình kinh doanh.
OpenAI đi theo chiến lược “chiếm đất bằng tốc độ”: Giai đoạn đầu dùng chiến lược miễn phí và đăng ký giá rẻ để thu hút người dùng ồ ạt—even if kiểm soát rủi ro hơi lỏng một chút, hay xuất hiện vài hành vi vi phạm nhẹ, họ cũng không dễ dàng khóa tài khoản.
Vì với họ, quy mô người dùng chính là “đường sinh mệnh”: Có đủ người dùng, mới thu hút được sự hỗ trợ tài chính từ Microsoft, mới chiếm ưu thế trong quá trình thương mại hóa (API, phiên bản doanh nghiệp, hệ sinh thái plugin). Ví dụ gần đây là hợp tác với Malta, công dân Malta được dùng GPT miễn phí trong một năm.
OpenAI thậm chí chủ động chào đón hệ sinh thái công cụ bên thứ ba—dù một số công cụ có dấu hiệu “chiếm lợi”, họ cũng chỉ chọn lọc khóa, chứ không làm như Anthropic: “cắt một nhát” và “tiêu diệt hàng loạt”.
Bởi họ hiểu rằng, công cụ bên thứ ba giúp họ giữ chân người dùng và mở rộng ảnh hưởng hệ sinh thái—giá trị này quan trọng hơn nhiều so với tổn thất token nhỏ lẻ.
Google Gemini: Ưu tiên bá quyền hệ sinh thái
Gemini dựa lưng vào đế chế quảng cáo và hệ sinh thái toàn diện của Google (Tìm kiếm, YouTube, Android, Điện toán đám mây), nên mục tiêu cốt lõi của nó không phải kiếm tiền trực tiếp từ Gemini, mà là dùng Gemini để thúc đẩy lưu lượng và doanh thu toàn bộ hệ sinh thái Google.
Vì vậy, logic kiểm soát rủi ro của nó là “không gây rắc rối lớn là được”: Miễn là không xảy ra sự cố an toàn nghiêm trọng, không bị cơ quan quản lý xử phạt, thì với các hành vi vi phạm nhẹ của người dùng cá nhân (ví dụ như IP bất thường nhẹ, dùng công cụ bên thứ ba), họ sẽ “mở một mắt, nhắm một mắt”.
Gemini thỉnh thoảng cũng siết chặt kiểm soát rủi ro, nhưng phần lớn là “biểu diễn tuân thủ” để làm vừa lòng cơ quan quản lý—chắc chắn không như Anthropic, vì an toàn mà sẵn sàng từ bỏ lượng lớn người dùng.
Vì với Google, số lượng người dùng hoạt động hàng ngày và khả năng tương thích hệ sinh thái quan trọng hơn nhiều so với an toàn tuyệt đối—họ không cần dựa vào “nhãn hiệu an toàn” để thu hút khách hàng, bởi thương hiệu và hệ sinh thái Google chính là chỗ dựa vững chắc nhất.
Ngoài ra, Anthropic còn có một logic chi phí ẩn khác:
Tháng 4 năm 2026, công ty thừa nhận trên blog chính thức rằng từng hạ mức độ suy luận mặc định của Claude Code nhằm giảm độ trễ, tiết kiệm token và cải thiện trải nghiệm người dùng; sau đó do phát hiện rủi ro an toàn, đã khẩn cấp khôi phục và tăng cường kiểm soát. Sự việc này gần đây cũng gây xôn xao dư luận.
Vì vậy, tôi cho rằng Anthropic thực sự luôn đặt an toàn lên hàng đầu trong bốn chiều kích “an toàn, độ trễ, chi phí, hạn mức”—ngay cả khi phải hy sinh trải nghiệm người dùng hoặc tăng chi phí, cũng tuyệt đối không thỏa hiệp. Đây vừa là niềm ám ảnh của Dario, vừa là lựa chọn tất yếu của mô hình kinh doanh.
Amazon/Google: Nghệ thuật cân bằng dưới sự ràng buộc lợi ích
Thực tế, dù niềm ám ảnh an toàn của Dario có kiên định đến đâu, cũng không thể thiếu sự hậu thuẫn của vốn—vì tốc độ đốt tiền trong nghiên cứu AI vượt xa tưởng tượng của người bình thường. Không có sự hỗ trợ tài chính và năng lực tính toán từ các “ông lớn”, Anthropic chắc chắn không thể tồn tại đến ngày hôm nay.
