

X mở mã nguồn thuật toán mới, rốt cuộc chúng ta nên viết nội dung gì để thu hút hơn?
Tuyển chọn TechFlowTuyển chọn TechFlow
X mở mã nguồn thuật toán mới, rốt cuộc chúng ta nên viết nội dung gì để thu hút hơn?
Việc thích gần như không có giá trị, tương tác qua lại mới là tiền tệ thật sự.
Tác giả: David, TechFlow
Chiều ngày 20 tháng 1, X đã công khai mã nguồn phiên bản mới của thuật toán đề xuất.
Musk đi kèm bình luận khá thú vị: «Chúng tôi biết thuật toán này rất ngốc nghếch, cần sửa đổi lớn, nhưng ít nhất bạn có thể thấy chúng tôi đang vật lộn cải thiện theo thời gian thực. Các nền tảng mạng xã hội khác không dám làm như vậy.»
Lời nói này có hai tầng ý nghĩa. Thứ nhất là thừa nhận thuật toán có vấn đề, thứ hai là lấy «sự minh bạch» làm điểm bán hàng.
Đây là lần thứ hai X công khai mã nguồn thuật toán. Phiên bản năm 2023 đã ba năm không cập nhật, sớm đã lạc hậu so với hệ thống thực tế. Lần này được viết lại hoàn toàn, mô hình cốt lõi chuyển từ học máy truyền thống sang transformer Grok, theo lời chính thức là «loại bỏ hoàn toàn kỹ thuật thủ công tạo đặc trưng».
Diễn giải dễ hiểu: trước kia thuật toán dựa vào kỹ sư điều chỉnh tham số bằng tay, giờ đây AI trực tiếp xem lịch sử tương tác của bạn để quyết định có đẩy nội dung hay không.
Với người sáng tạo nội dung, điều này đồng nghĩa các bí kíp kiểu «giờ nào đăng bài tốt nhất», «dùng thẻ tag nào để tăng follow» có lẽ sẽ không còn hiệu lực.
Chúng tôi cũng đã lục tìm kho lưu trữ GitHub được công khai, dưới sự hỗ trợ của AI, phát hiện trong mã nguồn quả thật ẩn chứa một số logic cứng, đáng để đào sâu.
Thay đổi logic thuật toán: Từ định nghĩa thủ công sang AI tự đánh giá
Trước tiên cần làm rõ sự khác biệt giữa phiên bản cũ và mới, nếu không sẽ dễ nhầm lẫn ở phần sau.
Năm 2023, Twitter công khai phiên bản tên Heavy Ranker, bản chất là học máy truyền thống. Kỹ sư phải tự định nghĩa hàng trăm «đặc trưng»: bài viết này có hình ảnh không, người đăng có bao nhiêu người theo dõi, thời gian đăng cách hiện tại bao lâu, bài viết có chứa liên kết không…
Sau đó gán trọng số cho từng đặc trưng, điều chỉnh qua lại để xem tổ hợp nào hiệu quả hơn.
Phiên bản mới công khai lần này gọi là Phoenix, kiến trúc hoàn toàn khác biệt, bạn có thể hiểu là một thuật toán phụ thuộc nhiều hơn vào mô hình AI lớn, cốt lõi dùng mô hình transformer Grok, cùng loại công nghệ với ChatGPT, Claude.
Tài liệu README chính thức viết rất thẳng: «Chúng tôi đã loại bỏ mọi đặc trưng do con người tạo ra.»
Mọi quy tắc trích xuất đặc trưng nội dung thủ công kiểu truyền thống đều bị loại bỏ sạch.
Vậy hiện tại, thuật toán này dựa vào đâu để đánh giá nội dung tốt hay xấu?
Câu trả lời là dãy hành vi của bạn. Bạn từng thích cái gì, trả lời ai, dừng lại trên bài viết nào quá hai phút, từng chặn loại tài khoản nào. Phoenix đưa những hành vi này vào transformer, để mô hình tự học ra quy luật và tổng kết.
Ví dụ: thuật toán cũ giống bảng chấm điểm do con người lập, mỗi mục tích điểm;
Thuật toán mới giống một AI đã xem toàn bộ lịch sử duyệt web của bạn, trực tiếp đoán bạn muốn xem gì trong giây tiếp theo.