Các khoản đầu tư từ Amazon và Google tuy bề ngoài là ủng hộ sự phát triển của AI an toàn, nhưng thực chất là một cuộc “đặt cược chiến lược chính xác”, đồng thời cũng là một trong những “người đẩy” vô hình cho logic kiểm soát rủi ro của Anthropic.
Tôi đã tìm được một bộ dữ liệu đầu tư cốt lõi—đây là chìa khóa để hiểu rõ cuộc đấu tranh quyền lực giữa các nhà đầu tư:
Amazon: Đầu tư tích lũy vào Anthropic hơn 4 tỷ đô la Mỹ, trong đó không chỉ có tiền mặt mà còn có lượng lớn tài nguyên điện toán đám mây AWS. Biết rằng việc huấn luyện các mô hình tiên tiến như Claude 3 đòi hỏi năng lực tính toán khổng lồ, nên sự hỗ trợ từ AWS thực sự là “tuyết giữa hè” đối với Anthropic.
Google: Đầu tư tích lũy vào Anthropic hơn 2 tỷ đô la Mỹ, đồng thời cung cấp lượng lớn năng lực tính toán và hỗ trợ kỹ thuật, nhằm tận dụng công nghệ AI của Anthropic để bổ khuyết điểm yếu trong lĩnh vực mô hình ngôn ngữ lớn, đối đầu liên minh OpenAI–Microsoft. Dù Google cũng có Gemini, nhưng đầu tư vào Anthropic giống như bổ sung hướng “lập trình cảm hứng” (Vibe Coding) cho phe mình.
Các “ông lớn” này đầu tư đều có mục tiêu cốt lõi riêng:
Với Amazon, việc đầu tư vào Anthropic nhằm hai mục đích: Thứ nhất, khiến Claude gắn bó sâu sắc với hệ sinh thái AWS—khách hàng doanh nghiệp dùng Claude thì buộc phải dùng tài nguyên điện toán đám mây AWS, từ đó thúc đẩy doanh thu AWS; thứ hai, Amazon cần “nhãn hiệu an toàn” của Anthropic để đối trọng rủi ro quản lý. Bởi vì quản lý AI ngày càng nghiêm ngặt, có một đối tác an toàn tuyệt đối như Anthropic sẽ giúp Amazon triển khai AI ổn định hơn, tránh bị cơ quan quản lý xử phạt.
Với Google, việc đầu tư vào Anthropic là để phá vỡ sự độc quyền của OpenAI và Microsoft. Google khởi đầu sớm trong lĩnh vực mô hình ngôn ngữ lớn, nhưng tiến triển chậm, hiệu suất Gemini luôn thua kém Claude và ChatGPT. Việc đầu tư vào Anthropic vừa giúp Google tiếp cận công nghệ cốt lõi, vừa phân tán người dùng và khách hàng của OpenAI, củng cố vị thế hệ sinh thái AI của mình.
Tuy nhiên, ở đây tồn tại một điểm then chốt trong cuộc đấu tranh:
Các “ông lớn” muốn Anthropic “an toàn”, nhưng không muốn nó “quá an toàn”.
Logic của tôi như sau: Nếu Anthropic quá bảo thủ, kiểm soát rủi ro quá khắt khe sẽ dẫn đến mất người dùng, hệ sinh thái teo tóp—cuối cùng ảnh hưởng đến chiến lược bố trí của các “ông lớn”.
Ví dụ như đã nêu ở trên, sau khi Bộ Quốc phòng Mỹ đưa Anthropic vào “Danh sách rủi ro chuỗi cung ứng” năm 2026, Amazon và Google không đi theo bước chân của quân đội, mà tiếp tục hợp tác với Anthropic trong lĩnh vực dân dụng, thậm chí còn tăng cường hỗ trợ năng lực tính toán. Bởi vì họ đã đầu tư quá nhiều tiền và tài nguyên—không thể để Anthropic sụp đổ vì “quá an toàn”, cũng không thể để khoản đầu tư của mình “đổ sông đổ biển”.
Vì vậy, điều này tạo nên một sự cân bằng tinh tế:
Dario kiên định theo đuổi niềm ám ảnh an toàn, thực thi chính sách kiểm soát rủi ro “không khoan nhượng”;
Còn vốn thì “kéo dây cương” phía sau—vừa ủng hộ vị trí “an toàn” của Anthropic, vừa ngầm kiềm chế hành vi cực đoan của nó, đảm bảo Anthropic sẽ không vì quá bảo thủ mà mất đi giá trị thương mại.
So sánh với logic ràng buộc vốn của OpenAI và Gemini thì đơn giản hơn:
OpenAI gắn bó sâu sắc với Microsoft: Không chỉ cung cấp vốn và năng lực tính toán, Microsoft còn tích hợp ChatGPT vào các sản phẩm Office, Azure…—hai bên hình thành “cộng đồng lợi ích”. Kiểm soát rủi ro lỏng lẻo của OpenAI bản chất là để phối hợp với chiến lược “mở rộng hệ sinh thái” của Microsoft.
Gemini là “con cưng” của Google, không cần dựa vào vốn bên ngoài, nên chiến lược kiểm soát rủi ro hoàn toàn phục vụ bố trí tổng thể hệ sinh thái Google—tính linh hoạt cao hơn.
Vì vậy, kiểm soát rủi ro khắt khe của Anthropic, bề ngoài là niềm ám ảnh cá nhân của Dario, nhưng thực chất cũng có sự “đẩy sóng” từ vốn.
Các “ông lớn” cần “nhãn hiệu an toàn” của nó, còn nó cần vốn và năng lực tính toán từ các “ông lớn”—hai bên cùng có lợi, còn tài khoản người dùng thông thường trở thành “hy sinh phẩm” trong mối ràng buộc lợi ích này.
Cuộc đọ sức công khai trong nội chiến AI Hoa Kỳ
Ngành AI Hoa Kỳ hiện nay thực tế đã chia thành hai phe rõ rệt.
Một phe là “phe An toàn” lấy Anthropic làm trung tâm; một phe là “phe Tăng tốc” lấy OpenAI và hệ thống quân sự làm trung tâm. Cuộc đấu tranh giữa hai phe từ “đấu âm thầm” dần chuyển thành “đọ sức công khai”, và thái độ kiểm soát rủi ro của Anthropic chính là biểu hiện trực tiếp của cuộc nội chiến này.
Chúng ta hãy làm rõ chủ trương cốt lõi của hai phe để hiểu bản chất cuộc đấu tranh:
Phe An toàn:
Chủ trương cốt lõi của phe này là “an toàn AI là ưu tiên hàng đầu, kiểm soát rủi ro là nhiệm vụ số một”. Họ cho rằng AI là “rủi ro cấp loài có thể dẫn đến tuyệt chủng nhân loại”, do đó cần làm chậm tốc độ phát triển, tăng cường kiểm tra an toàn, thiết lập hàng rào an toàn nghiêm ngặt—thậm chí kêu gọi quản lý bắt buộc, kiên quyết phản đối việc sử dụng AI vào lĩnh vực quân sự, giám sát quy mô lớn…
Dario Amodei là đại diện cốt lõi của phe này; cộng đồng EA (Hiệu quả vị tha) là lực lượng hỗ trợ quan trọng, chủ trương “dùng lý tính và khoa học để tối đa hóa lợi ích lâu dài cho nhân loại”, trong đó an toàn AI là chủ đề cốt lõi.
Phe Tăng tốc:
Chủ trương cốt lõi của phe này là “tăng tốc phát triển AI để chiếm ưu thế trong cuộc chạy đua vũ trang”, cho rằng AI là “năng lực cạnh tranh cốt lõi trong cuộc tranh giành giữa các cường quốc”, do đó cần nhanh chóng cập nhật mô hình, thương mại hóa và ứng dụng quân sự để chiếm lĩnh tiếng nói toàn cầu về AI; còn vấn đề an toàn thì có thể gác lại, đợi công nghệ chín muồi rồi mới từng bước giải quyết.
Sam Altman, Bộ Quốc phòng Hoa Kỳ, một số doanh nghiệp quốc phòng và một số quan chức chính quyền Trump (ví dụ như Hegseth, người đứng đầu Bộ Quốc phòng) là lực lượng nòng cốt của phe này.
Hạt nhân của cuộc đấu tranh này thực chất là quyền kiểm soát sự phát triển của AI: Liệu AI nên do phe An toàn dẫn dắt, phát triển chậm rãi dưới sự kiểm soát nghiêm ngặt; hay do phe Tăng tốc dẫn dắt, nhanh chóng cập nhật để phục vụ nhu cầu thương mại và quân sự?