Với người sáng tạo nội dung, điều này hàm ý hai việc:
Thứ nhất, các mẹo như «thời gian đăng bài lý tưởng», «thẻ vàng» v.v., giá trị tham khảo giảm mạnh. Vì mô hình không còn nhìn các đặc trưng cố định này, mà chú trọng sở thích cá nhân của từng người dùng.
Thứ hai, nội dung của bạn có được đề xuất hay không ngày càng phụ thuộc vào «phản ứng của người xem nội dung bạn». Phản ứng này được lượng hóa thành 15 dạng hành vi dự đoán, sẽ phân tích chi tiết ở chương sau.
Thuật toán đang dự đoán 15 phản ứng của bạn
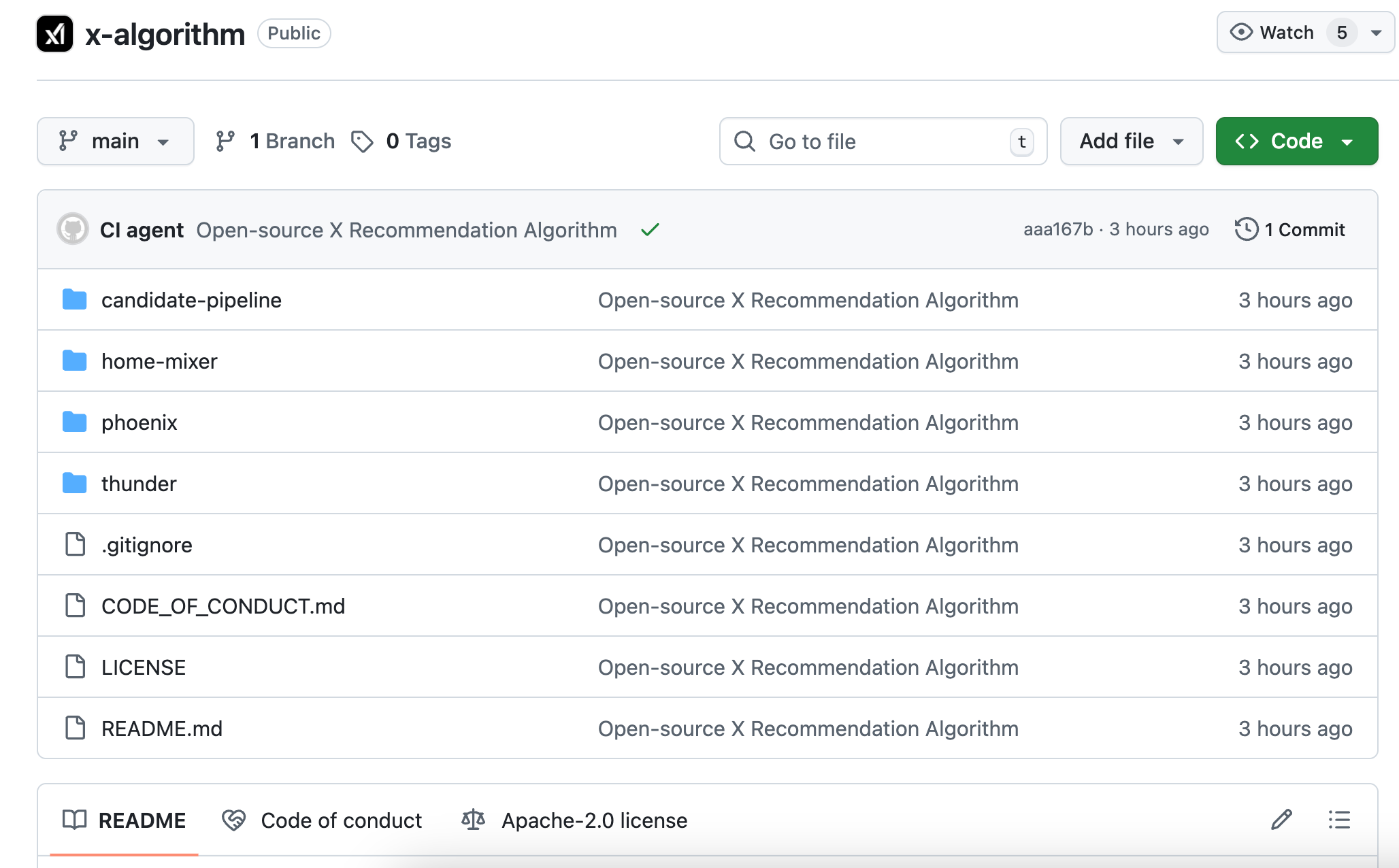
Sau khi Phoenix nhận một bài viết chờ đề xuất, nó sẽ dự đoán 15 hành vi có thể xảy ra khi người dùng hiện tại xem nội dung này:
- Hành vi tích cực: như thích, trả lời, chia sẻ, chia sẻ kèm bình luận, nhấn vào bài viết, nhấn vào trang cá nhân tác giả, xem video quá một nửa, mở rộng hình ảnh, chia sẻ, dừng lại đủ thời gian nhất định, theo dõi tác giả