Sự kiện Bộ Quốc phòng Mỹ đưa Anthropic vào “Danh sách rủi ro chuỗi cung ứng” năm 2026 chính là “điểm bùng nổ công khai” của cuộc nội chiến này.
Vì vậy, dùng góc nhìn đã nêu ở trên, chúng ta hãy điểm lại chi tiết sự kiện này:
Đầu năm 2026, Bộ Quốc phòng Hoa Kỳ yêu cầu Anthropic gỡ bỏ hai hàng rào an toàn của Claude: cấm sử dụng vào “giám sát quy mô lớn công dân Hoa Kỳ” và “nghiên cứu, triển khai vũ khí chết người hoàn toàn tự chủ”.
Về bản chất, đây là một cuộc “dò thăm” của phe Tăng tốc, nhằm thử xem Anthropic có chịu thỏa hiệp để trở thành “công cụ” phục vụ hệ thống quân sự hay không.
Nhưng Dario Amodei thẳng thừng từ chối—dù đối mặt với hợp đồng quốc phòng 200 triệu đô la Mỹ và sự hỗ trợ năng lực tính toán, dù đối mặt với các mối đe dọa từ Bộ Quốc phòng, ông vẫn kiên định giữ vững ranh giới an toàn của mình.
Sự “không thỏa hiệp” này khiến phe Tăng tốc tức giận tột độ—trong mắt họ, hành vi của Anthropic là đang cản trở cuộc chạy đua vũ trang AI của Hoa Kỳ, là đang “kéo chân” đất nước.
Vì vậy, phe Tăng tốc đã dùng sức mạnh của bộ máy nhà nước để “phản kích” Anthropic: Chính quyền Trump do Bộ Quốc phòng dẫn đầu trực tiếp đưa Anthropic vào “Danh sách rủi ro chuỗi cung ứng”.
Đây là lần đầu tiên trong lịch sử Hoa Kỳ một công ty AI nội địa bị đưa vào danh sách này—điều này đồng nghĩa với việc tất cả nhà thầu quốc phòng Hoa Kỳ đều bị cấm sử dụng sản phẩm và dịch vụ của Anthropic. Hơn nữa, Bộ Quốc phòng còn đe dọa áp dụng Đạo luật Sản xuất Quốc phòng để buộc Anthropic gỡ bỏ hàng rào an toàn, thậm chí trừng phạt công ty.
Cuộc “phản kích” này bề ngoài là mâu thuẫn giữa Anthropic và Bộ Quốc phòng, nhưng thực chất là cuộc đọ sức công khai giữa phe An toàn và phe Tăng tốc.
Phe Tăng tốc muốn dùng bộ máy nhà nước ép phe An toàn thỏa hiệp để AI phục vụ nhu cầu quân sự. Còn phe An toàn kiên định giữ vững lý tưởng của mình—thà từ bỏ lợi ích, cũng không bao giờ buông lơi ranh giới an toàn.
Đáng chú ý hơn nữa, OpenAI và Gemini trong cuộc nội chiến này đã chọn “thỏa hiệp”:
OpenAI vì muốn giành hợp đồng quốc phòng, đã lặng lẽ điều chỉnh chính sách an toàn của mình, nới lỏng các hạn chế đối với ứng dụng liên quan quân sự. Còn Gemini, với tư cách là sản phẩm của Google, cũng áp dụng thái độ “tuân thủ mềm dẻo” đối với nhu cầu quân đội—không công khai đối đầu với Bộ Quốc phòng như Anthropic.
Sự so sánh này càng làm nổi bật tính cực đoan của Anthropic.
Lý do Anthropic thực thi chính sách kiểm soát rủi ro “không khoan nhượng” không chỉ vì kiên định với lý tưởng an toàn, mà còn để trong cuộc nội chiến này, củng cố vị thế “trung tâm phe An toàn”, chiếm lĩnh “đỉnh cao đạo đức AI có trách nhiệm”. Với nó, mỗi lần khóa tài khoản đều là một thông điệp gửi tới thế giới: “Chúng tôi là AI an toàn nhất; chúng tôi sẽ không bao giờ vì lợi ích mà thỏa hiệp ranh giới an toàn của mình.”
Cuộc nội chiến này cũng khiến kiểm soát rủi ro của Anthropic ngày càng khắt khe hơn—bởi chỉ cần một chút lơi lỏng, phe Tăng tốc sẽ nắm bắt ngay cơ hội, và Anthropic sẽ mất đi lợi thế cạnh tranh cốt lõi của mình.
Vì vậy, Anthropic chỉ có thể siết chặt hơn nữa kiểm soát rủi ro, mở rộng phạm vi “tiêu diệt phòng ngừa”—dù phải giết nhầm thêm nhiều người dùng vô tội, cũng phải giữ vững “hào thành an toàn” của mình.
Vì vậy, “làn sóng khóa tài khoản” của Anthropic còn một nguyên nhân sâu xa hơn: Đó là sự “tràn ra ngoài” của nội chiến ngành AI Hoa Kỳ.
Sự đấu tranh giữa phe An toàn và phe Tăng tốc, sự giằng co giữa vốn và quyền lực, cuối cùng đều đổ dồn lên tài khoản của người dùng thông thường—việc khóa tài khoản chính là biểu hiện trực tiếp và tàn khốc nhất của cuộc nội chiến này.
03 Cục diện địa chính trị và bế tắc người dùng: Cuộc đấu tranh toàn cầu trong bối cảnh ly khai AI Trung-Mỹ
Bạn đã bao giờ tự hỏi: Vì sao Anthropic lại nhắm đặc biệt vào người dùng Trung Quốc?
Vì sao chúng ta dùng proxy, dịch vụ nhận mã, thẻ ảo—thậm chí chỉ sử dụng bình thường thôi—cũng dễ bị khóa tài khoản?
Nhìn từ góc độ vĩ mô hơn, đây là hệ quả tất yếu của việc phong tỏa công nghệ Mỹ trong bối cảnh ly khai AI Trung-Mỹ; còn kiểm soát rủi ro khắt khe của Anthropic chỉ là người thực thi cuộc đấu tranh địa chính trị này.
Thực tế, từ năm 2024, việc Mỹ phong tỏa công nghệ AI đối với Trung Quốc đã bước vào giai đoạn “nóng bỏng”:
Từ hạn chế xuất khẩu chip AI cao cấp (ví dụ chip NVIDIA H100/H20), đến cấm các công ty AI nội địa Mỹ cung cấp dịch vụ cho Trung Quốc, rồi đến hạn chế luồng nhân tài AI—Mỹ đang cố gắng cắt đứt kênh Trung Quốc tiếp cận công nghệ AI tiên tiến thông qua “ly khai công nghệ”, nhằm củng cố vị thế bá chủ toàn cầu trong lĩnh vực AI.
Còn Anthropic, với tư cách là một công ty AI nội địa Mỹ và gắn bó sâu sắc với các “ông lớn” công nghệ Mỹ như Amazon và Google, đương nhiên phải tuân thủ chính sách kiểm soát xuất khẩu của Mỹ.
Theo yêu cầu của Đạo luật Chip và Khoa học (CHIPS and Science Act) và Quy định Kiểm soát Xuất khẩu (EAR) của Mỹ, các công ty AI Mỹ không được cung cấp dịch vụ “có khả năng rủi ro cao” cho người dùng Trung Quốc (bao gồm cả Trung Quốc đại lục, Hồng Kông và Ma Cao). Còn Claude Code—công cụ có khả năng thực thi lệnh trực tiếp và truy cập đặc quyền hệ thống—tự nhiên nằm trong “danh sách hạn chế”.
Điều này có nghĩa Anthropic buộc phải xây dựng hệ thống “kiểm soát rủi ro theo khu vực” nghiêm ngặt để ngăn người dùng Trung Quốc sử dụng Claude Code, thậm chí việc sử dụng Claude phiên bản thông thường cũng bị hạn chế nghiêm ngặt. Tôi nhớ khi Claude mới ra mắt thị trường vào khoảng năm 2024, tôi dùng tài khoản Gmail của mình đăng ký và đăng nhập—tài khoản bị khóa ngay lập tức.
Tất nhiên, công nghệ không thể khóa được người dùng Trung Quốc thông minh—chúng ta có thể dùng proxy, thẻ ảo, nền tảng nhận mã để né hạn chế khu vực và đăng nhập sử dụng Claude. Nhưng trong mắt Anthropic, đây không chỉ là “sử dụng vi phạm”, mà còn là hành vi “vi phạm chính sách kiểm soát xuất khẩu của Mỹ”. Một khi bị cơ quan quản lý Mỹ phát hiện, Anthropic sẽ đối mặt với khoản phạt khổng lồ, thu hồi giấy phép, thậm chí bị buộc đóng cửa.