- Hành vi tiêu cực: nhấn «không quan tâm», chặn tác giả, tắt thông báo từ tác giả, báo cáo
Mỗi hành vi tương ứng một xác suất dự đoán. Ví dụ mô hình đánh giá bạn có 60% khả năng thích bài viết này, 5% khả năng chặn tác giả này, v.v.
Sau đó thuật toán làm một việc đơn giản: nhân các xác suất này với trọng số tương ứng, cộng lại để được một điểm tổng.
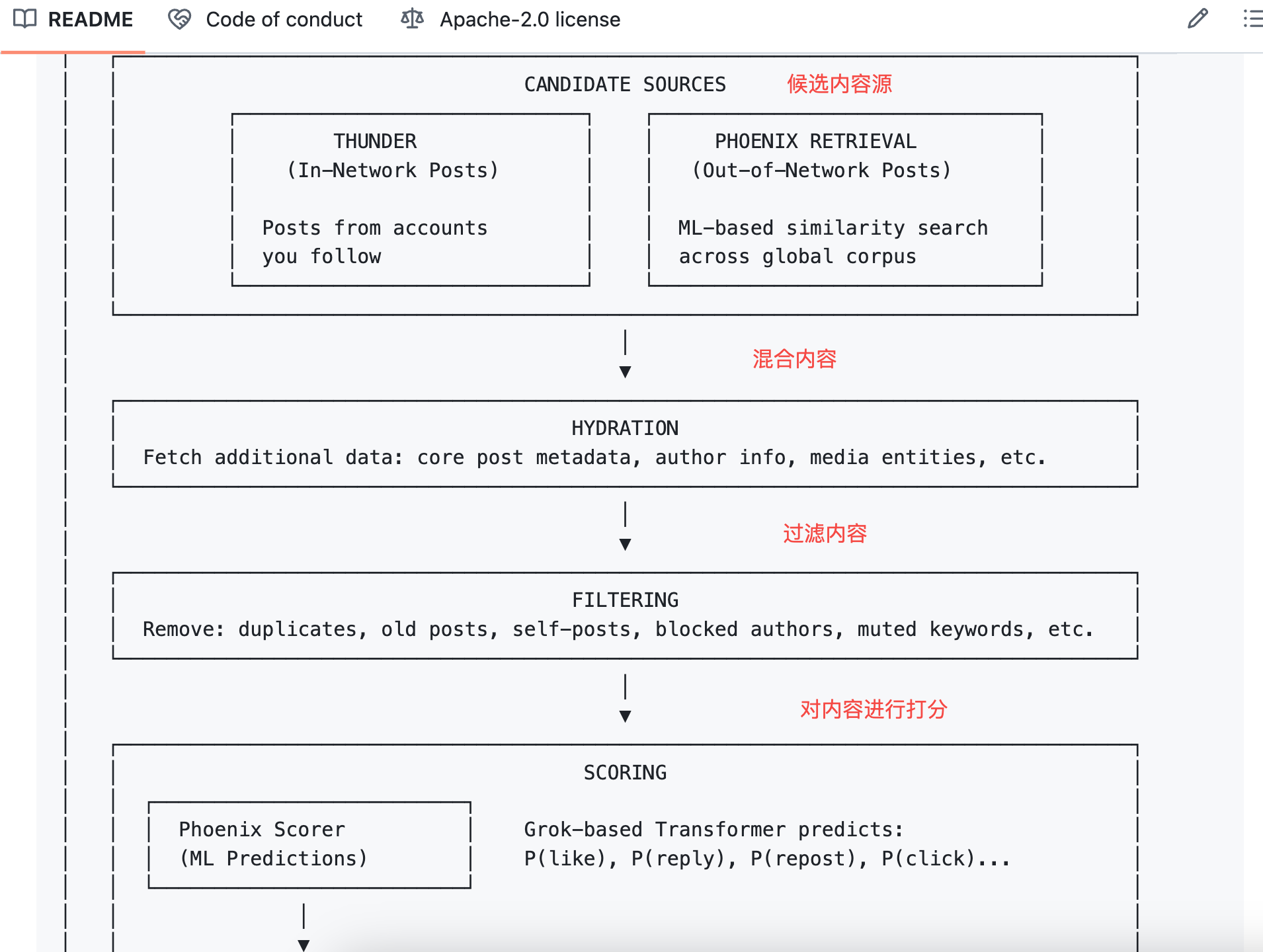
Công thức như sau:
Điểm cuối = Σ (trọng số × P(hành vi))
Trọng số hành vi tích cực là số dương, hành vi tiêu cực là số âm.
Bài viết có điểm cao xếp trước, điểm thấp bị chìm xuống.
Thoát khỏi công thức, nói đơn giản là:
Giờ đây chất lượng một nội dung không còn hoàn toàn do nội dung viết hay dở quyết định (dĩ nhiên tính dễ đọc và lợi ích vẫn là cơ sở lan truyền); mà chủ yếu phụ thuộc vào «nội dung này khiến bạn phản ứng thế nào». Thuật toán không quan tâm chất lượng bài viết, nó chỉ quan tâm hành vi của bạn.
Theo suy nghĩ này, trong trường hợp cực đoan, một bài viết tầm thường nhưng khiến người ta phải trả lời phàn nàn có thể đạt điểm cao hơn bài viết chất lượng nhưng không ai tương tác. Có lẽ đây chính là logic nền tảng của hệ thống này.
Tuy nhiên, phiên bản thuật toán mới công khai chưa tiết lộ giá trị trọng số cụ thể cho các hành vi, nhưng phiên bản năm 2023 thì có.
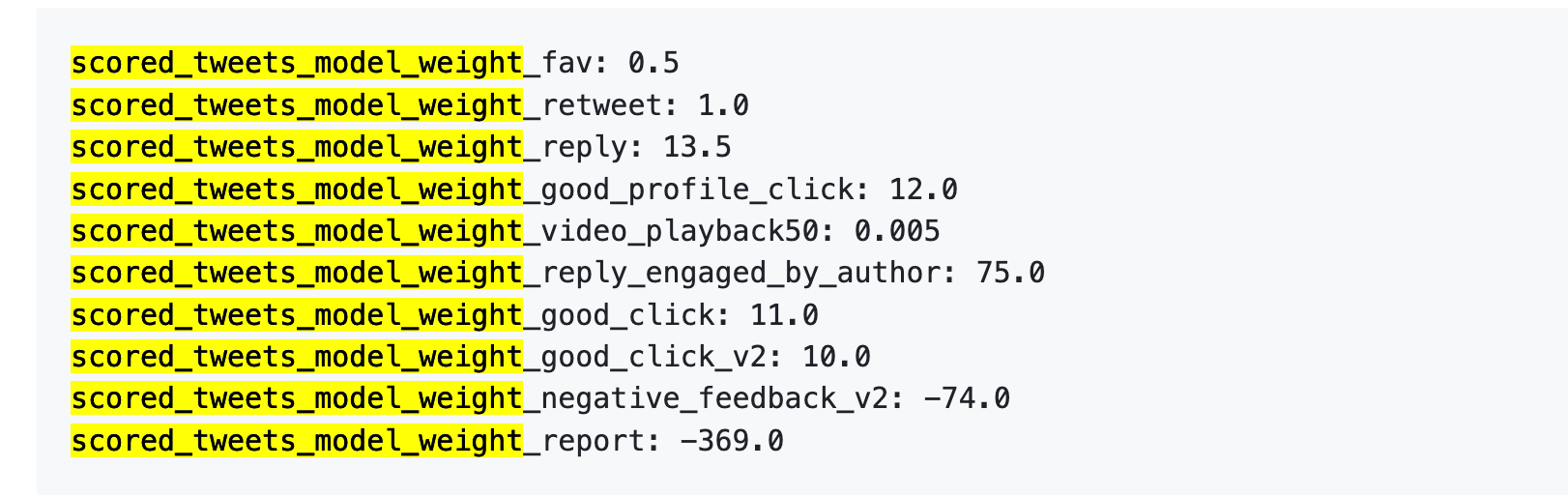
Tham khảo phiên bản cũ: Một lần báo cáo = 738 lượt thích
Giờ ta có thể mổ xẻ dữ liệu năm 23, dù cũ nhưng giúp bạn hiểu «giá trị» các hành vi trong mắt thuật toán chênh lệch bao nhiêu.