Vì vậy, việc “khóa hàng loạt tài khoản người dùng Trung Quốc” của Anthropic về bản chất là sự kết hợp giữa “tuân thủ bị động” và “tự bảo vệ chủ động”:
Một mặt, Anthropic phải tuân thủ chính sách kiểm soát xuất khẩu của Mỹ để tránh bị xử phạt;
Mặt khác, nó phải dùng kiểm soát rủi ro khắt khe để gửi tín hiệu “tuân thủ tích cực” tới cơ quan quản lý Mỹ, củng cố vị thế tồn tại trong nước.
Bởi vì trong bối cảnh ly khai AI Trung-Mỹ, Anthropic không có lựa chọn nào khác—hoặc tuân thủ và khóa tài khoản, hoặc bị cơ quan quản lý Mỹ loại bỏ.
Mức độ “giám sát tuân thủ” của cơ quan quản lý Mỹ đối với Anthropic nghiêm ngặt hơn nhiều so với tưởng tượng của chúng ta.
Theo báo cáo của Washington Post tháng 3 năm 2026, Cục An ninh Công nghiệp và An ninh (BIS) thuộc Bộ Thương mại Mỹ mỗi tháng đều kiểm tra ngẫu nhiên dữ liệu người dùng và hồ sơ kiểm soát rủi ro của Anthropic; một khi phát hiện người dùng Trung Quốc sử dụng vi phạm, sẽ cảnh báo Anthropic hoặc phạt tiền.
Nửa cuối năm 2025, Anthropic từng bị BIS phạt 12 triệu đô la Mỹ vì “lỗ hổng kiểm soát rủi ro khiến một số người dùng Trung Quốc sử dụng vi phạm Claude Code”—đây cũng là một trong những nguyên nhân quan trọng khiến Anthropic sau đó tăng cường mạnh mẽ việc khóa tài khoản và thực hiện “tiêu diệt phòng ngừa”.
So sánh với “hạn chế khu vực” của OpenAI và Google Gemini thì linh hoạt hơn nhiều—không phải vì họ “thân thiện” hơn, mà vì mô hình kinh doanh và bố trí chiến lược của họ mang lại “không gian vận hành” lớn hơn.
OpenAI gắn bó sâu sắc với Microsoft, còn Microsoft có khối lượng kinh doanh lớn tại Trung Quốc và cần cân bằng nhu cầu thị trường Trung Quốc, nên kiểm soát rủi ro theo khu vực của OpenAI tương đối linh hoạt, thậm chí ngầm cho phép một số người dùng Trung Quốc sử dụng qua công cụ bên thứ ba;
Gemini dù cũng tuân thủ chính sách kiểm soát xuất khẩu của Mỹ, nhưng hoạt động của Google tại Trung Quốc hạn chế, hơn nữa mục tiêu cốt lõi của Gemini là mở rộng quy mô người dùng, nên với việc người dùng Trung Quốc sử dụng vi phạm, họ áp dụng thái độ “mở một mắt, nhắm một mắt”, hiếm khi thực hiện khóa hàng loạt.
Vì vậy, bế tắc khóa tài khoản của người dùng tiếng Trung về bản chất cũng có thể coi là “hy sinh phẩm” trong cục diện ly khai AI Trung-Mỹ.
Kiểm soát rủi ro khắt khe của Anthropic không chỉ là kết quả của niềm ám ảnh an toàn, cuộc đấu tranh vốn và nội chiến phe phái, mà còn là biểu hiện trực tiếp của chính sách phong tỏa công nghệ Mỹ. Điều chúng ta cho là “khóa nhầm”, trong mắt Anthropic lại là “né tránh quản lý, sử dụng vi phạm”. Còn điều chúng ta cho là “nhắm vào”, thực chất chỉ là lựa chọn tự bảo vệ bắt buộc mà Anthropic phải đưa ra trong cuộc đấu tranh giữa các cường quốc.
Sự cân bằng tam giác giữa phe An toàn, phe Tăng tốc và lực lượng AI Trung Quốc
Hiện nay, cục diện AI toàn cầu không còn là cuộc “song đấu hai cường quốc” (Mỹ và Trung Quốc), mà đang dần chuyển sang “tam giác cân bằng”: Phe An toàn lấy Anthropic làm trung tâm, phe Tăng tốc lấy OpenAI làm trung tâm, và lực lượng AI Trung Quốc đang trỗi dậy mạnh mẽ—ba bên tương tác, đấu tranh và kiềm chế lẫn nhau, quyết định hướng phát triển tương lai của AI.
Việc đấu tranh giữa phe An toàn và phe Tăng tốc vẫn đang leo thang—điều này chúng ta đã phân tích sâu ở phần trên nên không lặp lại.
Nội chiến giữa hai phe Mỹ tuy dẫn đến kiểm soát rủi ro khắt khe của Anthropic, nhưng đồng thời cũng thúc đẩy sự phát triển nhanh chóng của công nghệ AI Mỹ: Phe An toàn chuyên sâu vào công nghệ an toàn AI, phe Tăng tốc thúc đẩy ứng dụng thương mại và quân sự của AI—hai bên cạnh tranh, hỗ trợ lẫn nhau, khiến lợi thế dẫn đầu của Mỹ trong lĩnh vực AI vẫn khó bị lay chuyển.
Hãy nhìn sang sự trỗi dậy của lực lượng AI Trung Quốc.
Trong bối cảnh ly khai AI Trung-Mỹ, các công ty AI nội địa Trung Quốc đã bước vào “thời kỳ cơ hội phát triển”.
Văn Tâm Nhất Ngôn của Baidu, Thông Nghĩa Thiên Vấn của Alibaba, Đại mô hình Phân Bố của Huawei, Đậu Bao của ByteDance… đều nhanh chóng cập nhật, từng bước thu hẹp khoảng cách về năng lực công nghệ và ứng dụng thực tiễn so với AI Mỹ.
Đặc biệt trong lĩnh vực công cụ lập trình, các công cụ AI mã hóa nội địa Trung Quốc (ví dụ trợ lý mã Đậu Bao, phiên bản mã hóa của Văn Tâm Nhất Ngôn) tuy vẫn còn khoảng cách với các sản phẩm đầu bảng, nhưng đã đủ đáp ứng nhu cầu lập trình của người dùng thông thường—đồng thời không có hạn chế khu vực, không có kiểm soát rủi ro khắt khe, phù hợp hơn với thói quen sử dụng của người dùng Trung Quốc, dần trở thành “lựa chọn thay thế” cho người dùng Trung Quốc.
Sự phát triển AI Trung Quốc đi theo con đường “thực tiễn, tuân thủ, cởi mở”: Vừa chú trọng an toàn AI, vừa chú trọng ứng dụng thương mại—không áp dụng kiểm soát rủi ro cực đoan “không khoan nhượng”, cũng không mù quáng theo đuổi “tăng tốc phát triển”, mà tìm kiếm sự cân bằng giữa an toàn và phát triển.
Con đường phát triển này không chỉ phù hợp với chính sách quản lý của Trung Quốc, mà còn sát hơn với nhu cầu của người dùng thông thường, dần dần giành được sự công nhận của thị trường.
Ngoài ra, châu Âu, Nhật Bản, Hàn Quốc và các quốc gia/vùng lãnh thổ khác cũng đang tích cực bố trí ngành AI, nỗ lực chiếm một vị trí trong cục diện AI toàn cầu.
Châu Âu chú trọng quản lý AI, ban hành Đạo luật Trí tuệ nhân tạo để quy phạm sự phát triển của AI, đồng thời hỗ trợ các công ty AI nội địa. Nhật Bản và Hàn Quốc tăng cường đầu tư vào nghiên cứu AI, tập trung phát triển ứng dụng AI trong sản xuất, y tế, tài chính… nhằm bắt kịp bước tiến của Mỹ và Trung Quốc.
Tương lai, cuộc đấu tranh cục diện AI toàn cầu sẽ là “cuộc tranh luận về quan điểm, cuộc tranh giành lợi ích và cuộc đấu tranh địa chính trị”.
Phe An toàn muốn “phát triển kiểm soát được”, phe Tăng tốc muốn “trỗi dậy nhanh chóng”, còn lực lượng AI Trung Quốc muốn “tự chủ, kiểm soát và hợp tác mở”, cuộc đấu tranh giữa ba bên sẽ quyết định hướng đi của AI, đồng thời ảnh hưởng đến đời sống của mỗi người dùng thông thường.
K
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News