Ngày 5 tháng 4 năm 2023, X quả thật từng công bố một nhóm dữ liệu trọng số trên GitHub.
Trực tiếp đưa con số:
Diễn giải rõ hơn:

Nguồn dữ liệu: kho lưu trữ cũ GitHub twitter/the-algorithm-ml, nhấn để xem thuật toán gốc
Một vài con số đáng chú ý.
Thứ nhất, lượt thích gần như chẳng đáng giá. Trọng số chỉ 0.5, thấp nhất trong mọi hành vi tích cực. Trong mắt thuật toán, giá trị một lượt thích gần như bằng không.
Thứ hai, tương tác đối thoại mới là tiền mặt cứng. «Bạn trả lời, tác giả lại trả lời bạn» có trọng số 75, gấp 150 lần lượt thích. Điều thuật toán mong muốn nhất không phải sự tán thưởng một chiều, mà là cuộc đối thoại qua lại.
Thứ ba, phản hồi tiêu cực代价 cực kỳ cao. Một lần Block hoặc Mute (-74) cần 148 lượt thích mới bù đắp. Một lần báo cáo (-369) cần 738 lượt thích. Và những điểm trừ này tích lũy vào điểm uy tín tài khoản bạn, ảnh hưởng đến việc phân phối tất cả bài viết sau này.
Thứ tư, trọng số tỷ lệ xem hết video thấp đến mức vô lý. Chỉ 0.005, gần như có thể bỏ qua. Khác biệt rõ rệt với Douyin, TikTok, hai nền tảng này coi tỷ lệ xem hết là chỉ số cốt lõi.
Chính thức cũng ghi trong cùng tài liệu: «Các trọng số chính xác trong tập tin có thể được điều chỉnh bất kỳ lúc nào... Kể từ đó, chúng tôi đã định kỳ điều chỉnh trọng số để tối ưu hóa các chỉ số nền tảng.»
Trọng số có thể thay đổi bất cứ lúc nào, và quả thật đã điều chỉnh.
Phiên bản mới không công bố giá trị cụ thể, nhưng logic khung trong README vẫn giống: hành vi tích cực cộng điểm, tiêu cực trừ điểm, cộng tổng có trọng số.
Con số cụ thể có thể đã thay đổi, nhưng mối quan hệ về bậc độ lớn có lẽ vẫn giữ nguyên. Bạn trả lời bình luận người khác hữu ích hơn nhận 100 lượt thích. Khiến người khác muốn block bạn tệ hại hơn là không có tương tác.
Biết những điều này rồi, người sáng tạo nên làm gì
Sau khi mổ xẻ mã nguồn cũ - mới của Twitter, tổng hợp lại, rút ra vài kết luận khả thi.
1. Trả lời người bình luận bạn. Trong bảng trọng số, «tác giả trả lời người bình luận» là hạng mục điểm cao nhất (+75), cao gấp 150 lần người dùng đơn phương thích. Không phải bảo bạn đi cầu xin bình luận, mà là khi có người bình luận thì hãy trả lời. Dù chỉ một câu «cảm ơn», thuật toán cũng sẽ ghi nhận.
2. Đừng khiến người khác muốn bỏ qua. Tác động tiêu cực của một lần block cần 148 lượt thích mới bù đắp. Nội dung gây tranh cãi thật sự dễ tạo tương tác, nhưng nếu kiểu tương tác là «người này phiền quá, block», điểm uy tín tài khoản bạn sẽ liên tục tổn hại, ảnh hưởng đến việc phân phối tất cả bài viết sau này. Lưu lượng gây tranh cãi là con dao hai lưỡi, chưa chặt người khác đã chặt mình trước.
3. Đặt liên kết ngoài ở phần bình luận. Thuật toán không muốn dẫn người dùng ra khỏi nền tảng. Đưa liên kết trong nội dung chính sẽ bị giảm trọng số, Musk từng công khai nói điều này. Muốn dẫn lưu, hãy viết nội dung trong bài, đặt liên kết ở bình luận đầu tiên.
4. Đừng đăng bài liên tục. Trong mã phiên bản mới có một Author Diversity Scorer, nhiệm vụ giảm trọng số cho các bài viết liên tiếp của cùng một tác giả. Mục đích thiết kế là để feed người dùng đa dạng hơn, hậu quả là đăng mười bài liên tiếp không bằng một bài chất lượng.
6. Không còn «thời gian đăng bài lý tưởng» nữa. Thuật toán cũ có đặc trưng thủ công «thời gian đăng», phiên bản mới nói bỏ là bỏ. Phoenix chỉ xem dãy hành vi người dùng, không quan tâm bài viết đăng lúc mấy giờ. Những hướng dẫn kiểu «đăng bài hiệu quả nhất vào 3 giờ chiều thứ Ba» ngày càng mất giá trị tham khảo.
Trên đây là những điều có thể đọc ra từ cấp độ mã nguồn.
Còn một số mục cộng/trừ điểm khác đến từ tài liệu công khai của X, không nằm trong kho lưu trữ mở mã lần này: chứng nhận dấu xanh có cộng điểm, viết toàn chữ in hoa bị giảm trọng số, nội dung nhạy cảm kích hoạt cắt giảm 80% phạm vi tiếp cận. Những quy tắc này không công khai, nên không đi sâu.
Tóm lại, lần công khai này khá thực chất.
Kiến trúc hệ thống đầy đủ, logic triệu hồi nội dung ứng cử viên, quy trình xếp hạng chấm điểm, cách triển khai các bộ lọc. Mã chủ yếu dùng Rust và Python, cấu trúc rõ ràng, README viết chi tiết hơn nhiều dự án thương mại.
Nhưng có vài thứ then chốt chưa công bố.
1. Tham số trọng số chưa công khai. Trong mã chỉ ghi «hành vi tích cực cộng điểm, tiêu cực trừ điểm», cụ thể like được bao nhiêu điểm, block trừ bao nhiêu điểm, không nói. Phiên bản 2023 ít ra còn công bố con số, lần này chỉ đưa khung công thức.
2. Trọng số mô hình chưa công khai. Phoenix dùng transformer Grok, nhưng tham số bên trong mô hình không được công bố. Bạn có thể thấy mô hình được gọi ra sao, nhưng không thấy bên trong nó tính toán thế nào.
3. Dữ liệu huấn luyện chưa công khai. Mô hình được huấn luyện bằng dữ liệu gì, hành vi người dùng lấy mẫu ra sao, mẫu tích cực - tiêu cực xây dựng thế nào, đều không nói.
Ví dụ, lần công khai này giống như nói với bạn «chúng tôi dùng cộng tổng có trọng số để tính điểm», nhưng không nói trọng số là bao nhiêu; nói «chúng tôi dùng transformer để dự đoán xác suất hành vi», nhưng không nói bên trong transformer trông thế nào.
So sánh ngang, TikTok và Instagram thậm chí chưa từng công khai những thứ này. Lượng thông tin X công khai lần này thực sự nhiều hơn các nền tảng chính khác. Chỉ là chưa đạt tới «minh bạch hoàn toàn».
Không có nghĩa việc công khai không có giá trị. Với người sáng tạo và nhà nghiên cứu, được xem mã nguồn luôn tốt hơn không được xem.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














